
我的一个朋友接到一个外包 爬取抖音视频的评论,我把这个做完了决定做个总结方便后续的学习,也欢迎讨论交流,Vx:mastercy1
先面向百度编程,看看大佬们怎么做的,参考了部分思路,然后大部分都是模拟器,在正准备下手机模拟器的时候,发现抖音已经有了PC的web端https://www.douyin.com/
于是我们来分析一下,首先查看一下网页结构,首页是跟app一样的各种推送的,
可以点进去进入用户主页,主页会有所有视频,
也可以搜索进入进入用户主页或者搜索某一关键词相关的视频。
点击搜索出来的视频或者用户主页的视频都会进入单个视频页
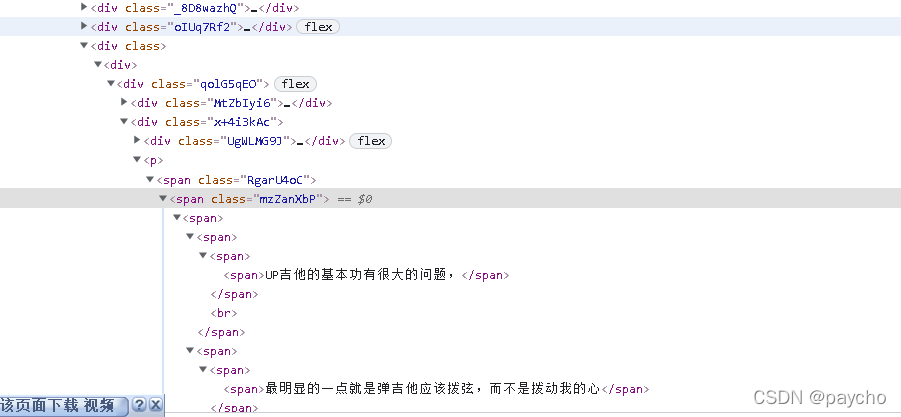
然后页面都是瀑布流加载的,那其实爬评论和视频下载链接是一样的,为了不片面的只是贴个爬虫代码,我先分析request的方法,我们来F12找一下方法
request分析
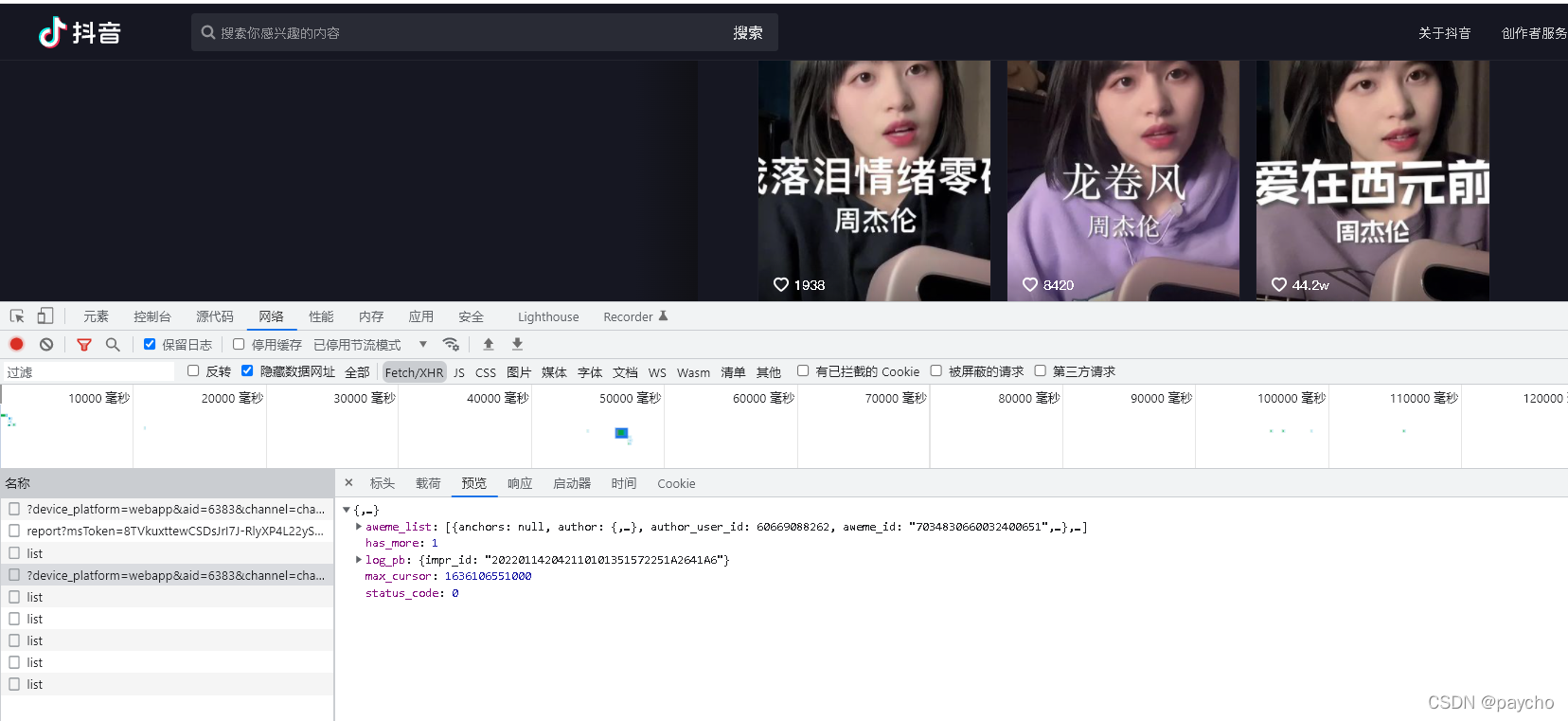
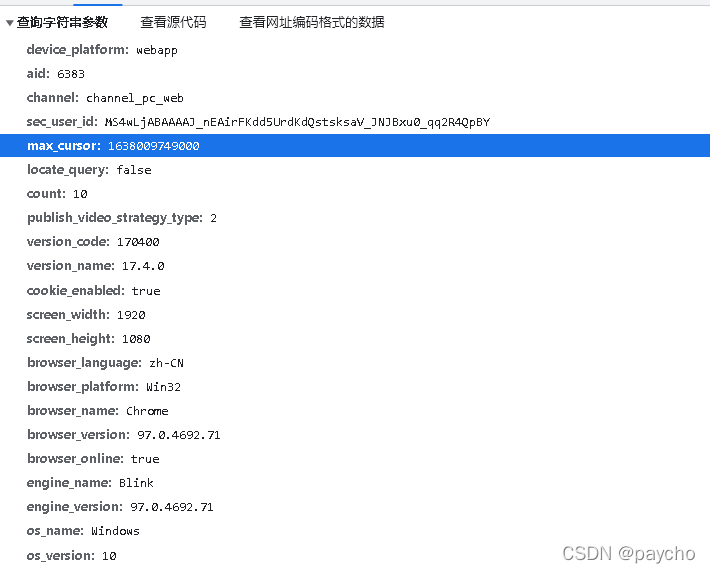
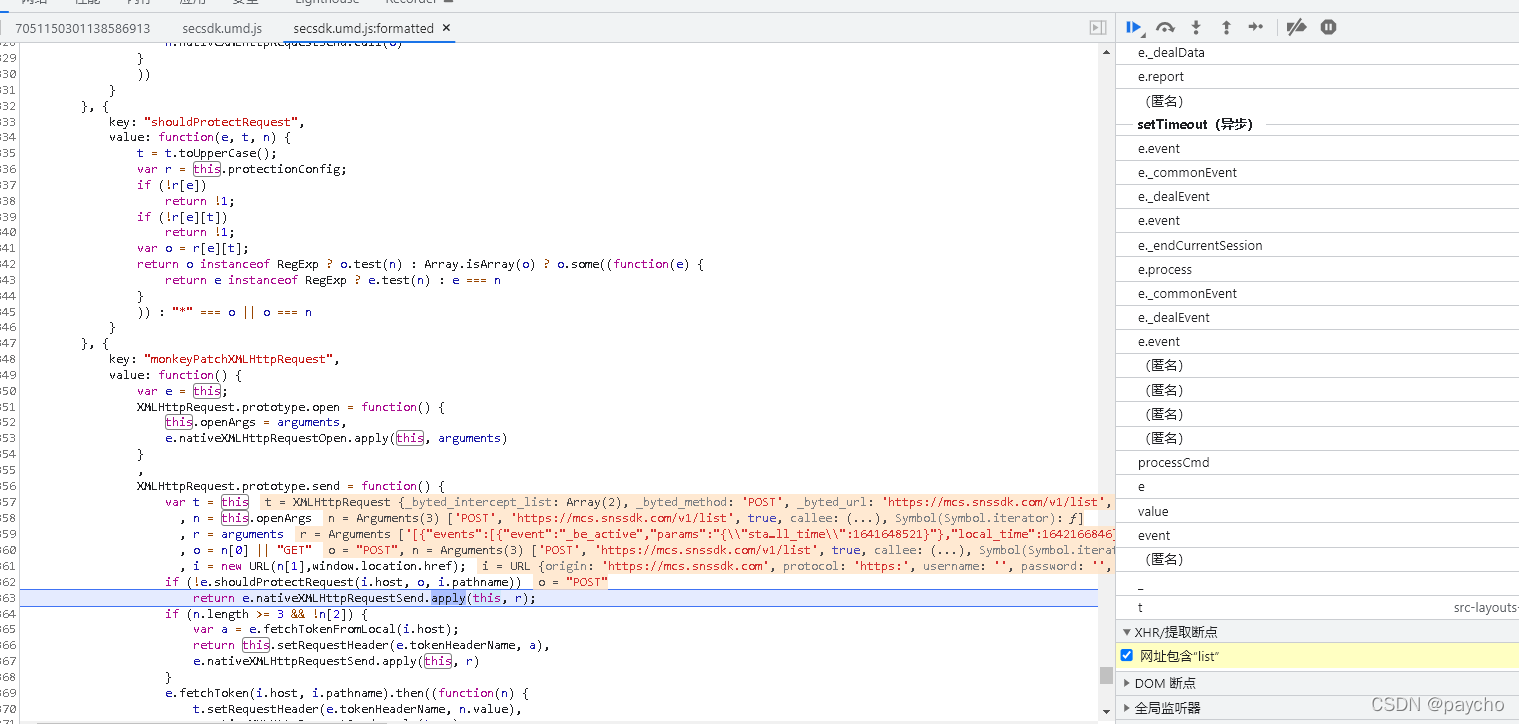
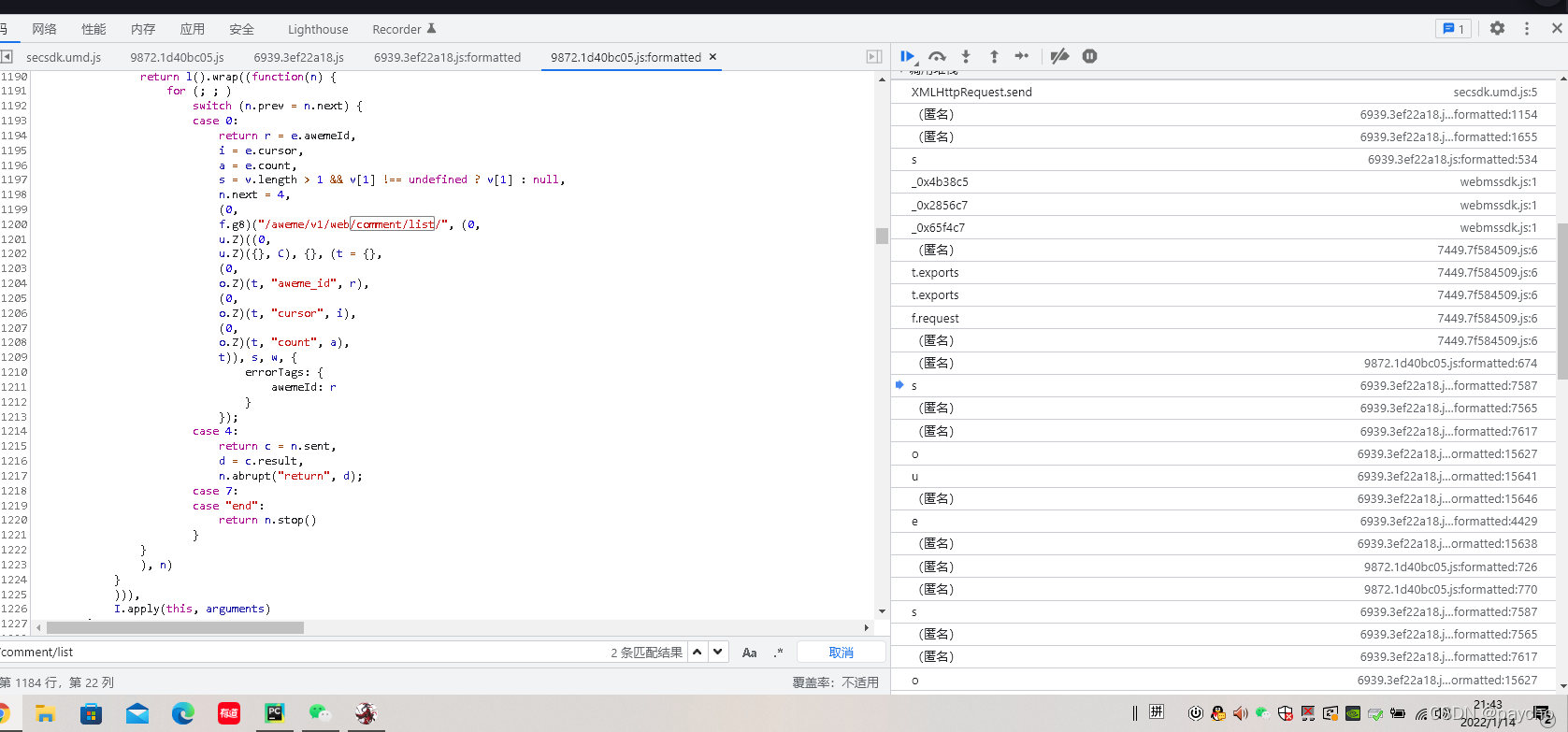
我们可以找到往下滚动的时候调用了这个方法,然后查看参数 比较重要的有max_cursor,count,以及下方的三个用js生成的 需要逆向解决,打上一个断点 一顿分析 最终找到这些个 /aweme/v1/web/comment/list/ 就是

这两个与之相关的js做逆向即可
页面元素定位这边不做赘述,就直接复制就行,xpath,re都可
正常的设置请求头,发起请求获取数据解析存储
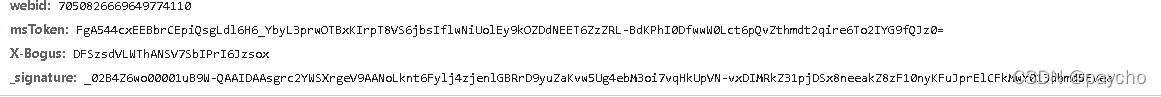
selenium方法
request方法好在不会一开始就有验证码,而seleium一打开浏览器访问抖音就会有一个滑动验证码,我这里参考网上的方法,做了一个解验证码的函数,大概思路就是保存弹出的图片对比像素点,得到不一样的像素点的位置,就移动的距离,然后加速减速拖动
import cv2
import time
from selenium.webdriver import ActionChains
import requests
import random
def canny(filepath, cell=7):
img = cv2.imread(filepath, 0)
blurred = cv2.GaussianBlur(img, (cell, cell), 0)
return cv2.Canny(blurred, 240, 250)
def getPosition(img_file1, img_file2):
img = canny(img_file1)
img2 = img.copy()
template = canny(img_file2, cell=5)
w, h = template.shape[::-1]
img = img2.copy()
method = eval("cv2.TM_CCOEFF_NORMED")
res = cv2.matchTemplate(img, template, method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv2.rectangle(img, top_left, bottom_right, 255, 2)
return top_left
def get_track(distance):
v = 0
t = 0.4
tracks = []
current = 0
mid = distance * 7 / 8
distance += 5
while current < distance:
if current < mid:
a = random.randint(2, 4) # 加速运动
else:
a = -random.randint(1, 3) # 减速运动
v0 = v
s = v0 * t + 0.6 * a * (t ** 2)
current += s
tracks.append(round(s))
v = v0 + a * t
random.shuffle(tracks)
return tracks
def checkCode(b, img_file1, img_file2):
scale = 1.7
try:
while 1:
t = b.find_element_by_xpath('//*[@id="captcha-verify-image"]')
t = t.get_attribute("src")
img = requests.get(t)
f = open(img_file1, "wb")
f.write(img.content)
f.close()
t = b.find_element_by_xpath('//*[@id="captcha_container"]/div/div[2]/img[2]').get_attribute("src")
img = requests.get(t)
f = open(img_file2, "wb")
f.write(img.content)
f.close()
p = int(getPosition(img_file1, img_file2)[0] / scale)
# print(p)
button = b.find_element_by_xpath('//*[@id="secsdk-captcha-drag-wrapper"]/div[2]')
tracks = get_track(p)
ActionChains(b).click_and_hold(button).perform()
for x in tracks:
ActionChains(b).move_by_offset(xoffset=x, yoffset=0).perform()
ActionChains(b).release(button).perform()
time.sleep(1)
except:
print("ok")
好 然后我们思路是这样,有两种
- 直接搜索某一个关键词,然后把这个关键词下的前x个视频的所有评论都爬了
- 直接搜索某个人的主页,然后把这个人下的全部视频的所有评论都爬了
(这里先爬个四五页因为没搞代理ip,也没做频繁访问时候会跳的文字验证码)
# @FILE : tt_getComment.py
# @Time : 2022/1/13 12:08
from selenium import webdriver
import re
from lxml import etree
import time
import os
import json
import datetime
import uuid
from tiktok_spider.check_Code import checkCode
#此脚本可以跑单个页面 也可以作为跑多个页面的线程
#跑单个时 修改下方要爬的url直接运行此文件
#作为线程时 调用get_comment(url),并传入参数即可
def get_review_number(b):
#//*[@id="root"]/div/div[2]/div/div/div[1]/div[1]/div[3]/div/div[2]/div[1]/div[2]/span
# num=b.find_element_by_xpath('//*[@id="root"]/div/div[2]/div/div/div[1]/div[1]/div[3]/div/div[2]/div[1]/div[2]/span').text
# print(int(num))
for x in range(1, 15, 5):
time.sleep(1)
j = x * 12
js = 'document.documentElement.scrollTop=document.documentElement.scrollHeight* %f' % j
b.execute_script(js)
def get_comment(url,id):
chrome_d = "C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe"
option = webdriver.ChromeOptions()
option.add_argument('headless') # 添加无头模式
b = webdriver.Chrome(executable_path=chrome_d,options=option)
b.get(url)
b.maximize_window()
time.sleep(2)
img1 = str(uuid.uuid1()) + '.jpeg'
img2 = str(uuid.uuid1()) + '.png'
checkCode(b,img1, img2) #过验证码
if os.path.exists(img1):
os.remove(img1)
if os.path.exists(img2):
os.remove(img2)
time.sleep(2)
get_review_number(b)
b.implicitly_wait(3)
# Review_list = b.find_elements_by_xpath('//*[@id="root"]/div/div[2]/div/div/div[1]/div[3]/div/div/div[4]/div/div')
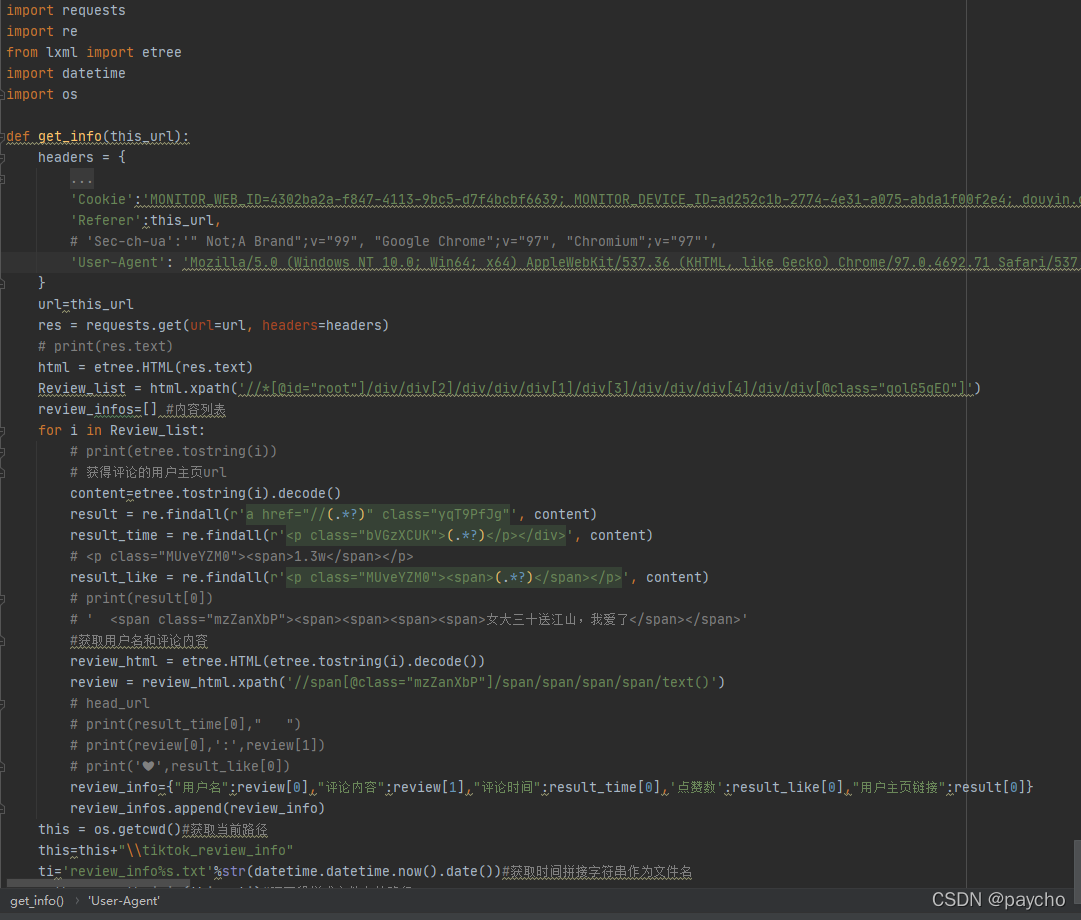
Review_list = b.find_element_by_xpath('//*[@id="root"]/div/div[2]/div/div/div[1]/div[3]/div/div').get_attribute("outerHTML")
b.close()
html = etree.HTML(Review_list)
Review_list = html.xpath('//div[4]/div/div[@class="qolG5qEO"]')
review_infos = [] # 内容列表
for i in Review_list:
# print('1',i)
review_html = etree.HTML(etree.tostring(i).decode())
# print(review_html)
review = review_html.xpath('//span[@class="mzZanXbP"]/span/span/span[1]/span/text()') #用户名和评论内容
# print(review)
try:
if len(review)==1:
# print(1111)
review.append('[表情]')
if len(review[2])!=0:
review[1]=review[1]+review[2]
except:
pass
result_like = review_html.xpath('//div[2]/div[2]/div/p/span/text()') #点赞数
content = etree.tostring(i).decode()
result_time = re.findall(r'<p class="bVGzXCUK">(.*?)</p>', content) #评论时间
result = re.findall(r'a href="//(.*?)" class="yqT9PfJg"', content) #用户主页地址
if len(result_time)==0:
result_time[0]=0
# print(review[0], ':', review[1])
# print(result_time[0],' ',result[0])
review_info = {"用户名": review[0], "评论内容": review[1], "评论时间": result_time[0], '点赞数': result_like[0],"用户主页链接": result[0]}
review_infos.append(review_info)
this = os.getcwd()#获取当前路径
this=this+"\\tiktok_review_info"
ti='review_info%s-%s.txt'%(str(datetime.datetime.now().date()),id)#获取时间拼接字符串作为文件名
path= os.path.join(this, ti)#吧两段拼成文件存储路径
fp = open(path,'w',encoding='utf-8')
fp.write('[\n')
for i in review_infos:
print(i)
data = json.dumps(i, ensure_ascii=False)
fp.write(data + ',\n')
fp.write(']')
fp.close()
需要注意的是 由于经验和时间的问题很多地方没有做异常判断,以及对于评论的非法字符判断只是比较初级的
然后是主函数,这里就放了一个给定某用户主页url爬取他的所有视频,然后把视频地址弄成一个列表,存在一个文件里,以及塞入多线程(一次跑x个视频)
对于这里需要注意 程序的命名问题 跑单例的时候验证码就存1.jpg, 1.png就行 如果多线程就会阻塞 所有线程都叫1.jpg了 所有需要弄个uuid这种唯一字段作为图片名,同时做好删除和数据存储的命名问题。
import random
import uuid
from selenium import webdriver
import time
import json
from threading import Thread
import requests
import re
from lxml import etree
import datetime
import os
from tiktok_spider.check_Code import checkCode
from tiktok_spider.tt_getComment import get_comment
def drop_down(b, img_file1, img_file2):
checkCode(b, img_file1, img_file2)
num = b.find_element_by_xpath(
'//*[@id="root"]/div/div[2]/div/div/div[4]/div[1]/div[1]/div[1]/span').text
for x in range(1, int(int(num) / 9), 1):
time.sleep(2)
j = x * 3
js = 'document.documentElement.scrollTop=document.documentElement.scrollHeight* %f' % j
b.execute_script(js)
# 先分析页面 找到用户主页
# 尝试用selenium访问 一发请求就有一个滑块验证码 手动过掉
def getUserPage(b,url,path):
b.get(url)
time.sleep(3)
img1 = str(uuid.uuid1()) + '.jpeg'
img2 = str(uuid.uuid1()) + '.png'
drop_down(b, img1, img2)
time.sleep(1)
if os.path.exists(img1):
os.remove(img1)
if os.path.exists(img2):
os.remove(img2)
lis = b.find_elements_by_xpath('//*[@id="root"]/div/div[2]/div/div/div[4]/div[1]/div[2]/ul/li/a')
fp = open(path, 'w', encoding='utf-8')
# url_list=[]
for li in lis:
href = li.get_attribute('href')
# print(href)
fp.write(href + ',\n')
# url_list.append(href)
fp.close()
print('视频地址采集完成!数据存储在%s' % fp)
b.quit()
if __name__ == '__main__':
scale = 1.8
chrome_d = "C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe"
b = webdriver.Chrome(executable_path=chrome_d)
b.maximize_window()
# url = 'https://www.douyin.com/user/MS4wLjABAAAAJ_nEAirFKdd5UrdKdQstsksaV_JNJBxu0_qq2R4QpBY'
url='https://www.douyin.com/user/MS4wLjABAAAAIkUGvJjhqY2IV6W_Tkht31LnogAFWBF2MBkEEbvAtnQ'
this = os.getcwd() # 获取当前路径
ti = 'tiktok_video_url-%s.txt' % str(datetime.datetime.now().date()) # 获取时间拼接字符串作为文件名
path = os.path.join(this, ti) # 吧两段拼成文件存储路径
print("获取所有视频url:")
# getUserPage(b, url,path) #
result = []
with open(path, 'r') as f:
for line in f:
result.append(str(line.strip(',\n').split(',')[0]))
T = []
# for url in result:
# print("当前爬取",url)
# # getComment(b, url)
# #需要设置一个代理ip 设置一个get ip 方法 线程跑的时候try 如果ip问题调用外面的方法获得新的ip继续跑
# #传入一个账号 打开浏览器后用账号 request登录 拿到cookie 放入selenium中
# t = Thread(target=get_comment, args=(url,))
# t.start()
# T.append(t)
# # break
for i in range(1,3): #len(result)
print("加入线程:", result[i])
# getComment(b, url)
# 需要设置一个代理ip 设置一个get ip 方法 线程跑的时候try 如果ip问题调用外面的方法获得新的ip继续跑
# 传入一个账号 打开浏览器后用账号 request登录 拿到cookie 放入selenium中
t = Thread(target=get_comment, args=(result[i],i,))
t.start()
T.append(t)
# break
for t in T:
# join等待线程结束
t.join()
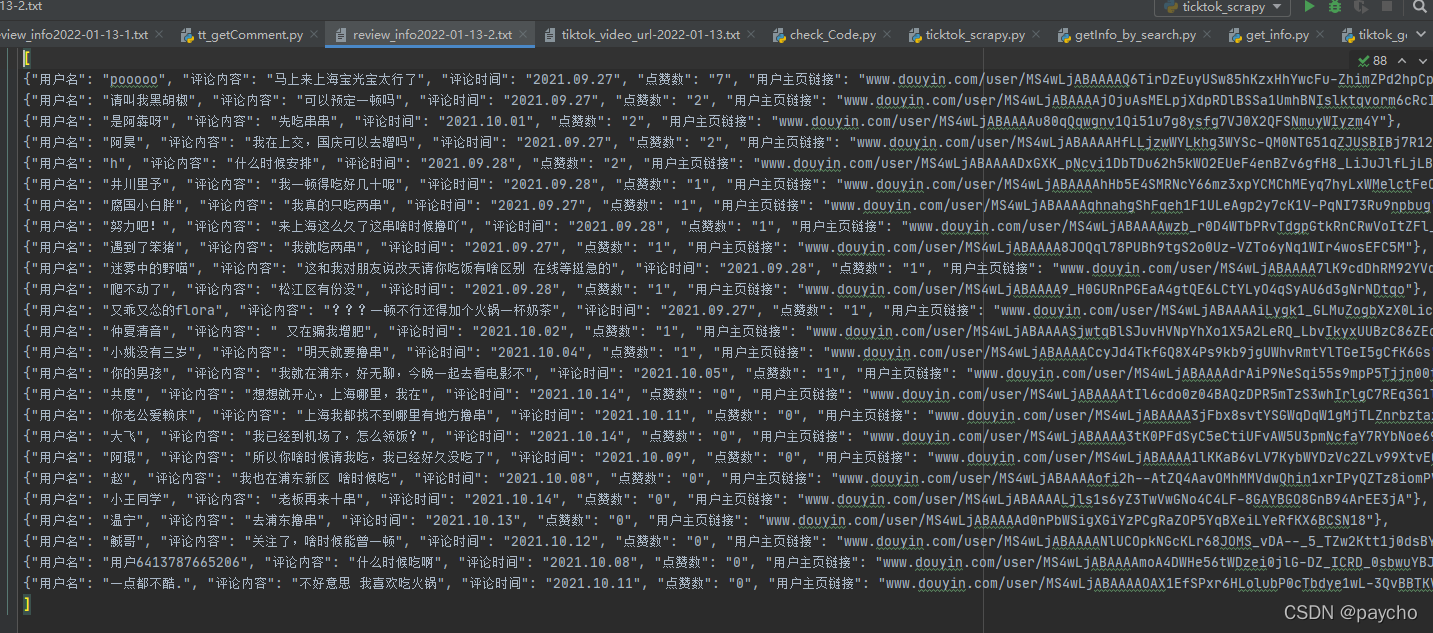
放一下爬取的数据,就是按视频顺序存储的,如果一天要爬多个人的就可以把这些文件内的数据直接入库,根据关键词-i或者用户名-i来存储。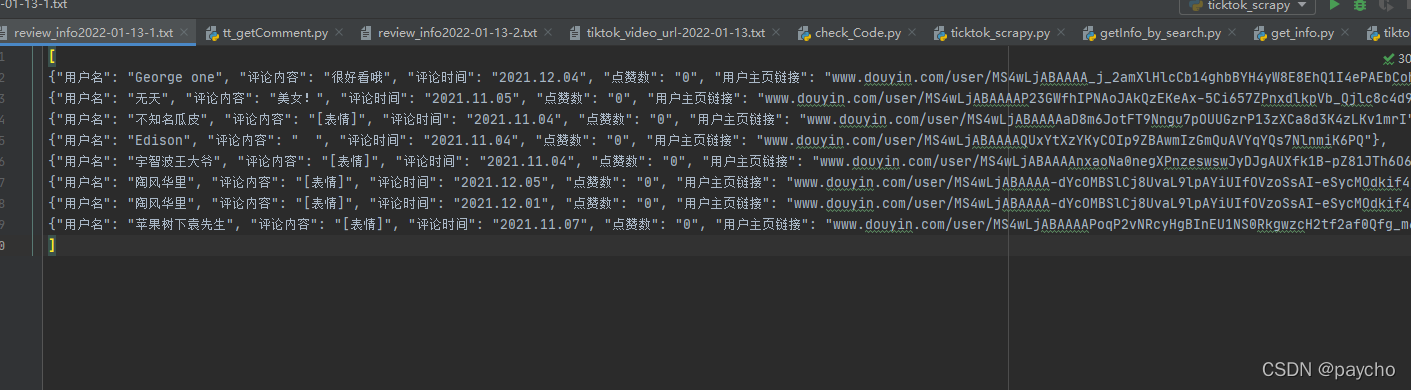
版权归原作者 陈虚渊 所有, 如有侵权,请联系我们删除。