
前言
大家好,我是辣条哥~
过往给大家更新了不少基础相关的,今天给大家上点硬货,基础不好的慎入,免得打击你们的积极性~
其次对数据分析|数据可视化|pandas感兴趣的可以来这里刷刷题: →→→《Pandas狂刷120题》←←←
工具准备
开发工具:pycharm
开发环境:python3.7, Windows10
使用工具包:requests
目录
采集目标地址
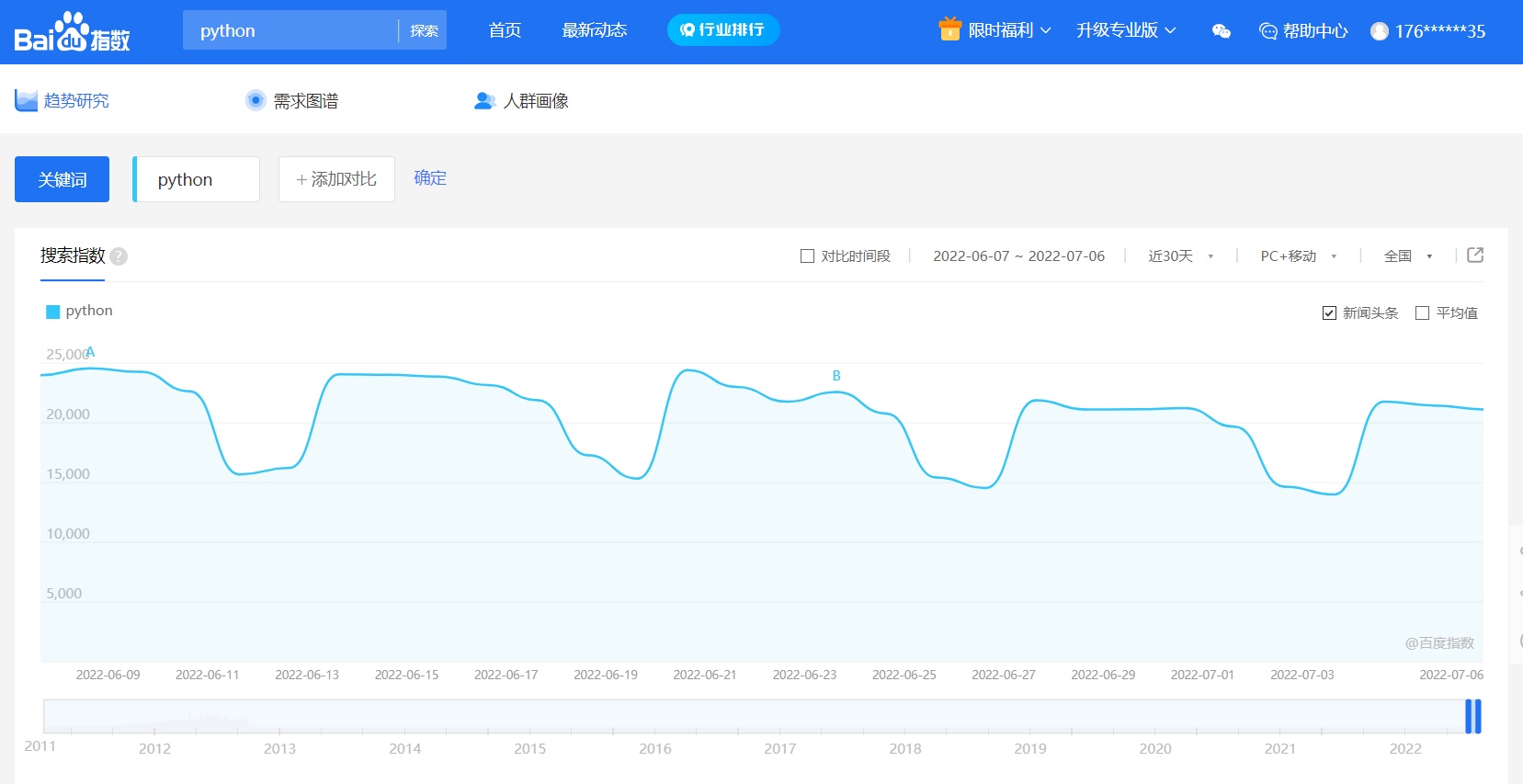
项目需求分析
需要通过代码来获取到当前网页上的曲线指数数据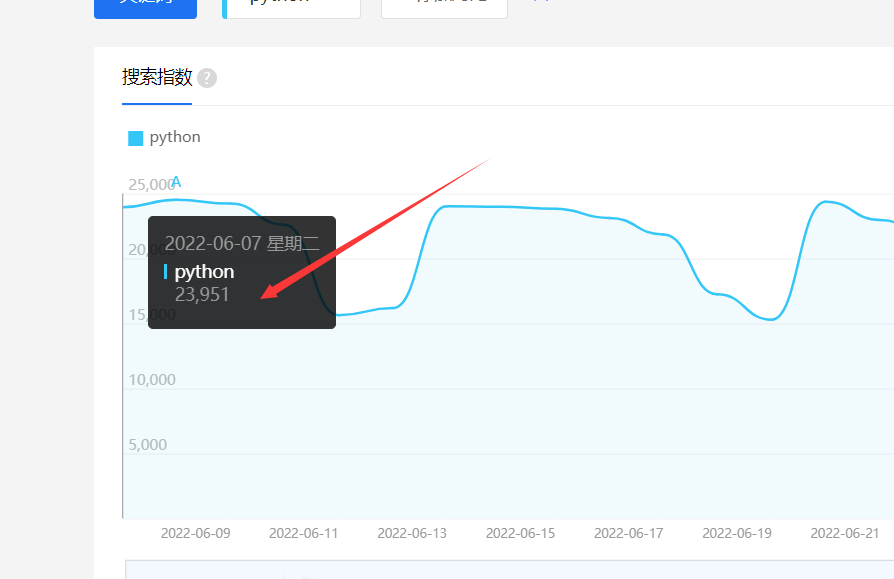
这是单独一个点,需要取出所以点的数据信息
项目思路解析
第一步 区分数据类型
我们获取的数据有静态和动态两种,首先区分是静态还是动态数据,在页面鼠标右击点击查看网页源代码,在源代码页面来进行搜索看看我们的数据是否是存在与静态页面上的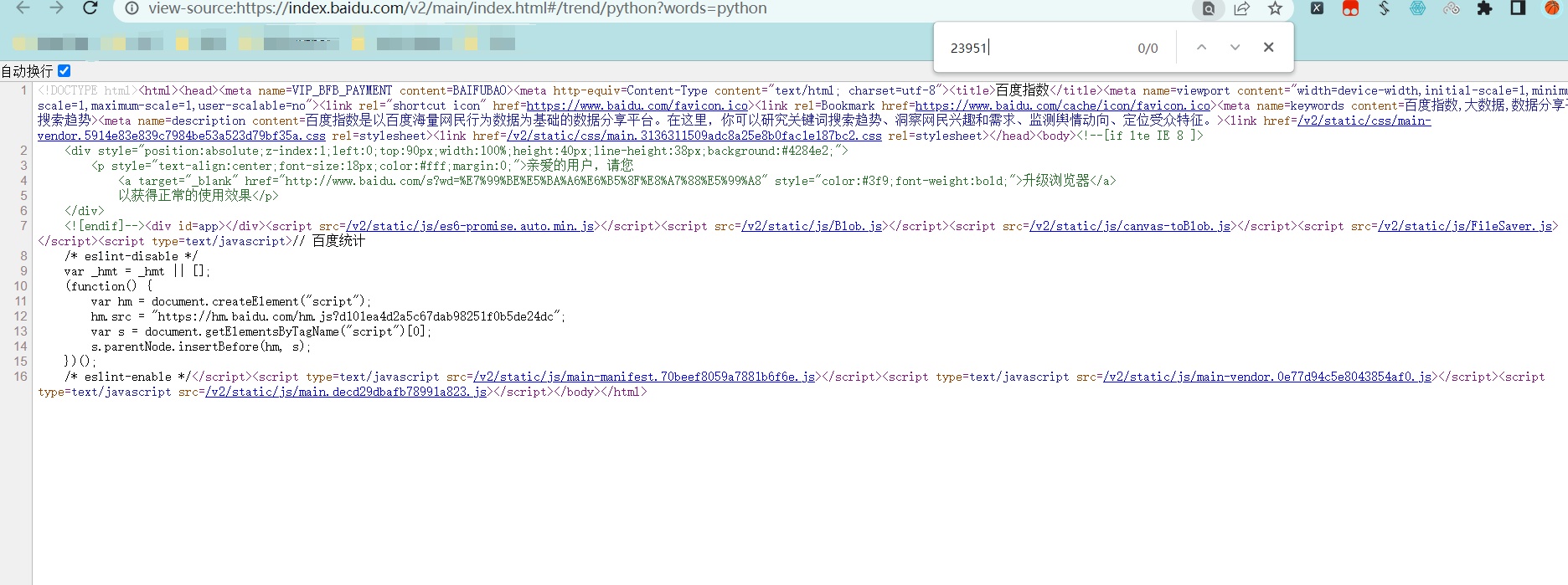
可以看到我们的数据并没有在页面上可以得出我们想要的数据为动态数据
第二步 抓包获取数据
动态数据的获取我们需要使用抓包的方式来进行获取,在浏览器页面鼠标右击点击检查,打开我们的抓包工具,点击network,选择xhr选项,xhr为筛选的动态数据,刷新页面,现在展示的就是动态数据
定位到我们想要的数据,要是不太熟练的可以一个个去进行确认看看那个数据是我们想要的,大致可以判断出我们想要的数据是在当前这个请求包里面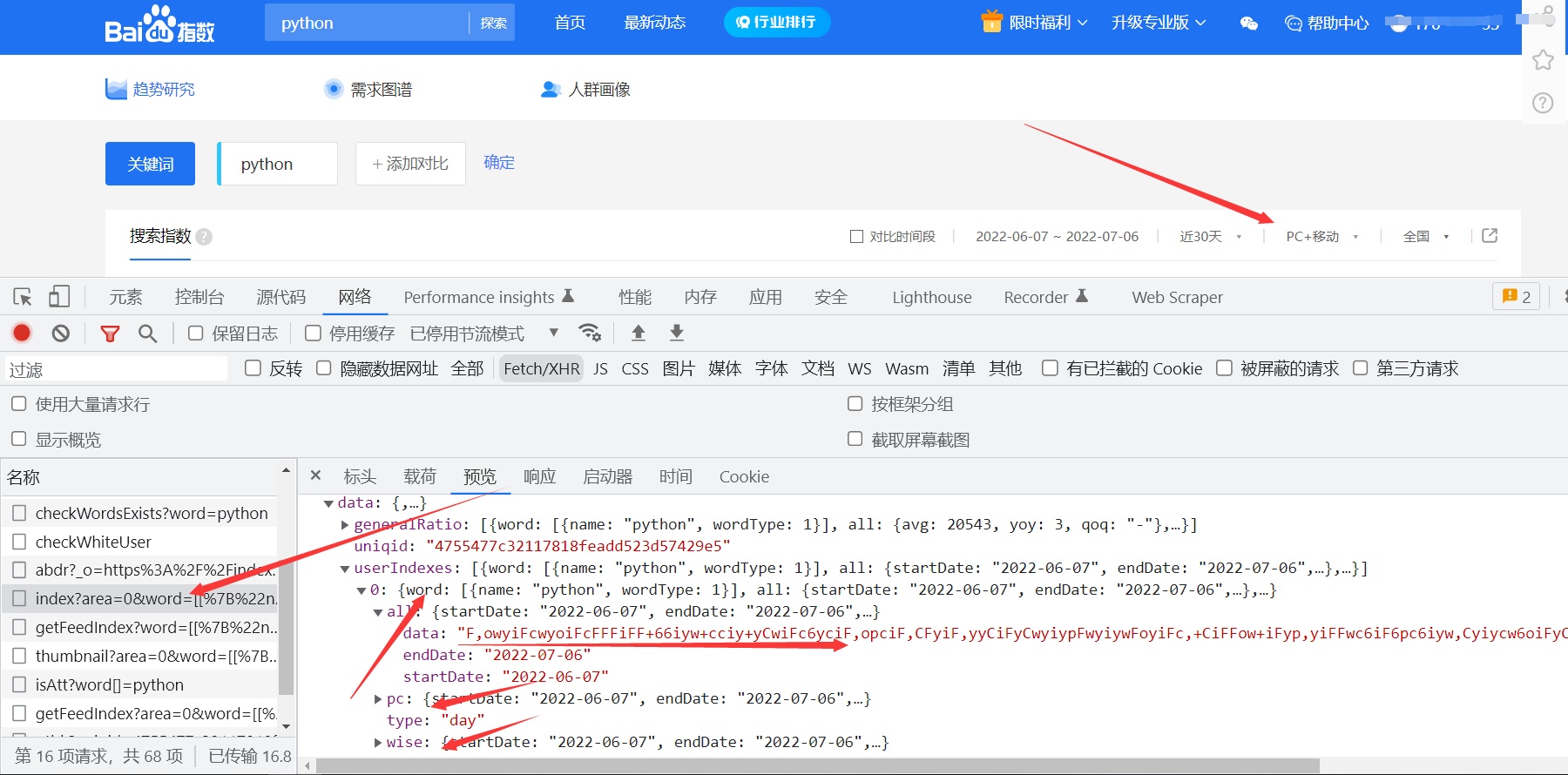
但是这个数据比较特殊,怎么看这个数据都不像是我们想获取的坐标点数据,可以由此得出,当前的数据为服务器加载过来的加密json数据,那我们需要考虑的就是如何去找到这个数据的解密位置,一个网页是有html、css、js所组成的,能用来处理数据的只能在js代码里面我们把找到js解密位置的过程就叫做js逆向
第三步 js代码逆向
通过全局来进行搜索定位到我们数据的位置,定位的方式有两种服务器传递的数据为json信息,我们可以直接通过JSON.parse来进行定位,js代码想处理js数据就需要通过这个关键字来转换,再有我们可以通过userIndexes来进行定位,因为前端在取数据的时候一定会根据userIndexes来进行定位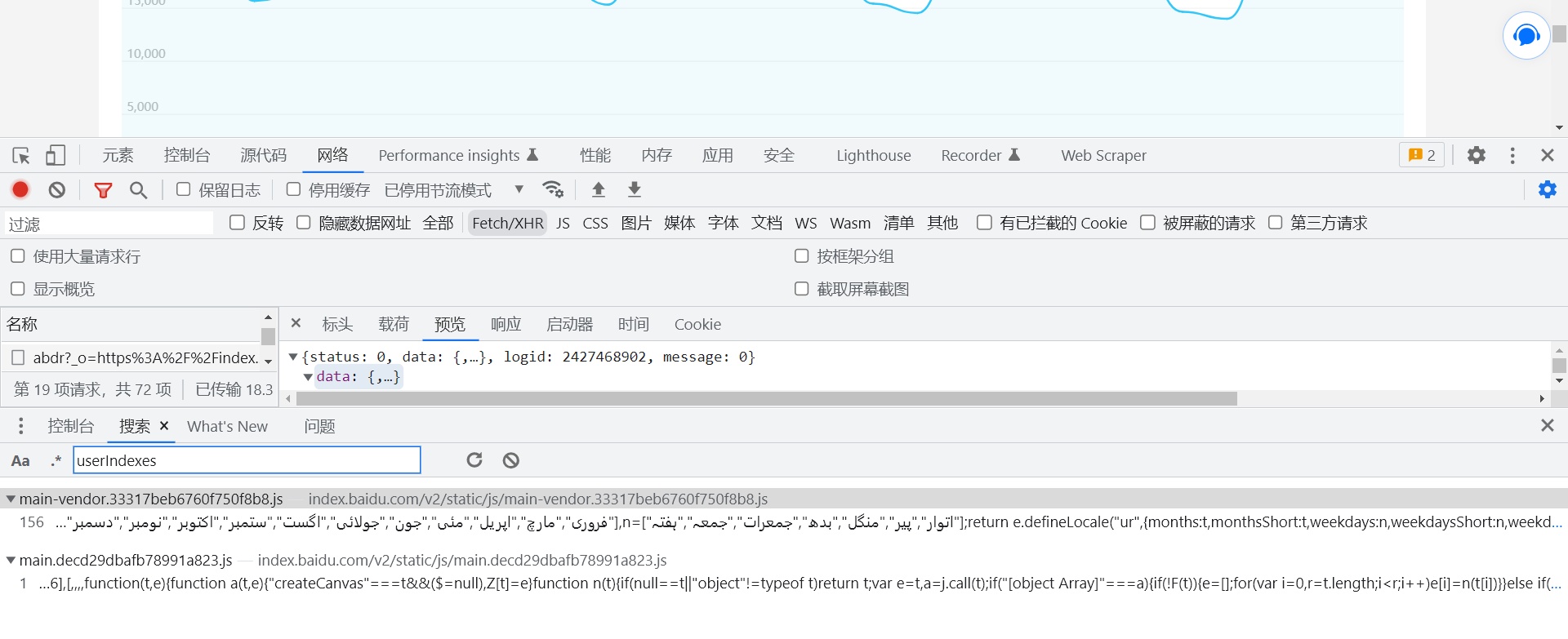
定位到的js文件有两个,感兴趣的可以一个个去进行访问,我们要的数据在第二个文件搜索到我们想要的数据,打上断点在进行解析,看看我们的数据是如何进行处理解密的,可以很直观的看到下方有个decrypt函数大致推断出是我们的解密函数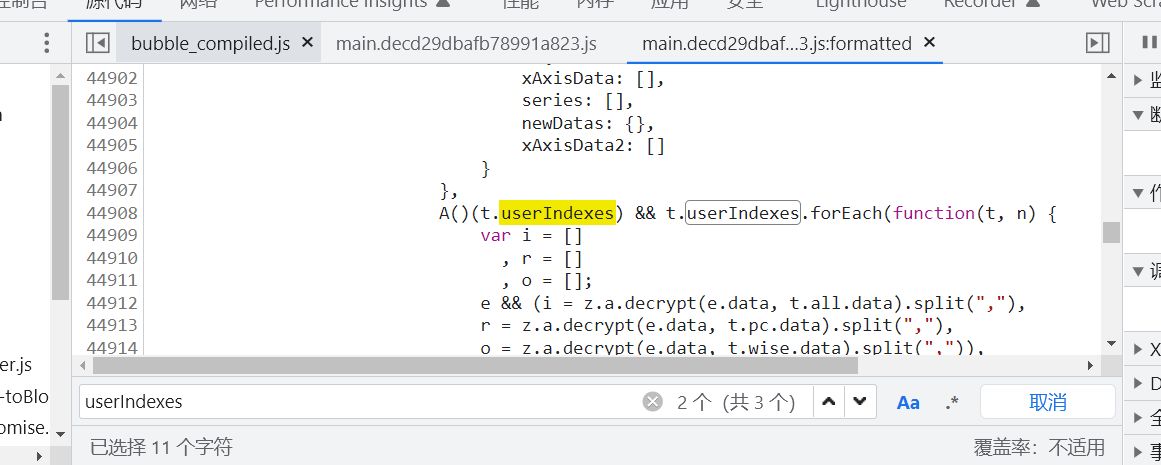
断点之后重新刷新页面,可以看到解密函数里面传递了两个参数,第二个参数是我们开始抓包得到服务器传递过来的加密数据,第一个参数目前还不是很明确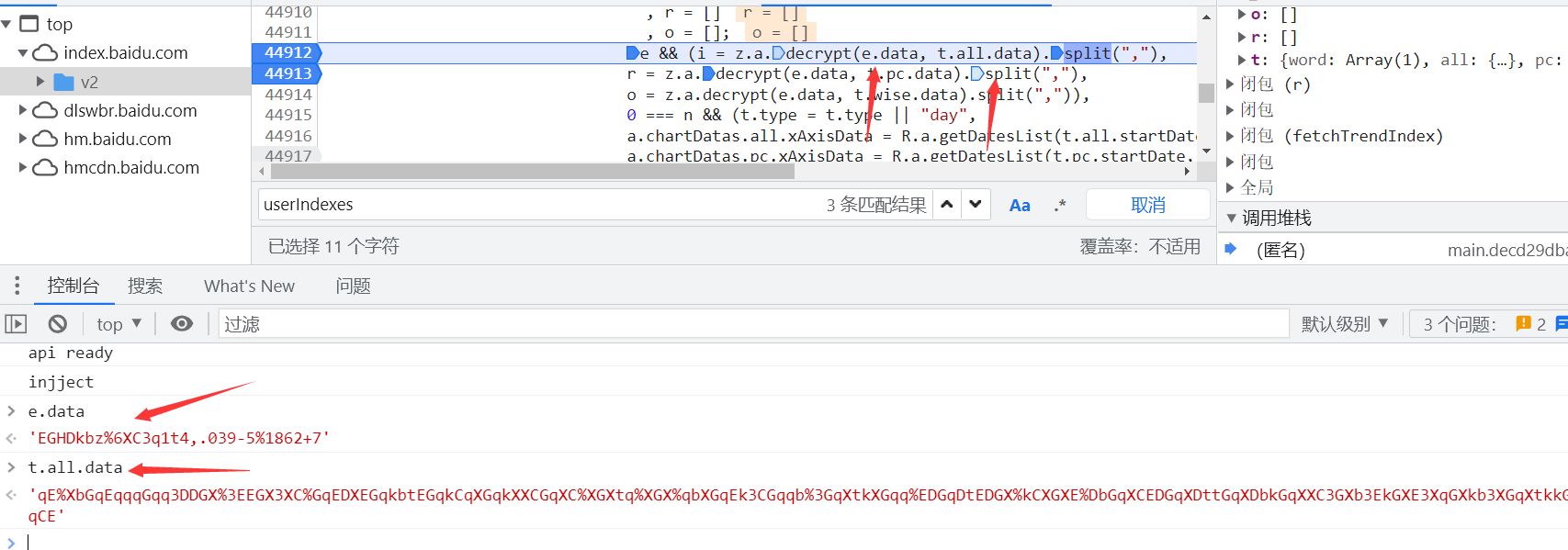
我们可以去搜索一下第一个传递的参数是什么内容,可以看到我们的数据是另外一个接口请求过来的,第一个参数还需要我们对这个接口再次发送请求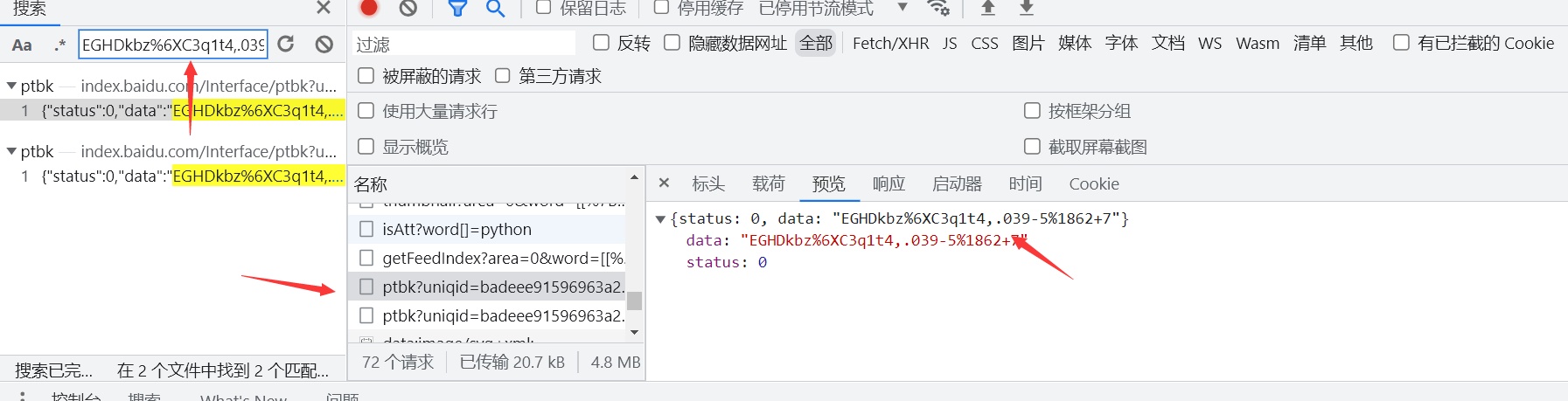
那我们的这个接口如何跟我们前面请求的数据发生关联呢,接口数据请求的网址是根据uniqid来进行获取的
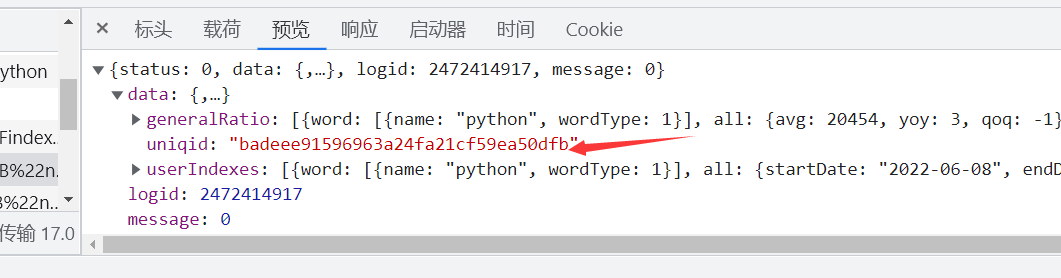
两个参数都明确了,那我们就开始对他的js代码来进行解析,
其实做的事情很简单,根据加密数据的索引来进行重新排列数据,根据索引值,得出最后的曲线上的坐标数据,现在我们需要做的就是把js代码转换成py代码
defdecrypt(t, e):
n =list(t)
i =list(e)
a ={}
result =[]
ln =int(len(n)/2)
start = n[ln:]
end = n[:ln]for j, k inzip(start, end):
a.update({k: j})for j in e:
result.append(a.get(j))return''.join(result)
简易代码分享
本篇文章只用于技术分享,切勿用作其他用途!!
import requests
import sys
import time
word_url ='http://index.baidu.com/api/SearchApi/thumbnail?area=0&word={}'
headers ={'Cipher-Text':'你的数据','Cookie':'你的cookie','Host':'index.baidu.com','Referer':'https://index.baidu.com/v2/main/index.html','User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36',# 'X-Requested-With': 'XMLHttpRequest',}defdecrypt(t, e):
n =list(t)
i =list(e)
a ={}
result =[]
ln =int(len(n)/2)
start = n[ln:]
end = n[:ln]for j, k inzip(start, end):
a.update({k: j})for j in e:
result.append(a.get(j))return''.join(result)defget_ptbk(uniqid):
url ='http://index.baidu.com/Interface/ptbk?uniqid={}'
resp = requests.get(url.format(uniqid), headers=headers)if resp.status_code !=200:print('获取uniqid失败')
sys.exit(1)return resp.json().get('data')defget_index_data(keyword, start='2011-02-10', end='2021-08-16'):
keyword =str(keyword).replace("'",'"')
url =f'https://index.baidu.com/api/SearchApi/index?area=0&word=[[%7B%22name%22:%22python%22,%22wordType%22:1%7D]]&days=30'
resp = requests.get(url, headers=headers)print(resp.json())
content = resp.json()
data = content.get('data')
user_indexes = data.get('userIndexes')[0]
uniqid = data.get('uniqid')
ptbk = get_ptbk(uniqid)
all_data = user_indexes.get('all').get('data')
result = decrypt(ptbk, all_data)
result = result.split(',')print(result)
版权归原作者 五包辣条! 所有, 如有侵权,请联系我们删除。