
HDFS Disk Balancer
背景
- 相比较于个人PC,服务器一般可以通过挂载多块磁盘来扩大单机的存储能力
- 在Hadoop HDFS中,DataNode负责最终数据block的存储,在所在机器上的磁盘之间分配数据块。当写入新block时,DataNodes将根据选择策略(循环策略或可用空间策略)来选择block的磁盘(卷)
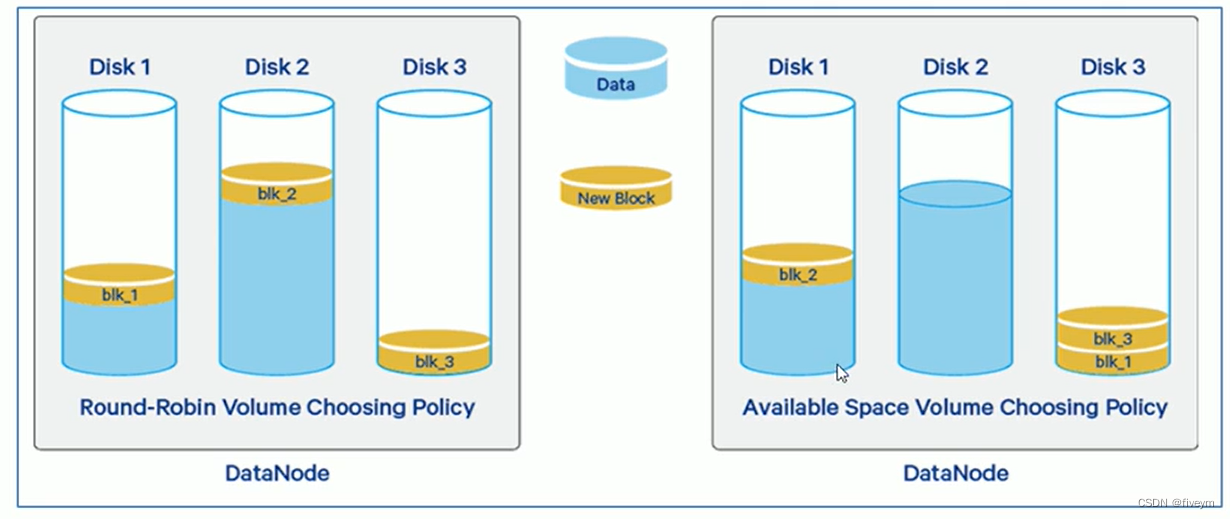
- 循环策略:它将新的block均匀分布在可用磁盘上
- 可用空间策略:此策略将数据写入具有更多可用空间(按百分比)的磁盘
产生的问题以及解决方法
- 在长期运行的集群中采用循环策略的时,DataNode有时会不均匀的填充其存储目录(磁盘/卷),从而导致某些磁盘已满而其他磁盘却很少使用的情况。发生这种情况的原因可能是由于大量的写入和删除操作,也可能是由于更换了磁盘。
- 另外,如果我们使用基于可用空间选择策略,则每个新写入将进入新添加的空磁盘,从而使该期间的其他磁盘处于空闲状态,这将在新磁盘上创建瓶颈。
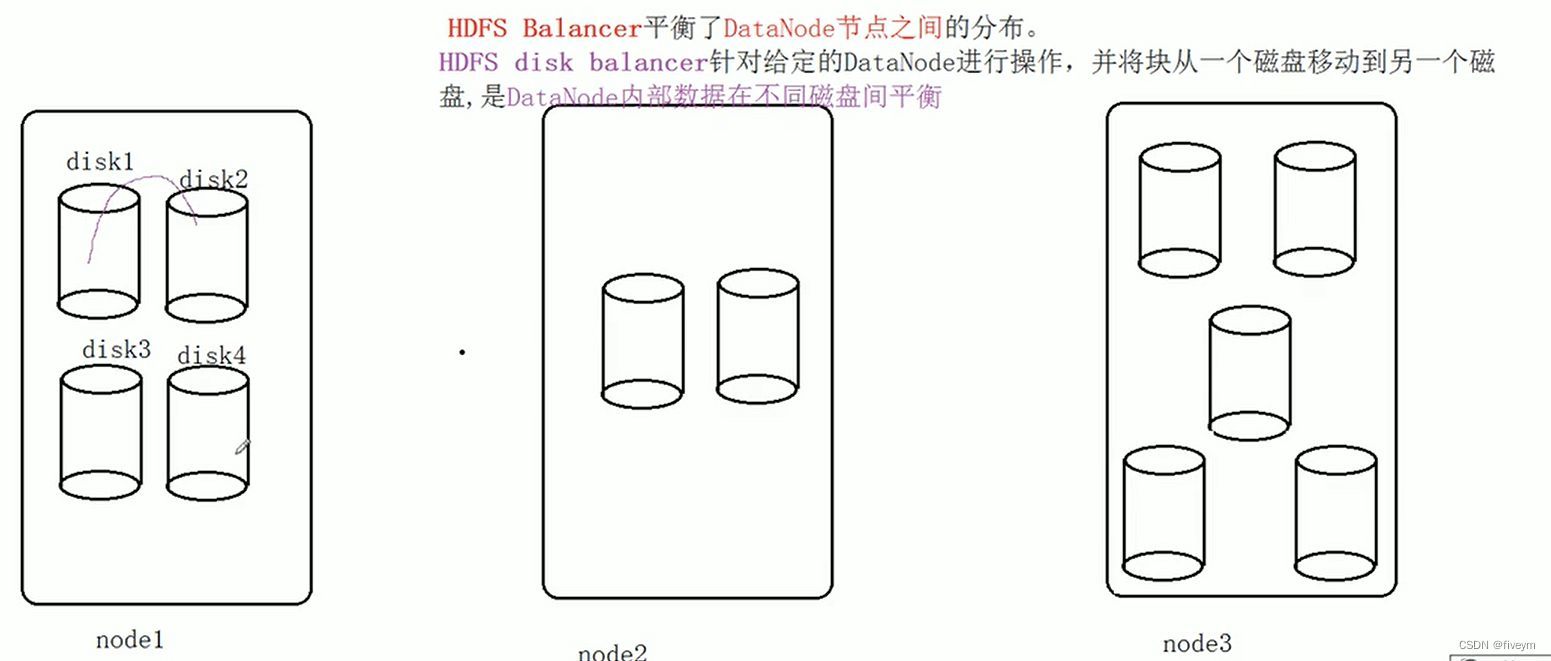
- 因此需要一种INTRA DATANODE BALANCING(DataNode内数据块的均匀分布)来解决intra-DataNode偏斜(在磁盘上块的不均匀分布),这种偏斜是由于磁盘更换或随机写入和删除发生的。
- 因此,hadoop3.0中引入了一个名为disk balancer的工具,该工具专注于在DataNode内分发数据
hdfs disk balancer简介
- hdfs disk balancer是hadoop3中引入的命令行工具,用于平衡DataNode中的数据在磁盘指甲分布不均匀问题。在这里特别注意,hdfs diskbalancer与hdfsbalancer是不同的
HDFS Disk Balancer功能
数据传播报告
为了衡量集群中哪些计算机遭受数据分布不均的影响,磁盘平衡器定义了volume data density metric(磁盘/卷数据密度度量标准)和Node Data Density metric(节点数据密度度量标准)
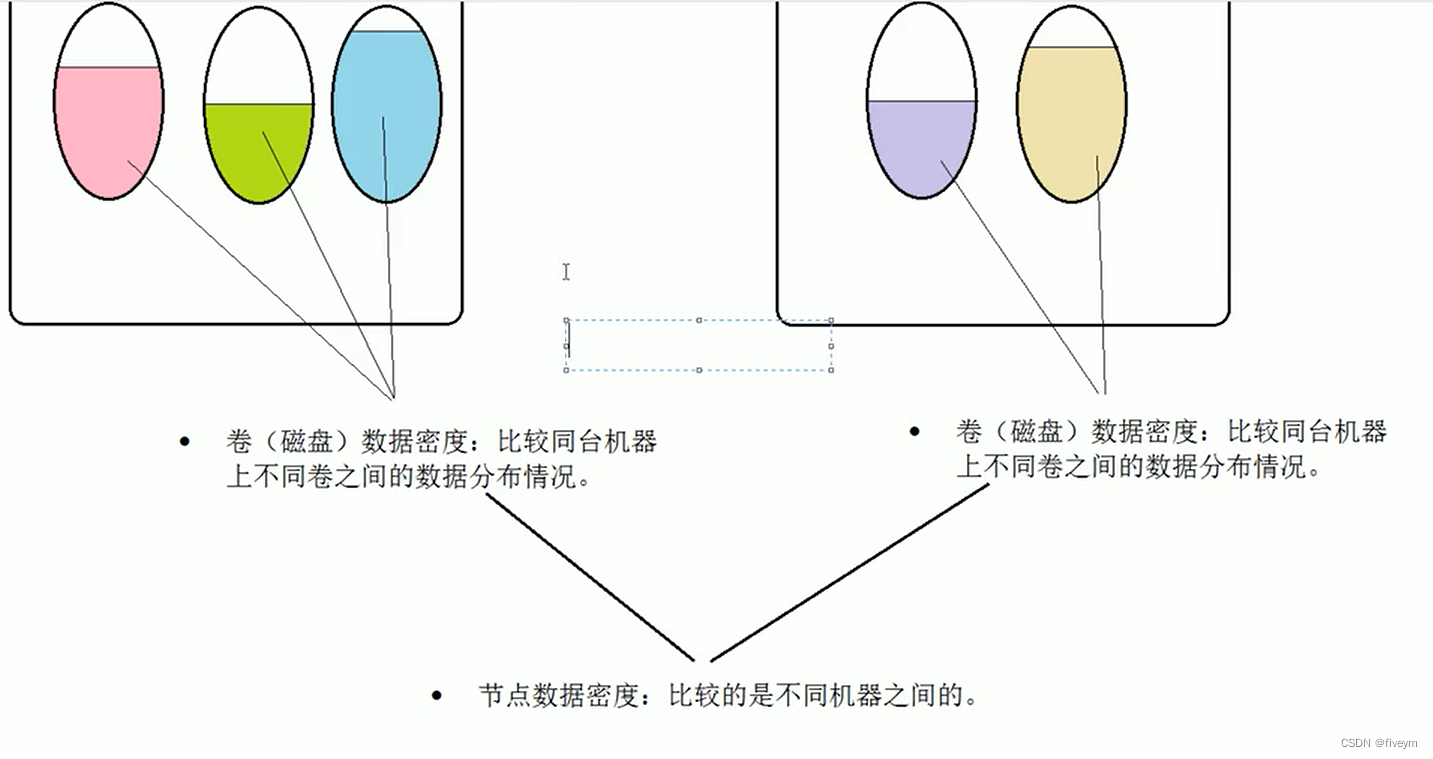
- 卷(磁盘)数据密度:比较同台机器上不同卷之间的数据分布情况
- 节点数据密度:比较的是不同机器之间的
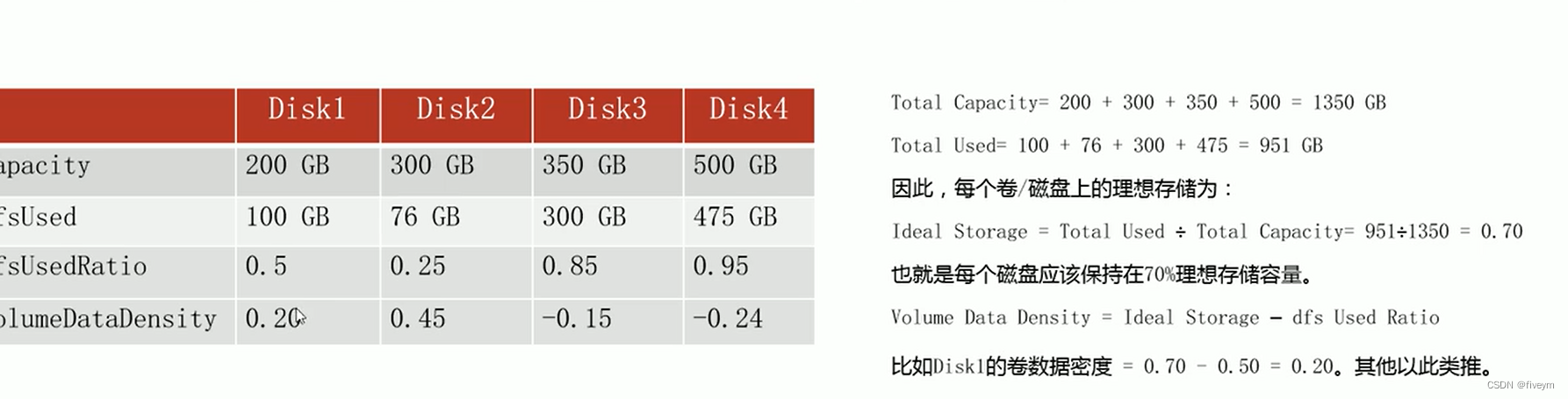
- 卷数据密度计算 假设有一台具有四个卷的计算机,各个磁盘的使情况

- 磁盘平衡 当指定某个datanode节点进行disk数据平衡,就可以先计算或读取当前的volume data density(磁盘数据密度)。有了这些数据,我们可以轻松确定哪些卷已经超量配置,哪些卷已经不足 为了将数据从一个卷移动到datanode中的另一个卷,Hadoop开发实现了基于rpc协议的disk balancer
HDFS Disk Balancer开启
- hdfs disk balancer通过创建计划进行操作,该计划是一组语句,描述应在两个磁盘之间移动多少数据,然后在datanode上执行该语句。计划包含多个移动步骤。计划中的每个移动步骤都具有目标磁盘,源磁盘的地址。移动步骤还具有要移动的字节数。该计划是针对可操作的datanode执行的
- 默认情况下,Hadoop集群上已经启用了disk balancer功能。通过hdfs-site.xml中调整dfs.disk.balancer.enabled参数值,选择在Hadoop中是否启用磁盘平衡器
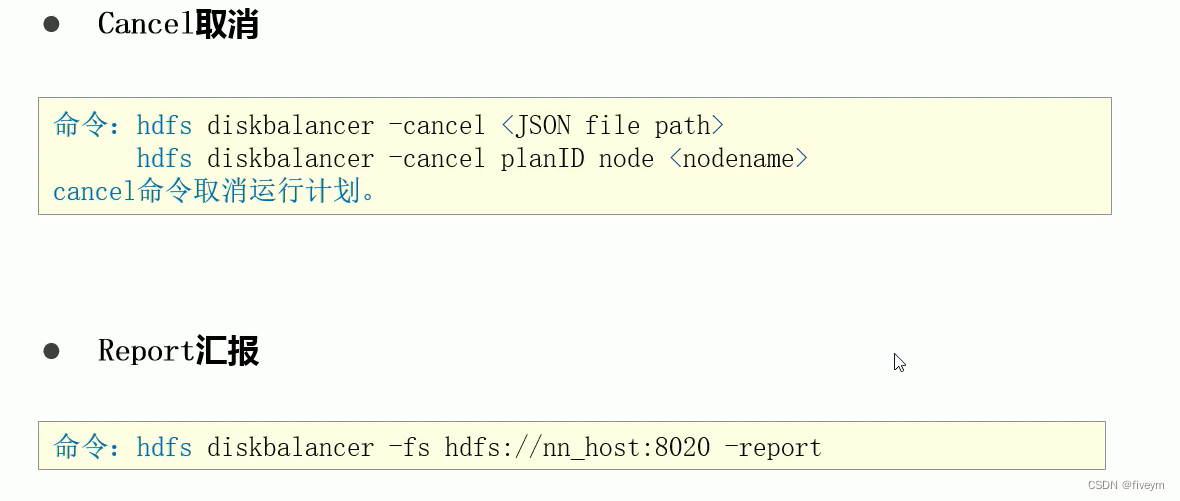
相关命令
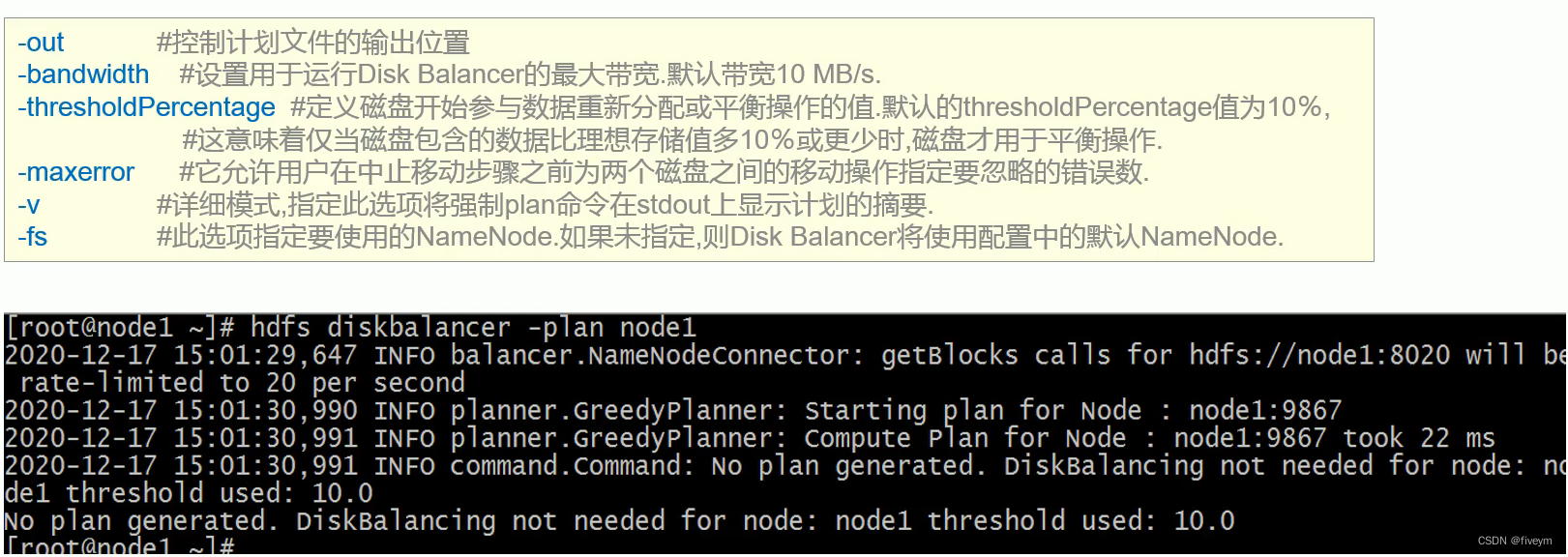
- plan计划 命令:hdfs diskbalancer -plan < datanode>

本文转载自: https://blog.csdn.net/weixin_49750432/article/details/132001473
版权归原作者 fiveym 所有, 如有侵权,请联系我们删除。
版权归原作者 fiveym 所有, 如有侵权,请联系我们删除。