
单机部署hadoop&单机上的伪多机部署&基于docker的模拟多机部署
单机部署
单机上部署hadoop,需要:
- linux环境
- java
- hadoop
- ssh
安装依赖
linux推荐使用wsl
wsl --install
也可以下载ubuntu镜像使用vmware等创建虚拟机
还可以使用Ubuntu的docker镜像
docker pull ubuntu:22.04
sudodocker run -it ubuntu:latest /bin/bash
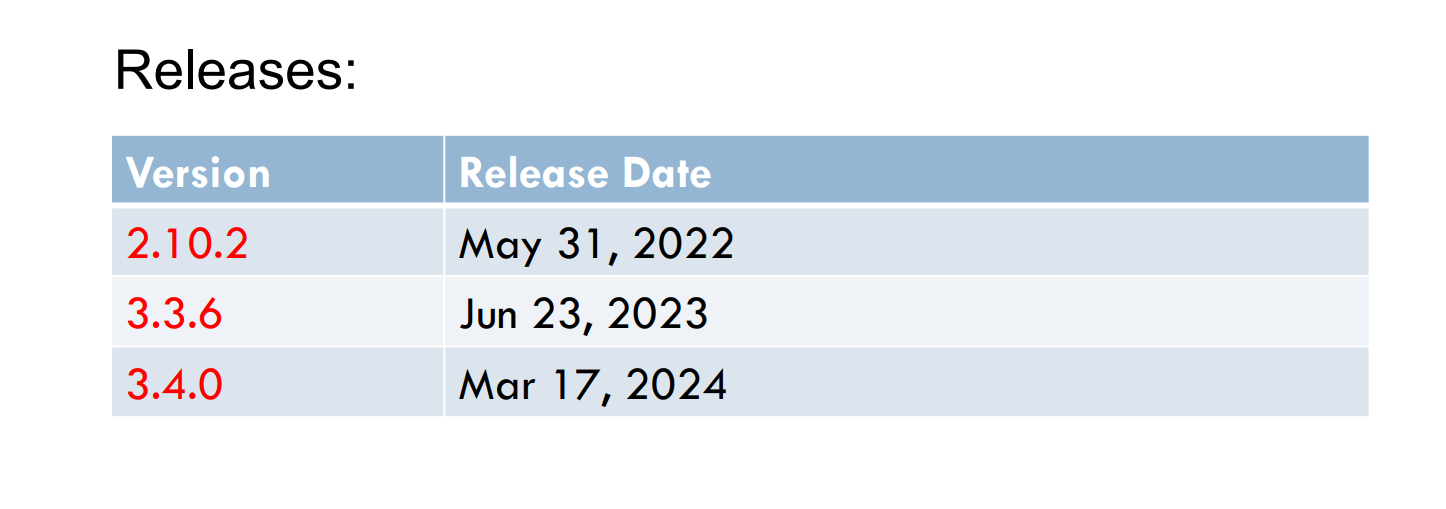

此处选择的版本是hadoop-3.4.0,java11
在官网下载hadoop-3.4.0.tar.gz文件,解压到
/usr/local
目录下
配置
配置文件均在
\usr\local\hadoop-3.4.0\etc\hadoop下
使用下面的命令获取java路径,写入配置文件
hadoop-env.sh
update-alternatives --configjava

根据获取到的路径,写入
hadoop-env.sh
此处注意不要有空格,结尾不要有斜杠
exportJAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
#optional:添加环境变量
vim ~/.bashrc
末尾添加
exportHADOOP_HOME=/usr/local/hadoop-3.4.0
exportPATH=HADOOP_HOME/bin
保存
测试
#/usr/local/hadoop-3.4.0<span class="katex--inline"><span class="katex"><span class="katex-mathml"><math xmlns="http://www.w3.org/1998/Math/MathML"><semantics><mrow><mi>m</mi><mi>k</mi><mi>d</mi><mi>i</mi><mi>r</mi><mi>i</mi><mi>n</mi><mi>p</mi><mi>u</mi><mi>t</mi></mrow><annotation encoding="application/x-tex">mkdir input
</annotation></semantics></math></span><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut"style="height:0.8889em;vertical-align:-0.1944em;"><span class="mord mathnormal"style="margin-right:0.03148em;">mk</span><span class="mord mathnormal">d</span><span class="mord mathnormal">i</span><span class="mord mathnormal"style="margin-right:0.02778em;">r</span><span class="mord mathnormal">in</span><span class="mord mathnormal">p</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span></span></span></span></span>cp etc/hadoop/*.xml input
<span class="katex--inline"><span class="katex"><span class="katex-mathml"><math xmlns="http://www.w3.org/1998/Math/MathML"><semantics><mrow><mi>b</mi><mi>i</mi><mi>n</mi><mi mathvariant="normal">/</mi><mi>h</mi><mi>a</mi><mi>d</mi><mi>o</mi><mi>o</mi><mi>p</mi><mi>j</mi><mi>a</mi><mi>r</mi><mi>s</mi><mi>h</mi><mi>a</mi><mi>r</mi><mi>e</mi><mi mathvariant="normal">/</mi><mi>h</mi><mi>a</mi><mi>d</mi><mi>o</mi><mi>o</mi><mi>p</mi><mi mathvariant="normal">/</mi><mi>m</mi><mi>a</mi><mi>p</mi><mi>r</mi><mi>e</mi><mi>d</mi><mi>u</mi><mi>c</mi><mi>e</mi><mi mathvariant="normal">/</mi><mi>h</mi><mi>a</mi><mi>d</mi><mi>o</mi><mi>o</mi><mi>p</mi><mo>−</mo><mi>m</mi><mi>a</mi><mi>p</mi><mi>r</mi><mi>e</mi><mi>d</mi><mi>u</mi><mi>c</mi><mi>e</mi><mo>−</mo><mi>e</mi><mi>x</mi><mi>a</mi><mi>m</mi><mi>p</mi><mi>l</mi><mi>e</mi><mi>s</mi><mo>−</mo><mn>3.4.0.</mn><mi>j</mi><mi>a</mi><mi>r</mi><mi>g</mi><mi>r</mi><mi>e</mi><mi>p</mi><mi>i</mi><mi>n</mi><mi>p</mi><mi>u</mi><mi>t</mi><mi>o</mi><mi>u</mi><mi>t</mi><mi>p</mi><mi>u</mi><msup><mi>t</mi><mo mathvariant="normal"lspace="0em"rspace="0em">′</mo></msup><mi>d</mi><mi>f</mi><mi>s</mi><mo stretchy="false">[</mo><mi>a</mi><mo>−</mo><mi>z</mi><mi mathvariant="normal">.</mi><mo stretchy="false">]</mo><msup><mo>+</mo><mo mathvariant="normal"lspace="0em"rspace="0em">′</mo></msup></mrow><annotation encoding="application/x-tex"> bin/hadoop jar share/hadoop/mapreduce /hadoop-mapreduce-examples-3.4.0.jar grep input output 'dfs[a-z.]+'</annotation></semantics></math></span><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut"style="height:1em;vertical-align:-0.25em;"><span class="mord mathnormal">bin</span><span class="mord">/</span><span class="mord mathnormal">ha</span><span class="mord mathnormal">d</span><span class="mord mathnormal">oo</span><span class="mord mathnormal">p</span><span class="mord mathnormal">ja</span><span class="mord mathnormal">rs</span><span class="mord mathnormal">ha</span><span class="mord mathnormal">re</span><span class="mord">/</span><span class="mord mathnormal">ha</span><span class="mord mathnormal">d</span><span class="mord mathnormal">oo</span><span class="mord mathnormal">p</span><span class="mord">/</span><span class="mord mathnormal">ma</span><span class="mord mathnormal">p</span><span class="mord mathnormal">re</span><span class="mord mathnormal">d</span><span class="mord mathnormal">u</span><span class="mord mathnormal">ce</span><span class="mord">/</span><span class="mord mathnormal">ha</span><span class="mord mathnormal">d</span><span class="mord mathnormal">oo</span><span class="mord mathnormal">p</span><span class="mspace"style="margin-right:0.2222em;"><span class="mbin">−</span><span class="mspace"style="margin-right:0.2222em;"></span><span class="base"><span class="strut"style="height:0.8889em;vertical-align:-0.1944em;"><span class="mord mathnormal">ma</span><span class="mord mathnormal">p</span><span class="mord mathnormal">re</span><span class="mord mathnormal">d</span><span class="mord mathnormal">u</span><span class="mord mathnormal">ce</span><span class="mspace"style="margin-right:0.2222em;"><span class="mbin">−</span><span class="mspace"style="margin-right:0.2222em;"></span><span class="base"><span class="strut"style="height:0.8889em;vertical-align:-0.1944em;"><span class="mord mathnormal">e</span><span class="mord mathnormal">x</span><span class="mord mathnormal">am</span><span class="mord mathnormal"style="margin-right:0.01968em;">pl</span><span class="mord mathnormal">es</span><span class="mspace"style="margin-right:0.2222em;"><span class="mbin">−</span><span class="mspace"style="margin-right:0.2222em;"></span><span class="base"><span class="strut"style="height:1.0019em;vertical-align:-0.25em;"><span class="mord">3.4.0.</span><span class="mord mathnormal">ja</span><span class="mord mathnormal"style="margin-right:0.02778em;">r</span><span class="mord mathnormal"style="margin-right:0.03588em;">g</span><span class="mord mathnormal">re</span><span class="mord mathnormal">p</span><span class="mord mathnormal">in</span><span class="mord mathnormal">p</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span><span class="mord mathnormal">o</span><span class="mord mathnormal">u</span><span class="mord mathnormal">tp</span><span class="mord mathnormal">u</span><span class="mord"><span class="mord mathnormal">t</span><span class="msupsub"><span class="vlist-t"><span class="vlist-r"><span class="vlist"style="height:0.7519em;"><span style="top:-3.063em;margin-right:0.05em;"><span class="pstrut"style="height:2.7em;"><span class="sizing reset-size6 size3 mtight"><span class="mord mtight"><span class="mord mtight">′</span></span></span></span></span></span></span></span></span><span class="mord mathnormal"style="margin-right:0.10764em;">df</span><span class="mord mathnormal">s</span><span class="mopen">[</span><span class="mord mathnormal">a</span><span class="mspace"style="margin-right:0.2222em;"><span class="mbin">−</span><span class="mspace"style="margin-right:0.2222em;"></span><span class="base"><span class="strut"style="height:1.0019em;vertical-align:-0.25em;"><span class="mord mathnormal"style="margin-right:0.04398em;">z</span><span class="mord">.</span><span class="mclose">]</span><span class="mord"><span class="mbin">+</span><span class="msupsub"><span class="vlist-t"><span class="vlist-r"><span class="vlist"style="height:0.7519em;"><span style="top:-3.063em;margin-right:0.05em;"><span class="pstrut"style="height:2.7em;"><span class="sizing reset-size6 size3 mtight"><span class="mord mtight"><span class="mord mtight">′</span></span></span></span></span></span></span></span></span></span></span></span></span>cat output/*
</span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span>
单机伪分布式
配置
需要修改配置文件:
etc/hadoop/core-site.xml

etc/hadoop/hdfs-site.xml
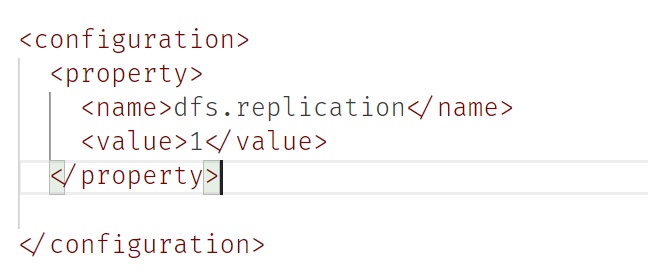
配置ssh
sudo apt-get install ssh rsync
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
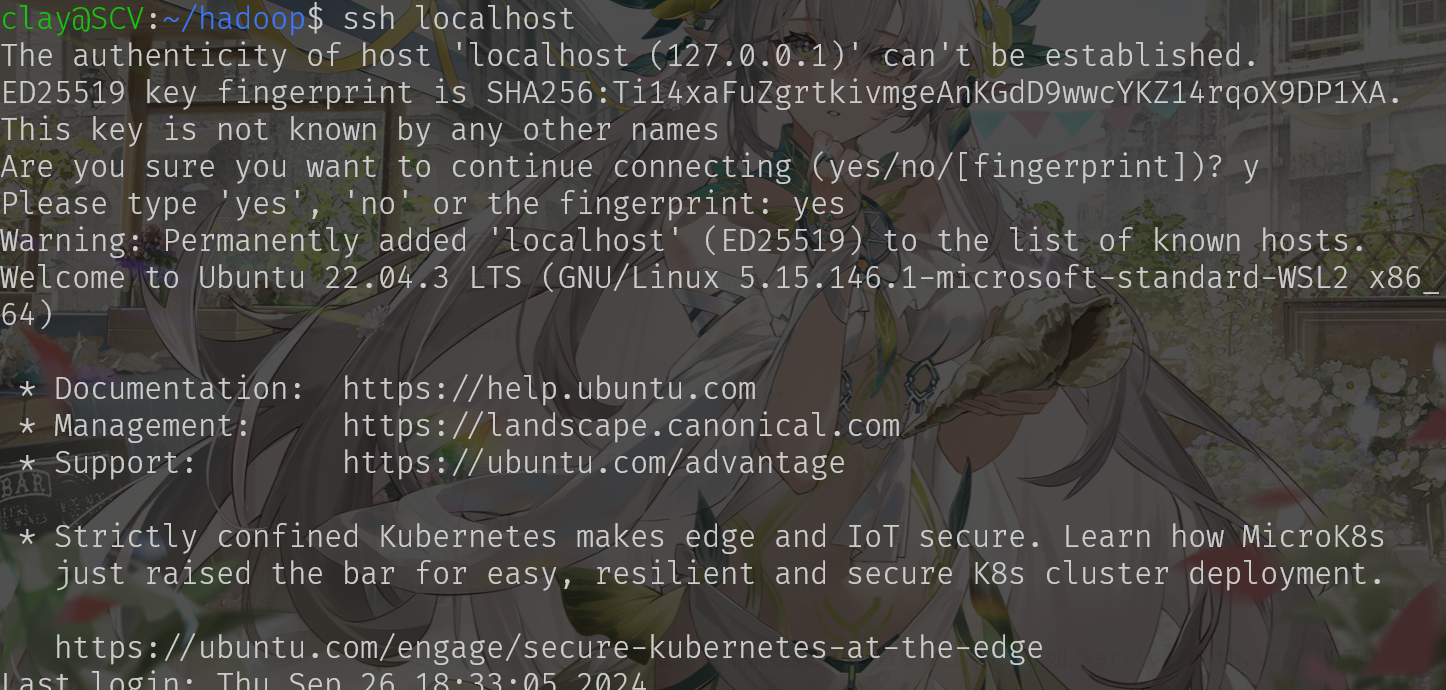
ssh localhost
检验ssh连接:
启动
格式化NameNode
bin/hdfs namenode -format
启动dfs
sbin/start-dfs.sh
#或者$HADOOP_HOME/sbin/start-dfs.sh
创建执行MapReduce作业的HDFS目录
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/clay
bin/hdfs dfs -mkdir /user/clay/input
web页面
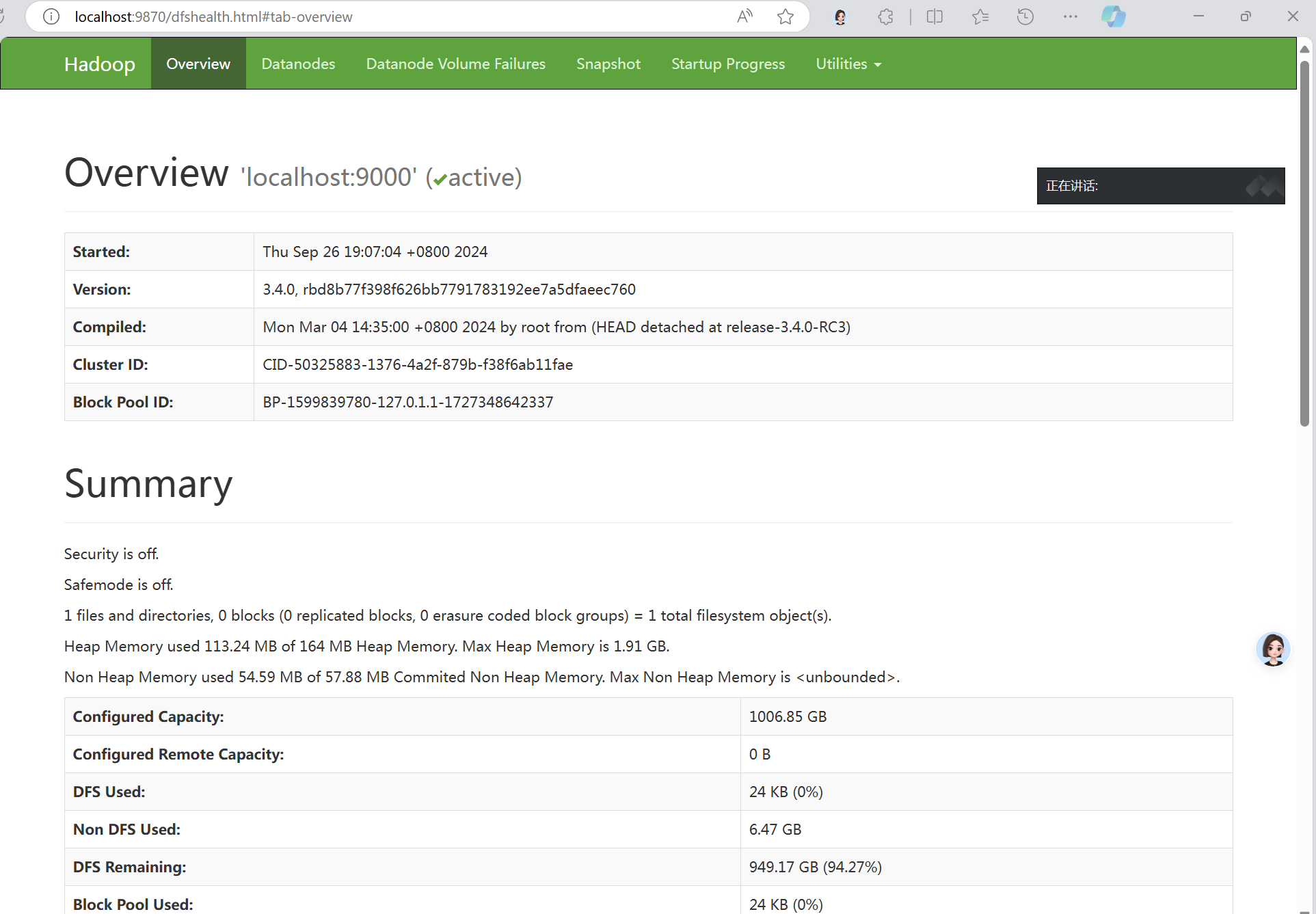
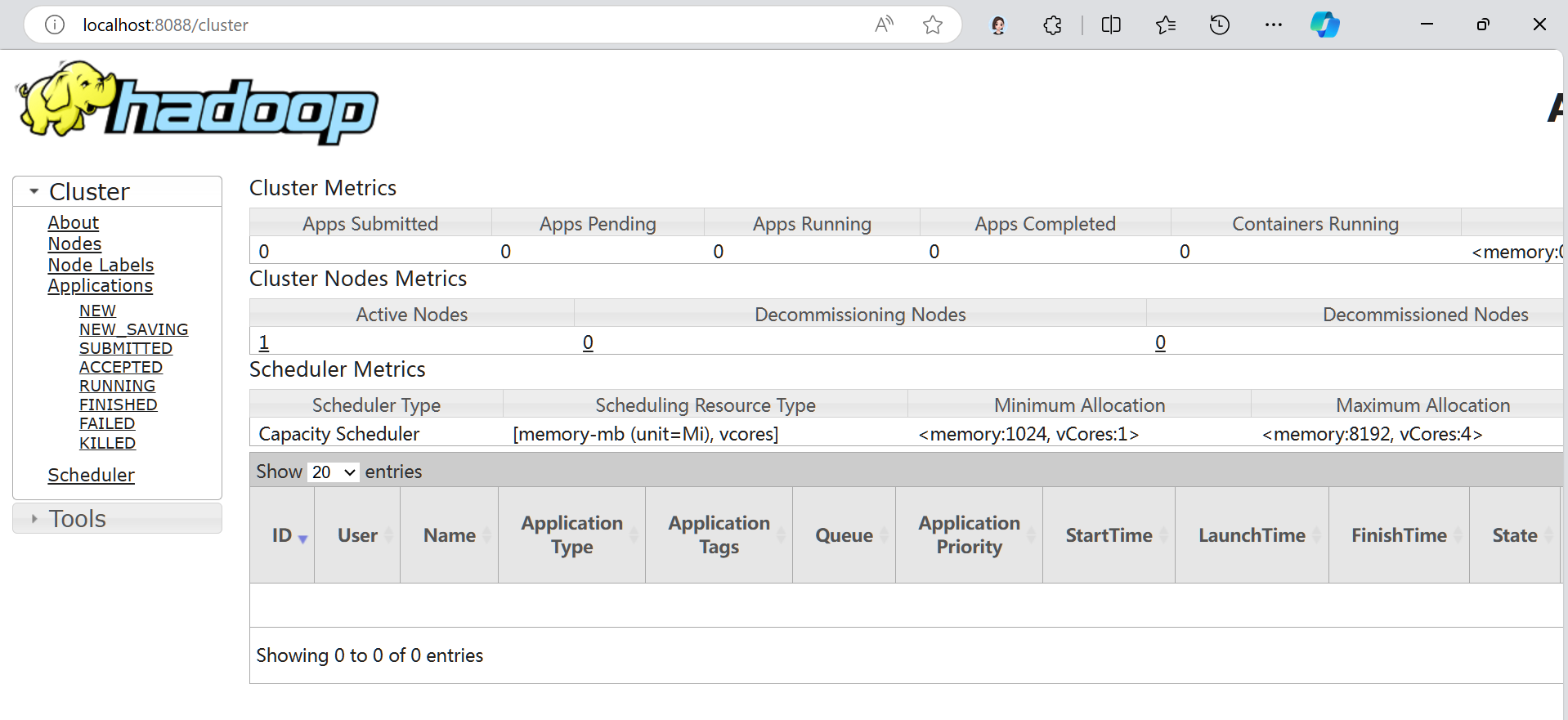
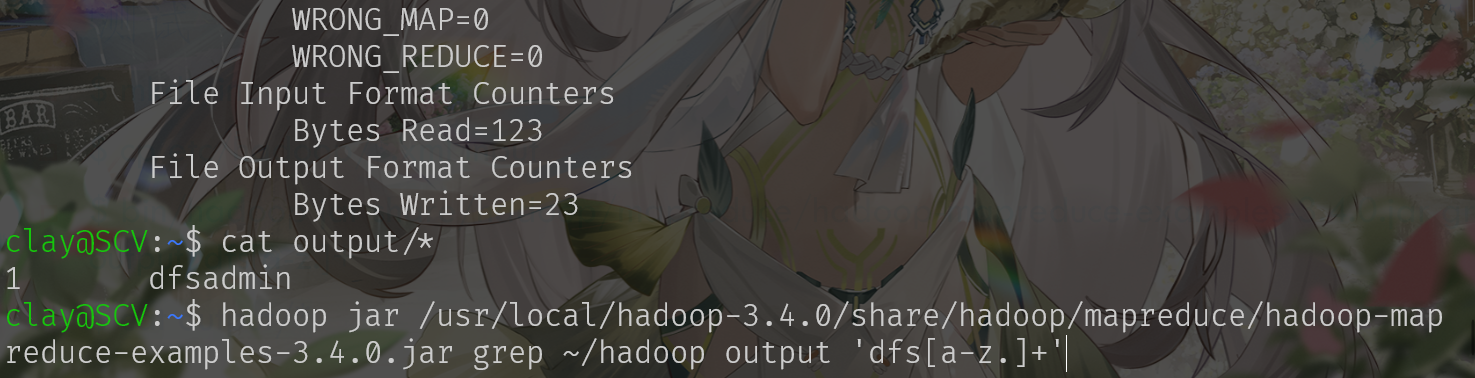
运行测试程序:
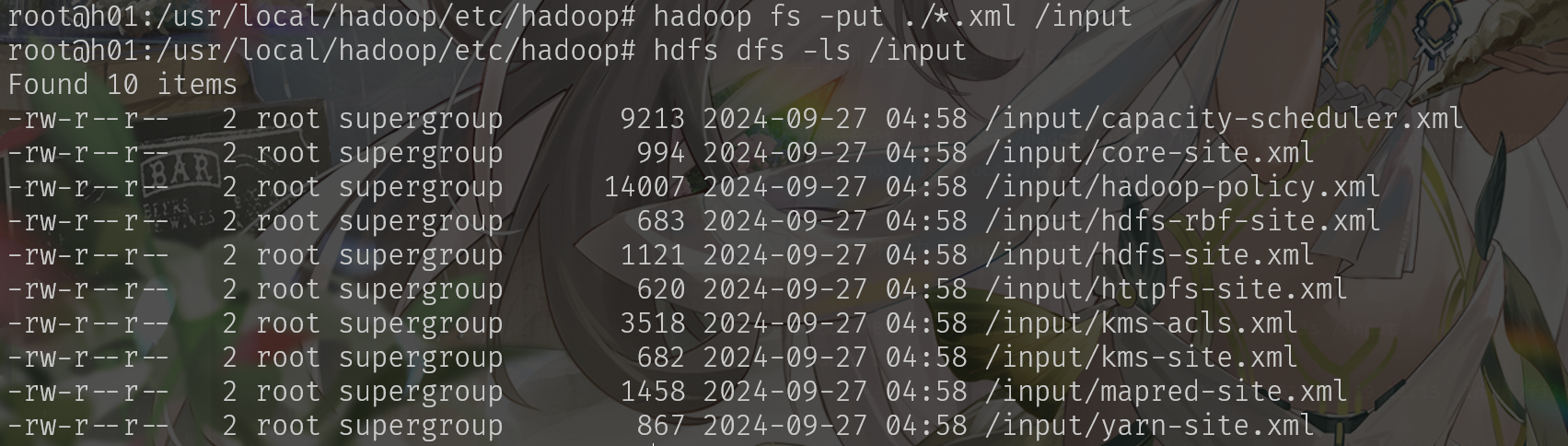
bin/hdfs dfs -put etc/hadoop/*.xml input
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.0.jar grep input output 'dfs[a-z.]+'
bin/hdfs dfs -get output output
cat output/*
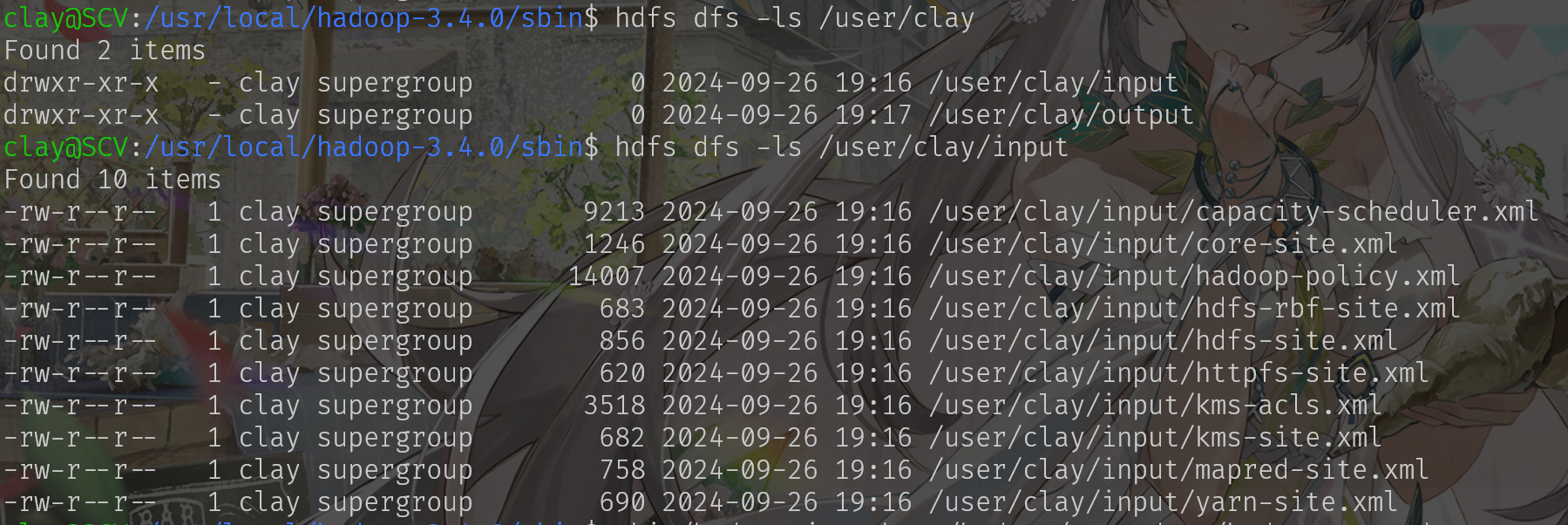
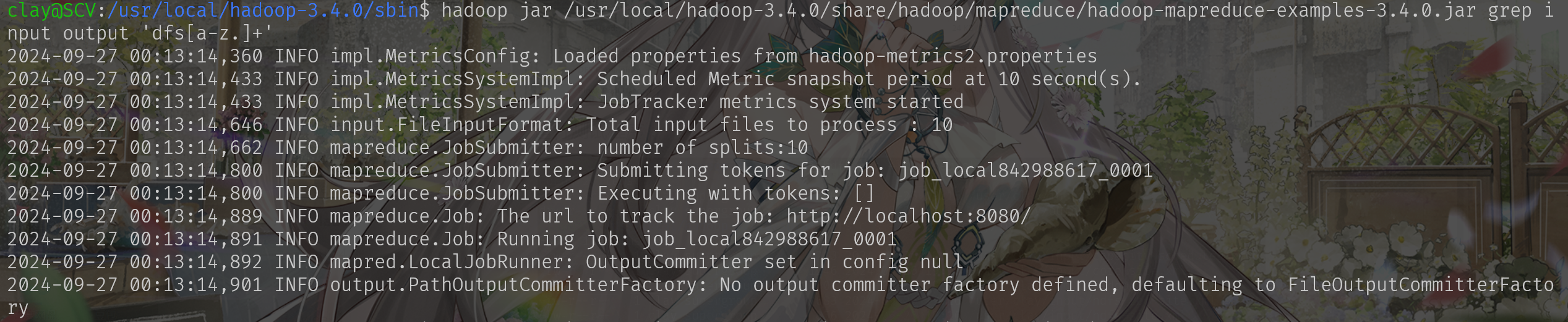

终止程序
sbin/stop-dfs.sh
基于Docker构建hadoop集群
从Ubuntu镜像搭建
拉取Ubuntu镜像以交互方式启动:
sudodocker run -it ubuntu:latest /bin/bash
进入后需要安装依赖软件:
apt-get update
apt-getinstallsudosudoapt-getinstall openjdk-8-jdk openssh-server openssh-client
hadoop使用之前下载的压缩包即可, 解压到
/usr/local
下,添加环境变量,配置JAVA_HOME等,同单节点部署
保存镜像
启动集群:h01为namenode,其他为datanode
sudodocker run -it--network hadoop -h"h01"--name"h01"-p9870:9870 -p8088:8088 hadoop_cluster /bin/bash
sudodocker run -it--network hadoop -h"h02"--name"h02" hadoop_cluster /bin/bash
sudodocker run -it--network hadoop -h"h03"--name"h03" hadoop_cluster /bin/bash

修改配置
etc/hadoop/workers

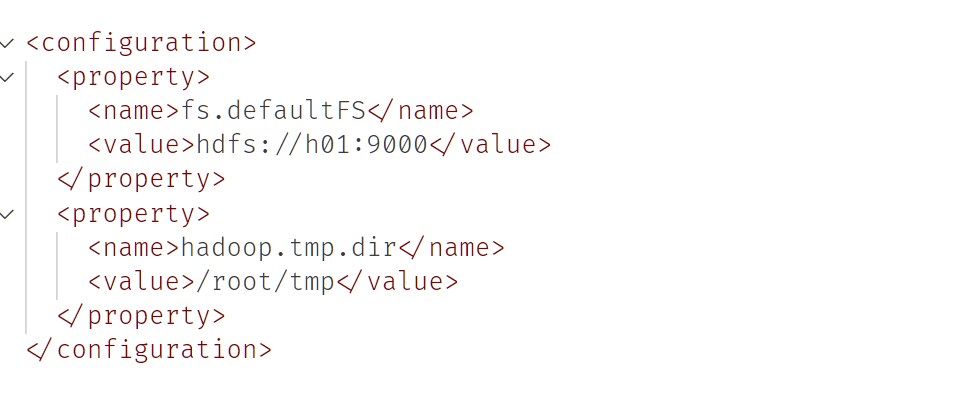
etc/hadoop/core-site.xml
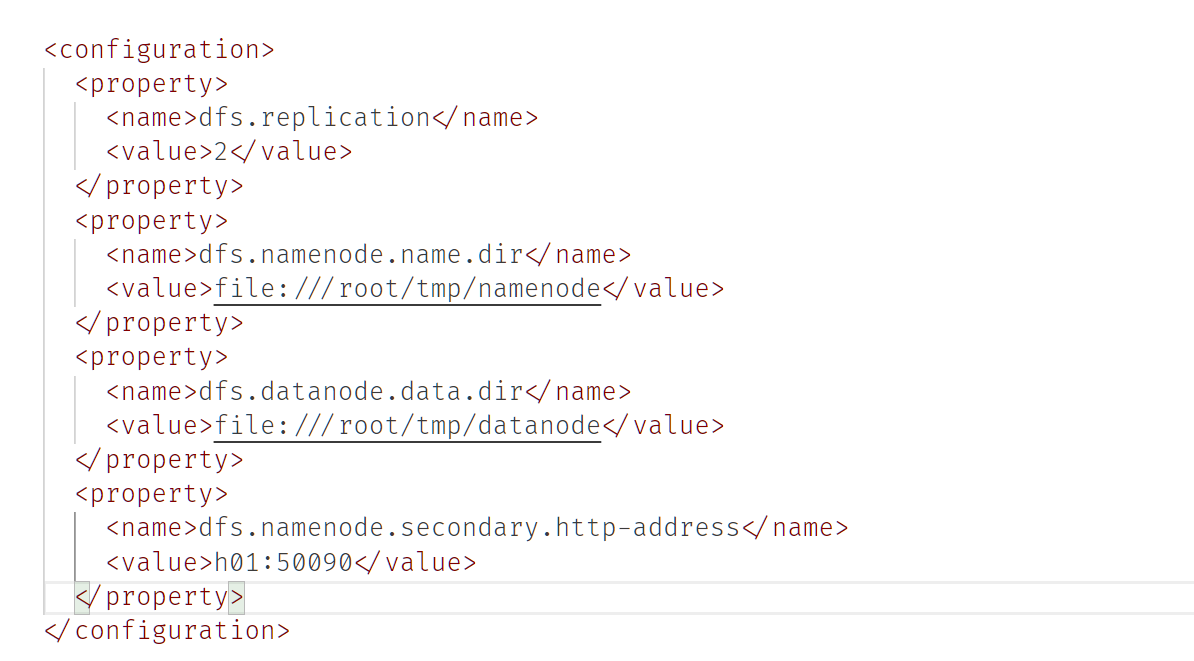
etc/hadoop/hdfs-site.xml
etc/hadoop/mapred-site.xml
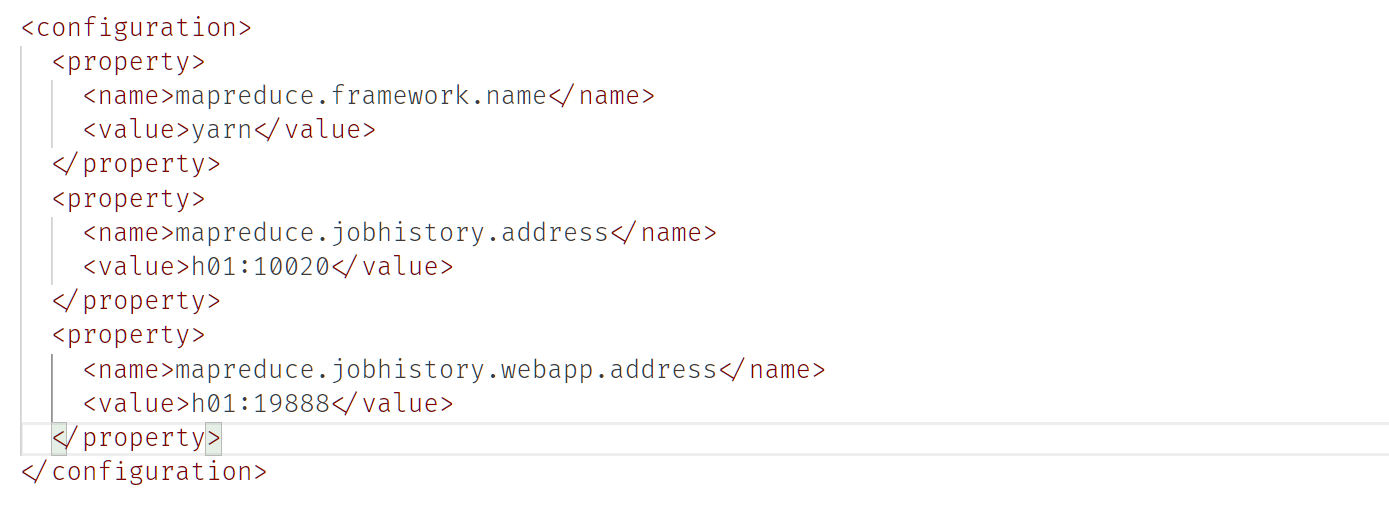
etc/hadoop/yarn-site.xml
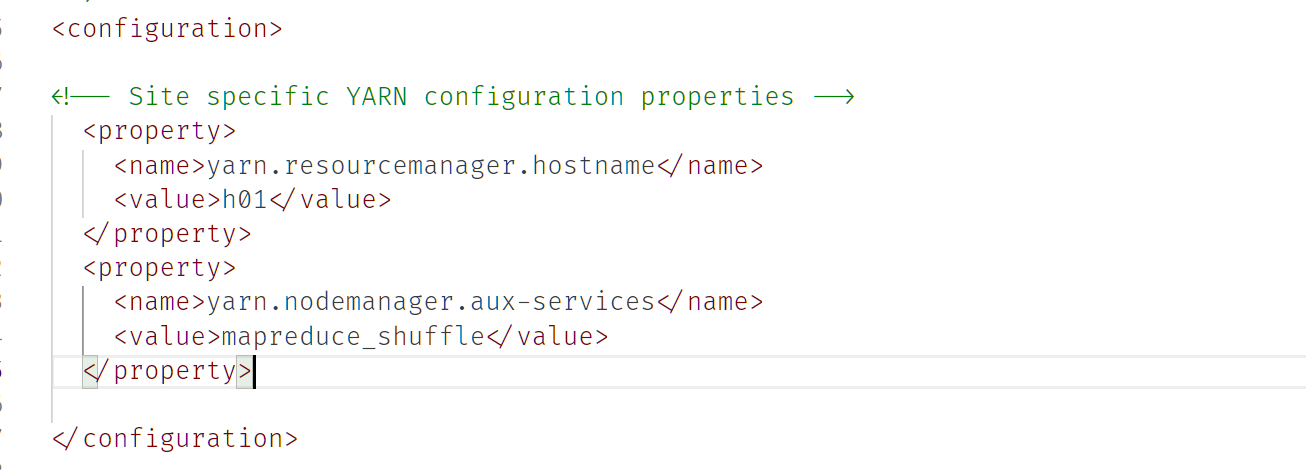
配置完成后,将配置文件复制到其他节点上:在docker desktop内拖动文件夹即可
此处更推荐写好配置文件后再打包镜像
分别启动:
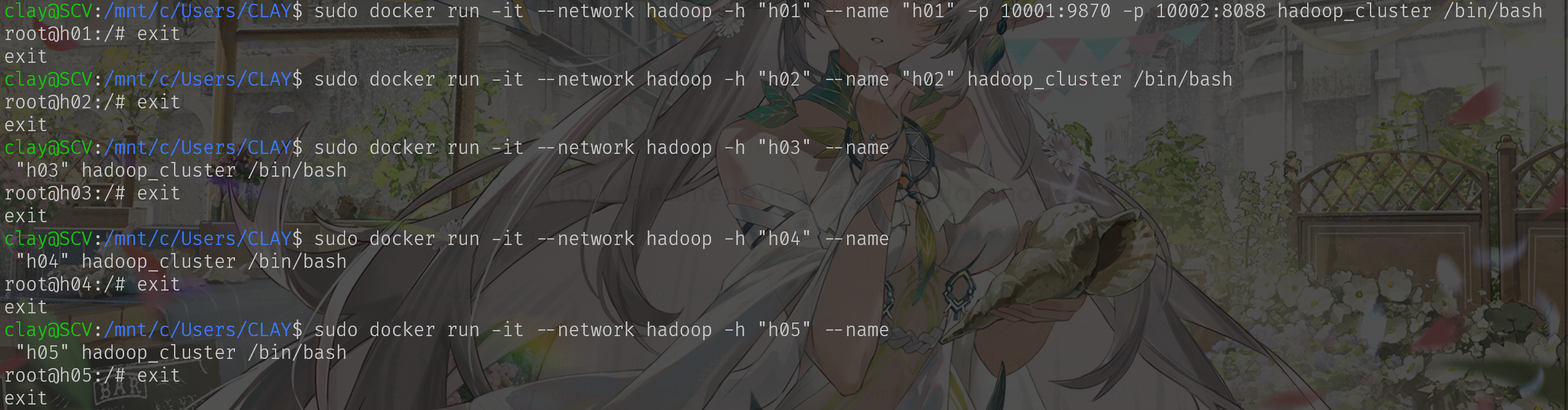
在namenode启动集群,运行
start-all.sh
文件
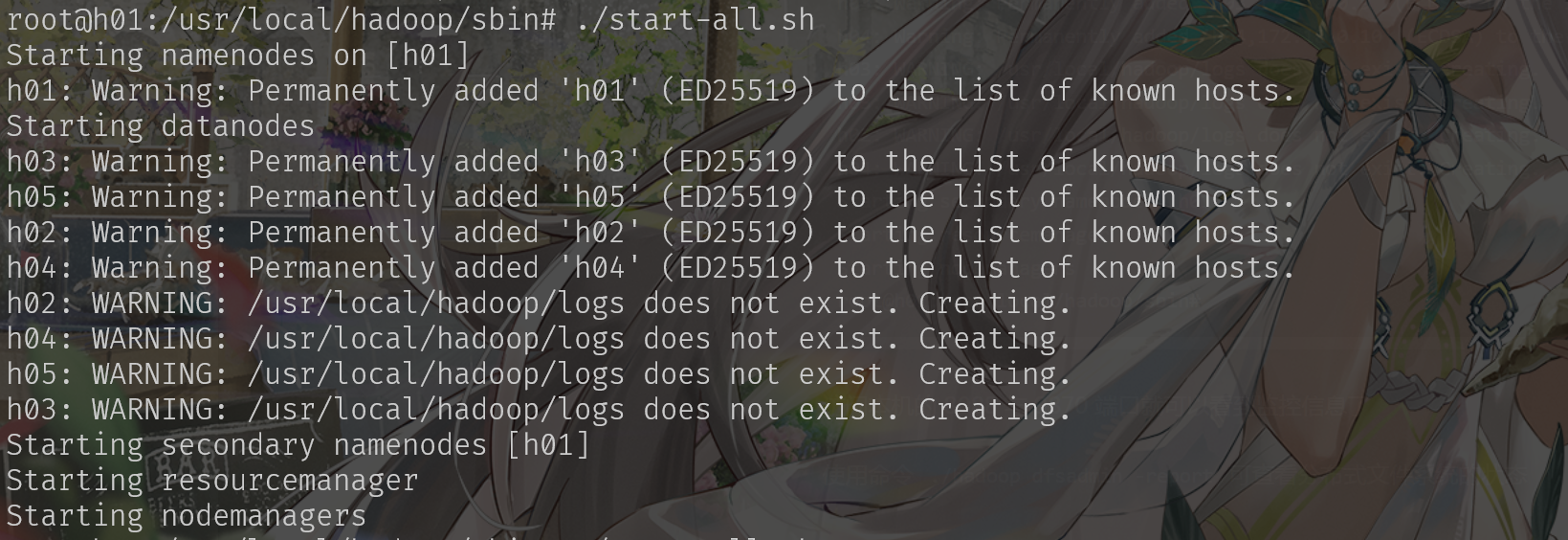
测试hadoop:
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples.3.4.0.jar grep input output 'dfs[a-z.]+


运行成功
更优的:启动自apache/hadoop:3.3.6
自行搭建的镜像缺乏优化,异常臃肿(>3GB),选择使用apache发行的hadoop镜像(1.66GB)
从apache/hadoop:3.3.6拉取镜像:
docker pull apache/hadoop:3.3.6
文件树结构:
hadoop-docker/
├── config
└── docker-compose.yaml
通过
docker-compose up -d
启动集群
docker-compose.yaml
version:"2"services:namenode:image: apache/hadoop:3.3.6
hostname: namenode
command:["hdfs","namenode"]ports:- 9870:9870env_file:- ./config
environment:HADOOP_HOME:"/opt/hadoop"ENSURE_NAMENODE_DIR:"/tmp/hadoop-root/dfs/name"datanode:image: apache/hadoop:3.3.6
command:["hdfs","datanode"]env_file:- ./config
resourcemanager:image: apache/hadoop:3.3.6
hostname: resourcemanager
command:["yarn","resourcemanager"]ports:- 8088:8088env_file:- ./config
volumes:- ./test.sh:/opt/test.sh
nodemanager:image: apache/hadoop:3.3.6
command:["yarn","nodemanager"]env_file:- ./config
config
CORE-SITE.XML_fs.default.name=hdfs://namenode
CORE-SITE.XML_fs.defaultFS=hdfs://namenode
HDFS-SITE.XML_dfs.namenode.rpc-address=namenode:8020
HDFS-SITE.XML_dfs.replication=1
MAPRED-SITE.XML_mapreduce.framework.name=yarn
MAPRED-SITE.XML_yarn.app.mapreduce.am.env=HADOOP_MAPRED_HOME=/opt/hadoop
MAPRED-SITE.XML_mapreduce.map.env=HADOOP_MAPRED_HOME=/opt/hadoop
MAPRED-SITE.XML_mapreduce.reduce.env=HADOOP_MAPRED_HOME=/opt/hadoop
YARN-SITE.XML_yarn.resourcemanager.hostname=resourcemanager
YARN-SITE.XML_yarn.nodemanager.pmem-check-enabled=false
YARN-SITE.XML_yarn.nodemanager.delete.debug-delay-sec=600
YARN-SITE.XML_yarn.nodemanager.vmem-check-enabled=false
YARN-SITE.XML_yarn.nodemanager.aux-services=mapreduce_shuffle
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.maximum-applications=10000
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.maximum-am-resource-percent=0.1
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.queues=default
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.capacity=100
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.user-limit-factor=1
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.maximum-capacity=100
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.state=RUNNING
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.acl_submit_applications=*
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.acl_administer_queue=*
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.node-locality-delay=40
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.queue-mappings=
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.queue-mappings-override.enable=false
以下是对Hadoop配置文件的逐行解释:
core-site.xml:
fs.default.name=hdfs://namenode
: 指定Hadoop的默认文件系统为HDFS,并且NameNode的地址是
namenode
。
fs.defaultFS=hdfs://namenode
: 这与
fs.default.name
是等价的,指定默认的文件系统URI。在某些Hadoop版本中,推荐使用
fs.defaultFS
。
hdfs-site.xml:
dfs.namenode.rpc-address=namenode:8020
: 指定NameNode的RPC服务器地址和端口,这里端口是8020。
dfs.replication=1
: 设置HDFS文件的默认副本数量为1。通常情况下,为了容错性,副本数会设置为3。
mapred-site.xml:
mapreduce.framework.name=yarn
: 指定MapReduce作业运行在YARN上。
yarn.app.mapreduce.am.env=HADOOP_MAPRED_HOME=/opt/hadoop
: 设置Application Master的环境变量,指定Hadoop MapReduce的安装路径。
mapreduce.map.env=HADOOP_MAPRED_HOME=/opt/hadoop
: 设置Map任务的环境变量。
mapreduce.reduce.env=HADOOP_MAPRED_HOME=/opt/hadoop
: 设置Reduce任务的环境变量。
yarn-site.xml:
yarn.resourcemanager.hostname=resourcemanager
: 指定ResourceManager的主机名。
yarn.nodemanager.pmem-check-enabled=false
: 禁用物理内存检查,允许NodeManager分配超过物理内存限制的资源。
yarn.nodemanager.delete.debug-delay-sec=600
: 设置删除日志文件的延迟时间,以秒为单位,这有助于调试。
yarn.nodemanager.vmem-check-enabled=false
: 禁用虚拟内存检查,允许NodeManager分配超过虚拟内存限制的资源。
yarn.nodemanager.aux-services=mapreduce_shuffle
: 设置NodeManager上运行的辅助服务,这里是MapReduce的shuffle服务。
capacity-scheduler.xml:
yarn.scheduler.capacity.maximum-applications=10000
: 设置集群中可以同时运行的最大应用程序数。
yarn.scheduler.capacity.maximum-am-resource-percent=0.1
: 设置集群中可用于运行Application Master的资源比例。
yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator
: 设置资源计算器,用于计算资源需求。
yarn.scheduler.capacity.root.queues=default
: 设置根队列的名称。
yarn.scheduler.capacity.root.default.capacity=100
: 设置默认队列的资源容量为100%。
yarn.scheduler.capacity.root.default.user-limit-factor=1
: 设置默认队列的用户资源限制因子。
yarn.scheduler.capacity.root.default.maximum-capacity=100
: 设置默认队列的最大资源容量。
yarn.scheduler.capacity.root.default.state=RUNNING
: 设置默认队列的状态为运行中。
yarn.scheduler.capacity.root.default.acl_submit_applications=*
: 设置默认队列的提交应用程序的访问控制列表,
*
表示任何用户都可以提交。
yarn.scheduler.capacity.root.default.acl_administer_queue=*
: 设置默认队列的管理访问控制列表,
*
表示任何用户都可以管理。
yarn.scheduler.capacity.node-locality-delay=40
: 设置节点本地性延迟,以轮询次数为单位。
yarn.scheduler.capacity.queue-mappings
: 设置队列映射规则,这里为空表示没有特定的映射规则。
yarn.scheduler.capacity.queue-mappings-override.enable=false
: 设置是否启用队列映射覆盖,这里设置为不启用。
运行
在终端内启动容器:
docker-compose up -d

网页端监控器运行状态:
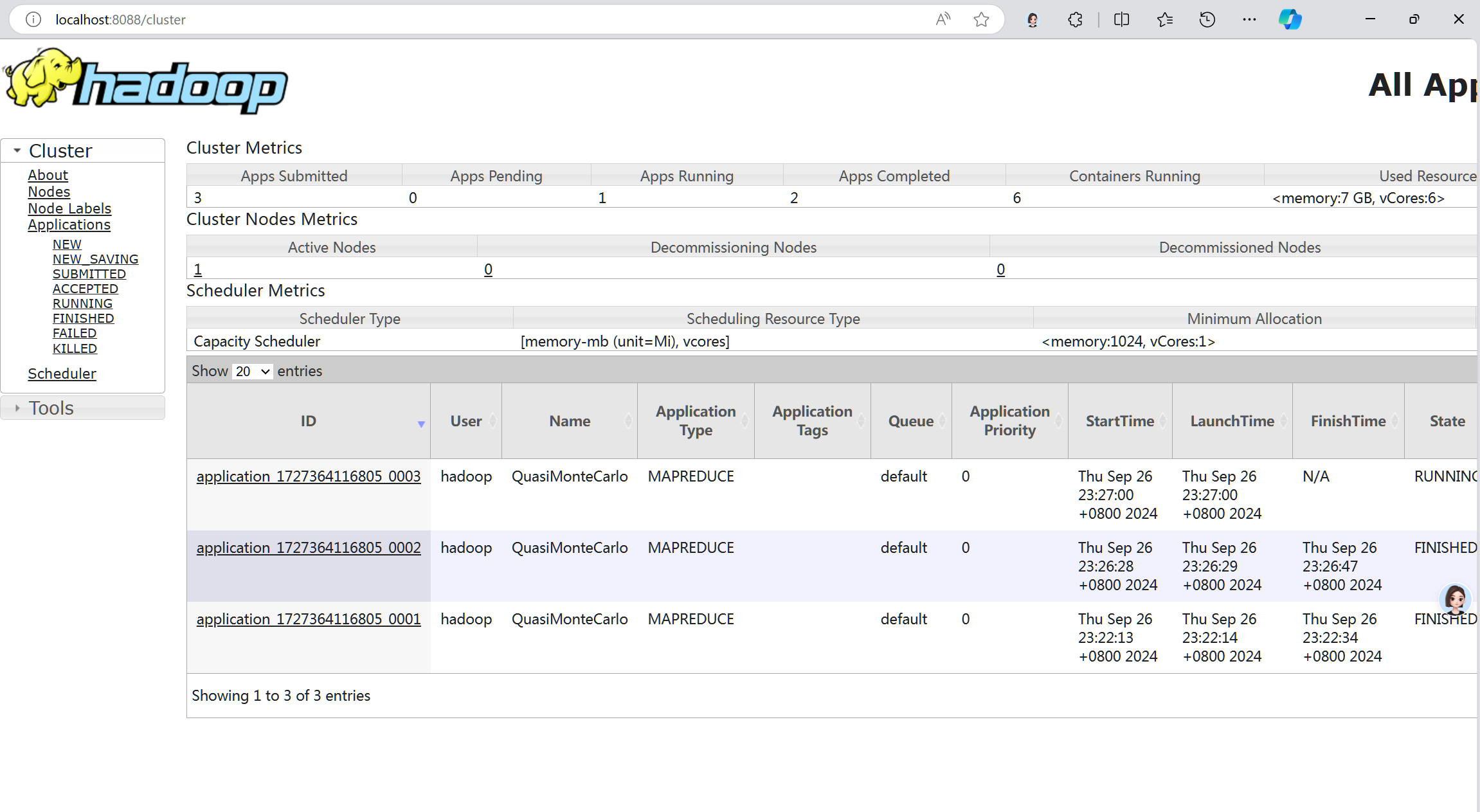
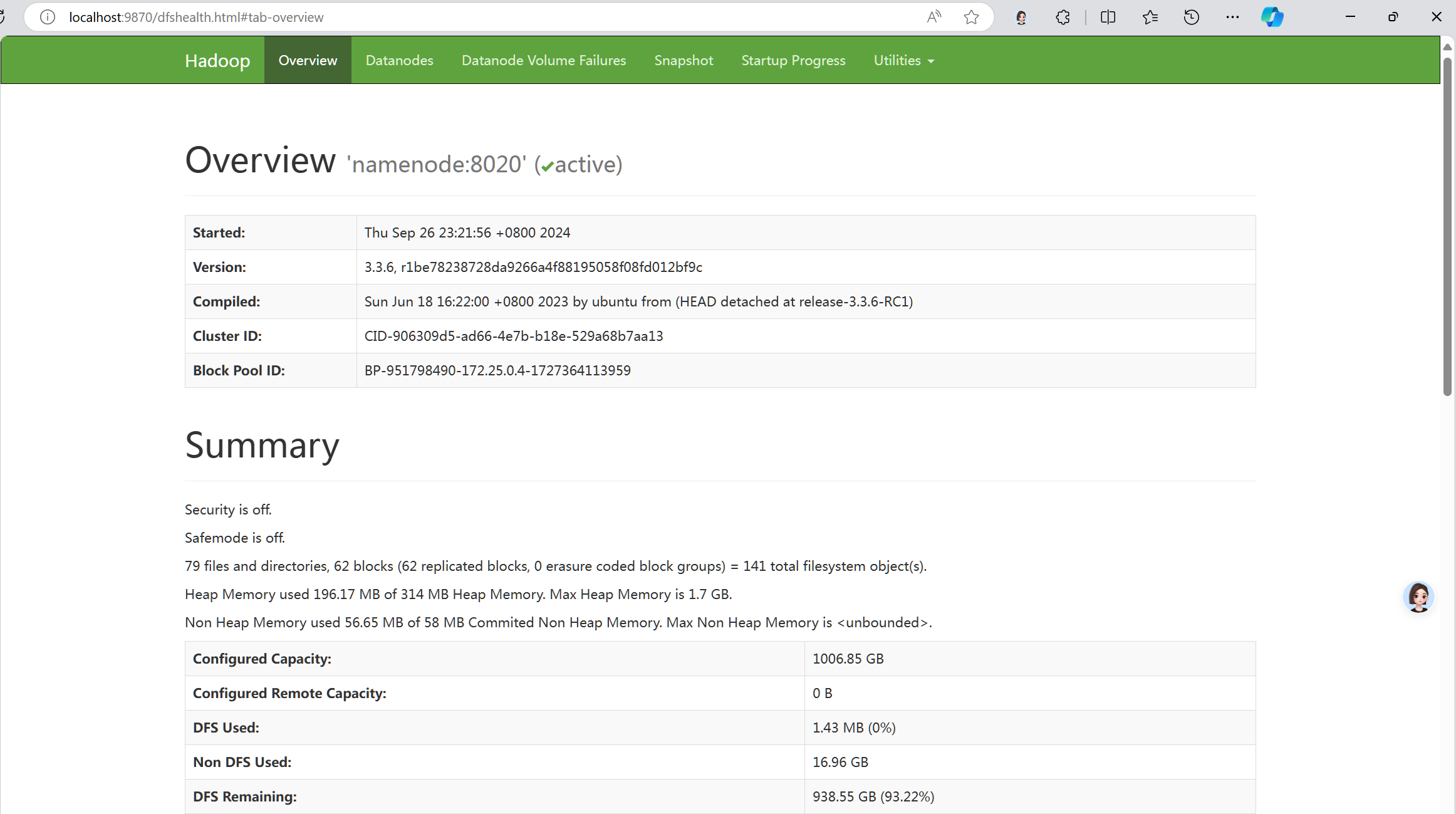
运行测试程序:
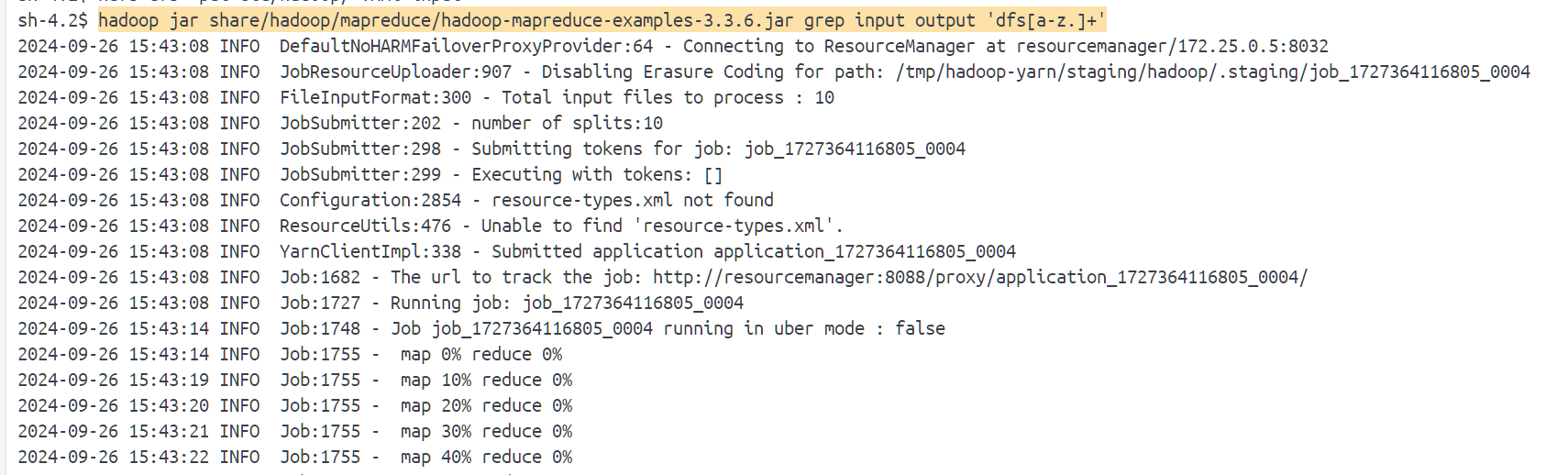
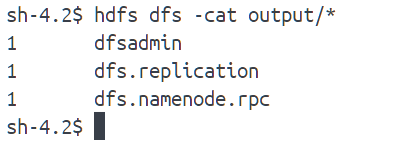
更多的节点
单节点到多节点, config无需修改
为了实现更多节点的集群,使用
docker-compose -v2
书写规则时,需要显式指定datanode, 以2个datanode的方式为例,需要写4配置项:(not recommend)
version:"2"services:datanode1:image: apache/hadoop:3.3.6
hostname: datanode1
command:["hdfs","datanode"]env_file:- ./config
depends_on:- namenode
nodemanager1:image: apache/hadoop:3.3.6
hostname: nodemanager1
command:["yarn","nodemanager"]env_file:- ./config
depends_on:- datanode1
datanode2:image: apache/hadoop:3.3.6
hostname: datanode2
command:["hdfs","datanode"]env_file:- ./config
depends_on:- namenode
nodemanager2:image: apache/hadoop:3.3.6
hostname: nodemanager2
command:["yarn","nodemanager"]env_file:- ./config
depends_on:- datanode2
但是这么写显然是不够优雅的, 这里介绍
docker-compose --ver3
的写法:
depends_on:
此节点启动之前会检查前提条件是否满足,此处逻辑为datanode启动后才能启动nodemanager
version:"3"services:namenode:image: apache/hadoop:3.3.6
hostname: namenode
command:["hdfs","namenode"]ports:- 9870:9870env_file:- ./config
environment:HADOOP_HOME:"/opt/hadoop"ENSURE_NAMENODE_DIR:"/tmp/hadoop-root/dfs/name"datanode:image: apache/hadoop:3.3.6
command:["hdfs","datanode"]env_file:- ./config
deploy:replicas:3# 设置3个datanode实例resourcemanager:image: apache/hadoop:3.3.6
hostname: resourcemanager
command:["yarn","resourcemanager"]ports:- 8088:8088env_file:- ./config
volumes:- ./test.sh:/opt/test.sh
nodemanager:image: apache/hadoop:3.3.6
command:["yarn","nodemanager"]env_file:- ./config
deploy:replicas:3# 创建3个nodemanager副本,确保与datanode匹配depends_on:- datanode
只需要修改
replicas: #节点个数
即可
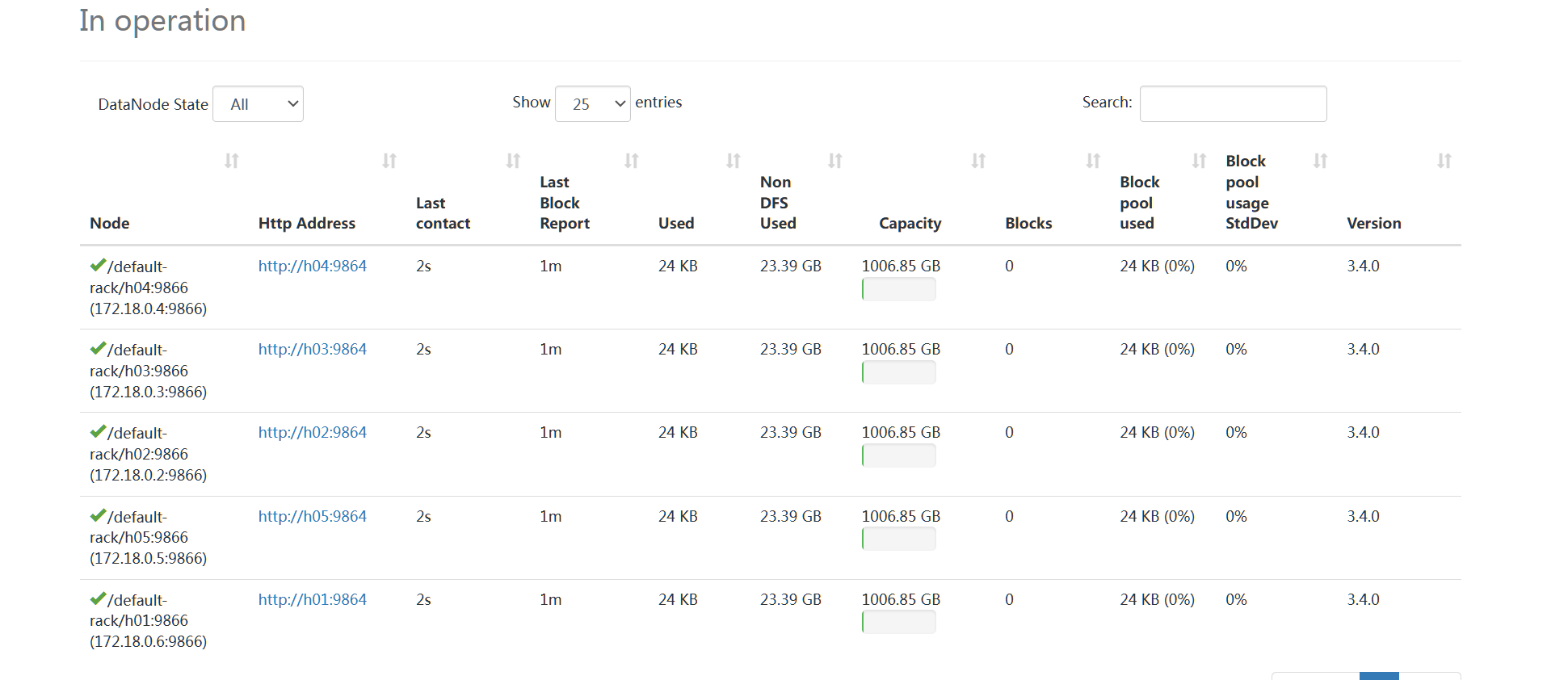
建立一个3 datenode的cluster:
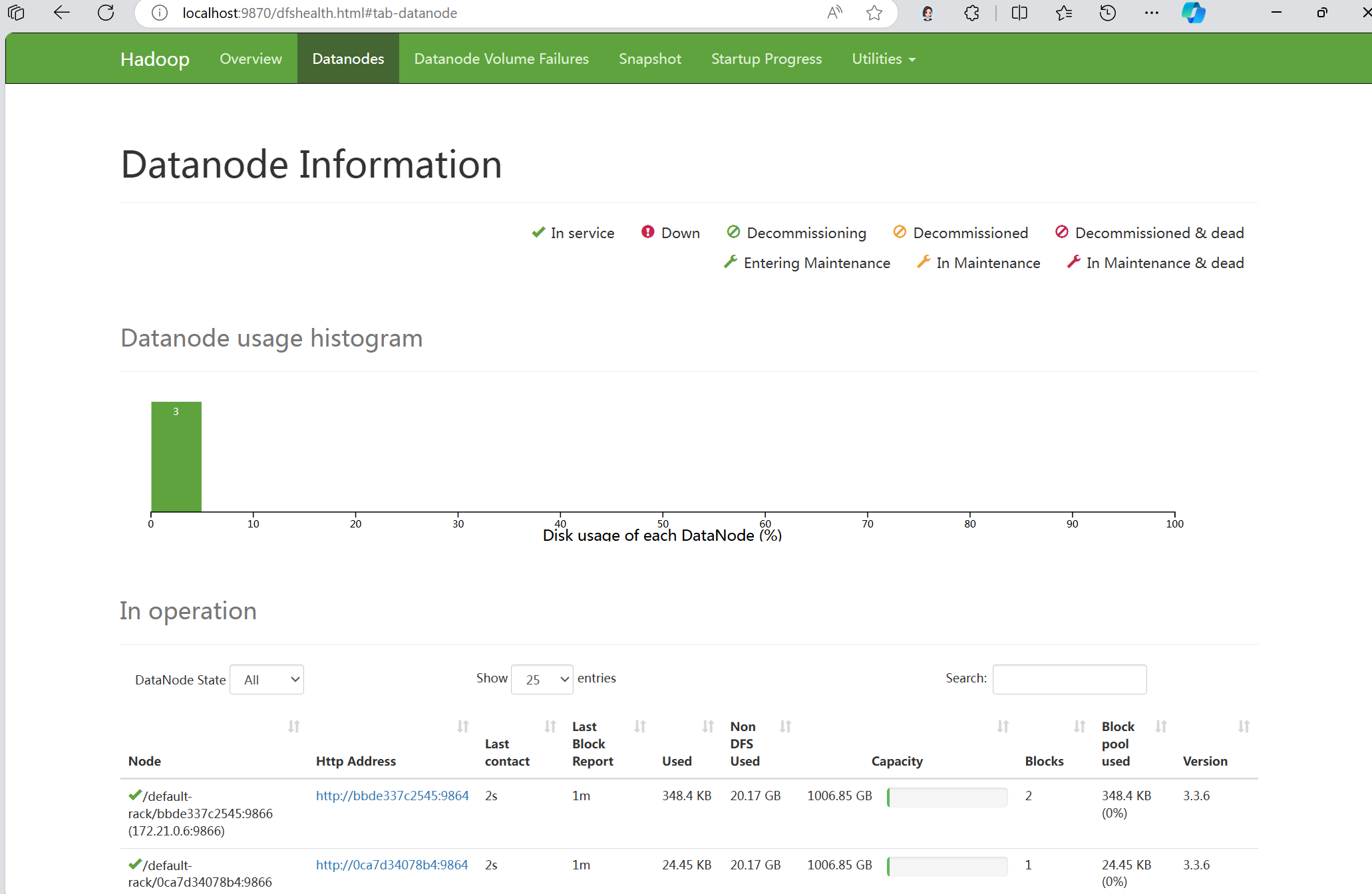
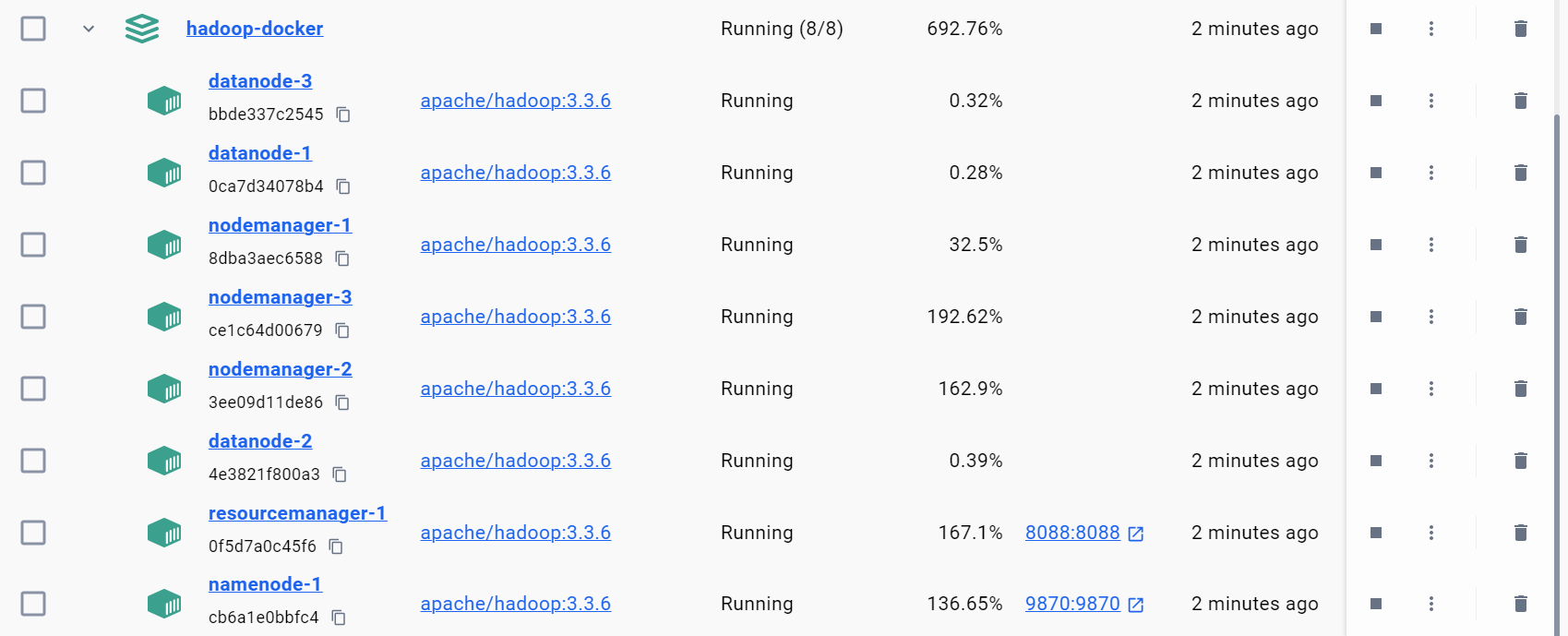
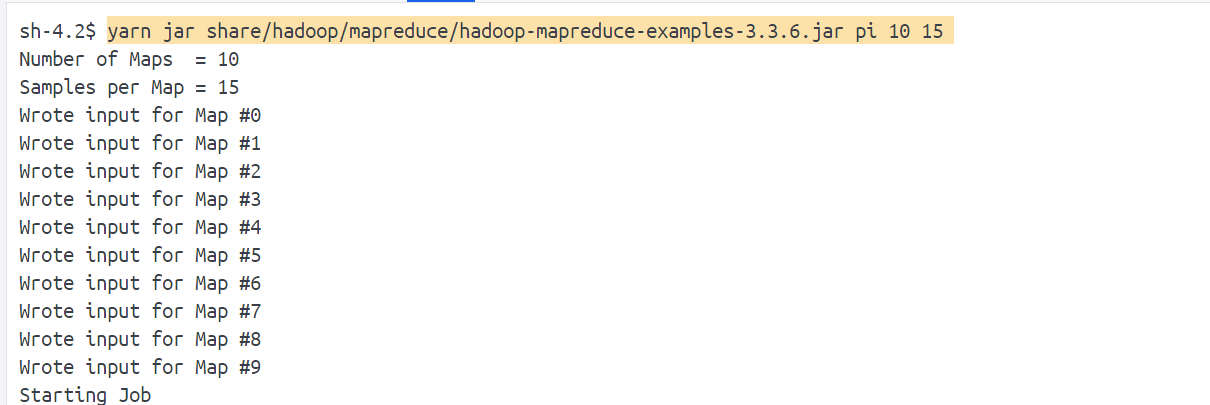
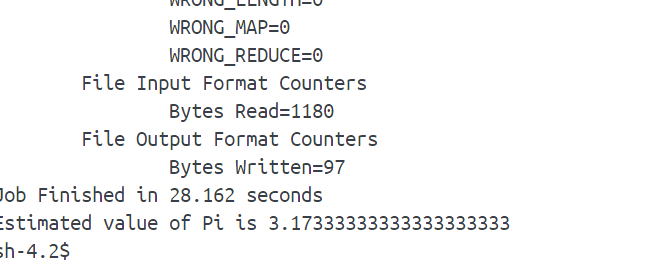
运行计算pi的示例程序:
版权归原作者 CLAYo 所有, 如有侵权,请联系我们删除。