
目录
一、前言
SQL(结构化查询语言)是一种用于管理关系型数据库的标准语言。它允许用户通过使用SQL语言来操作数据库中的数据。而在SQL中,UNION是一个非常强大的功能,它可以将多个SELECT语句的结果合并成一个结果集。本文将以GaussDB数据库为例,介绍一下UNION操作符的使用。
二、GaussDB UNION/UNION ALL
1、GaussDB UNION 操作符
GaussDB UNION 操作符用于合并两个或多个 SELECT 语句的结果集。请注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
2、语法定义
1****)UNION语法
SELECT column1
,column2
,……
FROM table1
[WHERE condition]
UNION
SELECT column1
,column2
,……
FROM table2
[WHERE condition]
2****)UNION ALL 语法
SELECT column1
,column2
,……
FROM table1
[WHERE condition]
UNION ALL
SELECT column1
,column2
,……
FROM table2
[WHERE condition]
说明:UNION在合并两个或多个集合时会执行去重操作,而UNION ALL则直接将两个或者多个结果集合并,不执行去重。 另外,执行去重会消耗大量的时间,因此,在一些实际应用场景中,如果通过业务逻辑已确认了两个集合不存在重重复数据时,可直接用UNION ALL 替代UNION,以便提升性能。
三、GaussDB实验示例
本文以GaussDB数据库为实验平台,
1、创建实验表并初始化
1****)学生信息表student(ID、姓名、性别、城市)
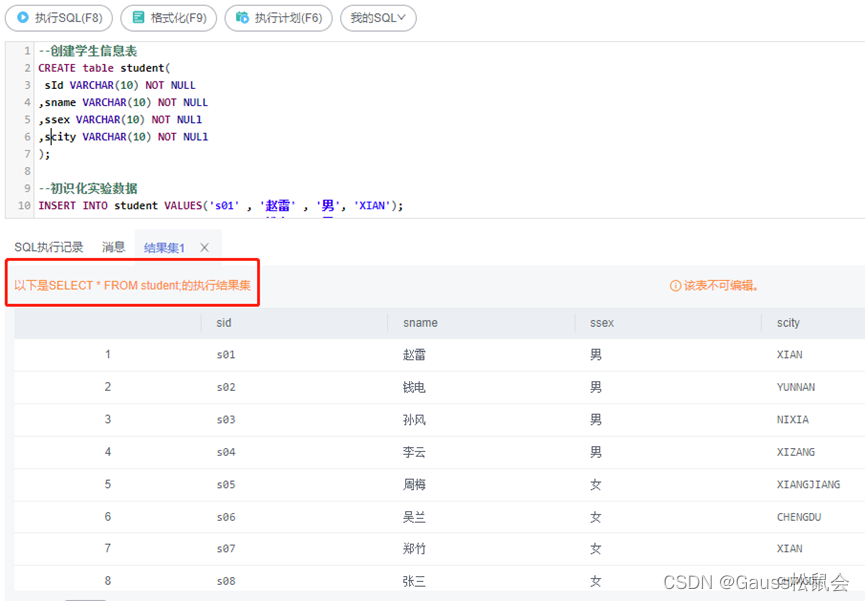
--创建学生信息表
CREATE table student(
sId VARCHAR(10) NOT NULL
,sname VARCHAR(10) NOT NULL
,ssex VARCHAR(10) NOT NULl
,scity VARCHAR(10) NOT NULl
);
--初识化实验数据
INSERT INTO student VALUES('s01' , '赵雷' , '男', 'XIAN');
INSERT INTO student VALUES('s02' , '钱电' , '男', 'YUNNAN');
INSERT INTO student VALUES('s03' , '孙风' , '男', 'NIXIA');
INSERT INTO student VALUES('s04' , '李云' , '男', 'XIZANG');
INSERT INTO student VALUES('s05' , '周梅' , '女', 'XINJIANG');
INSERT INTO student VALUES('s06' , '吴兰' , '女', 'CHENGDU');
INSERT INTO student VALUES('s07' , '郑竹' , '女', 'XIAN');
INSERT INTO student VALUES('s08' , '张三' , '女', 'CHENGDU');
--查看结果集
SELECT * FROM student;
2****)教师信息表teacher(ID、姓名、性别、城市)
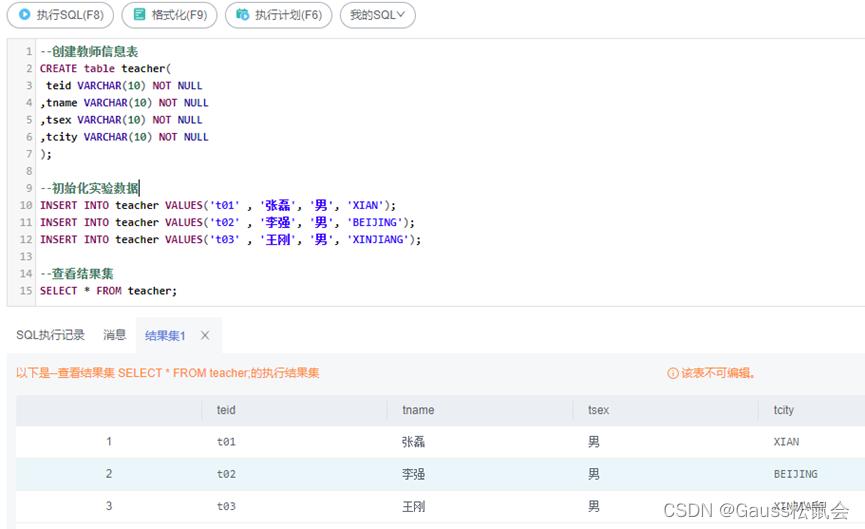
--创建教师信息表
CREATE table teacher(
teid VARCHAR(10) NOT NULL
,tname VARCHAR(10) NOT NULL
,tsex VARCHAR(10) NOT NULL
,tcity VARCHAR(10) NOT NULL
);
--初始化实验数据
INSERT INTO teacher VALUES('t01' , '张磊', '男', 'XIAN');
INSERT INTO teacher VALUES('t02' , '李强', '男', 'BEIJING');
INSERT INTO teacher VALUES('t03' , '王刚', '男', 'XINJIANG');
--查看结果集
SELECT * FROM teacher;
2、合并且除重(UNION)
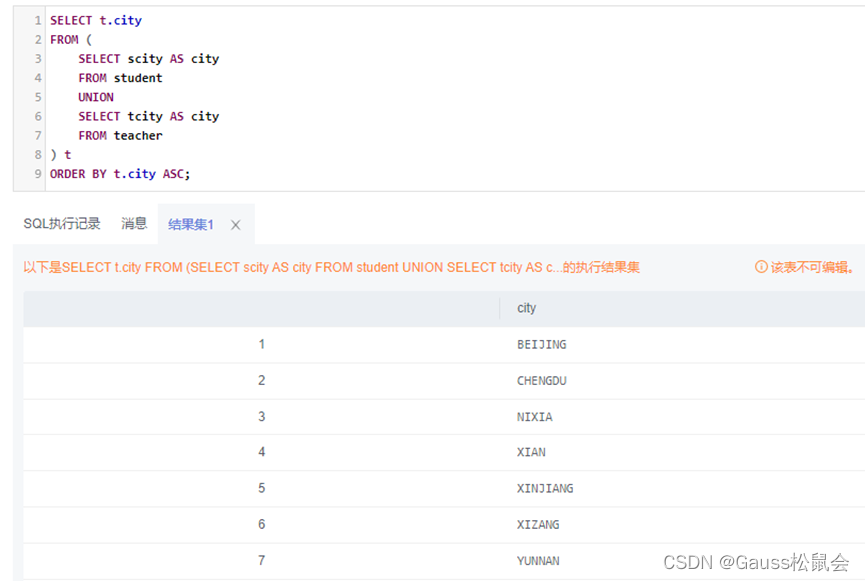
--获取学生和教师所属的城市,并按城市名称首字母升序排序。
SELECT t.city
FROM (
SELECT scity AS city
FROM student
UNION
SELECT tcity AS city
FROM teacher
) t
ORDER BY t.city ASC;
结果集如下截图,且城市数据不存在重复:
3、合并不除重(UNION ALL)
--获取所有学生和教师所属的城市,并按城市名称首字母升序排序。
SELECT t.city
FROM (
SELECT scity AS city
FROM student
UNION ALL
SELECT tcity AS city
FROM teacher
) t
ORDER BY t.city ASC;
结果集如下截图,罗列了所有城市数据:

4、合并带有WHERE子句SQL结果集(UNION ALL)
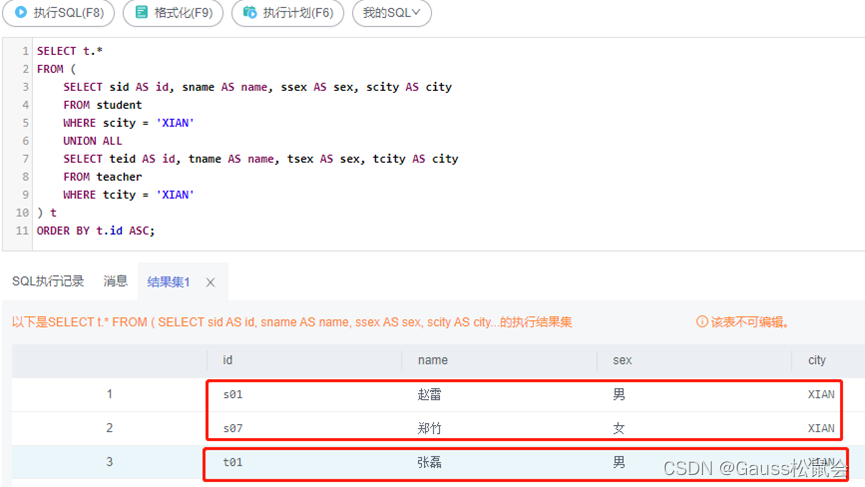
--获取来自'XIAN'的学生和教师的所有信息,并按学生和教师的编号升序排序。
SELECT t.*
FROM
(SELECT Sid AS id
,Sname AS name
,Ssex AS sex
,Scity AS city
FROM student WHERE Scity='XIAN'
UNION ALL
SELECT Tid AS id
,Tname AS name
,Tsex AS sex
,Tcity AS city
FROM teacher WHERE Tcity='XIAN') t
ORDER BY t.id ASC;
结果集如下截图,罗列了'XIAN'的学生和教师的所有信息:
5、业务逻辑除重后合并(UNION ALL)
在一些业务场景下,比如上游系统提供的两张表或者多张表之间互相不会存重复数据,且自身也不存在重复数据,则为了提升合并时SQL性能、减少SQL执行时间,则选择UNION ALL操作符。
四、GaussDB UNION常见错误
1、“each UNION query must have the same number of columns”
解决思路:根据提示查看两个表的表结构,看字段数量是否一支。

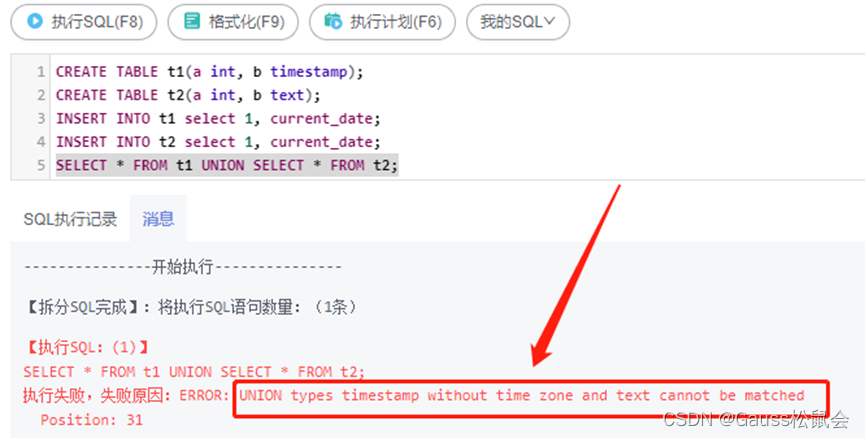
2、“UNION types timestamp without time zone and text cannot be matched”
解决思路:根据提示查看两个表的表结构,看字段类型是否一致。
五、小结
在实际业务场景中,无论选择GaussDB数据库,还是其他关系型数据库,在使用UNION和UNION ALL 时,都需要注意以下几点:
- 左右两侧的SQL字段数量和字段类型需要保持一致;
- 业务需求是否需要考虑数据除重(合并前除重还是合并时除重);
- 根据表中数据量的大小,需要对SQL的执行效率进行评估,从而考虑是否需要选择临时表进行过渡后再合并;
- 需要考虑SQL编写的复杂度,不能为了写SQL而写SQL,需要结合业务需求进行选择。
——结束
版权归原作者 Gauss松鼠会 所有, 如有侵权,请联系我们删除。