
0 写在前面
程序员闯荡江湖的一生都在与数据打交道,初入江湖时基于 MySQL 的 CRUD,渐入佳境后利用 Redis 实现查询加速及分布式控制,本质上都是数据处理;无论主动/被动,都在利用数据来达成业务/技术目的。自然而然的,数据处理成为了计算机科学的重要研究方向。
我们也充分享受了这门学科发展带来的红利,或许你很难想象,在20世纪50年代之前,人们保存与检索数据的方式还是纸质文档 + 字典目录的人工排列;而现今我们能够依据对性能、事务支持、扩展性、一致性、成本等不同层面的需求,在不同数据库间自由选型。
而在此基础之上,人们又对数据处理能力提出了更高的要求,例如:PB级海量数据、秒级响应速度、Exactly-Once 语义、失败容忍、动态扩缩容等等,此时传统数据库便显得有些捉襟见肘。数据库毕竟更专注于提供存储服务而非计算服务,并且受制于不同的底层实现,其所能提供的计算规模、灵活程度、性能表现等也各不相同(例如 RDBMS 的表关联、事务支持就是 KV 型数据库所无法提供的,KV 型数据库的高性能又是 RDBMS 无法企及的;不同索引数据结构的差异,导致对于点查、范围查支持程度的不同)。当然,目前也存在 OceanBase、Hologres 这类原生高性能实时数据仓库,不在本篇的讨论范围内。
因此,存储介质无关的大数据计算引擎应运而生,提供大量通用的函数算子、支持超大型数据计算规模、分布式调度能力、高性能底层计算处理引擎、高可用中间状态存储等等等等一系列牛逼的能力,能满足一切你想要的。
本文便以大数据实时计算领域的事实标准——Flink为例,带你走进计算引擎的世界。
1 初入江湖:初识 Flink
未见其人先闻其声,来看看对于 Flink 相对官方的介绍:
Apache Flink 是一个用于流处理和批处理的开源分布式数据处理框架,它提供了高吞吐量、低延迟的数据处理能力,可以处理大规模数据并具有容错性。Flink 最初是由德国柏林工业大学的研究人员开发的,现在是 Apache 软件基金会的顶级项目之一。
从这段介绍中可以提取出几个关键词:
- Apache(牛逼)
- 流(Streaming)处理/批(Batch)处理
- 分布式
- 高吞吐/低延迟/大规模数据集/容错性···
1.1 Streaming/Batch
什么是流处理/批处理?全程叫:流数据处理/批数据处理,大数据计算引擎的两大核心分支。
「批」并不难理解,一批人、一批货、一批任务(你还认识「批」这个字不?),常见的用于描述数量的抽象单位,一切既定规模的实体都可以描述为「一批」。因此,批数据处理就是对于大小已知数据集的处理。
再说「流」,人流量、车流量、金额流水,都是在描述无边界、数量未知、源源不断的数据流动趋势。因此,流数据处理是对于实时生成、无边界数据集的处理。
简单来说,流是源源不断流动着数据的管道,批是既定规模的数据集。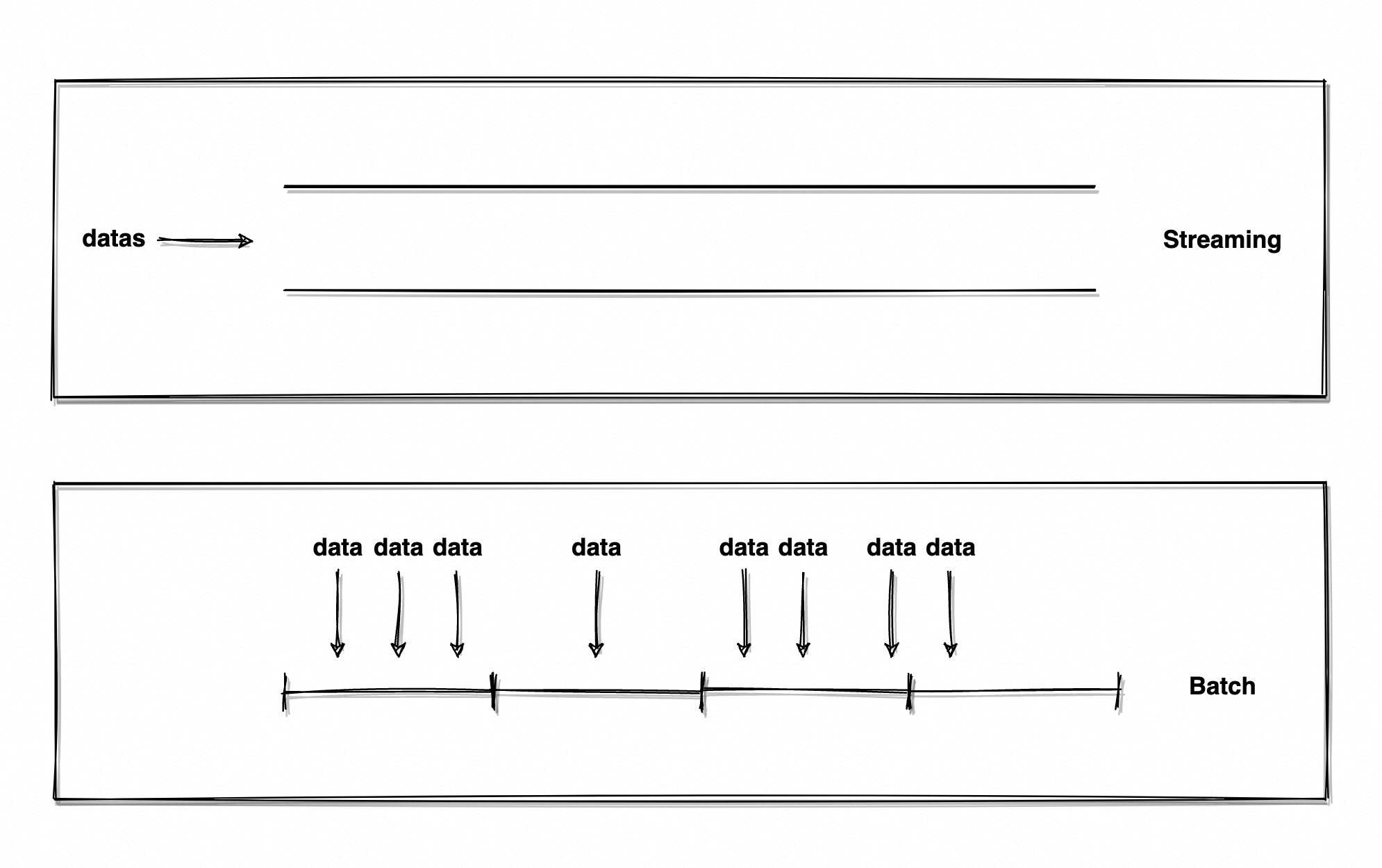
那「流」与「批」两个概念是否相悖呢?
为流加上“近1小时”、“近3天”的限定词,流有了边界、有了确定的范围,流就成了批;将批无限缩小,将每批数据的取值界限设定为1ms,批的实时性又无限接近于流。显然两者并不相悖,只是出发的视角不同,批可以是有边界的流、流也可以由无数个微型的批构成(Spark 便以此理念实现了流计算)。
这时有同学就说了:“这不小流吗?这我熟啊,我每天都 List.stream().map().collect()。”
在了解流的概念后,显然能够知晓这并不是真正意义上的流,只是套用了流式计算的理念——流计算提供了大量函数算子(如 map/filter/flatMap/sum),融合了函数式编程风格,风格类似对管道中元素分步处理。但必须要分清,这并不是真正的流、也不是真正的流计算,因为数据集是既定规模的、有边界的!一定要对流建立正确的认知!
再说回 Flink,其设计理念就是进行流数据处理,流又有着天然实时性和规模未知的特性,所以 Flink 被称为「大数据实时计算引擎」。现今 Flink 也支持了批计算,因为如上文所言“批就是有边界的流”,做一些简单的转换便可以实现批计算语义,因此 Flink 实际上是「流批一体计算引擎」。
1.2 分布式
分布式这个命题过于大,这里仅介绍分布式在 Flink 中的体现。实际这部分也是 Flink 运行时架构的核心内容,这里仅作枚举和简述,后续会进行详细介绍。
Flink 通常以分布式集群的形式运行,提到分布式集群就绕不开高并发/高可用/动态扩展等基本特性,Flink 也提供了这样的基础能力,内置 ZooKeeper 进行分布式环境协调及高可用保障。
Flink 架构包含四大组件:JobManager 作业管理器、ResourceManager 资源管理器、TaskManager 任务管理器、Dispatcher 分发器。每个组件都是一个 JVM 进程(Flink 用 Java + Scala 语言开发,运行于 JVM 之上),组件间通讯、Master 节点选举与高可用、动态扩缩容自然离不开分布式协调。
1.3 高级特性
Flink 具备「高吞吐/低延迟/大规模数据集/容错性」等高级特性,实际每个特性背后的实现都是门学问,这里只作简单的介绍。
- 高吞吐:Flink 程序通常运行在大型集群之上,再加之能灵活调整 Task/算子并行度、最大化利用集群资源,能够使数据处理能力达到极为夸张的水平。
- 低延迟:采用事件驱动模型,对输入事件进行实时处理;使用本地状态存储,减少网络通讯;异步化数据传输与网络通讯,最小化延迟。
- 大规模数据集:放不下就加内存加内存加内存,加机器加机器加机器。
- 容错性:Checkpoint 机制,定期保存作业执行状态 State 快照,故障发生/任务重启时可以利用 Checkpoint 快速恢复。
1.4 Why Flink?
也许大家还是会对「为什么用 Flink?」有疑问,笔者其实也很难以孤例让大家理解 Flink 的强大。以阿里巴巴 2018 年的公开数据为例:
- 运行总机器数 3000+
- 最大集群机器数 1500+
- 每秒支持实时计算次数 10 亿+
以笔者亲身体验来说,只要不是过于复杂的逻辑,基本单节点(单 TaskManager,类似 Worker 节点)就能支持千级别 RPS(Request Per Second,可以简单理解为吞吐量)实时计算;通过不断地调优与扩容(加机器加机器加机器),数十万级别 RPS 并不是难事。
所以,还就得是 Flink。
2 江湖新秀:初探 Flink
相信诸位对 Flink 已建立了基本认知,下面笔者会带领各位少侠,亲身感受这门武林绝学的强悍。但在这之前,还需要清楚什么是「数据处理」,才能知道怎么用 Flink 完成数据处理。
通用的数据处理可以抽象为 E-T-L三个环节:
- Extract 抽取:从不同数据源中获取数据。
- Transform 转换:按照使用方式或业务逻辑自定义数据转换逻辑,编写脚本/函数。
- Load 装载:装载到存储介质中,如数据库、消息队列等。
Flink 中的数据处理同样可以抽象为三个环节:
- Source:数据源读取。
- Transform:数据转换。
- Sink:数据输出。
不难发现两者概念上高度一致,因此 Flink 也不会跳出基本的数据处理流程与原则。
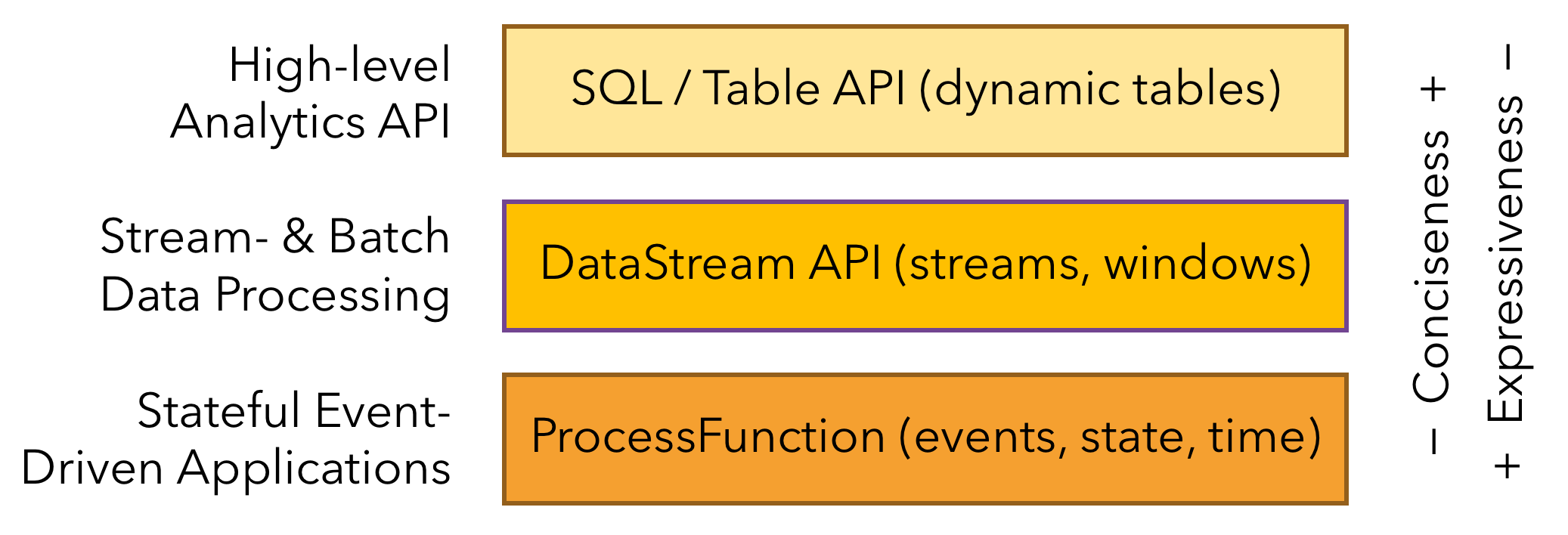
在使用层面 Flink 提供了多层 API(如图3),3 层 API 自上而下便利程度逐级降低、表达灵活程度逐级提高:
- SQL/Table API:最高层级,通用的结构化查询语言/数据定义语言,类似 DML/DDL。
- DataStream/DataSet API:核心 API,分别对应流/批(无界/有界)数据集计算,包含大量函数式计算 API,如 map/flatMap/sum/max/min/keyBy/window 等。
- Stateful Stream Processing:有状态流处理接口,由用户自定义流中事件的处理逻辑,并自行管理状态、时间属性等。过于底层,一般用不到。
得益于其提供的 SQL API,开发一个 Flink Job 实际就是写一段 SQL,写 SQL 也成了 Flink Job 开发最常用的方式。与 MySQL 语法基本完全一致,基本能想到的函数它都有,这使得 Flink 的入门门槛极低、使用极其方便,会写 SQL 基本就可以说自己会 Flink 了(当然了不建议这么说,还是谦虚一点)。
让俺们来动手写一写。
2.1 Flink SQL
本章节主要讨论“如何写出 Flink SQL”,再延伸到“怎么以流式思维写好 SQL”。上文提到 Flink 数据处理可抽象为 Source -> Transform -> Sink 三个环节,后续便以该结构展开讨论。
2.1.1 Source - 源表连接器
处理数据第一步要先读取数据,在Flink的世界里,构建与数据源链接的物质叫做「Connector 连接器」。
以最常见的 MySQL CDC(简称 MySQL)源表连接器为例,使用该连接器可以监听 MySQL 数据变动,类似于监听 binlog。如下代码块是 MySQL Connector 示例:
CREATETABLE mysqlcdc_source (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10,5),
product_id INT,
order_status BOOLEAN,PRIMARYKEY(order_id)NOT ENFORCED
)WITH(-- 连接器类型'connector'='mysql-cdc',-- 主机名'hostname'='<yourHostname>',-- 端口号'port'='3306',-- 账号'username'='<yourUsername>',-- 密码'password'='<yourPassword>',-- 数据库名称'database-name'='<yourDatabaseName>',-- 表名'table-name'='<yourTableName>');
显然这就是一段 DDL 语句,配置表字段以及元数据(WITH 参数,除连接地址/账号/密码等信息,还提供如批量读取条数、指定 binlog 消费点位、连接超时时长之类的高级特性可选用),Flink 就能够愉快读取到 MySQL 表的数据变化。简单到令人震惊,只需要一条简单的 DDL 语句,便可以实现数据流的接入,但实现原理显然没有用起来这么简单。
为什么只配置一句 DDL,就可以将源数据结构无损转换到流数据结构?为什么只靠一句 DDL,就能够实现流式语义的数据读取?
这对应两个极其重要的特性:流表对偶性(Duality)和持续查询(Continuous Queries),这两个特性赋予 Flink 将表转为流的能力,后续会重点介绍。
Flink 内置大量的 Connector,除了提到的 MySQL 还支持 Kafka、Socket、ElasticSearch、Hive 等等等等(见官方文档:https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/connectors/table/overview/),基本常用的队列/数据库都能找到。实在有邪门的数据源或者定制化需求还可以自定义,自行实现 Flink 提供的连接器模板,但这个区域还是以后再来探索吧。
2.1.2 Sink - 结果表连接器
读取数据后自然要写入数据,这种连接器被称为结果表连接器。它也是连接器的一种,使用方式与源表连接器基本无异:
CREATETABLE mysqlcdc_source (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10,5),
product_id INT,
order_status BOOLEAN,PRIMARYKEY(order_id)NOT ENFORCED
)WITH(-- 连接器类型'connector'='mysql',-- 主机名'hostname'='<yourHostname>',-- 端口号'port'='3306',-- 账号'username'='<yourUsername>',-- 密码'password'='<yourPassword>',-- 数据库名称'database-name'='<yourDatabaseName>',-- 表名'table-name'='<yourTableName>');
可以说是毫无差别,事实上就是一模一样的 DDL 语句,只不过 WITH 参数内声明了不同的连接器类型、及部分结果表特有的元数据。实现原理也与上一章提到的流表对偶性和持续查询息息相关,这里还是按下不表。
有了结果表连接器,就可以将计算结果写入特定的存储介质中。具备读/写的能力,就只差计算了。
2.1.3 Transform - 算子
Flink 精髓之处就在于大量的内置函数,而每个函数、每步转换都可以称为一个算子,对算子做组合就是 Transform。
说半天其实就是在写 SQL,老本行了,这也是为啥上文说会 SQL ≈ 会 Flink。
BEGIN STATEMENT SET;INSERTINTO`sink`SELECT
id AS subscription_id
,typeAS subscription_type
,age AS user_age
,trim(sexual)AS user_sexual
,CASEWHEN age <18THEN1ELSE0ENDAS is_minor
FROM`source`END;
如上代码块,只比普通 SQL 多了写入逻辑开始/结束的声明(该声明在只有一条 INSERT 语句时可以不加,多条 INSERT 时需要用该声明括起来),具体写法和内置函数算子(见官方文档:https://nightlies.apache.org/flink/flink-docs-master/zh/docs/dev/table/functions/systemfunctions/)这里不作赘述。
「算子」篇主要聊聊 Flink 最强大的算子——时间窗口算子,这是使得实时计算引擎如此不同的根本所在。
「时间」是 Streaming 的丈量尺度(Streaming 中每个元素,都对应绝对时间坐标轴上一个点),也是实时性的体现基准(实时性强弱计算公式:
m
=
T
c
u
r
r
−
T
e
v
e
n
t
m = T_{curr} - T_{event}
m=Tcurr−Tevent,m 越小实时性越强),是至高神一般的存在。
在 Batch/离线计算中,时间就显得没那么重要——数据源天然被划分好了时间属性(有界数据源,「界」通常就是时间边界,或是可以转换成时间边界),时效性通常不作强要求(通常采取 T 计算 T - 1 数据,有延误可以通过重跑补偿)。
正是由于「时间」在 Flink 中的崇高地位、与人们对计算实时性的强要求不谋而合,致使大家选择了 Flink。所以,是我们选择了时间,而非时间选择了我们。
所以,Flink 到底为什么需要时间?
2.1.3.1 时间
脱离时间谈实时性没有意义、甚至谈流计算也没有意义——没有人需要从盘古开天辟地起的某个指标,通常需要的是“本月某品类产品的营业额”、“当日某景区的客流量”、“当前小时某工厂制造元件的坏品率”;也没有人2024年看1995年的指标,人们更想感知一瞬间的实时变化趋势。
所以 Flink 通常将「时间」作为计算起止的界限,Streaming 没有边界,必须有人为限定的边界作为计算触发条件,例如上面提到的本月/当日/当前小时。
时间的精准程度直接决定了计算结果的精准程度,试想元素乱序(某商品最近一次的成交价格,先产生的元素由于网络异常后到达)、元素延迟到达(某商品近一小时内的总成交额,部分元素时间延迟导致被划分到错误的时间窗口,甚至直接丢弃)会对计算会造成多大影响。
因此 Flink 提供了「处理时间 Processing Time」和「事件时间 Event Time」。
「处理时间」是 Flink 所能提供最简单的时间属性,可以简单理解为机器的系统时钟,使用上没有任何心智负担。但同时也带来了最差的保障性——当元素流入的先后顺序并非其原本的生产顺序(如数据源网络异常消息延迟下发,或不同机器节点由于负载情况不同、出现了消费吞吐量差异,发往下游顺序错乱),Flink 完全无法感知。
因此更常用的是「事件时间」,通常由使用者自行将时间属性写入元素内,再于Flink中提取对应属性作为元素的时间戳。如此一来,哪怕元素以混乱的时钟顺序进入 Flink,也能用事件时间重新扭转。
但这只解决了乱序,还有更致命的延迟。这里涉及一个更复杂的概念:Watermark 数据水位,专门用于解决延迟问题,后续会重点介绍。
了解了时间在 Flink 中的重要性,Flink 对时间的使用更是得心应手。
2.1.3.2 滚动窗口
上一章提到“没有人需要从盘古开天辟地起的某个指标”,指标通常带有确定的时间界限:天级、小时级、分钟级、秒级,就是在为元素划分好「时间窗口」,再计算每个窗口内的指标,而最简单常用的时间窗口就是「滚动窗口 Tumble」。
「滚动窗口」通常具有固定的大小,且每个窗口不重叠,如图5所示的时间轴就由 [0, 5) 、 [5, 10) 两个滚动窗口组成,它们没有任何重叠部分。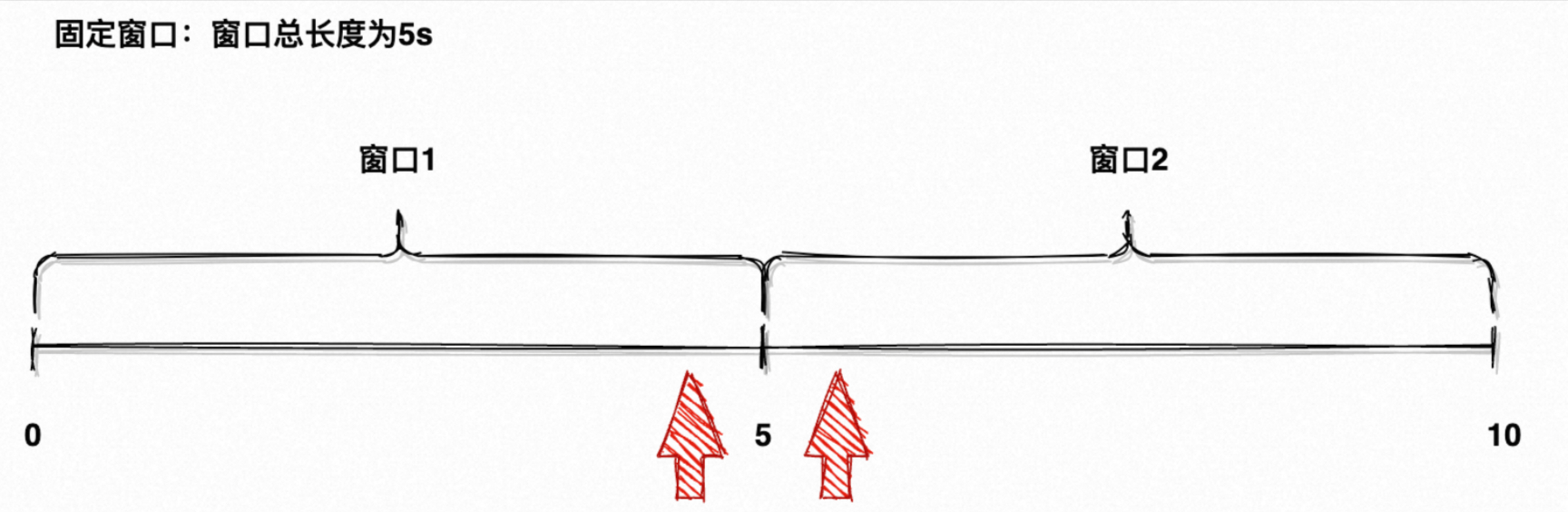
指定元素时间对应字段和时间窗口长度,元素就被分组到了所处时间窗口内,此时再计算对应窗口内的数据,如求聚合值、最大最小值等。
CREATETEMPORARYTABLE user_clicks(
username varchar,
click_url varchar,
eventtime varchar,
ts AS TO_TIMESTAMP(eventtime),
WATERMARK FOR ts AS ts -INTERVAL'2'SECOND--为Rowtime定义Watermark。)WITH('connector'='sls',...);CREATETEMPORARYTABLE tumble_output(
window_start TIMESTAMP,
window_end TIMESTAMP,
username VARCHAR,
clicks BIGINT)WITH('connector'='datahub'--目前SLS只支持输出VARCHAR类型的DDL,所以使用DataHub存储。...);INSERTINTO tumble_output
SELECT
TUMBLE_START(ts,INTERVAL'1'MINUTE)as window_start,
TUMBLE_END(ts,INTERVAL'1'MINUTE)as window_end,
username,COUNT(click_url)FROM user_clicks
GROUPBY TUMBLE(ts,INTERVAL'1'MINUTE),username;
如上代码块,TUMBLE 函数有两个参数:
- 第一个参数“ts”代表元素时间戳字段(时间字段需要在连接器中指定,可用处理时间或事件时间);
- 第二个参数“INTERVAL ‘1’ MINUTE”意为窗口长度为1分钟。
再配合 TUMBLE_START/TUMBLE_END 函数获取窗口起始/结束时间,便可以得到每个窗口内的计算结果(如图5)。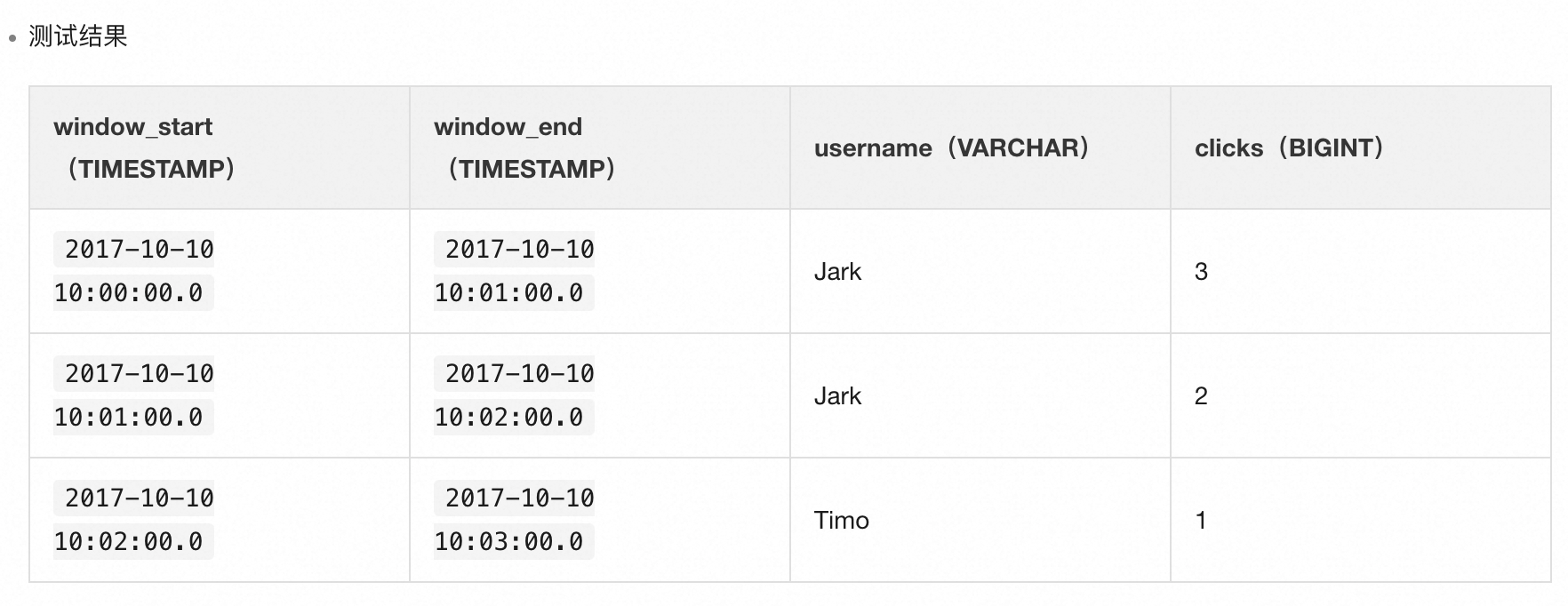
2.1.3.3 滑动窗口
「滑动窗口 Hop」比滚动窗口更丝滑,其由长度 + 步长两个参数组成,长度代表计算窗口的总长度,步长代表每次滑动的步长。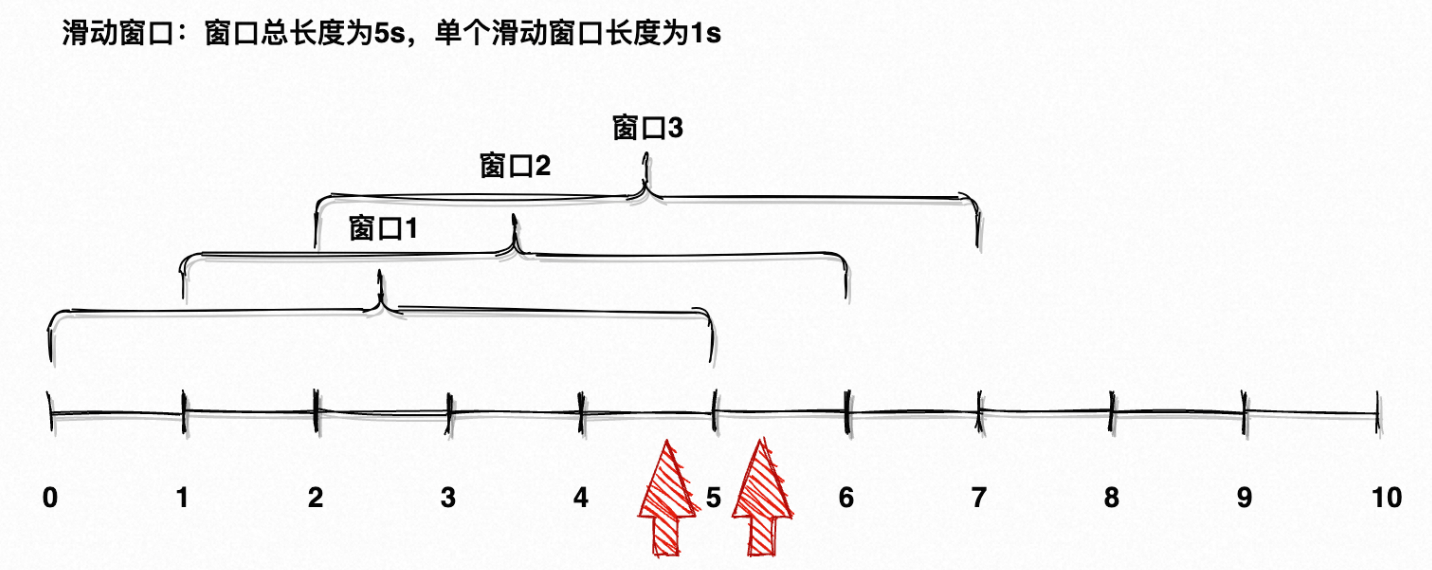
如图7所示是长度为 5s、步长为 1s 的滑动窗口,每次滑动步长1s;这意味着每个滑动窗口会与上个窗口有 4s 的重叠,数据的变化会更加平滑(具体原理可以自行搜索)。
CREATETEMPORARYTABLE user_clicks (
username VARCHAR,
click_url VARCHAR,
eventtime VARCHAR,
ts AS TO_TIMESTAMP(eventtime),
WATERMARK FOR ts AS ts -INTERVAL'2'SECOND--为Rowtime定义Watermark。)WITH('connector'='sls',...);CREATETEMPORARYTABLE hop_output (
window_start TIMESTAMP,
window_end TIMESTAMP,
username VARCHAR,
clicks BIGINT)WITH('connector'='datahub'--目前SLS只支持输出VARCHAR类型的DDL,所以使用DataHub存储。...);INSERTINTO
hop_output
SELECT
HOP_START (ts,INTERVAL'30'SECOND,INTERVAL'1'MINUTE),
HOP_END (ts,INTERVAL'30'SECOND,INTERVAL'1'MINUTE),
username,COUNT(click_url)FROM
user_clicks
GROUPBY
HOP (ts,INTERVAL'30'SECOND,INTERVAL'1'MINUTE),username;
HOP 函数使用方法与滚动窗口基本一致,只是多传入了一个步长。如上代码块代表窗口长度与步长分别为1分钟和30秒,意为每30秒计算一次过去1分钟的数据,与滚动窗口最显著的差异就是有30秒的窗口重合。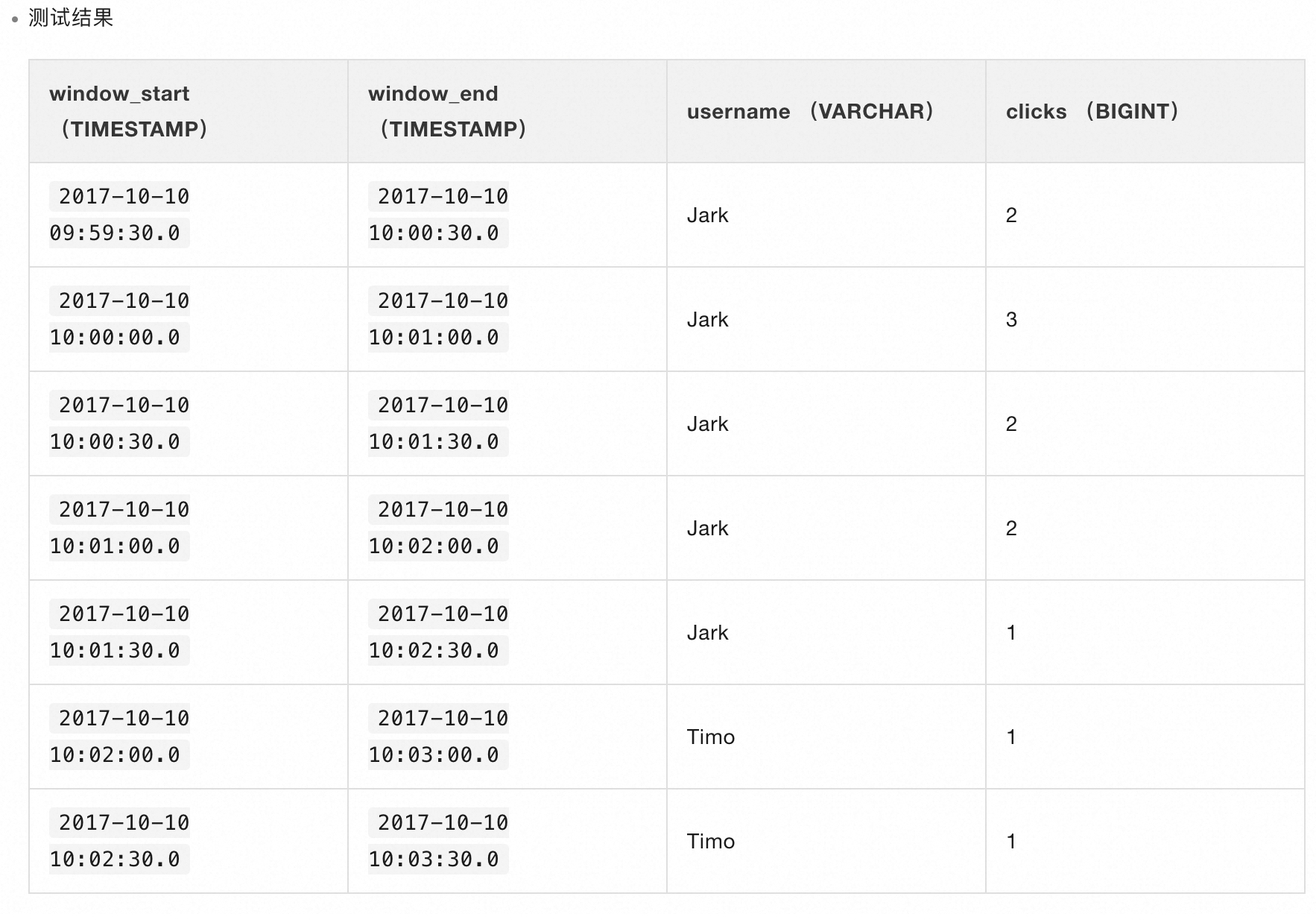
从图7的计算结果可以看出,每30秒触发一次计算,计算过去1分钟内窗口的数据。
2.1.3.4 会话窗口
「会话窗口 Session」比较有意思,没有窗口大小、也没有窗口重叠,而是以会话开启/断开时机作为窗口。会话窗口会定义一个时间间隔(Gap),如果在该时间间隔内有元素产生,则会一直续期该窗口,反之则关闭窗口、输出结果。
以时间间隔30分钟举个例子:
- 00:00 元素进入,开启会话窗口,此时会话窗口为 [00:00, 00:30] ;
- 00:15 元素进入,续期窗口,此时会话窗口为 [00:00, 00:45] ;
- 00:35 元素进入,续期窗口,此时会话窗口为 **[00:00, 01:15] **;
- 01:15 会话窗口关闭,输出结果;
- 01:35 元素进入,开启新会话窗口,此时会话窗口为 [01:35, 02:05] ;
- ······
CREATE TEMPORARY TABLE user_clicks(
username varchar,
click_url varchar,
eventtime varchar,
ts AS TO_TIMESTAMP(eventtime),
WATERMARK FOR ts AS ts - INTERVAL '2' SECOND --为Rowtime定义Watermark。
) WITH (
'connector'='sls',
...
);
CREATE TEMPORARY TABLE session_output(
window_start TIMESTAMP,
window_end TIMESTAMP,
username VARCHAR,
clicks BIGINT
) WITH (
'connector'='datahub' --目前SLS只支持输出VARCHAR类型的DDL,所以使用DataHub存储。
...
);
INSERT INTO session_output
SELECT
SESSION_START(ts, INTERVAL '30' SECOND),
SESSION_END(ts, INTERVAL '30' SECOND),
username,
COUNT(click_url)
FROM user_clicks
GROUP BY SESSION(ts, INTERVAL '30' SECOND), username;
会话窗口通常用于用户短活跃时间内的数据统计,如用户登录以来所有的浏览记录,超过10分钟没有操作视为会话断开,停止统计。
2.1.3.5 OVER 窗口
「OVER 窗口」比较特殊,它认为每个元素都是一个窗口,每个窗口都有自己的时间戳;实际分为两种模式,合并过去 N 个窗口(实际就是 N 个元素)/合并过去N分钟对应的窗口,再进行最终结果计算。并且,它是唯一可以实时触发的窗口函数,前面3个窗口函数的触发时机都是窗口结束,而 OVER 窗口可以来一个输出一条、来一个输出一条。
有点抽象,直接通过例子来看吧。
-- 以Bounded ROWS OVER Window场景为例。-- 假设,一张商品上架表,包含有商品ID、商品类型、商品上架时间、商品价格数据。-- 要求输出在当前商品上架之前同类的3个商品中的最高价格。SELECT
itemID,
itemType,
onSellTime,
price,MAX(price)OVER(PARTITIONBY itemType
ORDERBY onSellTime
ROWSBETWEEN2precedingANDCURRENTROW)AS maxPrice
FROM tmall_item;
如上代码块使用了 Rows Over Window,以 itemType 为分区键、以 onSellTime 为时间字段倒序排序、向前追溯2个窗口,计算 Max(price)。简单来说,就是以一个时间字段排序,往前追溯 N 行作为一个窗口计算。
-- Bounded RANGE OVER Window场景为例。-- 假设一张商品上架表,包含有商品ID、商品类型、商品上架时间、商品价格数据。-- 需要求比当前商品上架时间早2分钟的同类商品中的最高价格。SELECT
itemID,
itemType,
onSellTime,
price,MAX(price)OVER(PARTITIONBY itemType
ORDERBY onSellTime
RANGE BETWEENINTERVAL'2'MINUTEprecedingANDCURRENTROW)AS maxPrice
FROM tmall_item;
如上代码块使用了 Range Over Window,以 itemType 为分区键、以 onSellTime 为时间字段倒序排序、向前追溯2分钟,计算 Max(price)。简单来说,就是以一个时间字段排序,往前追溯N分钟内元素作为一个窗口计算。
数据计算通常由「时间量级」和「指标聚合」两部分组成,Flink 窗口函数大大简化了时间计算语义,再配合丰富的内置函数,使其变得极容易上手。
2.1.4 Join - 表连接
「表连接 Join」大家都不陌生,通过特定条件构建表与表之间关联关系,达成补充/拓宽数据维度的效果。作为数据库广为流传的传统艺能,Flink SQL 自然也是支持的。
传统的 Join(换句话说是批处理中的 Join)是两张表通过某个键进行逻辑关联,如下代码块是将订单表 order_record 与用户信息表 user_info_record 通过用户id进行关联,补充订单表中不存在的用户信息。
SELECT
A.id,
A.order_id,
A.price,
A.user_id,
B.user_name,
B.user_sexual,
B.user_age
FROM order_record A
LEFTJOIN user_info_record B
ON A.user_id = B.user_id
ORDERBY A.gmt_create descLIMIT100;
在关联关系左侧的表通常被称为「事实表 Fact Table」,右侧的表为「维表 Dimension Table」。依据数据库第三范式:独立性,事实表中通常只存储与当前行为强相关的信息(当然这并不绝对,有时也会视情况冗余一些字段),因此需要维表进行事实表的维度补充。
在流式计算中构建表连接显然更具有挑战性——事实表是一个流,随时都会发生变化,表连接也要随时触发吗?维表在流式计算中又该如何描述、也能够被定义为流吗?
2.1.4.1 维表 & 流表
维表相较事实表有几个显著差异:
- 变化频率更低:相较于事实表随时可能插入/修改,维表的信息相对固化,如城市编码信息、用户地址信息。
- 维度更收敛:事实表通常含括一种行为对应的所有信息,如订单包含商品、用户、物流、评价、交易等信息,而一张维表通常只会包含一个维度的信息。
- 数量级更小:相较事实表来说,一个维度通常不会有过多的可选项(甚至是枚举值),因此数据量会少很多。
在传统数据仓库中,维表与事实表的差异只存在于逻辑层面;但在流式计算中,维表与流表基本是两个独立的概念,因为「时间」是流式计算的一等公民。Flink 为何要花这么大功夫区分这两种语义,大家不妨先自己思考一下。
从维表的定义其实就能看出一二,维度是对事实的补充,这意味着维表不会作为驱动计算的主体,自然也就没必要像流一样实时流入元素。
其次,维表数据的变化频率较低,通常在小时级或天级;实时性不高的数据可以采取一定的缓存措施,避免每次查询都产生网络 IO,这也与流的强时效性不同。
最后最重要的一点,维度是事实的附庸,因此维度的时间来源于事实的时间;换言之,维度不具有独立的时间属性,或者说他自身具有的时间毫无意义,必须依附于事实才有意义。说得再通俗一点,今天发生的事实,只有今天的维度于其才有意义。
TimestampStreaming emitDimension version12024-06-01 00:00:002024-06-01 00:00:002024-06-01 00:00:0022024-06-01 06:00:002024-06-01 06:00:002024-06-01 06:00:0032024-06-01 12:00:002024-06-01 12:00:002024-06-01 12:00:0042024-06-01 18:00:002024-06-01 18:00:002024-06-01 18:00:0052024-06-02 00:00:002024-06-02 00:00:002024-06-02 00:00:0062024-06-02 00:00:002024-06-01 00:00:00 (乱序)2024-06-02 00:00:00
有点绕,举个例子大家就懂了。流中元素因为一些原因出现了延迟,6月1日发生的事件延迟了整整一天、于6月2日才流入下游,维表数据此时已经更新到了最新版本6月2日;但对于延迟的事件来说,它需要的维度一定是6月1日,6月2日的维表数据确实是最新鲜的、最实时的,但没有意义。
对于这个例子而言,查询条件是:关联键 + 事件时间,也就是找到历史版本的时间快照。因此维表在Flink当中其实是「历史表 Temporal Table」,是种具有时间/版本属性的表,这样就满足了找到任何时间线版本、而非最新版本数据的诉求,这是流无法实现的。
2.1.4.2 维表/历史表连接器
为了区分这类特殊的数据源,Flink 提供了「维表/历史表连接器」。
createTEMPORARYtable`dimension_table`(`user_id`VARCHAR,`user_name`VARCHAR,`user_age`VARCHAR,`user_sexual`VARCHAR,`user_weight`VARCHAR,PRIMARYKEY(`user_id`)NOT ENFORCED
)with('connector'='mysql','endpoint'='****','project'='****','tablename'='****','accessid'='****','accesskey'='****'-- 读取最大记录数,最好大于实际值,'maxRowCount'='100000000'-- 动态最大分区,'partition'='max_pt()'-- 缓存策略,仅支持ALL,'cache'='ALL'-- 缓存超时时间,默认空,即永不过期 + 不reload缓存;需要设置该过期时间,才会刷新新分区!!!,'cacheTTLMs'='3600000');
维表连接器在元数据上多了数据缓存策略相关配置,维表数据通常固化,没必要每次都去发起查询(向外部存储介质发起网络 IO),因此可以采用一定的缓存策略:
- None(默认值):不使用缓存,每次都发起查询,一般只有在实时性极强的维表场景才会使用。
- LRU:最近使用缓存策略,配合缓存大小、缓存超时时间使用。
- ALL:全量缓存策略,在作业启动时一次性将所有维表数据读取进内存,配合缓存超时时间使用。
维表对作业的影响通常在于查询效率以及内存占用,需要根据维表数据特性选取合适的维表存储介质(更推荐 KV 型存储,如 HBase/Redis)和缓存策略,笔者在这里就踩了许多坑,后续会专门介绍。
2.1.4.3 流表 Join
流表 Join 是将流与维表进行关联,需要构建与维表主键的关联关系并指定时间属性。
SELECT
A.id,
A.order_id,
A.price,
A.user_id,
B.user_name,
B.user_sexual,
B.user_age
FROM order_record A
LEFTJOIN user_info_record FOR SYSTEM_TIME ASOF PROCTIME()AS B
ON A.user_id = B.user_id
“FOR SYSTEM_TIME AS OF PROCTIME()”意为获取处理时间时刻的表快照,Flink 目前只支持使用处理时间,后续会支持事件时间。
2.1.4.4 双流 Join
双流 Join 就有点意思了,笔者第一次听到这个玩意儿的时候脑子里完全没概念,这两边都是无界数据流咋 join 啊?谁 join 谁啊?
Join 说白了就是拿着一边的数据去另一边找,在流表 Join 场景下为拿着流里的元素去维表里找,因为只有流驱动计算;双流 Join 本质就是相互的过程,左侧流元素来了去右侧流里找找、右侧流元素来了去左侧流里找找。前提是两侧流的元素都得先保存下来,才能实现一侧来了去另一侧找,这就引出了 Flink/流式计算状态 State 这一概念。
Flink 十分依赖状态,比如现在讨论的双流 Join,就需要将左右侧流的元素分别维护在自己的状态中,待任意一侧元素流入、去对侧的 State 中进行 Join 计算,这被叫作「算子状态 OperatorState」。大部分算子都会维护一份自身的 State(也叫作有状态算子 Stateful Operator),例如上文提到的 Window 算子,也需要 State 存放时间窗口内的元素。一来是算子确实需要数据暂存的区域;二是算子需要保存中间结果,计算通常建立在中间结果基础之上,例如求和算子不可能每次都对全量数据发起重新计算,这不现实。
言归正传,画个图来理解一下双流 Join 的流程,仍然以上面的订单表 Join 用户信息表为例。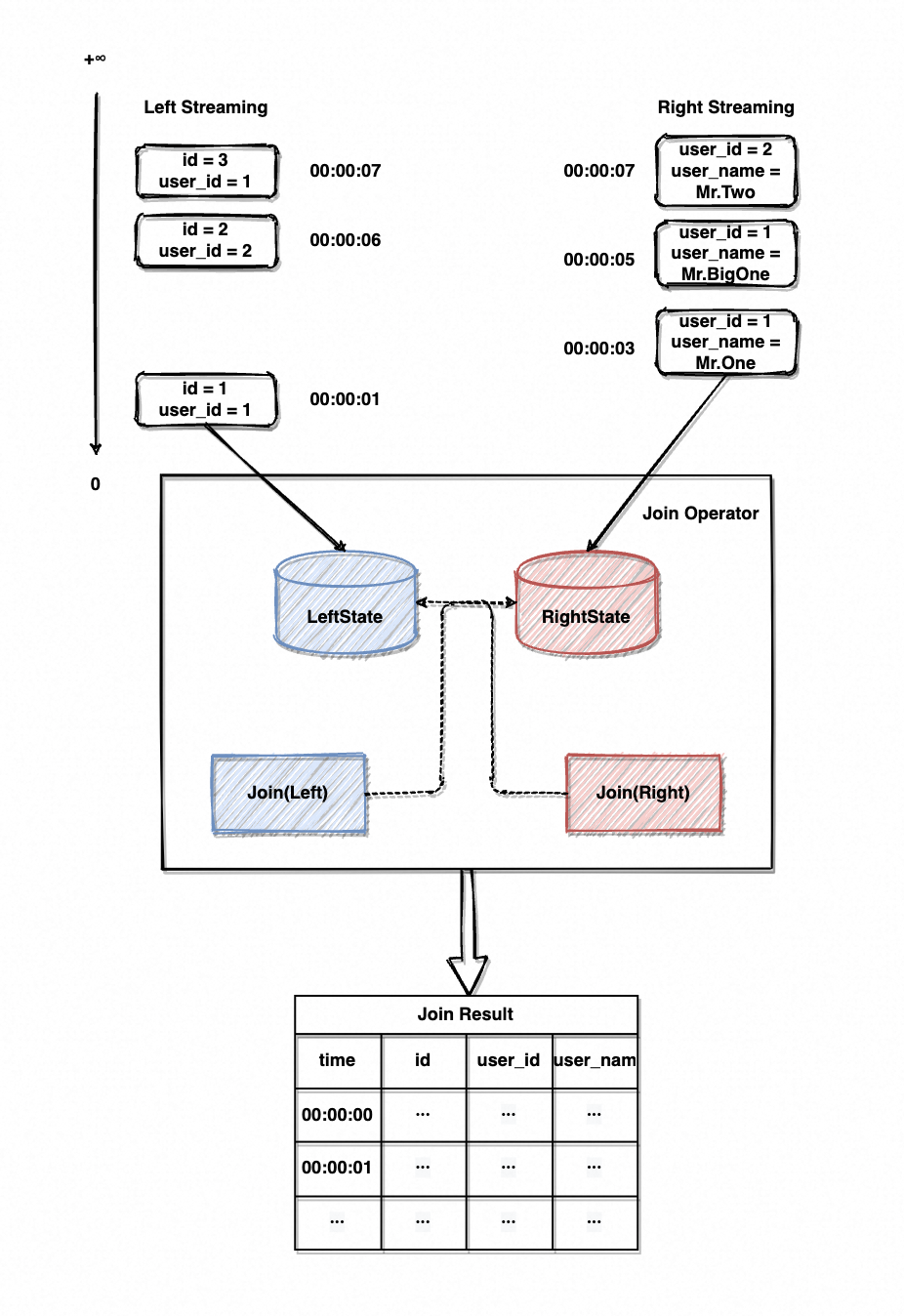
在双流 Join 场景下,Join 算子会维护两侧流的 State(如图8中的 LeftState/RightState)。元素流入 Join 算子后会先暂存进 State 中,再触发 Join 计算、去另一侧的 State 中寻找可关联的元素。
如图9的双流 Join 示例,左侧流会流入订单id/用户id、右侧流会流入用户id/用户名,以用户id作为关联键进行 Join 计算。Join 过程示意大致如下:
timeiduser_iduser_nameis_retract100:00:00nullnullnullnull200:00:0111nullfalse300:00:02nullnullnullnull400:00:0311nulltrue511Mr.Onefalse600:00:04nullnullnullnull700:00:0511Mr.BigOnefalse800:00:0622nullfalse9****00:00:07
| 2 | 2 | null | true |
| 10 | | 2 | 2 | Mr.Two | false |
| 11 | | 3 | 1 | Mr.One | false |
| 12 | | 3 | 1 | Mr.BigOne | false |
表头从左至右分别代表行数、时间、订单id、用户id、用户名、是否为回撤操作,再来逐行分析:
- 无事发生。
- 左流来了一个元素、放入 LeftState 中,去 RightState 寻找 user_id = 1 的记录,未找到所以 user_name 补 null。最终向下游输出 1/1/null 。
- 无事发生。
- 右流来了一个元素、放入 RightState 中,去 LeftState 寻找 user_id = 1 的记录,找到1条记录。首先可以输出一条 1/1/Mr.One 的记录,但 LeftState 中该元素已经被计算并产生了结果(对应第2行的 1/1/null ),且该结果是不完整的结果;在右流已经能够补充左流时,之前输出的结果显然是不准确的,应当以当前结果为最终结果。 因此,实际产生了2次结果输出,一次正向的输出(1/1/Mr.one)、一次逆向的撤回(1/1/null),这种撤回输出也叫回撤 Retract,是一种特殊的输出流,可以将之前输出的不完整/错误结果撤回。
- 同4。
- 无事发生。
- 右流来了一个元素、放入 RightState 中,去 LeftState 寻找 user_id = 1 的记录,找到1条记录;最终向下游输出 1/1/Mr.BigOne。
- 左流来了一个元素、放入 LeftState 中,去 RightState 寻找 user_id = 2 的记录,未找到所以 user_name 补null。最终向下游输出 2/2/null 。
- 右流来了一个元素、放入 RightState 中,去 LeftState 寻找 user_id = 2 的记录,找到1条记录。 场景同4,最终向下游输出正向的 2/2/Mr.Two、逆向的 2/2/null。
- 同9。
- 左流来了一个元素、放入 LeftState 中,去 RightState 寻找 user_id = 1 的记录,找到2条记录。最终向下游输出 3/1/Mr.One 、 3/1/Mr.BigOne。
- 同11。
Left Join/Right Join/Inner Join本质上都是一样的过程,以 State 作为状态存储,由元素流入事件触发计算,输出正向(输出)/逆向(撤回)事件。
但这个过程显然有脆弱的环节,比如可预见的 State 容量膨胀、大量输出 null 事件产生的数据倾斜、多流 Join 是否会产生新的风暴?后续调优环节会探讨这些问题。
2.2 流式计算 SQL
看完 Flink SQL 章节,相信同学们对于「如何写」已经有了底气,但要「如何写好」又是另一门学问。本文一直在强调“流式计算是一项技术、更是一种理念”,流式计算倾向于描述:对流这种特殊载体的处理流程以及对变化事件的响应模式。
为何要这么说,还是可以拿更传统的批处理作对比。
批处理是完美的面向过程编程,对已知的数据分步骤处理、朝向最终期望的结果进发。可以发现当处理主体不可变时,唯一需要考虑的就是如何清晰地描述步骤,五步化作三步也无所谓,甚至一步到位也 OK。
但这套理念套在 Streaming 上显然不成立,流式计算的主体是事件,是随时可产生、可变化、可伸缩的;不管你愿不愿意,事件/元素会不断流入。这意味着必须明确每个处理环节该做什么,处理好所有异常、边界、逻辑,否则流会因为某个环节的异常而整个 Crash。
这种场景下其对于 SQL 的要求便更严格,SQL 的好坏直接影响到了执行计划的生成,而执行计划又对应了无数个执行节点,节点间的影响是相互的且无法估量的。如同一条由无数中转站连接的航道,任一站点异常都会影响整条航道的正常运转(例如产生反压 BackPressure,后续章节会介绍)。并且这对后续排查问题是极为重要的,如果作业的执行计划十分清晰,你就能快速定位到异常的执行节点,通过优化节点配置/算子来消除问题。
因此,在编写流式计算 SQL 时有几个原则:
- 构思清晰的执行计划
- 以事件为主体的响应式处理
- 尽可能编写完美的函数
也是老生常谈的「低耦合,高内聚」,尽可能保证每步处理的原子性。
在 Flink SQL 中,可以采用「视图 View」来清晰地描述计算步骤、编写流式 SQL。举个简单例子,现在要计算订单中不同城市用户、对于不同消费金额的偏向水平,俗称城市级消费水平。
这个过程可以描述为:
- 按业务对于金额的分阶进行订单金额划分,这里以每百元作为分阶模式。
- 按省份对订单区域进行划分,需要将省份编码转换为对应名称。
- 统计不同城市、不同消费金额阶级的总数。
//简单的数据提取CREATETEMPORARYVIEW`original`ASSELECT
total_price AS price
,province_code AS province
FROM`order_info`;//数据转换CREATETEMPORARYVIEW`price_rank_calculate`ASSELECT
FLOOR(price /100)AS price_rank
,code_to_name(province)AS province
FROM`original`;//group byCREATETEMPORARYVIEW`price_rank_group_by`ASSELECT
province,
price_rank,count(*)as total_count
FROM`price_rank_calculate`GROUPBY province, price_rank
;//sinkBEGIN STATEMENT SET;INSERTINTO`result`SELECT*FROM`price_rank_group_by`;END;
一定要将过程描述清晰,千万不要担心步骤过多(或者是字数过多)对性能产生影响,Flink 会根据 SQL 生成最优执行计划(例如进行算子合并等),因此描述得越清晰越细致、对于执行计划的生成就越有利。
3 江湖少侠:Flink 核心概念
本章会介绍是什么支撑了 Flink 以及流式计算、是什么使它变得如此美丽且不同,前面卖的所有关子,都会在这一章揭晓。笔者相信,这会成为你真正走进 Flink 以及 Streaming Compute 至关重要的一步。
3.1 流表对偶性 Duality
3.1.1 MySQL binlog
binlog(Binary Log,二进制日志) MySQL 中极为重要的组件,是实现数据恢复、主从同步、增量监听的核心。binlog 记录了数据库所有执行的 DDL 与 DML,简言之为所有的变更操作。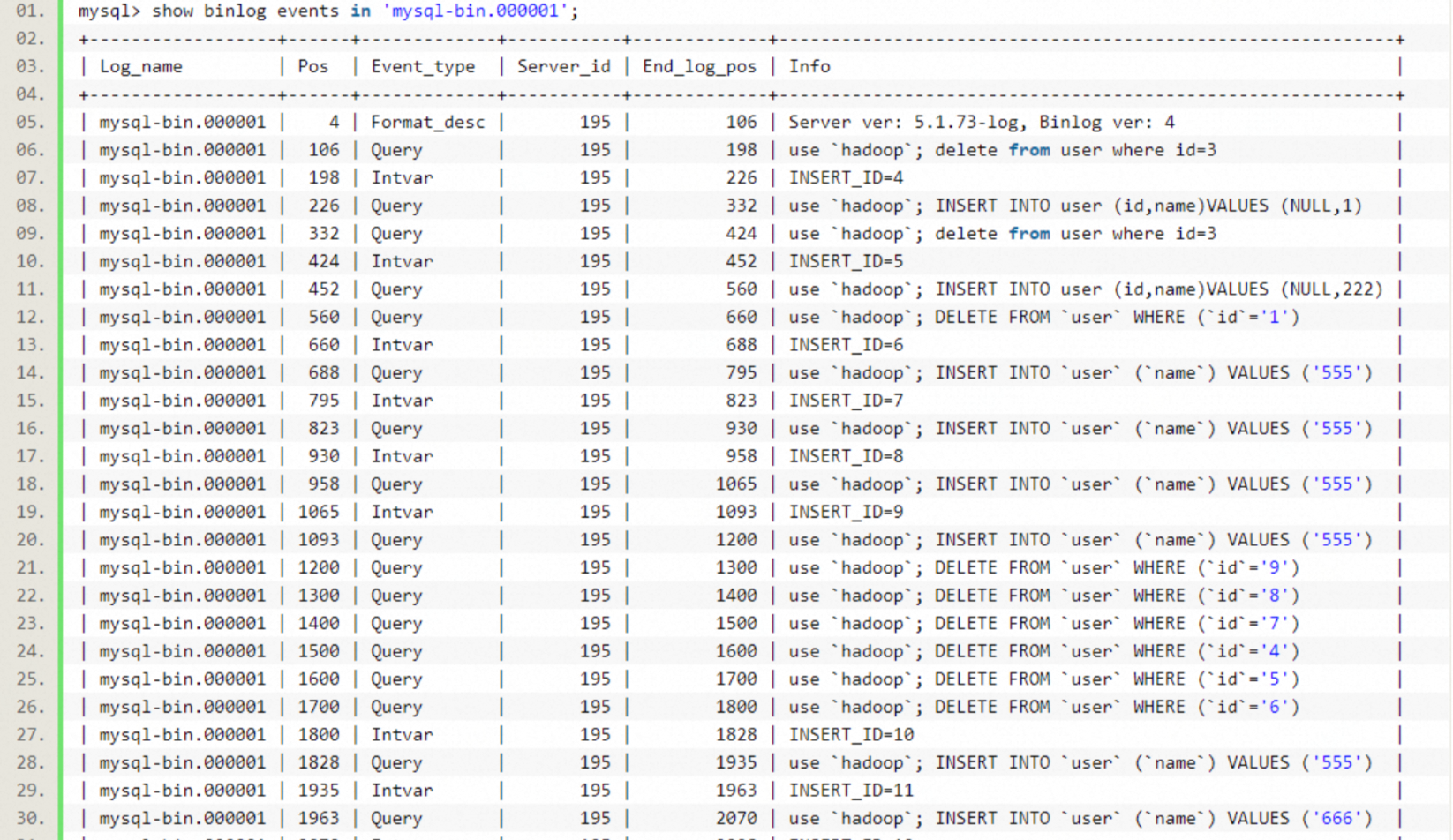
如图 9 所示,binlog 将所有数据库操作视为事件并记录操作内容(具体见 binlog 的3种格式,Statement/Row/Mixed)。
# at 447#170330 14:19:25 server id 10 end_log_pos 607 CRC32 0x321d4518 Update_rows: table id 133 flags: STMT_END_F### UPDATE `sbtest`.`sbtest`### WHERE### @1=1### @2=0### @3=''### @4='qqqqqqqqqqwwwwwwwwwweeeeeeeeeerrrrrrrrrrtttttttttt'### SET### @1=1### @2=1### @3=''### @4='qqqqqqqqqqwwwwwwwwwweeeeeeeeeerrrrrrrrrrtttttttttt'
操作事件具体内容如上代码块,记录了操作时间与操作内容,例如代码块内就记录了今天 14:19:25 执行的一条 UPDATE 语句。这也是为何通过 binlog 可以实现数据同步等功能,拥有 binlog 即拥有数据库进行的所有操作记录,通过回放 binlog 就可以还原完整的数据库数据。
3.1.2 流表对偶
对传统数据库而言,DDL 只是用于描述表元数据的语句,描述的是一张表静态的结构信息。而通过 binlog 回放可以发现,表的变更操作可以用带时间的事件描述、表也可以通过回放操作事件得到最终的变更结果。
动态表可由 DDL(静态结构) + binlog(动态变更事件) 描述,动态表的变化趋势可以视为流,而流的处理结果又构成了表。这就是流与动态表的对偶性:
Dynamic Table = DDL + binlog <=> Streaming
因此在 Flink 中,DDL 并非简单描述了表的结构,而是声明了动态表的结构与变更事件;又由于动态表与流的对偶性,这就相当于描述了流。
3.2 持续查询 Continuous Queries
- 声明动态表(Source + DDL)
- 持续读取动态表(DML)+ 处理最新记录(Operator)
- 流向下游节点(DML)
- ······
- 输出结果(Sink)
利用「流表对偶性」与「持续查询」,Flink 实现了真正意义上的无损转换与流式读取,通过 SQL API 大大降低了流式计算的难度。
3.3 数据水位 Watermark
- 事件时间在 [0, 8) 内的元素都能被 [0, 5) 窗口捕获,因为 [0, 8) 内生成的 Watermark 都会处于 [0, 5) 窗口;系统 Watermark < 5s,此时不会触发窗口计算。
- 当 EventTime = 9s 的元素流入,其 Watermark = 6s;系统 Watermark 被推进到 6s,此时 10s > Watermark > 5s,触发 [0, 5) 窗口计算、继续收集 [5, 10) 窗口元素。
- 当 EventTime = 10s 的元素流入,其 Watermark = 7s;系统 Watermark 被推进到 7s,此时 Watermark < 10s,继续收集 [5, 10) 窗口元素。
- 当 EventTime = 12s 的元素流入,其 Watermark = 9s;系统 Watermark 被推进到 9s,此时 Watermark < 10s,继续收集 [5, 10) 窗口元素。
- 当 EventTime = 15s 的元素流入,其 Watermark = 12s;系统 Watermark 被推进到 12s,此时 15s > Watermark > 10s,触发 [5, 10) 窗口计算、继续收集 [10, 15) 窗口元素。
- ·······
设置合理的 Watermark 确实可以解决大部分元素延迟,但也是把双刃剑——降低了结果的实时性,窗口计算结果最少也会延迟所设定的时间之久;其次在笔者看来,如果 Watermark 一直不推进(即一直没有元素流入)、已结束窗口的计算就一直不会被触发(这里需要了解 Watermark 的两种生成模式「Punctuated Watermark 标点水位线」与「Periodic Watermark 定期水位线」,标点水位线是以元素流入事件触发 Watermark 生成、后者是周期性生成。使用标点水位线就可能会出现 Watermark 不推进的现象,但实时性更强)。
因此不建议设置过长的水位延迟时间,根据业务可能存在的延迟时间及实时性要求合理配置即可。
3.4 状态 State
- Keyed State:具有分区键的算子会以键为单位维护自身的 State,例如 group by 算子在求和计算时,会为每个分区键维护其数量总和。结构大致为 Map<Keyed, Long>。
- Operator State:不具有分区键算子的 State 统称为算子 State,例如 Source 连接消息队列时需要维护已消费位点、双流 Join 时需要维护左右侧流中元素。结构大致为 Map<Operator, State>。
通常情况下,State 会先维护在内存内,通俗地说就是一个 HashMap****;经过一段时间、或内存占用量达到阈值,会写入本地的 RocksDBStateBackend,这是 Flink 提供的本地高性能 KV 数据库;为了避免作业异常重启、确保 Checkpoint 构建,隔一段时间还要将 State 从 RocksDB、异步同步到外部分布式存储(通常是 HDFS)。这样的架构,既避免内存不断膨胀、也保证数据的安全性,同时通过异步保障性能。
还有 HashMapStateBackend 供选择,即纯内存 StateBackend,由于其不存在磁盘 IO 与序列化,因此性能比 RocksDBStateBackend 快一个数量级;但完全依赖分配内存,并且安全性较弱,因此这里不作探讨。
使用者还可以维护自身的 State,通过实现 ValueState、ListState、ReducingState、MapState<UK, UV>等接口,将信息缓存在本地状态中。但需要时刻注意 State 对于内存的占用,设置合理的清除策略或 TTL。
3.5 检查点 Checkpoint
Checkpoint 意为检查点,是 Flink Failover 最大的仰仗。其本质就是保存全局快照,快照内存储了集群内所有算子的 State,在读取时重放所有算子的状态,并一比一恢复到 Checkpoint 存储的状态。
这一章太过艰深,利用许多算法来解决诸如:分布式集群全局状态一致性、Checkpoint 持久化模式、Exactly-Once/At-Least-Once 语义保证之类的问题。因此不作展开,有兴趣的同学可以自行学习。
3.6 回撤流 Retract
- Append Only:仅支持追加。
- Upsert:支持插入、更新、删除,最完备的模式。
- Retract:支持插入、删除。
Append Only 模式不支持回撤,每次 Sink 都会插入一条记录。而 Upsert 模式在处理回撤流时,可以根据主键直接更新已有的记录,或者先删除已有记录、再插入新的记录代替它,实现结果上的更新。Retract 模式使用先删除、后插入,也可以实现更新效果。显然 Append Only 模式的数据准确性不如其他两者,只有最新输出的一条记录才是准确的。
不同数据源支持不同的插入模式,例如 Kafka 只支持 Append Only ,但其是消息队列所以可以接受这种顺序读写;而 MySQL 如果只支持 Append Only 那就成灾难了,基本没法使用,因此其支持基于主键的 Upsert。因此在使用回撤流以及回撤算子时,需要结合数据源的插入模式分别考虑,合理利用回撤流来保证数据的准确性。
3.7 反压/背压 BackPressure
publicvoidput(E e)throwsInterruptedException{if(e ==null)thrownewNullPointerException();// Note: convention in all put/take/etc is to preset local var// holding count negative to indicate failure unless set.int c =-1;Node<E> node =newNode<E>(e);finalReentrantLock putLock =this.putLock;finalAtomicInteger count =this.count;
putLock.lockInterruptibly();try{/*
* Note that count is used in wait guard even though it is
* not protected by lock. This works because count can
* only decrease at this point (all other puts are shut
* out by lock), and we (or some other waiting put) are
* signalled if it ever changes from capacity. Similarly
* for all other uses of count in other wait guards.
*/while(count.get()== capacity){
notFull.await();}enqueue(node);
c = count.getAndIncrement();if(c +1< capacity)
notFull.signal();}finally{
putLock.unlock();}if(c ==0)signalNotEmpty();}
在笔者之前的一篇文章《Reactor 响应式编程》中有介绍过,Reactor 采取了推拉结合的方式,下游向上游发出具体拉取元素数量的信号量,上游根据信号量向下游推送对应数量(具体见https://blog.csdn.net/m0_62375467/article/details/132404504 《响应式编程:面向数据/事件流的编程范式
》)。不同系统对反压有不同的实现方式,本质都是对下发/消费速率的调控与平衡,并且反压都是级联,从反压节点一路向上影响到初始节点。
而 Flink 支持反压的方式十分自然,可谓是天生反压圣体。
当节点的消费速率 < 生产速度,节点的 local buffer(本地缓冲区,可以理解为 JVM 内存)就会趋于膨胀;local buffer 塞不进去,Netty 的 buffer 就没法腾地方出来,也会跟着膨胀;Netty buffer 在膨胀到一定程度后也塞不下了,就会停止读取 Socket 中的数据(不发起调用recv()函数或调用被阻塞);而 Socket 不被读取后,TCP 又具有端到端自动调速的能力(详见 TCP 滑动窗口),TCP 的发送方就会自动停止。
整个反压的过程浑然天成,利用了所有可利用的网络传输机制,牛逼。考虑到这个过程有些抽象,以下游节点的视角重新梳理一次反压过程:
- 节点的消费速率 < 生产速度,local buffer 开始膨胀,直至打满。
- local buffer 打满,Netty 无法写入,导致 Netty buffer 开始膨胀,直至打满。
- Netty buffer 打满,停止读取 Socket,导致 **Socket read buffer **开始膨胀,直至打满。
- Socket read buffer 打满,TCP 写入(write()函数)read buffer 操作阻塞。
- TCP 发起端到端自动调速,TCP 发送方自动停止。
- 分割线
- 上游节点作为 TCP 发送方,此时也受到了影响。
- TCP 无法继续发送,Socket write buffer 打满。
- Socket write buffer 打满,Netty 不可写,Netty buffer 打满。
- Netty buffer 打满,local buffer 无法回收,也打满。
- ······
如图 14 是 Alibaba VVP 作业运维的执行计划信息,该作业的 Vertex5 节点负载较高,该节点就会发起反压;Vertex4 节点受到反压影响,调整生产速率,但其本身的消费速率也会受到影响(他是下游的生产者、也是上游的消费者)。因此可以看出,每个节点都有不同程度的反压。整个过程周而复始,最坏的情况下反压会一路影响到 Source 节点,整个作业会 Crash 重启;因此反压现象是一定要处理的,后续的作业调优会介绍大致方法。
反压过程远比描述复杂得多,笔者唯恐误人子弟,建议有兴趣的同学了解一下以下知识:Flink 网络传输模型、Netty 实现及水位线、TCP 滑动窗口及拥塞控制。
4 江湖豪侠:Flink 作业调优
看到这里的你,已经对如何开发一个 Flink Job 有了基本的认知,也对 Flink 最核心的概念、以及依托于其之上的设计有了大致的理解。
本章将会更贴近工程层面,就 Flink Job 如何生成、如何调优、并结合场景具体分析。磨刀不误砍柴工,在思考如何调优前,更需要先知晓一个 Flink Job 进入系统后都发生了什么,本章也会以该顺序循序渐进展开讨论。
4.1 Flink 运行时架构
- JobManager 作业管理器:Flink 集群的 Master,每个集群有且只有一个主 JobManager(为保障高可用会有多个备 JobManager),负责 Flink 集群的作业管理、资源调度、任务分配、环境协调等等,是集群真正的心脏。
- ResourceManager 资源管理器:负责 Flink 集群的资源分配管理,JobManager 在进行任务分配时需要先获取相应的运行资源(TaskSlot),此时就会与 ResourceManager 产生交互。每个集群有且只有一个 ResourceManager。 比较有意思的点是,它可以与资源管理框架交互(如 YARN、K8S、Mesos 等),动态控制资源的扩缩容。
- TaskManager 任务管理器:Flink 集群的 Worker,任务真正执行的工作节点,通常一个集群有 N 个 TaskManager(非 standalone 模式)。最小工作单元是 TaskSlot(任务槽),一个 TaskManager 可以提供多个 TaskSlot,这些 Slot 会作为 ResourceManager 的分配单元。 每个 Slot 拥有独立的内存空间,但 CPU 资源会被共享,因此通常建议 Slot 数 = CPU 核数。
- Dispatcher 分发器:主要提供 REST 接口用于提交作业,以及 Web UI 用于展示作业执行监控,非必需。
说直白点:
- JobManager 是大老板,集群的协调分配者;
- TaskManager 是工作人员,纯干活儿的,负责执行计算任务;
- ResourceManager 是管账的,JobManager 协调资源先找 ResourceManager,负责分配/回收 TaskManager;
- Dispatcher 是前台,负责任务提交后报信给 JobManager,以及作业指标展示。
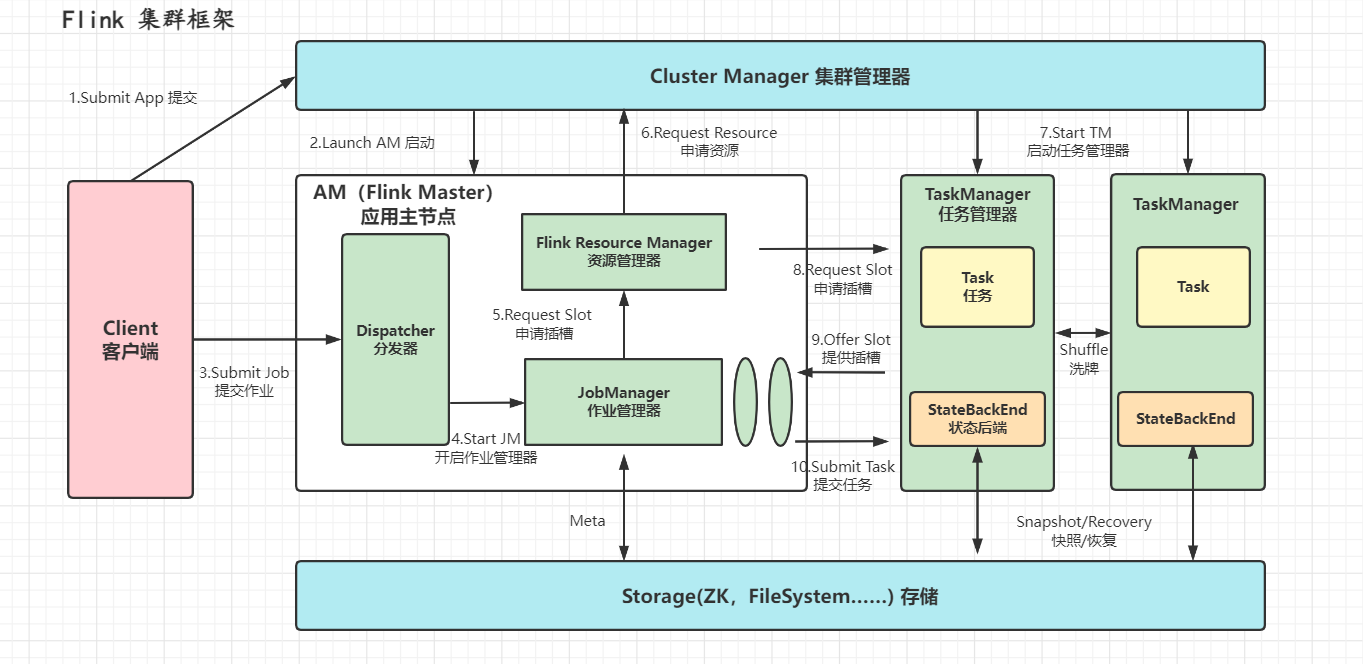
那么在 Flink Job 提交进 Flink 集群后,运行时架构的运行交互关系(如图 16)可以简述为:
- **JobManager **将 Job 解析为 ExecutionGraph(执行图),即一份具体的执行计划(DAG);
- **JobManager **根据执行图向 **ResourceManager 申请执行所需资源,ResourceManager **与底层资源管理系统(如 YARN)交互,确保集群资源满足执行要求(通常伴随着动态扩缩容、启停 TaskManager);
- **JobManager **获取所需资源后,将任务分发给 TaskManager,由 **TaskManager **具体执行计算逻辑;
- **TaskManager **会持续上报执行状态 State,并由 **JobManager **维护检查点 Checkpoint,确保作业的故障恢复。
4.2 执行计划
Flink 运行时架构的全貌大致清晰,Flink 官方也通过整体架构图(如图 15)强调了 JobManager 与 TaskManager 、以及二者间关联的重要性,这是作业调优不可缺少的前置知识。本章将会着重介绍 JobManager 如何解析并构建执行计划。
借用 Flink Forward Asia 2022《Adaptive and flexible execution management for batch jobs》中的一张图,图 17 描述了最终的执行计划 ExecutionGraph 是如何生成的。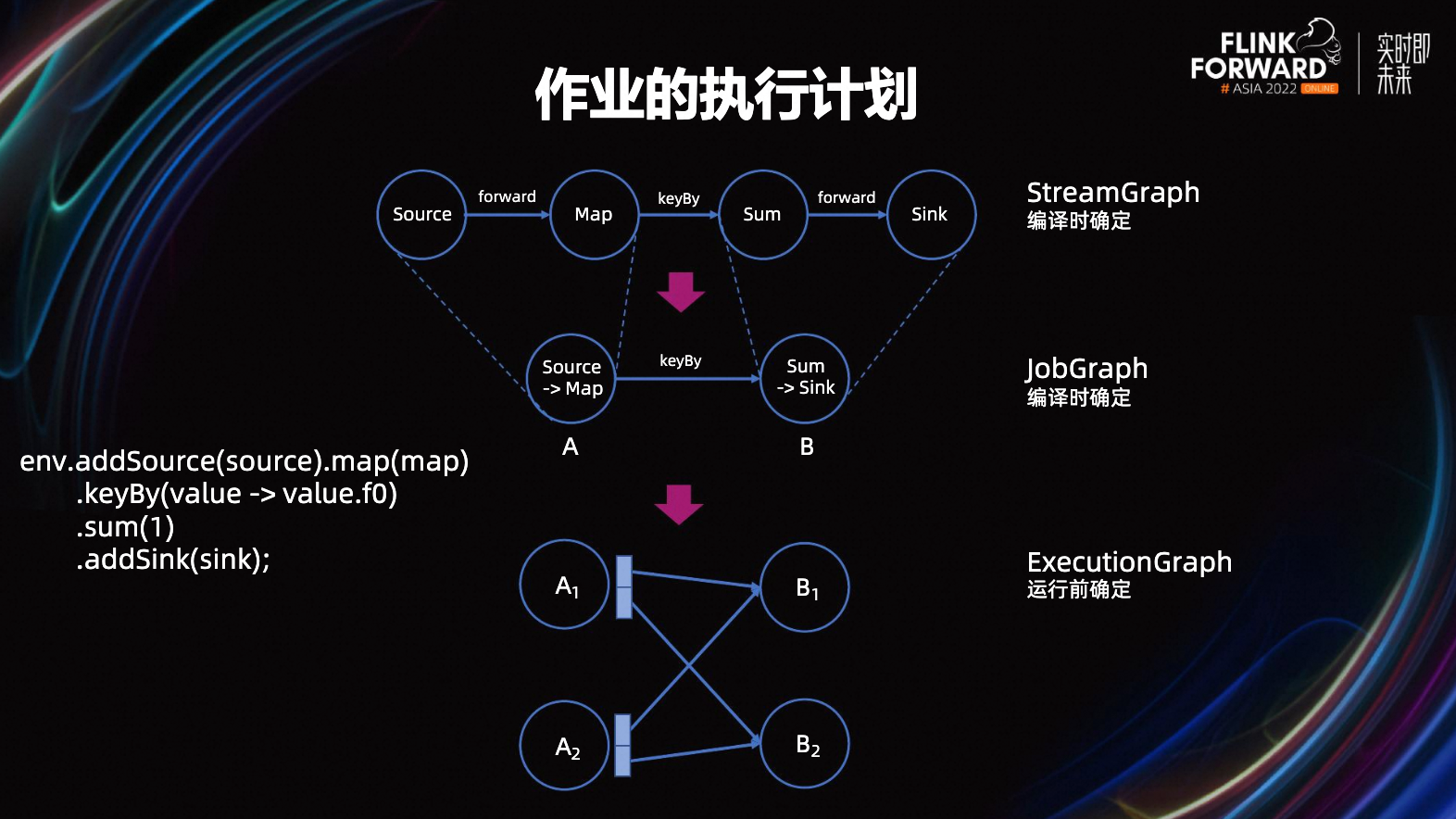
以 DataStream 作业为例,作业代码编译完毕后会生成「流图 StreamGraph」,流图内描述了完整的 DataStream API 计算逻辑,如图中例子为:Source -> 元素转换 -> 按 key 分组并求和 -> Sink。
在未禁用「算子链(Operator chain)合并」的情况下,编译期间还会根据算子逻辑的复杂程度、并行度、分发方式(分组/forward)等因素,对相连算子进行合并、组成一个算子链。算子链合并是 Flink 最常用的优化手段之一,因为算子逻辑天然存在复杂度差异,如果每个算子都分配单独的资源,会使得负载极其不均衡;合并也能够减少服务间网络通讯、线程切换、序列化带来的损耗。因此,编译的最终结果会生成「作业图 JobGraph」,即算子合并后的图。
JobGraph 提交给 JobManager,JobManager 会根据每个任务节点的并行度进行展开,并确定节点间的连接关系,生成最终可执行的「执行图 ExecutionGraph」,此时每个任务节点都对应一个具体执行的 TaskSlot。「并行度 Parallelism」代表每个算子需要几个 Worker ,类似于多线程并行消费,只不过调度资源由 Thread 变成了 TaskSlot。
例如图 17 中的作业并行度为 2,A 节点的结果会发往 B,因此最终执行图为 A1/A2 -> B1/B2,共对应 4 个 TaskSlot。而实际的执行计划还存在进一步优化空间。如图 18 所示,在经过算子合并后的每个算子链会分配一个 TaskSlot,部分节点计算逻辑仍然相对简单,其分配到的 TaskSlot 大部分时间是空闲的,其他节点却一秒没闲着。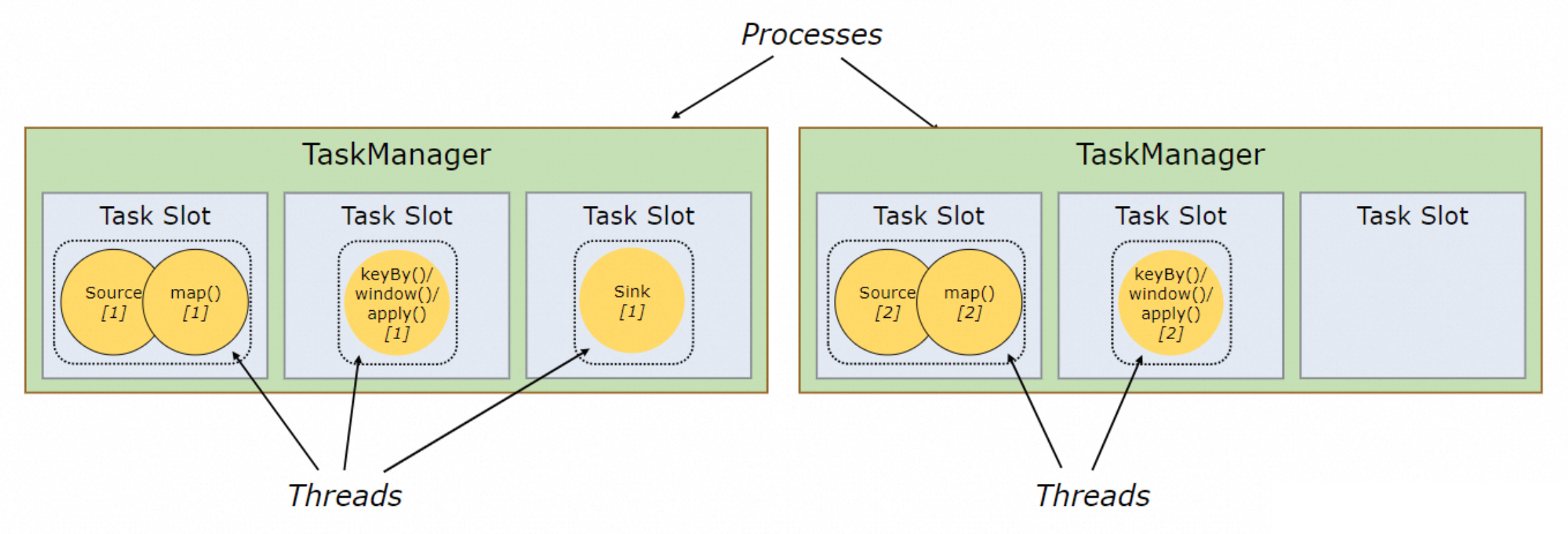
因此 Flink 会在 Slot 维度采取进一步合并,将简单算子的 Slot 共享给复杂算子(Slot Sharing),反正闲着也是闲着,不如给别人用;在算子并发度高的场景下,最终会得到如图 19 的执行计划。但是同一个 Slot 只能共享给同一 Job 内不同的算子,例如合并 Map + Sink,将两个相同的算子放在一个 Slot 内无法实现并行。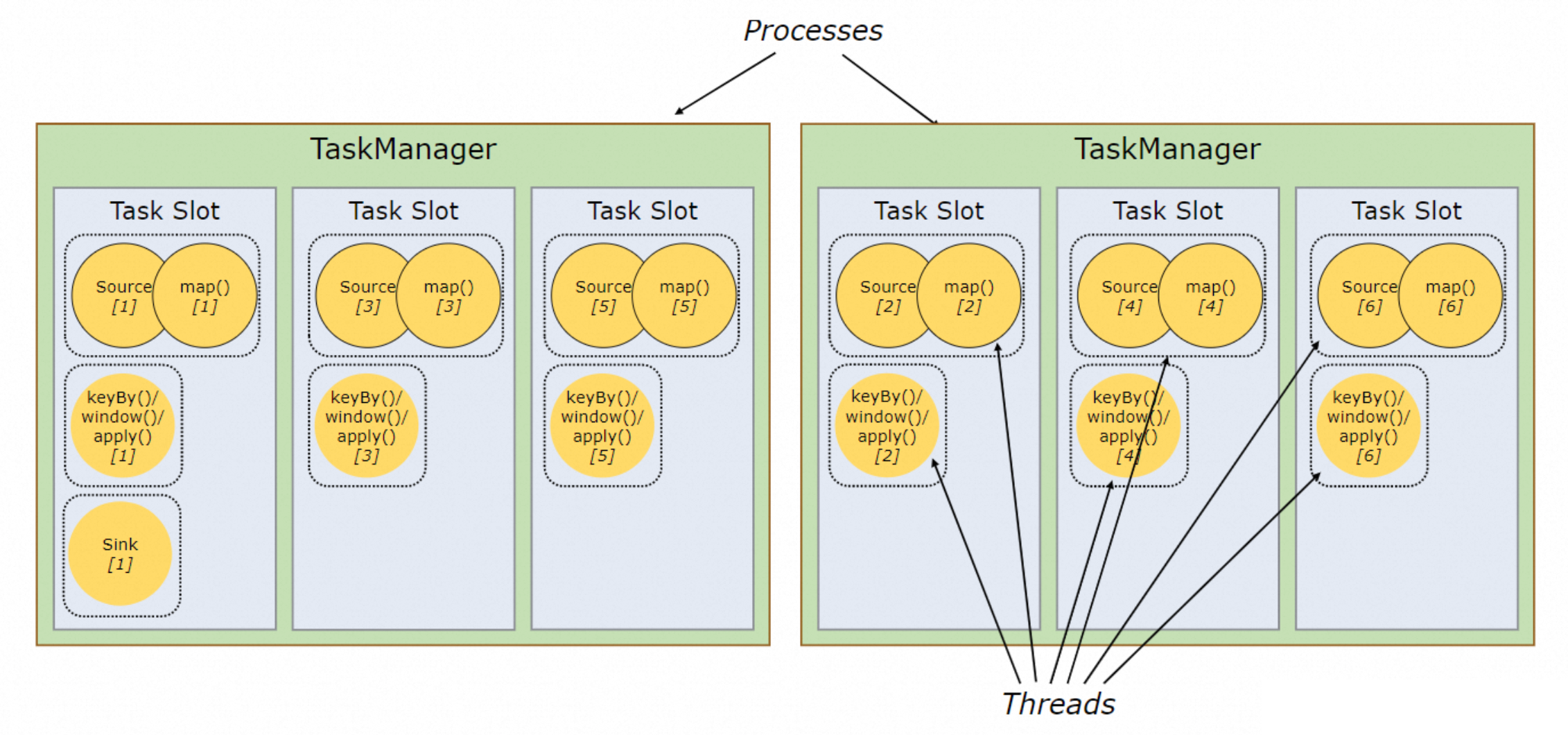
4.3 性能瓶颈
讨论到 Flink Job 的性能瓶颈,其表现形式在前文其实都有提及。
首先是背压,在消费速率 < 生产速率时该节点会向上游算子发起背压,严重时会阻塞住整个作业的运行;表现出来就是数据延时越来越大,这种情况不手动调优是不可能主动恢复的。
其次是所有运行于 JVM 之上程序的共性问题——内存。于 Flink 而言又分为两类:
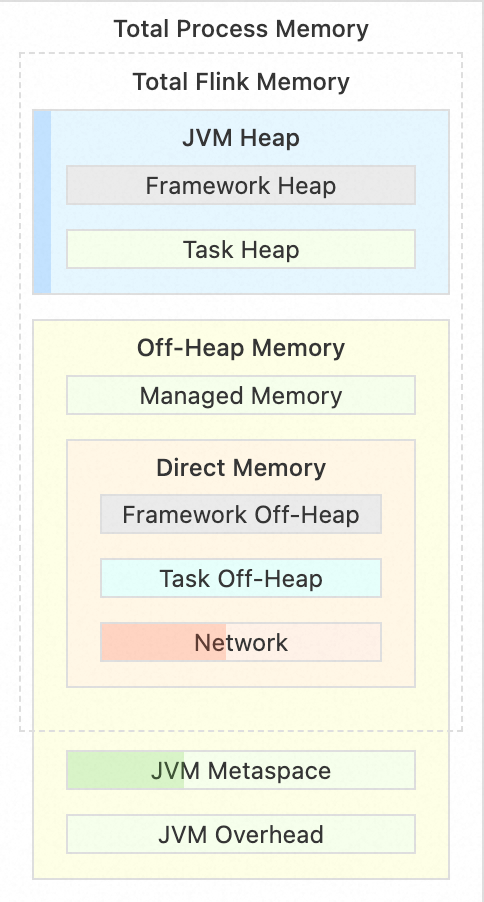
- 堆内占用过大,如图 20 中的 Task Heap(图 20 是 Flink TaskManager 的内存模型,分为堆内/堆外内存,有兴趣的同学可以自行了解),算子逻辑与业务代码产生的内存将会占用 Task Heap 空间;这个区域非常容易膨胀,处理复杂运算逻辑时更甚。
- 堆外内存占用过大,如图 20 中的 Managed Memory,Flink Job State 会存储在这个区域内;算子逻辑复杂(或者是双流 Join 这种本身就强依赖 State 的算子)一定程度也会导致 State 变大,也是俗称的「大状态」。
内存瓶颈的表现形式通常为作业 OOM 后崩溃重启,如果不进行调整作业会一直重启。
4.4 配置调优
首先记住大原则:写出高性能 SQL 才是最有效的优化方案!!!
不过要写出美丽高性能 SQL 还是有难度的,例如谓词下推、手动构建 PK、避免 NULL 热点、Shuffle/Rebalance 等概念,每个拿出来都能说半天。因此本章还是仅针对上文场景、讨论配置层面的调优方向,不涉及特定算子及计算模式层面的优化方式。
4.4.1 加机器
直白地说,Flink 中的大部分性能问题都能够通过加机器解决。算子消费速率过低?上 128C 的!数据延迟越来越大?再加二北台机器!内存占用过大一直 OOM?上 128G 的!甚至连 Flink 官方也建议先通过加内存/加机器来尝试解决问题(来自 Flink 官方文档 -> Tunning Checkpoints and Large State -> Tuning RocksDB Memory 的原话),可谓是一力降十会。
因此在作业性能出现问题时,建议先加机器恢复正常运行,后续再针对细节进行优化。当然也不能无脑加,需要结合实际的执行计划和具体异常节点,合理且有针对性地调整。
4.4.2 算子并发度
4.4.3 关闭共享
前文提到 Flink 在执行计划层面会采取两种优化:算子链合并和 Slot 共享,但好心也有可能办坏事。
算子链合并确实能一定程度减少网络通讯带来的损耗,并且实打实节省了资源。但同时也导致了资源分配不均且不透明,原本一人一个了变成一人一半(甚至可能因为争抢导致不足一人一半)。并且为算子层面的调优造成了极大困难,在不开启算子链合并的情况下,每个算子独立存在,哪个算子异常一眼便知;合并后,5 个算子合成一个,只能看到这一坨,基本没法定位某个算子来调整细节。Slot 共享同理,原本一个算子用 4C,现在变成一人 2C,对性能的影响是必然的。
因此需要算子层面的细节调优时,可以关闭这两类共享(或者调整为仅允许某些高吞吐算子共享,将这类算子设置相同的组别,详见 SlotSharingGroup)。
4.4.4 内存分配
前文提到与内存有关的性能瓶颈通常出现在两块区域,对应 TaskManager 的堆内/堆外内存的核心部分,即运行时内存 Task Heap、管理内存 Managed Memory。两块内存的具体大小会根据比例自行计算,默认情况下 Managed Memory 会占用总内存的 40%,而 Task Heap 会用所有内存区域分配完毕后剩余的。
Managed Memory 通常用于存储 State Backend,而 Flink 最常见使用场景是做数据 ETL,ETL 本质上就是 Mapping,而 Map 算子是无状态算子。这意味着大部分作业的 State 容量并不会很大,Managed Memory 利用率也就低得可怜。如图 21 是一个纯 ETL 作业的内存占用情况,可以看到 Managed Memory 的占用量是 0%,却和堆内内存大小持平(1.19GB/1.33GB)——这是由于 Flink 的默认配置中,Managed Memory 会分配到总内存的 40%。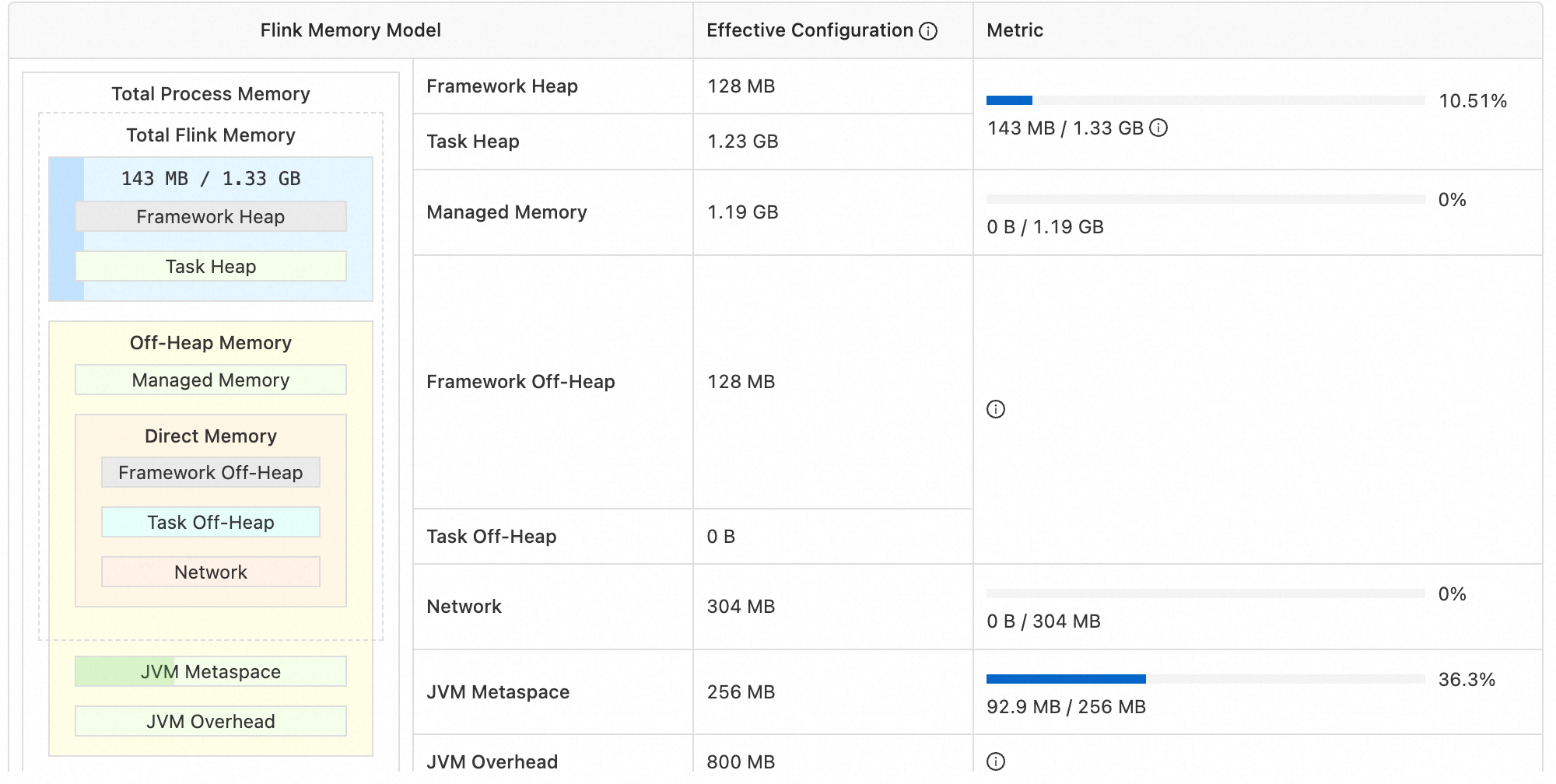
但图中的作业设置分配 5% 就已经足够,甚至更低。因此,使用者应当根据运行时不同内存区域的占用情况,自行调整内存分配。
4.4.5 大状态
前文提到,内存瓶颈最大的罪魁祸首之一便是「大状态」,大状态对 Flink Job 稳定性的危害是不言而喻的:
- 大状态会迅速填满 Managed Memory,加剧节点 GC。
- 从 RocksDBStateBackend 中读取大状态效率很差,因为涉及大量数据的检索、磁盘 IO、序列化/反序列化。
- Checkpoint 的构建依赖状态,状态越大构建效率越低。
在双流 Join、以及无边界的聚合计算等场景,State 非常容易膨胀。但实际使用者能做得也不多,要减少对 State 的使用那是执行计划层面的优化,不在本章探讨范围内。
但绝大多数情况大状态的出现,是因为没有设置 State TTL,TTL 默认是永久,你敢信?所以,请务必根据业务对 State 中历史数据的依赖程度(例如双流 Join 中,业务方不会出现依赖 1 天前记录场景下,就可以设置 TTL 为 24H 左右),设置合理的 State TTL!
4.4.6 Mini-Batch
Mini-Batch 俗称攒批,是 Flink 中最常用、好用的调优方式之一。
在聚合计算场景下,每个元素的到来都会触发一次计算,即 State 读取 + State 累加 + State 回写;当上游 RPS 极高时,State 的急剧膨胀及高频率读写会成为极大的性能瓶颈。而使用方大部分时候并不需要感知每一秒的指标变化,此时便可以使用 Mini-Batch。
Mini-Batch 的原理实际就是将元素攒在手里,周期性地触发计算,而不是每次元素到来都触发。这样做能大幅度降低计算频率,减少高频率计算产生的性能负担;最重要的是用批量操作 State 代替了单行操作,要知道每次 State 操作都意味着磁盘 IO + 序列化。Mini-Batch 会以使用者配置的允许延迟时长作为周期触发计算,性能提升的同时意味着数据的实时性降低了,这一秒发生的事件需要 N 秒后才能看到结果。
因此需要结合对数据时效性的要求合理设置是否开启 Mini-Batch、合理配置允许延迟时长。
4.5 调优效果
以上为笔者曾经使用过的部分调优策略,笔者的一个作业曾经由于 Source RPS 突然提高了 3000 左右,导致部分节点反压,作业延迟一度增大到 3 小时。在尝试过以上所有的调优策略后,吞吐量增长也是十分显著:

从 3000 输出 RPS 最终达到稳定 16000+,非常好用。
5 一代宗师:后车之师
到这里,对于 Flink 的整体介绍基本结束,相信你已经深切感受到 Flink/流式计算的魅力所在,也衷心祝愿你能在流式计算的世界里越走越远。
笔者在学习与使用 Flink 的过程中踩了不少坑,希望在最后能帮到你。
5.1 大型维表 Join 导致 OOM
- 加内存、加内存、加内存,但这样肯定不是个事。
- 调整内存空间分配,由于维表数据存储在 Task Heap 区域、且并不是大状态作业,因此可以调小其他区域(如上文提到的 Managed Memory),优先确保 Task Heap 空间。
在初期确实能够很好的缓解问题,但维表的数据会一直膨胀,总不能没事就来调调作业的内存吧?但既然一台机器放不下所有记录,能不能打散到所有机器内呢?
答案是可以!Flink 的分区算子就是干这个的。
通常情况下,上游算子流入哪个下游算子分区(可以理解为哪台机器)是 shuffle 算子随机选择的(keyedBy 聚合场景除外),因为都大差不差;但如果在 Join 计算前先对 Join Key 作 hash 运算,将左侧流元素根据 hash 结果分配到同一分区,确保相同 hash 的记录落在同一分区内,那就可以确定每个分区需要加载哪些 key 对应的维表信息。
相当于从每台机器加载全量维表数据,变成了每台机器只加载被分配到的 key 的维表数据,数据量缩减到了 1/Parallelism。但前提要先扩大算子并发数,否则就 1 个分区参与分配等于没分。
5.2 并发度过高导致无法启动
调整并发度是提高作业吞吐非常有效的手段,但连接器的吞吐往往不是越大越好。因为提高并发度相当于增加同时计算的 Worker,而数据源的读取通常具有事务性,不能谁来都能读。例如 Kafka Connector,有多少个 shard 就支持多少个并发,调大了剩下几个 Worker 就只能一直闲着。
笔者有次遇到一个奇怪的问题,在数据源 Datahub(类似 Kafka 的消息队列)shard 数为 1 的场景下设置了并发度为 4,此时作业出现一直重启的现象;在调低并发度后(即调整并发度 = shard 数),作业又能够正常启动了。但是笔者后续再也没有复现过该场景,哪怕并发度与 shard 不对等也没有影响作业的启动。
这也成了笔者心中的一根刺,希望有人能解惑。T_T
5.3 窗口函数启动异常
使用窗口函数时需要指定时间字段,且该字段类型必须是 timestamp + rowtime,否则无法正常启动窗口。
笔者在 DDL 中指定了时间字段、将其转换为 timestamp 类型、还设置了 Watermark,可以说是妥妥的优质可开窗字段。但在调用下方的 TUMBLE 算子后,还是报出了“当前字段不是时间格式”的错误。
CREATETEMPORARYTABLE user_clicks(
username varchar,
click_url varchar,
eventtime varchar,
ts AS TO_TIMESTAMP(eventtime),
WATERMARK FOR ts AS ts -INTERVAL'2'SECOND--为Rowtime定义Watermark。)with('connector'='sls',...);CREATETEMPORARYVIEW one_minute_window_output ASSELECT
TUMBLE_ROWTIME(ts,INTERVAL'1'MINUTE)as rowtime,--使用TUMBLE_ROWTIME作为二级Window的聚合时间。
username,COUNT(click_url)as cnt
FROM user_clicks
GROUPBY TUMBLE(ts,INTERVAL'1'MINUTE),username;
笔者简直不敢相信自己的眼睛,并且其他的测试 demo 中,同样的写法也没有任何问题。
在不断地排错后,发现问题出在开窗的时机不对。笔者的 SQL 类似于一个子查询查出表中所有的字段、再于子查询外侧调用窗口算子,查完表字段直接开窗就没有出现问题。这说明:子查询在查出时间字段时,没有保留其附加的 rowtime 属性,只剩了基本的数据类型 timestamp。这就有点坑了,原封不动地查出来还能把字段上的属性丢掉?在笔者看来这应该属于 bug。
因此,子查询可能会丢失字段原有的属性,这点是可能存在的风险。
5.4 序列化
由于 Flink 中存在大量的网络/磁盘 IO,因此其要求所有传输的对象都必须是可序列化的。而在一次 Flink UDF 开发中,笔者在上传 UDF 并尝试启动后,发现作业一直报序列化错误:
Exception in thread "main"org.apache.flink.api.common.InvalidProgramException: java.***.***$***@123 is not serializable.
令人困惑的是,UDF 实现的 TableFunction 接口本身实现了 Serializable 序列化接口,那为啥又会出现序列化错误呢?在不断地寻觅后,笔者发现 UDF 的一个局部变量没有实现序列化,笔者将这个类删掉以后就没报错了。但那又是个很重要的外部类,没法删掉、也不方便 copy 过来的那种,笔者当时心凉了半截。
那这个问题该如何解决呢?
首先想到 transient 修饰符,它用于标记一个局部变量不用被序列化。看起来没什么实际意义,因为字段如果不被序列化,那在分布式环境肯定是没法使用的;但如果这个字段在外部环境确实没什么用,只在系统内部(内/外部指网络通讯的发起/接收者)使用,外部不感知,那确实是不用被序列化。笔者试了试,倒是不报序列化错误了,但调用该类的时候直接开始报错,因为变量根本没被序列化(服了。。。)。
可如果变量本身就无法被序列化,那就必须得用 transient 标记,不然对象都无法正常序列化并传输。那不成死结了?
但是,Java 基础知识中提到:类变量属于类、不归属于对象。而序列化/反序列化都是在字节序列和对象之间转换,如果一个变量不属于对象,它也就不需要参与序列化。
所以最终解决方案就是把它标记为成员变量(类变量),如果要网络传输某个字段、而这个字段又没有实现序列化,就把它标记成类变量吧,准好使。
6 特别鸣谢
感谢你看到这里,也感谢领笔者进门的两位帮派师兄,最后感谢所有 Committer、编写官方文档、分享技术知识、极具开源精神的程序员们。
再推荐几篇笔者觉得非常有意思的文章(也同时作为本文的参考文献),链接一同贴在下面,再次感谢各位的无私奉献。
- 阿里云 Flink 产品文档:https://help.aliyun.com/zh/flink/?spm=a2c4g.11186623.0.0.15584a58S2EZt8
- Apache Flink 漫谈系列(必看!必看!必看!):https://developer.aliyun.com/article/666043
- Apache Flink 官方文档:https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/try-flink/local_installation/
- Flink Forward Asia 2022:https://2022.flink-forward.org.cn/
如果你对本文的内容仍有疑惑、指正、补充、更优解,欢迎随时找笔者讨论,不允许自带酒水。
版权归原作者 不识愁滋味. 所有, 如有侵权,请联系我们删除。