
上篇文章大致讲了下Vision Mamba的相关知识,网上关于Vision Mamba的配置博客太多,笔者主要用来整合下。
笔者在Win10和Linux下分别尝试配置相关环境。
Win10下配置
失败
\textcolor{red}{失败}
失败,最后出现的问题如下:
https://blog.csdn.net/weixin_46135891/article/details/137141378
有解决方法还请留言。
配置Linux下的Vision Mamba还是比较方便的,
目录
前言
笔者在linux下选用CUDA
11.8
\textcolor{red}{11.8}
11.8版本,也比较推荐读者使用此版本,方便后续环境配置。
CUDA,cudnn下载以及安装
CUDA
CUDA官网:https://developer.nvidia.com/cuda-11-8-0-download-archive?
笔者Linux版本是Ubuntu20.20的,固下载如下文件:cuda_11.8.0_520.61.05_linux.run
Cudnn官网:https://developer.nvidia.com/rdp/cudnn-archive
选择适配CUDA11.8的版本即可, 笔者选用cudnn 8.9.7 (for CUDA 11.x)
选择 --Local Installer for Linux x86_64 (Tar) 下载离线包
首先安装CUDA,采用离线安装方式,
sudosh cuda_11.8.0_520.61.05_linux.run
首先accpet,
然后具体配置的时,去掉Deiver,只保留 CUDA 相关。
如下图类似,(下图取自网络,不是笔者的CUDA11.8的实时截图)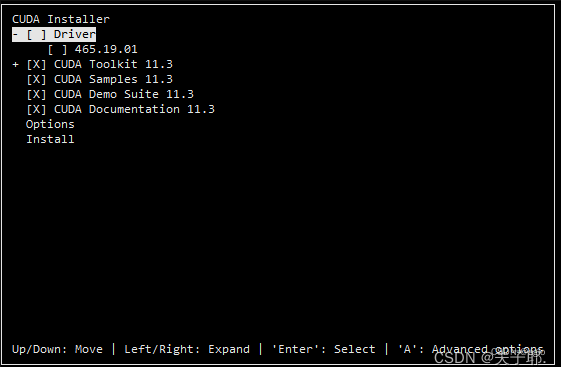
然后正常安装即可,一般安装在了 /usr/local/CUDA-11.8
配置CUDA环境
exportLD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
exportPATH=/usr/local/cuda/bin:$PATHexportCUDA_HOME=/usr/local/cuda
exportLIBRARY_PATH=/usr/local/cuda/lib64
如果/usr/local/中没有自动生成CUDA文件, 手动生成CUDA软连接
sudoln-s /usr/local/cuda-11.8 /usr/local/cuda
cudnn
解压缩
tar -xvf cudnn-XX-linux-x64-vXXX.XXX.XX.tgz ## 这是最开始下载的cudnn文件
再将 刚刚解压的 cuDNN里面的对应文件拷贝至CUDA指定路径:
sudocp include/cudnn*.h /usr/local/cuda-11.8/include
sudocp lib/libcudnn* /usr/local/cuda-11.8/lib64
sudochmod a+r /usr/local/cuda-11.8/include/cudnn*.h /usr/local/cuda-11.8/lib64/libcudnn*
一切弄完后,重启电脑。
多CUDA环境切换
如果读者只有一个cudaXX.X版本的文件夹可以不用看此处,此节涉及多cuda环境切换。
在/usr/local 路径下,分别执行
nvcc -Vstat cuda
如果指向同一个cuda版本,那么该版本就是正在使用的版本,而且没意外的话,应该都是cuda-11.8
输出类似如下:(下图取自网络,不是笔者的CUDA11.8的实时截图)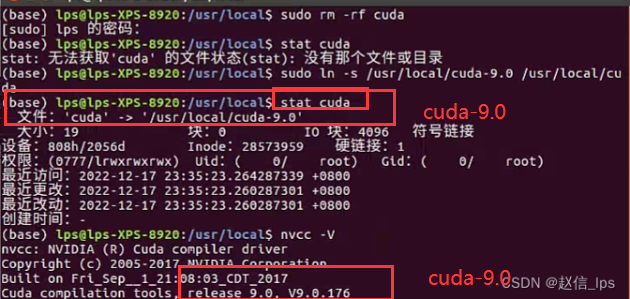
如果要切换另一个cuda版本:
sudorm-rf /usr/local/cuda ##这一步是去除软连接sudoln-s /usr/local/cuda-XX.X /usr/local/cuda ##指定XX.X 为想要使用的版本
然后重新执行
nvcc -Vstat cuda
发现输出的cuda版本同时发生了变化,此时就更换成功了
比如 将cuda11.8 设置为想要的版本:
sudorm-rf /usr/local/cuda
sudoln-s /usr/local/cuda-11.8 /usr/local/cuda
Vision Mamba环境配置
重启后,电脑就有了CUDA-11.8,下面我们来具体配置Vision Mamba的环境。
笔者推荐Anaconda创建虚拟环境
#anaconda 创建py310虚拟环境
conda create -n your_name python=3.10.13 -y
安装对应的torch包
#安装虚拟环境其它包(笔者是 cuda11.8,安装pytorch如下)
pip installtorch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
去github上下载 vision mamba源码包
https://github.com/hustvl/Vim
下载.zip文件然后手动解压缩
或
git clone https://github.com/hustvl/Vim.git
接下来先安装两个比较有问题的包,这两个装好后基本就没什么问题了。
mamba-1.1.1
方法1
下载 mamba-1.1.1的源码包 :https://github.com/state-spaces/mamba/archive/refs/tags/v1.1.1.zip
解压缩 mamba-1.1.1.zip
虚拟环境 进入到这个文件夹 执行
pip install.
方法2
如果方法1不行,来执行方法2
手动下载轮子:https://github.com/state-spaces/mamba/releases/download/v1.1.1/mamba_ssm-1.1.1+cu118torch2.1cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
注:此轮子只对应cuda11.8的版本,所以笔者在文章开头推荐读者使用cuda11.8的环境。
然后安装轮子
# 虚拟环境下安装
pip install /下载路径/mamba_ssm-1.1.1+cu118torch2.1cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
方法2的安装一般没什么问题,如果报超时问题,可以梯子或重复执行上面这个安装命令
安装好后需要执行下面这个步骤,否则后续运行会报错:
( “TypeError: Mamba.init() got an unexpected keyword argument ‘bimamba_type’.”)
读者把vision mamba源码里面的mamba-ssm替换到虚拟环境里面的mamba-ssm
具体的
sudocp-r"其他路径/Vim-main/mamba-1p1p1/mamba_ssm""Annotation路径/envs/mamba的虚拟环境/lib/python3.10/site-packages/"
casual-conv1d-1.1.3
方法1
下载casual-conv1d-1.1.3的源码包 : https://github.com/Dao-AILab/causal-conv1d/archive/refs/tags/v1.1.3.zip
解压缩 casual-conv1d-1.1.3.zip
虚拟环境 进入到这个文件夹 执行
pip install.
方法2
手动下载轮子:
https://github.com/Dao-AILab/causal-conv1d/releases/download/v1.1.3/causal_conv1d-1.1.3+cu118torch2.1cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
注:此轮子只对应cuda11.8的版本,所以笔者在文章开头推荐读者使用cuda11.8的环境。
然后安装轮子
# 虚拟环境下安装
pip install /下载路径/causal_conv1d-1.1.3+cu118torch2.1cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
方法2的安装一般没什么问题,如果报超时问题,可以梯子或重复执行上面这个安装命令
其他组件
如果上面两个组件都安装上了,那么以及成功99%了
#虚拟环境下
pip install timm mlflow -i https://pypi.tuna.tsinghua.edu.cn/simple
可能有遗漏的组件,后续执行代码的时候,缺少什么安装同样的方式添加
测试代码
在 VIM-main/vim/models_mamba.py的末尾添加如下代码
if __name__ =='__main__':# cuda or cpu
device = torch.device("cuda"if torch.cuda.is_available()else"cpu")print(device)# 实例化模型得到分类结果
inputs = torch.randn(1,3,224,224).to(device)
model = vim_small_patch16_stride8_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2(
pretrained=False).to(device)print(model)
outputs = model(inputs)print(outputs.shape)# 实例化mamba模块,输入输出特征维度不变 B C H W
x = torch.rand(10,16,64,128).to(device)
B, C, H, W = x.shape
print("输入特征维度:", x.shape)
x = x.view(B, C, H * W).permute(0,2,1)print("维度变换:", x.shape)
mamba = create_block(d_model=C).to(device)# mamba模型代码中返回的是一个元组:hidden_states, residual
hidden_states, residual = mamba(x)
x = hidden_states.permute(0,2,1).view(B, C, H, W)print("输出特征维度:", x.shape)
执行(run) VIM-main/vim/models_mamba.py
如果没有问题会输出 模型架构和一些结果:
torch.Size([1, 1000])
输入特征维度: torch.Size([10, 16, 64, 128])
维度变换: torch.Size([10, 8192, 16])
输出特征维度: torch.Size([10, 16, 64, 128])
如果输出以上结果,那么恭喜你,vision mamba环境配置好了
vision mamba的简单运行
希望读者能够大概看下vision mamba 的readme 来看看如何进行训练的。
也应当看看main.py的参数配置,来进行选择如何自定义一些配置信息
如下是笔者cifar-python100的训练参数:
(虚拟环境下,在Vim-main/vim/路径下 terminal终端执行代码)CUDA_VISIBLE_DEVICES=0 python main.py \--model vim_small_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2 --batch-size 2\
--drop-path 0.05 --weight-decay 0.05--lr 1e-3 --num_workers1\
--data-set CIFAR \
--data-path /home/cr7/python/code/mamba_classify_test/cifer_dataset/ \--output_dir /home/cr7/python/code/mamba_classify_test/mamba_outputs/cifar_result \--no_amp
当然读者也可以直接配置train.py,在pycharm里面点击train.py执行,修改main.py的参数来进行想要的训练了。
以下是必须配置,否则执行的时候缺少配置报错,在main.py的对应配置地方进行修改
--batch-size , default=64##按照自己gpu显存来设置 太大会爆显存--epochs, default=300## 训练批次--model, default="vim_small_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2"## 在 models_mamba.py的结尾有4个可以选择--data-path , default=" /home/cr7/python/code/mamba_classify_test/cifer_dataset/"##下载的分类数据集路径 --data-set, default="CIFAR"##分类数据集名字--num_workers ,default =4##根据电脑性能 调整
注:以下是 pycharm 运行 main.py必要做的事情,否则会报错
在main.py中的
def main(args):
添加一行 args.gpu=0 ##设置gpu的index
这里由于笔者只有一个gpu , 所以使用gpu序号0 做为训练gpu
不添加的话,后续运行main.py会报错:
AttributeError:'Namespace'object has no attribute 'gpu'
输出大致如下。
(mamba_py310) cr7@cr7:~/python/code/mamba_classify_test/Vim/vim$ CUDA_VISIBLE_DEVICES=0 python main.py \>--model vim_small_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2 --batch-size 2\> --drop-path 0.05 --weight-decay 0.05--lr 1e-3 --num_workers1\> --data-set CIFAR \> --data-path /home/cr7/python/code/mamba_classify_test/cifer_dataset/ \>--output_dir /home/cr7/python/code/mamba_classify_test/mamba_outputs/cifar_result \>--no_amp
Not using distributed mode
Namespace(batch_size=2, epochs=300, bce_loss=False, unscale_lr=False, model='vim_small_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2', input_size=224, drop=0.0, drop_path=0.05, model_ema=True, model_ema_decay=0.99996, model_ema_force_cpu=False, opt='adamw', opt_eps=1e-08, opt_betas=None, clip_grad=None, momentum=0.9, weight_decay=0.05, sched='cosine', lr=0.001, lr_noise=None, lr_noise_pct=0.67, lr_noise_std=1.0, warmup_lr=1e-06, min_lr=1e-05, decay_epochs=30, warmup_epochs=5, cooldown_epochs=10, patience_epochs=10, decay_rate=0.1, color_jitter=0.3, aa='rand-m9-mstd0.5-inc1', smoothing=0.1, train_interpolation='bicubic', repeated_aug=True, train_mode=True, ThreeAugment=False, src=False, reprob=0.25, remode='pixel', recount=1, resplit=False, mixup=0.8, cutmix=1.0, cutmix_minmax=None, mixup_prob=1.0, mixup_switch_prob=0.5, mixup_mode='batch', teacher_model='regnety_160', teacher_path='', distillation_type='none', distillation_alpha=0.5, distillation_tau=1.0, cosub=False, finetune='', attn_only=False, data_path='/home/cr7/python/code/mamba_classify_test/cifer_dataset/', data_set='CIFAR', inat_category='name', output_dir='/home/cr7/python/code/mamba_classify_test/mamba_outputs/cifar_result', device='cuda', seed=0, resume='', start_epoch=0, eval=False, eval_crop_ratio=0.875, dist_eval=False, num_workers=1, pin_mem=True, distributed=False, world_size=1, dist_url='env://', if_amp=False, if_continue_inf=False, if_nan2num=False, if_random_cls_token_position=False, if_random_token_rank=False, local_rank=0)
Creating model: vim_small_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2
number of params: 25450084
Start training for300 epochs
Epoch: [0][0/25000] eta: 22:46:27 lr: 0.000001 loss: 4.2079(4.2079) time: 3.2795 data: 0.0525 max mem: 707
Epoch: [0][10/25000] eta: 2:23:41 lr: 0.000001 loss: 4.6698(4.6594) time: 0.3450 data: 0.0049 max mem: 765
Epoch: [0][20/25000] eta: 1:25:18 lr: 0.000001 loss: 4.7118(4.7024) time: 0.0512 data: 0.0001 max mem: 765
Epoch: [0][30/25000] eta: 1:04:32 lr: 0.000001 loss: 4.7599(4.6847) time: 0.0506 data: 0.0001 max mem: 765
Epoch: [0][40/25000] eta: 0:54:04 lr: 0.000001 loss: 4.7495(4.6971) time: 0.0513 data: 0.0001 max mem: 765
Epoch: [0][50/25000] eta: 0:47:35 lr: 0.000001 loss: 4.6873(4.6862) time: 0.0515 data: 0.0001 max mem: 765
Epoch: [0][60/25000] eta: 0:43:12 lr: 0.000001 loss: 4.6870(4.6894) time: 0.0506 data: 0.0001 max mem: 765
Epoch: [0][70/25000] eta: 0:40:04 lr: 0.000001 loss: 4.6236(4.6846) time: 0.0506 data: 0.0001 max mem: 765
Epoch: [0][80/25000] eta: 0:37:45 lr: 0.000001 loss: 4.5900(4.6900) time: 0.0512 data: 0.0001 max mem: 765
Epoch: [0][90/25000] eta: 0:36:03 lr: 0.000001 loss: 4.6688(4.6900) time: 0.0528 data: 0.0001 max mem: 765
参考博客
linux 下 多CUDA版本切换: https://blog.csdn.net/weixin_43408382/article/details/128358138
linux 下 vision mamba环境配置:https://blog.csdn.net/qq_52811934/article/details/136818016
linux 下 vision mamba配置的可能问题:https://blog.csdn.net/weixin_43408382/article/details/128358138
(笔者不建议参考下文博客中的cuda版本切换的方法)
linux 下 cuda11.8的安装https://blog.csdn.net/w946612410/article/details/131786512
版权归原作者 啊 昃 所有, 如有侵权,请联系我们删除。