
Go web
Web工作方式
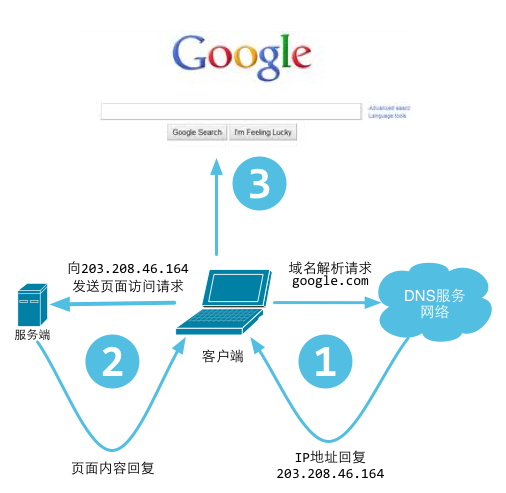
浏览器本身是一个客户端,当你输入URL的时候,首先浏览器会去请求DNS服务器,通过DNS获取相应的域名对应的IP,然后通过IP地址找到IP对应的服务器后,要求建立TCP连接,等浏览器发送完HTTP Request包后,服务器接收到请求包之后才开始处理请求包,服务器调用自身服务
URL和DNS解析
URL是“统一资源定位符”的英文缩写,用于描述一个网络上的资源
scheme://host[:port#]/path/.../[?query-string][#anchor]
scheme 指定低层使用的协议(例如:http, https, ftp)
host HTTP服务器的IP地址或者域名
port# HTTP服务器的默认端口是80,这种情况下端口号可以省略。如果使用了别的端口,必须指明,例如 http://www.cnblogs.com:8080/
path 访问资源的路径
query-string 发送给http服务器的数据
anchor 锚
DNS 是“域名系统”的英文缩写,是一种组织成域层次结构的计算机和网络服务命名系统,他用于TCP/IP网络,从事将主机名或域名转换为实际IP地址的工作
DNS解析过程:
1.在浏览器中输入www.qq.com域名,操作系统会检查自己本地的hosts文件是否由这个网址映射关系,如果有,直接返回域名解析
2.如果hosts里没有这个域名的映射,则查找本地DNS解析器缓存,是否有这个网址映射关系
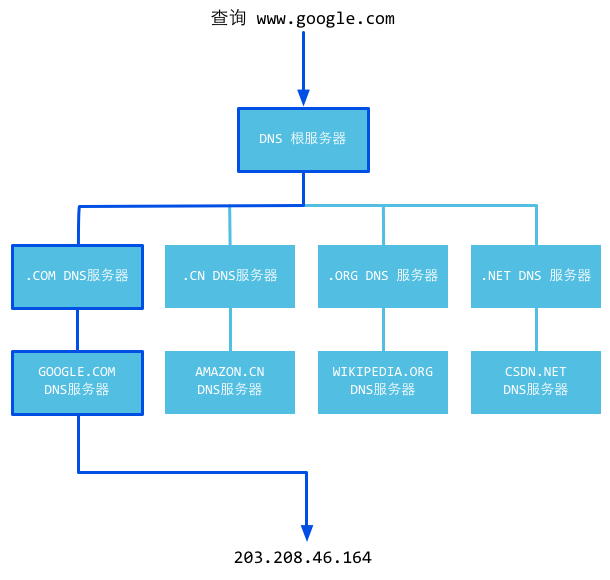
3.如果本地DNS缓存器缓存都没有相应的网址映射关系,首先会找TCP/IP参数中设置的首选DNS服务器,在此我们叫他本地DNS服务器,如果要查询的域名,包含在本地配置区域资源中,则返回解析结果给客户机,完成域名解析
4.如果要查询的域名,不由本地DNS服务器区域解析
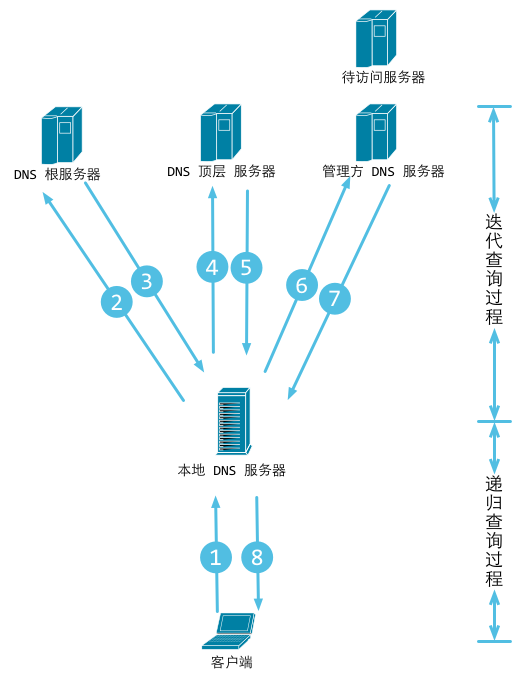
举个例子来说,你想知道某个一起上法律课的女孩的电话,并且你偷偷拍了她的照片,回到寝室告诉一个很仗义的哥们儿,这个哥们儿二话没说,拍着胸脯告诉你,甭急,我替你查(此处完成了一次递归查询,即,问询者的角色更替)。然后他拿着照片问了学院大四学长,学长告诉他,这姑娘是xx系的;然后这哥们儿马不停蹄又问了xx系的办公室主任助理同学,助理同学说是xx系yy班的,然后很仗义的哥们儿去xx系yy班的班长那里取到了该女孩儿电话。(此处完成若干次迭代查询,即,问询者角色不变,但反复更替问询对象)最后,他把号码交到了你手里。完成整个查询过程
HTTP协议详解
HTTP协议是Web工作的核心
HTTP是一种让Web服务器与浏览器通过Internet发送与接收数据的协议,它建立在TCP协议之上,一般采用TCP的80端口。
HTTP协议是无状态的,同一个客户端的这次请求和上次请求时没有对应关系,对HTTP服务器来说,它并不知道这两个请求
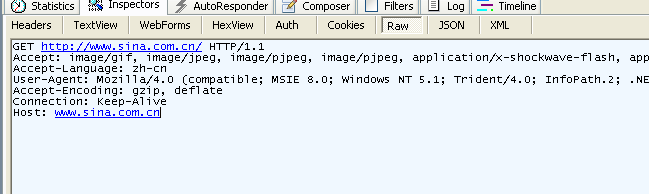
HTTP请求包(浏览器信息)
GET /domains/example/ HTTP/1.1//请求行: 请求方法 请求URI HTTP协议/协议版本
Host:www.iana.org //服务端的主机名
User-Agent:Mozilla/5.0(Windows NT 6.1) AppleWebKit/537.4(KHTML, like Gecko) Chrome/22.0.1229.94 Safari/537.4//浏览器信息
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 //客户端能接收的mine
Accept-Encoding:gzip,deflate,sdch //是否支持流压缩
Accept-Charset:UTF-8,*;q=0.5 //客户端字符编码集
//空行,用于分割请求头和消息体
//消息体,请求资源参数,例如POST传递的参数
HTTP协议定义了很多与服务器交互的请求方法,最基本的有4种,分别是GET,POST,PUT,DELETE。一个URL地址用于描述一个网络上的资源,而HTTP中的GET, POST, PUT, DELETE就对应着对这个资源的查,增,改,删4个操作。我们最常见的就是GET和POST了。GET一般用于获取/查询资源信息,而POST一般用于更新资源信息。
这个是GET信息
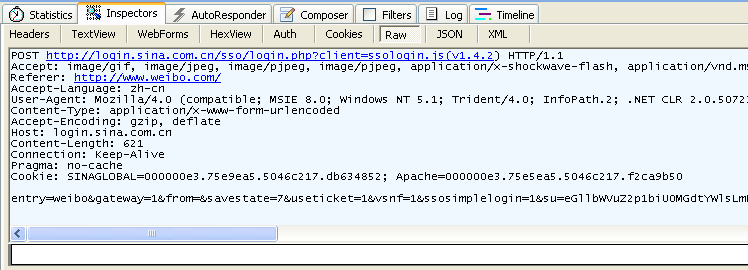
这个是POST信息
GET和POST信息:
1.GET请求信息体为空,POST请求带有消息体
2.GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连
3.GET提交的数据大小有限制,而POST方法提交的数据没有限制
4.GET方式提交数据,会带来安全问题
如果输入用户名和密码提交数据,用户名和密码将出现在URL上,如果页面可以被缓存,将从历史记录获得该用户的账号和密码
HTTP响应包(服务器信息)
response包:
HTTP/1.1200 OK //状态行
Server: nginx/1.0.8//服务器使用的WEB软件名及版本
Date:Date: Tue,30 Oct 201204:14:25 GMT //发送时间
Content-Type: text/html //服务器发送信息的类型
Transfer-Encoding: chunked //表示发送HTTP包是分段发的
Connection: keep-alive //保持连接状态
Content-Length:90//主体内容长度//空行 用来分割消息头和主体<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"...//消息体
第一行叫做状态行,由HTTP协议版本号,状态码,状态消息 三部分组成
我们可以看到200是它的状态码
- 1XX 提示信息 - 表示请求已被成功接收,继续处理
- 2XX 成功 - 表示请求已被成功接收,理解,接受
- 3XX 重定向 - 要完成请求必须进行更进一步的处理
- 4XX 客户端错误 - 请求有语法错误或请求无法实现
- 5XX 服务器端错误 - 服务器未能实现合法的请求
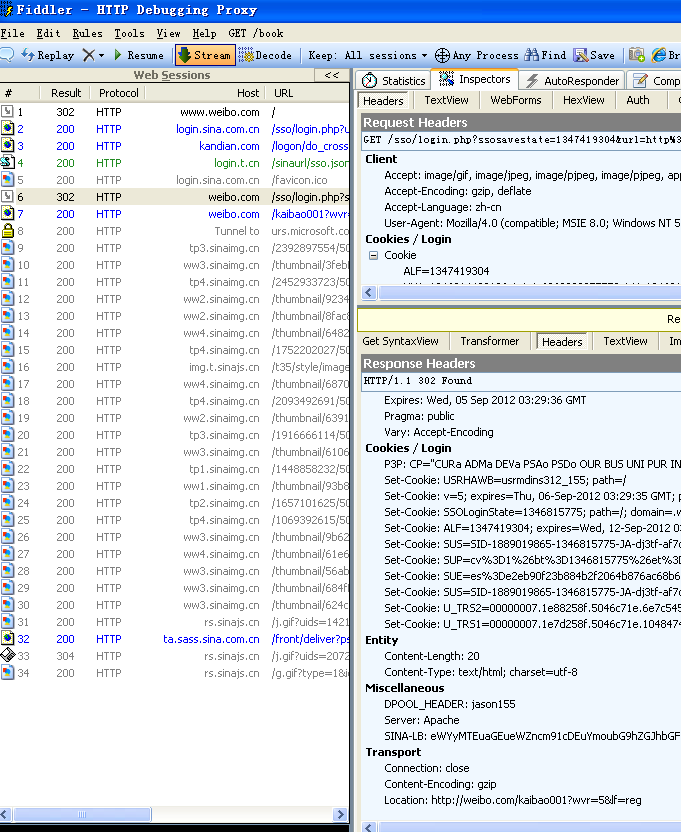
200是常用的,302表示跳转
HTTP协议是无状态的和Connection:keep-alive 的区别
无状态是指协议对于事务处理没有记忆能力,服务器不知道客户端是什么状态。从另一方面讲,打开一个服务器上的网页和你之前打开这个服务器上的网页之间没有任何联系
从HTTP/1.1起,默认都开启了Keep-Alive保持连接特性,简单地说,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的TCP连接。
Keep-Alive不会永久保持连接,它有一个保持时间
这是一次请求的request和response
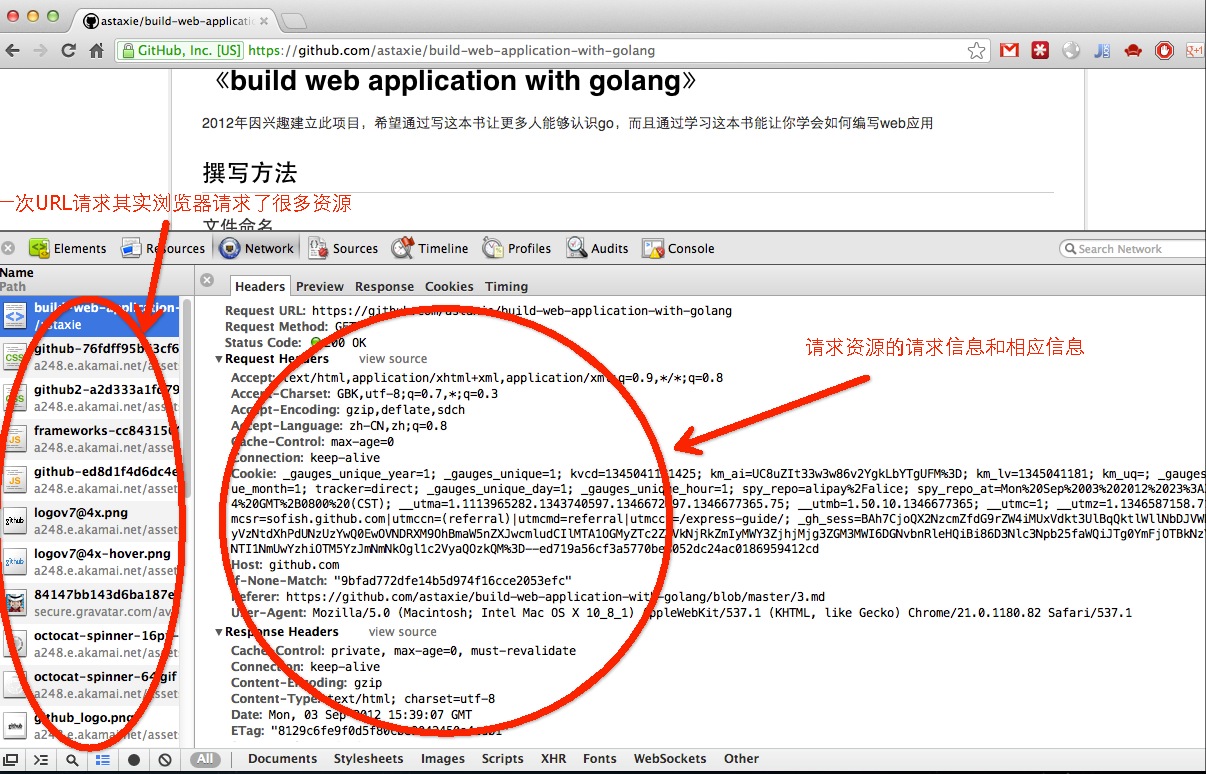
我们可以注意到
为什么一个URL请求但是左边栏里面为什么会有那么多的资源请求
这个就是浏览器的一个功能:第一次请求url,服务器端返回的是html页面,然后浏览器开始渲染HTML:当解析到HTML DOM里面的图片链接,css脚本和js脚本的链接,浏览器就会自动发起一个请求静态资源的HTTP请求,获取相对应的静态资源
3.2 Go搭建一个Web服务器
Go语言里面提供了一个完善的net/http包,通过这个包可以对Web的路由,静态文件,模板,cookie等数据进行设置和操作
package main
import("fmt""log""net/http""strings")funcsayhelloName(w http.ResponseWriter, r *http.Request){
r.ParseForm()//解析参数,默认是不会解析的
fmt.Println(r.Form)//这些信息是输出到服务器端的打印信息
fmt.Println("path", r.URL.Path)
fmt.Println("scheme", r.URL.Scheme)
fmt.Println(r.Form["url_long"])for k, v :=range r.Form {
fmt.Println("key:", k)
fmt.Println("val:", strings.Join(v,""))}
fmt.Fprintf(w,"Hello astaxie!")//这个写入到w的是输出到客户端}funcmain(){
http.HandleFunc("/", sayhelloName)
err := http.ListenAndServe(":9090",nil)if err !=nil{
log.Fatal("ListenAndServe: ", err)}}
3.3 Go如何使得Web工作
Web工作方式的几个概念
Request:用户请求的新消息,用来解析用户的请求信息,包括post,get,cookie,url等信息
Response:服务器需要反馈给客户端的信息
Conn:用户的每次请求连接
Handler:处理请求和生成返回信息的处理逻辑
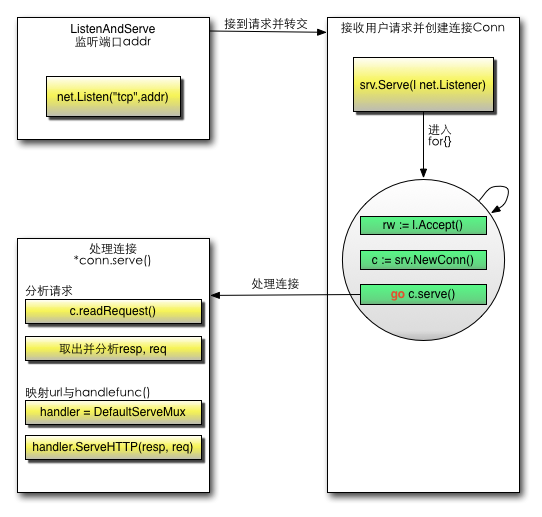
分析http包运行机制
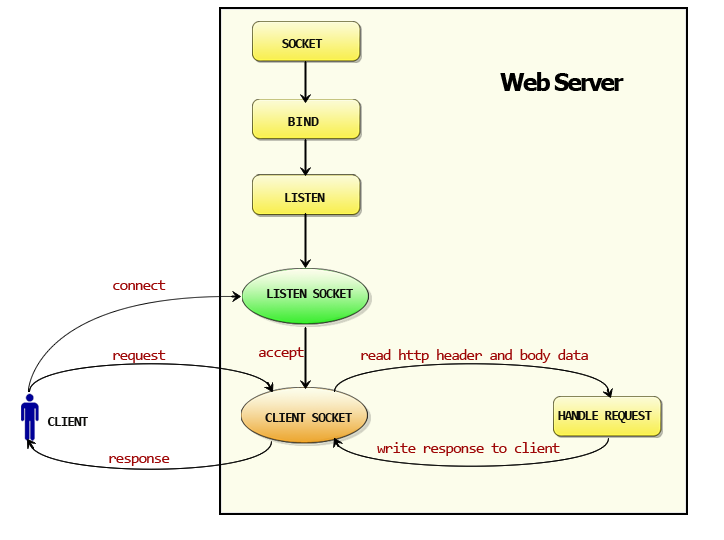
- 创建Listen Socket, 监听指定的端口, 等待客户端请求到来。
- Listen Socket接受客户端的请求, 得到Client Socket, 接下来通过Client Socket与客户端通信。
- 处理客户端的请求, 首先从Client Socket读取HTTP请求的协议头, 如果是POST方法, 还可能要读取客户端提交的数据, 然后交给相应的handler处理请求, handler处理完毕准备好客户端需要的数据, 通过Client Socket写给客户端。
如何监听端口?
Go通过一个 函数ListenAndServe来处理这个事情,底层:
初始化一个serve对象,然后调用net.Listen(“tcp”,addr),也就是底层用TCP协议搭建了一个服务,然后监控我们设置的端口
如何接收客户端请求?
//接下来我会调用srv.Serve(net.Listener)这个函数,这个函数就是处理接收客户端的请求信息func(srv *Server)Serve(l net.Listener)error{//用来处理接收客户端的请求信息defer l.Close()var tempDelay time.Duration // how long to sleep on accept failurefor{
rw, e := l.Accept()if e !=nil{if ne, ok := e.(net.Error); ok && ne.Temporary(){if tempDelay ==0{
tempDelay =5* time.Millisecond
}else{
tempDelay *=2}if max :=1* time.Second; tempDelay > max {
tempDelay = max
}
log.Printf("http: Accept error: %v; retrying in %v", e, tempDelay)
time.Sleep(tempDelay)continue}return e
}
tempDelay =0
c, err := srv.newConn(rw)//创建一个Connif err !=nil{continue}go c.serve()//单独开了一个goroutine}}
如何分配handler?
如何具体分配到相应的函数来处理请求?
conn首先会解析
request:c.readRequest
,然后获取对应的handler:
handler :=c.server.Handler
Go的http详解
Go的http有两个核心功能:Conn,ServeMux
Conn的goroutine
Go为了实现高并发和高性能,使用了goroutine来处理Conn的读写事件,这样每个请求都能保持独立
c, err := srv.newConn(rw)if err !=nil{continue}go c.serve()
客户端的每次请求都会创建一个Conn,这个Conn里面保存了该次请求的信息,然后再传递到对应的handler,该handler中可以读取到相应的header信息,这样保证了每个请求的独立性
ServeMux的自定义(路由器的实现)
并发(Concurrency)是指在计算机科学中,指的是同时执行多个独立的任务或操作的能力。这些任务可能在同一时间段内交替执行,也可能在同一时间段内同时执行,但它们都是在同一个时间段内并发地进行。并发通常涉及到多个线程、进程或任务同时执行,并且这些执行之间可能相互独立,也可能存在一定的交互关系。并发通常被用来提高系统的性能、资源利用率和响应能力。
需要锁机制是为了防止只有一个进程能访问共享资源
type ServeMux struct{
mu sync.RWMutex //锁,由于请求涉及到并发处理,因此这里需要一个锁机制
m map[string]muxEntry // 路由规则,一个string对应一个muxEntry实体,这里的string就是注册的路由表达式
hosts bool// 是否在任意的规则中带有host信息}
type muxEntry struct{
explicit bool// 是否精确匹配
h Handler // 这个路由表达式对应哪个handler
pattern string//匹配字符串}//每个路由表达式都对应着一个handler
type Handler interface{ServeHTTP(ResponseWriter,*Request)// 路由实现器}
我们调用了HandlerFunc(f),强制类型转换f称为HandlerFunc类型,这样f就拥有了ServeHTTP方法
HandlerFunc(f)-因为HandlerFunc实现了Handler接口类型
type HandlerFunc func(ResponseWriter,*Request)// ServeHTTP calls f(w, r).func(f HandlerFunc)ServeHTTP(w ResponseWriter, r *Request){f(w, r)}
默认路由器实现了ServeHTTP:
func(mux *ServeMux)ServeHTTP(w ResponseWriter, r *Request){if r.RequestURI =="*"{
w.Header().Set("Connection","close")
w.WriteHeader(StatusBadRequest)return}
h,_:= mux.Handler(r)
h.ServeHTTP(w, r)}
通过对http包的分析之后,现在让我们来梳理一下整个的代码执行过程。
- 首先调用Http.HandleFunc按顺序做了几件事:1 调用了DefaultServeMux的HandleFunc2 调用了DefaultServeMux的Handle3 往DefaultServeMux的map[string]muxEntry中增加对应的handler和路由规则
- 其次调用http.ListenAndServe(“:9090”, nil)按顺序做了几件事情:1 实例化Server2 调用Server的ListenAndServe()3 调用net.Listen(“tcp”, addr)监听端口4 启动一个for循环,在循环体中Accept请求5 对每个请求实例化一个Conn,并且开启一个goroutine为这个请求进行服务go c.serve()6 读取每个请求的内容w, err := c.readRequest()7 判断handler是否为空,如果没有设置handler(这个例子就没有设置handler),handler就设置为DefaultServeMux8 调用handler的ServeHttp9 在这个例子中,下面就进入到DefaultServeMux.ServeHttp10 根据request选择handler,并且进入到这个handler的ServeHTTP
mux.handler(r).ServeHTTP(w, r)11 选择handler:A 判断是否有路由能满足这个request(循环遍历ServeMux的muxEntry)B 如果有路由满足,调用这个路由handler的ServeHTTPC 如果没有路由满足,调用NotFoundHandler的ServeHTTP
表单
表单是一个包含表单元素的区域
通过表单我们可以让客户端于服务器进行数据的交互
表单元素是允许用户在表单中输入信息的元素
<form>...
input 元素
...</form>

4.1处理表单的输入
package main
import("fmt""log""net/http""text/template")funcsayhelloName(w http.ResponseWriter, r *http.Request){
r.ParseForm()//解析url传递的参数,对于POST则解析相应包的主体//如果没有调用ParseForm方法,下面无法获取表单的数据
fmt.Println(r.Form)//这些信息是输出到服务器端的打印信息
fmt.Println("path", r.URL.Path)
fmt.Println("scheme", r.URL.Scheme)
fmt.Println(r.Form["url_long"])for k, v :=range r.Form {
fmt.Println("key:", k)
fmt.Println("value:", v)}
fmt.Fprintln(w,"Hello astaxie!")//这个写入到w的是输出客户端的}funclogin(w http.ResponseWriter, r *http.Request){
fmt.Println("method:", r.Method)//获取请求的方法if r.Method =="GET"{
t,_:= template.ParseFiles("login.gtpl")
log.Println(t.Execute(w,nil))}else{//请求的要么是登录数据,要么是执行登录的逻辑判断//如查询数据库,验证登录信息等
fmt.Println("username:",r.Form["username"])
fmt.Println("password:",r.Form["password"])}}funcmain(){
http.HandleFunc("/",sayhelloName)// 设置访问的路由
http.HandleFunc("/login",login)
err := http.ListenAndServe("9090",nil)if err!=nil{
log.Fatal("ListenAndServe:",err);}}
4.2验证表单的输入
如何在服务器端验证我们从一个表单元素中得到了一个值。
//如果username是map的值必须通过这种形式iflen(r.Form["username"][0])==0{//为空的处理}
我们通过r.Form.Get()来获取单个值
只能是数字
如果想要确保一个表单输入框中获取的只能是数字
getint,err:=strconv.Atoi(r.Form.Get("age"))if err!=nil{//数字转化出错了,那么可能就不是数字}//接下来就可以判断这个数字的大小范围了if getint >100{//太大了}
只能是中文
于中文我们目前有两种方式来验证,可以使用
unicode
包提供的
func Is(rangeTab *RangeTable, r rune) bool
来验证,也可以使用正则方式来验证,这里使用最简单的正则方式,如下代码所示
if m,_:= regexp.MatchString("^\\p{Han}+$", r.Form.Get("realname"));!m {returnfalse}
英文
if m,_:= regexp.MatchString("^[a-zA-Z]+$", r.Form.Get("engname"));!m {returnfalse}
电子邮箱地址
if m,_:= regexp.MatchString(`^([\w\.\_]{2,10})@(\w{1,}).([a-z]{2,4})$`, r.Form.Get("email"));!m {
fmt.Println("no")}else{
fmt.Println("yes")}
手机号码
if m,_:= regexp.MatchString(`^(1[3|4|5|8][0-9]\d{4,8})$`, r.Form.Get("mobile"));!m {returnfalse}
下拉菜单
想要知道元素生成的下拉菜单中是否有被选中的项目
假设我们的select是这样一些元素
<select name="fruit"><option value="apple">apple</option><option value="pear">pear</option><option value="banana">banana</option></select>
slice:=[]string{"apple","pear","banana"}
v := r.Form.Get("fruit")for_, item :=range slice {if item == v {returntrue}}returnfalse
单选按钮
当我们需要判断一个单选按钮是否选中的时候
<input type="radio" name="gender" value="1">男
<input type="radio" name="gender" value="2">女
和下拉菜单的做法一样
slice:=[]string{"1","2"}for_, v :=range slice {if v == r.Form.Get("gender"){returntrue}}returnfalse
复选框
就是多选的
<input type="checkbox" name="interest" value="football">足球
<input type="checkbox" name="interest" value="basketball">篮球
<input type="checkbox" name="interest" value="tennis">网球
slice:=[]string{"football","basketball","tennis"}
a:=Slice_diff(r.Form["interest"],slice)if a ==nil{returntrue}returnfalse
funcSlice_diff(slice1, slice2 []interface{})(diffslice []interface{}){for_, v :=range slice1 {if!In_slice(v, slice2){
diffslice =append(diffslice, v)}}return}
日期和时间
你想确定日期时间是否有效
t := time.Date(2009, time.November,10,23,0,0,0, time.UTC)
fmt.Printf("Go launched at %s\n", t.Local())
身份证号码
身份证有十五位和十八位
//验证15位身份证,15位的是全部数字if m,_:= regexp.MatchString(`^(\d{15})$`, r.Form.Get("usercard"));!m {returnfalse}//验证18位身份证,18位前17位为数字,最后一位是校验位,可能为数字或字符X。if m,_:= regexp.MatchString(`^(\d{17})([0-9]|X)$`, r.Form.Get("usercard"));!m {returnfalse}
4.3预防跨站脚本
我们的网站包含了大量的动态内容以提高用户体验,比过去要复杂的多,所谓动态内容,就是根据用户环境的需要,Web应用程序能够输出相应的内容 。
对XSS(跨站脚本攻击)最佳的防护应该结合以下两种方法:
1.对所有输入数据进行检验
2.进行适当的处理,防止任何已经成功注入的脚本在浏览器端运行
HTML转义
HTML 转义是指将 HTML 特殊字符转换为对应的 HTML 实体,以防止恶意用户插入 HTML 或 JavaScript 代码导致的安全漏洞。HTML/template 包提供了几个函数来帮助进行 HTML 转义。
在 web 应用程序中,如果允许用户输入的内容直接嵌入到 HTML 页面中而没有经过转义处理,就可能会导致安全漏洞。这种情况被称为跨站脚本攻击(Cross-Site Scripting,XSS)。
XSS 攻击的原理是攻击者向网页中注入恶意的客户端脚本,当其他用户访问包含恶意脚本的页面时,这些脚本就会在用户浏览器中执行,从而达到攻击的目的,例如盗取用户的会话信息、篡改页面内容等。
举个例子,如果一个网站允许用户在评论中输入任意内容,并且将这些内容直接显示在网页上,而不进行转义处理,那么攻击者可以在评论中插入恶意的 JavaScript 代码。当其他用户浏览这些评论时,恶意脚本就会在其浏览器中执行,可能导致用户的账户被盗取或者其他安全问题。
因此,对用户输入的内容进行适当的转义处理是防范 XSS 攻击的重要手段之一。HTML 转义函数就是一种常见的转义处理方式,它将 HTML 特殊字符转换为对应的 HTML 实体,从而使得恶意脚本失效,保护了网站的安全。
脚本
脚本(Script)是一种用于自动化和控制计算机程序行为的编程语言。脚本通常以文本形式编写,并且可以被解释器直接执行,而不需要预先编译成二进制代码。脚本语言通常用于快速编写小型程序或自动化任务,如网页交互、系统管理、数据处理等。
在 web 开发中,脚本通常指的是客户端脚本(Client-side Script),它是嵌入在网页中的脚本代码,由浏览器解释执行。常见的客户端脚本语言包括 JavaScript、VBScript 等。这些脚本可以在用户浏览网页时在浏览器中执行,用于实现网页的交互功能、动态效果等。
举个例子,当你在网页上点击一个按钮,触发了一些动作或者弹出了一个对话框,很可能是因为网页中嵌入了 JavaScript 脚本,它在用户与网页交互时被触发执行。
然而,如果恶意用户能够将自己的恶意脚本注入到网页中,并成功执行,就可能导致安全问题,比如跨站脚本攻击(XSS)或其他类型的安全漏洞。因此,开发者需要注意对用户输入数据进行适当的过滤和转义,以防止这类安全风险的发生。
MD5(Message Digest Algorithm 5)是一种常用的哈希函数,用于将任意长度的消息(或数据)转换为固定长度的哈希值(通常为128位的二进制字符串,或者32个十六进制字符)。
MD5
MD5 哈希对象通常在计算机安全、数据完整性验证等领域中使用,其主要用途包括:
数据完整性验证:** MD5 哈希函数可以将任意长度的数据转换为固定长度的哈希值。通过对原始数据进行哈希处理,可以生成一个唯一的标识符,称为哈希值。如果数据的任何部分发生了改变,其哈希值也会发生变化。因此,可以通过比较数据的哈希值来验证数据的完整性,确保数据在传输或存储过程中没有被篡改。
package main
import("crypto/md5""fmt""html/template""io""log""net/http""strconv""strings""time")funcsayhelloName(w http.ResponseWriter, r *http.Request){
r.ParseForm()//解析url传递的参数,对于POST则解析响应包的主体(request body)//注意:如果没有调用ParseForm方法,下面无法获取表单的数据
fmt.Println(r.Form)//这些信息是输出到服务器端的打印信息
fmt.Println("path", r.URL.Path)
fmt.Println("scheme", r.URL.Scheme)
fmt.Println(r.Form["url_long"])for k, v :=range r.Form {
fmt.Println("key:", k)
fmt.Println("val:", strings.Join(v,""))}
fmt.Fprintf(w,"Hello astaxie!")//这个写入到w的是输出到客户端的}funclogin(w http.ResponseWriter, r *http.Request){
fmt.Println("method:", r.Method)if r.Method =="GET"{//如果时GET请求,就返回登录页面
crutime := time.Now().Unix()//获取当前时间戳(当前时刻)
h := md5.New()//创建一个MD5,MD5对象可以保证这个时间戳的安全性
io.WriteString(h, strconv.FormatInt(crutime,10))//将当前时间戳转换成字符串并写入哈希对象h
token := fmt.Sprintf("%x", h.Sum(nil))//fmt.Sprintf用来返回格式化的字符串//计算哈希值并将其格式化为十六进制字符串
t,_:= template.ParseFiles("vote.html")//解析模板文件并赋值给t
t.Execute(w, token)//将token(格式化的字符串)渲染到模板中//发送给客户端}else{//如果时POST就需要处理 用户提交的登陆数据
r.ParseForm()//解析表单数据
token := r.Form.Get("token")if token !=""{//验证token的合法性}else{//不存在token则报错}
fmt.Println("username length:",len(r.Form["username"][0]))
fmt.Println("username:", template.HTMLEscapeString(r.Form.Get(("username"))))//打印用户名,并适应HTML转义
fmt.Println("password:", template.HTMLEscapeString(r.Form.Get("password")))
template.HTMLEscape(w,[]byte(r.Form.Get("username")))//将用户名转移之后,输出到客户端}}funcmain(){
http.HandleFunc("/", sayhelloName)//设置访问的路由
http.HandleFunc("/login", login)//设置访问的路由
err := http.ListenAndServe(":9090",nil)//设置监听的端口if err !=nil{
log.Fatal("ListenAndServe: ", err)}}
4.5处理文件上传
要使表单能够上传文件
我们要添加form的enctype属性,enctype属性有三种情况:
application/x-www-form-urlencoded 表示在发送前编码所有字符(默认)multipart/form-data 不对字符编码。在使用包含文件上传控件的表单时,必须使用该值。text/plain 空格转换为 "+" 加号,但不对特殊字符编码。
package main
import("crypto/md5""fmt""html/template""io""net/http""os""strconv""time")funcupload(w http.ResponseWriter, r *http.Request){
fmt.Println("method", r.Method)//获取请求的方法if r.Method =="GET"{
crutime := time.Now().Unix()
h := md5.New()
io.WriteString(h, strconv.FormatInt(crutime,10))
token := fmt.Sprintf("%x", h.Sum(nil))
t,_:= template.ParseFiles("upload.html")
t.Execute(w, token)}else{
r.ParseMultipartForm(32<<20)//限制最大大小为32MB
file, handler, err := r.FormFile("uploadfile")//文件handler是multipart.FileHeader//里面存储了如下结构信息/*
type FileHeader struct{
Filename string
Header textproto.MIMEHeader
}
*/if err !=nil{
fmt.Println(err)return}defer file.Close()
fmt.Fprintf(w,"%v", handler.Header)
f, err := os.OpenFile("./test/"+handler.Filename, os.O_WRONLY|os.O_CREATE,0666)if err !=nil{
fmt.Println(err)return}defer f.Close()
io.Copy(f, file)}}
<!DOCTYPE html><html ><head><meta charset="UTF-8"><title>上传文件</title></head><body><form enctype="multipart/form-data" action ="/upload" method ="post"><input type="file" name ="uploadfile"/><input type="hidden" name ="token" value="{{.}}"/><input type="submit" value="upload"></form></body></html>
上传文件主要三步处理:
1.表单中增加
enctype = "multipart/from-data"
2.服务器端调用
r.ParseMultipartForm
,把上传的文件存储在内存和临时文件中
3.使用
r.FormFile
获取文件句柄,然后对文件进行存储等处理
5 访问数据库
5.1database/sql接口
什么是数据库驱动?
数据库驱动是一种API
用于连接应用程序与数据库之间的通信
可以通过数据库驱动对数据库完成相应的查询,插入和更新
但是Go没有数据库驱动,未开发着定义了一些标准接口口,开发者可以根据定义的接口来开发相应的数据库驱动
sql.Register
- 用来注册数据库驱动
- 会实现init函数,在init里面调用Register(name string ,driver driver.Driver)完成本驱动的注册
在database/sql内部通过一个map来存储用户定义的相应驱动
var drivres =make(map[string]driver.Driver)
我们可以通过这个函数同时注册多个数据库驱动,只要不重复
import("database/sql"_"github.com/mattn/go-sqlite3"/*
_是go设计的一个巧妙的地方,它作为一个占位符。然后我们引入后面的包但是不直接使用这个包中定义的资源
/*
原因就是我们在引入一个包的时候会init函数初始化,而init函数又恰好注册了这个数据库驱动
*/*/)
driver.Driver
Driver是一个数据库驱动的接口,他定义了一个method:Open(name string),这个方法返回一个 数据库的Conn接口
type Driver interface{Open(name string)(Conn,error)}
返回的Conn只能用于进行一次goroutine操作
...go goroutineA (Conn)//执行查询操作go goroutineB (Conn)//执行插入操作...
driver.Conn
Conn是一个数据库连接的接口定义,它定义了一系列方法,这个Conn只能应用在一个goroutine里面
type Conn interface{Prepare(query string)(Stmt,error)//返回与当前连接相关的Sql的准备状态,可以进行查询、删除操作Close()error//关闭当前连接,释放资源Begin()(Tx,error)//Tx是代表事务的,通过它可以对事务进行回滚和递交}
driver.Stmt
Stmt是一种准备好的状态,和Conn相关联,而且只能应用于一个goroutine中,不能应用于多个goroutine
type Stmt interface{Close()error//Close函数关闭当前的连接状态NumInput()int//这个返回的是参数个数,当返回>=0 数据库驱动就会只能检查调用者的参数。当数据库驱动包不知道预留参数的时候,返回-1Exec(args []Value)(Result,error)//用来执行Prepare准备好的squl,传入参数执行update/insert等操作,返回Result数据 Query(args []Value)(Rows,error)//也是执行操作,执行select操作,返回Rows操作集}
driver.Tx
事务处理一般就两个过程,递交或者回滚。数据库驱动里面也只需要实现这两个函数就可以
type Tx interface{Commit()errorRollback()error}
driver.Execer
这是一个Conn可选择实现的接口
type Execer interface{Exec(query string,args []Value)(Result,error)}
如果这个接口没有定义,那么在调用DB.Exec,就会首先调用Prepare返回Stmt,然后执行Stmt的Exec,然后关闭Stmt
driver.Result
这个是执行Update/Insert等操作的结果接口定义
type Result interface{LastInsertId()(int64,error)//返回由数据库执行插入操作得到的自增ID号RowAffected()(int64,error)//返回query操作影响的数据条目数}
driver.Rows
Rows是执行查询返回的结果集接口定义
type Rows interface{Columns()[]string//返回查询数据库表的字段信息//不是返回表的所有字段Close()error//关闭Rows迭代器Next(dest []Value)error//用来返回下一条数据,把数据传给dest//dest里面的数据必须是driver.Value的值除了string//数据中的string必须要转换成[]byte}
driver.RowsAffected
是int64的别名
实现了Result接口
type RowAffected int64func(RowsAffected)LastInsertId()(int64,error)func(v RowsAffected)RowsAffected()(int64,error)
driver.Value
- 是一个空接口,可以容纳任何数据
type Value interface{}
Value是驱动需要操作的value
Value只能是下面的任意一种
int64float64bool[]bytestring[*]除了Rows.Next返回的不能是string.
time.Time
nil
driver.ValueConverter
- 将一个普通的值转变为value
type ValueConverter interface{ConverterValue(v interface{})(value,error)}
ValueConverter有很多好处:
- 转化driver.value到数据库相应的字段
- 把数据库查询结果转化成driver.Value值
- 在scan函数里面如何把driver.Value值转化成用户定义的值
driver.Valuer
Valuer接口定义了返回一个driver.Value的方式
type Valuer interface{Value()(Value,error)}
很多类型都实现了这个Value方法,用来自身与driver.Value的转化
一个驱动只要实现了这些接口就能完成增删查改等基本操作
database/sql
提供了一个更高阶的方法,用以简化数据库操作,同时内部还建议性地实现了一个conn pool
type DB struct{
driver driver.Driver
dsn string
mu sync.Mutex
freeConn []driver.Conn
closed bool}
Open函数返回的是DB对象,里面有一个freeConn,它就是那个简易的连接池。
Web 应用程序的一部分
我们可以看到Web应用程序时执行以下操作的一段程序:
1.通过HTTP发送请求
2.处理HTTP请求信息并执行必要的工作
3.生成HTML并在HTTP的相应消息中返回它
Web应用程序有两个不同的部分:处理程序和模板引擎
- 处理程序接收并处理从客户端发送的HTTP请求
处理程序是控制器也是模型
我们需要了解一下MVC模式
模型-视图-控制器模式是一种用于编写Web应用的流行模式
模型是底层数据的表示
视图是模型对用户的可视化
控制器通过控制用户的输入来修改模型
请求格式通常是应用程序本身的特权
格式:
http:///?
funcmain(){//首先创建一个多路复用器,用来重定向
mux := http.NewServeMux()//创建一个文件服务器,用于提供静态文件的服务,接收http.FileSystem接口类型的参数//返回http.Handler类型的对象//http.Dir("/public")表示文件服务器的根目录为"/public"目录
files := http.FileServer(http.Dir("/public"))
mux.Handle("/static/", http.StripPrefix("/static/", files))
mux.HandleFunc("/", index)
server :=&http.Server{
Addr:"0.0.0.0:8080",
Handler: mux,}
server.ListenAndServe()}
files := http.FileServer(http.Dir("/public"))
->http.FileServer( a http.FileSystem)
所以说http.Dir(“/public”) 会返回一个实现了http.FileSystem的对象,这个对象是一个指定路径的文件系统
表示文件服务器的根目录是当前文件系统中的”/public“目录
当客户向服务端请求静态文件,FileServer get the information and get into FileSystem.And Then got into the “/public” to find if the file exit
func index(w http.ResponseWriter, r *http.Request) {
files := []string{"templates/layout.html",
"templates/navbar.html",
"templates/index.html",}
templates := template.Must(template.ParseFiles(files...))
threads, err := data.Threads(); if err == nil {
templates.ExecuteTemplate(w, "layout", threads)
}
}
3.7(3.8 3.10 3.14)
HTML的基本概念和知识点
1.HTML:
- 是一个用于创建网页结构的标记语言,由一系列标签组成,用于描述页面的结构和内容
2.HTML标签:
标签格式:<>
eg :xzc就是标签的名称
3.HTML元素:
通常成对出现:
比如开始标签和结束标签:
表示段落的开始
表示段落的结束
开始标签和结束标签之间的内容就是该元素的内容
4.HTML属性:
属性位于开始标签内部,并且具有名称和值
eg:
5.常用HTML标签
-
用来定义标签
用来定义段落
用来创建链接
6.HTML文档结构
HTML文档通常由
<!DOCTYPE html>
声明、
<html>
元素、
<head>
元素和
<body>
元素组成。
<!DOCTYPE html>
声明用于指定文档类型,
<html>
元素是文档的根元素,
<head>
元素包含了文档的元信息,如标题、样式表和脚本等,而
<body>
元素包含了页面的可见内容。
7.HTML注释
注释以
结尾
中国
3.创建css文件,在css文件中编写并在HTML中引进来
1.在head中引用
```css
引用方式:head中添加<link href="css文件地址" rel="stylesheet">
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<link href="css/01.css" rel="stylesheet"/>
</head>
<body>
<h1>CSS使用方法3:在head中使用linked</h1>
</body>
</html>
2.在style中引用(style位于head和body中间)
引用方式:style中添加@import url(对应CSS文件地址)
<!DOCTYPEhtml><htmllang="en"><head><metacharset="UTF-8"><metahttp-equiv="X-UA-Compatible"content="IE=edge"><metaname="viewport"content="width=device-width, initial-scale=1.0"><title>Document</title></head><body><h1>CSS使用方法3:在style中使用 @import url(地址) </h1></body></html>
选择器
1.元素(标签)选择器
<!DOCTYPEhtml><htmllang="en"><head><metacharset="UTF-8"><metahttp-equiv="X-UA-Compatible"content="IE=edge"><metaname="viewport"content="width=device-width, initial-scale=1.0"><title>Document</title></head><style>/*
所有p标签字体都会变成红色
(也可以有其它格式设置,本处以颜色红举例)
标签选择器会选择所有对应的标签,即p标签
*/p{color: red;}</style><body><p>段落1</p><p>段落2</p><p>段落3</p><p>段落4</p></body></html>
2.类选择器
<!DOCTYPEhtml><htmllang="en"><head><metacharset="UTF-8"><metahttp-equiv="X-UA-Compatible"content="IE=edge"><metaname="viewport"content="width=device-width, initial-scale=1.0"><title>Document</title></head><style>/*
标签里面加上class="名字"
.class名字 指定的会变成红色,即段落2以红色显示
(也可以有其它格式设置,本处以颜色红举例)
*/.p2{color: red;}</style><body><p>段落1</p><pclass="p2">段落2</p><p>段落3</p><p>段落4</p></body></html>
3.id选择器
<!DOCTYPEhtml><htmllang="en"><head><metacharset="UTF-8"><metahttp-equiv="X-UA-Compatible"content="IE=edge"><metaname="viewport"content="width=device-width, initial-scale=1.0"><title>Document</title></head><style>/*
标签里面加上id="名字"
# id名字 指定的会变成红色,即段落2以红色显示
(也可以有其它格式设置,本处以颜色红举例)
*/#p2{color: red;}</style><body><p>段落1</p><pid="p2">段落2</p><p>段落3</p><p>段落4</p></body></html>
5.选择器组
<!DOCTYPEhtml><htmllang="en"><head><metacharset="UTF-8"><metahttp-equiv="X-UA-Compatible"content="IE=edge"><metaname="viewport"content="width=device-width, initial-scale=1.0"><title>Document</title></head><style>/*
如果两个选择器内部设置相同,那么可以合并两个选择器,中间用逗号隔开
*/.p2,#p3{color: red;}</style><body><p>段落1</p><pclass="p2">段落2</p><pid="p3">段落3</p><p>段落4</p></body></html>
6.派生选择器
<!DOCTYPEhtml><htmllang="en"><head><metacharset="UTF-8"><metahttp-equiv="X-UA-Compatible"content="IE=edge"><metaname="viewport"content="width=device-width, initial-scale=1.0"><title>Document</title></head><style>/*
div 标签 :所有的标签都会变红(此处以变红为例,当然也可有有其它设置)
*/div p{color: red;}</style><body><p>p1</p><p>p2</p><p>p3</p><p>p4</p><p>p5</p><span><p>p6</p><span><p>p7</p></span></span><p>p8</p></body></html>
<!DOCTYPEhtml><htmllang="en"><head><metacharset="UTF-8"><metahttp-equiv="X-UA-Compatible"content="IE=edge"><metaname="viewport"content="width=device-width, initial-scale=1.0"><title>Document</title></head><style>/*
div > 标签 :只有最外层的标签都会变红(此处以变红为例,当然也可有有其它设置)
*/div > p{color: red;}</style><body><p>p1</p><p>p2</p><p>p3</p><p>p4</p><p>p5</p><span><p>p6</p><span><p>p7</p></span></span><p>p8</p></body></html>
伪类
<!DOCTYPEhtml><htmllang="en"><head><metacharset="UTF-8"><metahttp-equiv="X-UA-Compatible"content="IE=edge"><metaname="viewport"content="width=device-width, initial-scale=1.0"><title>Document</title></head><style>/* 未点击百度一下之前的颜色 */a:link{color:rgb(8, 7, 7)}/* 鼠标放在百度一下上面的样子 */a:hover{font-size: 50px;}/* 访问过百度一下的颜色 */a:visited{color:rgb(161, 15, 15);}/* 鼠标点住百度一下没松开时候的颜色 */a:active{color: lawngreen;}</style><body><ahref="https://www.baidu.com">百度一下</a></body></html>
属性
1.文本属性:
font-family:设置文本字体
font-size:设置字体尺寸
font-weight:设置字体的粗细
color:字体严肃
text-align:字体对齐方式
line-height:行高
text-decoration:文本装饰
text-indent:文本缩进
2.背景属性
background-image:url("图片地址") 设置背景图片
background-color 设置背景颜色
background-position 背景图片的位置
background-repeat 背景的平铺方式——repeat 图片在垂直水平方向上重复
——repeat-x 图片在水平方向上重复
——repeat-y 图片在垂直方向上重复
——no-repeat 图片不重复
background-attachment:fixed 背景图片固定
3.列表属性
list-style-type: none没有标记 disc默认标记
circle 标记是实心圆
dquare 标记是实心方块
decimal 标记是数字
javascript基础知识
我们在HTML元素中的
document.write("Hello World")
可以写出“Hello World”
可以插入在部分和部分都可以
引用外部脚本的方法:
版权归原作者 vd_vd 所有, 如有侵权,请联系我们删除。