
文章目录
1.Playwright介绍
Playwright 是一个用于自动化浏览器操作的开源工具,由 Microsoft 开发和维护。
它支持多种浏览器(包括 Chromium、Firefox 和 WebKit)和多种编程语言(如 Python、JavaScript 和 C#),可以用于测试、爬虫、自动化任务等场景。
Playwright 是针对 Python 语言的纯自动化工具,它可以通过单个API自动执行 Chromium,Firefox 和 WebKit 浏览器,连代码都不用写,就能实现自动化功能,并同时支持以无头模式、有头模式运行。
2.与 Selenium 和 pyppeteer 相比,Playwright 具有以下几个区别和优势
- 多浏览器支持:支持所有主流浏览器。这使得开发人员可以根据需求选择最适合的浏览器进行自动化操作。(Playwright不支持旧版Microsoft Edge或IE11)
- 更快的执行速度:Playwright 通过使用浏览器的底层调试协议来进行操作,相比于 Selenium 和 pyppeteer,playwright是异步的,它具有更快的执行速度和更低的资源消耗。
- 可靠性和稳定性:Playwright 提供了更可靠和稳定的浏览器自动化操作,通过使用浏览器的原生 API 来模拟用户行为,避免了一些传统自动化工具的一些限制和不稳定性。
- 支持跨浏览器和跨平台:Playwright 可以在不同浏览器和不同操作系统上运行,这使得开发人员可以更方便地进行跨浏览器和跨平台的测试和自动化操作。
- selenium是基于http协议,而Playwright是基于websocket协议。由于使用 HTTP 协议,Selenium 的性能相对较低。每次与浏览器进行通信时,都需要发送 HTTP 请求和等待响应。 而Playwright使用 WebSocket 协议,Playwright 的性能会更高。WebSocket 的双向通信使得数据交换更高效,可以更快地获取页面内容和执行操作。
- 支持屏幕录制功能:根据屏幕录制指定生成相关操作代码。
3.在爬虫中使用 Playwright 的好处
- 动态网页爬取:Playwright 可以模拟用户在浏览器中的操作,包括渲染 JavaScript、点击按钮、填写表单等,从而可以爬取包含动态内容的网页。
- 多浏览器支持:Playwright 支持多种浏览器,可以根据需求选择最适合的浏览器进行爬取,以确保爬取结果的准确性和一致性。
- 更高的稳定性和可靠性:Playwright 使用浏览器的原生 API 进行操作,避免了一些传统爬虫工具的一些限制和不稳定性,提供了更可靠和稳定的爬取能力。
总之,Playwright 是一个功能强大、跨浏览器、跨平台的浏览器自动化工具,相比于 Selenium 和 pyppeteer,它具有更快的执行速度、更高的稳定性和更广泛的浏览器支持,适用于多种自动化操作和爬虫场景。
4.环境安装
- 系统要求:- Python 3.8 或更高版本。- Windows 10+、Windows Server 2016+ 或适用于 Linux 的 Windows 子系统 (WSL)。- MacOS 12 Monterey 或 MacOS 13 Ventura。- Debian 11、Debian 12、Ubuntu 20.04 或 Ubuntu 22.04。
- 安装playwright的python版本- pip install playwright
- 安装Playwright所需的所有工具插件和所支持的浏览器- playwright install- 该步骤耗时较长
安装playwright的python版本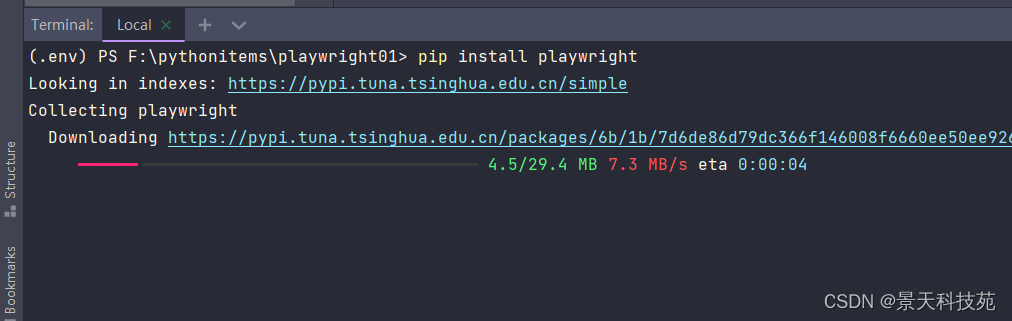
安装Playwright所需的所有工具插件和所支持的浏览器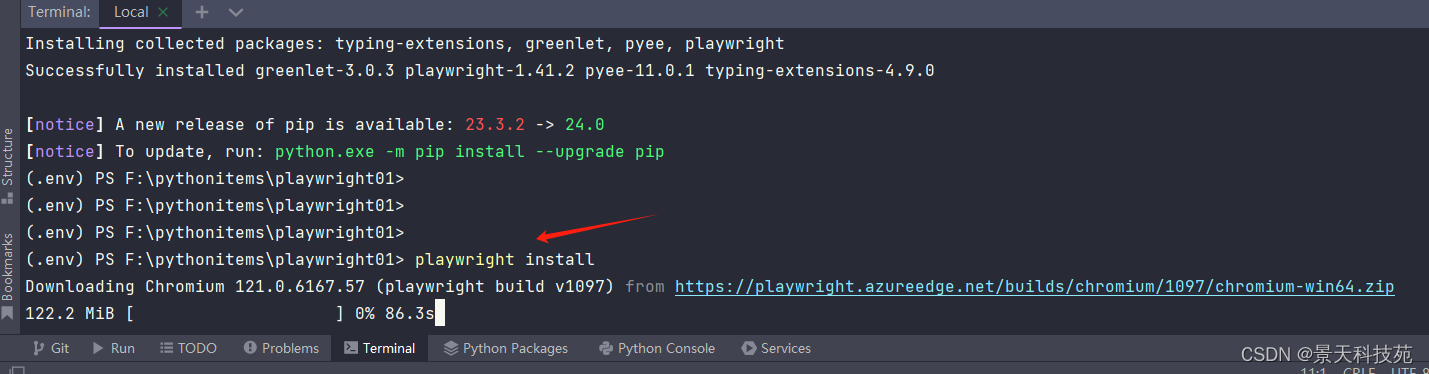
5.屏幕录制
- 创建一个py文件,比如:main.py
- 在终端中,执行如下指令:
- playwright codegen -o main.py- 将屏幕录制生成的代码保存到main.py文件中- 可以通过如下设置,生成同步还是异步的代码:
在终端执行这个命令,会根据我们在浏览器的操作,生成相应的代码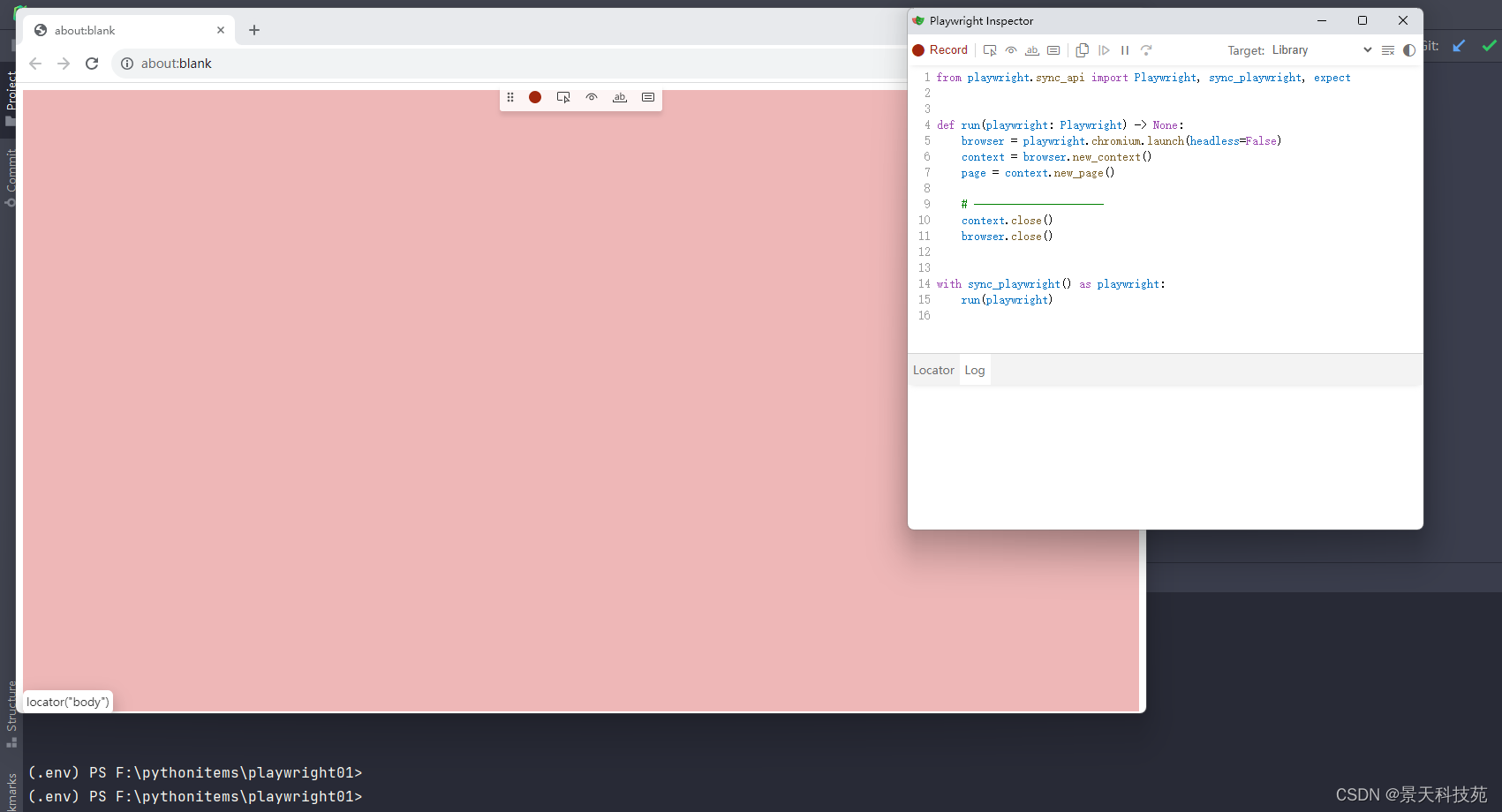
默认生成的代码时同步的,我们可以在target这里修改,Library Async,改为异步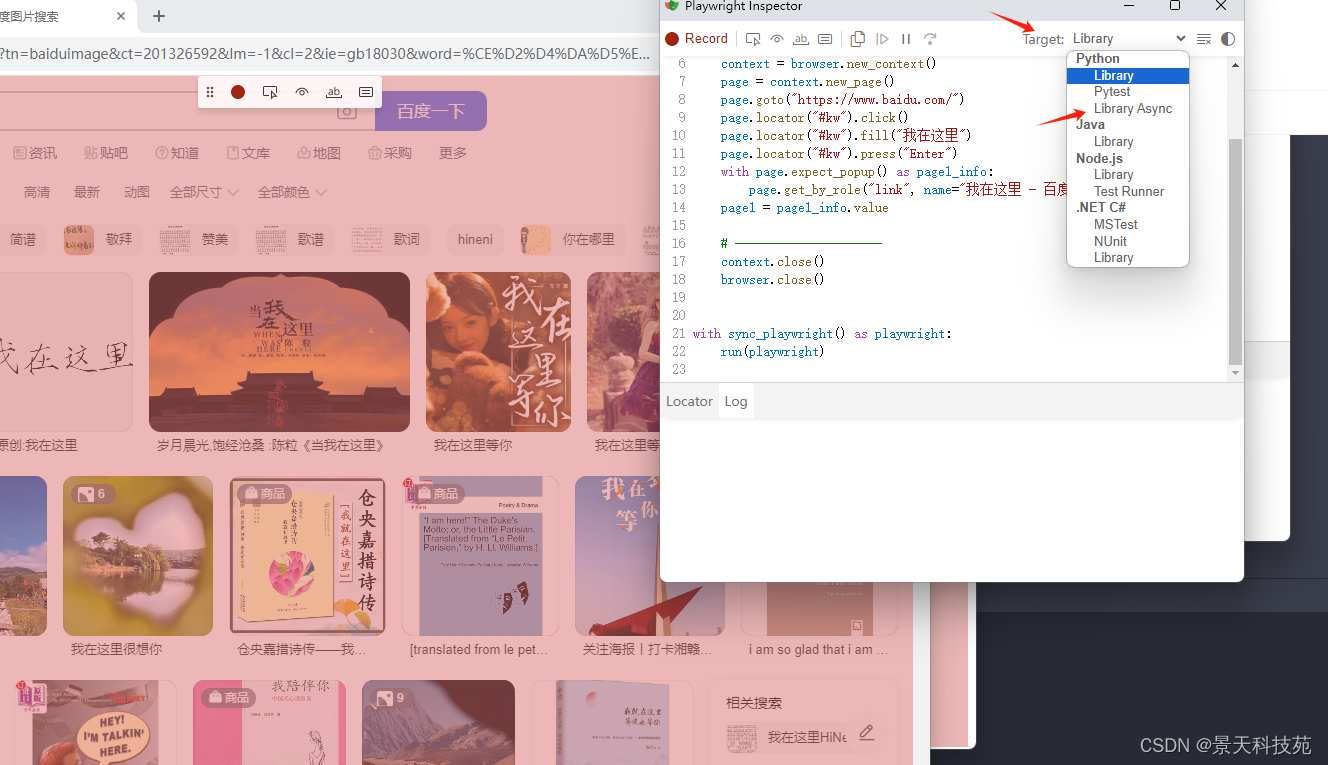
点击停止录制,就会在本地生成我们操作浏览器的代码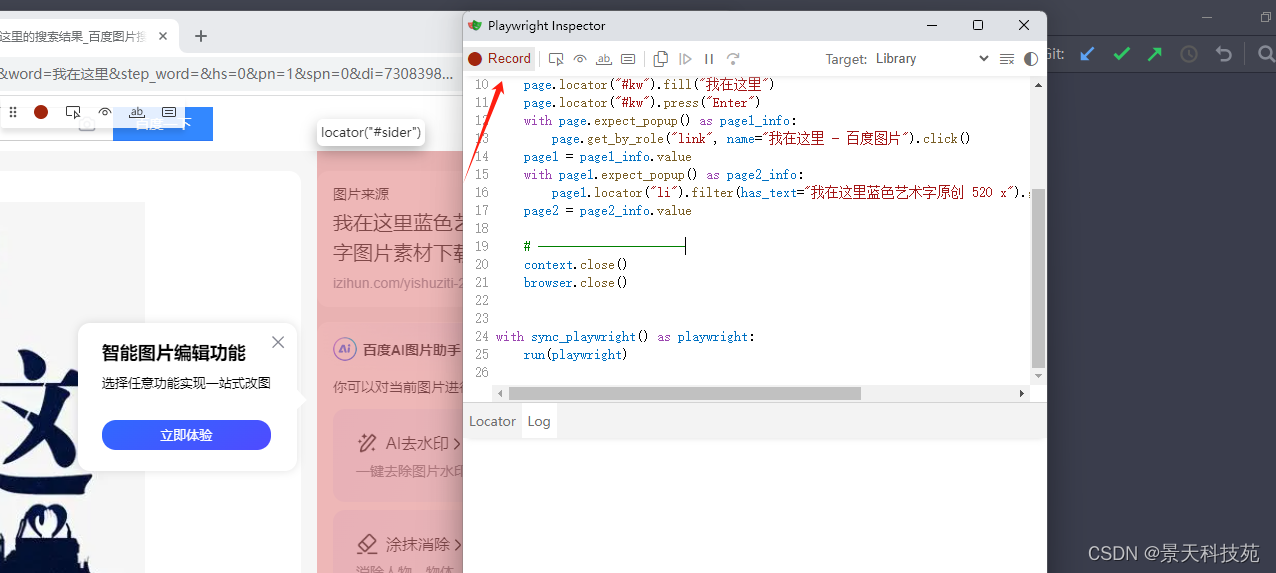
查看生成的爬虫代码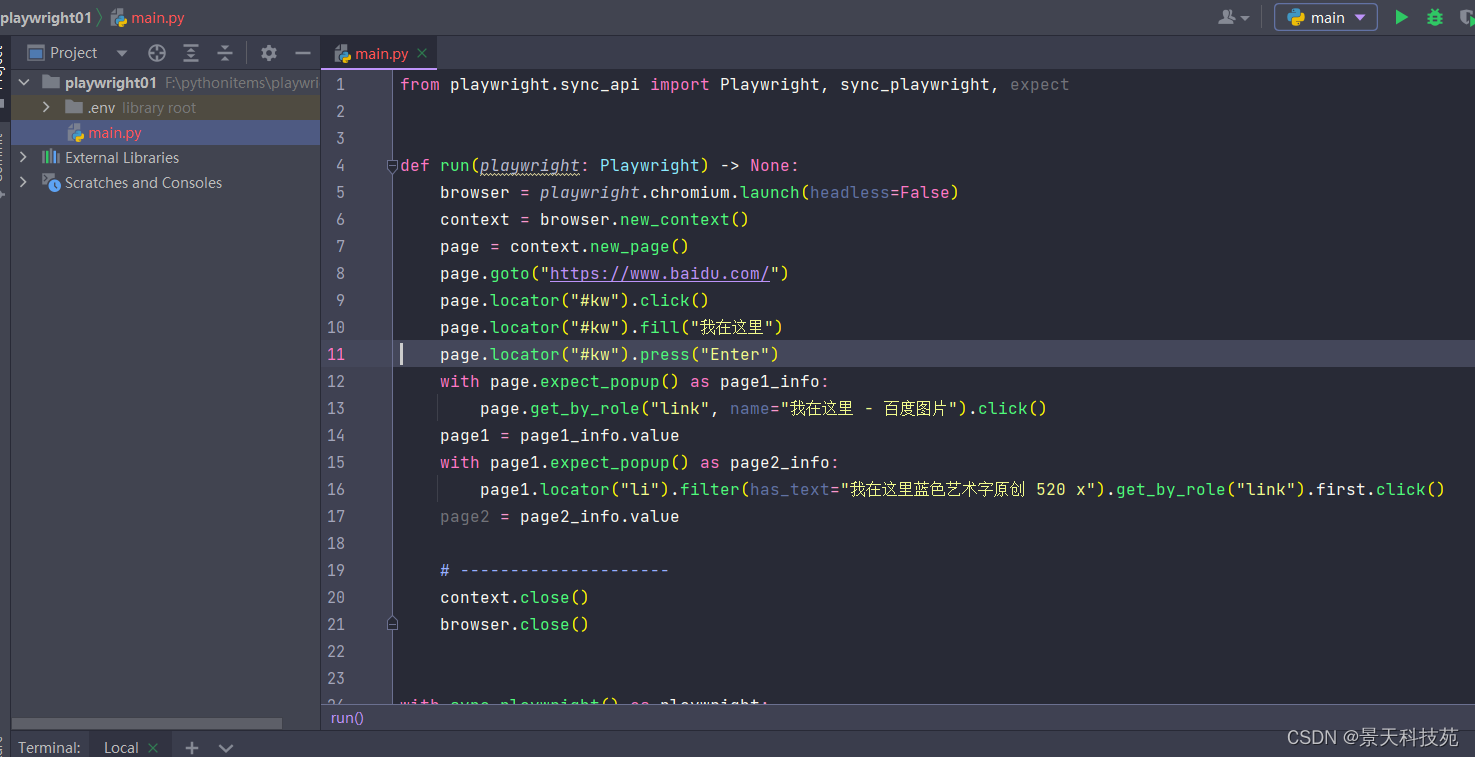
我们可以在本地run测试一下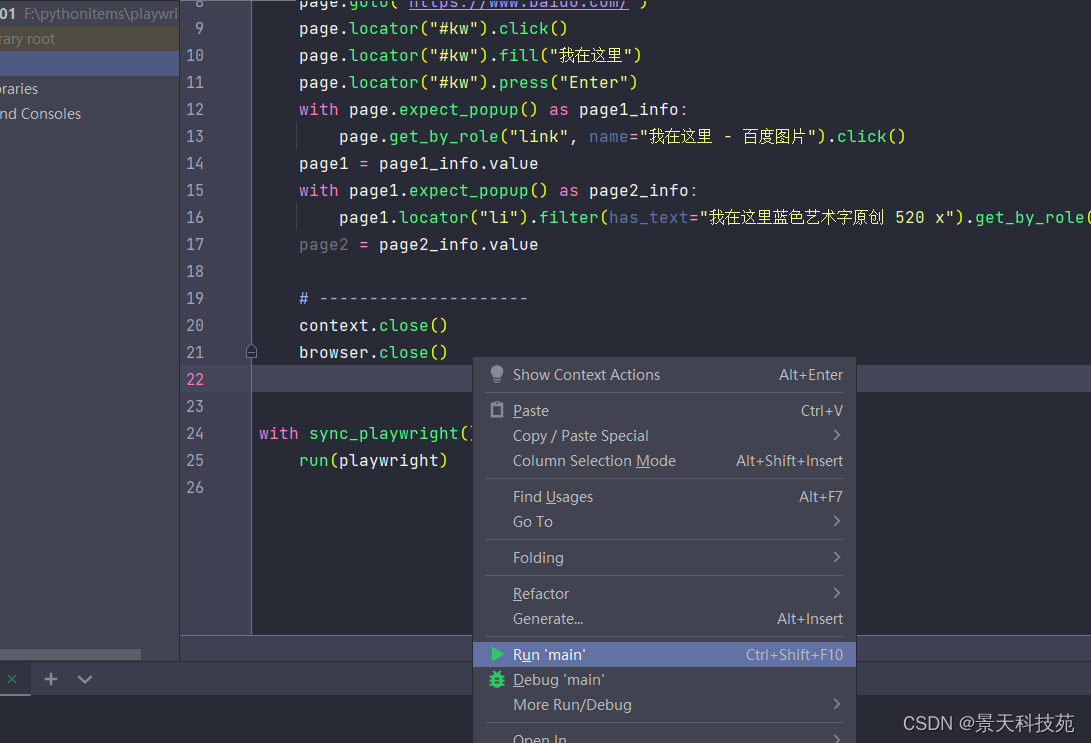
可以看到,程序就会按我们之前操作的步骤运行,全程不用自己手动写代码!!!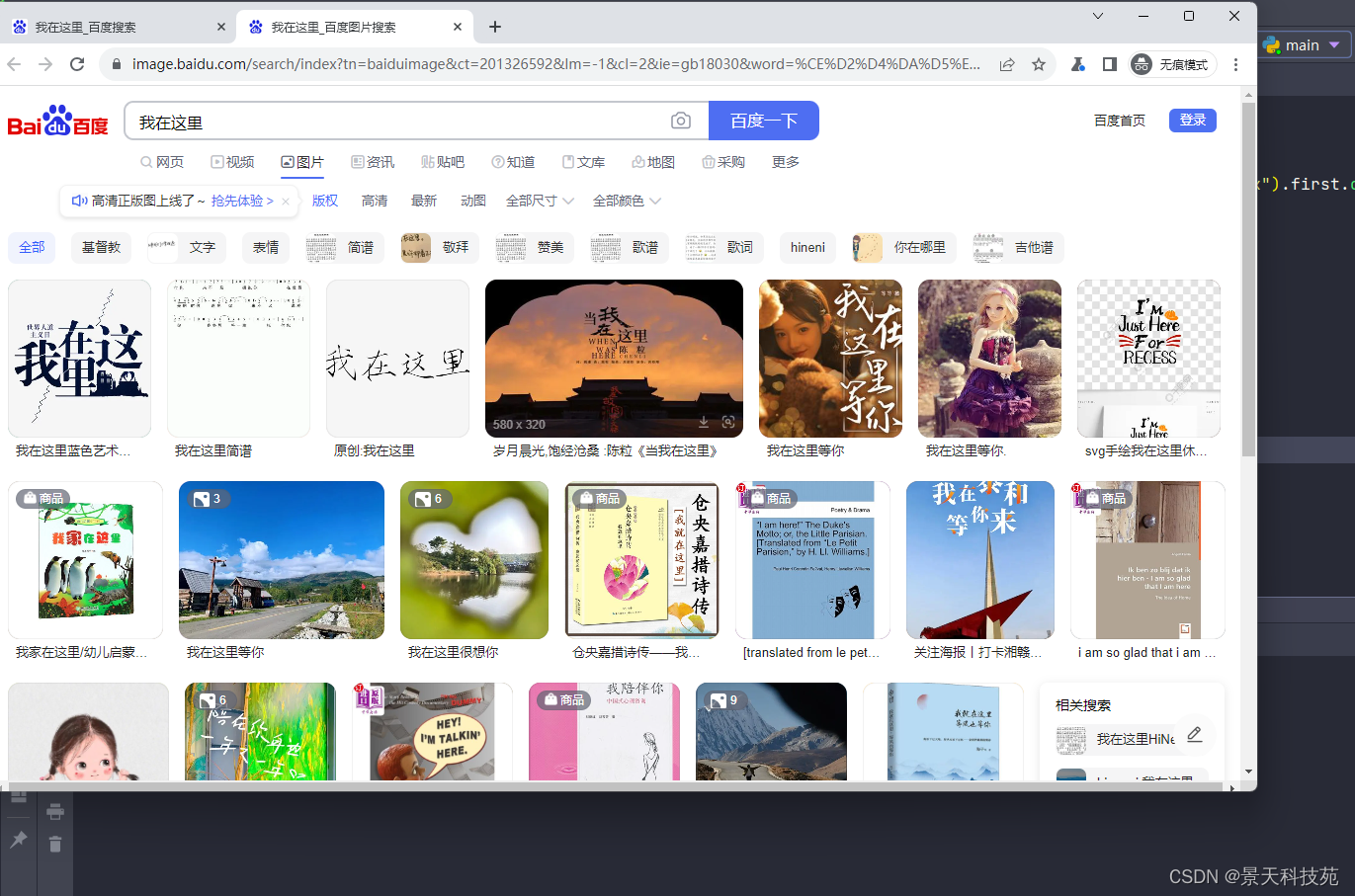
- playwright codegen --viewport-size=800,600 www.baidu.com -o main.py- 访问指定网址,并且设置浏览器窗口大小
playwright codegen --device=“iPhone 13” -o main.py
- 模拟手机设备进行网络请求(只支持手机模拟器,无需单独安装)
- 支持的移动端设备如下:目前对安卓设备的覆盖率不高
"Blackberry PlayBook", "Blackberry PlayBook landscape", "BlackBerry Z30", "BlackBerry Z30 landscape", "Galaxy Note 3", "Galaxy Note 3 landscape", "Galaxy Note II", "Galaxy Note II landscape", "Galaxy S III", "Galaxy S III landscape", "Galaxy S5", "Galaxy S5 landscape", "Galaxy S8", "Galaxy S8 landscape", "Galaxy S9+", "Galaxy S9+ landscape", "Galaxy Tab S4", "Galaxy Tab S4 landscape", "iPad (gen 5)", "iPad (gen 5) landscape", "iPad (gen 6)", "iPad (gen 6) landscape", "iPad (gen 7)", "iPad (gen 7) landscape", "iPad Mini", "iPad Mini landscape", "iPad Pro 11", "iPad Pro 11 landscape", "iPhone 6", "iPhone 6 landscape", "iPhone 6 Plus", "iPhone 6 Plus landscape", "iPhone 7", "iPhone 7 landscape", "iPhone 7 Plus", "iPhone 7 Plus landscape", "iPhone 8", "iPhone 8 landscape", "iPhone 8 Plus", "iPhone 8 Plus landscape", "iPhone SE", "iPhone SE landscape", "iPhone X", "iPhone X landscape", "iPhone XR", "iPhone XR landscape", "iPhone 11", "iPhone 11 landscape", "iPhone 11 Pro", "iPhone 11 Pro landscape", "iPhone 11 Pro Max", "iPhone 11 Pro Max landscape", "iPhone 12", "iPhone 12 landscape", "iPhone 12 Pro", "iPhone 12 Pro landscape", "iPhone 12 Pro Max", "iPhone 12 Pro Max landscape", "iPhone 12 Mini", "iPhone 12 Mini landscape", "iPhone 13", "iPhone 13 landscape", "iPhone 13 Pro", "iPhone 13 Pro landscape", "iPhone 13 Pro Max", "iPhone 13 Pro Max landscape", "iPhone 13 Mini", "iPhone 13 Mini landscape", "iPhone 14", "iPhone 14 landscape", "iPhone 14 Plus", "iPhone 14 Plus landscape", "iPhone 14 Pro", "iPhone 14 Pro landscape", "iPhone 14 Pro Max", "iPhone 14 Pro Max landscape", "Kindle Fire HDX", "Kindle Fire HDX landscape", "LG Optimus L70", "LG Optimus L70 landscape", "Microsoft Lumia 550", "Microsoft Lumia 550 landscape", "Microsoft Lumia 950", "Microsoft Lumia 950 landscape", "Nexus 10", "Nexus 10 landscape", "Nexus 4", "Nexus 4 landscape", "Nexus 5", "Nexus 5 landscape", "Nexus 5X", "Nexus 5X landscape", "Nexus 6", "Nexus 6 landscape", "Nexus 6P", "Nexus 6P landscape", "Nexus 7", "Nexus 7 landscape", "Nokia Lumia 520", "Nokia Lumia 520 landscape", "Nokia N9", "Nokia N9 landscape", "Pixel 2", "Pixel 2 landscape", "Pixel 2 XL", "Pixel 2 XL landscape", "Pixel 3", "Pixel 3 landscape", "Pixel 4", "Pixel 4 landscape", "Pixel 4a (5G)", "Pixel 4a (5G) landscape", "Pixel 5", "Pixel 5 landscape", "Pixel 7", "Pixel 7 landscape", "Moto G4", "Moto G4 landscape"
6.保留记录cookie信息
录制过程中,如果用到了cookie,playwright会自动将cookie信息保存到指定文件中,文件一定要是json类型文件
- playwright codegen --save-storage=auth.json https://www.17k.com - 在屏幕录制时,进行登录操作,登录后,cookie信息会被保存到auth.json文件中 在终端执行

手动登录一次
关掉页面
在本地生成一个json文件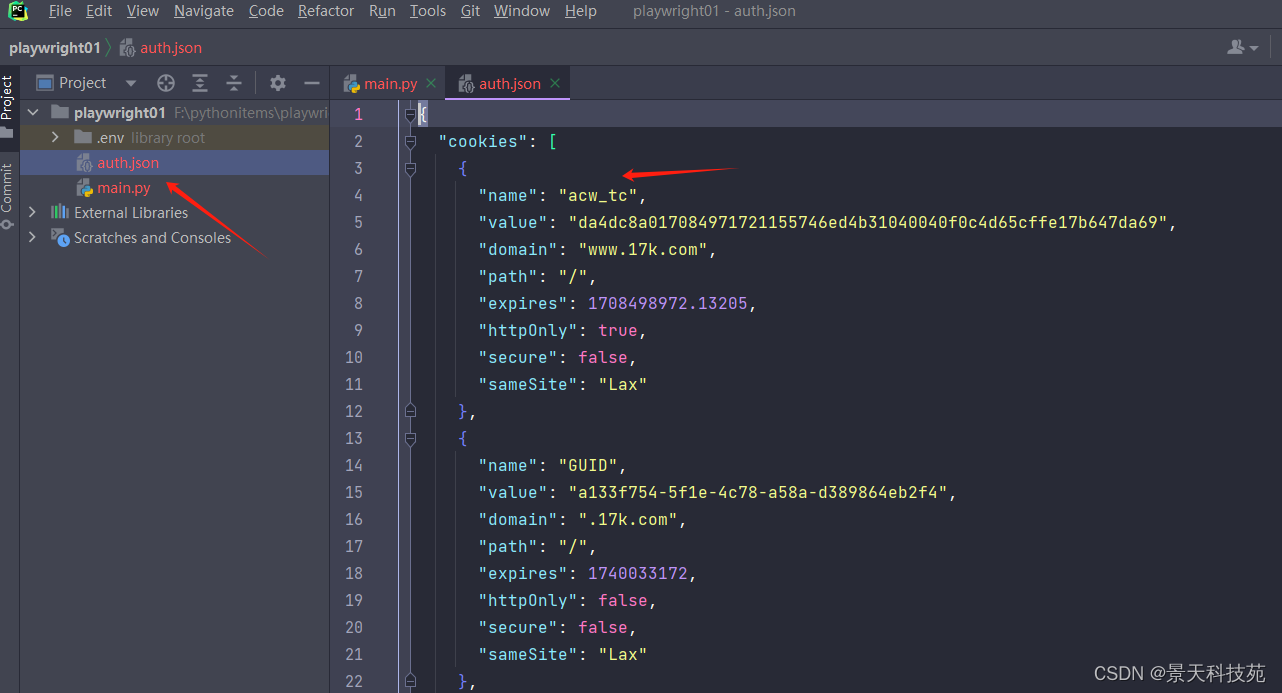
我们可以再次录制,基于之前生成的json文件,这次程序就可以自动登录了
- playwright codegen --load-storage=auth.json https://www.17k.com -o main.py - 基于auth.json进行屏幕录制,会自动进入到登录成功后的页面中
可以看到账号的书架了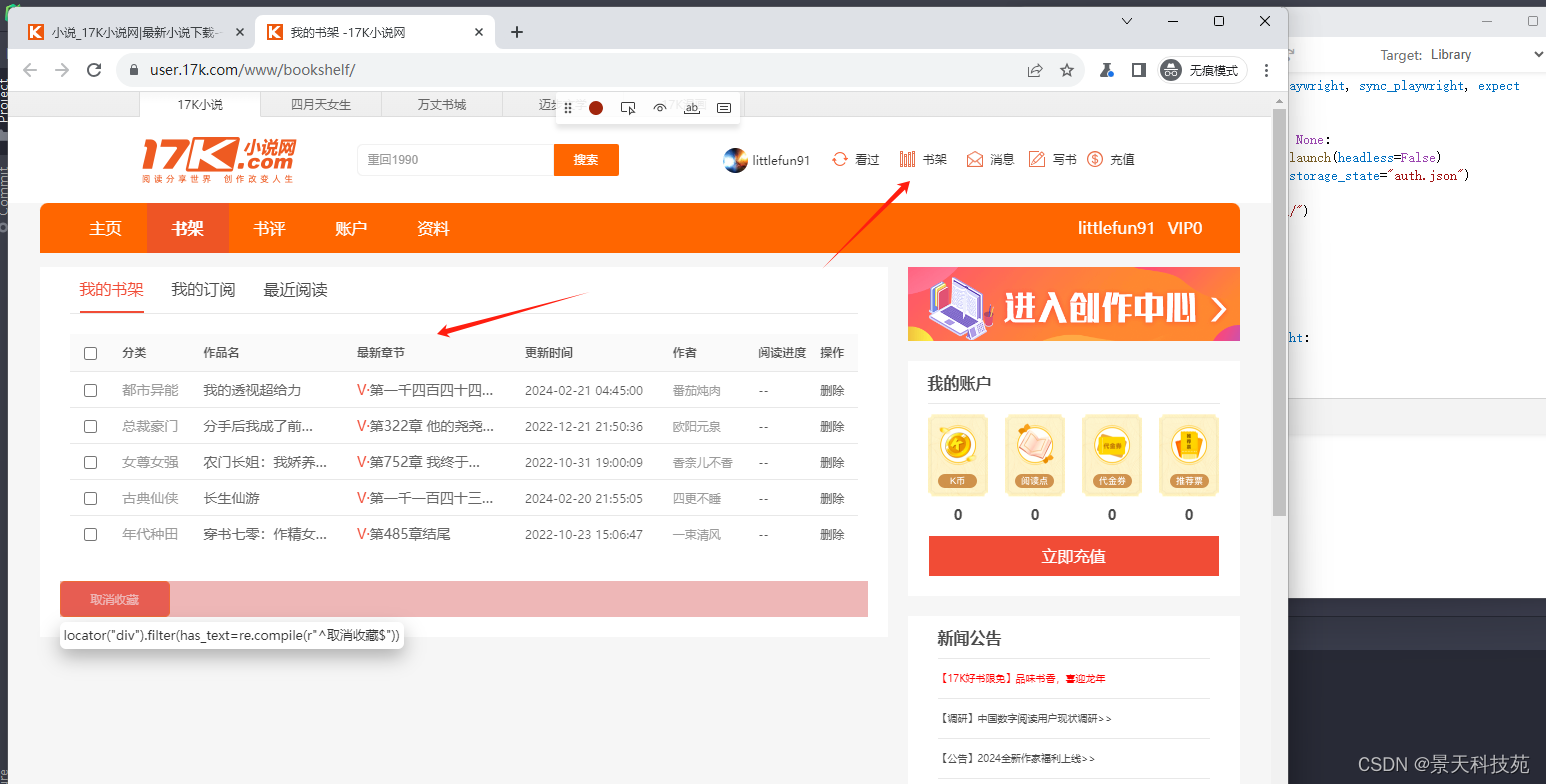
7.playwright代码编写详解
playwright我们用with语句启动,可以避免:
1、忘记关闭文件
2、语句有异常,未做处理
在看下之前用start和stop的启动方式
from playwright.sync_api import sync_playwright # 先导包
playwright = sync_playwright().start() # 创建playwright对象
browser = playwright.chromium.launch(headless=False) # 启动谷歌浏览器赋值给对象
page = browser.new_page() # 打开一个页面
page.goto(‘https://www.baidu.com/’) # 打开百度地址
browser.close() # 关闭浏览器对象
playwright.stop() # 关闭playwright对象释放资源
1.第一个Playwright脚本
(1)同步模式
from playwright.sync_api import sync_playwright #导入同步模块#创建一个Playwright的管理器对象with sync_playwright()as p:# p = sync_playwright()#基于p创建一个浏览器对象(默认就是谷歌浏览器对象)
bro = p.chromium.launch(headless=False)#创建一个浏览器页面
page = bro.new_page()#在指定的页面中进行请求发送
page.goto('https://www.baidu.com')#暂定2s中
page.wait_for_timeout(2000)#获取访问页面的标题
title = page.title()#获取页面的页面源码数据(重要=》可见即可得)
page_text = page.content()print(page_text,title)
page.close()
bro.close()
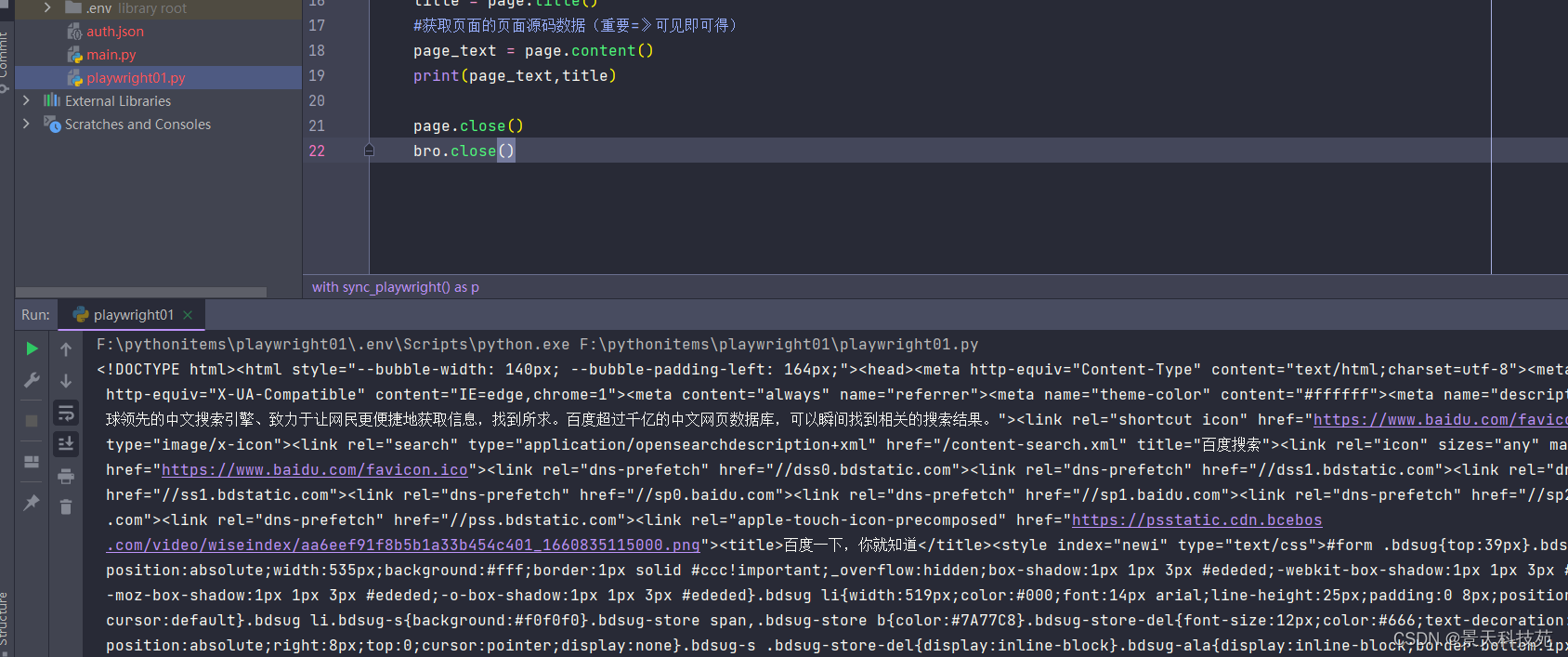
(2)异步模式
import asyncio
from playwright.async_api import async_playwright
#封装一个特殊的函数asyncdefmain():asyncwith async_playwright()as p:# p = sync_playwright()# 基于p创建一个浏览器对象(谷歌浏览器对象)
bro =await p.chromium.launch(headless=False)# 创建一个浏览器页面
page =await bro.new_page()# 在指定的页面中进行请求发送await page.goto('https://www.baidu.com')# 暂定2s中await page.wait_for_timeout(2000)# 获取访问页面的标题
title =await page.title()# 获取页面的页面源码数据(重要=》可见即可得)
page_text =await page.content()print(page_text, title)await page.close()await bro.close()
asyncio.run(main())
我们写的更多的是同步代码
2.元素定位(重点)
比较常用的有两种,css选择器和xpath选择器
(1)CSS选择器定位
- 语法结构:page.locator() - 参数:标签/id/层级/class 选择器
- 交互操作: - 点击元素, click() 方法- 元素内输入文本, fill() 方法
我们先看下浏览器中的标签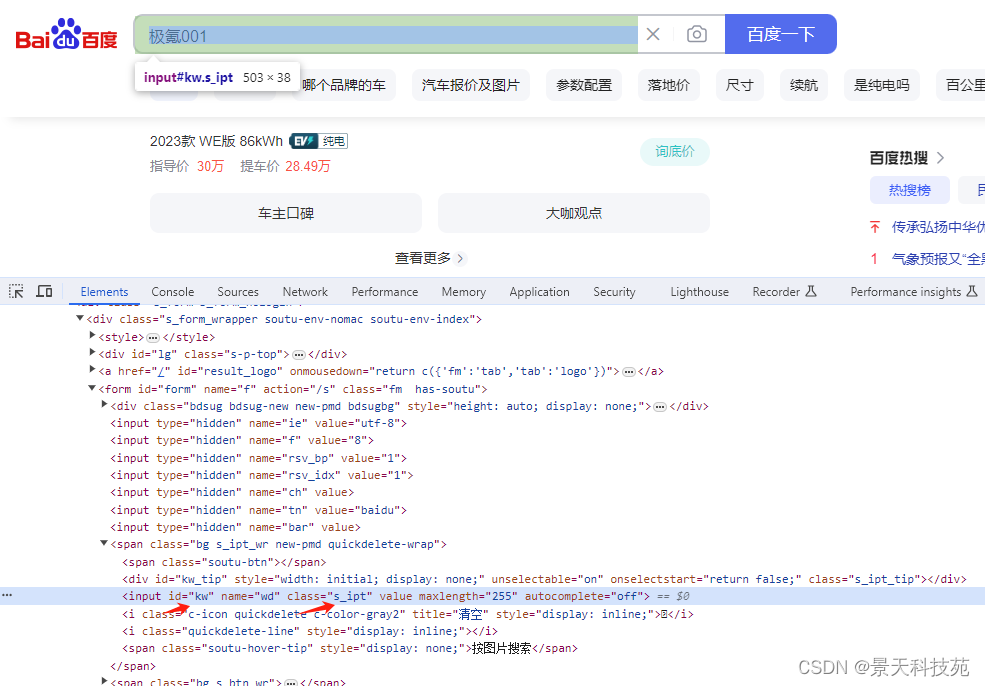
代码:
from playwright.sync_api import sync_playwright
with sync_playwright()as p:
bro = p.chromium.launch(headless=False,slow_mo=2000)#slow_mo放慢执行速度,从而可以容易跟踪操作,单位是毫秒。是全局的每步操作的等待时间
page = bro.new_page()
page.goto('https://www.baidu.com')#定位到输入框,进行文本录入
page.locator('#kw').fill('Python教程')#id定位# 定位搜索按钮,进行点击操作
page.locator('#su').click()#go_back() 后退操作,go_forward() 是页面前进
page.go_back()
page.locator('.s_ipt').fill('爬虫')# class定位 class里面如果有空格的话,空格切分的都是class的属性值,选择器选择的拿其中一个就行,但是这个class必须唯一才能选到
page.locator('#su').click()
page.go_back()
page.locator('input#kw').fill('人工智能')# 标签+属性定位
page.locator('#su').click()
page.go_back()
page.locator('#form > span > input#kw').fill('数据分析')#层级定位
page.locator('#su').click()
page.close()
bro.close()
针对class选择器,如果某个class属性有多个标签使用的话,可以使用标签+属性值一起定位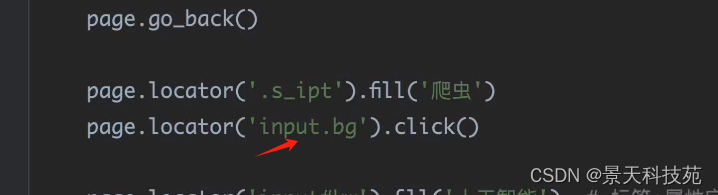
3.设置内容输入的时间间隔
from playwright.sync_api import sync_playwright
with sync_playwright()as p:
bro = p.chromium.launch(headless=False)
page = bro.new_page()
page.goto('https://www.baidu.com')#方式1:#input_tag = page.locator('#kw').press_sequentially('hello world',delay=500)#方式2:设置内容的输入的时间间隔
tag = page.locator('#kw')#id定位
tag.focus()#聚焦于当前标签
input_text ='Hello, World!'for char in input_text:
page.keyboard.type(char, delay=500)# 定位搜索按钮,进行点击操作
page.locator('#su').click()
page.close()
bro.close()
模拟人的操作,一个一个字符输入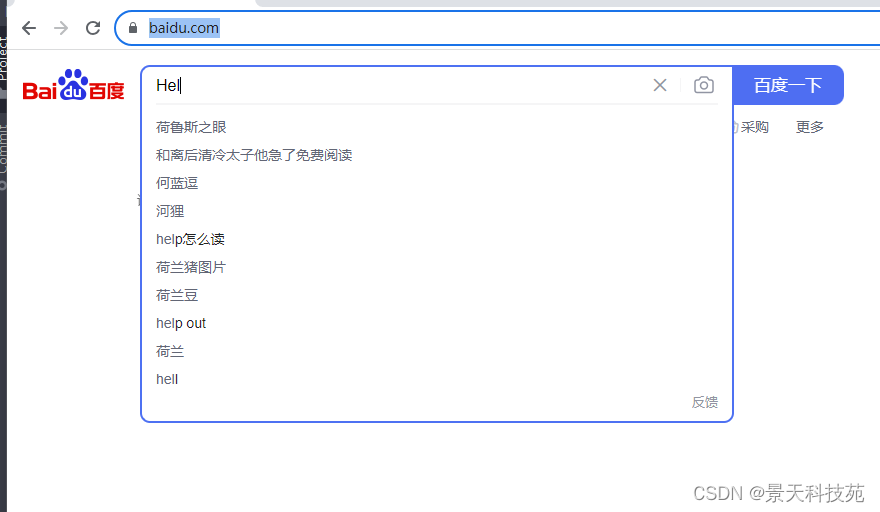
4.更多操作
- locator.all() #获取所有标签
- locator.count() #获取标签个数
- locator.nth(index) #根据标签索引获取某个标签
- inner_text() #获取标签内的所有文本内容
- get_by_text(xxx) #根据标签的文本内容做标签定位
- get_attribute(attrName) #获取标签属性值
- taobao在不登录情况下无法进行商品搜索,因此需要手动登录,保留Cookie信息- playwright codegen --save-storage=taobao.json https://www.taobao.com
- 携带Cookie信息进行操作:- context = browser.new_context(storage_state=“taobao.json”)
代码:
from playwright.sync_api import Playwright, sync_playwright, expect
with sync_playwright()as p:
browser = p.chromium.launch(headless=False,slow_mo=2000)
context = browser.new_context(storage_state="taobao.json")#创建页面时,通过context来创建,此时创建的页面就携带了我们的cookie
page = context.new_page()
page.goto("https://www.taobao.com/")
page.locator('#q').fill('mac pro')# class属性值为btn-search tb-bg,在定位的时候选择空格左右两侧任意一个属性值即可,但是一定要确认是唯一的
page.locator('.btn-search').click()
page.wait_for_timeout(1000)# 根据文本定位
page.get_by_text('发货地').click()
page.wait_for_timeout(1000)# 定位到满足要求所有的标签(商品列表最外层的a标签)
locator = page.locator('.Content--contentInner--QVTcU0M > div > a')
all_eles = locator.all()#将标签保存到列表中# 查看定位到满足要求标签的数量
count = locator.count()print(count)# 定位到第10个a标签,nth下标从0开始
a_10 = locator.nth(9)#get_attribute('href')得到href属性值,inner_text()是文本内容,所有文本内容print(a_10.get_attribute('href'), a_10.inner_text())print('---------------------------------------------------------------------------')# 获得每一个a标签中的文本内容和href属性值for index inrange(count):
ele = locator.nth(index)#得到第几个标签
text = ele.inner_text()
href = ele.get_attribute('href')print(text, href)
page.close()
context.close()
browser.close()
5.xpath定位
page.locator(xpath表达式)
from playwright.sync_api import sync_playwright
with sync_playwright()as p:
bro = p.chromium.launch(headless=False,slow_mo=2000)
page = bro.new_page()
page.goto('https://www.bilibili.com/')#xpath定位
page.locator('//*[@id="nav-searchform"]/div[1]/input').fill('Python教程')
page.locator('//*[@id="nav-searchform"]/div[2]').click()
page.wait_for_timeout(4000)
page.close()
bro.close()
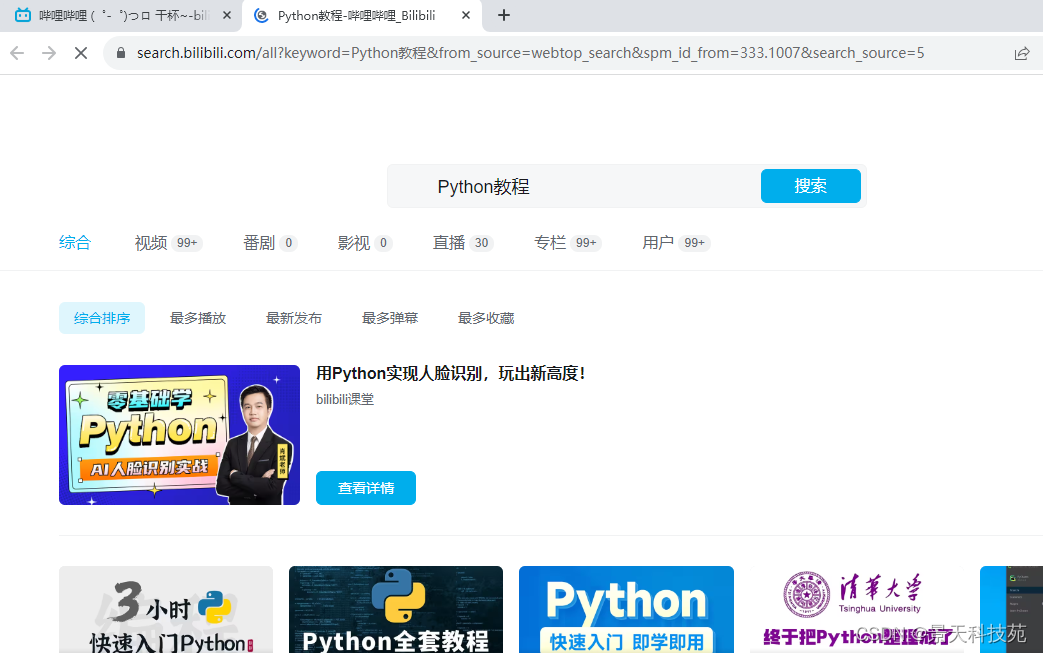
6.Context上下文(重点)
浏览器的上下文管理对象Context可以用于管理Context打开/创建的多个page页面。
并且可以创建多个Context对象,那么不同的Context对象打开/创建的page之间是相互隔离的(每个Context上下文都有自己的Cookie、浏览器存储和浏览历史记录)。
- 打开百度的多个链接对应的page页面
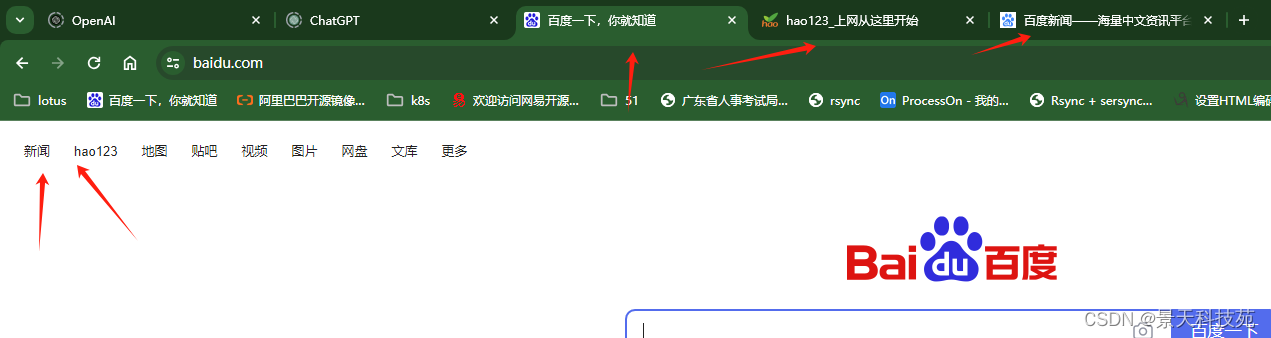
看下标签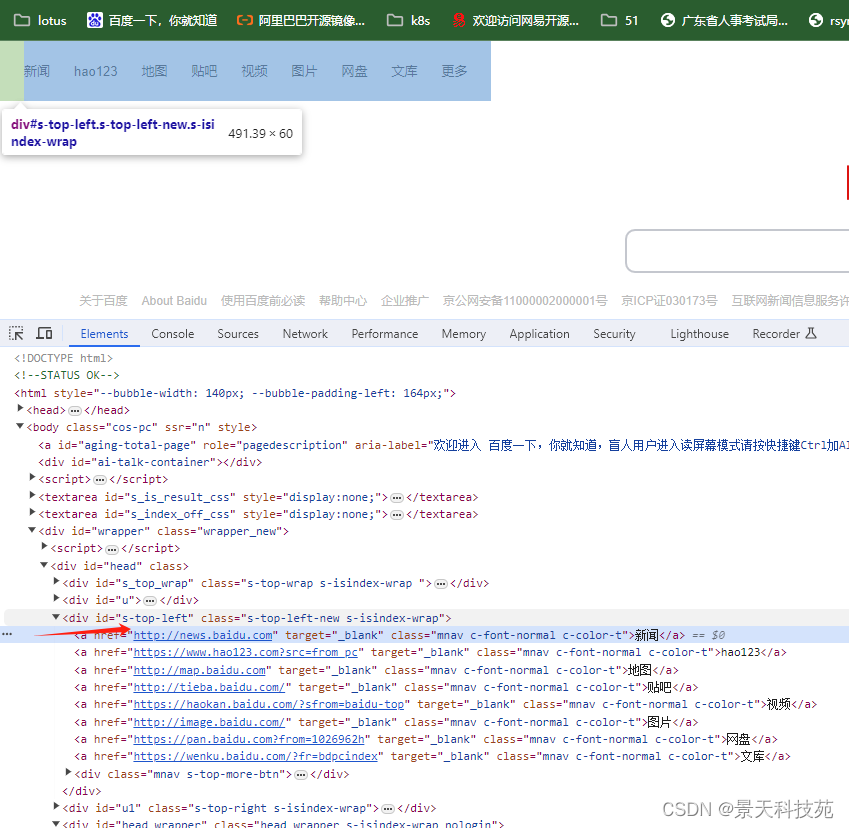
from playwright.sync_api import sync_playwright
# 点击百度首页中左上角的全部链接,以打开多个不同的page页面with sync_playwright()as p:
bro = p.chromium.launch(headless=False, slow_mo=1000)# 创建上下文管理对象
context = bro.new_context()# 基于上下文管理对象打开一个page页面
page = context.new_page()
page.goto('https://www.baidu.com')# 点击百度首页中左上角的全部链接,以打开多个不同的page页面
a_list = page.locator('//*[@id="s-top-left"]/a').all()for a in a_list:
a.click()# 使用上下文管理对象获取浏览器打开的所有page页面
pages = context.pages
for sub_page in pages:# 遍历每一个page,打印起page标题print(sub_page.title())
page.wait_for_timeout(3000)
page.close()
bro.close()
可以看到可以打印出每个page的title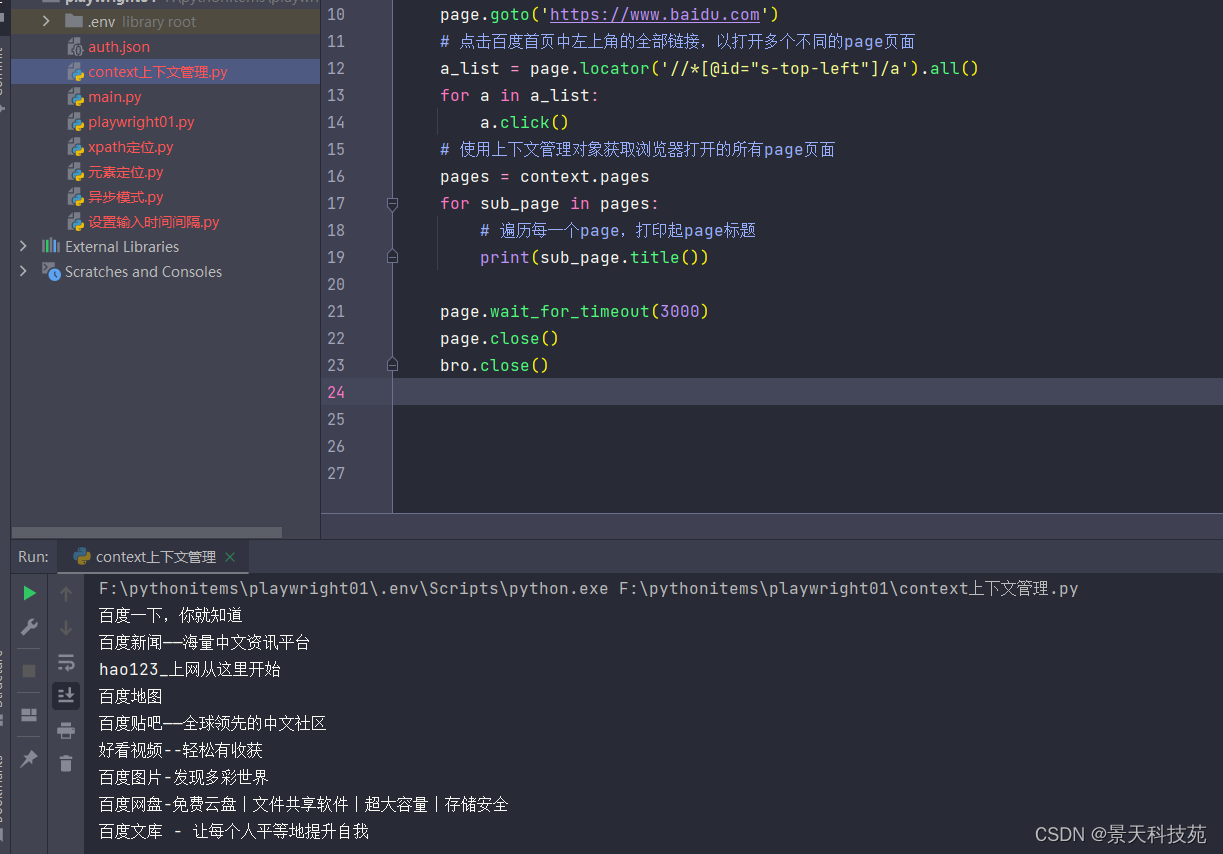
通过sub_page的title判断进行sub_page页面的切换和管理
from playwright.sync_api import sync_playwright
# 封装页面切换的函数defswitch_to_page(context, title):for page in context.pages:if title == page.title():# 浏览器停留在此page页面
page.bring_to_front()return page
# 点击百度首页中左上角的全部链接,以打开多个不同的page页面with sync_playwright()as p:
bro = p.chromium.launch(headless=False, slow_mo=1000)# 创建上下文管理对象
context = bro.new_context()# 基于上下文管理对象打开一个page页面
page = context.new_page()
page.goto('https://www.baidu.com')# 点击百度首页中左上角的全部链接,以打开多个不同的page页面
a_list = page.locator('//*[@id="s-top-left"]/a').all()for a in a_list:
a.click()# page页面的切换,switch_to_page是自己封装的函数
select_page = switch_to_page(context,'hao123_上网从这里开始')# 在指定的page中进行相关操作
select_page.locator('//*[@id="search"]/form/div[2]/input').fill('测试测试')
select_page.locator('//*[@id="search"]/form/div[3]/input').click()
page.close()
bro.close()
页面切换到hao123,并输入指定内容点击查询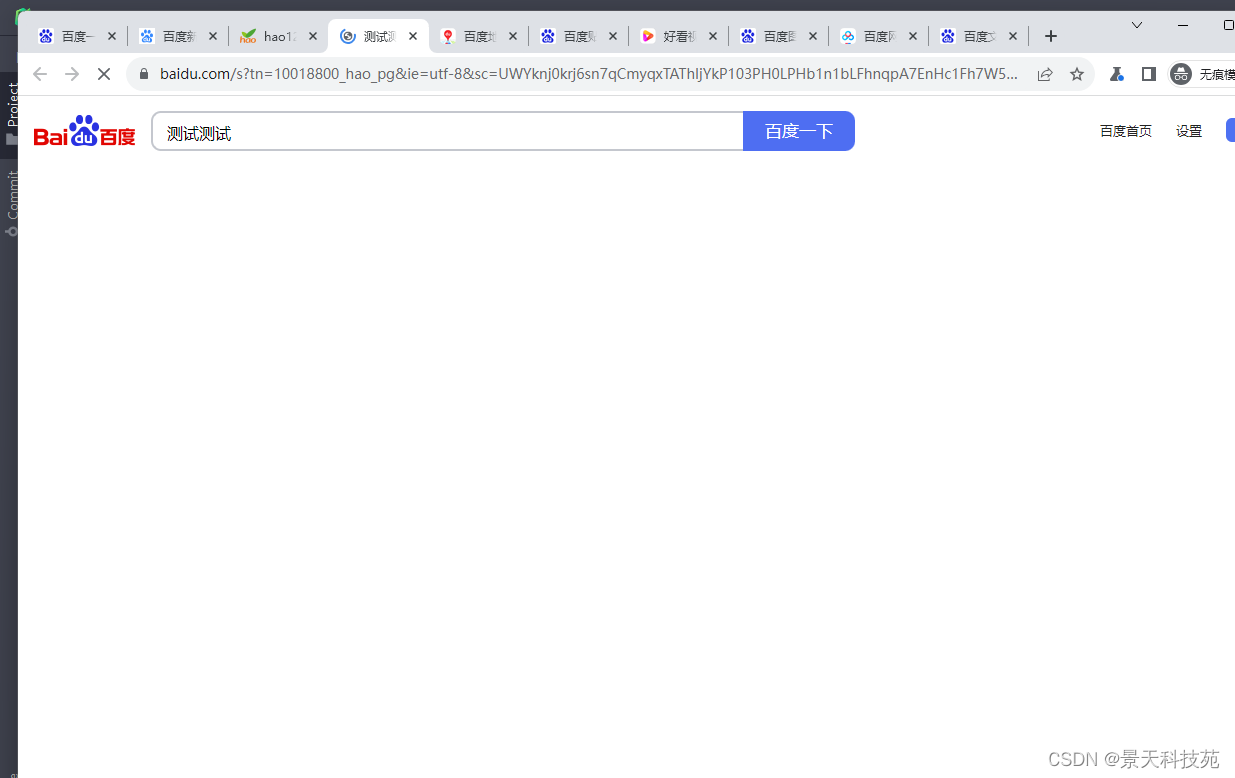
7.实战案例
- 抓取bili中指定关键字搜索页面中视频的标题和作者名称
from playwright.sync_api import sync_playwright
from lxml import etree
#封装页面切换的函数,可以根据标题,也可以根据url等切换defswitch_to_page(context,title):for page in context.pages:if title == page.title():#浏览器停留在此page页面
page.bring_to_front()return page
with sync_playwright()as p:
bro = p.chromium.launch(headless=False,slow_mo=1000)
context = bro.new_context()
page = context.new_page()
page.goto('https://www.bilibili.com/')#xpath定位
page.locator('//*[@id="nav-searchform"]/div[1]/input').fill('Python教程')
page.locator('//*[@id="nav-searchform"]/div[2]').click()#切换到新打开的page中,我们封装的函数返回的就是需要的页面
select_page = switch_to_page(context,'Python教程-哔哩哔哩_Bilibili')
page_text = select_page.content()
tree = etree.HTML(page_text)
div_list = tree.xpath('//*[@id="i_cecream"]/div/div[2]/div[2]/div/div/div/div[3]/div/div')for div in div_list:
title = div.xpath('.//h3[@class="bili-video-card__info--tit"]/@title')[0]
author = div.xpath('.//span[@class="bili-video-card__info--author"]/text()')[0]print(title,author)
page.wait_for_timeout(3000)
page.close()
bro.close()
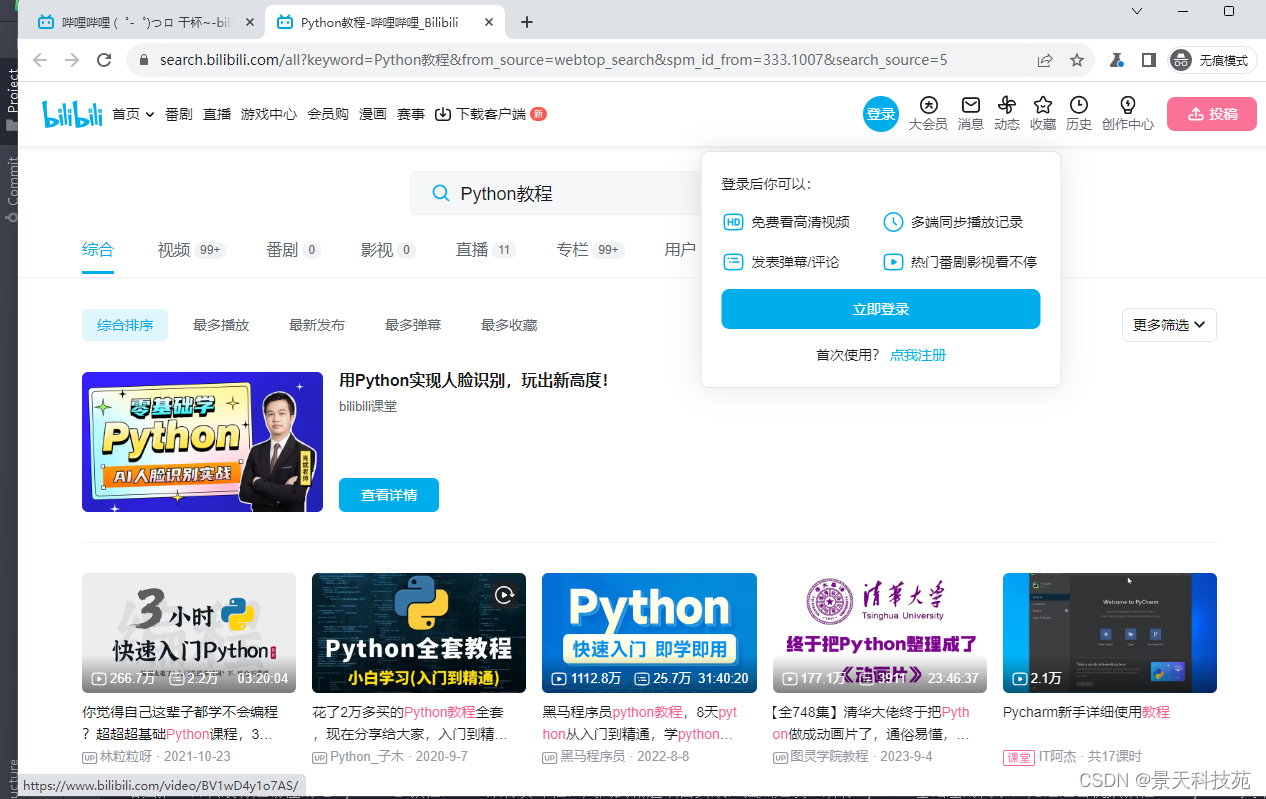
得到查出来的视频课程名称和作者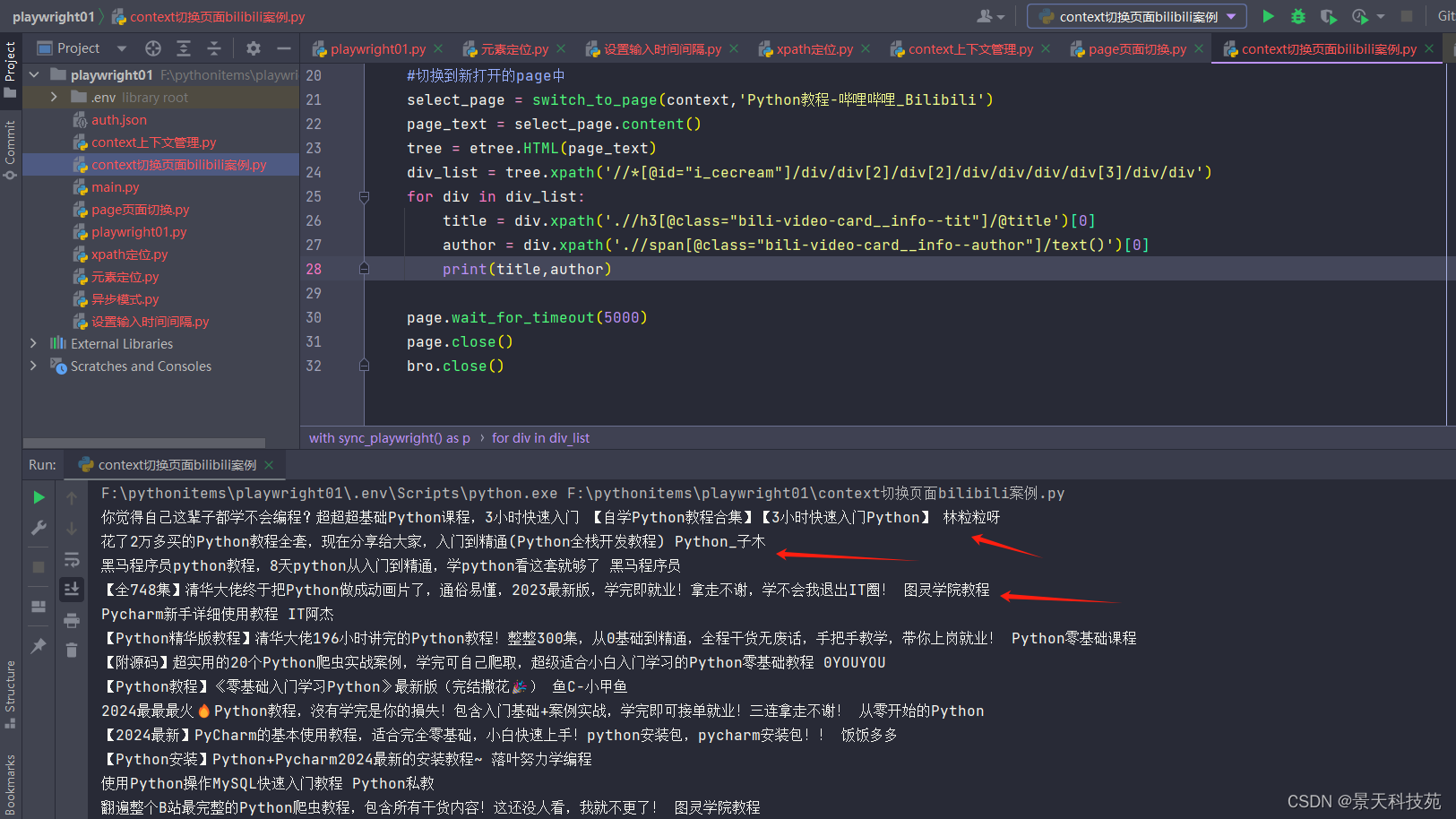
不同用户登录,加载不同cookie就可以使用context,不用用户使用不同context。没必要使用多个浏览器
当爬虫逆向比较困难时,可以结合playwright来爬取数据
逆向中,playwright可以很好做浏览器环境补充
这些playwright进阶用法,我们下次接着讲,感兴趣的朋友请一键三连,谢谢!
版权归原作者 景天科技苑 所有, 如有侵权,请联系我们删除。