
说明:本篇文章基于selenium 4.1.0
定位全部文本
很多时候,我们在进行web自动化测试,进行元素定位时,如果元素有文本属性,那直接使用text属性就可以直接使用元素的text属性来进行定位,例如我们要定位百度首页的新闻元素并进行点击。

具体定位代码为:
driver.find_element(By.XPATH, "//*[text()='新闻']")
定位部分文本
但是有时候,文本前后可能存在空格或者有其他符号,这样我们使用全部文本匹配必定会出现无法找到元素出现报错的问题,所以,我们就需要通过部分文本来完成定位。比如,我们在百度搜索结果页想要点击下一页,这个元素在文本之外还有其他符号存在,那我们应该怎么来定位这个元素呢?
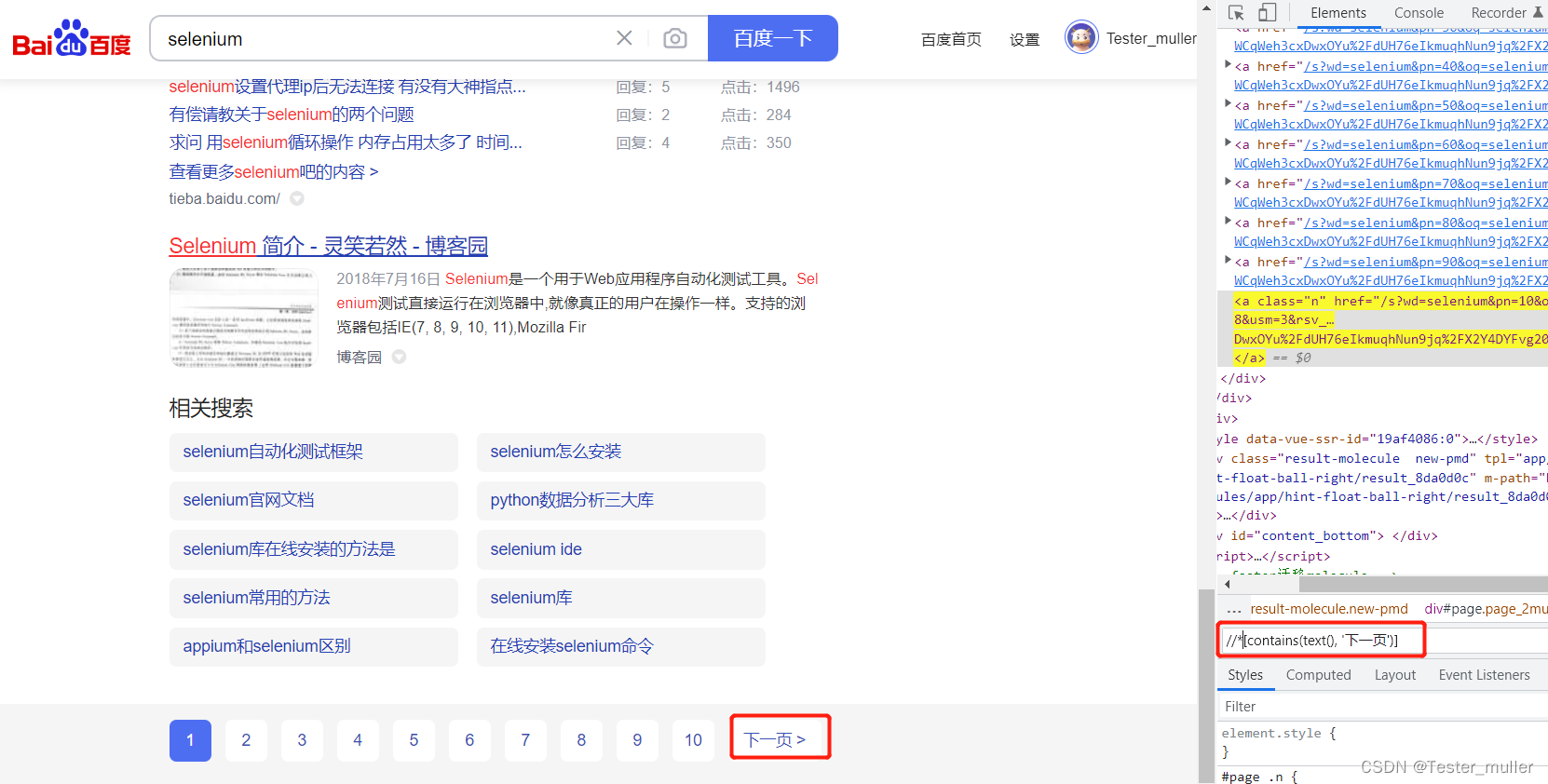
driver.find_element(By.XPATH, "//*[contains(text(), '下一页')]")
这样就可以完成对下一页元素的定位了。
更多技术文章
本文转载自: https://blog.csdn.net/Tester_muller/article/details/127279363
版权归原作者 软件测试大空翼 所有, 如有侵权,请联系我们删除。
版权归原作者 软件测试大空翼 所有, 如有侵权,请联系我们删除。