
论文:CBAM: Convolutional Block Attention Module
代码: code
前言
CBAM( Convolutional Block Attention Module )是一种轻量级注意力模块的提出于2018年,它可以在空间维度和通道维度上进行Attention操作。论文在Resnet和MobileNet上加入CBAM模块进行对比,并针对两个注意力模块应用的先后进行实验,同时进行CAM可视化,可以看到Attention更关注目标物体。
1.什么是CBAM?
CBAM(Convolutional Block Attention Module)是轻量级的卷积注意力模块,它结合了通道和空间的注意力机制模块。
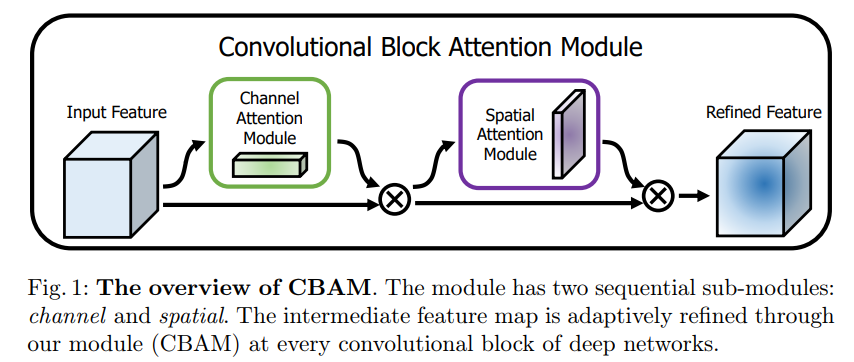
上图可以看到,CBAM包含CAM(Channel Attention Module)和SAM(Spartial Attention Module)两个子模块,分别进行通道和空间上的Attention。这样不只能够节约参数和计算力,并且保证了其能够做为即插即用的模块集成到现有的网络架构中去。
由上图所示,有输入、通道注意力模块、空间注意力模块和输出组成。输入特征,然后是通道注意力模块一维卷积
,将卷积结果乘原图,将CAM输出结果作为输入,进行空间注意力模块的二维卷积
,再将输出结果与原图相乘。
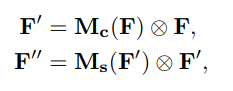
(1)Channel attention module(CAM)
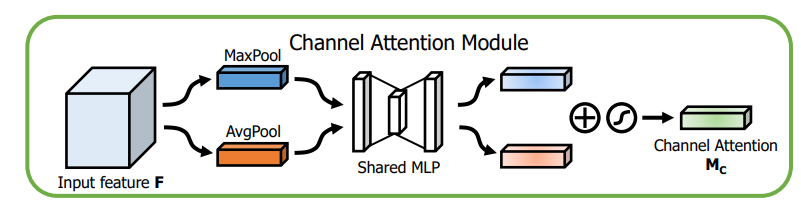
通道注意力模块:通道维度不变,压缩空间维度。该模块关注输入图片中有意义的信息(分类任务就关注因为什么分成了不同类别)。
图解:将输入的feature map经过两个并行的MaxPool层和AvgPool层,将特征图从CHW变为C11的大小,然后经过Share MLP模块,在该模块中,它先将通道数压缩为原来的1/r(Reduction,减少率)倍,再扩张到原通道数,经过ReLU激活函数得到两个激活后的结果。将这两个输出结果进行逐元素相加,再通过一个sigmoid激活函数得到Channel Attention的输出结果,再将这个输出结果乘原图,变回CHW的大小。
通道注意力公式:
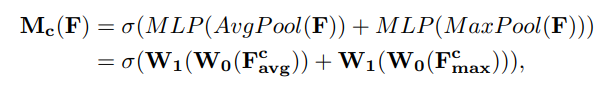
CAM与SEnet的不同之处是加了一个并行的最大池化层,提取到的高层特征更全面,更丰富。论文中也对为什么如此改动做出了解释。
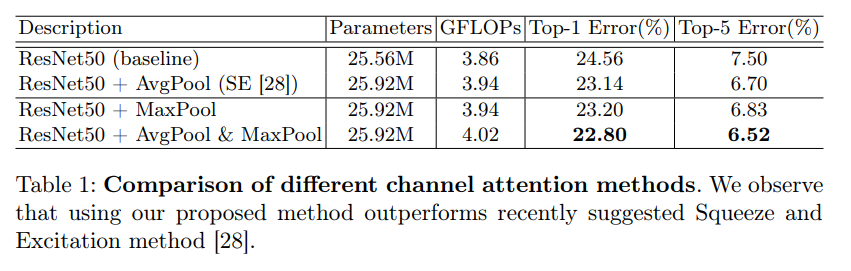
AvgPool & MaxPool对比实验
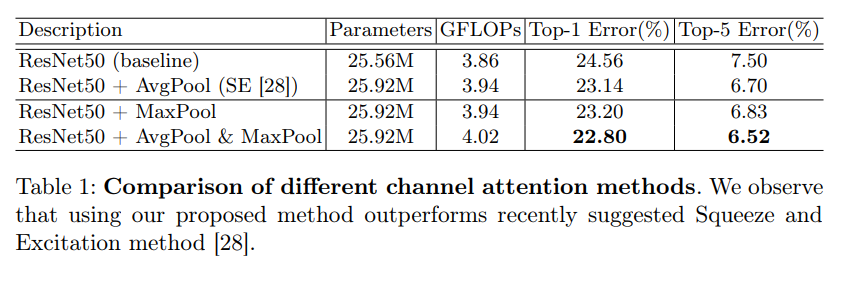
在channel attention中,表1对于pooling的使用进行了实验对比,发现avg & max的并行池化的效果要更好。这里也有可能是池化丢失的信息太多,avg&max的并行连接方式比单一的池化丢失的信息更少,所以效果会更好一点。
(2)Spatial attention module(SAM)
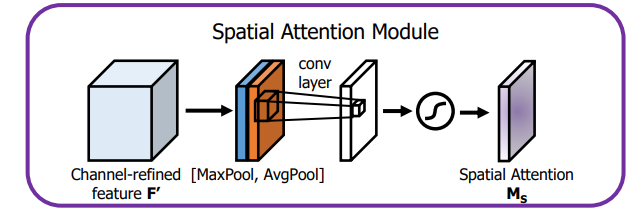
** 空间注意力模块:空间维度不变,压缩通道维度。该模块关注的是目标的位置信息**。
图解:将Channel Attention的输出结果通过最大池化和平均池化得到两个1HW的特征图,然后经过Concat操作对两个特征图进行拼接,通过77卷积变为1通道的特征图(实验证明77效果比33好),再经过一个sigmoid得到Spatial Attention的特征图,最后将输出结果乘原图变回CH*W大小。
空间注意力公式:
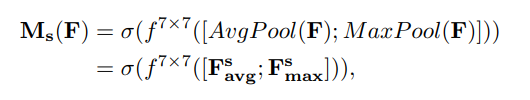
(3)CAM和SAM组合形式
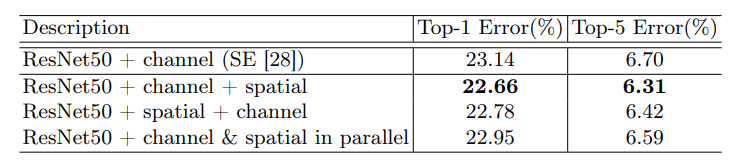
通道注意力和空间注意力这两个模块能够以并行或者串行顺序的方式组合在一块儿,关于通道和空间上的串行顺序和并行作者进行了实验对比,发现先通道再空间的结果会稍微好一点。具体实验结果如下:
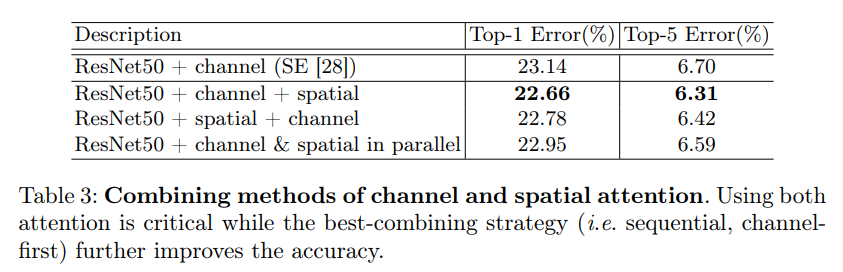
由表三可以看出,基于ResNet网络,两个Attention模块按Channel Attention + Spatial Attention的顺序效果会更好一些。
2.消融实验
(1)Channel attention
首先是不同的通道注意力结果比较,平均池化、最大池化和两种联合使用并使用共享MLP来进行推断保存参数,结果如下:
首先,参数量和内存损耗差距不大,而错误率的提高,显然两者联合的方法更优。
(2)Spatial attention
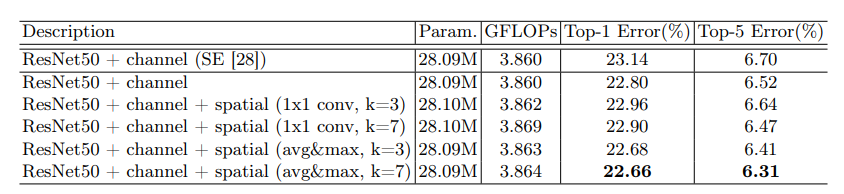
对比77卷积核和33卷积核的效果,结果7*7卷积核效果更好
(3)Channel attention+spatial attention
对比SEnet、CAM和SAM并行、SAM+CAM和CAM+SAM的效果,最终CAM+SAM效果最好 。
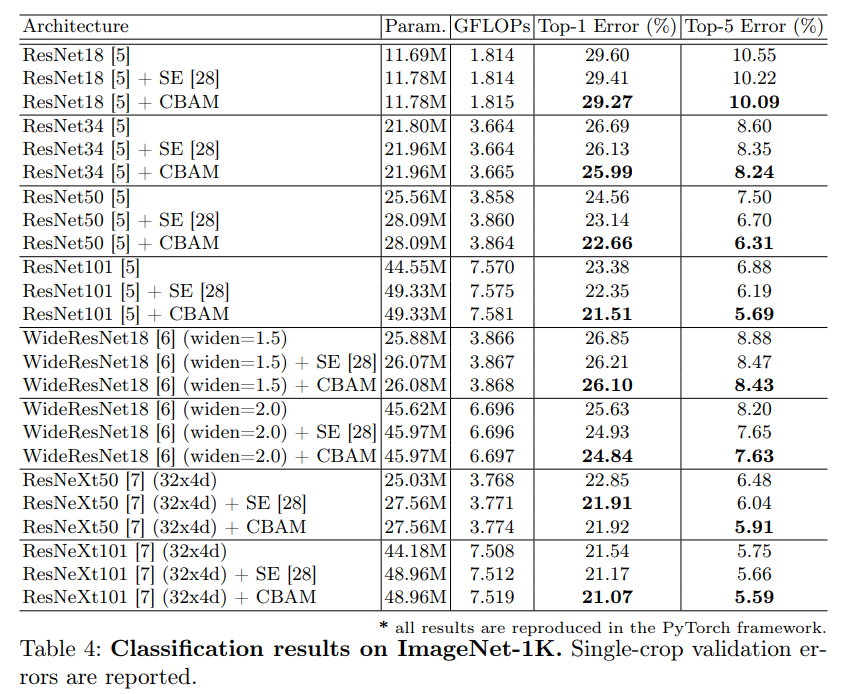
3.图像分类
再数据集ImageNet-1K上使用ResNet网络进行对比实验
4.目标检测
数据集:MS COCO和VOC 2007
如下表所示:
MS COCO上,CBAM在识别任务上泛化性能较基线网络有了显著提高。。
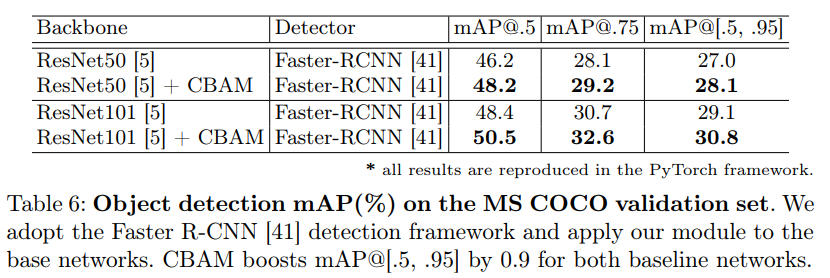
如下表:
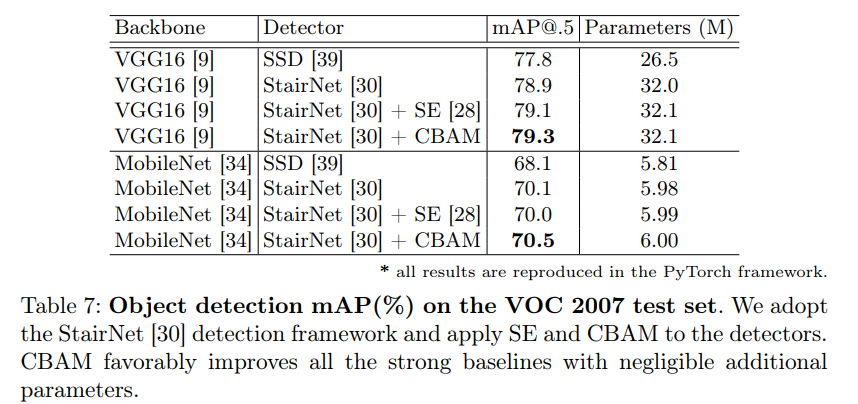
VOC 2007中,采用阶梯检测框架,并将SE和CBAM应用于检测器。CBAM极大的改善了所有强大的基线与微不足道的额外参数。
5.CBAM可视化

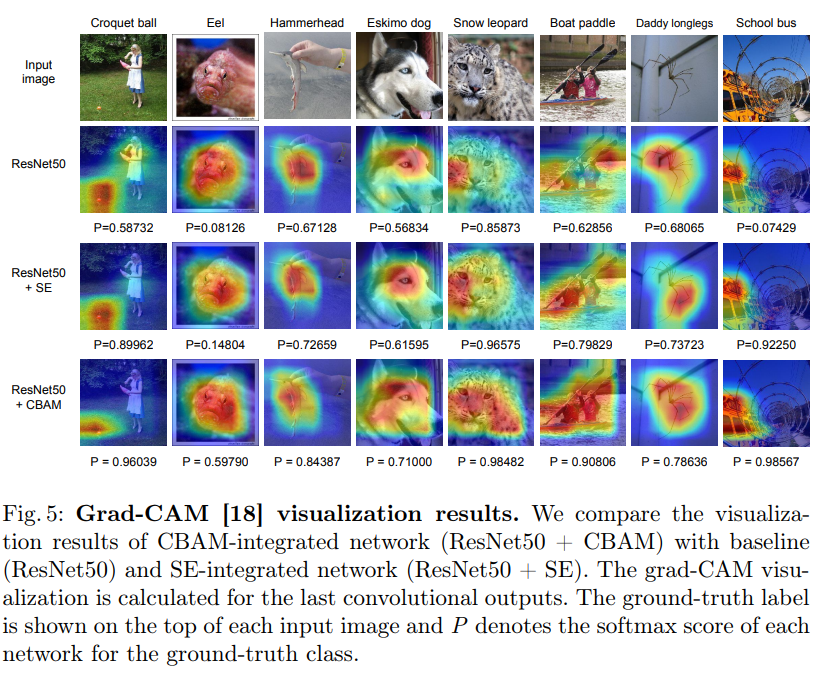
本文利用Grad CAM对不一样的网络进行可视化后,能够发现,引入 CBAM 后,特征覆盖到了待识别物体的更多部位,而且最终判别物体的几率也更高,这表示注意力机制的确让网络学会了关注重点信息。
6.Pytorch 代码实现
代码实现:
import torch
import torch.nn as nn
class CBAMLayer(nn.Module):
def __init__(self, channel, reduction=16, spatial_kernel=7):
super(CBAMLayer, self).__init__()
# channel attention 压缩H,W为1
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# shared MLP
self.mlp = nn.Sequential(
# Conv2d比Linear方便操作
# nn.Linear(channel, channel // reduction, bias=False)
nn.Conv2d(channel, channel // reduction, 1, bias=False),
# inplace=True直接替换,节省内存
nn.ReLU(inplace=True),
# nn.Linear(channel // reduction, channel,bias=False)
nn.Conv2d(channel // reduction, channel, 1, bias=False)
)
# spatial attention
self.conv = nn.Conv2d(2, 1, kernel_size=spatial_kernel,
padding=spatial_kernel // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
max_out = self.mlp(self.max_pool(x))
avg_out = self.mlp(self.avg_pool(x))
channel_out = self.sigmoid(max_out + avg_out)
x = channel_out * x
max_out, _ = torch.max(x, dim=1, keepdim=True)
avg_out = torch.mean(x, dim=1, keepdim=True)
spatial_out = self.sigmoid(self.conv(torch.cat([max_out, avg_out], dim=1)))
x = spatial_out * x
return x
x = torch.randn(1,1024,32,32)
net = CBAMLayer(1024)
y = net.forward(x)
print(y.shape)
总结
- CBAM中作者对两个注意力机制使用的先后顺序做了实验,发现通道注意力在空间注意力之前效果最好。
- 作者在实验中应用了grad-CAM来可视化feature map,是个非常有用的可视化手段,在图像分类任务中可以观察feature map的特征,解释了为什么模型将原图分类到某一类的结果。
- 加入CBAM模块不一定会给网络带来性能上的提升,受自身网络还有数据等其他因素影响,甚至会下降。如果网络模型的泛化能力已经很强,而你的数据集不是benchmarks而是自己采集的数据集的话,不建议加入CBAM模块。CBAM性能虽然改进的比SE高了不少,但绝不是无脑加入到网络里就能有提升的。也要根据自己的数据、网络等因素综合考量。
版权归原作者 Billie使劲学 所有, 如有侵权,请联系我们删除。