

本文旨在收集整理ODPS开发中入门及进阶级知识,尽可能涵盖大多数ODPS开发问题,成为一本mini百科全书,后续也会持续更新。希望通过笔者的梳理和理解,帮助刚接触ODPS开发的同学快速上手。
本系列分为两部分:入门篇和进阶篇。
ODPS开发大全:入门篇

常用参数设置
常用的调整无外乎调整map、join、reduce的个数,map、join、reduce的内存大小。
以ODPS的参数设置为例,参数可能因版本不同而略有差异。
参数类型
具体使用
- Map设置
set odps.sql.mapper.cpu=100
作用:设置处理Map Task每个Instance的CPU数目,默认为100,在[50,800]之间调整。场景:某些任务如果特别耗计算资源的话,可以适当调整Cpu数目。对于大多数Sql任务来说,一般不需要调整Cpu个数的。
set odps.sql.mapper.memory=1024
作用:设定Map Task每个Instance的Memory大小,单位M,默认1024M,在[256,12288]之间调整。场景:当Map阶段的Instance有Writer Dumps时,可以适当的增加内存大小,减少Dumps所花的时间。
set odps.sql.mapper.merge.limit.size=64
作用:设定控制文件被合并的最大阈值,单位M,默认64M,在[0,Integer.MAX_VALUE]之间调整。场景:当Map端每个Instance读入的数据量不均匀时,可以通过设置这个变量值进行小文件的合并,使得每个Instance的读入文件均匀。一般会和odps.sql.mapper.split.size这个参数结合使用。
set odps.sql.mapper.split.size=256
作用:设定一个Map的最大数据输入量,可以通过设置这个变量达到对Map端输入的控制,单位M,默认256M,在[1,Integer.MAX_VALUE]之间调整。场景:当每个Map Instance处理的数据量比较大,时间比较长,并且没有发生长尾时,可以适当调小这个参数。如果有发生长尾,则结合odps.sql.mapper.merge.limit.size这个参数设置每个Map的输入数量。
- Join设置
set odps.sql.joiner.instances=-1
作用: 设定Join Task的Instance数量,默认为-1,在[0,2000]之间调整。不走HBO优化时,ODPS能够自动设定的最大值为1111,手动设定的最大值为2000,走HBO时可以超过2000。场景:每个Join Instance处理的数据量比较大,耗时较长,没有发生长尾,可以考虑增大使用这个参数。
set odps.sql.joiner.cpu=100
作用: 设定Join Task每个Instance的CPU数目,默认为100,在[50,800]之间调整。场景:某些任务如果特别耗计算资源的话,可以适当调整CPU数目。对于大多数SQL任务来说,一般不需要调整CPU。
set odps.sql.joiner.memory=1024
作用:设定Join Task每个Instance的Memory大小,单位为M,默认为1024M,在[256,12288]之间调整。场景:当Join阶段的Instance有Writer Dumps时,可以适当的增加内存大小,减少Dumps所花的时间。
- Reduce设置
set odps.sql.reducer.instances=-1
作用: 设定Reduce Task的Instance数量,手动设置区间在[1,99999]之间调整。不走HBO优化时,ODPS能够自动设定的最大值为1111,手动设定的最大值为99999,走HBO优化时可以超过99999。场景:每个Join Instance处理的数据量比较大,耗时较长,没有发生长尾,可以考虑增大使用这个参数。
set odps.sql.reducer.cpu=100
作用:设定处理Reduce Task每个Instance的Cpu数目,默认为100,在[50,800]之间调整。场景:某些任务如果特别耗计算资源的话,可以适当调整Cpu数目。对于大多数Sql任务来说,一般不需要调整Cpu。
set odps.sql.reducer.memory=1024
作用:设定Reduce Task每个Instance的Memory大小,单位M,默认1024M,在[256,12288]之间调整。场景:当Reduce阶段的Instance有Writer Dumps时,可以适当的增加内存的大小,减少Dumps所花的时间。
上面这些参数虽然好用,但是也过于简单暴力,可能会对集群产生一定的压力。特别是在集群整体资源紧张的情况下,增加资源的方法可能得不到应有的效果,随着资源的增大,等待资源的时间变长的风险也随之增加,导致效果不好!因此请合理的使用资源参数!
- 小文件合并参数
set odps.merge.cross.paths=true|false
作用:设置是否跨路径合并,对于表下面有多个分区的情况,合并过程会将多个分区生成独立的Merge Action进行合并,所以对于odps.merge.cross.paths设置为true,并不会改变路径个数,只是分别去合并每个路径下的小文件。
set odps.merge.smallfile.filesize.threshold = 64
作用:设置合并文件的小文件大小阀值,文件大小超过该阀值,则不进行合并,单位为M,可以不设,不设时,则使用全局变量odps_g_merge_filesize_threshold,该值默认为32M,设置时必须大于32M。
set odps.merge.maxmerged.filesize.threshold = 256
作用:设置合并输出文件量的大小,输出文件大于该阀值,则创建新的输出文件,单位为M,可以不设,不设时,则使用全局变odps_g_max_merged_filesize_threshold,该值默认为256M,设置时必须大于256M。
set odps.merge.max.filenumber.per.instance = 10000
作用:设置合并Fuxi Job的单个Instance允许合并的小文件个数,控制合并并行的Fuxi Instance数,可以不设,不设时,则使用全局变量odps_g_merge_files_per_instance,该值默认为100,在一个Merge任务中,需要的Fuxi Instance个数至少为该目录下面的总文件个数除以该限制。
set odps.merge.max.filenumber.per.job = 10000
作用:设置合并最大的小文件个数,小文件数量超过该限制,则超过限制部分的文件忽略,不进行合并,可以不设,不设时,则使用全局变量odps_g_max_merge_files,该值默认为10000。
- UDF相关参数
set odps.sql.udf.jvm.memory=1024
作用: 设定UDF JVM Heap使用的最大内存,单位M,默认1024M,在[256,12288]之间调整。场景:某些UDF在内存计算、排序的数据量比较大时,会报内存溢出错误,这时候可以调大该参数,不过这个方法只能暂时缓解,还是需要从业务上去优化。
set odps.sql.udf.timeout=1800
作用:设置UDF超时时间,默认为1800秒,单位秒。[0,3600]之间调整。
set odps.sql.udf.python.memory=256
作用:设定UDF python 使用的最大内存,单位M,默认256M。[64,3072]之间调整。
set odps.sql.udf.optimize.reuse=true/false
作用:开启后,相同的UDF函数表达式,只计算一次,可以提高性能,默认为True。
set odps.sql.udf.strict.mode=false/true
作用:True为金融模式,False为淘宝模式,控制有些函数在遇到脏数据时是返回NULL还是抛异常,True是抛出异常,False是返回null。
- Mapjoin设置
set odps.sql.mapjoin.memory.max=512
作用:设置Mapjoin时小表的最大内存,默认512,单位M,[128,2048]之间调整。
- 动态分区设置
set odps.sql.reshuffle.dynamicpt=true/false
作用:默认true,用于避免拆分动态分区时产生过多小文件。如果生成的动态分区个数只会是很少几个,设为false避免数据倾斜。
- 数据倾斜设置
set odps.sql.groupby.skewindata=true/false
作用:开启Group By优化。
set odps.sql.skewjoin=true/false
作用:开启Join优化,必须设置odps.sql.skewinfo 才有效。
常用内建函数
常用内建函数大概分为这几类,这边我们挑选一些重点的函数进行说明。
函数类型
说明
日期函数
支持处理DATE、DATETIME、TIMESTAMP等日期类型数据,实现加减日期、计算日期差值、提取日期字段、获取当前时间、转换日期格式等业务处理能力。
数学函数
支持处理BIGINT、DOUBLE、DECIMAL、FLOAT等数值类型数据,实现转换进制、数学运算、四舍五入、获取随机数等业务处理能力。
窗口函数
支持在指定的开窗列中,实现求和、求最大最小值、求平均值、求中间值、数值排序、数值偏移、抽样等业务处理能力。
聚合函数
支持将多条输入记录聚合成一条输出值,实现求和、求平均值、求最大最小值、求平均值、参数聚合、字符串连接等业务处理能力。
字符串函数
支持处理STRING类型字符串,实现截取字符串、替换字符串、查找字符串、转换大小写、转换字符串格式等业务处理能力。
复杂类型函数
支持处理MAP、ARRAY、STRUCT及JSON类型数据,实现去重元素、聚合元素、元素排序、合并元素等业务处理能力。
加密函数
支持处理STRING、BINARY类型的表数据,实现加密、解密等业务处理能力。
其他函数
除上述函数之外,提供支持其他业务场景的函数。
▐** **日期函数
函数名
具体操作
- 获取当前日期7天内的日期:
SELECTDATEADD(GETDATE(),-7,'dd');
TO_CHAR(DATEADD(GETDATE(),-7,'dd'),'yyyymmdd');
- DATEADD(指定日期加减):
SELECT DATEADD(GETDATE(),1,"dd"); //2021-01-09 10:48:40 GETDATE()返回值是2021-01-08 10:48:40
SELECT DATEADD(GETDATE(),1,"mm");//2021-02-08 10:49:24 GETDATE()返回值是2021-01-08 10:49:24
- DATEDIFF(计算两个日期的差值):
datediff(end, start, 'dd') = 1
datediff(end, start, 'mm') = 1
datediff(end, start, 'yyyy') = 1
datediff(end, start, 'hh') = 1
- DATEPART(返回指定日期的年/月/日):
SELECT DATEPART(GETDATE(),'mm');
SELECT DATEPART(GETDATE(),'yyyy');
SELECT DATEPART(GETDATE(),'dd');
SELECT DATEPART(GETDATE(),'hh');
- DATETRUNC(截取时间):
datetrunc(datetime '2011-12-07 16:28:46', 'yyyy') = 2011-01-01 00:00:00
datetrunc(datetime '2011-12-07 16:28:46', 'month') = 2011-12-01 00:00:00
datetrunc(datetime '2011-12-07 16:28:46', 'DD') = 2011-12-07 00:00:00
- TO_CHAR 函数
使用方式 to_char(要处理的日期,日期格式)
推荐用法:2018-01-11 10:00:00 格式 ,处理为指定格式的日期字符串
效果:处理为yyyymmdd的日期格式,类型为字符串
to_char('2018-01-11 10:00:00','yyyymmdd') as date_3
to_char('2018-01-11 10:00:00','yyyymmdd hh:mi:ss') as date_5
to_char('2018-01-11 10:00:00','yyyy-mm-dd hh:mi:ss') as date_6
to_char('2018-01-11 10:00:00','yyyy-mm-dd 00:00:00') as date_8
to_char('2018-01-11 10:00:00','yyyy-mm-01 23:59:59') as date_9
- TO_DATE函数
使用方式:to_date(datetime,format)
推荐用法:根据时间的格式,适当调整format的模版
效果:处理20180111、2018-01-11、2018-01-11 10:00:00
to_char('2018-01-11 10:00:00','yyyymmdd') as date_3
to_char('2018-01-11 10:00:00','yyyymmdd hh:mi:ss') as date_5
to_char('2018-01-11 10:00:00','yyyy-mm-dd hh:mi:ss') as date_6
to_char('2018-01-11 10:00:00','yyyy-mm-dd 00:00:00') as date_8
- UNIX时间戳转换
函数:datetime from_unixtime(bigint unixtime) 支持秒
from_unixtime(123456789) = 1973-11-30 05:33:09
函数: from_utc_timestamp(bigint unixtime,string timezone) 支持毫秒
SELECT from_utc_timestamp(1501557840000 ,'GMT') ;
--返回:2017-08-01 04:24:00
- DATE转UNIX时间戳
函数:bigint unix_timestamp(datetime date)
select unix_timestamp(datetime '2019-09-20 01:00:00');
--返回1568912400
select unix_timestamp('2019-09-20 01:00:00');
--返回1568912400
▐** **字符串函数
函数1. SPLIT
场景:将字符串列按照分隔符(支持正则表达式)分割后返回数组。
split(str, pat)
例子:
split("浙江省-杭州市-余杭区", "-") 返回["浙江省", "杭州市", "余杭区"]
如果需要解析出杭州市,加上index即可,split("浙江省-杭州市-余杭区", "-")[1],下标从0开始计数。
函数2. SPLIT_PART
场景:将字符串按照分隔符分割,返回指定的子串。
string split_part(string str, string separator, bigint start[, bigint end])
例子:
split_part("浙江省-杭州市-余杭区", "-", 2) 返回"杭州市", start从1开始
split_part("浙江省-杭州市-余杭区", "-", 1, 2) 返回"浙江省-杭州市"
函数3. KEYVALUE
场景:将字符串按照key、value分隔符分割,返回指定key的value
KEYVALUE(STRING srcStr,STRING split1,STRING split2, STRING key)
KEYVALUE(STRING srcStr, STRING key) //默认split1 = ";",默认split2 = ":"
例子:
keyvalue("sendFlag_pass:20,sendFlag_benefit:30", "," , ":", "sendFlag_pass") 返回20
函数4. STR_TO_MAP
场景:跟KEYVALUE类似,将字符串按照key、value分隔符分割,返回一个map
str_to_map(text [, delimiter1 [, delimiter2]])
delimiter1 默认为 ","
delimiter2 默认为 "="
例子:
str_to_map("sendFlag_pass:20,sendFlag_benefit:30", "," , ":") 返回map
str_to_map("sendFlag_pass:20,sendFlag_benefit:30", "," , ":")["sendFlag_pass"], 返回sendFlag_pass的值20
函数5. REGEXP_REPLACE
场景:将字符串中的某些字符根据正则表达式进行替换,替换成""则相当于删除。
string regexp_replace(string source, string pattern, string replace_string[, bigint occurrence])
例子:需要将msg_id中的方括号去掉,然后再一列转多行处理
regexp_replace(msg_id, "\[|\]", "") as msg_id
函数6. GET_JSON_OBJECT
场景:解析json格式字符串,返回指定key对应的value
STRING GET_JSON_OBJECT(STRING json,STRING path)
例子:
解析bizSuccess,则使用get_json_object(json, "$.bizSuccess"),返回true
解析totalCount,则使用get_json_object(json, "$.module.totalCount"),返回1,多层嵌套用.隔开
函数7. JSON_TUPLE
场景:get_json_object增强版,解析json格式字符串,返回指定多个key对应的value
STRING JSON_TUPLE(STRING json,STRING key1,STRING key2,...)
例子:
json_tuple(json, "module.object[*].activityId") 返回"[1310, 1314]"数组,然后可以使用regexp_replace去掉方括号进行处理。
函数8. CONCAT
场景:将多个字符串合并成一个字符串,如果有参数为NULL,则返回NULL
string concat(string a, string b...)
函数9. TRIM/LTRIM/RTRIM
场景:字符串预处理,去除字符串两边的空格,LTRIM去除左边的空格,RTRIM去除右边的空格
string trim(string str)
函数10. TOUPPER/TOLOWER
场景:字符串预处理,转大写/小写
string tolower(string source)
string toupper(string source)
自定义UDF开发
这一章节主要讲Java UDF的开发流程,大概分为这样几个步骤:
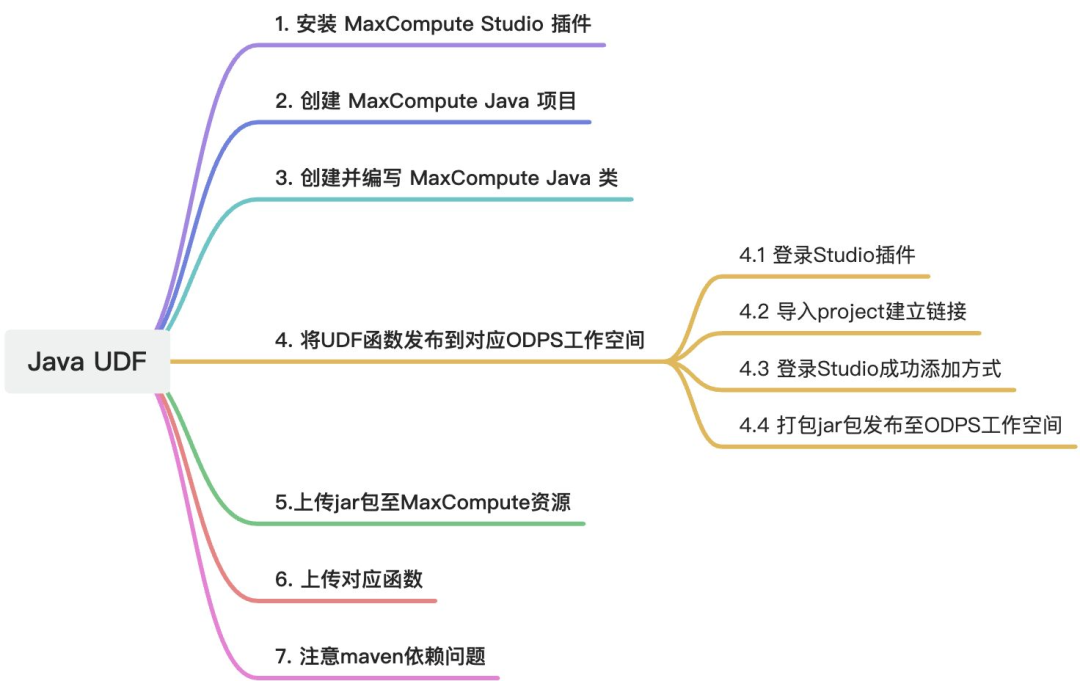
具体流程:
▐** 1. 安装MaxCompute Studio idea插件**
在IDEA中,打开settings设置,找到Plugins
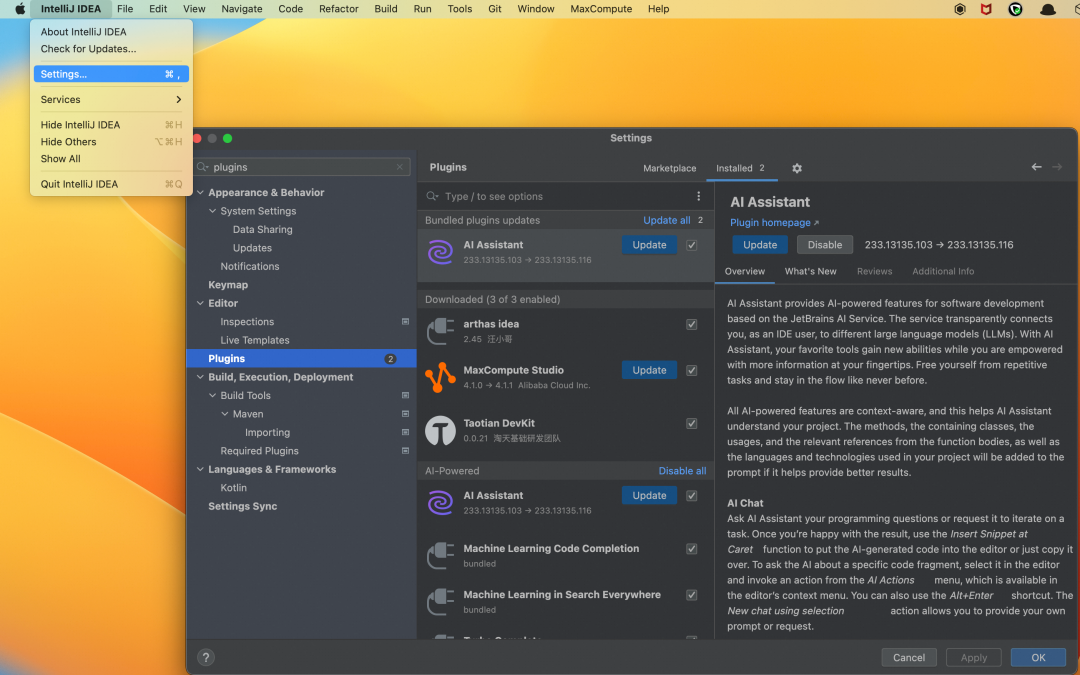
点开Mange Plugin Repositories,如图
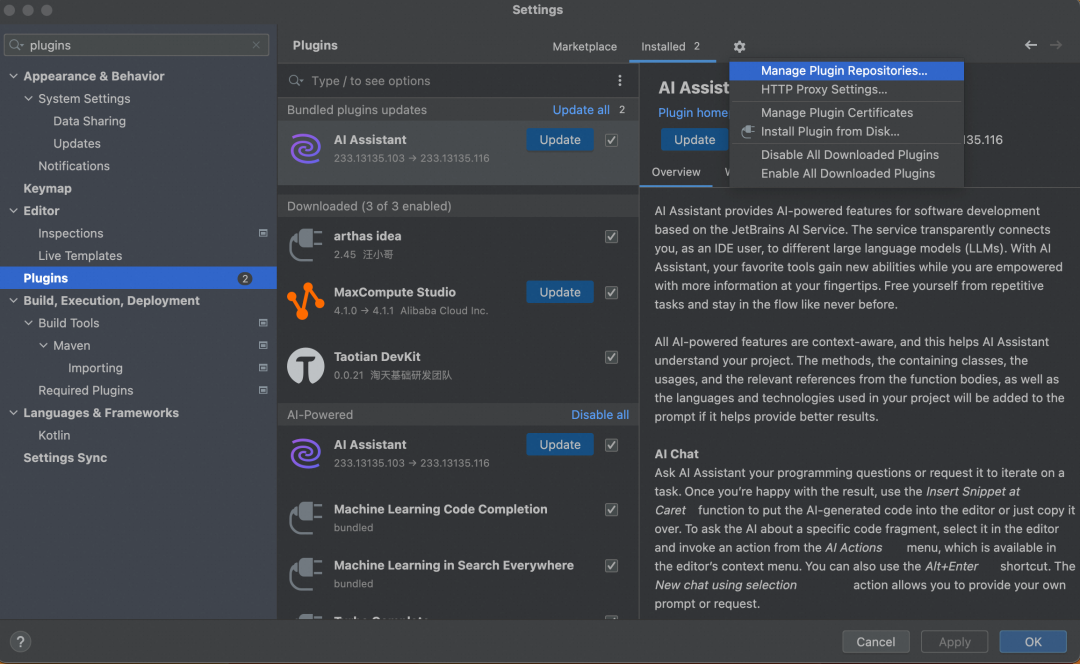
点击➕号,添加 http://odps.alibaba.net:8080/studio/updatePlugins.xml

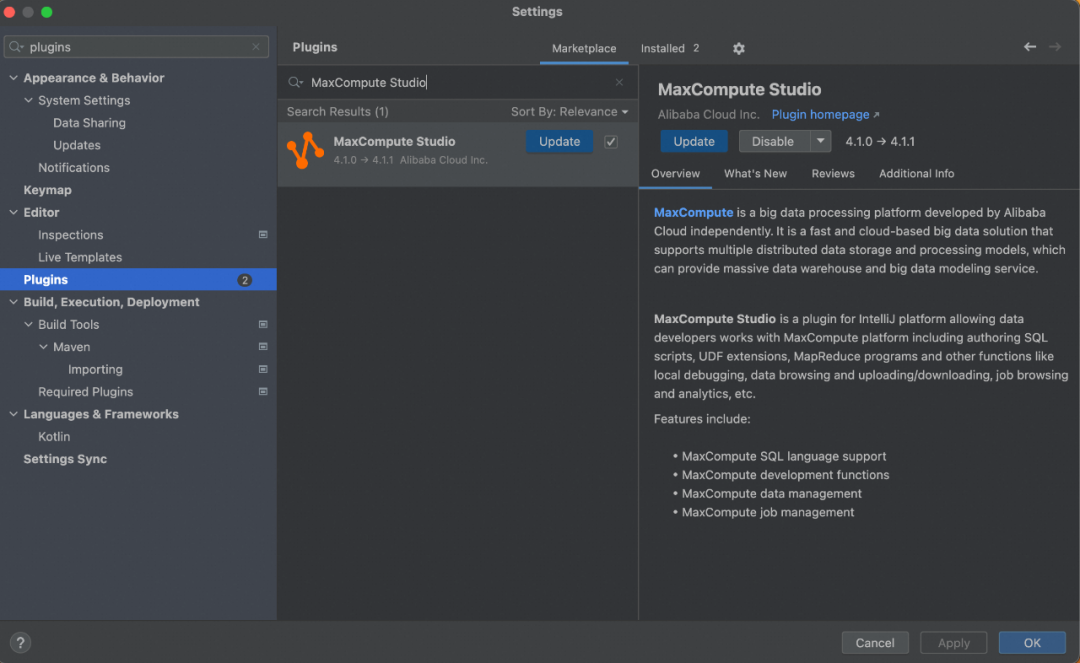
在Plugins marketplace里搜索MaxCompute Studio插件,安装并重启idea
▐** 2. 创建MaxCompute Java项目**
按默认继续创建,定好自己的project名
创建好的project如图:
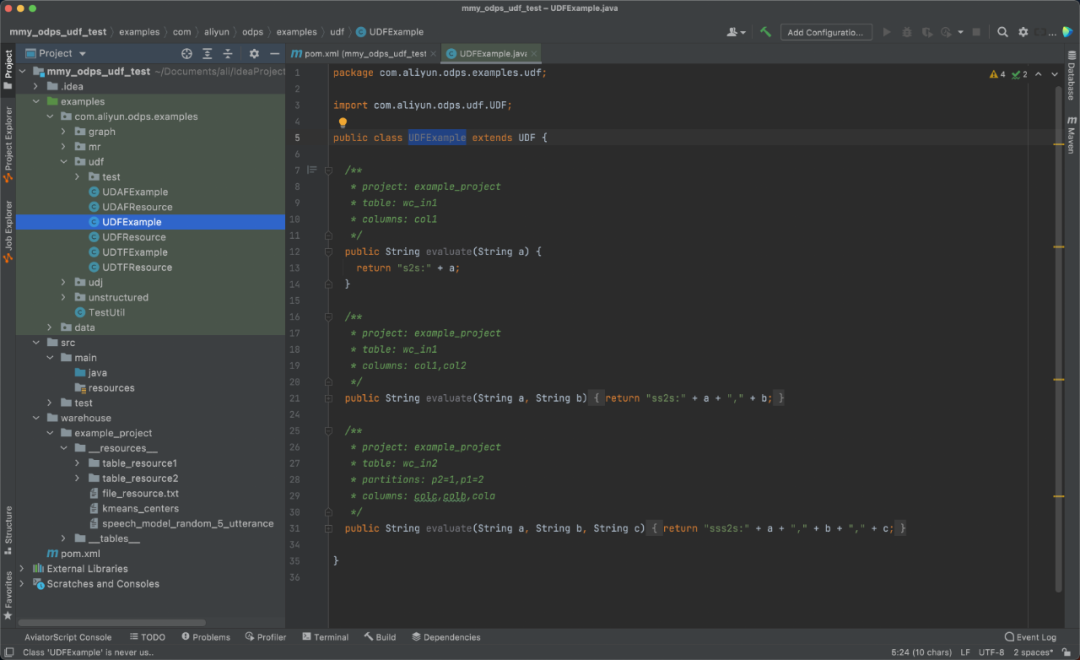
▐** 3. 创建并编写MaxCompute Java类**
在project中,选择目录src->java右击添加新类,选择MaxCompute Java
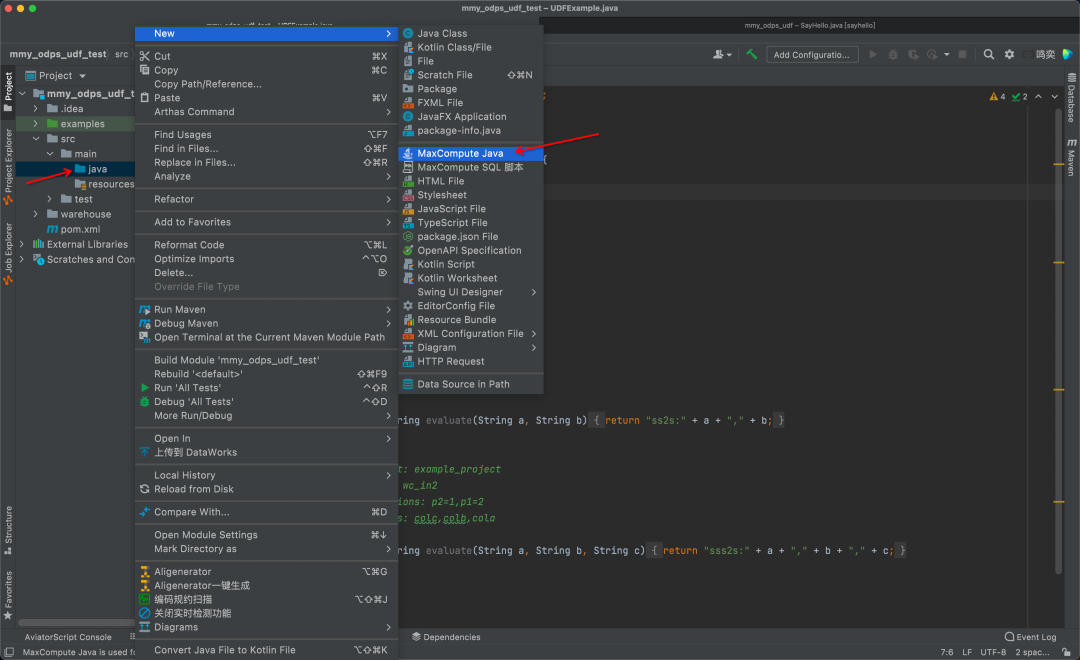
选择UDF
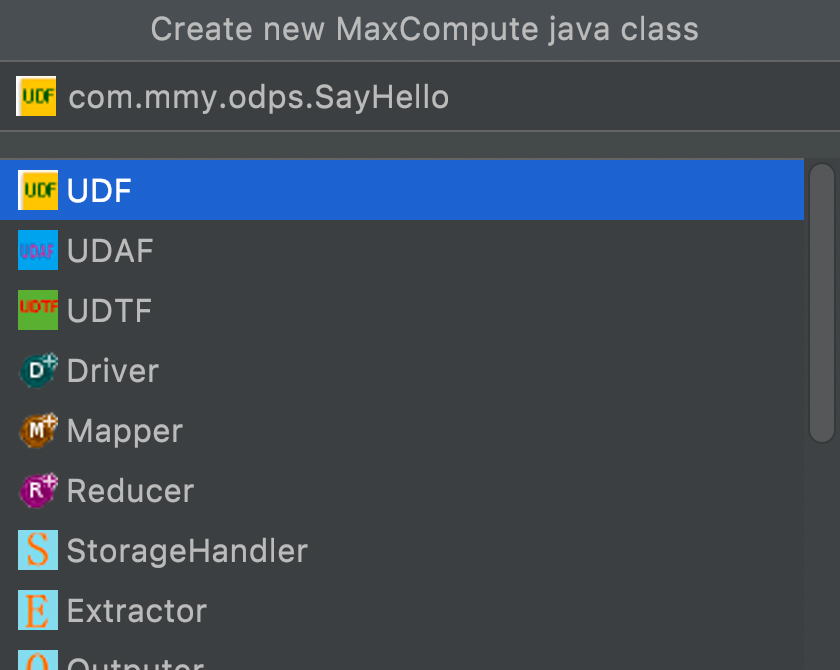
在此,可看到已经建好的UDF类,对其中的evaluate方法进行自定义编写(定义入参出参),并验证方法的正确性(添加Main方法进行自测)
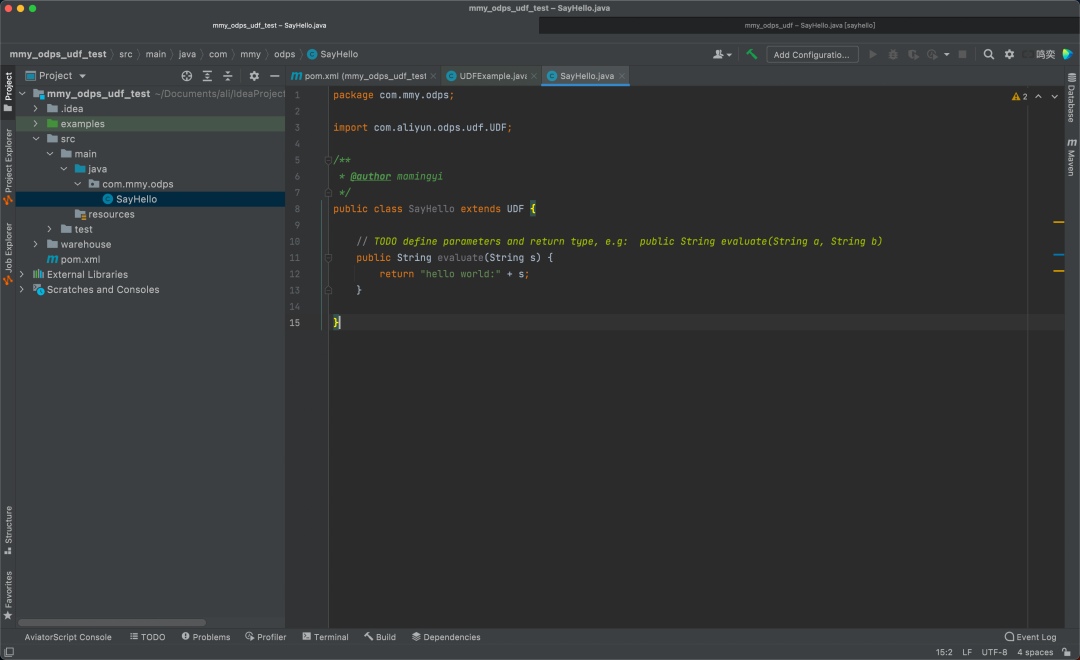
▐** 4. **将UDF函数发布到对应ODPS工作空间
首先,在idea上登陆个人账号
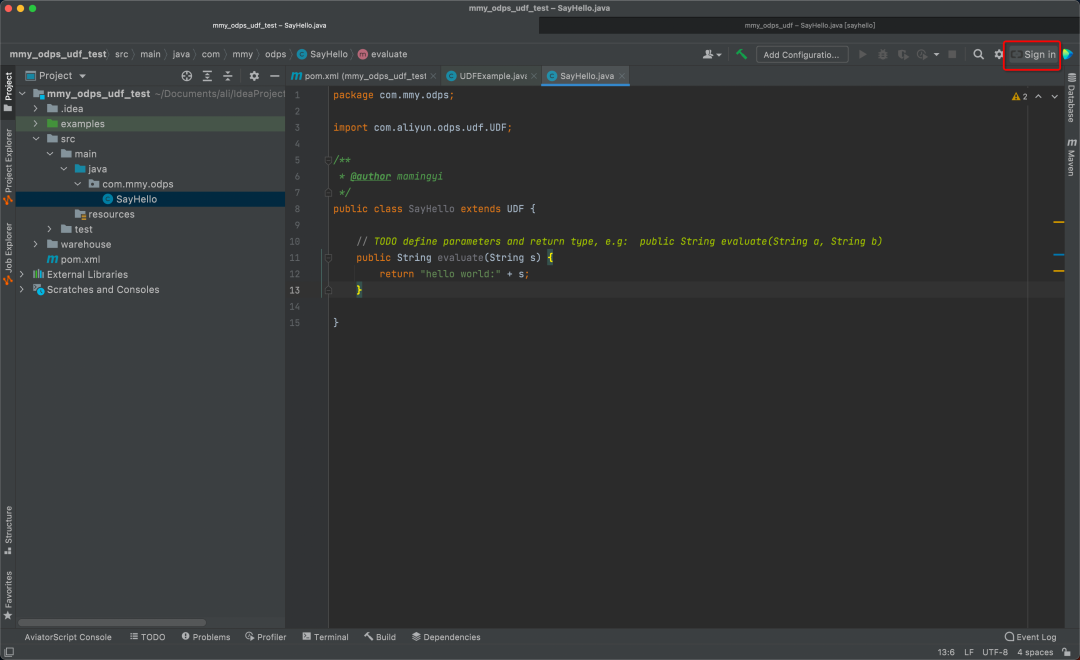
登陆成功后,可见到自己的花名
接下来导入project建立链接:
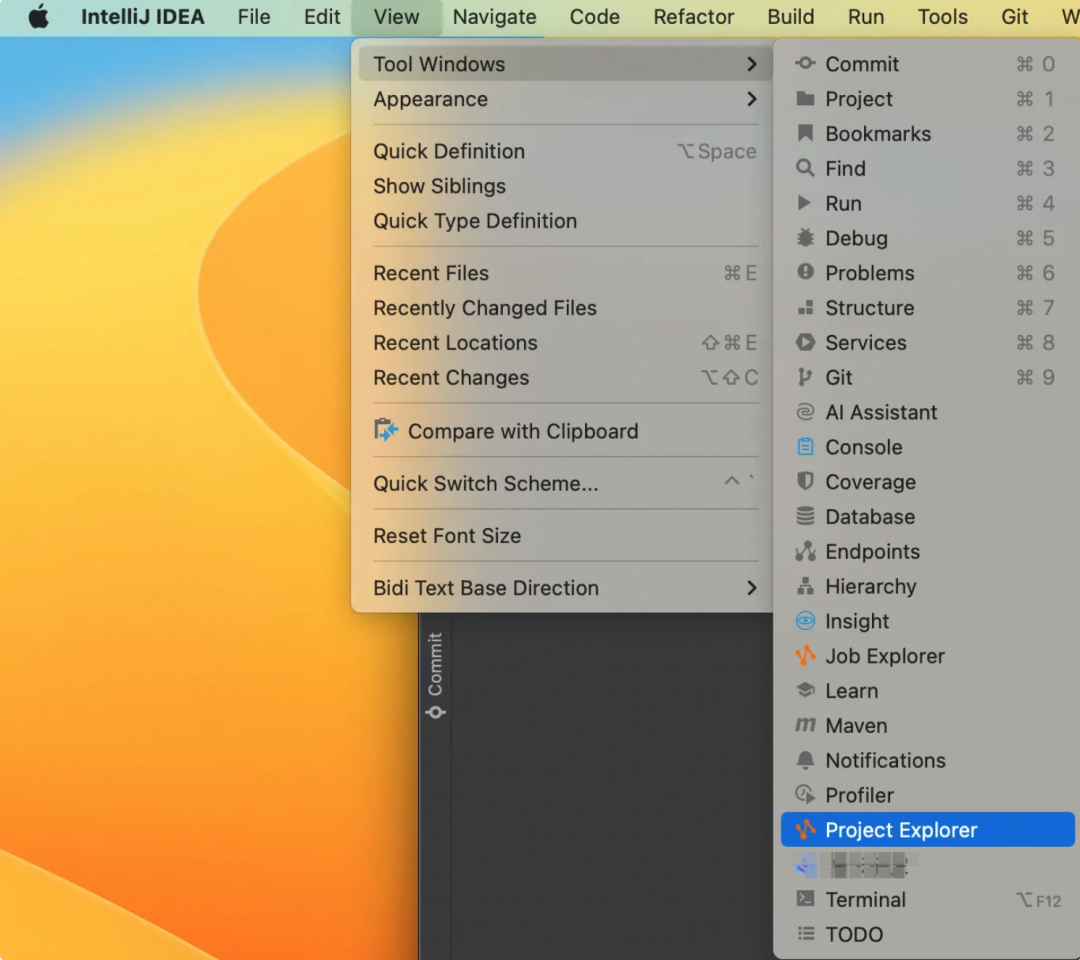
首先打开 Project Explorer, View->Tool Windows->Project Explorer
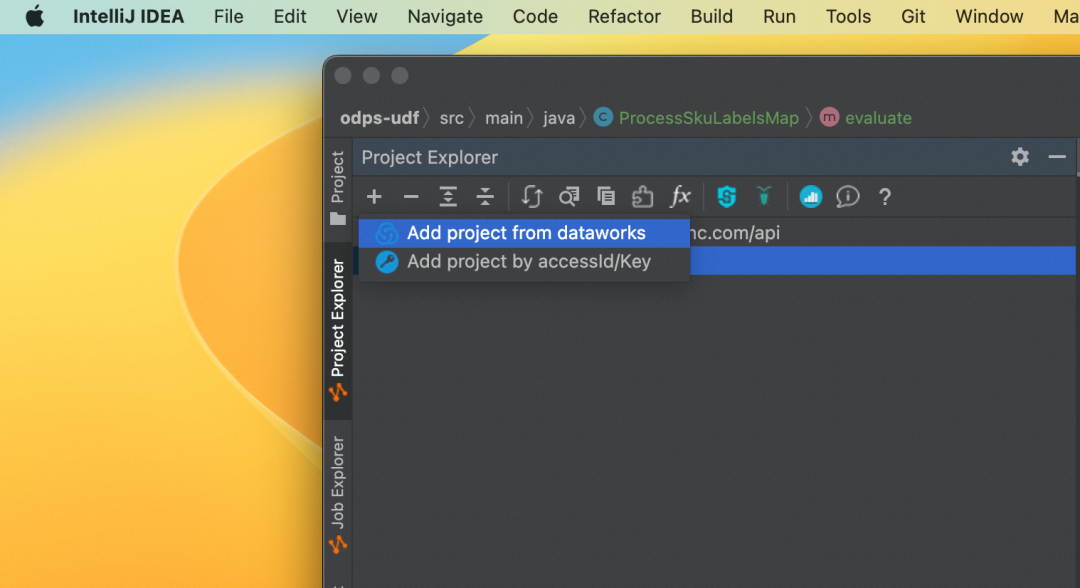
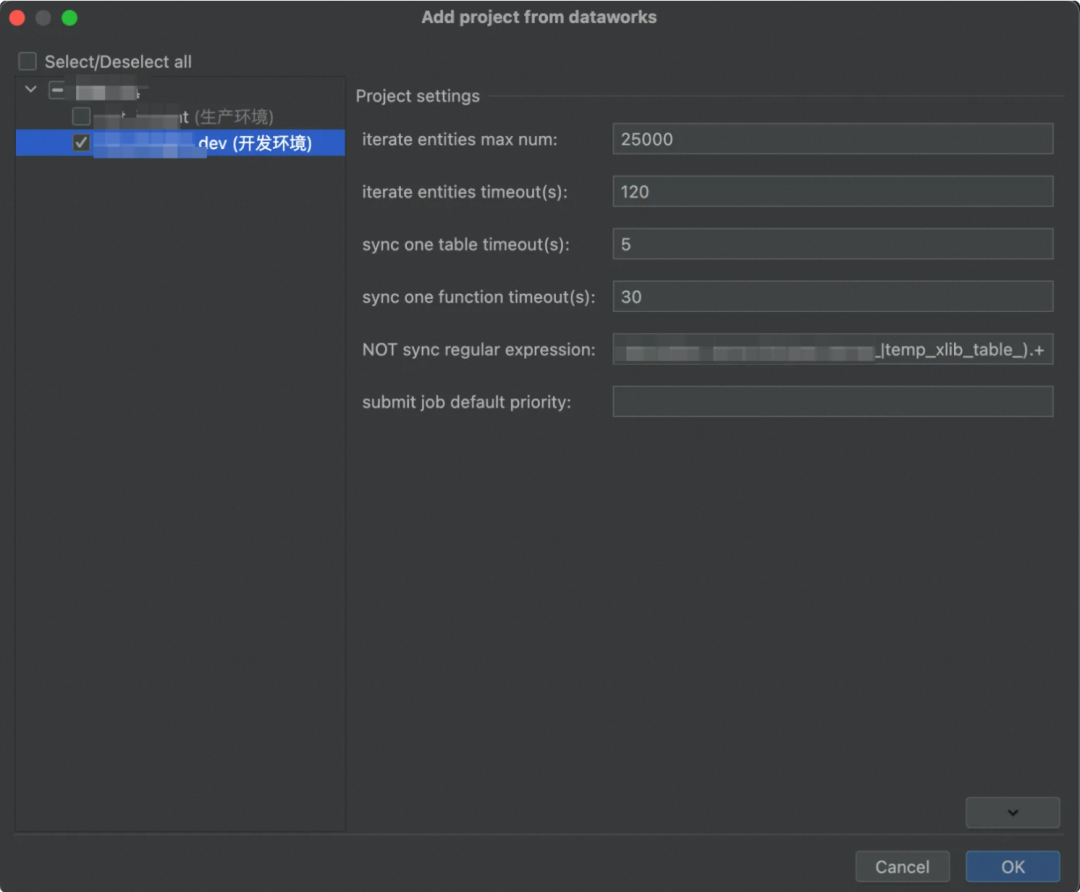
一般来说,选择添加开发环境即可;添加生产环境可能导致后续步骤没权限的问题。
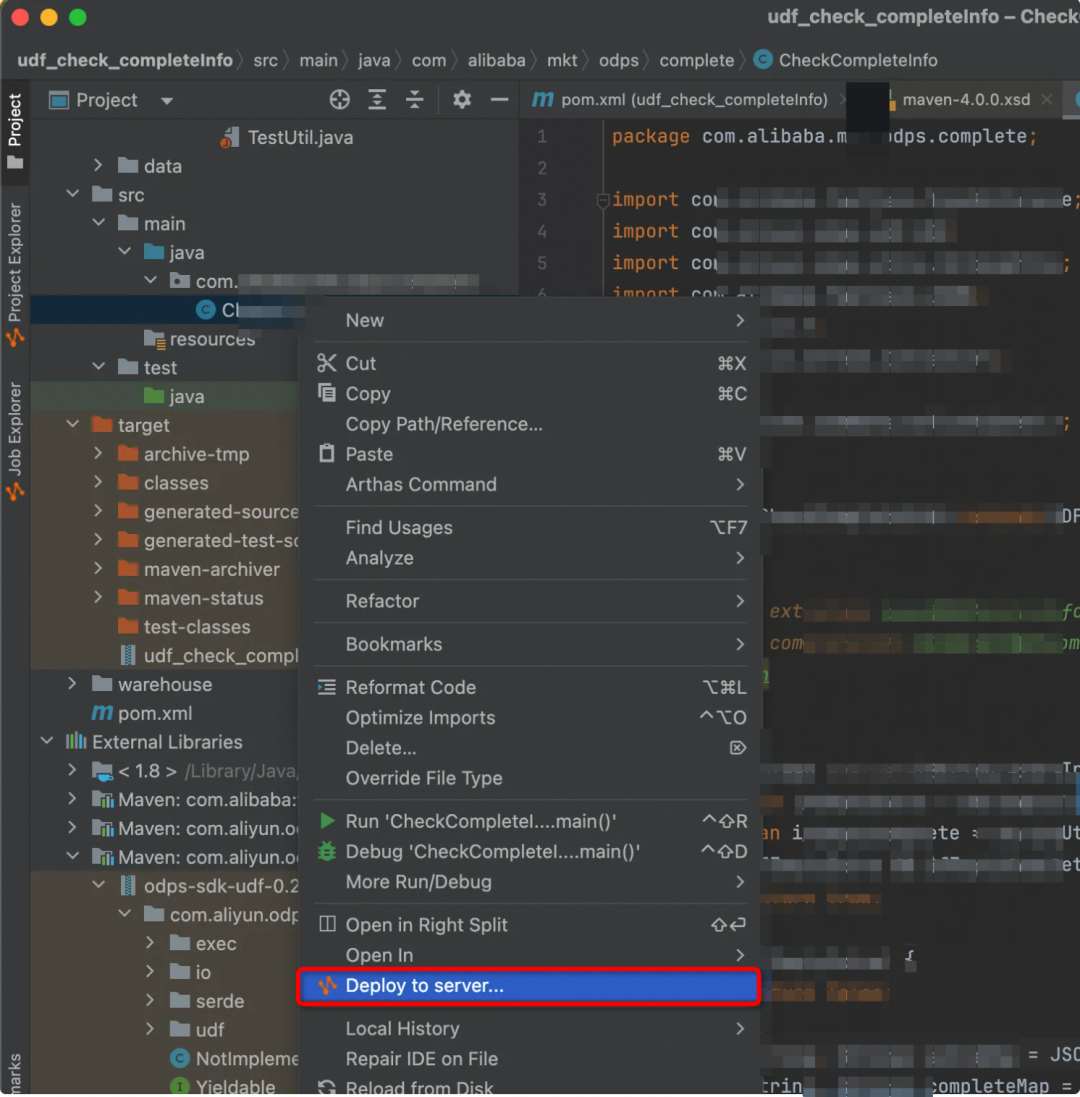
接着,我们将自己的项目打包成jar包
右击我们写好的类,选择Delply to server
填写好函数名,再点击 ok 即可
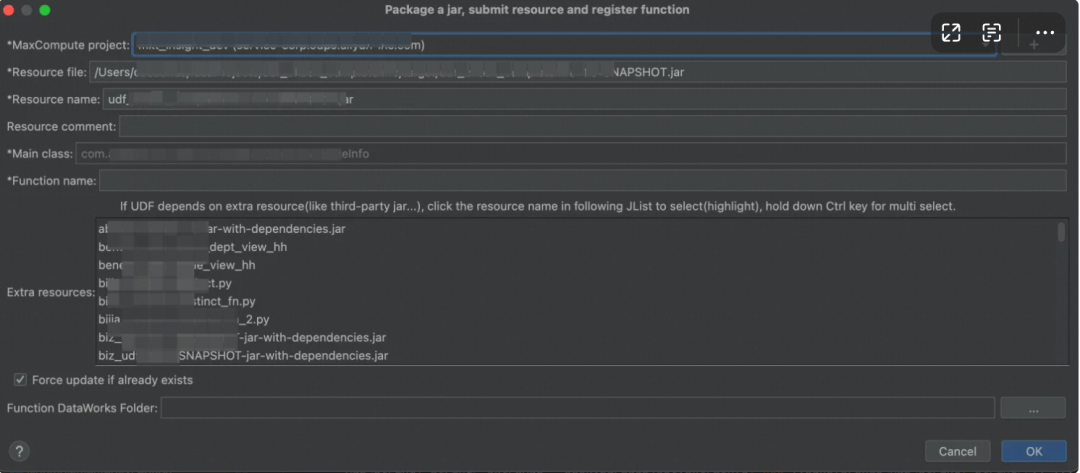
打包完成会有success的提示
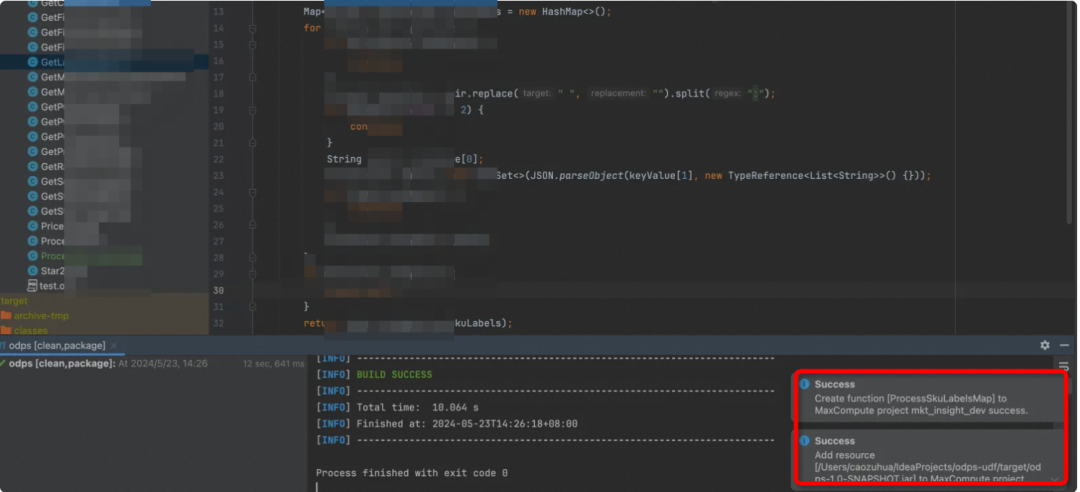
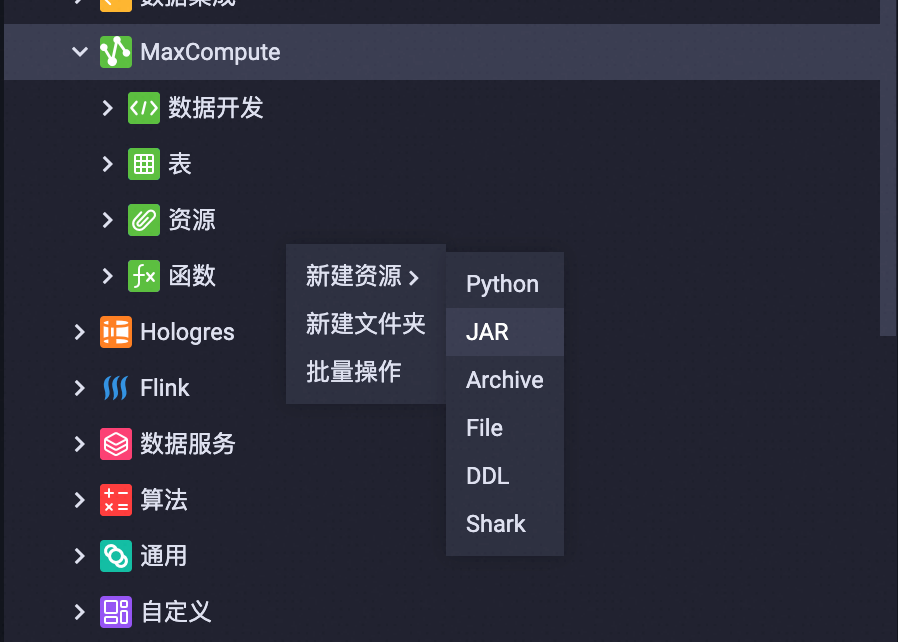
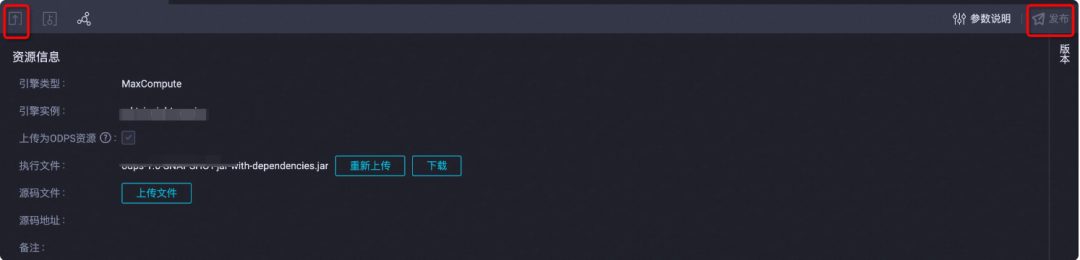
▐** 5. **上传jar包至MaxCompute资源
在自己项目ODPS空间中,MaxCompute -> 资源 -> JAR
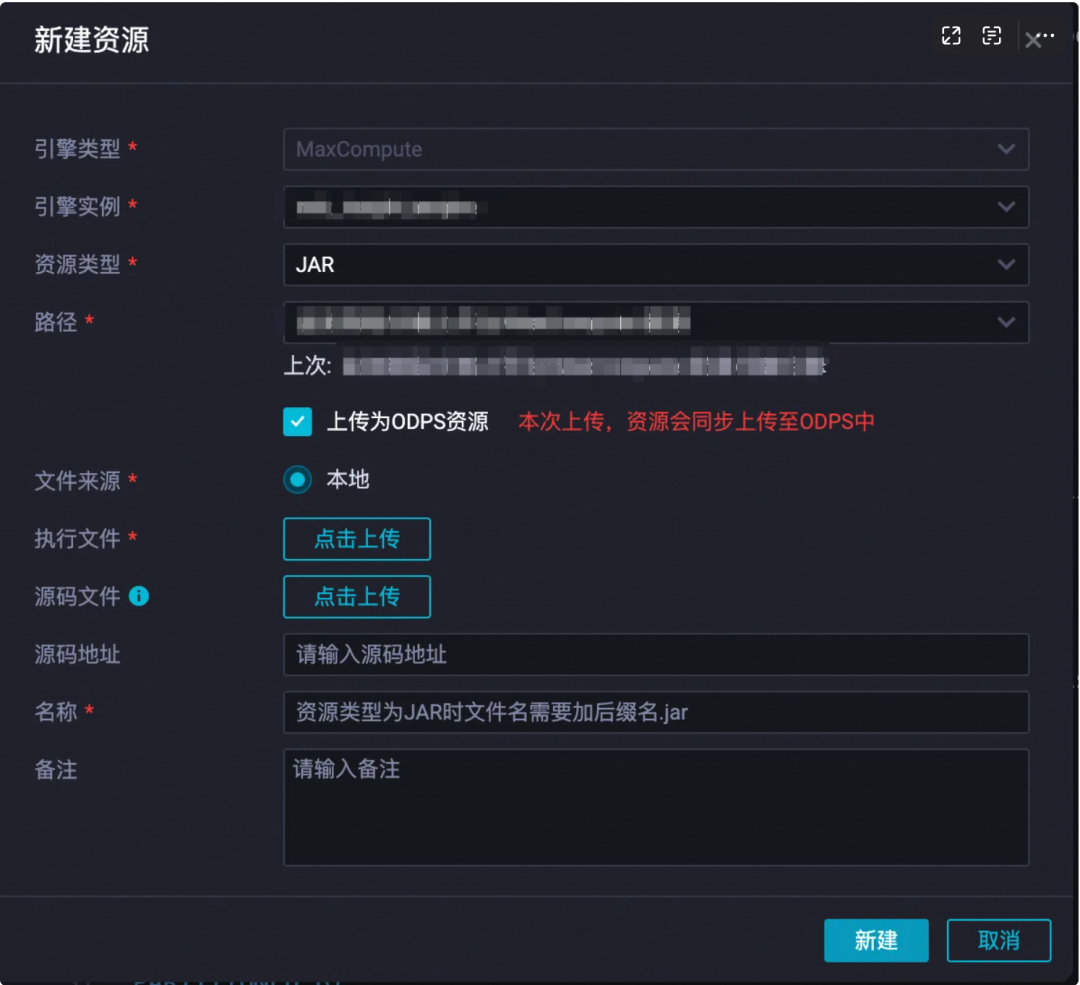
可自定义资源名称,并点击执行文件,进行上传
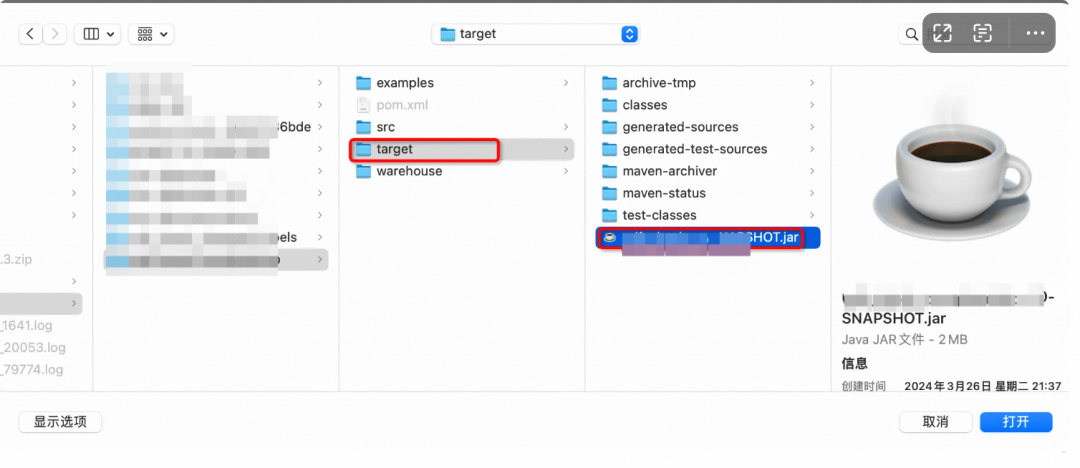
这里我们选择项目中 targert->xxx.jar 文件
最后,点击左上角提交资源,再点击右上角发布资源,即可
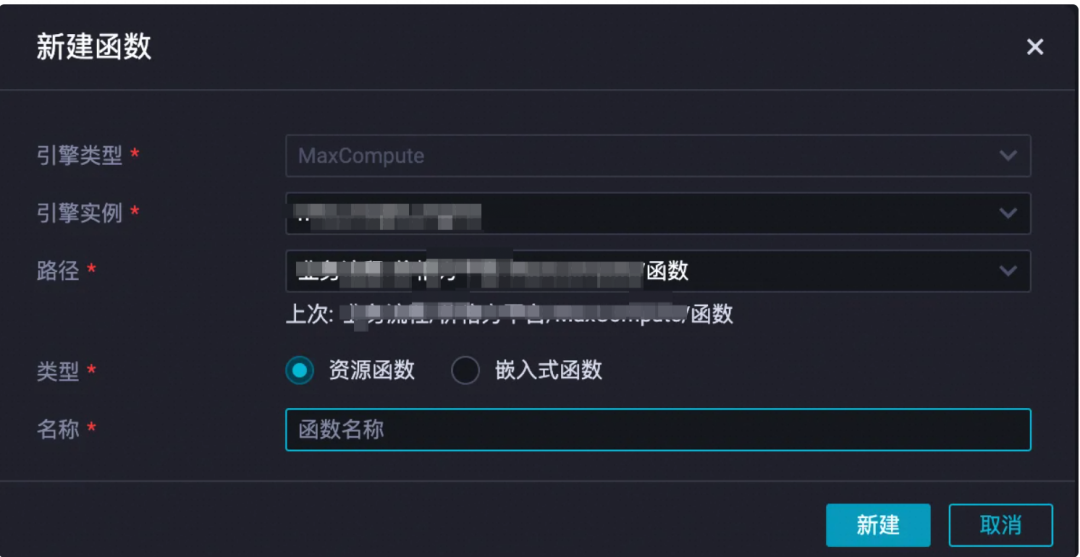
▐** 6. **上传对应函数
在自己项目ODPS空间中,MaxCompute->函数->新建函数

取好函数名称,点击新建
先从资源列表中,选择我们刚发布的资源,再点击提交➕发布
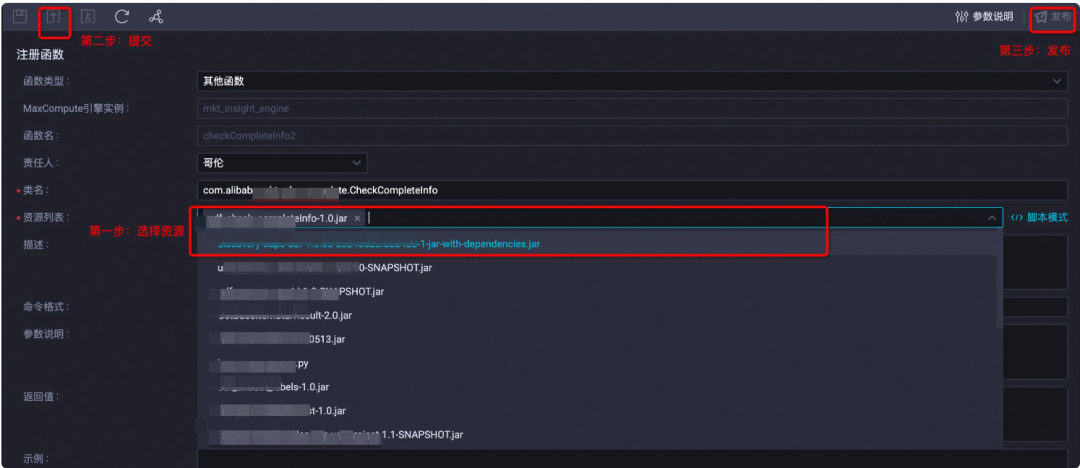
至此,UDF上传已经成功,我们就可以在自己的SQL中直接输入函数名称进行调用啦

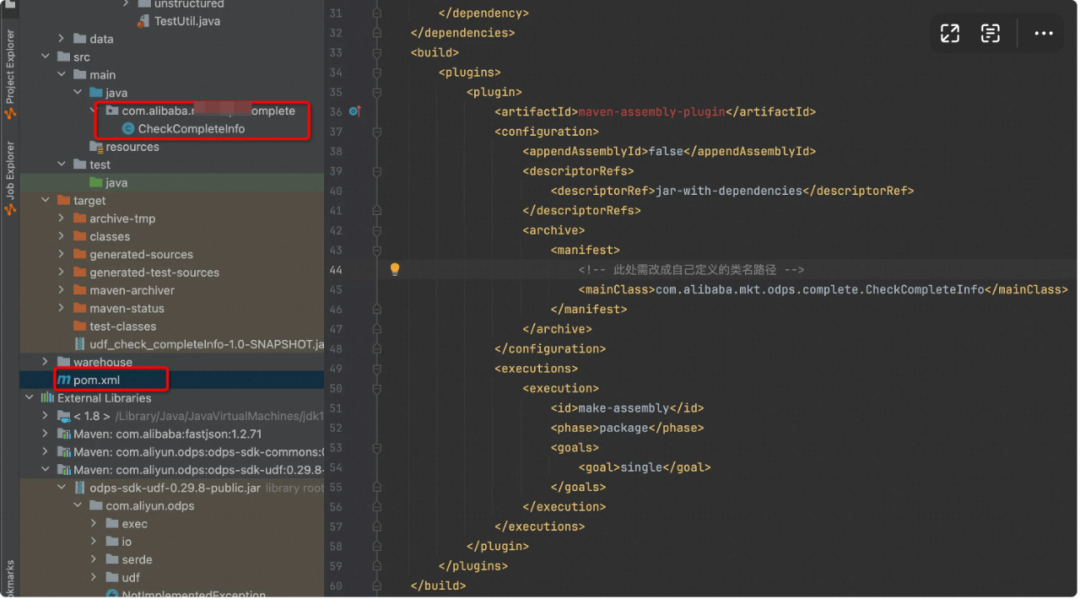
▐** 7. **注意maven依赖问题
当我们UDF需要依赖其他jar包时,比如fastJSON,需要把其他依赖包一起打包进来,否则上传至ODPS时会报错:java.lang.NoClassDefFoundError
此时需要在项目的pom.xml文件中,加入一段代码,即可将所有依赖一起打包,jar-with-dependencies
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<!-- 此处需改成自己定义的类名路径 -->
<mainClass>com.alibaba.mkt.odps.complete.CheckCompleteInfo</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>

拓展功能
▐** ****ODPS + SQL function **
在跑SQL时,我们可以将一些重复繁琐的过程抽象成函数。明确好入参和出参,写好方法后可进行验证。
例1:
问题背景:
字符串类型:对于所有的信息都存放在一个json串中,需要根据不同的key进行解析
初始代码
REPLACE(REPLACE(REPLACE(GET_JSON_OBJECT(json_data,'$.checkboxField_l1d6qn51'),'[\\\"',''),'\\\"]',''),'\\\"','')
改造成SQL函数
CREATE SQL FUNCTION if not exists get_json_object_checkboxField(@a STRING,@b STRING )
AS REPLACE(REPLACE(REPLACE(GET_JSON_OBJECT(@a,@b),'[\\\"',''),'\\\"]',''),'\\\"','');
改造后代码
get_json_object_checkboxField(json_data,'$.checkboxField_l1d6qn51')
例2:
问题背景:
时间类型:计算自然周或者自然月维度的指标
初始代码
TO_CHAR(DATEADD(TO_DATE('${bizdate}','yyyymmdd'), - 1 * IF(WEEKDAY(TO_DATE('${bizdate}','yyyymmdd')) == 0,7,WEEKDAY(TO_DATE('${bizdate}','yyyymmdd'))), 'dd'),'yyyymmdd')
改造成SQL函数
CREATE SQL FUNCTION if not exists natural_week(@a STRING)
AS TO_CHAR(DATEADD(TO_DATE(@a,'yyyymmdd'), - 1 * IF(WEEKDAY(TO_DATE(@a,'yyyymmdd')) == 0,7,WEEKDAY(TO_DATE(@a,'yyyymmdd'))), 'dd'),'yyyymmdd');
改造后代码
natural_week('${bizdate}')
▐** **ODPS + UDF
通过对自定义的MAX_UDF函数的推出,仅通过申请一个UDF函数即可调用所有函数,操作简便,达到减少申请时间成本及重复开发成本的目的。
本部分与上文自定义UDF开发篇密切相关,下面举一个简单的例子:
问题背景:
字符串加密。
入参:第一个参数是字符串加密的序列号;第二个参数是要加密的字符;第三个是加密的开始位数;第四个是要加密几位;第五个参数是加密的字符内容。
出参:针对字符串加密处理。
select process_string('{"clazzNo":"011","methodNo":"01"}',"123411412341","2","7","*");
注:这里process_string,是我们自己写的UDF方法。

问题处理
▐** **性能分析
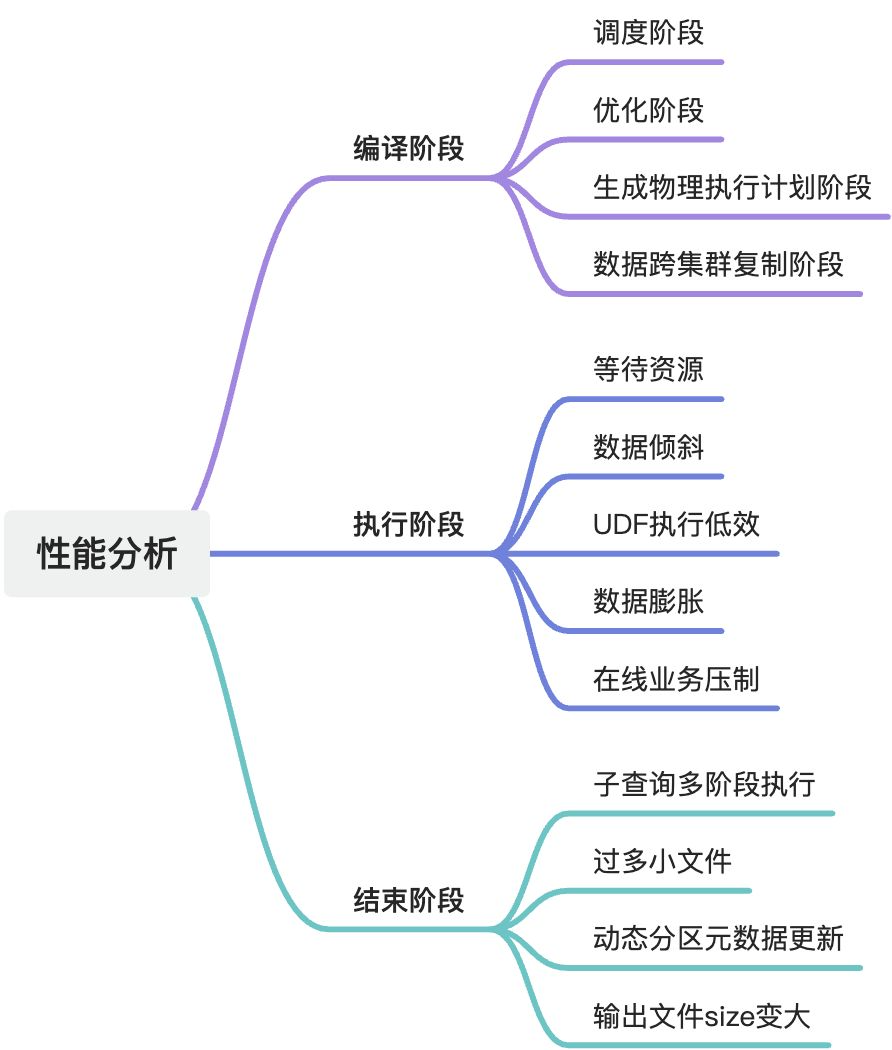
- 编译阶段
据 logview 的子状态(SubStatusHistory)可以进一步细分为调度、优化、生成物理执行计划、数据跨集群复制等子阶段。
阶段
特征
原因
解决方案
调度阶段
子状态为“Waiting for cluster resource”,作业排队等待被编译。
1.计算集群资源紧缺。
查看计算集群的状态,需要等待计算集群的资源。
- 编译资源池资源不够
优化阶段
子状态为“SQLTask is optimizing query”,优化器正在优化执行计划。
1.执行计划复杂,需要等待较长时间做优化。
一般可接受10分钟以内,如果真的太长时间不退出,基本可认为是 odps 的 bug。
生成物理执行计划阶段
子状态为“SQLTask is generating execution plan”。
1.读取的分区太多。每个分区需要去根据分区信息来决定处理方式,决定 split,并且会写到生成的执行计划中。
需要好好设计 SQL,减少分区的数量,包括:分区裁剪、筛除不需要读的分区、把大作业拆成小作业。
2.小文件太多(万级别),ODPS 会根据文件大小决定 split,小文件多了会导致计算 split 的过程耗时增加。
使用TunnelBufferedWriter接口,可以更简单的进行上传功能,同时避免小文件。
执行一次 alter table merge smallfiles; 让 odps 把小文件 merge 起来,
数据跨集群复制阶段
子状态列表里面出现多次“Task rerun”,result 里有错误信息“FAILED: ODPS-0110141:Data version exception”。
1.project 刚做集群迁移,往往前一两天有大量需要跨集群复制的作业。
这种情况是预期中的跨集群复制,需要用户等待。
2.可能是作业提交错集群,或者是中间 project 做过迁移,分区过滤没做好,读取了一些比较老的分区。
检查作业提交的集群是否正确, Logview2.0任务详情页左侧的 BasicInfo 查看作业提交的集群。
- 执行阶段
logview 的 detail 界面有执行计划(执行计划没有全都绿掉),且作业状态还是 Running。
执行阶段卡住或执行时间比预期长的主要原因有等待资源,数据倾斜,UDF 执行低效,数据膨胀等。
阶段
特征
解决方案
等待资源
一些instance处于Ready状态,部分instance处于Running状态。
确定排队状态是否正常。可以通过 logview 的排队信息“Queue”看作业在队列的位置。
数据倾斜
task 中大多数 instance 都已经结束了,但有某几个 instance 却迟迟不结束(长尾)。
- 利用 MaxCompute Studio 的作业执行图及作业详情功能来分析作业运行情况,定位到长尾实例,找到导致长尾的数据来源。
- 利用 Logveiw2.0 查看任务执行图和 instance 运行情况来定位长尾实例。
UDF执行低效
某个 task 执行效率低,且该 task 中有用户自定义的扩展。
- 检查 UDF 是否有 bug。
有时候 bug 是由于某些特定的数据值引起的,比如出现某个值的时候会引起死循环。
- 检查 UDF 函数是否与内置函数同名。
内置函数是有可能被同名 UDF 覆盖的,当看到一个函数像是内置函数时,需要确定是否有同名 UDF 覆盖了内置函数。
- 使用内置函数代替 UDF。
evaluate 中只做与参数相关的必要操作。
数据膨胀
task 的输出数据量比输入数据量大很多。
- 检查代码是否有 bug:JOIN 条件是不是写错,变成笛卡尔积了;UDTF是不是有问题,输出太多数据。
- 检查 Aggregation 引起的数据膨胀。
- 避免join引起的数据膨胀。
- 由于grouping set 导致的数据膨胀。
在线业务压制
ODPS集群中的一部分是离线集群,另一部分是在线集群。
如果是弹内环境,可通过fuxi sensor确认是否存在在线业务压制。
UDF执行:
set odps.sql.udf.jvm.memory=
-- 设定UDF JVM Heap使用的最大内存,单位M,默认1024M
-- 可手动调整区间[256,12288]
- 结束阶段
有时 Fuxi 作业结束时,作业总体进度仍然处于运行状态。原因有两种:
- 单 SQL 作业可能包含多个 Fuxi 作业
- Fuxi 作业结束后,SQL 在结束阶段运行于控制集群的逻辑占用时间较长
阶段特性解决方案
子查询多阶段执行
MaxCompute SQL 的子查询会被编译进同一个 Fuxi DAG,即所有子查询和主查询都通过一个 Fuxi 作业完成。
但也有一些特殊子查询需要先将子查询单独执行。
子查询 SELECT DISTINCT ds FROM t_ds_set 先执行,其结果需要被用来做分区裁剪,来优化主查询需要读取的分区数。
过多小文件
存储方面:小文件过多会给 Pangu 文件系统带来一定的压力,且影响空间的有效利用。
计算方面:ODPS 处理单个大文件比处理多个小文件更有效率,小文件过多会影响整体的计算执行性能。
为了避免系统产生过多小文件,SQL作业会在结束时自动触发合并小文件的操作。
根据参数odps.merge.smallfile.filesize.threshold来判定小文件,默认阈值为32MB。
可通过logview查看作业是否触发了自动合并小文件。
动态分区元数据更新
Fuxi 作业执行完后,有可能还有一些元数据操作。
对分区表 sales 使用 insert into ... values命令新增 2000 个分区:
INSERT INTO TABLE sales partition (ds)(ds, product, price)
VALUES ('20170101','a',1),('20170102','b',2),('20170103','c',3), ...;
输出文件size变大
在输入输出条数相差不大的情况,结果膨胀几倍。
一般是数据分布变化导致的,在写表的过程中,会对数据进行压缩,而压缩算法对于重复数据的压缩率是最高的。
子查询:
SELECT
product,
sum(price)
FROM
sales
WHERE
ds in (SELECT DISTINCT ds FROM t_ds_set)
GROUP BY product;
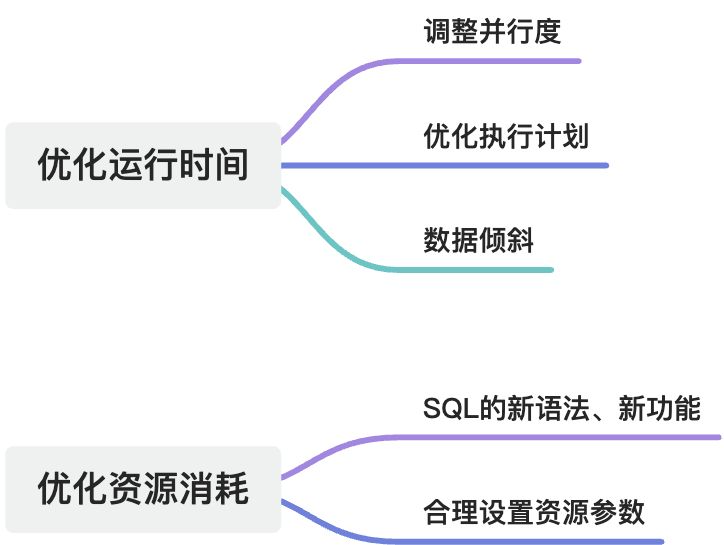
▐** **性能优化
- 优化运行时间
在优化运行时间这个维度上,我们重点关注时间上的加速,单位时间内可能会消耗更多的计算资源。总成本有可能上升,也可能降低。
优化类型
具体类型
优化措施
调整并行度
instance数量的增加会对执行速度产生影响:
- 更多的instance意味着更长的等待资源和排队次数。
- 每个instance的初始化需要一定时间,并行度越高,总初始化时间越长,有效执行时间占比越低。
需要强制 1 个 instance 执行
用户需要检查这些操作是否必要,能否去掉,尽量取消掉这些操作:读表的 task + 非读表的 task
影响单个task并行度主要因素:
- 某些操作强制必须 1 个 instance 来执行
- 读表的 task
- 非读表的 task
- HBO会在上面的基础上根据历史作业的执行情况做调整
对于读表的 task,一个 instance 读取 256M的数据,一些常见出问题的情况:
- 数据压缩比很高
- Task 中执行了一些很 heavy 的操作,特别是存在 UDF
- 读取 256M 数据太少,导致 instance 的执行时间太短
可以通过调整flag实现:
set odps.sql.mapper.split.size= xxx
非读表的 task,主要有三种方式调整并行度:
- 调整 odps.sql.mapper.split.size
- 通过 odps.sql.reducer.instances 强制设置 reducer 并行度
- 通过 odps.sql.joiner.instances 强制设置 joiner 并行度
set odps.sql.reducer.instances= xxx
-- 设定Reduce task的instance数量
set odps.sql.joiner.instances= xxx
-- 设定Join task的instance数量
HBO
HBO (History-Based Optimization) 会根据对历史作业的分析来优化当前作业的。
包括内存、并行度等一系列参数,它能让你的周期作业越跑越快。
为了尽可能解决HBO失效这个顽疾,我们在HBO中增加了若干新的功能,包括:
- realtime hbo
- task-wise hbo
- new signature
优化执行计划
CBO优化器会基于统计信息、SQL语义、执行引擎能力、丰富的优化能力,自动生成最优的执行计划,并且在持续提升优化能力。
Map Join Hint
用户可以手动添加map join hint,使得原本的Sort-Merge Join变成Map Join,避免大表数据shuffle从而提升性能。
Distributed Map Join Hint
Distributed MapJoin是MapJoin的升级版,适用于适用于大表Join中表的场景 的场景,二者的核心目的都是为了减少大表侧的Shuffle和排序。
Dynamic Filter Hint
基于JOIN等值连接的特性,MaxCompute可以通过表A的数据生成一个过滤器,在Shuffle或JOIN之前提前过滤表B的数据。
物化视图
物化视图(Materialized View)本质是一种预计算,即把某些耗时的操作(如JOIN/AGGREGATE)的结果保存下来。
以便在查询时直接复用,从而避免这些耗时的操作,最终达到加速查询的目的。
数据倾斜
数据Shuffle导致的数据倾斜 1
数据倾斜大多数是由于数据的 reshuffle 引起的,因为按照某个 key 来做 shuffle,同一个 key 值的数据会强制集中在一个 instance 处理。
- 去掉 shuffle
- 换别的 shuffle key
- 将热点数据特殊处理
数据Shuffle导致的数据倾斜 2
特征:读表并写动态分区作业,M task 读入大量数据,但是只会写出少量的 动态分区。
解决方法:set odps.sql.reshuffle.dynamicpt =false; 去掉reshuffle 过程。
- 优化资源消耗
优化类型
具体类型
优化措施
SQL的新语法、新功能
GROUPING SETS:对 SELECT 语句中 GROUP BY 子句的扩展。
SQL 运行*时物理执行计划做了 3 次聚合,然后再 UNION 起来。
脚本模式:
脚本模式能让用户以脚本的形式提交多条语句同时执行。
脚本模式的性能优势,实际上是“将分散的业务逻辑合并成一个作业来运行“的性能优势:
- 合并重复的公共操作。
- 避免中间数据写表,减少临时表。
- 更好的发挥 optimizer 的作用。
- 减少了作业调度的开销。
MR典型场景用SQL实现
- 使用 SQL-聚合函数
select k, WM_CONCAT(';',concat(v,":",c)) from
( select k, v, count(v) c from t group by k,v) t2 group by k;
- 用 SQL-窗口/分析函数
rows between x preceding|following and y preceding|following
- 使用 SQL-UDJ (User Defined Join)
MapReduce 实现的 JOIN 逻辑。
- 使用 SQL-TRANSFORM
适用场景:MapReduce Streaming 作业。
合理设置资源参数
Map设置
set odps.sql.mapper.cpu=100
作用:设置处理Map Task每个Instance的CPU数目
set odps.sql.mapper.memory=1024
作用:设定Map Task每个Instance的Memory大小
set odps.sql.mapper.merge.limit.size=64
作用:设定控制文件被合并的最大阈值
set odps.sql.mapper.split.size=256
作用:设定一个Map的最大数据输入量
Join设置
set odps.sql.joiner.instances=-1
作用: 设定Join Task的Instance数量
set odps.sql.joiner.cpu=100
作用: 设定Join Task每个Instance的CPU数目
set odps.sql.joiner.memory=1024
作用:设定Join Task每个Instance的Memory大小
Reduce设置
set odps.sql.reducer.instances=-1
作用: 设定Reduce Task的Instance数量
set odps.sql.reducer.cpu=100
作用:设定处理Reduce Task每个Instance的Cpu数目
set odps.sql.reducer.memory=1024
作用:设定Reduce Task每个Instance的Memory大小
GROUPING SETS 优化措施*:
SELECT NULL, NULL, NULL, COUNT(*)
FROM requests
UNION ALL
SELECT os, device, NULL, COUNT(*)
FROM requests GROUP BY os, device
UNION ALL
SELECT NULL, NULL, city, COUNT(*)
FROM requests GROUP BY city;
上述 SQL 运行时物理执行计划做了 3 次聚合,然后再 UNION 起来。
SELECT os, device, city, COUNT(*)
FROM requests
GROUP BY os, device, city GROUPING SETS((os, device), (city), ());
物理执行计划只包含一个 Reduce 阶段,无需进行 UNION 操作,使用更少代码的同时消耗更少的集群资源。
▐** **恢复已删

总结
经过一个多月的整理和总结,终于完成了《ODPS开发大全》的这个基础版本。在这过程中我不断地接触到新的知识点,学到之前未曾掌握的技术,也感叹ODPS功能之丰富强大。期望在未来工作中,自己可以多沉淀好的技术文档,这不仅让我更加深刻地温习过往学习的技术,也可以把知识共享给更多求知若渴的技术人,建设更开放的CS技术社区。
¤** 拓展阅读 **¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法
版权归原作者 阿里巴巴淘系技术团队官网博客 所有, 如有侵权,请联系我们删除。