
本文介绍如何在win系统中使用IDEA开发spark应用程序,并将其打成jar包上传到虚拟机中的三个Ubuntu系统,然后在分布式环境中运行。
主要步骤包括:
- 安装Scala插件:在Intellij IDEA中安装Scala插件,并重启IDEA。
- 创建Maven项目:在Intellij IDEA中创建一个Maven项目,选择Scala语言,并添加Spark和HBase依赖。
- 配置Scala SDK:在Intellij IDEA中添加Scala SDK,并给项目添加Scala支持。
- 编写Spark应用程序:在src/main/scala目录下创建一个Scala对象,并编写Spark代码。
- 打包和运行Spark项目:在本地模式下测试Spark应用程序,打包成jar包,上传到虚拟机中的master节点,使用spark-submit命令提交到集群。
基础环境
首先确保已经在虚拟机中安装配置好Hadoop,HBase和Spark,并且可以正常运行。本文假设已经按照之前文章的步骤搭建了一个三节点的Hadoop集群,其中scala版本为2.12,hbase版本为2.3.7,spark版本为3.2.3,hadoop版本为3.2.4
一、安装Scala插件
- 在Intellij IDEA中,选择File->Settings->Plugins,在Marketplace中搜索scala进行安装,安装后根据提示重启IDEA。
二、创建Maven项目
- 在Intellij IDEA中,选择File->New->Project,选择Maven作为项目类型,填写项目名称和位置。
- 在pom.xml文件中添加Spark和HBase相关的依赖,注意要与虚拟机中的Spark版本和Scala版本保持一致。本文使用的是Spark 3.2.3和Scala 2.12。例如:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>sparkhbase</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<hbase.version>2.3.7</hbase.version>
<hadoop.version>3.2.4</hadoop.version>
<spark.version>3.2.3</spark.version>
<scala.version>2.12</scala.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase</artifactId>
<version>${hbase.version}</version>
<type>pom</type>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
</project>
三、配置Scala SDK
- 在Intellij IDEA中,选择File->Project Structure->Global Libraries,添加Scala SDK,选择本地安装的Scala版本。
- 在项目中右键选择Add Framework Support,在弹出的对话框中勾选Scala,并选择对应的SDK。
四、编写Spark应用程序
- 在src/main/scala目录下创建一个包,例如com.spark.example,并在该包下创建一个Scala对象,例如WordCountFromHBase。编写Spark应用程序的代码,例如:
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.hbase.client.{Connection, ConnectionFactory, Scan}
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.{SparkConf, SparkContext}
object WordCountFromHBase {
def main(args: Array[String]): Unit = {
//创建Spark配置对象
val conf = new SparkConf().setAppName("WordCountFromHBase").setMaster("local")
//创建Spark上下文对象
val sc = new SparkContext(conf)
//创建HBase配置对象
val hbaseConf = HBaseConfiguration.create()
//设置HBase的Zookeeper地址
hbaseConf.set("hbase.zookeeper.quorum", "hadoop100:2181,hadoop200:2181,hadoop201:2181")
//设置HBase的Zookeeper端口
hbaseConf.set("hbase.zookeeper.property.clientPort", "2181")
//设置要读取的HBase表名,提前通过hbase shell创建
val tableName = "testtable"
hbaseConf.set(TableInputFormat.INPUT_TABLE, tableName)
//创建HBase连接对象
val connection: Connection = ConnectionFactory.createConnection(hbaseConf)
//获取HBase表对象
val table = connection.getTable(TableName.valueOf(tableName))
//创建一个扫描对象,指定要读取的列族和列名
val scan = new Scan()
scan.addColumn(Bytes.toBytes("f"), Bytes.toBytes("word"))
//将扫描对象转换为字符串,设置到HBase配置对象中
hbaseConf.set(TableInputFormat.SCAN, TableMapReduceUtil.convertScanToString(scan))
//从HBase中读取数据,返回一个RDD
val hbaseRDD = sc.newAPIHadoopRDD(hbaseConf, classOf[TableInputFormat], classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable], classOf[org.apache.hadoop.hbase.client.Result])
//对RDD进行单词统计
val wordCount = hbaseRDD.map(tuple => {
//获取Result对象
val result = tuple._2
//获取word列的值,转换为字符串
val word = Bytes.toString(result.getValue(Bytes.toBytes("f"), Bytes.toBytes("word")))
//返回(word, 1)的元组
(word, 1)
}).reduceByKey((a, b) => a + b)
//打印结果
wordCount.foreach(println)
//关闭Spark上下文和HBase连接
sc.stop()
connection.close()
}
}
五、打包和运行Spark项目
在Intellij IDEA中右键运行WordCountFromHBase对象,可以在本地模式下测试Spark应用程序是否正确。如果没有问题,可以进行打包操作。
在Intellij IDEA中打开Maven工具栏,双击lifecycle下的package命令,将项目打成jar包。打包完成后的jar包在target目录下,例如spark-example-1.0-SNAPSHOT.jar。
将jar包上传到虚拟机中的hadoop100主节点,userjar/目录。
在master节点上使用spark-submit命令提交Spark应用程序到集群,指定jar包路径和主类名。例如:
spark-submit --class com.spark.example.WordCountFromHBase spark-example-1.0-SNAPSHOT.jar
- 查看Spark应用程序的运行结果,可以在终端中输出,也可以在Spark Web UI中查看。
打包方式二:
File->Project Structure->artifacts->点击加号->JAR->from model->点击Main Class选项框后的文件夹->点击Projet->选择main方法->点击ok

仅保留类似红框中函数名的程序包,去掉多余依赖,打成比较小的jar包,需要linux中的软件环境与依赖版本相同才能运行
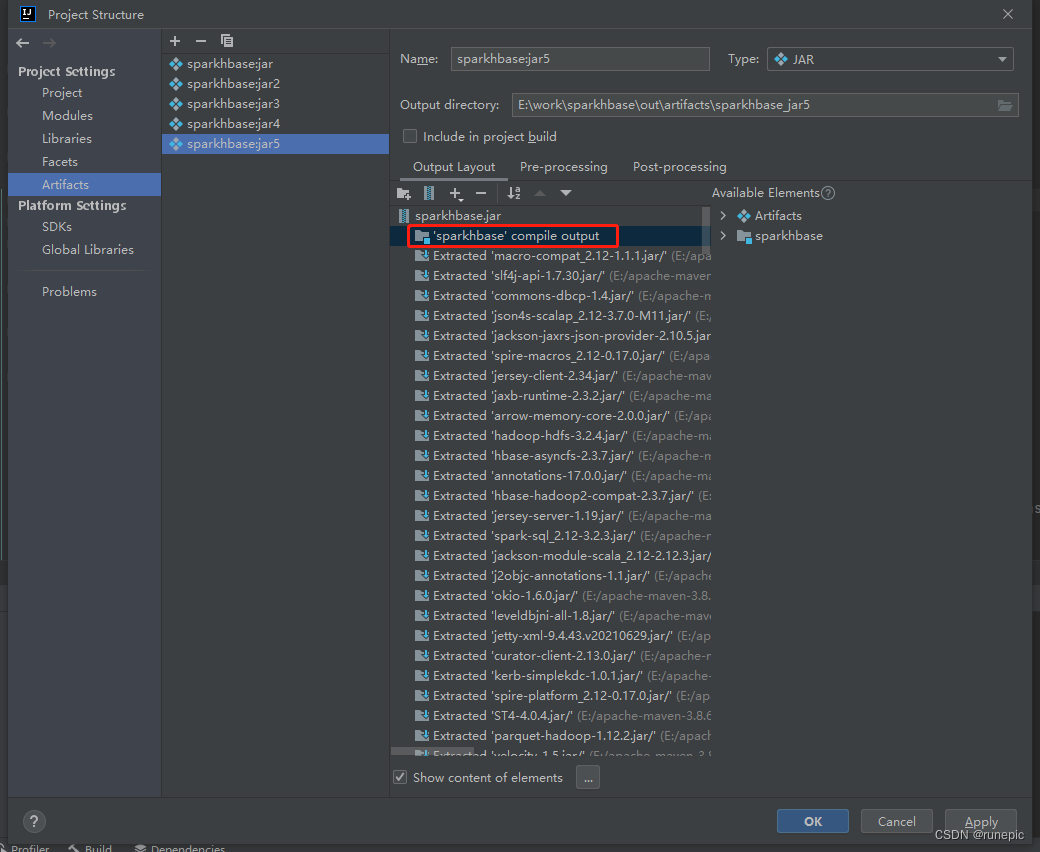
之后Build->Build artifacts->选中项目点击build即可
本文转载自: https://blog.csdn.net/weixin_40694662/article/details/131172915
版权归原作者 runepic 所有, 如有侵权,请联系我们删除。
版权归原作者 runepic 所有, 如有侵权,请联系我们删除。