
本文介绍Flume监听本地文件采集数据流到HDFS
我还写了一篇文章是Flume监听端口采集数据流到Kafka【点击即可跳转,写的也非常详细】
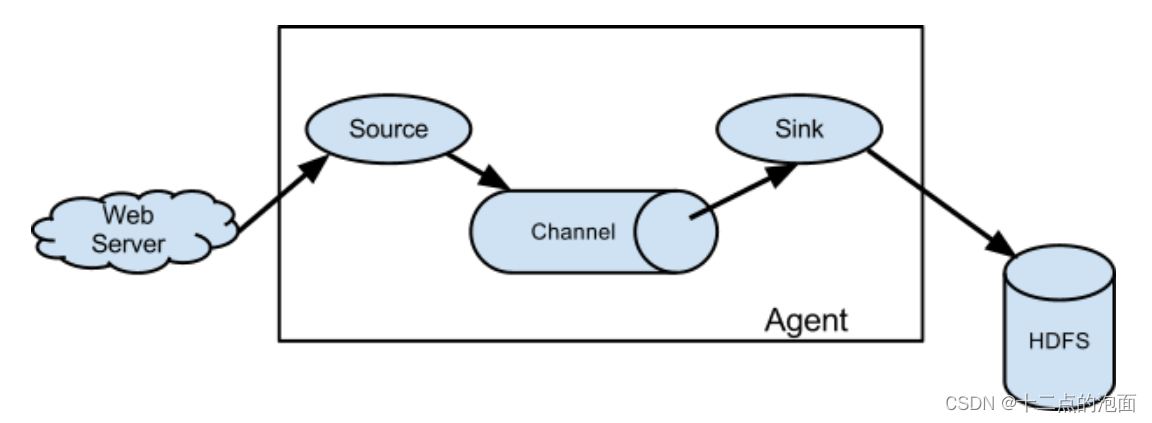
任务一:
在Master节点使用Flume采集/data_log目录下实时日志文件中的数据(实时日志文件生成方式为在/data_log目录下执行./make_data_file_v1命令即可生成日志文件,如果没有权限,请执行授权命令chmod 777 /data_log/make_data_file_v1),将数据存入到Kafka的Topic中(Topic名称分别为ChangeRecord、ProduceRecord和EnvironmentData,分区数为4),将Flume采集ChangeRecord主题的配置截图粘贴至对应报告中;
任务二:
编写新的Flume配置文件,将数据备份到HDFS目录/user/test/flumebackup下,要求所有主题的数据使用同一个Flume配置文件完成,将Flume的配置截图粘贴至对应报告中。
①模拟数据源环境
进入/data_log路径运行脚本mak
本文转载自: https://blog.csdn.net/2301_78038072/article/details/135490910
版权归原作者 十二点的泡面 所有, 如有侵权,请联系我们删除。
版权归原作者 十二点的泡面 所有, 如有侵权,请联系我们删除。