
**hadoop102 **
hadoop103
hadoop104
HDFS
NameNode
DataNode
DataNode
SecondaryNameNode
DataNode
YARN
NodeManager
ResourceManager
NodeManager
NodeManager
停止firewalld防火墙
systemctl stop firewalld
//关闭防火墙开机自启动
systemctl disable firewalld
//查看防火墙状态
systemctl status firewalld
关闭selinux防火墙
vi /etc/sysconfig/selinx
#设置
SELINUX=disabled
基于rpm安装配置jdk
#rpm -ivh jdk-8u281-linux.x64.rpm
配置环境变量
#export JAVA_HOME=/usr/java/jdk1.8.0_281-amd64
#export CLASSAATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib.tools.jar
#export PATH=$JAVA_HOME/bin
tar -zxf opt/software/jdk-8u261-linux-x64.tar.gz
vi /etc/profile
export JAVA_HOME=/opt/module/jdk1.8.0_261
CLASSPATH=.:$JAVA_HOME/lib.tools.jars
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
使得环境变量生效
source /etc/profile
查看jdk环境变量是否配置正确
javac -version
java -version
安装配置hadoop
tar -zxvf /opt/software/hadoop-3.1.4.tar.gz -C /opt/module
配置环境变量
export HADOOP_HOME=/opt/module/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使得环境变量生效
source /etc/profile
查看hadoop环境变量是否配置正确
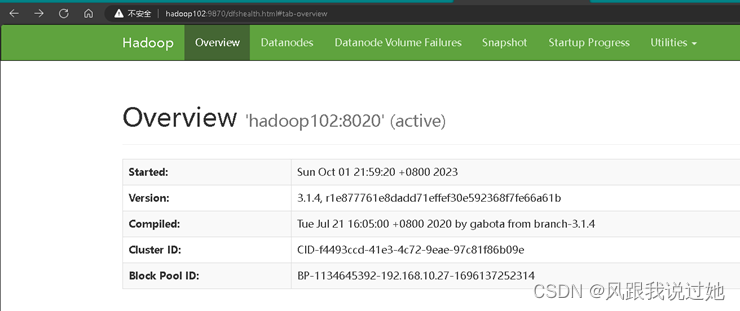
hadoop version
克隆
- 克隆母机(hadoop102)克隆二台虚拟机,分别命名为hadoop103、hadoop104
- 母机 右键 管理 克隆
- 选择完整克隆
虚拟机ip 以此修改
vi /etc/sysconfig/network-scripts/ifcfg-eng33
详细修改ip可参考Linux修改ip
hadoop102为192.168.10.27
hadoop103为192.168.10.28
hadoop104为192.168.10.29
重启网络并验证是否正常使用并连接xshell测试
- systemctl restart network -> 2.ping wwww.baidu.com ->3. ip addr show eng33
修改主机名
hostnamectl set-hostname hadoop102(主机名)
查看主机名
hostname

另外两个节点也是
hostnamectl set-hostname hadoop103
hostnamectl set-hostname hadoop104
主机映射
vim /etc/hosts
192.168.10.27 hadoop102
192.168.10.28 hadoop103
192.168.10.29 hadoop104
时间同步
安装ntp服务
yum install ntp
同步时间
ntpdate -u ntp1.aliyun.com
查看时间
date
免密登录(ssh)
在集群开发中,主节点通常会对集群中各个节点频繁的访问,就需要不断输入目标服务器的用户名和密码,这种操作方式非常麻烦并且还会影响集群服务的连续运行。
为了解决上述问题,我们可以通过配置SSH服务来实现远程登录和SSH的免密登录功能。
可检查是否安装了ssh服务 rpm -qa |grep ssh
看看是否启动了ssh服务 ps -e |grep sshd
安装ssh服务命令为yum install openssh-server
原理
- 生成密钥对:
- 在本地机器上,你会生成一对密钥:公钥(public key)和私钥(private key)。
- 公钥是一个用于加密的字符串,可以公开分享,而私钥必须保密妥善保存。
- 将公钥复制到远程服务器:
- 将你的公钥复制到你想要连接的远程服务器的~/.ssh/authorized_keys文件中。
- 这个文件包含了所有被信任的公钥,允许拥有对应私钥的用户连接到这个账户。
- 连接到远程服务器:
- 当你尝试连接到远程服务器时,SSH客户端会发送一个请求,请求使用公钥来进行身份验证。
- 验证身份:
- 服务器接收到连接请求后,会检查请求中是否包含了一个匹配~/.ssh/authorized_keys中的公钥。
- 如果匹配成功,服务器会向你的客户端发送一个随机字符串(称为挑战 challenge)。
- 使用私钥签名:
- 你的SSH客户端会使用你的私钥来对挑战进行签名,然后将签名发送回服务器。
- 验证签名:
- 服务器使用与你公钥匹配的公钥来验证签名。如果签名验证成功,服务器会确认你的身份,并允许你登录。
三台机器生成公钥和私钥
生成公钥和私钥 ssh-keygen -t rsa 组图按下三个回车即可
第一个回车是指的是 密钥保存的默认位置一般不修改 直接回车
第二个输入密码无 直接来两次回车
生成的公钥和私钥
公钥复制到hadoop102主机
[[email protected]]# ssh-copy-id hadoop102 //包括本机
[root@hodoop103 ~]# ssh-copy-id hadoop102
[root@hodoop104 ~]# ssh-copy-id hadoop102
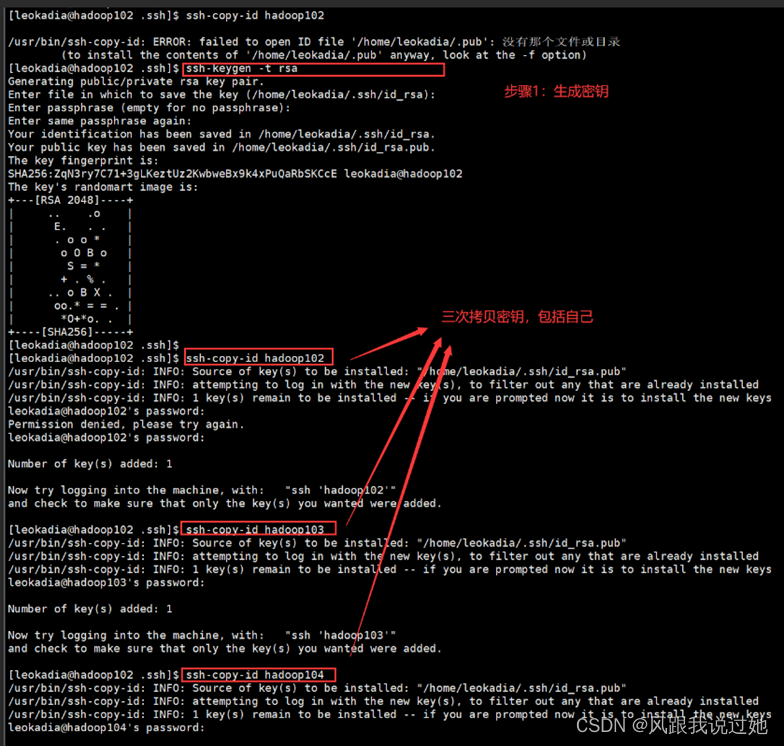
将第一台机器上authorized_keys文件拷贝到其他机器上,使得每台主机都有三台主机的公钥
scp:远程拷贝,可跨主机拷贝; cp:本地拷贝
[[email protected]]# scp /root/.ssh/authorized_keys hadoop103:/root/.ssh
// 此/root/.ssh/authorized_keys文件在hadoop102主机上
[[email protected]]# scp /root/.ssh/authorized_keys hadoop104:/root/.ssh
bin目录是Hadoop最基本的管理脚本和使用脚本所在的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop
sbin目录存放的是我们管理脚本的所在目录,重要是对hdfs和yarn的各种开启和关闭和单线程开启和守护
etc目录存放的是一些Hadoop的配置文件
lib目录存放的是Hadoop运行时依赖的jar包,Hadoop在执行时会把lib目录下面的jar全部加到classpath中
logs目录存放的是Hadoop运行的日志,查看日志对寻找Hadoop运行错误非常有帮助
includ目录对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序
libexec目录各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。
share目录Hadoop各个模块编译后的jar包所在的目录
vi /etc/profile
定义HDFS和yarn在root用户上运行
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_SECURE_DN=hdfs
##yarn
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_SECURE_DN_USER=root
以上也可在hadoop的sbin目录 start(stop)-dfs.sh 或start(stop)-yarn.sh添加
#HDFS_DATANODE_USER=root:用于启动和停止数据节点(DataNode)。
#HADOOP_SECURE_DN_USER=root:在启用了安全模式(安全模式)的情况下,用于启动和停止安全数据节点。
#HDFS_NAMENODE_USER=root:用于启动和停止主要的名称节点(NameNode)。
#HDFS_SECONDARYNAMENODE_USER=root:用于启动和停止辅助标题节点(Secondary NameNode)。
cd /opt/module/hadoop-3.1.4/etc/hadoop
vi hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_261
配置core-site.xml
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.4/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为root-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 配置该root(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!-- 配置该root(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 配置该root(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
</configuration>
配置hdfs-stie.xml
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
<!-- 测试环境指定HDFS副本的数量1 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
配置yarn-site.xml 配置resource manager nodemanager通信端口 web监控端口
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承(环境变量白名单) -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!--yarn单个容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2000</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>3072</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
获取白名单:
Hadooop官方网站:Hadoop – Apache Hadoop 3.1.4
配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置workers用来指定hadoop集群中所有的工作节点DataNode和NodeManager节点
hadoop102
hadoop103
hadoop104
远程发送scp
scp -r /opt/module/hadoop-3.1.4/etc/hadoop hadoop103:/opt/module/hadoop-3.1.4/etc/hadoop
scp -r /opt/module/hadoop-3.1.4/etc/hadoop hadoop104:/opt/module/hadoop-3.1.4/etc/hadoop
格式化前需要三台需删除日志文件
rm -rf data/ logs/
格式化 格式化日志有succefully format 则成功
hdfs namenode -format
进入hadoop的sbin目录编辑下面内容
cd $HADOOP_HOME/sbin
vim start-dfs.sh 和vim stop-dfs.sh
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
在start-yarn.sh和stop-yarn.sh文件开头添加下列参数:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
hadoop102 启动HDFS
start-dfs.sh
hadoop103 启动YARN
start-yarn.sh
HDFS WEB http://hadoop102:9870/
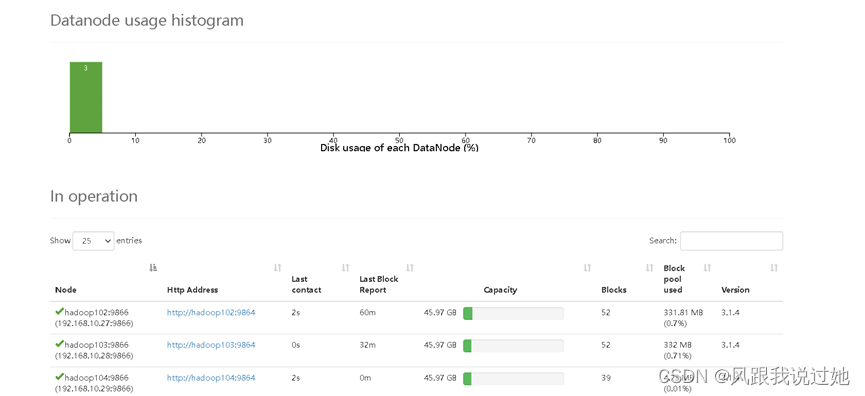
hadoop-daemon.sh
通过执行hadoop命令来启动/停止一个守护进程(daemon);他可以单独开启一个进程也可以使用hadoop-daemons来开启多个进程,这样我们在某台机器挂掉时,就不用全部重新开启了
start-all.sh
调用 start-dfs.sh和start-yarn.sh
stop-all.sh
调用 stop-dfs.sh和stop-yarn.sh
start-dfs.sh
启动NameNode ,SecondaryNamenode ,DataNode这些进程
start-yarn.sh
启动ResourceManager,nodeManager 这些进程
stop-dfs.sh
关闭NameNode ,SecondaryNamenode ,DataNode这些进程
stop-yarn.sh
关闭ResourceManager,nodeManager 这些进程
YARN WEB http://hadoop103:8088/
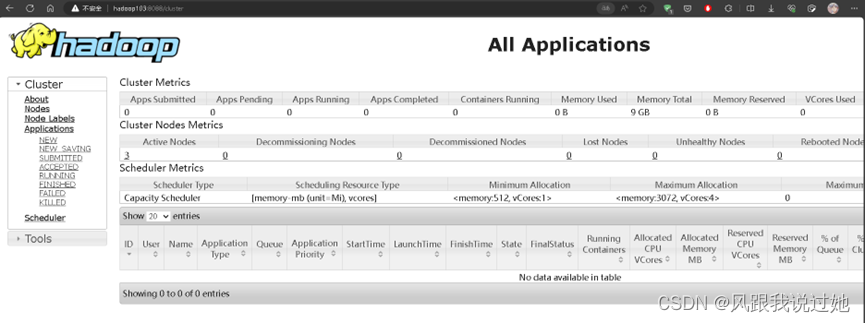
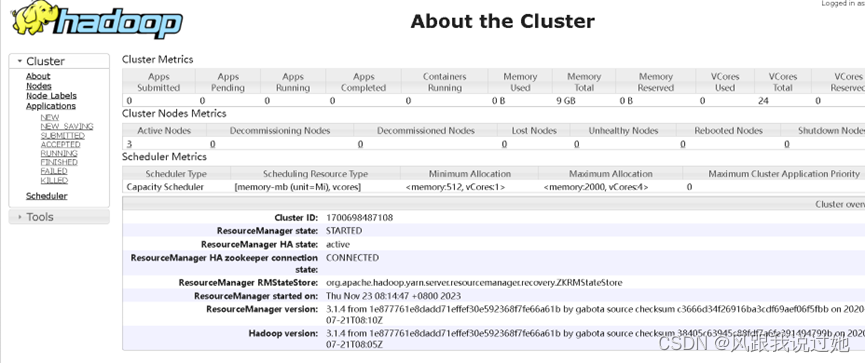
在此之间只需把进程关闭即可
stop-hdfs.sh
stop-yarn.sh
配置历史服务器
配置mapred-site.xml
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager、ResourceManager和HistoryManager。
配置yarn-site.xml
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
远程发送
scp -r mpared-site.xml hadoop103:/opt/module/hadoop-3.1.4/etc/hadoop
scp -r yarn-site.xml hadoop103:/opt/module/hadoop-3.1.4/etc/hadoop
scp -r mpared-site.xml hadoop104:/opt/module/hadoop-3.1.4/etc/hadoop
scp -r yarn-site.xml hadoop104:/opt/module/hadoop-3.1.4/etc/hadoop
这样就可以不用格式化这些了
hadoop102 启动HDFS
start-dfs.sh
hadoop103 启动YARN
start-yarn.sh
hadoop102启动JobHistory命令
mr-jobhistory-daemon.sh start historyserver
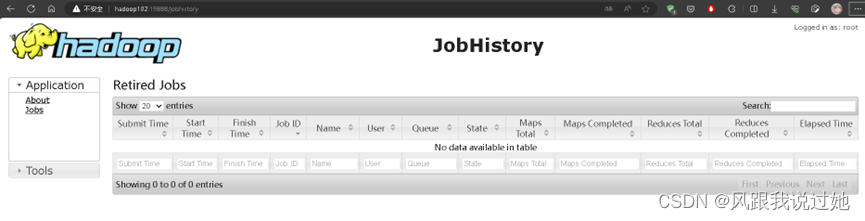
习题
单词统计

新建文本文件
vim word.txt
单词和单词直接要空格分隔(程序规定)

新建目录
上传word.txt文本文件到/user/data

cd $HADOOP_HOME/share/hadoop/mapreduce/

hadoop jar 执行jar包功能 mapreduce-examples-3.1.4.jar 指定执行具体的jar包 wordcount 单词计数功能 /user/data源文件 /user/data/output 目标文件output自动生成
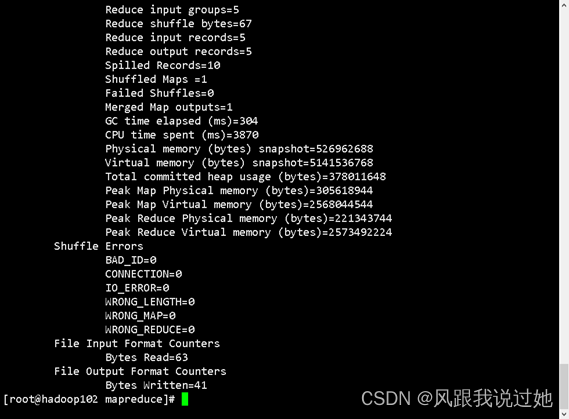
查看结果
/user/data/output/_SUCCESS 运行成功标志
/user/data/output/part-r-00000

查看运行结果 hdfs dfs -cat /user/data/output/part*|part-r-00000

hdfs
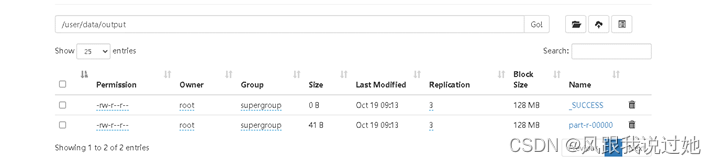
hadoop102:9870 utilities -> Browse the file system -> /user/data ->part-r-00000 Download

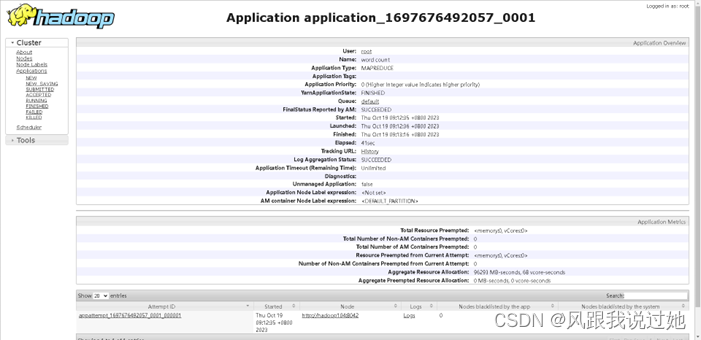
yarn查看
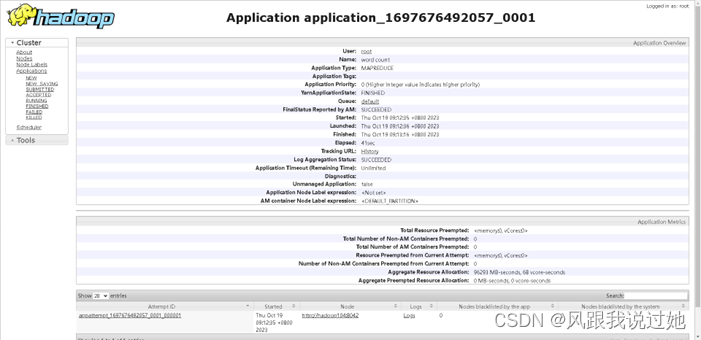
历史服务器查看
版权归原作者 风跟我说过她 所有, 如有侵权,请联系我们删除。