
一、目标
通过本实验的练习,应达到如下目标:
- 了解Hadoop的三种安装模式
- 掌握Hadoop的安装配置方法
- 熟悉基本的Hadoop命令
- 理解Hadoop:示例程序WordCount的运行方法
二、Hadoop的三种安装模式
- 单机模式standalone mode- 单机模式是Hadoop的默认模式- 在这种默认模式下配置文件是没有信息的,Hadoop完全运行在本地- 该模式主要用于开发调试
MapReduce程序的应用逻辑 - 伪分布式模式pseudo distributed mode- Hadoop通过不同的java进程模拟多个进程,实现模拟的分布式配置- (each Hadoop daemon runs in a separate Java process.)- 伪分布式模式适合初学者用于学习Hadoop的原理和基本使用方法
- 分布式(集群)模式distributed mode- Hadoop安装在多个(3+)个节点的集群之上- 分布式模式是Hadoop在实际生产应用中采用的模式
⭐本实验采用【伪分布式】安装模式
三、实验环境与安装文件

操作系统在这里选用的是ubuntu22及以上
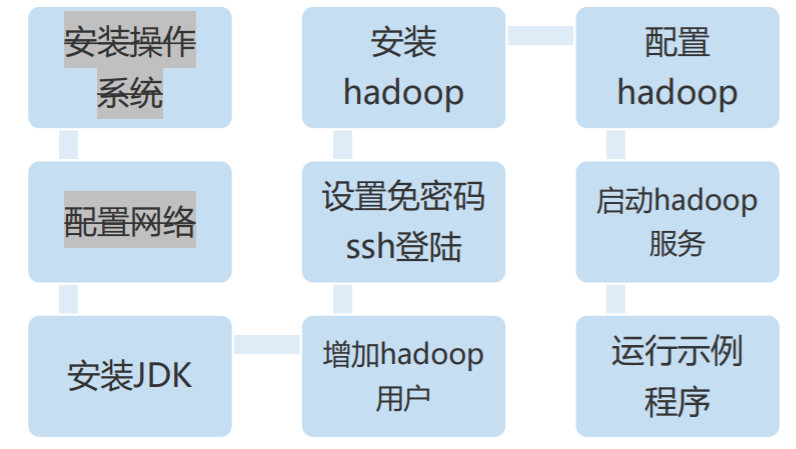
四、实验流程
4.1:安装操作系统
4.1.0:安装虚拟机
由于我采用的是在windows环境中安装虚拟机来安装linux系统,所以我要先下载和安装VM虚拟机:
参考教程:vmware-17虚拟机安装教程及版本密钥(保姆级,包含图文讲解,不需注册账户)
4.1.1:安装CentOS操作系统or ubuntu
参考教程:inux入门三:安装CentOS 7(桌面版);
⭐【Tools】Ubuntu22.04安装详细教程
4.1.2:配置操作系统网络
虚拟机网卡默认有三种配置模式:桥接模式、NAT模式、仅主机模式,在本实验中,我们配置的是 **
NAT
模式。**
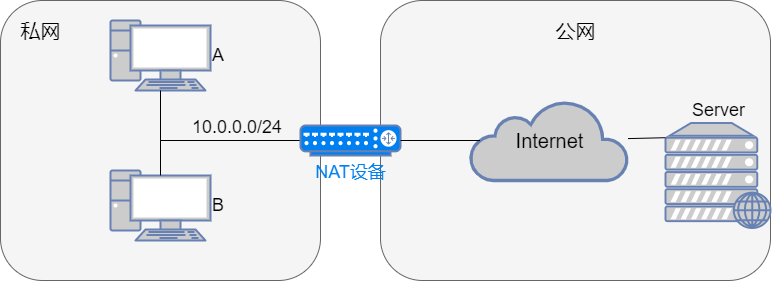
NAT(Network Address Translator,网络地址转换)是用于在本地网络中使用私有地址,在连接互联网时转而使用全局 IP 地址的技术。NAT实际上是为解决IPv4地址短缺而开发的技术。
可在安装Ubuntu的过程中选择: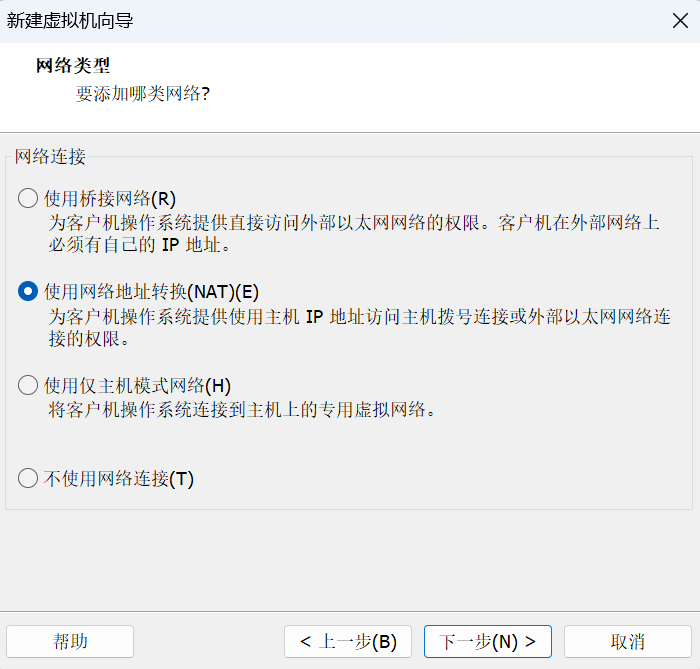
- 桥接模式 需要依赖外部网络环境,VMware 虚拟出来的操作系统就像是局域网中的一台独立的主机,需要手工为虚拟系统配置IP地址,虚拟机的ip必须和宿主机(windows)的ip是同一个网段。开发环境下可能会使用, 学习环境不用, 类似于虚拟机和主机就好比插在同一台交换机上的两台电脑
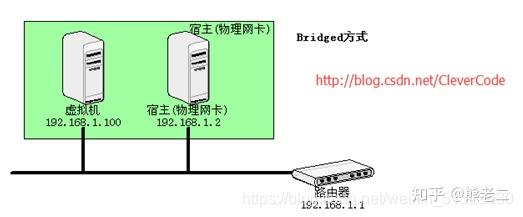
- NAT模式 使用 NAT 模式,就是让虚拟系统借助 NAT(网络地址转换) 功能,通过宿主机器所在的网络来访问公网,如果主机能够正常上网,那么虚拟机也能够直接上网。此时虚拟机处于一个新的网段内,由VMware提供的DHCP服务自动分配IP地址,然后通过VMware提供的NAT服务,共享主机实现上网, 不依赖外部网络环境
- 仅主机模式 仅主机模式和NAT模式是类似的,在该模式下,虚拟网络是一个全封闭的网络,它唯一能够访问的就是主机,当然多个虚拟机之间也可以互相访问, 只需要记住仅主机模式是无法进行上网的
4.2:创建Hadoop用户并登录
如果你在安装ubuntu操作系统时起的用户名就是
hadoop那么这小节也可以省略
🌸我目前的情况
- 在安装时已经创建了一个用户名为
yaoyao的用户
🌸我现在需要做的
- 添加
hadoop用户,并赋予管理员权限
🌱原因:拥有更纯净的部署Hadoop的环境
👉🏻1.按 Ctrl + Alt + T,即可进入命令行模式。
👉🏻2.输入以下语句,创建一个名为hadoop的用户,
useradd
命令的
-m
用来指定用户名,
-s
用来指定用户登录时所需的shell文件:
sudouseradd-m hadoop -s /bin/bash
👉🏻3.由于部门权限规定或安全限制,负责部署hadoop的管理员没有linux root权限,但按照最佳做法,安装时有一些操作需要以root用户身份执行。以下给予该用户root权限:
sudo adduser hadoop sudo
并设置密码
sudopasswd hadoop
👉🏻4.点击ubuntu主页的电源按钮,选择
Logout(注销)
,即退出当前用户。退出当前用户(
yaoyao
),登录刚刚创建的
hadoop
用户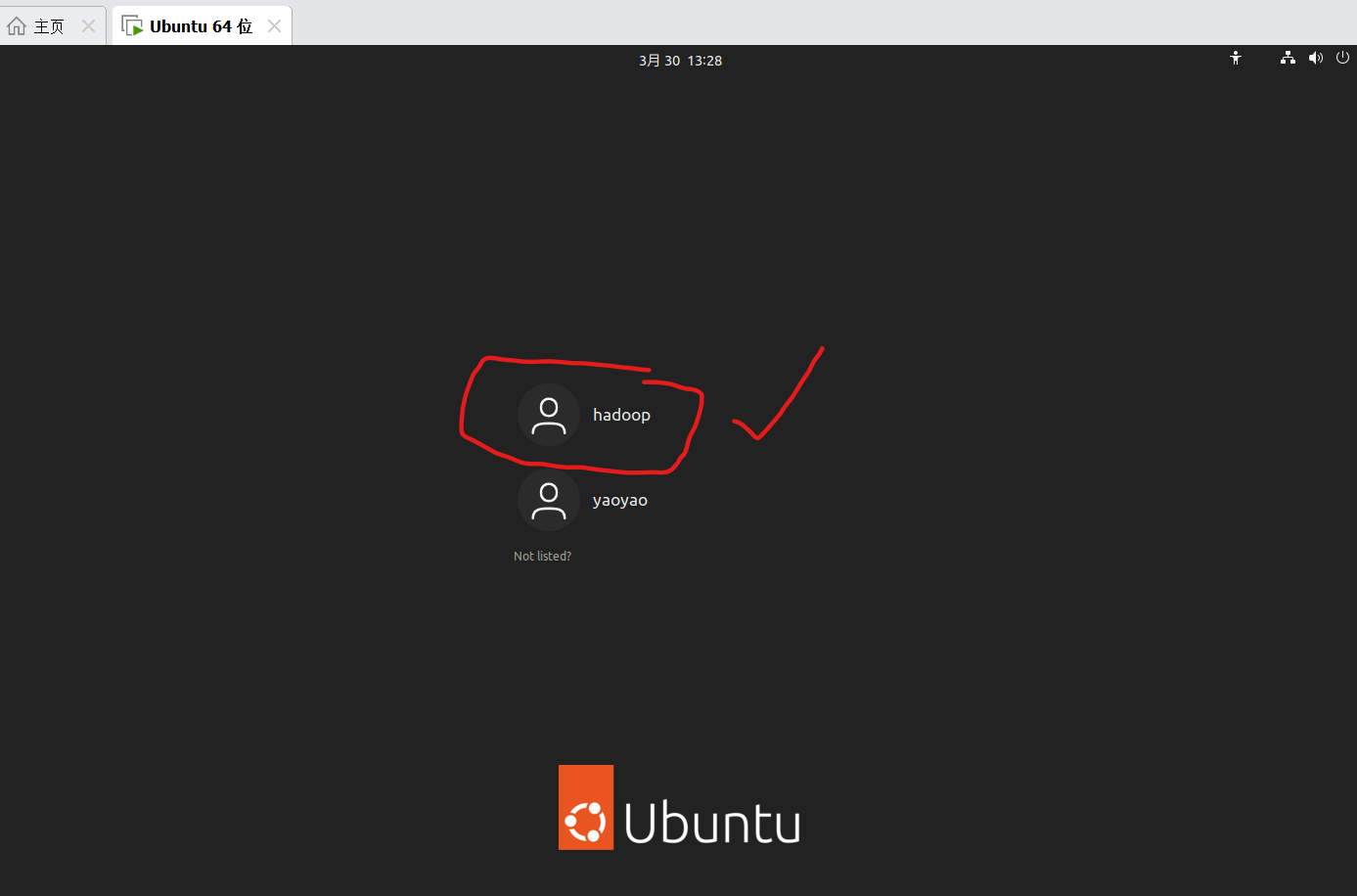
👉🏻5.此时以
hadoop
用户的身份登入系统,.由于ubuntu系统刚完成安装,需要更新相关一些软件,确保接下来的操作可以正常完成:
sudoapt-get update
👉🏻6.安装
vim
编辑器,方便后续编辑一些配置文件:
sudoapt-getinstallvim
4.3: 配置SSH,并设置无密码登录
根据Hadoop分布式系统的特性,在任务计划分发、心跳监测、任务管理、多租户管理等功能上,需要通过
SSH(Secure Shell)进行通讯
,所以必须安装配置SSH。另因为Hadoop没有提供SSH输入密码登录的形式,因此需要将所有机器配置为NameNode可以无密码登录的状态。
4.3.1:下载SSH
🐣1.首先安装SSH server(之所以不需要安装SSH client是因为ubuntu已经默认安装了):
sudoapt-getinstall openssh-server
🐣2.完成后连接本地SSH
ssh localhost
按提示输入yes,再输入hadoop用户的密码,完成登录。
4.3.2:设置无密码登录
🍊1.以下进行无密码登录的设置,首先先退出刚刚ssh localhost的连接:
exit
🍊2.然后进入SSH对应目录下,该目录包含了几乎所有当前用户SSH配置认证相关的文件:
cd ~/.ssh/
🍊3.输入生成SSH私钥与公钥的命令,-t用于声明密钥的加密类型,输入Hadoop密码。这一步会提醒设置SSH密码,输入密码时直接回车就表示无密码,第二次输入密码回车确定,最后一次提交:
ssh-keygen -t rsa
🍊4.将生成的SSH的公钥加入目标机器的SSH目录下,这里采用cat命令与>>,cat file1>>file2的含义为将file1内容append到file2中。
cat ./id_rsa.pub >> ./authorized_keys
4.4:安装Java并配置环境变量
Hadoop和与之相关的很多工具都是通过java语言编写的,并且很多基于hadoop的应用开发也是使用java语言的,但是ubuntu系统不会默认安装java环境,所以需要安装java并配置环境变量。以下安装下载java的jdk、jre:
4.4.1:Java的下载
这里我们直接在
ubuntu
系统中采用命令行的形式来下载Java
sudoapt-getinstall default-jre default-jdk
4.4.2:配置环境变量
🧚🏻♀️1.通过vim编辑器打开环境变量的设置文件:
sudovim ~/.bashrc
🧚🏻♀️2.在文件的尾部加上以下语句:(按
i
进入编辑模式)
exportJAVA_HOME=/usr/lib/jvm/default-java
exportHADOOP_HOME=/usr/local/hadoop
exportPATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
🧚🏻♀️3.按
Esc
键退出,然后输入
:wq
保存修改。然后使环境变量生效:
source ~/.bashrc
4.5:下载编译好的hadoop,配置hadoop的环境
4.5.1:下载并解压
Tips:上面是官网网址,下载会巨慢,可以用国内镜像网站,这里给出阿里的一个镜像网站:https://mirrors.aliyun.com/apache/hadoop/core/hadoop-3.3.5/
🍓2. 进入解压包存放的Downloads文件夹,右键属性查看压缩包的绝对路径,然后解压至/usr/local目录下:
sudotar-zxf /home/hadoop/Downloads/hadoop-2.9.2.tar.gz -C /usr/local
🍓3.进入刚刚解压后存放的目录下:
cd /usr/local/
🍓4.将该文件夹的名字重命名为hadoop,屏蔽掉版本号的信息,使得后续命令行输入更为简便:
sudomv ./hadoop-2.9.2/ ./hadoop
4.5.2:配置环境
💐1.将已重命名的该文件夹的拥有者,指定给用户hadoop,缺少这一步,将导致后续操作特别是运行Hadoop时,反复因权限不足而停止:
cd /usr/local/
sudochown-R hadoop ./hadoop
💐2.经后续测试发现问题,虽然已经为ubuntu系统设置了java的环境变量,但hadoop实际运行时仍会出现找不到java-jdk的现象,故再对hadoop的环境文件进行修改,此外,该文件还包括启动参数、日志、pid文件目录等信息。先进入目录
cd ./hadoop/etc/hadoop
💐3.使用vim编辑器,打开环境变量文件:
sudovim hadoop-env.sh
💐4.添加该语句(这里也需要手动输入export):
exportJAVA_HOME=/usr/lib/jvm/default-java
💐5.按Esc键退出,然后输入:wq保存修改。然后使环境变量生效:
source hadoop-env.sh
💐6.截至目前,hadoop框架已经搭建好了,可以通过调用版本号进行测试hadoop是否可用
cd /usr/local/hadoop
./bin/hadoop version
正确搭建应该能看到hadoop的版本号等信息: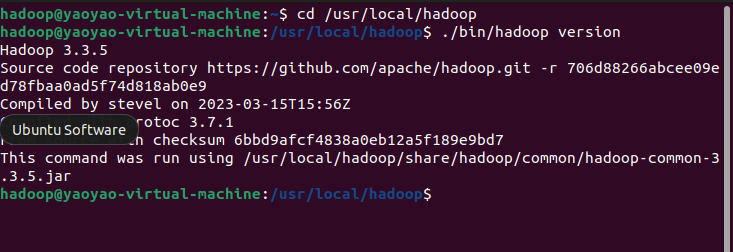
4.6:配置伪分布所需的四个文件
这四个文件都是在这个路径下,所以需要提前进入这个路径!
cd /usr/local/hadoop/etc/hadoop/
4.6.1:core-site.xml
- 先打开xml文件,
cd /usr/local/hadoop/etc/hadoop/。
sudo gedit core-site.xml
- 打开xml文件应该是有内容的,如果没有内容说明打开文件不对,需要检查输入的路径及文件名是否正确。 将替换为以下内容: - 第一个属性表示Hadoop重要临时文件的存放目录,指定后需将使用到的所有子级文件夹都要手动创建出来,否则无法正常启动服务- 第二个被官方称之为默认系统文件的名称(the name of the default file system),实际上决定了文件系统的主机号、端口号,对于伪分布式模型来说,其主机地址为localhost。
<configuration><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value><description>Abase for other temporary directories.</description></property><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property></configuration>
4.6.2:hdfs-site.xml
- 同样进入hdfs-site.xml文件:
sudo gedit hdfs-site.xml
- 对hdfs-site.xml进行同样的替换操作,属性的含义分别为复制的块的数量、DFS管理节点的本地存储路径、DFS数据节点的本地存储路径:
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/tmp/dfs/data</value></property><property><name>dfs.namenode.http-address</name><value>0.0.0.0:9870</value></property></configuration>
4.6.3:mapred-site.xml
- 同样打开
sudo gedit mapred-site.xml
- 这里使用yarn。yarn 是一种资源管理和作业调度技术,作为Hadoop 的核心组件之一,负责将系统资源分配给在 Hadoop 集群中运行的各种应用程序,并调度要在不同集群节点上执行的任务,其基本思想是将资源管理和作业调度/监视的功能分解为单独的 daemon,总体上yarn是 master/slave 结构,在整个资源管理框架中,ResourceManager 为 master,NodeManager 是 slaver。具体配置内容如下:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
4.6.4:yarn-site.xml
- 打开
sudo gedit yarn-site.xml
- 然后配置yarn-site.xml文件,这里修改NodeManager上运行的附属服务即可:
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
4.7:格式化并启动Hadoop服务
4.7.1:格式化(初始化)主节点
保险起见,执行这一步前关闭命令行模式,重新打开,放弃当前路径。
更改配置并保存后,格式化HDFS的NameNode,在这一步之前,如果hdfs-site.xml中dfs.namenode.name.dir属性指定的目录不存在,格式化命令会自动创建之;如果存在,请确保其权限设置正确,此时格式操作会清除其内部所有的数据并重新建立一个新的文件系统:
格式化是个巨大的坑,慎用!当我们进行多次格式化的时候,会出现datanode无法启动。原因在于多格式化之后,datanode的clusterID 和 namenode的clusterID 不匹配。这时datanode将无法启动。
解决方法:开机之后只进行一次格式化,格式化之后会导致datanode的clusterID 和 namenode的clusterID的不一致,就要进行替换。
cd /usr/local/hadoop/
./bin/hdfs namenode -format
4.7.2:启动hadoop服务
- 进入相应文件夹
cd /usr/local/hadoop/
- 首先停止启动所有的节点,使用命令行启动stop-all.sh脚本
./sbin/stop-all.sh
- 再进行启动
./sbin/start-all.sh
start-all.sh(该命令是start-dfs.sh与start-yarn.sh这两个命令的合并)。
mr-jobhistory-daemon.sh start historyserver
start-dfs.sh:启动HDFS服务start-yarn.sh:启动YARN服务mr-jobhistory-daemon.sh start historyserver:启动MapReduce服务
4.7.3:测试Hadoop服务
- 查看hadoop进程– 首先运行jps命令,查看正在运行的进程
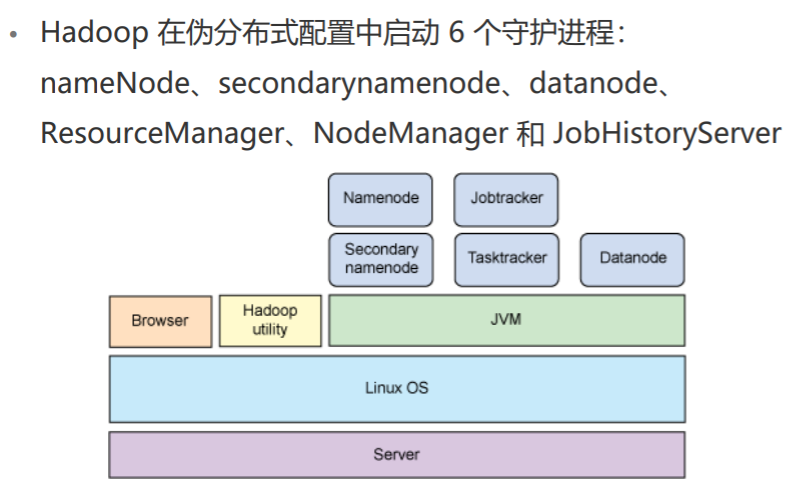
jps– 如果Hadoop成功运行,应该显示6个守护进程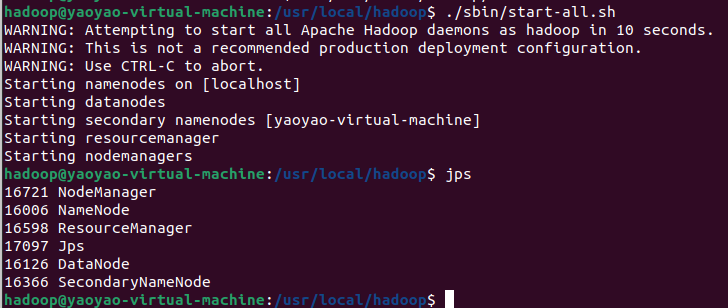 > Tips:少一个都不行!!!少了就说明上面的启动命令肯定没有完全运行成功,哪个少了就去google一下!
> Tips:少一个都不行!!!少了就说明上面的启动命令肯定没有完全运行成功,哪个少了就去google一下! - 通过web查看hadoop运行状态
• 通过http://localhost:9870/查看Namenode状态。
• 通过http://localhost:8088/ 查看资源管理器 状态。
• 通过http://localhost:19888/查看JobHistoryServer历史服务器 状态
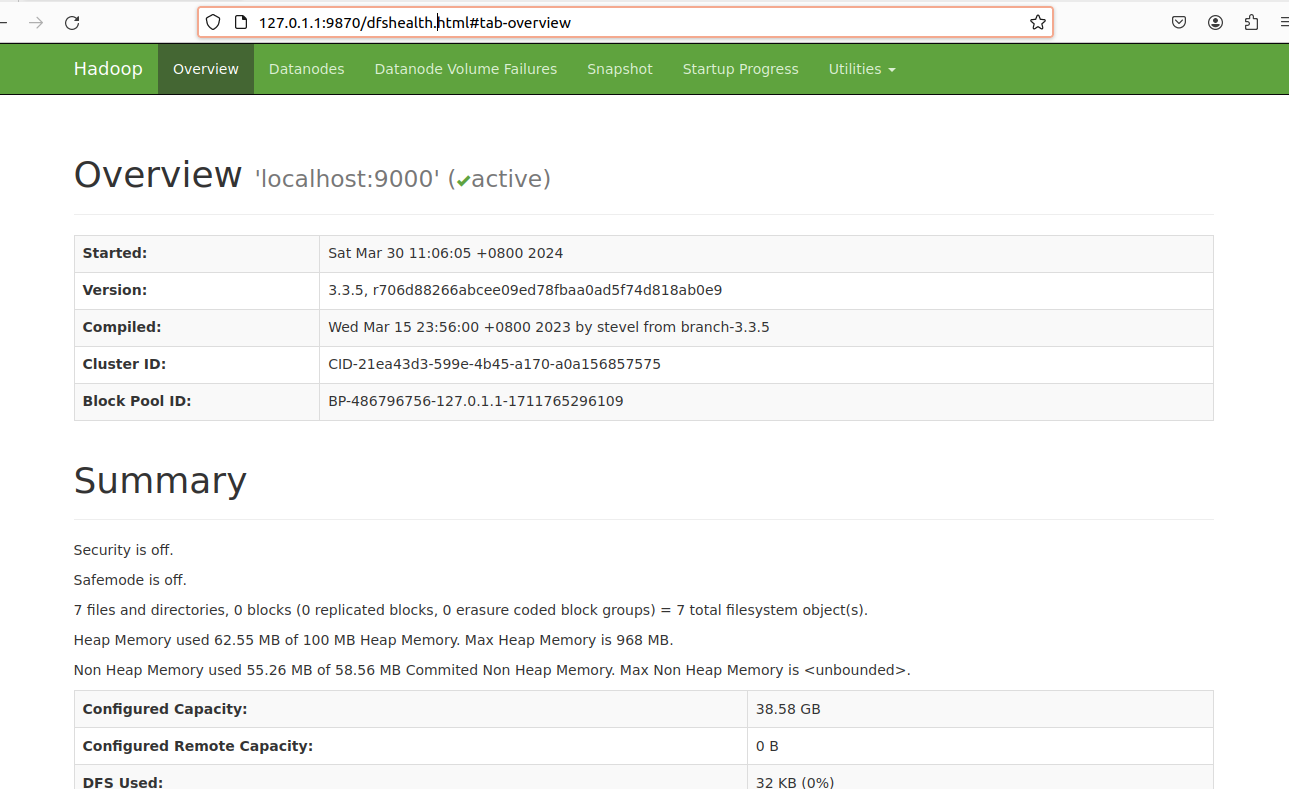
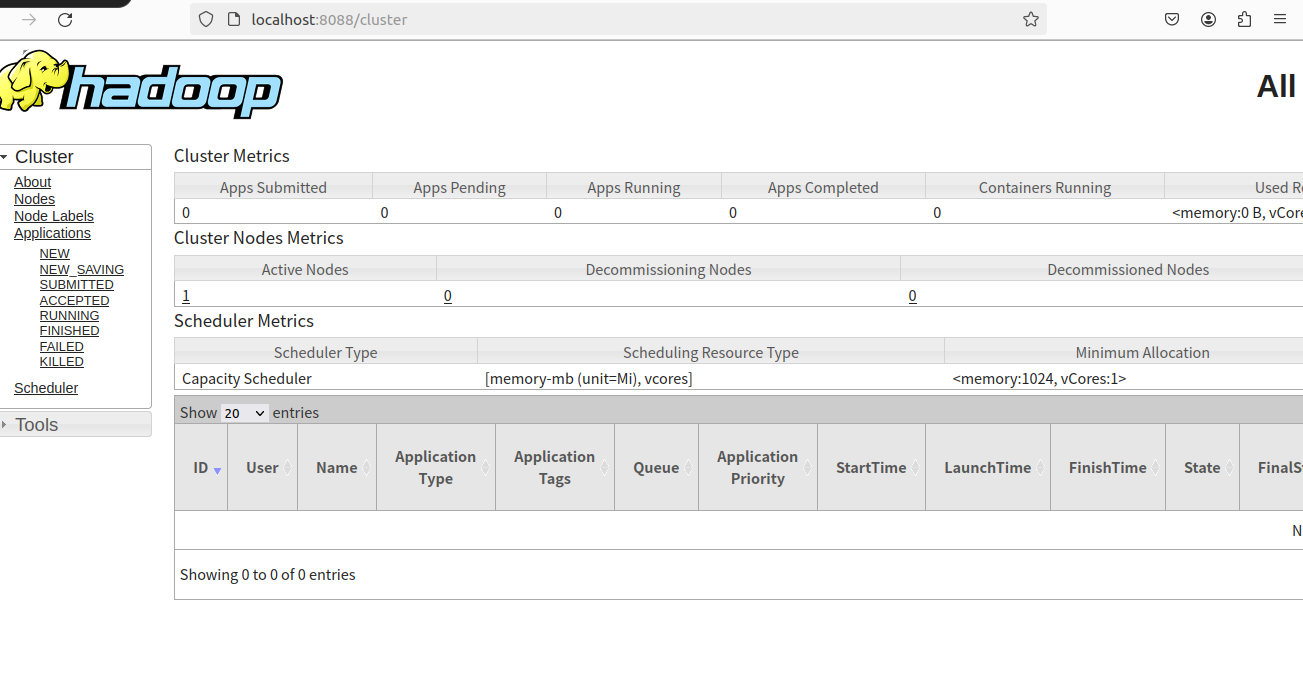
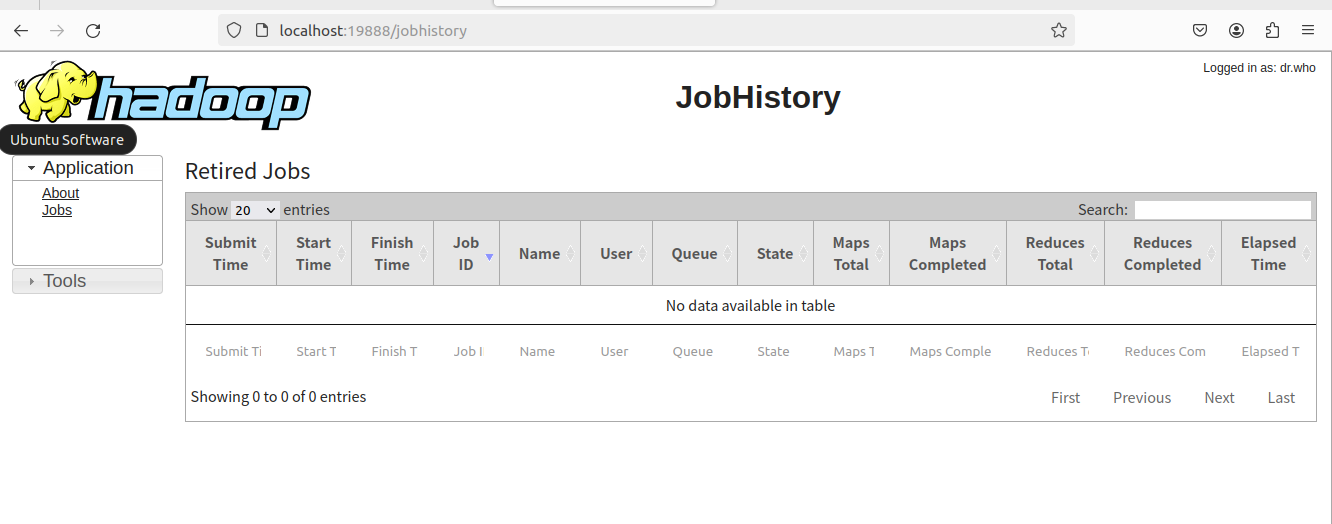
4.7.4:关闭Hadoop服务
当不再需要Hadoop运行时,运行下面的命令终止
Hadoop的全部服务、顺序相反
mr-jobhistory-daemon.sh stop historyserver
stop-yarn.sh
stop-dfs.sh
版权归原作者 Yaoyao2024 所有, 如有侵权,请联系我们删除。