
1:hello world体验

最直接的方式,P端发送一个消息到一个指定的queue,中间不需要任何exchange
规则。C端按queue方式进行消费。
关键代码:(其实关键的区别也就是几个声明上的不同。)
producer:
channel.queueDeclare(QUEUE_NAME,false,false,false,null);
channel.basicPublish("", QUEUE_NAME, null, message.getBytes("UTF-8"));
consumer:
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
2.Work queues 工作序列
这就是kafka同一groupId的消息分发模式
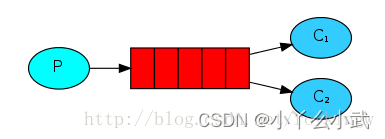
Producer消息发送给queue,服务器根据负载方案决定把消息发给一个指定的
Consumer处理。
工作任务模式,领导部署一个任务,由下面的一个员工来处理。
producer:
channel.queueDeclare(TASK_QUEUE_NAME, true, false, false, null);
//任务一般是不能因为消息中间件的服务而被耽误的,所以durable设置成了true,这样,
//即使rabbitMQ服务断了,这个消息也不会消失
channel.basicPublish("",
TASK_QUEUE_NAME,MessageProperties.PERSISTENT_TEXT_PLAIN,
message.getBytes("UTF-8"));
consumer:
channel.queueDeclare(TASK_QUEUE_NAME, true, false, false, null);
channel.basicQos(1);
channel.basicConsume(TASK_QUEUE_NAME, false, consumer);
这个模式应该是最常用的模式,也是官网讨论比较详细的一种模式,所以官网上也对这种模式做了重点讲述。
- 首先。Consumer端的autoAck字段设置的是false,这表示consumer在接收到消息后不会自动反馈服务器已消费了message,而要改在对message处理完成了之后,再调用channel.basicAck来通知服务器已经消费了该message.这样即使Consumer在执行message过程中出问题了,也不会造成message被忽略,因为没有ack的message会被服务器重新进行投递。 但是,这其中也要注意一个很常见的BUG,就是如果所有的consumer都忘记调用basicAck()了,就会造成message被不停的分发,也就造成不断的消耗系统资源。这也就是 Poison Message(毒消息)
- 其次,官方特意提到的message的持久性。关键的message不能因为服务出现问题而被忽略。还要注意,官方特意提到,所有的queue是不能被多次定义的。如果一个queue在开始时被声明为durable,那在后面再次声明这个queue时,即使声明为 not durable,那这个queue的结果也还是durable的。
- 然后,是中间件最为关键的分发方式。这里,RabbitMQ默认是采用的fair dispatch,也叫round-robin模式,就是把消息轮询,在所有consumer中轮流发送。这种方式,没有考虑消息处理的复杂度以及consumer的处理能力。而他们改进后的方案,是consumer可以向服务器声明一个prefetchCount,我把他叫做预处理能力值。channel.basicQos(prefetchCount);表示当前这个consumer可以同时处理几个message。这样服务器在进行消息发送前,会检查这个consumer当前正在处理中的message(message已经发送,但是未收到consumer的basicAck)有几个,如果超过了这个consumer节点的能力值,就不再往这个consumer发布。 这种模式,官方也指出还是有问题的,消息有可能全部阻塞,所有consumer节点都超过了能力值,那消息就阻塞在服务器上,这时需要自己及时发现这个问题,采取措施,比如增加consumer节点或者其他策略
Note about queue size If all the workers are busy, your queue can fill up. You will want to keep an eye on that, and maybe add more workers, or have some other strategy. - 另外 官网上没有深入提到的,就是还是没有考虑到message处理的复杂程度。有的message处理可能很简单,有的可能很复杂,现在还是将所有message的处理程度当成一样的。还是有缺陷的,但是目前也只看到dubbo里对单个服务有权重值的概念,涉及到了这个问题。
然后,是中间件最为关键的分发方式。这里,RabbitMQ默认是采用的fairdispatch,也叫round-robin模式,就是把消息轮询,在所有consumer中轮流发送。这种方式,没有考虑消息处理的复杂度以及consumer的处理能力。而他们改进后的方案,是consumer可以向服务器声明一个prefetchCount,我把他叫做预处理能力值。channel.basicQos(prefetchCount);表示当前这个
consumer可以同时处理几个message。这样服务器在进行消息发送前,会检查这个consumer当前正在处理中的message(message已经发送,但是未收到consumer的basicAck)有几个,如果超过了这个consumer节点的能力值,就不再往这个consumer发布。这种模式,官方也指出还是有问题的,消息有可能全部阻塞,所有consumer节点都超过了能力值,那消息就阻塞在服务器上,这时需要自己及时发现这个问题,采取措施,比如增加consumer节点或者其他策略。
3:Publish/Subscribe 订阅 发布 机制
type为fanout 的exchange:
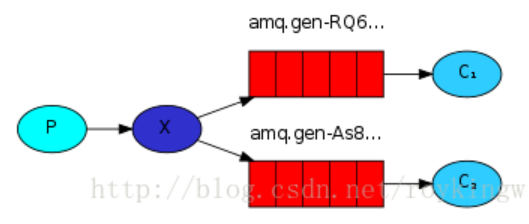
这个机制是对上面的一种补充。也就是把preducer与Consumer进行进一步的解耦。producer只负责发送消息,至于消息进入哪个queue,由exchange来分配。如上图,就是把producer发送的消息,交由exchange同时发送到两个queue里,然后由不同的Consumer去进行消费。
关键代码 ===》 producer: //只负责往exchange里发消息,后面的事情不管。
channel.exchangeDeclare(EXCHANGE_NAME, "fanout");
channel.basicPublish(EXCHANGE_NAME, "", null, message.getBytes("UTF-8"));
receiver: //将消费的目标队列绑定到exchange上。
channel.exchangeDeclare(EXCHANGE_NAME, "fanout");
String queueName = channel.queueDeclare().getQueue();
channel.queueBind(queueName, EXCHANGE_NAME, "");
关键处就是type为”fanout” 的exchange,这种类型的exchange只负责往所有已绑定的队列上发送消息。
4:Routing 基于内容的路由
type为”direct” 的exchange
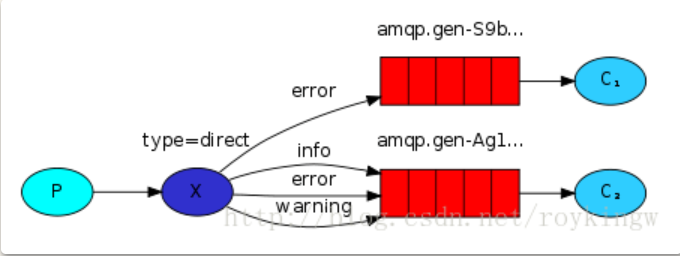
这种模式一看图就清晰了。 在上一章 exchange 往所有队列发送消息的基础上,增加一个路由配置,指定exchange如何将不同类别的消息分发到不同的queue上。
关键代码===> Producer:
channel.exchangeDeclare(EXCHANGE_NAME, "direct");
channel.basicPublish(EXCHANGE_NAME, routingKey, null, message.getBytes("UTF-8"));12
Receiver:
channel.exchangeDeclare(EXCHANGE_NAME, "direct");
channel.queueBind(queueName, EXCHANGE_NAME, routingKey1);
channel.queueBind(queueName, EXCHANGE_NAME, routingKey2);
channel.basicConsume(queueName, true, consumer);1234
5:Topics 话题
type为"topic" 的exchange
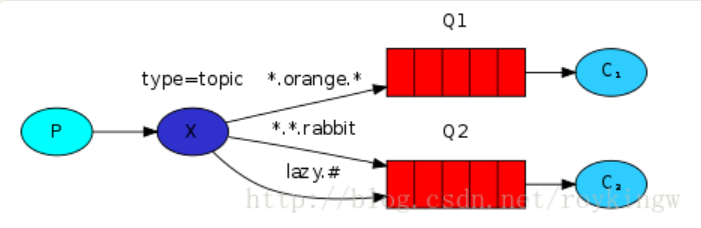
这个模式也就在上一个模式的基础上,对routingKey进行了模糊匹配单词之间用,隔开,* 代表一个具体的单词。# 代表0个或多个单词。
关键代码===> Producer:
channel.exchangeDeclare(EXCHANGE_NAME, "topic");
channel.basicPublish(EXCHANGE_NAME, routingKey, null, message.getBytes("UTF-8"));12
Receiver:
channel.exchangeDeclare(EXCHANGE_NAME, "topic");
channel.queueBind(queueName, EXCHANGE_NAME, routingKey1);
channel.queueBind(queueName, EXCHANGE_NAME, routingKey2);
channel.basicConsume(queueName, true, consumer);1234
6:RPC 远程调用
远程调用是同步阻塞的调用远程服务并获取结果。
RPC远程调用机制其实并不是消息中间件的处理强项。毕竟消息队列机制很大程度上来说就是为了缓冲同步RPC调用造成的瞬间高峰。而RabbitMQ的同步调用示例,看着也确实怪怪的。并且,RPC远程调用的场景,也有太多可替代的技术会比用消息中间件处理得更优雅,更流畅。
A note on RPC
Although RPC is a pretty common pattern in computing, it’s often criticised. The problems arise when a programmer is not aware whether a function call is local or if it’s a slow RPC. Confusions like that result in an unpredictable system and adds unnecessary complexity to debugging. Instead of simplifying software, misused RPC can result in unmaintainable spaghetti code.
Bearing that in mind, consider the following advice:
● Make sure it’s obvious which function call is local and which is remote.
● Document your system. Make the dependencies between components clear.
● Handle error cases. How should the client react when the RPC server is down for a long time?
When in doubt avoid RPC. If you can, you should use an asynchronous pipeline - instead of RPC-like blocking, results are asynchronously pushed to a next computation stage.
官网上这一大堆说明,其实我觉得就是表明,叫你不要用消息中间件来做RPC。所以关于这个RPC调用功能,就不再多做解释了。代码实现可以参见官网,或者配套的示例代码。
7:Publisher Confirms 发送者消息确认
RabbitMQ的消息可靠性是非常高的,但是他以往的机制都是保证消息发送到了MQ之后,可以推送到消费者消费,不会丢失消息。但是发送者发送消息是否成功是没有保证的。我们可以回顾下,发送者发送消息的基础API:Producer.basicPublish方法是没有返回值的,也就是说,一次发送消息是否成功,应用是不知道的,这在业务上就容易造成消息丢失。而这个模块就是通过给发送者提供一些确认机制,来保证这个消息发送的过程是成功的。
如果了解了这个机制就会发现,这个消息确认机制就是跟RocketMQ的事务消息机制差不多的。而对于这个机制,RocketMQ的支持明显更优雅。
发送者确认模式默认是不开启的,所以如果需要开启发送者确认模式,需要手动在channel中进行声明。
channel.confirmSelect();
在官网的示例中,重点解释了三种策略:
1、发布单条消息
即发布一条消息就确认一条消息。核心代码:
for (int i = 0; i < MESSAGE_COUNT; i++) {
String body = String.valueOf(i);
channel.basicPublish("", queue, null, body.getBytes());
channel.waitForConfirmsOrDie(5_000);
}
channel.waitForConfirmsOrDie(5_000);这个方法就会在channel端等待RabbitMQ给出一个响应,用来表明这个消息已经正确发送到了RabbitMQ服务端。但是要注意,这个方法会同步阻塞channel,在等待确认期间,channel将不能再继续发送消息,也就是说会明显降低集群的发送速度即吞吐量。
官方说明了,其实channel底层是异步工作的,会将channel阻塞住,然后异步等待服务端发送一个确认消息,才解除阻塞。但是我们在使用时,可以把他当作一个同步工具来看待。
然后如果到了超时时间,还没有收到服务端的确认机制,那就会抛出异常。然后通常处理这个异常的方式是记录错误日志或者尝试重发消息,但是尝试重发时一定要注意不要使程序陷入死循环。
2、发送批量消息
之前单条确认的机制会对系统的吞吐量造成很大的影响,所以稍微中和一点的方式就是发送一批消息后,再一起确认。
核心代码:
int batchSize = 100;
int outstandingMessageCount = 0;
long start = System.nanoTime();
for (int i = 0; i < MESSAGE_COUNT; i++) {
String body = String.valueOf(i);
ch.basicPublish("", queue, null, body.getBytes());
outstandingMessageCount++;
if (outstandingMessageCount == batchSize) {
ch.waitForConfirmsOrDie(5_000);
outstandingMessageCount = 0;
}
}
if (outstandingMessageCount > 0) {
ch.waitForConfirmsOrDie(5_000);
}
这种方式可以稍微缓解下发送者确认模式对吞吐量的影响。但是也有个固有的问题就是,当确认出现异常时,发送者只能知道是这一批消息出问题了, 而无法确认具体是哪一条消息出了问题。所以接下来就需要增加一个机制能够具体对每一条发送出错的消息进行处理。
3、异步确认消息
实现的方式也比较简单,Producer在channel中注册监听器来对消息进行确认。核心代码就是一个:
channel.addConfirmListener(ConfirmCallback var1, ConfirmCallback var2);
按说监听只要注册一个就可以了,那为什么这里要注册两个呢?如果对照下RocketMQ的事务消息机制,这就很容易理解了。发送者在发送完消息后,就会执行第一个监听器callback1,然后等服务端发过来的反馈后,再执行第二个监听器callback2。
然后关于这个ConfirmCallback,这是个监听器接口,里面只有一个方法: void handle(long sequenceNumber, boolean multiple) throws IOException; 这方法中的两个参数,
- sequenceNumer:这个是一个唯一的序列号,代表一个唯一的消息。在RabbitMQ中,他的消息体只是一个二进制数组,并不像RocketMQ一样有一个封装的对象,所以默认消息是没有序列号的。而RabbitMQ提供了一个方法
int sequenceNumber = channel.getNextPublishSeqNo());来生成一个全局递增的序列号。然后应用程序需要自己来将这个序列号与消息对应起来。没错!是的!需要客户端自己去做对应! - multiple:这个是一个Boolean型的参数。如果是false,就表示这一次只确认了当前一条消息。如果是true,就表示RabbitMQ这一次确认了一批消息,在sequenceNumber之前的所有消息都已经确认完成了。
对比下RocketMQ的事务消息机制,有没有觉得很熟悉,但是又很别扭?当然,考虑到这个对于RabbitMQ来说还是个新鲜玩意,所以有理由相信这个机制在未来会越来越完善。
版权归原作者 小丫么小武 所有, 如有侵权,请联系我们删除。