
前言
作者:小蜗牛向前冲
** 如果觉的博主的文章还不错的话,还请
点赞,收藏,关注👀支持博主。如果发现有问题的地方欢迎❀大家在评论区指正 **
本期学习:理解什么是数据库,数据库的基本操作增删查改。
一、数据库的基础知识
1、什么是数据库
大家在日常生活中,用电脑记录数据通常是保证在文件中的,比如写论文,写计划书等。
那我在企业中存放用户数据也用文件不就可以了。
为什么要弄出一个数据库这要的东西呢?
文件保存数据有以下几个缺点:
- 文件的安全性问题
- 文件不利于数据查询和管理
- 文件不利于存储海量数据 文
- 件在程序中控制不方便
为了解决上述问题,专家们设计出更加利于管理数据的东西——数据库,它能更有效的管理数据。数据 库的水平是衡量一个程序员水平的重要指标。
数据库存储介质:
- 磁盘
- 内存
数据库是有客户端(mysql)和服务端(mysqld) ,所以数据库的本质也就是基于C(mysql)S(mysqld)模式的一种网络服务。
当我们程序员在客户端(mysql)对服务端(mysqld)进行字段或者要求时,服务端(mysqld)在他存放数据的地方查找,然后给客户端(mysql)返回结果。
2、数据库基本常识
主流数据库
- SQL Sever: 微软的产品,.Net程序员的最爱,中大型项目。
- Oracle: 甲骨文产品,适合大型项目,复杂的业务逻辑,并发一般来说不如MySQL。
- MySQL:世界上最受欢迎的数据库,属于甲骨文,并发性好,不适合做复杂的业务。主要用在电 商,SNS,论坛。对简单的SQL处理效果好。
- PostgreSQL :加州大学伯克利分校计算机系开发的关系型数据库,不管是私用,商用,还是学术研 究使用,可以免费使用,修改和分发。
- SQLite: 是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库 中。它的设计目标是嵌入式的,而且目前已经在很多嵌入式产品中使用了它,它占用资源非常的 低,在嵌入式设备中,可能只需要几百K的内存就够了。
- H2: 是一个用Java开发的嵌入式数据库,它本身只是一个类库,可以直接嵌入到应用项目中。
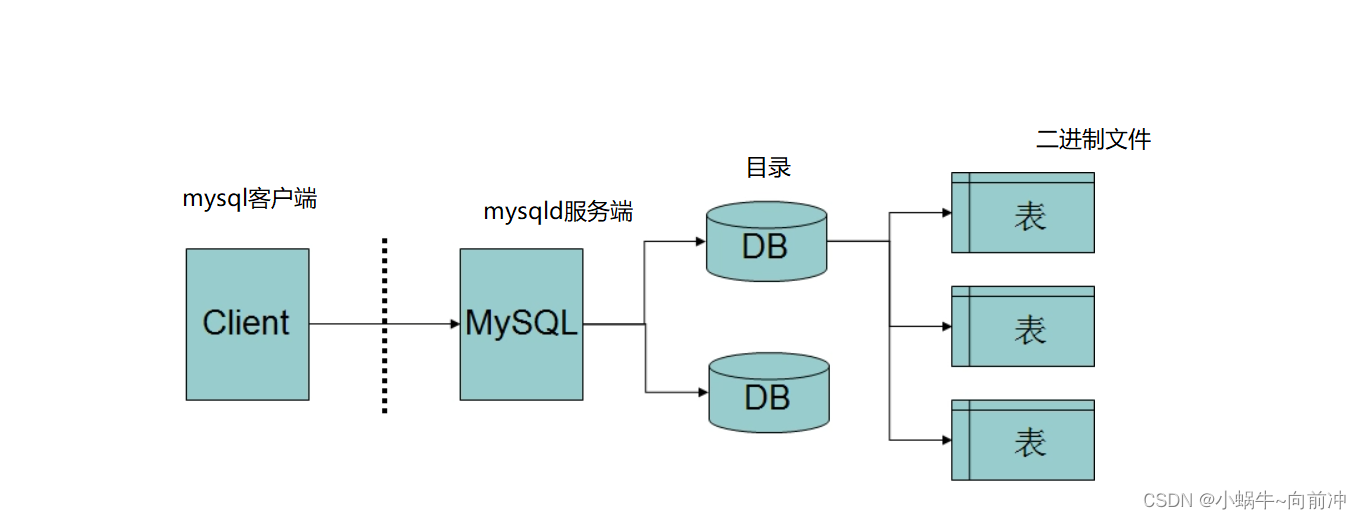
**服务器,数据库,表关系 **
- 所谓安装数据库服务器,只是在机器上安装了一个数据库管理系统程序,这个管理程序可以管理多个数据库,一般开发人员会针对每一个应用创建一个数据库。
- 为保存应用中实体的数据,一般会在数据库中创建多个表,以保存程序中实体的数据。
- 数据库服务器、数据库和表的关系如下:
**MySQL架构 **
- MySQL 是一个可移植的数据库,几乎能在当前所有的操作系统上运行,如 Unix/Linux、Windows、 Mac 和 Solaris。
- 各种系统在底层实现方面各有不同,但是 MySQL 基本上能保证在各个平台上的物理体 系结构的一致性。
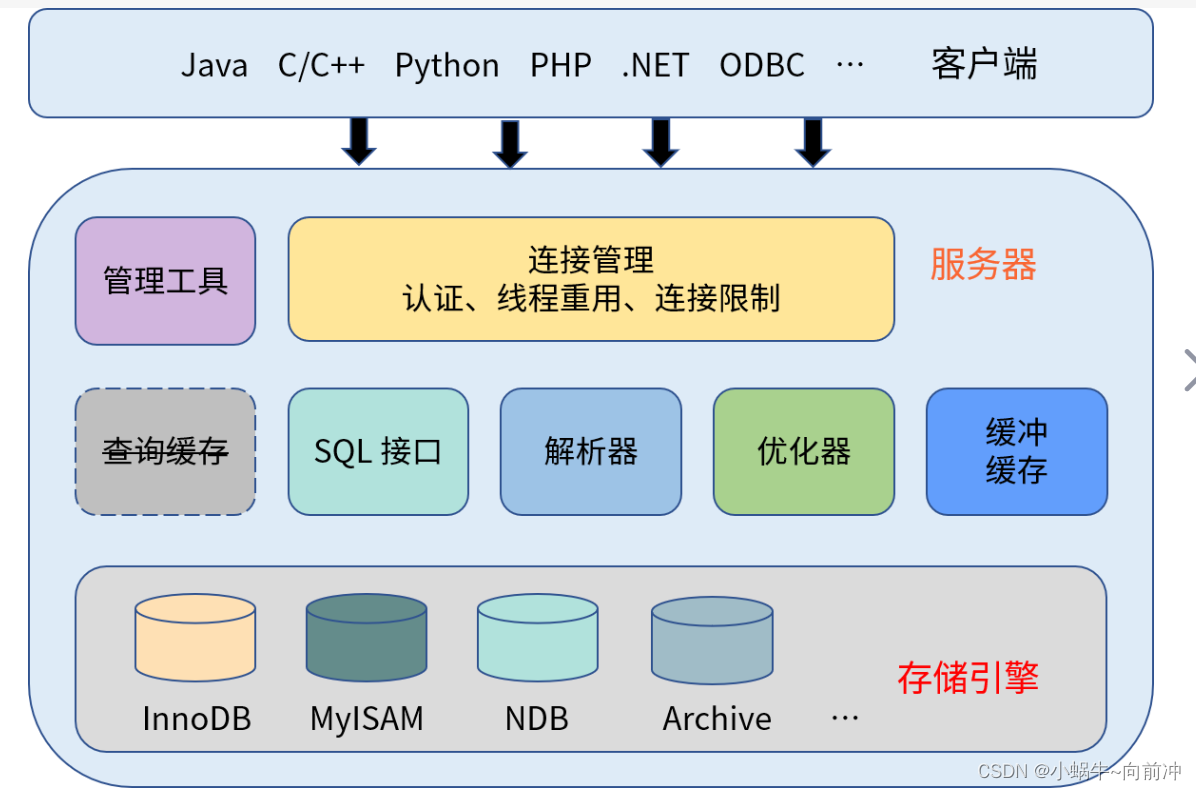
MySQL 的架构可以分为两个主要层次:服务层和存储引擎层。以下是 MySQL 架构的主要组成部分:
服务层(Server Layer):
- 连接管理器(Connection Manager): 处理客户端连接的建立和断开。
- 查询解析器(Query Parser): 解析客户端发送的 SQL 查询语句。
- 查询缓存(Query Cache): 缓存查询语句及其结果,以提高相同查询的响应速度。在 MySQL 8.0 版本后,查询缓存被废弃,不再被推荐使用。
- 优化器(Optimizer): 分析查询并生成最优的执行计划。
- 执行引擎(Execution Engine): 执行优化后的查询计划,与存储引擎进行交互,返回结果给客户端
存储引擎层(Storage Engine Layer):
- 存储引擎(Storage Engine): 负责数据的存储和检索。MySQL 支持插件式存储引擎,常见的存储引擎包括: - InnoDB: 默认的事务型存储引擎,提供了ACID事务支持和行级锁定。- MyISAM: 不支持事务,但对于读密集型操作效果较好。- Memory: 将表中的数据存储在内存中,适用于对速度要求较高的临时表。
- 表管理器(Table Manager): 负责管理表的创建、修改和删除等操作。
- 缓冲池(Buffer Pool): 存储引擎使用的内存缓存,主要用于缓存数据和索引,提高读取性能。
- 日志管理器(Log Manager): 记录数据的变更,包括事务日志和错误日志。
3、简单的见一见MYSQL
在自己服务器机会后安装后在操作,SCDN中有许多优秀的博客分享了如何安装MYSQL,我这里就不在献丑了。
首先查看一下自己服务器是否安装好
ps ajx |grep mysql

没有问题后,就进行mysql的登入
mysql -u root -p
 创建数据库
创建数据库
create database helloworld;

** 使用数据库**
use helloworld;

**创建数据库表 **
create table student(
name varchar(32),
gender varchar(2),
age int
);

**表中插入数据 **
insert into student (name, gender, age) values ('张三', '男' , 18);
insert into student (name, gender, age) values ('李四', '女' , 19);
insert into student (name, gender, age) values ('李四', '女' , 19);

**查询表中的数据 **
select * from student;
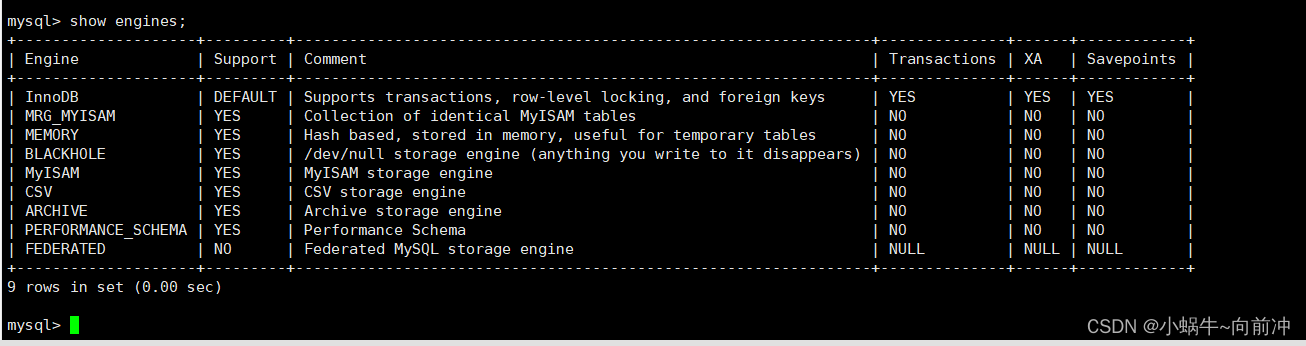
 查看存储引擎
查看存储引擎
show engines;
**退出数据库 **
\q;
 我们可以在root的权限下进入 cd /var/lib/mysql这个路径
我们可以在root的权限下进入 cd /var/lib/mysql这个路径
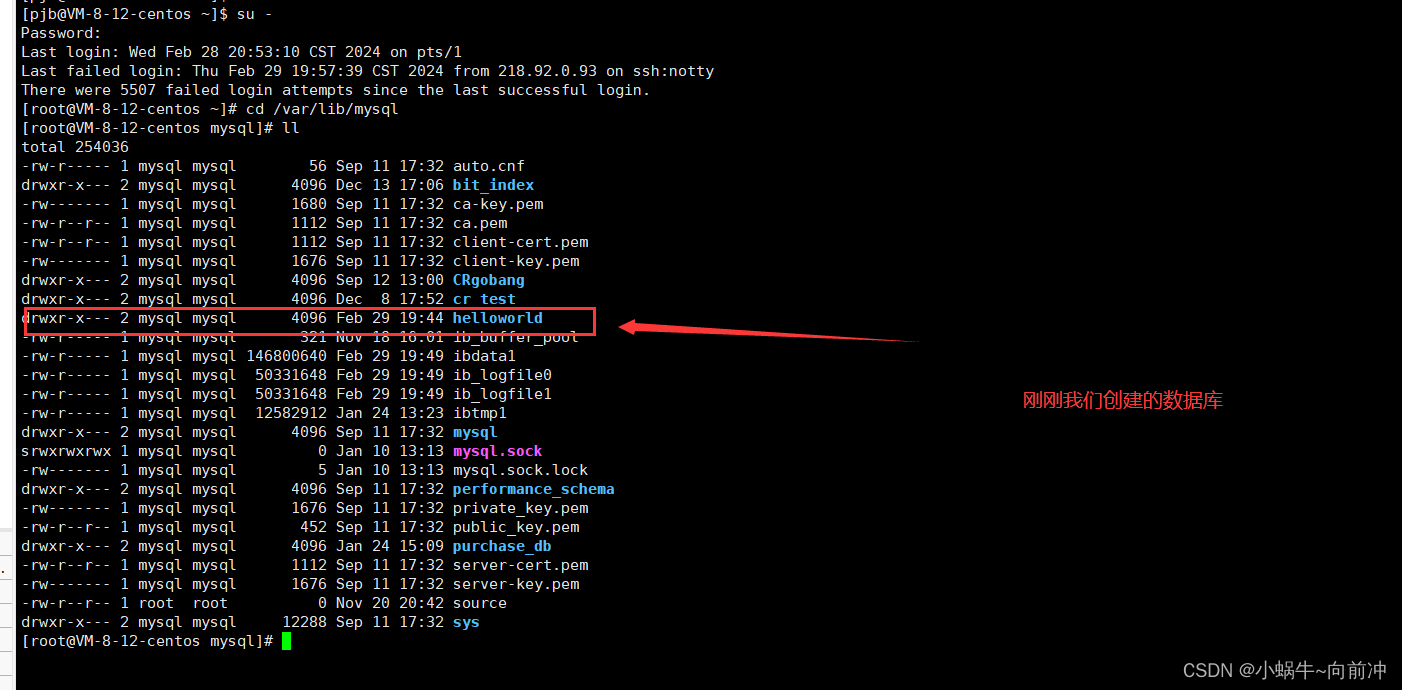
对于上面的案例我们认识到了什么呢?
- 1.建立数据库,本质就是Linux下的一个目录
- ⒉在数据库内建立表,本质就是在Linux下创建对应的文件即可!
- 3 数据库本质其实也是文件! !只不过这些文件并不由程序员直接操作,而是由数据库服务帮我们进行操作
**SQL分类 **
- DDL【data definition language】 数据定义语言,用来维护存储数据的结构 代表指令:
- create, drop, alter
- DML【data manipulation language】 数据操纵语言,用来对数据进行操作 代表指令: insert,delete,update
- DML中又单独分了一个DQL,数据查询语言,代表指令: select DCL【Data Control Language】 数据控制语言,主要负责权限管理和事务 代表指令: grant,revoke,commit
对于SQL分类命令的细节后面会为大家一一分享。
二、MYSQL中的库的操作(增删查改)
1、库的创建
创建数据库的时候,有两个编码集:
- 1**.数据库编码集-**-数据库未来存储数据(写入的格式)
- 2数据库校验集--支持数据库,进行字段比较使用的编码,本质也是一种读取数据库中数据的采用的编码格式(读取的格式)
数据库无论对数据做任何操作,都必须保证操作和编码必须是编码一致的!
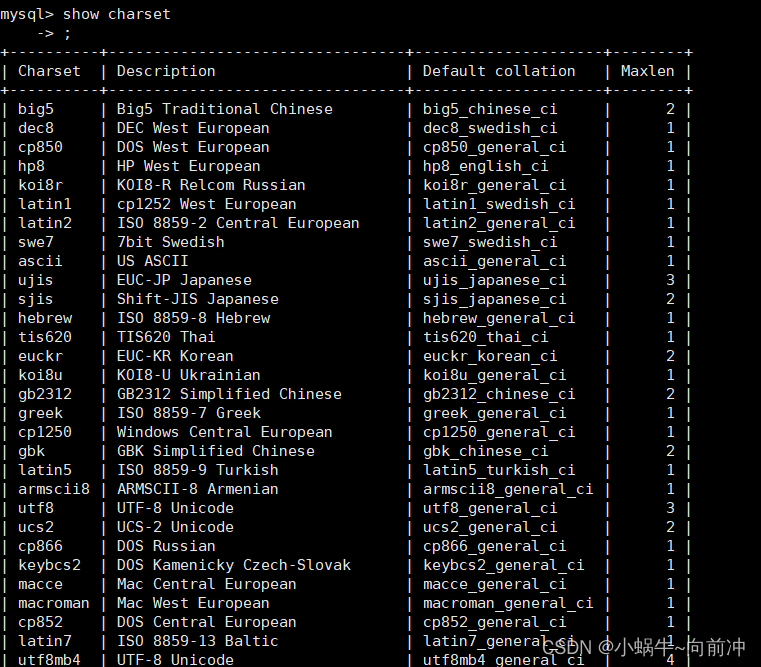
查看数据库支持的字符集
show charset;
**查看数据库支持的字符集校验规则 **
show collation;
**校验规则对数据库的影响 **:
不区分大小写
- 创建一个数据库,校验规则使用utf8_ general_ ci[不区分大小写]
- 创建一个数据库,校验规则使用utf8_ bin[区分大小写]
创建数据库的语法
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [,
create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name
CREATE DATABASE [IF NOT EXISTS] db_name: 这部分定义了创建数据库的语法。IF NOT EXISTS是一个可选的子句,它表示如果数据库已经存在,则不会创建新的数据库。db_name是要创建的数据库的名称。create_specification: 这是用于指定数据库创建选项的部分。你可以在这里指定默认的字符集和校对规则。[DEFAULT] CHARACTER SET charset_name: 这是用于指定默认字符集的部分。DEFAULT关键字是可选的,如果不指定,默认的字符集将被设置为指定的charset_name。[DEFAULT] COLLATE collation_name: 这是用于指定默认校对规则的部分。DEFAULT关键字是可选的,如果不指定,默认的校对规则将被设置为指定的collation_name。
在了解到数据库的创建后,我们分别创建test1和test2数据库用来验证 校验规则使用utf8_ general_ ci[不区分大小写]和校验规则使用utf8_ bin[区分大小写]
创建test1和test2
create database test1 collate utf8_general_ci;
create database test2 collate utf8_bin;

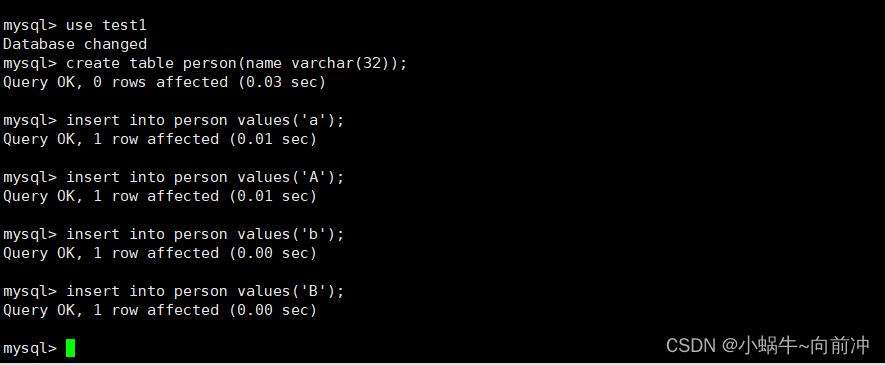
** 分别进入test1和test2数据库后插入数据**
test1库
use test1;
create table person(name varchar(20));
insert into person values('a');
insert into person values('A');
insert into person values('b');
insert into person values('B');
test2库
use test2;
create table person(name varchar(20));
insert into person values('a');
insert into person values('A');
insert into person values('b');
insert into person values('B');

这里我们插入test1和test2数据的库都是相同的数据。
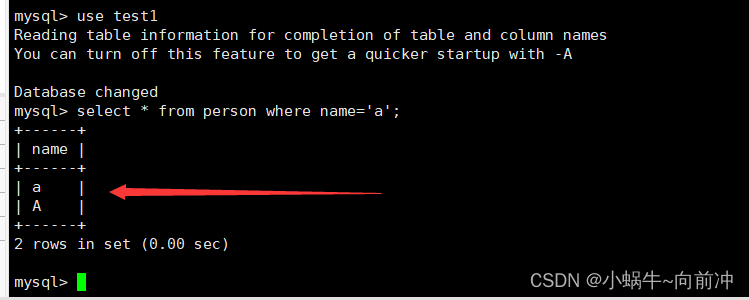
对test1和test2分别进行 查询和排序
mysql> use test1;
mysql> select * from person where name='a';
不区分大小写的查询以及结果
区分大小写的查询以及结果
不区分大小写排序以及结果:
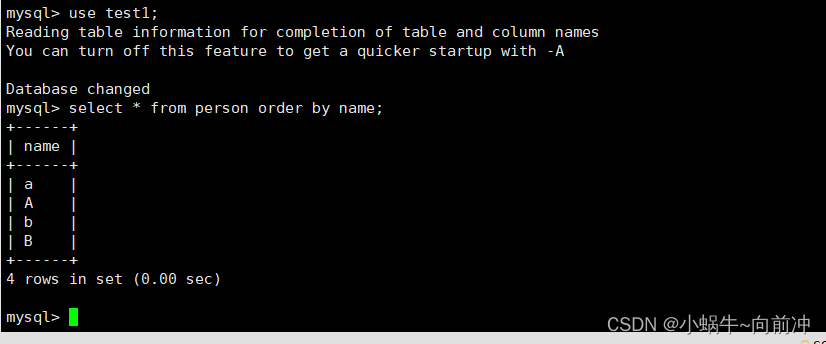
区分大小写排序以及结果:
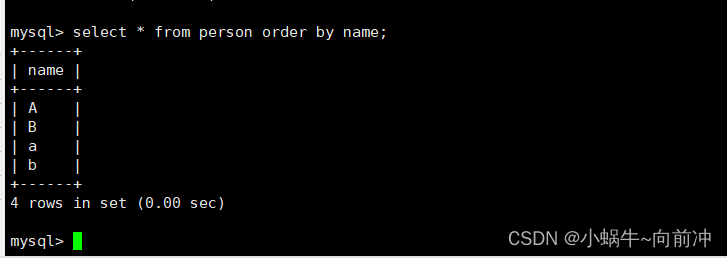
这些都是因为 **字符集校验规则 **不同而引起的。
2、库的删除
语法
DROP DATABASE [IF EXISTS] db_ name;
执行删除之后的结果:
- 数据库内部看不到对应的数据库
- 对应的数据库文件夹被删除,级联删除,里面的数据表全部被删
注意:不要随意删除数据库 ,如果我们一定删除,请记得一定要备份
这里我们把我们以前创建的helloworld删除。
drop datadase helloworld;

3、库的修改
语法:
ALTER DATABASE db_name
[alter_spacification [,alter_spacification]...]
alter_spacification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name
ALTER DATABASE db_name: 这部分定义了要修改的数据库的名称。alter_specification: 这是用于指定数据库修改选项的部分。你可以在这里指定新的默认字符集和校对规则。[DEFAULT] CHARACTER SET charset_name: 这是用于指定新的默认字符集的部分。DEFAULT关键字是可选的,如果不指定,默认的字符集将被设置为指定的charset_name。[DEFAULT] COLLATE collation_name: 这是用于指定新的默认校对规则的部分。DEFAULT关键字是可选的,如果不指定,默认的校对规则将被设置为指定的collation_name。
对数据库的修改主要指的是修改数据库的字符集,校验规则
实例: 将 test1数据库字符集改成 gbk
alter database test1 charset=gbk;
show create database test1;
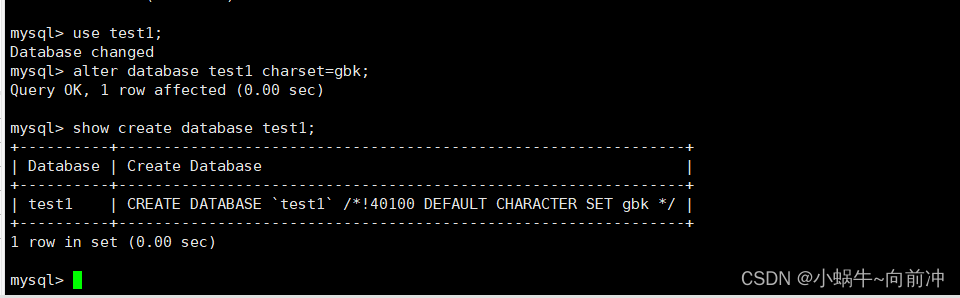
4、库的备份和恢复
备份
语法:
mysqldump -P3306 -u root -p 密码 -B 数据库名 > 数据库备份存储的文件路径
示例:将mytest库备份到文件(退出连接)
mysqldump -P3306 -u root -p123456 -B mytest > D:/mytest.sql
这时,可以打开看看 mytest.sql 文件里的内容,其实把我们整个创建数据库,建表,导入数据的语句 都装载这个文件中。
还原
mysql> source D:/mysql-5.7.22/mytest.sql;
** 注意事项**
- 如果备份的不是整个数据库,而是其中的一张表,怎么做?
mysqldump -u root -p 数据库名 表名1 表名2 > D:/mytest.sql
- 同时备份多个数据库
mysqldump -u root -p -B 数据库名1 数据库名2 ... > 数据库存放路径
如果备份一个数据库时,没有带上-B参数, 在恢复数据库时,需要先创建空数据库,然后使用数据 库,再使用source来还原。
** 查看连接情况 **
** 语法:**
show processlist
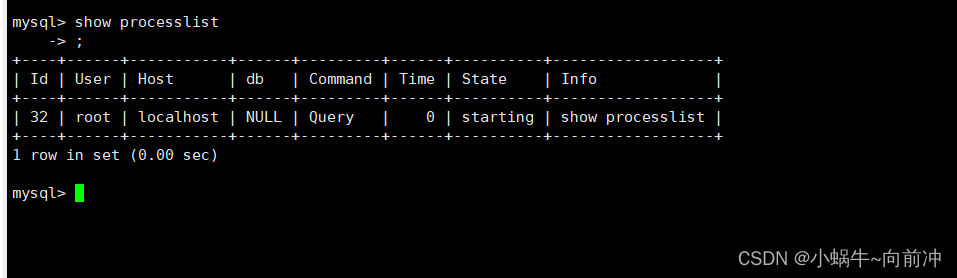
可以告诉我们当前有哪些用户连接到我们的MySQL,如果查出某个用户不是你正常登陆的,很有可能你 的数据库被人入侵了。以后大家发现自己数据库比较慢时,可以用这个指令来查看数据库连接情况
版权归原作者 小蜗牛~向前冲 所有, 如有侵权,请联系我们删除。