
一:hadoop简介
Hadoop指Apache这款开源框架,它的核心组件有:
- HDFS(分布式文件系统):解决海量数据存储
- MAPREDUCE(分布式运算编程框架):解决海量数据计算
- YARN(作业调度和集群资源管理的框架):解决资源任务调度
二:hadoop架构

目前主流的hadoop框架已经迭代更新到hadoop3.x的版本了,本篇的介绍也是围绕着hadoop3.x展开的
接下来我们根据以下的结构图来了解hadoop框架中各个组成部分的作用:
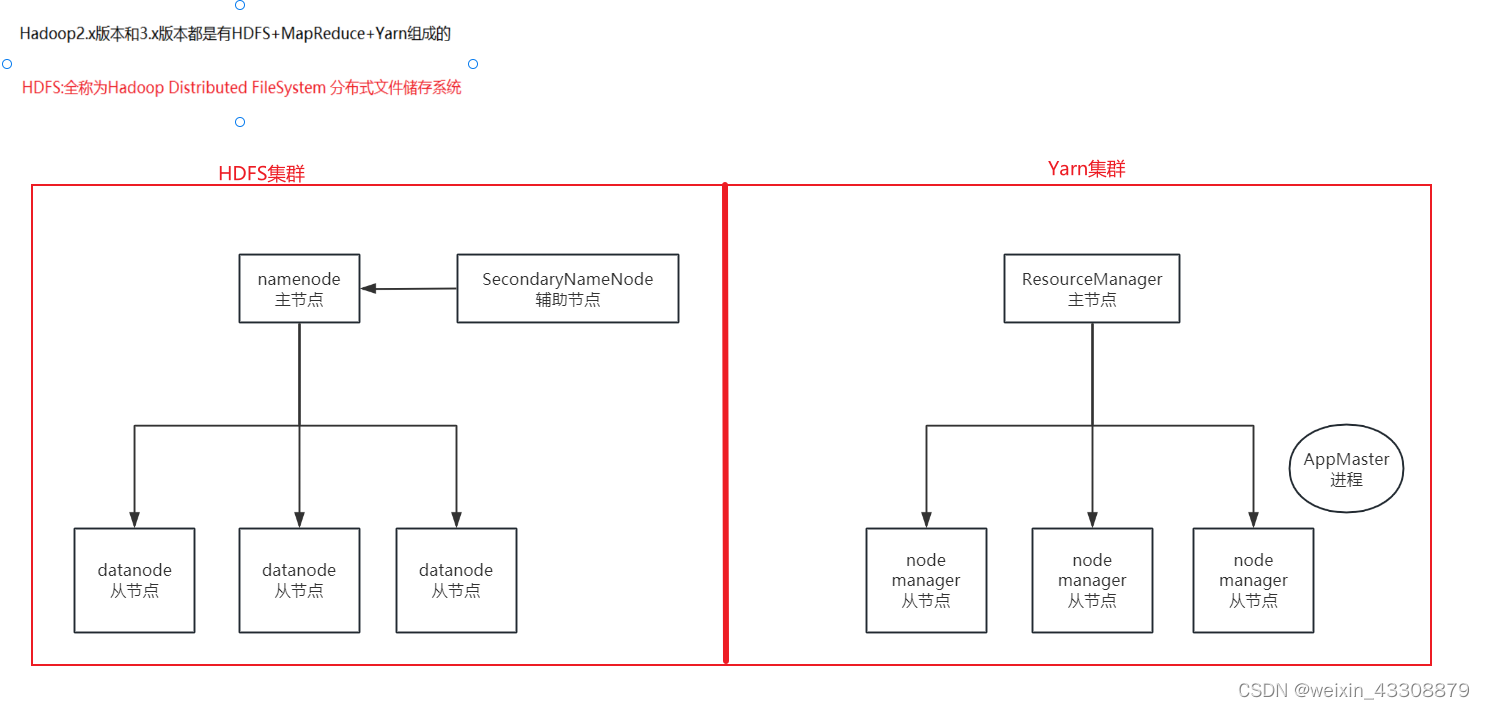
HDFS集群
namenode:主节点
- 管理整个HDFS集群
- 维护和管理元数据
SecondaryNameNode:辅助节点
- 辅助namenode管理元数据
datanode:从节点
- 维护和管理元数据
- 负责数据的读写操作
- 定时向namenode报活
yarn集群
ResourceManager:主节点
- 负责任务的接受
- 负责资源的调度和分配
AppMaster进程:输入代码级别
- 1个计算任务 = 1个Application Master进程
- 由该AppMaster进程来监控和管理该计算任务,并负责向ResourceManager申请资源
nodemanager:从节点
- 负责接收并执行ResourceManager分配过来的计算任务
注意:此时已经没有MapReduce集群的概念了。而是代码级别的程序,即:MR计算任务
我们只需要用代码编写MR计算任务,然后又交由Yarn调度执行即可
三:Hadoop集群搭建
搭建方式:
方式1: Standalone mode 单机模式
把所有的服务(namenode, SecondaryNameNode, datanode, ResourceManager, nodemanager)装到1台机器方式2: Cluster mode 集群模式
这里我们创建3台虚拟机: node1(192.168.88.161),node2(192.168.88.162),node3(192.168.88.163) 具体部署节点如下: node1: namenode, datanode, ResourceManager, nodemanager node2: SecondaryNameNode, datanode, nodemanager node3: datanode nodemanager
启动方式:
- 在node1中执行 start-all.sh 命令, 即可启动Hadoop集群.
- 然后在node1中单独运行 mapred --daemon start historyserver 启动历史服务.
- 然后在三台虚拟机中分别输入 jps 查看服务, 因为我们的主节点都布置在node1中,辅助节点布置在node2中,从节点在node1,node2,node3中都有部署,具体如下:
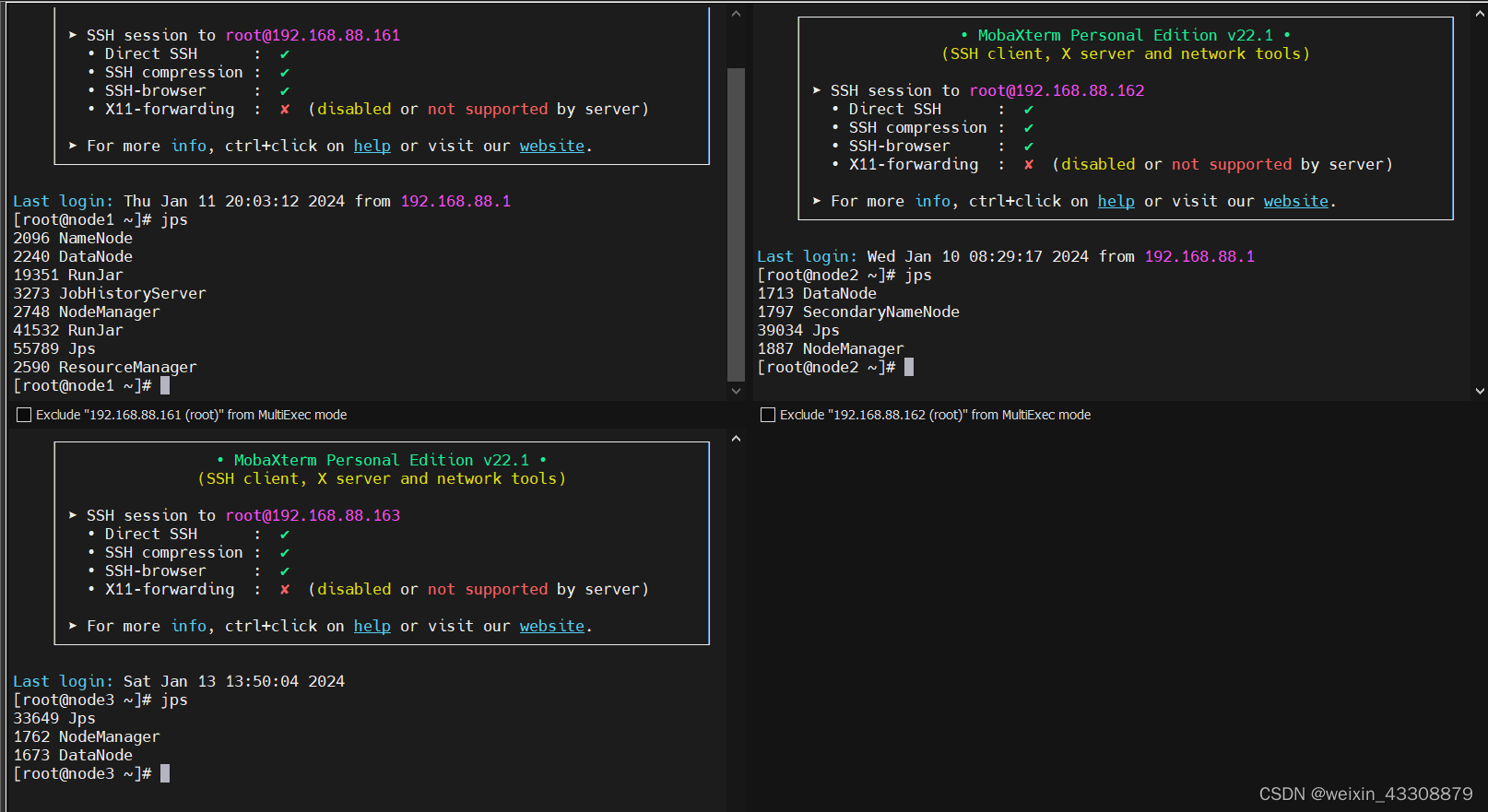
查看WebUI界面:
当我们启动好hadoop集群之后,我们便可以在浏览器中用如下端口号进行访问
- HDFS的WebUI界面: 192.168.88.161:9870 注意: 如果是Hadoop2.X, 端口号是: 50070
- Yarn的WebUI界面: 192.168.88.161:8088, 只记录本次启动Hadoop集群至关闭, 所有的计算任务.
- 历史服务的WebUI界面: 192.168.88.161:19888, 记录Hadoop从搭建好至现在, 所有的计算任务.
域名映射配置:
如果想在浏览器中直接通过 域名的方式直接访问上述的WebUI界面, 则需要配置下: 域名映射.
具体操作如下:
首先我们需要配置Linux系统中的域名映射:
# 进入到该文件中
vim /etc/hosts
# 在上述文件的最后追加如下的内容
192.168.88.161 node1 node1.itcast.cn
192.168.88.162 node2 node2.itcast.cn
192.168.88.163 node3 node3.itcast.cn
# 保存退出, 然后重启Linux系统即可.
然后我们还需要在windows系统 配置域名映射:
在 C:\Windows\System32\drivers\etc\hosts 文件中, 追加如下的内容:
# HiveCluster
192.168.88.161 node1.itcast.cn node1
192.168.88.162 node2.itcast.cn node2
192.168.88.163 node3.itcast.cn node3
# 保存, 关闭hosts文件, 然后重启windows系统即可,注意部分电脑不需要重启也可以生效.
以上操作都配置完成后,我们便可以将上面的域名修改为:
- HDFS的WebUI界面: node1:9870
- Yarn的WebUI界面: node1:8088
- 历史服务的WebUI界面: node1:19888
测试Hadoop中的MapReduce任务:
# 进入到测试包中
cd /export/server/hadoop/share/hadoop/mapreduce
# 执行MR任务:
# 这里我们执行的是圆周率的计算
yarn jar hadoop-mapreduce-examples-3.3.0.jar pi 2 50
# 上述格式解释:
yarn jar 固定格式, 说明要把某个jar包交给yarn调度执行.
hadoop-mapreduce-examples-3.3.0.jar Hadoop提供的MR任务的测试包
pi 要执行的任务名
2 表示MapTask的任务数, 即: 几个线程来做这个事儿.
50 投点数, 越大, 计算结果越精准.
四:HDFS详解
通过以上的介绍,我们已大致了解了hadoop集群框架,现在让我们深入的了解一下构成hadoop框架之一的HDFS集群
HDFS的特点:
- HDFS文件系统可存储超大文件,时效性稍差。
- HDFS具有硬件故障检测和自动快速恢复功能。
- HDFS为数据存储提供很强的扩展能力。
- HDFS存储一般为一次写入,多次读取,只支持追加写入,不支持随机修改。
- HDFS可在普通廉价的机器上运行。
HDFS的架构图:

心跳机制:
- datanode会定时(3秒)向namenode发送心跳包,告诉namenode,自己还活着。
- 如果超过一定时间(630秒),namenode没收到datanode的心跳包,就认为他宕机了。
- 所有的datanode会定时(6小时),向namenode汇报一次自己完整的块信息,让namenode校验更新
负载均衡:
- namenode会保证所有的datanode的资源使用率,使其尽量保持一致
副本机制:
- 可以提高容错率,默认的副本数是:3
- 如果当前副本总数 > 默认副本数,则namenode会自动删除某个副本
- 如果当前副本总数 < 默认副本数,则namenode会自动增加该副本
- 如果当前活跃的机器总数 < 默认副本数,例如:默认3个副本,但现在只有2台机器活跃了,就会强制进入安全模式(safemode),在安全模式下:只能进行读操作不能进行写操作。
HDFS的Shell命令:
# HDFS的Shell命令, 类似于Linux的Shell命令, 格式稍有不同, 具体如下:
hadoop fs -选项 参数 # 既能操作HDFS文件系统, 还能操作本地文件系统.
hdfs dfs -选项 参数 # 只能操作HDFS文件系统.
# 细节: 操作HDFS路径的时候, 建议加上前缀 hdfs://node1:8020/
# -ls命令, 查看指定的HDFS路径下所有的内容.
hadoop fs -ls / # 查看根目录下所有内容(不包括子级)
hadoop fs -ls -R / # 查看根目录下所有内容(包括子级)
# mkdir命令, 创建目录
hdfs dfs -mkdir /aa # 创建单级.
hdfs dfs -mkdir -p /aa/bb/cc/dd # 创建多级目录.
# cat命令, 查看文件内容.
hadoop fs -cat /input/word.txt
# mv命令, 剪切. 只能是 HDFS路径 => HDFS路径
hadoop fs -mv /input/word.txt /aa
# cp命令, 拷贝. 只能是 HDFS路径 => HDFS路径
hadoop fs -cp /input/word.txt /aa
# rm命令, 删除.
hadoop fs -rm /aa/bb/word.txt
hadoop fs -rm -r /aa # 递归删除aa文件夹
# put命令, 把Linux系统的文件 上传到 HDFS文件系统中.
hadoop fs -put 1.txt /input # 1.txt是Linux的文件路径, /input是HDFS的目录路径
# get命令, 把HDFS文件系统的某个文件 下载到 Linux系统的文件中.
hadoop fs -get /input/1.txt ./ # 1.txt是HDFS的文件路径, ./Linux的路径.
五:总结
以上内容便是对Hadoop集群架构以及HDFS集群的大致介绍,关于组成Hadoop集群框架的另外两个部分,我们下篇文章再来详细介绍,以上便是我学习大数据过程中的一些总结,谢谢各位的观看和指导。
本文转载自: https://blog.csdn.net/weixin_43308879/article/details/135466574
版权归原作者 weixin_43308879 所有, 如有侵权,请联系我们删除。
版权归原作者 weixin_43308879 所有, 如有侵权,请联系我们删除。