
1.VGG背景
2. VGGNet模型结构
3. 特点(创新、优缺点及新知识点)
一、VGG背景

VGGNet是2014年ILSVRC(ImageNet Large Scale Visual Recognition Challenge大规模视觉识别挑战赛)竞赛的第二名,解决ImageNet中的1000类图像分类和定位问题,第一名是GoogLeNet。
VGG全称是Visual Geometry Group,因为是由Oxford的Visual Geometry Group提出的。AlexNet问世之后,很多学者通过改进AlexNet的网络结构来提高自己的准确率,主要有两个方向:小卷积核和多尺度。而VGG的作者们则选择了另外一个方向,即加深网络深度。主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。

他们以 7.32% 的错误率赢得了 2014 年 ILSVRC 分类任务的亚军(冠军由 GoogLeNet 以 6.65% 的错误率夺得)和 25.32% 的错误率夺得定位任务(Localization)的第一名(GoogLeNet 错误率为 26.44%)。VGG可以看成是加深版本的AlexNet. 都是conv layer + FC layer。
补充:
ImageNet Large Scale Visual Recognition Challenge 是李飞飞等人于2010年创办的图像识别挑战赛,自2010起连续举办8年,极大地推动计算机视觉发展。比赛项目涵盖:图像分类(Classification)、目标定位(Object localization)、目标检测(Object detection)、视频目标检测(Object detection from video)、场景分类(Scene classification)、场景解析(Scene parsing)。竞赛中脱颖而出大量经典模型: alexnet,vgg,googlenet,resnet,densenet等。
二、VGGNet模型结构
1.相关论文
论文全名:Very deep convolutional networks for large-scale image recognition
论文下载地址https://arxiv.org/pdf/1409.1556.pdf
VGG有两种结构,分别是VGG16和VGG19,两者并没有本质上的区别,只是网络深度不一样。在此过程中,作者做了六组实验,对应6个不同的网络模型,这六个网络深度逐渐递增的同时,也有各自的特点。实验表明最后两组,即深度最深的两组16和19层的VGGNet网络模型在分类和定位任务上的效果最好。
2.各组的区别:
A:起始。
A-LRN:加了LRN,这是AlexNet里提出来的。
B:加了两个卷积层。
C: 进一步叠加了3个卷积层,但是加的是1 * 1的kernel。
D:将C中1 * 1的卷积核替换成了3 * 3的,即VGG16。
E:在D的基础上进一步叠加了3个3*3卷积层,即VGG19。
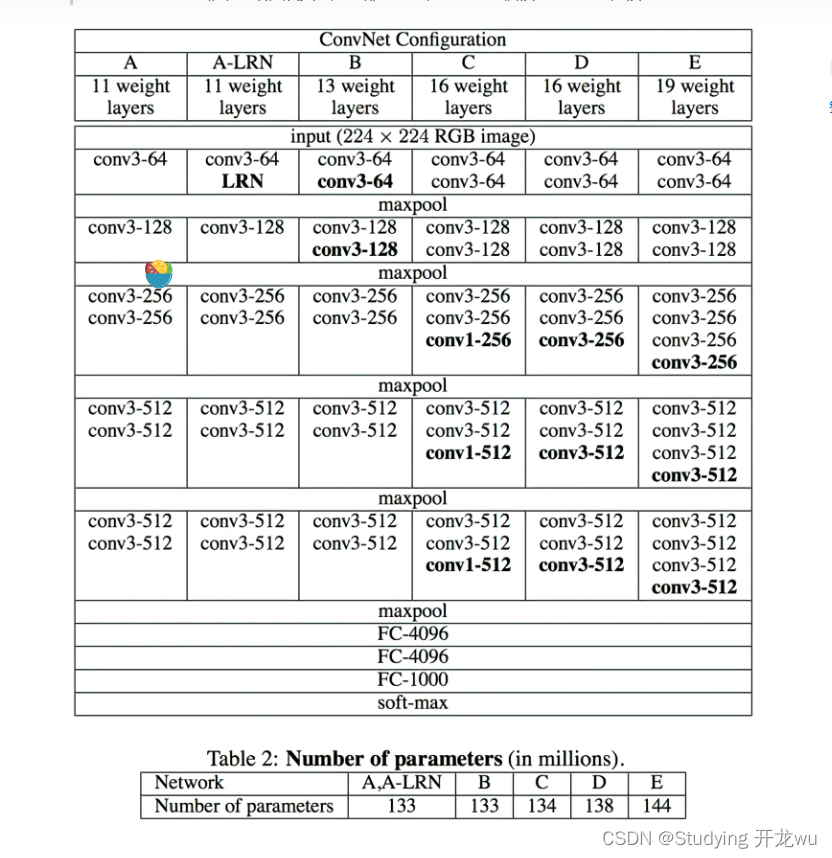
VGG16包含了16个隐藏层(13个卷积层和3个全连接层),如上图中的D列所示。
VGG19包含了19个隐藏层(16个卷积层和3个全连接层),如上图中的E列所示。
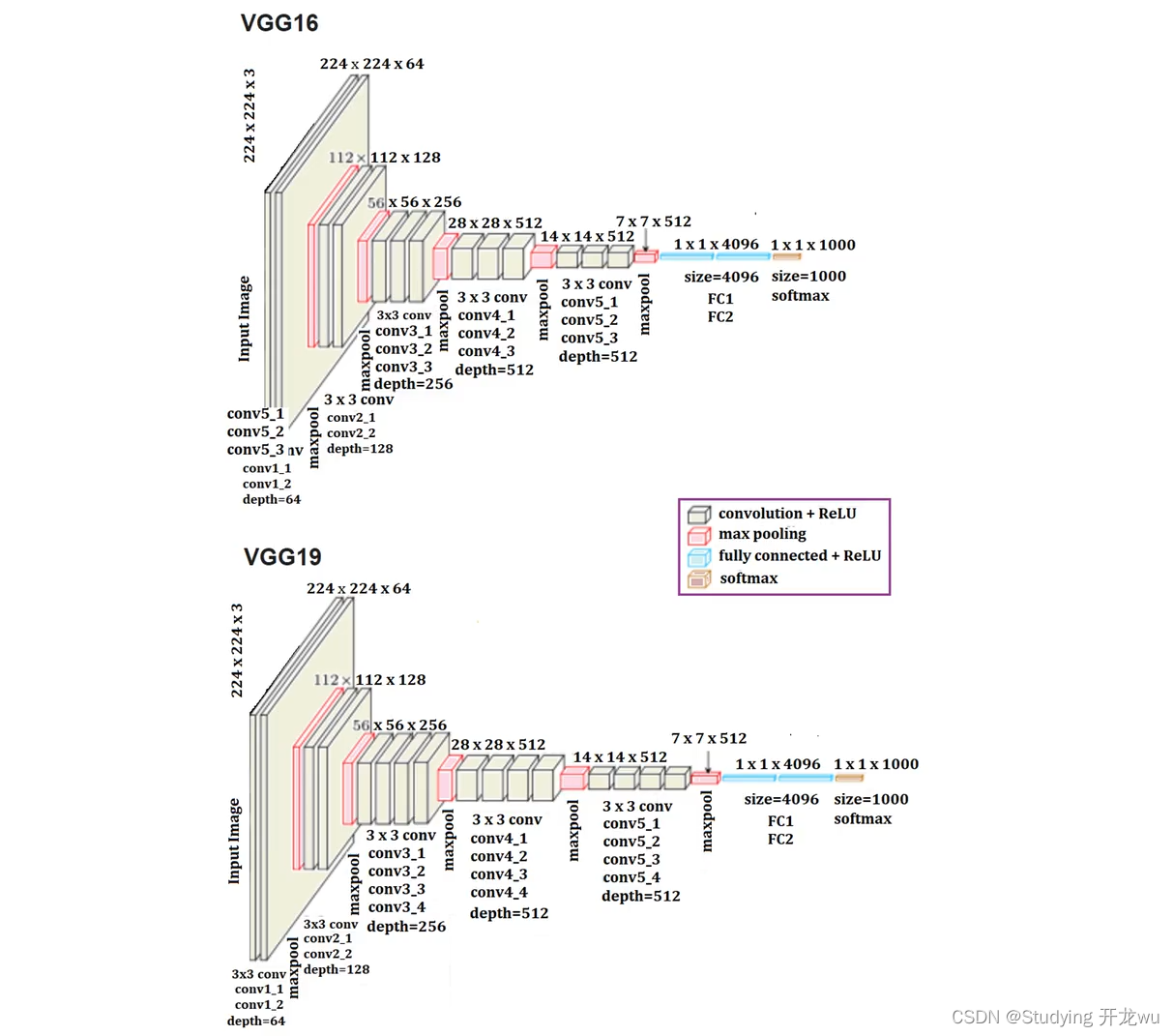

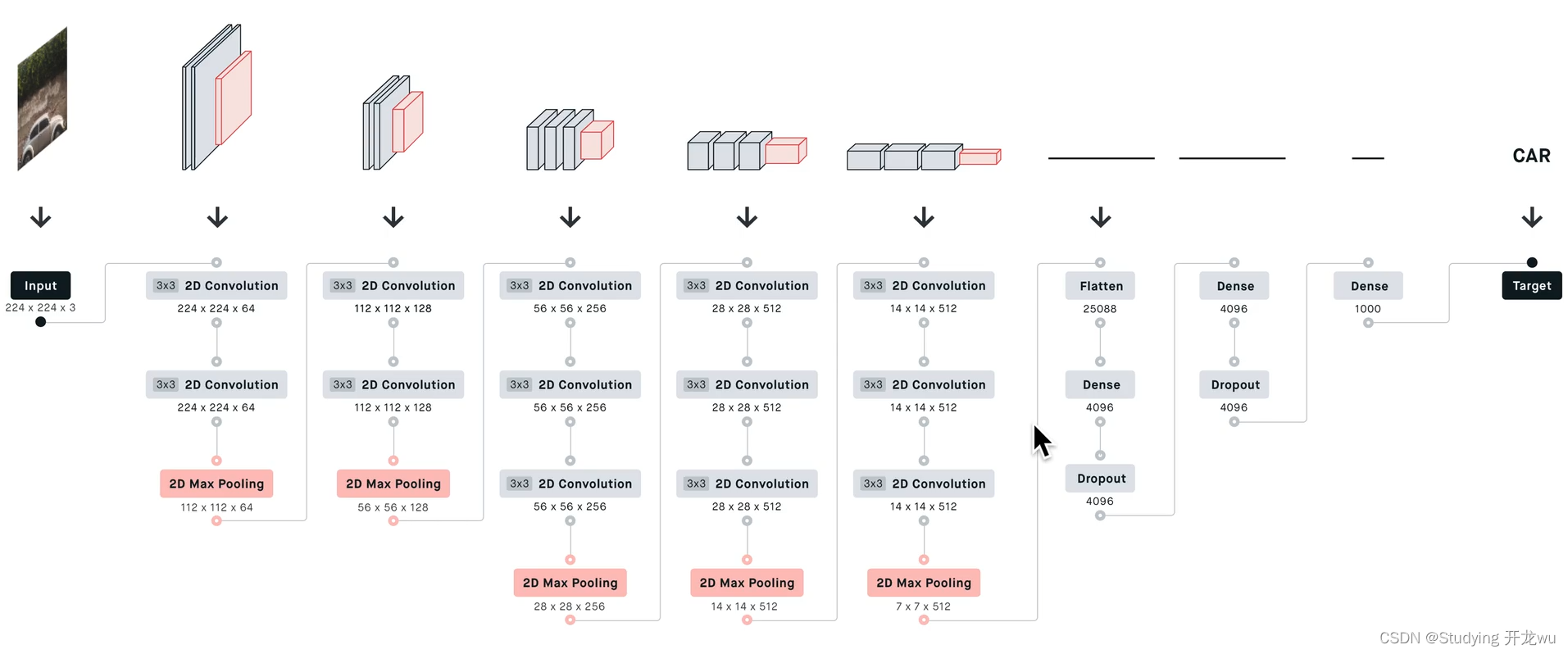
所有卷积层有相同的配置,即卷积核大小为3x3,步长为1,填充为1;共有5个最大池化层,大小都为2x2,步长为2;共有三个全连接层,前两层都有4096通道,第三层共1000路及代表1000个标签类别;最后一层为softmax层;所有隐藏层后都带有ReLU非线性激活函数;
三、特点(创新及新知识点)
作者就用验证集当做测试集来观察模型性能。这里作者使用两种方式来评估模型在测试集(实际的验证集)的性能表现。LRN层无性能增益(A和A-LRN)、深度增加,分类性能提高(A、B、C、D、E)、conv1x1的非线性变化有作用(C和D)、多小卷积核比单大卷积核性能好(B)。
对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
简单来说,在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
VGG16相比AlexNet的一个改进是,采用连续的几个3x3的卷积核(步长=1,padding=0),代替AlexNet中的较大卷积核(11x11,7x7,5x5)。
2、小池化核
相比AlexNet的3x3的池化核,VGG全部为2x2的池化核;
3、层数更深、特征图更宽
把网络层数加到了16、19层(不包括池化层和softmax层),而AlexNet是8层结构。基于前两点外,由于卷积核专注于扩大通道数、池化核专注于缩小宽和高,使得模型架构上更深更宽的同时,计算量的增加放缓。使网络有更大感受野的同时能降低网络参数,同时多次使用ReLu激活函数有更多的线性变换,学习能力更强。训练时将同一张图片缩放到不同的尺寸,在随机剪裁到224224的大小,能够增加数据量。预测时将同一张图片缩放到不同尺寸做预测,最后取平均值。网络测试阶段,全连接换成卷积。网络测试阶段,将训练阶段的3个全连接替换为3个卷积,测试重新用训练时的参数,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入。*数据增强:方法一:针对位置 训练阶段:按比例缩放图片至最小边为S,随机位置裁剪出224*224区域,随机进行水平翻转。方法二:针对颜色 修改RGB通道的像素值,实现颜色扰动,S设置方法:固定值:固定为256,或384,随机值:每个batch的S在[256, 512],实现尺度扰动。
4、VGG优点
VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。几个小滤波器(3x3)卷积层的组合比一个大滤波器(5x5或7x7)卷积层好:验证了通过不断加深网络结构可以提升性能。
5、VGG缺点
VGG耗费更多计算资源,并且使用了更多的参数(这里不是3x3卷积的锅),导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。VGG可是有3个全连接层啊!
版权归原作者 Studying 开龙wu 所有, 如有侵权,请联系我们删除。