
入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
一、RF背景——集成学习中的bagging流派
RF模型属于集成学习中的bagging流派,可以说是bagging的进化版
1、集成学习简介
集成学习分为2派:
(1)boosting:它组合多个弱学习器形成一个强学习器,且各个弱学习器之间有依赖关系。
(2)bagging:同样的,它也是组合多个弱学习器形成一个强学习器,但它各个弱学习器之间没有依赖关系,而且可以并行拟合。
2、bagging流派算法简介
(1)算法结构图
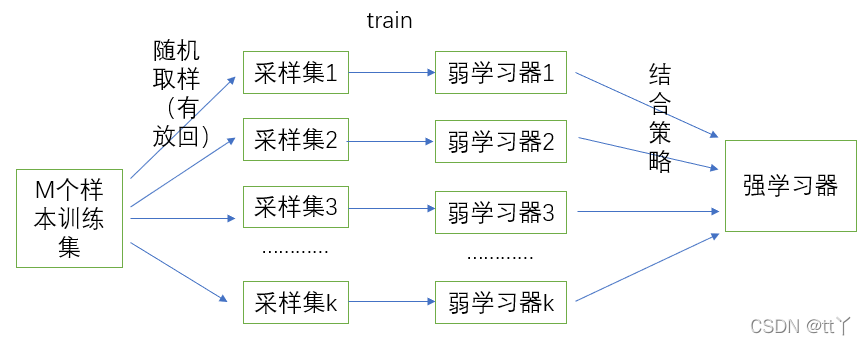
(2)算法步骤
🌳从原始样本集(包含M个样本)中抽取k个采样集
每个采样集的生成是使用随机采样(bootsrap)的方法抽取M个训练样本(有放回的抽样:所以可能被重复抽取)
进行k轮抽取,得到k个采样集。(k个采样集之间是相互独立的)
🌳分别对这k个采样集进行训练形成对应的k个弱学习器
🌳将这k个弱学习器模型输出通过结合策略得到最终的模型输出
结合策略:
对于分类问题:通常使用简单投票法,得到最多票数的类别或者类别之一为最终的模型输出。
对于回归问题:通常使用简单平均法,对k个弱学习器得到的回归结果进行算术平均得到最终的模型输出。
(3)OOB(袋外数据)& 泛化能力
🌳OOB:即Out of Bag(袋外数据)
上面我们提到“每个采样集的生成是使用随机采样(bootsrap)的方法抽取M个训练样本”。
那么原始数据集中任意一个样本被抽取出来的概率是1/M,没被抽取出来的概率为1-1/M。
那么M次采样都没抽中的概率就为
当m→∞时,p→1/e,约等于0.368
那么在每轮采样集的生成中大约有36.8%的数据没有被采样集采集中,这部分数据被称为袋外数据。
🌳OOB的作用
因为这些数据没有参与采样集模型的拟合,所以可以用来检测模型的泛化能力
🌳泛化能力
由于Bagging算法每次都进行采样来训练模型,因此泛化能力很强,对降低模型的方差很有效。当然对于训练集(采样集)的拟合程度就会差一些,也就是模型的偏差会大一些。
二、RF模型算法原理
1、RF Vs bagging
RF用了改进的CART决策树来作为弱学习器
(1)CART决策树
CART决策树是在给定输入随机变量X的条件下输出随机变量Y的条件概率分布的学习方法
CART假设决策树全是二叉树(即其结点只有两种选择:“是” or “否”):决策树递归二分每个特征,最终得到决策树,通过不断的划分,将特征空间划分为有限个单元,并在这些单元上确定预测的概率分布
因此CART就是递归构建二叉树,但是对于分类和回归问题使用的策略是不一样的:
对于回归树使用的是平方误差最小;而对于分类树使用的是基尼指数最小化准则()
(2)RF中的CART决策树
普通决策树:在节点上所有的n个样本特征中选择一个最优特征来作为决策树的左右子树划分
RF:随机选择节点上的一部分样本特征,假设为t个特征(t<n),然后在这些随机选择样本特征中,选择一个最优的特征来作为决策树的左右子树划分,这样进一步增强了模型的泛化能力
t越小——模型越稳定(模型方差变小),但对于训练集的拟合程度会变差(偏差变大)
所以在实际案例中,一般会通过交叉验证调参获取一个合适的t
注:分类问题中,t默认取
;回归问题中,默认取M/3
2、算法步骤
(1)从原始样本集(包含M个样本)中抽取k个采样集
每个采样集的生成是使用随机采样(bootsrap)的方法抽取M个训练样本(有放回的抽样:所以可能被重复抽取)
进行k轮抽取,得到k个采样集。(k个采样集之间是相互独立的)
(2)分别对这k个采样集进行训练形成对应的k个弱学习器
在训练决策树模型的节点的时候, 在节点上所有样本特征中选择一部分样本特征(选中了就不放回了),在这部分样本特征中选择一个最优的特征来作为决策树的左右子树划分
判断特征的重要性:
🎈对整个随机森林,得到相应OOB,然后计算OOB误差,记为errOOB1
🎈随机对OOB所有样本的特征X加入噪声干扰(即可以随机改变样本在特征X处的值),再次计算袋外数据误差,记为errOOB2
🎈假设森林中有N棵树,则特征X的重要性 = (∑errOOB2−errOOB1)/N
(3)将这k个弱学习器模型输出通过结合策略得到最终的模型输出
结合策略:
对于分类问题:通常使用简单投票法,得到最多票数的类别或者类别之一为最终的模型输出。(RF通常处理的是分类问题)
对于回归问题:通常使用简单平均法,对k个弱学习器得到的回归结果进行算术平均得到最终的模型输出。
刚刚不是说有OOB嘛~派上用场啦
🌳对OOB样本中的每个样本,计算对应决策树对它的分类情况;
🌳然后以简单多数投票作为该样本的分类结果;
🌳最后用误分个数占样本总数的比率作为随机森林的oob误分率。
三、RF模型的优缺点
1、优点
RF善于处理高维数据,特征遗失数据,和不平衡数据
(1)训练可以并行化,速度快
(2)对高维数据集的处理能力强,它可以处理成千上万的输入变量,并确定最重要的变量,因此被认为是一个不错的降维方法。
(3)在训练集缺失数据时依旧能保持较好的精度(原因:RF随机选取样本和特征;RF可以继承决策树对缺失数据的处理方式)
(4)泛化能力强,因为随机
2、缺点
(1)在解决回归问题时效果不是很好
RF不能给出一个连续的输出,而且RF不能做出超越训练集数据范围的预测,这可能会导致在训练含有某些特定噪声的数据时出现过拟合
(2)对特征数比较少的数据,它的随机性不好发挥,效果不太好
四、RF的变式——extra trees
改进点:
1、extra trees的每个决策树采用原始训练集
2、extra trees随机选择一个特征值来划分决策树
五、代码实现RF模型
我们可以调用sklearn里面现成的RF模型来实现
🌳首先导入所需要的库
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier #导入随机森林模型
from sklearn.datasets import load_boston #让我们利用sklearn里现有的boston数据
from sklearn.model_selection import train_test_split#用来进行训练集和测试集的自动分配
🌳我们这里使用sklearn里的boston数据
boston = load_boston()#导入boston数据
🌳我们把数据变成DataFrame类型,这样比较好处理,我们看起来也比较清晰
bos = pd.DataFrame(boston.data, columns = boston.feature_names)
bos['MEDV'] = boston.target
print(bos)
print(bos.columns)
数据变成这样
🌳让我们把数据变为numpy类型再送进train_test_split进行训练集和测试集的分配
y = np.array(bos['MEDV']) #目标
x = bos.drop(['MEDV'], axis=1)#去除目标后的所有数据作为输入
x = np.array(x)
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2)#分成80%训练,20%测试
🌳模型配置并训练
rf = RandomForestClassifier(n_estimators=10000, random_state=0, n_jobs=-1)#RF模型设置
rf.fit(x_train, y_train.astype('int'))#把数据送进去训练
🎈RandomForestClassifier函数
n_estimators :森林里决策树的数目,默认是10
random_state:随机数生成器使用的种子
n_jobs:用于拟合和预测的并行运行的工作数量。如果值为-1,那么工作数量被设置为核的数量
🌳输出预测后的每个特征对于MEDV的重要性
a = rf.feature_importances_
print(boston.feature_names)
print("重要性:",a)
预测结果

欢迎大家在评论区批评指正,谢谢大家~
版权归原作者 tt丫 所有, 如有侵权,请联系我们删除。