
Spark Streaming 编程权威使用指南
文章目录
注意:本文档为Spark的旧版本Streaming引擎。Spark Streaming 不再更新,是一个遗留项目。在Spark中有一种新的、更易用的流处理引擎,称为结构化流式处理。您应该使用Spark结构化流处理来开发流式应用和流水线。请参阅结构化流式处理编程指南。
概述
Spark Streaming 是 Spark 核心 API 的扩展,支持可扩展、高吞吐量、容错的实时数据流处理。可以从多个来源(如Kafka、Kinesis或TCP sockets)摄取数据,并使用高级函数(如map、reduce、join和window)执行复杂算法进行处理。最后,处理后的数据可以推送到文件系统、数据库和实时仪表板。事实上,可以在数据流上应用 Spark 的机器学习和图处理算法。
Spark Streaming 的内部工作原理如下。它接收实时输入数据流并将数据划分为批次,然后由 Spark 引擎处理生成最终结果流的批次。
Spark Streaming 提供了一个称为离散化流(Discretized Stream)或 DStream 的高级抽象,它表示连续的数据流。DStream 可以通过从诸如 Kafka 和 Kinesis 等源创建输入数据流,或者通过对其他 DStream 应用高级操作来创建。在内部,DStream 被表示为 RDD(弹性分布式数据集)的序列。
本指南向您展示如何使用 DStream 编写 Spark Streaming 程序。本指南介绍了在Scala、Java或Python(从Spark 1.2开始引入)中编写 Spark Streaming 程序的方法。在本指南的各个部分中,您将找到可以选择不同语言的代码片段的选项卡。
注意:在 Python 中有一些与其他语言不同或不可用的 API。在本指南中,您将找到标记为 Python API 的标签来突出显示这些差异。
快速示例
在我们深入研究如何编写自己的 Spark Streaming 程序之前,让我们快速看一下一个简单的 Spark Streaming 程序是什么样子的。假设我们想要计算从监听 TCP socket 上接收的文本数据中的单词数量。您只需要执行以下操作。
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# 创建具有两个工作线程和批处理间隔为1秒的本地StreamingContext
sc = SparkContext("local[2]","NetworkWordCount")
ssc = StreamingContext(sc,1)# 创建将连接到 hostname:port(例如localhost:9999)的DStream
lines = ssc.socketTextStream("localhost",9999)# 将每行拆分为单词
words = lines.flatMap(lambda line: line.split(" "))# 计算每批次中的每个单词的数量
wordCounts = words.map(lambda word:(word,1)).reduceByKey(lambda x, y: x + y)# 将每个RDD生成的前十个元素打印到控制台
wordCounts.pprint()# 开始计算
ssc.start()# 等待计算结束
ssc.awaitTermination()
完整的代码可以在 Spark Streaming 示例 NetworkWordCount 中找到。
如果您已经下载并构建了 Spark,可以按照以下方式运行此示例。首先,您需要使用 Netcat(大多数类Unix系统中都有的小工具)作为数据服务器运行:
$ nc-lk9999
然后,在另一个终端中,您可以使用以下命令启动示例:
$ ./bin/spark-submit examples/src/main/python/streaming/network_wordcount.py localhost 9999
然后,您在运行 netcat 服务器的终端中键入的任何行都将被计数并每秒打印在屏幕上。效果如下:
-------------------------------------------
Time: 2014-10-14 15:25:21
-------------------------------------------
(hello,1)
(world,1)
...
基本概念
接下来,我们将超越简单示例,详细介绍 Spark Streaming 的基本知识。
链接
与 Spark 类似,Spark Streaming 可通过 Maven Central 获得。要编写自己的 Spark Streaming 程序,您需要将以下依赖项添加到 SBT 或 Maven 项目中。
Maven:
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>3.5.0</version><scope>provided</scope></dependency>
对于像 Kafka 和 Kinesis 这样的不在 Spark Streaming 核心 API 中的数据源,您需要将相应的 artifact spark-streaming-xyz_2.12 添加到依赖项中。例如,一些常见的数据源如下:
数据源 Artifact
Kafka spark-streaming-kafka-0-10_2.12
Kinesis spark-streaming-kinesis-asl_2.12(Amazon Software License)
有关最新列表,请参阅 Maven 存储库以获取支持的所有数据源和 artifact 的完整列表。
初始化 StreamingContext
要初始化 Spark Streaming 程序,必须创建一个 StreamingContext 对象,该对象是所有 Spark Streaming 功能的主要入口点。
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
sc = SparkContext(master, appName)
ssc = StreamingContext(sc,1)
appName 参数是用于在集群 UI 上显示的应用程序名称。master 是 Spark、Mesos 或 YARN 集群的 URL,或者是一个特殊的 “local[]" 字符串,表示在本地模式下运行。实际上,在集群上运行时,您不会想在程序中硬编码 master,而是使用 spark-submit 在其中启动应用程序。然而,在本地测试和单元测试中,可以传递 "local[]” 以在进程内运行 Spark Streaming(检测本地系统中的核心数)。
批处理间隔必须根据应用程序的延迟要求和可用集群资源进行设置。有关详细信息,请参见性能调整部分。
定义上下文后,您需要执行以下操作:
- 通过创建输入 DStream 定义输入源。
- 通过对 DStream 应用转换和输出操作来定义流计算。
- 使用
streamingContext.start()接收数据并进行处理。 - 使用
streamingContext.awaitTermination()等待处理结束(手动或由于任何错误)。 - 使用
streamingContext.stop()可以手动停止处理。
请记住:
- 一旦上下文已启动,就无法向其设置或添加新的流计算。
- 一旦上下文停止,就无法重新启动。
- 一个 JVM 中只能同时存在一个 StreamingContext。
- 调用
stop()时会同时停止 SparkContext。如果只想停止 StreamingContext,请将stopSparkContext参数设置为 false。 - 可以重复使用 SparkContext 来创建多个 StreamingContext,只要在创建下一个 StreamingContext 之前停止上一个 StreamingContext(而不是停止 SparkContext)即可。
离散化流(DStreams)
离散化流(Discretized Stream)或 DStream 是 Spark Streaming 提供的基本抽象。它表示连续的数据流,可以是从源接收的输入数据流,也可以是通过转换输入流生成的处理后的数据流。在内部,DStream 由一系列 RDD(弹性分布式数据集)表示,RDD 是 Spark 对不可变分布式数据集的抽象(有关详细信息,请参阅 Spark 编程指南)。DStream 中的每个 RDD 包含来自特定间隔的数据,如下图所示。
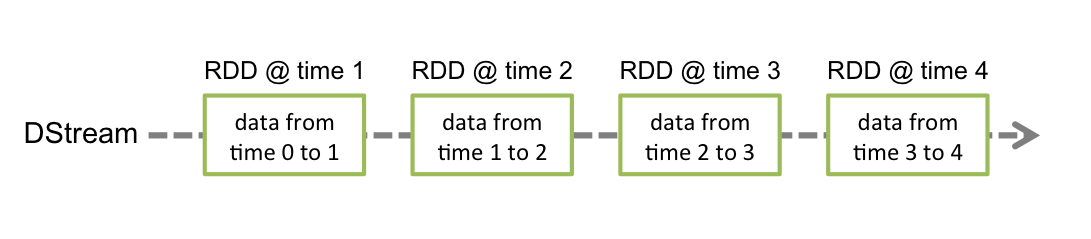
任何应用于 DStream 的操作都会转化为对底层 RDD 的操作。例如,在将行流转换为单词流的示例中,flatMap 操作将应用于 lines DStream 中的每个 RDD,以生成 words DStream 中的 RDD。如下图所示。
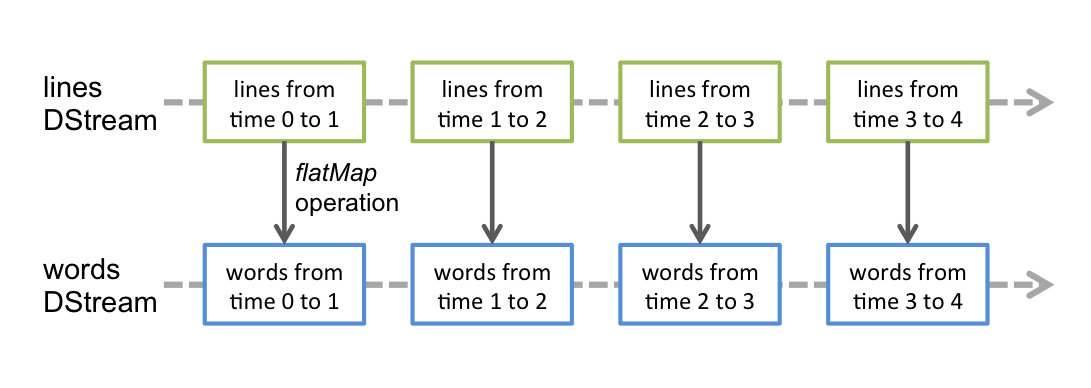
这些底层 RDD 转换由 Spark 引擎计算。DStream 操作隐藏了大多数这些细节,并为开发人员提供了更高级别的 API 以提供方便。这些操作将在后面的章节中详细讨论。
输入 DStreams 和 Receivers
输入 DStream 是表示从流式源接收到的输入数据流的 DStream。在快速示例中,lines 是一个输入 DStream,因为它表示从 netcat 服务器接收到的数据流。除文件流之外,每个输入 DStream 都与一个 Receiver(Scala 文档,Java 文档)对象相关联,该对象从源接收数据并将其存储在 Spark 的内存中进行处理。
Spark Streaming 提供了两类内置的流式源。
基本源:直接在 StreamingContext API 中提供的源。例如:文件系统和 socket 连接。
高级源:通过额外的实用程序类提供的 Kafka、Kinesis 等源。这些需要链接到额外的依赖项,如链接部分所述。
我们将在本节后面讨论每个类别中存在的一些源。
请注意,如果要在流式应用程序中并行接收多个数据流,可以创建多个输入 DStream(在性能调整部分中进一步讨论)。这将创建多个接收器,它们将同时接收多个数据流。但请注意,Spark worker/executor 是一个长时间运行的任务,因此它占用了分配给 Spark Streaming 应用程序的一个核心。因此,重要的是要记住,Spark Streaming 应用程序需要分配足够的核心(或线程,如果在本地运行)来处理接收到的数据以及运行接收器。
基本源
我们已经看过了快速示例中的
ssc.socketTextStream(...)
,它使用文本数据从 TCP socket 连接创建了一个 DStream。除了 sockets,StreamingContext API 还提供了从文件作为输入源创建 DStream 的方法。
文件流
要从与 HDFS API 兼容的任何文件系统
版权归原作者 wang2leee 所有, 如有侵权,请联系我们删除。