
准备工作:
准备三台虚拟机,关闭防火墙,修改他们的主机名,第一台虚拟机为master 剩下两台分别是slave1和slave2,修改hosts文件 修改他们的主机映射,三台进行免密操作。
基础配置:
修改主机名
永久修改:vim /etc/hostname
重启 restart
零时修改: hostnamectl set-hostname name
刷新 bash
关闭防火墙,配置主机映射
1.判断防火墙是否关闭 systemctl status firewalld
2.关闭防火墙 systemctl stop firewalld ps:我们只需要关闭防火墙即可,三台都要关闭
3.开启 systemctl start firewalld
修改host文件
vim /etc/hosts
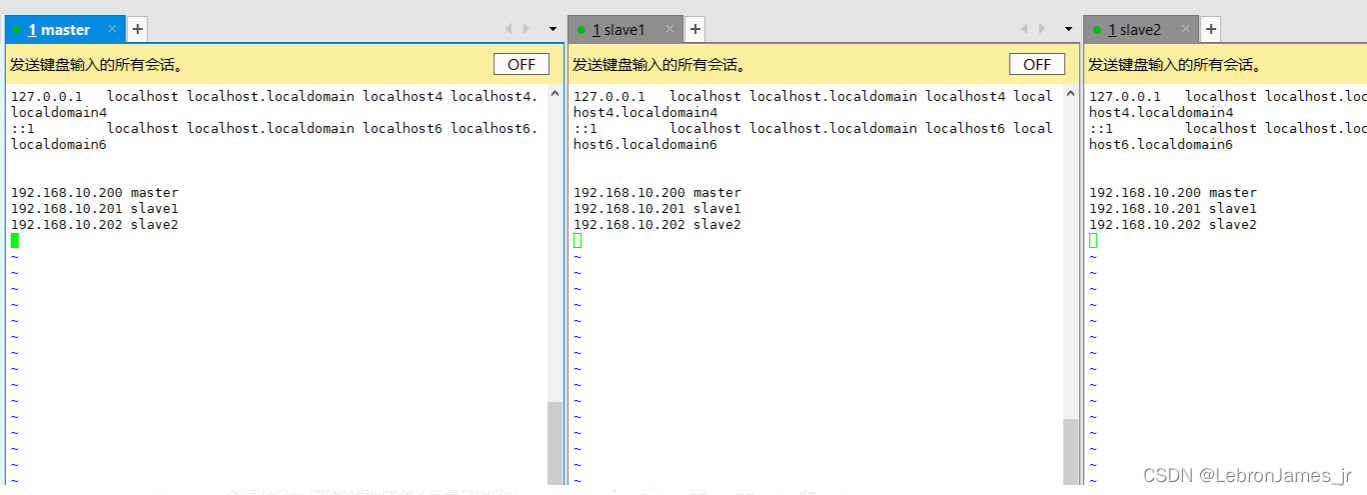
ip地址填你们自己的 上面的图的ip地址是我的。
免密登入:
ssh-keygen 生成公钥之后三次回车
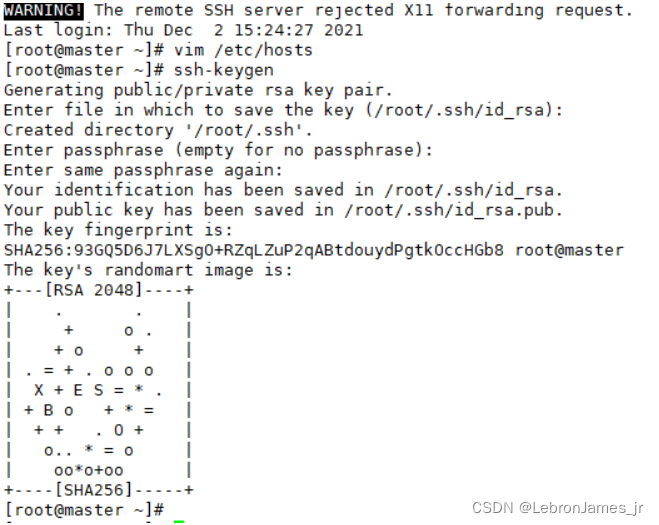
出现这个表示秘钥生成成功
进行配置免密登入:
ssh-copy-id master #对master进行免密
ssh-copy-id slave1 #对slave1进行免密
ssh-copy-id slave2 #对slave2进行免密
shh localhost #内回环
如果显示无法找到hostname 就去hosts文件看一下是不是自己的单词或者ip写错了
或者可以直接使用ssh-copy-id (192.xx.xx.xxx)ip地址 #对指定虚拟机进行免密
第一步 安装JDK
首先解压文件jdk压缩包到指定目录
tar -zxvf 压缩包名字 -C 解压路径
配置系统环境变量
vim /etc/profile
配置代码
JAVA_HOME=/usr/java/jdk1.8.0_221
CLASSPATH=$JAVA_HOME/lib
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME CLASSPATH PATH
分发给slave1 slave2-
分发命令:
scp -r /分发的文件夹路径地址 分发ip地址或者主机名:/上一级路径地址
示例代码:
scp -r /usr/java/ slave1:/usr/
scp -r /usr/java/ slave2:/usr/
分发系统变量
scp -r /etc/profile/ slave1:/etc/
scp -r /etc/profile/ slave2:/etc/
JDK分发过去之后,环境变量也要记得分发过去。
在另外两个节点
source /etc/profile
之后查看是否配置成功
java -version
出现版本号 则配置成功
HADOOP集群搭建:
解压文件jdk压缩包到指定路径
示例代码: tar -zxvf hadoop-2.7.7.tar.gz -C /usr/hadoop/
配置hadoop系统环境变量
vim /etc/profile
配置系统环境变量代码
#hadoop
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.7
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
上面是我的hadoop安装地址 HADOOP_HOME的安装路径需要替换成你自己hadoop安装目录
source /etc/profile
查看服务
hadoop version
来到配置文件目录下
cd /usr/hadoop/hadoop-2.7.7/etc/hadoop/
cd 进入你安装的hadoop的目录/etc/hadoop/
然后可以ls 查看下面的文件
1.编辑hadoop-env.sh文件
往里面添加java_home就行了,可以在环境变量里面复制过来 /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_221
2.vim yarn-evn.sh
同样添加java_home进去
export JAVA_HOME=/usr/java/jdk1.8.0_221
3.设置全局参数,指定NN的IP为master,端口为9000
vim core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-2.7.7/hdfs/tmp</value>
</property>
4.设置HDFS参数
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/hadoopData/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/hadoopData/data</value>
</property>
</configuration>
5.配置yarn核心参数'
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Site specific YARN configuration properties -->
</configuration>
6 vim mapred-site.xml 这个文件只有模板文件
需要cp mapred-site.xml.template* *mapred-site.xml
然后编辑刚刚cp过的文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
7.编辑slaves文件
往里面添加另外两个虚拟机的主机名,如果主机名没有配置好可以输入另外两台的ip地址
slave1
slave2
8.编辑master文件
添加主节点虚拟机的名字进去就好了,
master
9.分发集群 ,系统环境变量到slave1 slave2
ps:分发hadoop过去 同时也要分发环境变量过去,另外两台别忘记source一下。
10.初始化hadoop 在master节点
初始化命令为: hadoop namenode -format
11.启动集群 查看节点
start-all.sh
然后可以输入jps命令 查看节点 看看是否启动成功,
可以在浏览器输入
192.xxx.xxx.xx (你的master节点的ip地址):/50070 进入web页面
示例代码:192.168.10.100:50070
如果进不去 则是没有关闭防火墙,或者节点没有开启,节点开不起来可以重新输入启动命令,如果还是起不来,则要去检查hadoop的配置文件是否写正确,这东西熟能生巧,多搭建就好了,嘿嘿,到此教程结束了,小编第一次发教程可能写的不是太好,请多多担待。
版权归原作者 LebronJames_jr 所有, 如有侵权,请联系我们删除。