
系统模型
ZNode:ZK有着类似Unix文件系统的视图结构,但并没有引入传统文件系统中的目录和文件的概念,而是称为数据节点-ZNode。ZNode是ZK中数据的最小单元,ZNode构成了一个层次化的命名空间,称之为树。
事务ID: 事务是对物理和抽象的应用状态上的操作集合。在ZK中,事务是指能够改变ZK服务器状态的操作,包括数据节点创建与删除,数据节点内容更新和客户端会话创建与失效等操作。每一个事务操作的全局唯一ID称为ZXID,ZXID是一个64位数字,通过ZXID可以间接识别出ZK操作的全局顺序。
ZNode节点特性
ZNode节点类型
持久节点;
持久顺序节点:每个父节点会为一级子节点维护一份顺序,记录每个子节点创建的先后顺序,节点创建时ZK会为其加上一个数字后缀作为节点名。该数字后缀的上限是Integer.MAX_VALUE;
临时节点:客户端会话失效时会自动消失(不是TCP连接断开时)ZK规定了临时节点下不能创建子节点,临时节点只能作为叶子节点;
临时顺序节点;
ZNode 节点内容
除了保存了data还保存了Stat节点状态信息。具体字段有:
- czxid:Created ZXID 数据节点被创建时的ZXID
- mzxid:Modified ZXID 节点最后一次被更新的ZXID
- ctime:Created Time 节点创建时间
- mtime:Modified Time 节点最后一次被更新的时间
- version:数据节点版本号
- cversion:子节点的版本号
- aversion:节点的ACL版本号
- ephemeralOwner:创建临时节点会话的sessionID,对于持久节点是0
- dataLength:数据内容的长度
- numChildren:当前节点的子节点个数
ZK通过ZNode的version属性保证分布式数据的原子性操作,ZNode的版本信息有version、cversion、aversion,表示对节点数据内容、子节点列表、节点ACL信息的修改次数,节点刚创建完毕时的version=0,节点更新时即使value相同也会导致version+1
ZK的Watcher机制
包括客户端线程、客户端WatchManager、ZooKeeper服务器三部分。
Watcher接口
Watcher事件的分类
KeeperStateEventType触发条件说明SyncConnected(3)None(-1)客户端与服务器成功建立会话此时客户端和服务器处于连接状态NodeCreated(1)Watcher监听的数据节点被创建NodeDeletedWatcher监听的数据节点被删除NodeDataChanged(3)节点data被修改NodeChildrenChanged(4)节点的子节点列表发生变更(子节点data变更不算)Disconnected(0)None(-1)客户端与ZK服务器断开连接Expire(-112)None(-1)会话超时客户端会话失效,同时收到SessionExpiredExceptionAuthFailed(4)None(-1)造成此结果的原因有: addAuthInfo时使用了错误的schema(第一个参数) SASL权限检查失败通常客户端也会收到AuthFailedException
Watcher接口中的WatchedEvent与WatcherEvent的区别:
两者都是对一个服务端事件的封装,Watcher机制传递的Event事件中的信息很少,需要客户端主动再查询。
- WatchedEvent是Watcher接口void process(WatchedEvent event)方法的入参,内部包含3个属性:KeeperState、EventType、节点路径 path。WatchedEvent是一个逻辑事件,用于服务端和客户端程序执行过程中所需的逻辑对象
- org.apache.zookeeper.proto.WatcherEvent 实现了序列化接口,可以用于网络传输。服务端通过getWrapper方法将WatchedEvent事件包装成一个可序列化的WatcherEvent事件,以便通过网络传输到客户端,客户端接收到后再还原成WatchedEvent事件,传递给process方法处理。
Watcher机制的流程
客户端注册Watcher
ZooKeeper客户端构造过程中可以传入一个Watcher,将作为整个会话期间的默认Watcher一直保存在ZKWatchManager的defaultWatcher中。(其他注册非默认watcher的API有getData、getChildren、exists)
getData注册Watcher入参有boolean和Watcher两种,前者表示使用new ZooKeeper时传入的默认Watcher,后者则是指定一个自定义Watcher。 注册Watcher首先会封装注册信息到WatchRegistration对象,保存节点路径和Watcher的对应关系。在ClientCnxn中会将WatchRegistration封装成Packet对象(ClientCnxn#submitRequest),放入发送队列中。Packet可以看做最小的通信协议单元,用于客户端与服务端之间的网络传输。Watcher注册结果通过 ClientCnxn.SendThread#readResponse 方法进行接收,内部调用的ClientCnxn#finishPacket 会从Packet中取出对应Watcher并注册到ZKWatchManager中。注册方法是 ZooKeeper.WatchRegistration#register,会将新的Watcher放入一个Map<String,Set<Watcher>>中,这个map的Key是节点的path,value set的元素类型是DataWatchRegistration。
客户端每调用一次getData就注册一个Watcher,这些Watcher实例会随着客户端请求发送到服务端吗?
不会,WatchRegistration封装到了Packet对象中,在ClientCnxn.Packet#createBB()方法中可见,客户端请求时仅序列化了Packet的 header和request两个属性到底层字节数组进行网络传输。
服务端如何处理Watcher
服务端接收并存储Watcher:
- 服务端在收到客户端的请求 FinalRequestProcessor.processRequest() 中会判断当前请求是否需要注册Watcher。 代码位置 case multi: --> FinalRequestProcessor#handleGetDataRequest:通过 GetDataRequest#getWatch 返回true确定将 ServerCnxn 传入getData方法,ServerCnxn implements Stats, Watcher 是ZK客户端与服务器之间的连接接口,代表了一个客户端与服务器的连接,默认实现是 NIOServerCnxn,3.4.0版引入了基于Netty的实现:NettyServerCnxn。
- WatchManager是ZK服务端Watcher的管理者,数据节点的节点路径和ServerCnxn最终会被存储在WatchManager的watchTable和watch2Paths中,这两个字段都是Map,存储了String path与Watcher 的正反多对多对应关系
DataTree#setData()方法中在synchronized同步代码块中对节点的data、stat数据进行了修改,最后调用了WatchManager#triggerWatch()方法触发数据节点data变更时的NodeDataChanged事件。
WatchManager#triggerWatch()方法中的一些逻辑解释了ZK Watcher需要反复注册的原因:
- 方法入参EventType指定触发事件的类型:data变更还是childNodes变更等。
- 将KeeperState、EventType、Path new 到WatchedEvent实例中
- 根据Path路径从watchTable中找到所有对应的Watcher,为空continue,不为空时再iterator.remove掉,这样Watcher触发一次就失效了
- 从Map中找到的所有Watcher执行一遍其process方法,服务端Watcher的实际类型是ServerCnxn,其process方法(NIOServerCnxn#process)内容:- 创建ReplyHeader,设置zxid=-1表示当前是一个通知- 调用WatchedEvent#getWrapper方法将WatchedEvent包装成WatcherEvent(类似BeanUtil#copyProperties),便于网络传输- 调用sendResponse方法向客户端发送通知
ZK借助当前客户端TCP连接的ServerCnxn对象实现对客户端的WatchedEvent传递,Watcher的回调和业务处理都在客户端执行。
客户端回调Watcher
ClientCnxn.SendThread#readResponse()方法中接收并处理服务端响应,以xid=-1(表示通知事件)为例:
- 调用WatcherEvent#deserialize方法对接收到的字节流进行反序列化,转换成WatcherEvent对象
- 处理chrootPath:如果客户端设置了chrootPath属性,需要修改反序列化得到的Event#path
- WatcherEvent 再转成 WatchedEvent
- 交给ClientCnxn中的EventThread处理,放入队列,等待下一轮询周期中进行Watchcer回调
客户端回调Watcher
- 处理逻辑位于ClientCnxn.SendThread#readResponse(ByteBuffer incomingBuffer),转成WatchedEvent最终会交给ClientCnxn.EventThread#queueEvent 处理。
- queueEvent方法通过ZKWatchManager#materialize方法(入参 KeeperState、EventType、String path)从ZKWatchManager中取出所有相关Watcher。
- 在对于EventType=NodeDataChanged或NodeCreated的处理中,调用了addTo方法,先通过Map#remove API从 注册的dataWatches和existWatches中移除指定path的Set并将其返回,放入结果result中进行返回。这里的操作说明客户端的Wathcer机制同样是一次性的。
- queueEvent会将取出的Watcher集合放入EventThread的LinkedBlockingQueue waitingEvents字段中,其run方法中对LinkBlockingQueue进行while true式的不断take传递给ClientCnxn.EventThread#processEvent处理:- 判断出类型是WatcherSetEventPair,取出Set字段for循环式调用其process方法,这个process方法就是用户处理业务逻辑的回调方法了综上分析,ZK的Watcher具有以下特性:- 一次性:这样可以减轻服务端的通知压力。如果一个Watcher一直有效,对于频繁更新的节点,服务端会不断向客户端发送事件通知,对于服务端的网络和性能都是一个挑战。- 客户端串行执行:客户端取出Set时逐个(串行)同步回调,这样可以保证顺序。但要注意Wathcer处理逻辑的异常捕获- Wathcer注册轻量化:客户端注册Watcher不会将Watcher实例传递到Server端,仅仅在客户端请求中使用boolean类型属性标记是否Watch,服务端也仅仅只保存了当前连接的ServerCnxn对象。- Wathcer通知轻量化:WatchedEvent是ZK整个Watcher通知机制的最小通知单元,该对象只有3个字段:KeeperStat、EventType、String path,只会告诉客户端发生了事件,而事件的具体内容需要客户端发起查询请求。
ACL:保障数据安全
ZooKeeper内部存储的分布式系统的状态信息需要保障数据安全,这需要借助ACL权限控制机制。
在Unix\Linux文件系统中广泛使用的权限控制方式是UGO(User\Group\Others)权限控制机制,这是一种粗粒度的文件系统权限控制模式。ACL访问控制列表可以实现更细粒度的权限控制,Linux 2.6内核已开始支持这一特性。
ZK的ACL机制通常使用
schema:id:permission
来标识一个有效的ACL信息:
- 权限模式 Schema:有四种权限模式:- IP(IPAuthenticationProvider):如 ip:192.168.1.10,或按网段配置 ip:192.168.1.1/24 表示 192.168.0.* 这个IP段- Digest(DigestAuthenticationProvider):最常用的权限控制模式,以 username:password 的形式,ZK内部通过DigestAuthenticationProvider.generateDigest static 方法进行编码- World:即 world:anyone 特殊的Digest模式,节点对所有用户开放- Super:超级用户可以对ZK上的任意数据节点进行任何操作
- 授权对象 ID:上述每种Schema对应的ID分别是 192.168.1.10、192.168.1.1/24、username:BASE64(SHA-1(username:password))、anyone
- 权限Permission:通过权限检查后可以被允许执行的操作:CREATE、DELETE、READ、WRITE、ADMIN-数据节点的管理员权限,允许授权对象对该数据节点进行ACL相关的设置操作自定义权限控制 Pluggable ZooKeeper Authentication:需要用户实现 AuthenticationProvider 接口,通过配置ZK启动参数
-Dzookeeper.authProvider.1=com.zkbook.CustomAuthenticationProvider或 通过配置文件 zoo.cfg 添加authProvider.1=com.zklearn.CustomAuthenticationProvider。对于权限控制器的注册,ZK采用了延迟加载的策略,只有在第一次处理包含权限控制的客户端请求时,才会进行权限控制器的初始化。ZK会将所有的权限控制器注册到ProviderRegistry中,逻辑位于 ProviderRegistry#initialize 方法中,对 zookeeper.authProvider. 这个属性进行了解析使用zkCli进行ACL操作ZooKeeper ZkCli 官方文档
# 创建节点时指定ACL
# -e 临时节点 -s sequential节点,digest固定开头,crwd表示权限,支持 create read write delete admin
> create -e /zklearn/c4 data_content digest:userJ:passJ:crwd
Created /zklearn/c4
# 查看节点权限
> getAcl /zklearn/c3
'world,'anyone
: cdrwa
# 修改节点权限
# 已设置acl的path再setAcl就不行了,需要开启super权限
> setAcl path acl
序列化与协议
Jute序列化反序列化
OutputArchive和InputArchive分别是Jute底层的序列化器和反序列化器的接口定义,最新的实现有 BinaryXXputArchive、CsvXXputArchive、XmlXXputArchive。无论哪种实现,都是基于OutputStream和InputStream进行操作。
通信协议
ZK基于TCP/IP协议实现了自己的通信协议,进行客户端与服务端、服务端与服务端的网络通信。
ZK请求的数据包
以 获取节点数据请求 GetDataRequest 为例
请求头 RequestHeader
/*
zk中的许多类是jute proto文件定义的,通过JavaGenerator生成的源码
这些proto为了正反序列化以便网络传输,需要实现Jute的Record接口
同时这些类的注解里会有这样一行 File generated by hadoop record compiler. Do not edit.
*/
public class RequestHeader implements Record {
private int xid;// 记录客户端请求发起的先后序号,确保单个客户端请求的响应顺序
private int type;// 请求的操作类型,定义在ZooDefs.OpCode中:创建节点 OpCode.create-1;删除节点 OpCode.delete-2;获取节点数据 OpCode.getDate-4;
请求体 Request
// ConnectRequest 会话创建
public class ConnectRequest implements Record {
private int protocolVersion;//协议版本号
private long lastZxidSeen;//最近一次收到的服务器ZXID
private int timeOut;// 会话超时时间
private long sessionId;// 会话标识
private byte[] passwd;// 会话密码
// GetDataRequest 获取节点数据
public class GetDataRequest implements Record {
private String path;//
private boolean watch;//是否注册 Watcher
// SetDataRequest 更新节点数据
public class SetDataRequest implements Record {
private String path;// 数据节点的节点路径
private byte[] data;//数据内容
private int version;//节点数据的期望版本号
请求体的抓包分析
使用WireShark嗅探GetDataRequest产生的TCP包(十六进制字节数组)
十六进制位协议部分数值或字符串00,00,00,1d0-3位:len 整个数据包长度长度2900,00,00,014-7位:xid 客户端请求的发起序号100,00,00,048-11位:type 客户端请求类型4 OpCode.getData00,00,00,1012-15位:len 节点路径的长度16 节点路径长度转换成十六进制是16位2f,24,37,5f, 32,5f,34,2f, 67,65,74,5f, 64,61,74,6116-31位:path 节点路径Hex编码0132位:是否注册Watcher1-是
响应
GetDataResponse响应完整协议定义
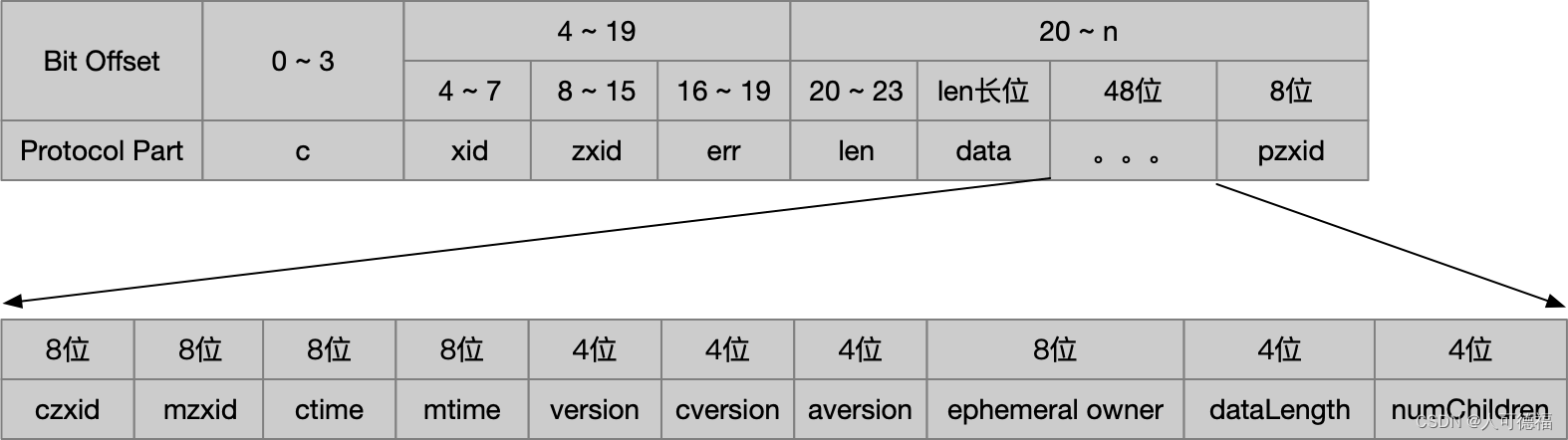
响应头 ReplyHeader
public class ReplyHeader implements Record {
private int xid; // 请求时传过来的xid会在响应中原样返回
private long zxid; // zxid 代表ZK服务器上当前最新事务ID
private int err; // 错误码:Code.OK-0,NONODE-101,NOAUTH-102,定义在KeeperException.Code中
响应体Response
//会话创建
public class ConnectResponse implements Record {
private int protocolVersion;
private int timeOut;
private long sessionId;
private byte[] passwd;
// 获取节点数据
public class GetDataResponse implements Record {
private byte[] data;
private org.apache.zookeeper.data.Stat stat;
// 更新节点数据
public class SetDataResponse implements Record {
private org.apache.zookeeper.data.Stat stat;
GetDataResponse 协议定义
十六进制位协议解释当前值00,00,00,630-3位:len 整个响应的数据包长度9900,00,00,054-7位:xid 客户端请求序号5 本次请求所属会话创建后的第5次请求00,00,00,00, 00,00,00,048-15位: zxid 当前服务器处理过的最大ZXID400,00,00,0016-19位:err 错误码0-Codes.OK00,00,00,0b20-23位:len 节点数据内容的长度11 后面11位是数据内容的字节数组xxx24-34位:data 节点数据内容Hex编码00,00,00,00, 00,00,00,0435-42位:czxid 创建该节点时的ZXID400,00,00,00, 00,00,00,0443-50位:mzxid 最后一次访问该数据节点时的ZXID400,00,01,43,67,bd,0e,0851-58位:ctime 数据节点的创建时间unix_timestamp 138901487975200,00,01,43,67,bd,0e,0859-66位:mtime 数据节点最后一次变更的时间00,00,00,0067-70位:version 数据节点内容的版本号000,00,00,0071-74位:cversion 数据节点的子版本号000,00,00,0075-78位:aversion 数据节点的ACL变更版本号000,00,00,00,00,00,00,0079-86位:ephemeralOwner 如果是临时节点,则记录创建该节点的sessionID,否则置00 (该节点是永久节点)00,00,00,0b87-90位:dataLength 数据节点的数据内容长度1100,00,00,0091-94位:numChildren 数据节点的子节点个数000,00,00,00,00,00,00,0495-102位:pzxid 最后一次对子节点列表变更的ZXID4
ZK客户端
ZK客户端的组成:ZooKeeper实例-客户端入口,HostProvider - 客户端地址列表管理器,ClientCnxn-客户端核心线程,内部包含SendThread和EventThread两个线程。前者是一个IO线程,负责ZooKeeper客户端和服务器端间的网络IO通信,后者是一个事件线程,负责对服务端事件进行处理。
ZK会话的创建过程
初始化阶段
- 初始化ZK对象,通过调用ZooKeeper的构造方法实例化,在此过程中会创建客户端Watcher管理器 ClientWatcherManager
- 设置会话默认Watcher:如果在构造方法中传入了一个Watcher对象,客户端会将这个对象作为默认Watcher保存在ClientWatcherManager中
- 构造ZooKeeper服务器地址列表管理器 HostProvider:对于构造函数传入的服务器地址,客户端会将其存放在服务器地址列表管理器HostProvider中
- 创建并初始化客户端网络连接器 ClientCnxn:ClientCnxn连接器的底层IO处理器是ClientCnxnSocket。另外还会初始化客户端两个核心队列 outgoingQueue 和 pendingQueue 分别作为客户端的请求发送队列和服务端响应的等待队列。
- 初始化SendThread和EventThread:前者管理客户端与服务端之间的所有网络IO,后者用于客户端的事件处理
会话创建阶段
- 启动SendThread和EventThread
- 获取一个服务器地址:开始创建TCP连接前,SendThread从HostProvider中随机选择一个地址,调用ClientCnxnSocket 创建与ZK服务器之间的TCP连接
- 创建TCP长连接
- 构造ConnectRequest请求:SendThread根据当前客户端的实际设置,构造出一个ConnectRequest请求,代表了客户端视图与服务端创建一个会话。同时ZK客户端会将请求包装成IO层的Packet对象放入请求发送队列outgoingQueue中
- 发送请求:ClientCnxnSocket从outgoingQueue中取出一个待发送的Pocket对象序列化成ByteBuffer发送到服务端
响应处理阶段
- 接收并处理服务端响应:ClientCnxnSocket接收到服务端的响应后,会首先判断当前客户端状态是否是已初始化,才进行反序列化,得到ConnectResponse对象,从中获取ZK服务端分配的sessionID
- 连接成功:通知SendThread进一步对客户端进行会话参数的设置:readTimeout\connectTimeout,更新客户端状态。通知HostProvider当前成功连接的服务器地址
- 生成事件 SyncConnected - None:为了让上层应用感知到会话的成功创建,SendThread会生成该事件传递给EventThread,通知会话创建成功
- 查询Watcher:EventThread线程收到事件后,会从ClientWatchManager中获取对应Watcher,针对SyncConnected-None事件找到默认的Wathcer,放入EventThread的waitingEvents队列中
- 处理事件:EventThread不断从waitingEvents队列中取出待处理的Watcher对象,调用process方法触发Watcher
connectString解析
connectString 形如 192.168.0.1:2181,192.168.0.2:2181,192.168.0.3:2181,ZK客户端允许将服务器所有地址配置在字符上,ZK客户端在连接服务器的过程中是如何从服务器列表中选择机器的?是顺序?还是随机?
org.apache.zookeeper.client.ConnectStringParser 中的构造方法对connectString进行的处理有:解析chrootPath + 保存服务器地址列表到 ArrayList<InetSocketAddress> serverAddresses
chroot 客户端命名空间
ZK3.2.0 之后的版本中添加了该特性,connectString 可 设置为 192.168.0.1:2181,192.168.0.2:2181/apps/domainName,将解析出chroot=/apps/domainName,这样客户端的所有操作都会限制在这个命名空间下
ZooKeeper.java
private static HostProvider createDefaultHostProvider(String connectString) {
return new StaticHostProvider(new ConnectStringParser(connectString).getServerAddresses());
}
解析的结果会返回 地址列表管理器 StaticHostProvider 的构造方法中
HostProvider
HostProvider 提供了客户端连接所需的host,每一个实现该接口的类需要确保下述几点:
- next() 方法必须有效的InetSocketAddress,这样迭代器能一直运行下去。必须返回解析过的InetSocketAddress实例
- size() 方法不能返回0
public interface HostProvider {
//当前服务器地址列表的个数,不能返回0
int size();
// 获取下一个将要连接的InetSocketAddress,spinDelay 表示所有地址都尝试过后的等待时间
InetSocketAddress next(long spinDelay);
//连接成功后的回调方法
void onConnected();
//更新服务器列表,返回是否需要改变连接用于负载均衡
boolean updateServerList(Collection<InetSocketAddress> serverAddresses, InetSocketAddress currentHost);
}
解析服务器地址:StaticHostProvider会解析服务器地址放入serverAddress 集合中,同时使用Collections#shuffle方法将服务器地址列表进行随机打散。
获取可用的服务器地址:StaticHostProvider#next() 方法中将随机排序后的服务器地址列表拼成一个环形循环队列,该过程是一次性的。
HostProvider的实现:自动从配置文件中读取服务器地址列表、动态变更的地址列表管理器(定时从配置管理中心上解析ZK服务器地址)、实现服务调用时同机房优先的策略
ClientCnxn 网络IO
ClientCnxn维护客户端与服务器之间的网络连接并进行通信
Packet是ClientCnxn的内部类,定义:
static class Packet {
RequestHeader requestHeader;
ReplyHeader replyHeader;
Record request;
Record response;
ByteBuffer bb;
String clientPath;
//server视角下的path,chroot不同
String serverPath;
boolean finished;
AsyncCallback cb;
Object ctx;
WatchRegistration watchRegistration;
public boolean readOnly;
WatchDeregistration watchDeregistration;
//并不是Packet中的所有字段都进行网络传输,在createBB方法中定义了用于网络传输的ByteBuffer bb字段的生成逻辑
//里面只用到了RequestHeader requestHeader,Record request,boolean readOnly 3个字段
public void createBB() {}
}
ClientCnxn的两个核心队列(都是Packet队列):
- outgoingQueue:客户端的请求发送队列,存储要发送到服务端的Packet集合
- pendingQueue:服务端响应的等待队列,存储已经从客户端发送到服务端但需要等待服务端响应的Packer集合
ClientCnxnSocket
ZK3.4之后ClientCnxnSocket从ClientCnxn中提取了出来,便于对底层Socket进行扩展(如使用Netty实现)
通过系统变量配合ClientCnxnSocket实现类的全类名:
-Dzookeeper.clientCnxnSocket=org.apache.zookeeper.ClientCnxnSocketNIO
ClientCnxnSocketNIO是ClientCnxnSocket的Java NIO原生实现
会话Session
【分布式】Zookeeper会话 - leesf - 博客园
会话状态有:CONNECTING CONNECTED RECONNECTING RECONNECTED CLOSE
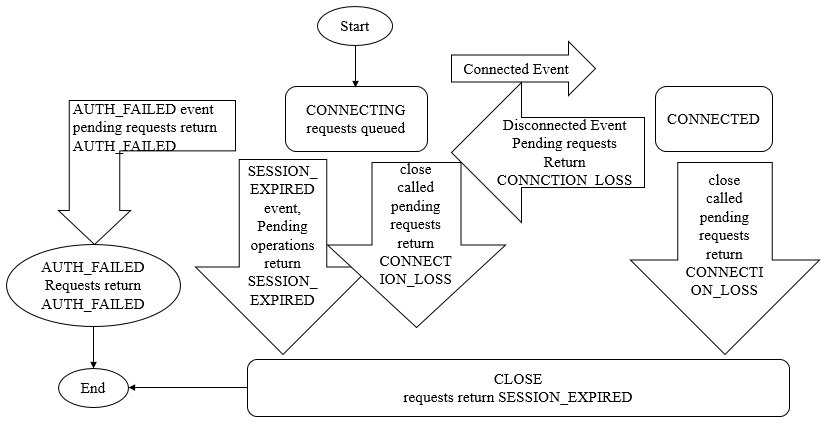
Session是ZK中的会话实体,代表一个客户端会话,包含以下4个基本属性:
- sessionID 唯一标识一个会话,每次客户端创建新会话时,ZK会为其分配一个全局唯一的sessionID
- timeout 会话超时时间,客户端构造ZK实例时会传入sessionTImeout指定会话的超时时间,客户端向服务器发送这个超时时间后,服务器会根据自己的超时限定确定会话的超时时间
- tickTime 下次会话超时时间点,这个参数用于会话管理的分桶策略执行。TickTIme是一个13位的long型(unix_timestamp)
- isClosing 服务端检测到一个会话失效后会标记其isClosing=true,这样就不再处理来自该会话的新请求了
sessionID的生成原理
代码位于 SessionTrackerImpl#initializeNextSession
//最终返回的sessionID:高8位是传入的id,剩下的56位最后16位被置零了,前面的40位是最高位截掉的timestamp(去掉数字1)
public static long initializeNextSessionId(long id) {
long nextSid;
// nanoTime/10^6 就是 currentTimeMillis 13位long型,long型占空间8B,共64位
//如 1657349408123 对应 44 位的二进制是 00011000000111110001101110010000010101111011
//左移24位后再右移8位后的结果:00000000(-8位)1000000111110001101110010000010101111011(16位-)0000000000000000
//注意这个右移8位是无符号右移,防止unixtimes第5位是1带来的负数问题
nextSid = (System.nanoTime() / 1000000 << 24) >>> 8;
//添加机器标识 sid 正好补在前面腾出的8位中
nextSid = nextSid | (id << 56);
if (nextSid == EphemeralType.CONTAINER_EPHEMERAL_OWNER) {
++nextSid; // this is an unlikely edge case, but check it just in case
}
return nextSid;
}
左移24位可以将高位的1去掉(unixTimestamp转二进制的44位数字开头总是0001),防止负数(负数右移8位后最高位的1不变),sid不能明确得出
SessionTracker
ZK服务端的会话管理器,负责会话的创建、管理和清理,使用3个数据结构管理Session:
- sessionsById:ConcurrentHashMap<Long, SessionImpl>类型,根据sessionID管理Session实体
- sessionsWithTimeout:ConcurrentMap<Long, Integer> 根据sessionID管理会话的超时时间,定期被持久化到快照文件中
- sessionSets:ExpiryQueue<SessionImpl> sessionExpiryQueue 服务于会话管理和超时检查,分桶策略会用到
Session管理 - 分桶策略
ZK的会话管理主要由SessionTracker负责,其采用了分桶策略:将理论上可以在同一时间点超时的会话放在同一区块中,便于进行会话的隔离处理和同一区块的统一管理。

对于一个会话的超时时间理论上就是客户端设置的超时时间之后,即图中的 ExpirationTime = CurrentTime + sessionTimeout(客户端进行设置),这样到达这个ExpirationTime检查各会话是否真的需要置超时状态
但是ZK服务端检查各区块的会话是否超时是有周期的,如每隔 ExpirationInterval 进行检查,这样实际的 ExpirationTime 是在原数值之后的最近一个周期上进行检查,这样
ExpirationTime_Adjust = ((CurrentTime + sessionTimeout) / ExpirationInterval + 1) * ExpirationInterval (单位均是ms)
如对于当前时间为4,,10 超时,检查周期为3,在15的时候才是第一个可能的超时时间。这样 ExpirationTime_Adjust 总是 ExpirationInterval 的整数倍。这样SessionTracker中的会话超时检查线程就可以在 ExpirationInterval 的整数倍的时间点上对会话进行批量清理(未及时移走的会话都是要被清理掉的,没有客户端触发会话激活)
会话激活
Leader服务器收到客户端的心跳消息PING后:
- 检查改会话是否是isClose
- 如果会话尚未关闭,则激活会话,计算出会话的下一次超时时间点 ExpirationTime_NEW
- 根据会话的旧超时时间点 ExpirationTime_Old 定位到会话所在的区块
- 迁移会话,将会话放入 ExpirationTime_NEW 对应的新区块中
触发会话激活的两种场景:
- 只要客户端向服务器发送请求(不论读/写)就会触发一次会话激活
- 客户端在sessionTimeout / 3 的时间间隔内没有向服务器发出任何请求,就会主动发起一次PING请求触发会话激活
会话清理的步骤
- 先将该会话的isClosing置为true,这样在会话清理期间再收到客户端的新请求就返回 Session_Expire,再标记会话状态为已关闭 - CLOSE
- 发起会话关闭 请求给 PrepRequestProcessor处理器进行处理
- 根据sessionID从内存数据库中找到对应的临时节点列表
- 将这些临时节点转换成 节点删除 请求,放入事务变更队列 outstandingChanges 中
- FinalRequestProcessor触发内存数据库,删除该会话对应的所有临时节点
- 节点删除后从SessionTracker中移除session(从sessionById sessionWithTimeout sessionExpiryQueue中移除对应session的信息)
- 从NIOServerCnxnFactory中找到会话对应的NIOServerCnxn进行关闭
重连机制
客户端与服务端网络连接断开时,ZK客户端会进行反复的重连
客户端经常看到的两种连接异常是:CONNECTION_LOSS 连接断开,SESSION_EXPIRE 会话过期;服务端可能看到的连接异常是SESSION_MOVED 会话转移
- CONNECTION_LOSS:客户端在发现连接断开时会逐个尝试连接 connectString 解析出的服务器地址,同时此时收到连接事件 None-Disconnected,同时抛出异常 KeeperException$ConnectionLossException,应用层应捕获住此异常并等待重连成功(收到None-SyncConnected事件)后进行重试
- SESSION_EXPIRE:通常发生在CONNECTION_LOSS,客户端重连成功后会话在服务端已过期被清理。应用层此时需要重新创建一个ZooKeeper实例进行初始化
- SESSION_MOVED:ZooKeeper在3.2.0版本后明确提出的概念,客户端 C 向服务端 S1发出的请求R1因网络抖动导致重连到S2,并重试请求R11,但后面R1成功到达S1,导致S1 S2 都执行了相同的请求。针对这一罕见场景,ZooKeeper提出的处理方案: 在处理客户端请求时检查此会话Owner是不是当前服务器,不是的话会抛出 SessionMovedException 异常,但C1因为已断开与S1的连接,看不到S1上的这个异常。在多个客户端使用相同的sessionId/pass连接不同服务端时才会看到这种异常
ZK服务端
ZK服务端架构
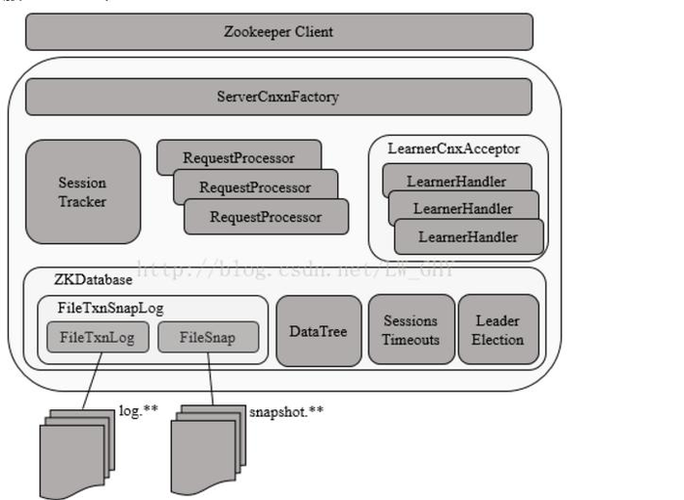
zookeeper学习笔记Sky_的博客-CSDN博客
单机版ZK服务器的启动流程
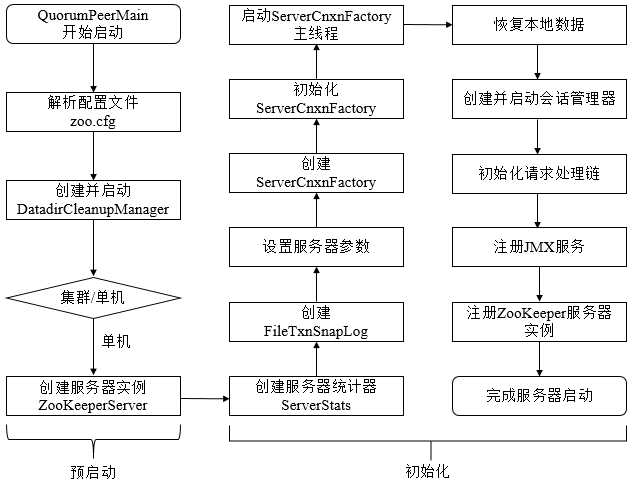
预启动
- 不论是单机还是集群模式,zkServer.cmd和zkServer.sh两个脚本中都配置了使用QuorumPeerMain 作为启动入口类
ZOOMAIN="org.apache.zookeeper.server.quorum.QuorumPeerMain" - 解析配置文件 zoo.cfg
- 在QuorumPeerMain#initializeAndRun方法中创建并启动了文件清理器 DatadirCleanupManager,包括对事物日志和快照数据文件的定时清理
- 根据zoo.cfg配置文件的解析判断当前是单机还是集群模式启动,单机模式使用ZooKeeperServerMain启动
- 创建ZooKeeperServer实例并进行初始化,包括连接器、内存数据库和请求处理器等组件的初始化
初始化
- 创建服务器统计器ServerStats,包含下述基本运行时信息:- packetsSent: 从服务启动或重置以来,服务端向客户端发送的响应包次数- packetsReceived: ... 服务端接收到的来自客户端的请求包次数- maxLatency/minLatency/totalLatency: 服务端请求处理的最大延时、最小延时、总延时- count: 服务端处理的客户端请求总次数
- 创建ZK数据管理器FileTxnSnapLog:FileTxnSnapLog是ZK上层服务器和底层数据存储之间的对接层,提供了一些列操作数据文件的接口,包括事务日志文件(TxnLog接口)和快照数据文件(SnapShot接口)。ZK根据zoo.cfg文件中解析出的快照数据目录dataDir和事务日志目录dataLogDir来创建FileTxnSnapLog。
- 设置服务端 tickTime 和 会话超时时间 限制
- 创建并初始化 ServerCnxnFactory , 通过属性 zookeeper.serverCnxnFactory 指定zookeeper使用 Java原生NIO还是Netty框架作为ZooKeeper服务端网络连接工厂
- 启动ServerCnxnFactory主线程(执行主逻辑所在的run方法)此时ZK的NIO服务器已经对外开放了端口,客户端可以访问到2181端口,但此时zk服务器还无法正常处理客户端请求
- 恢复本地数据:ZK启动时都会从本地快照文件和事务日志文件中进行数据恢复
- 创建并启动会话管理器SessionTracker,同时会设置 expirationInterval 计算 nextExpirationTime、sessionID ,初始化本地数据结构 sessionsWithTimeout(保存每个会话的超时时间)。之后ZK就会开始会话管理器的会话超时检查
- 初始化ZK的请求处理链,ZK服务端对于请求的初始方式是典型的责任链模式,单机版服务器的处理链主要包括:PrepRequestProcessor -> SyncRequestProcessor ->FinalRequestProcessor
- 注册JMX服务:ZK会将服务器运行时的一些状态信息以JMX的方式暴露出来
- 注册ZK服务器实例:此时ZK服务器初始化完毕,注册到ServerCnxnFactory之后就可以对外提供服务了,至此单机版的ZK服务器启动完毕
集群版ZK服务器的启动过程
zk源码阅读26:集群版服务器启动概述 - 简书

预启动过程与单机版一致
初始化
- 创建并初始化 ServerCnxnFactory
- 创建ZooKeeper数据管理器 FileTxnSnapLog
- 创建QuorumPeer 实例:Quorum是集群模式下特有的对象,是ZooKeeper服务器实例ZooKeeperServer的托管者。从集群层面看QuorumPeer代表了ZooKeeper集群中的一台机器。在运行期间,Quorum会不断检测当前服务器实例的运行状态,同时根据情况发起Leader选举
- 创建内存数据库 ZKDatabase,管理ZooKeeper的所有会话记录以及DataTree 和事务日志的存储
- 初始化 QuorumPeer,将一些核心组件注册到QuorumPeer,包括 FileTxnSnapLog、ServerCnxnFactory、ZKDatabase,同时配置一些参数,包括服务器地址列表、Leader选举算法和会话超时时间限制等
- 恢复本地数据
- 启动 ServerCnxnFactory 主线程
Leader选举
- Leader选举初始化阶段:Leader选举是集群版启动流程与单机版最大的不同,ZK会根据SID(服务器分配的ID)、lastLoggedZxid(最新的ZXID)和当前的服务器epoch(currentEpoch)生成一个初始化的投票,初始化过程中每个服务器会为自己投票。 ZooKeeper会根据zoo.cfg中的配置(electionAlg),创建响应的Leader选举算法实现,3.4.0之前支持 LeaderElection\AuthFastLeaderElection\FastLeaderElection 三种算法实现,3.4.0之后只支持FastLeaderElection。 在初始化阶段,ZooKeeper会首先创建Leader选举所需的网络IO层 QuorumCnxManager,同时启动对Leader选举端口的监听,等待集群中的其他服务器创建连接
- 注册JMX服务
- 检测当前服务器状态:QuorumPeer不断检测当前服务器的状态做出相应的处理,正常情况下,ZK服务器的状态在LOOKING、LEADING和FOLLOWING/OBSERVING之间进行切换,。启动阶段QuorumPeer的状态是LOOKING,因此开始进行Leader选举
- Leader选举:投票选举产生Leader服务器,其他机器成为Follower或是Observer; Leader选举算法的原则:集群中的数据越新(根据每个服务器处理过的最大ZXID来确定数据是否比较新)越有可能成为Leader,ZXID相同时SID越大越有可能成为Leader。
Leader和Follower服务器启动期交互过程

- 完成Leader选举后,每个服务器根据自己的角色创建相应服务器实例,并开始进入各自角色主流程
- Leader服务器启动Follower接收器LearnerCnxAcceptor,负责接收所有非Leader服务器的连接请求
- Learner服务器根据投票选举结果找到当前集群中的Leader服务器,与其建立连接
- Leader接收来自其他机器的连接创建请求后,创建一个LearnerHandler实例。每个LearnerHandler实例都对应了一个Leader与Learner的服务器之间的连接,负责消息、数据同步
- Learner向Leader发起注册:将含有当前服务器SID和服务器处理的最新ZXID信息的LearnerInfo发送给Leader服务器
- Leader接收到注册信息后解析出SID和ZXID,根据ZXID解析出Learner对应的epoch_of_learner_parse,与自己的epoch_of_leader_self进行比较,如果epoch_of_learner_parse>epoch_of_leader_self,则更新 epoch_of_leader_self=epoch_of_learner_parse+1。LearnerHandler会进行等待,直到过半的Learner向Leader注册完毕,同时更新 epoch_of_leader 之后,Leader就可以确定当前集群的epoch
- Leader将最终的epoch以LEADERINFO消息的形式发送给Learner,同时等待Learner的响应
- Follower从LEADERINFO消息中解析出epoch和ZXID向Leader返回ACKEPOCH响应
- Leader收到反馈响应ACKEPOCH后与Follower进行数据同步
- 如果过半的Learner完成了数据同步,就启动Leader和Learner服务器实例
Leader和Follower启动
接上面步骤10,启动步骤如下:
- 创建并启动会话管理器
- 初始化ZooKeeper的请求处理链:根据服务器角色的不同生成不同的请求处理链
- 注册JMX服务
至此,集群版的ZK服务器启动完毕
Leader选举过程
Leader选举是ZooKeeper中最重要的技术之一,也是保证分布式数据一致性的关键
服务器启动时期的Leader选举
以3台机器组成的集群为例:Server1首先启动,此时无法完成Leader选举
- Server2启动后,与Server1进行Leader选举,由于是初始化阶段,都会投票给自己,于是Server1投票内容 (myid, ZXID) 为 (1,0),Server2投票 (2,0),各自将这个投票发送给集群中的其他所有机器
- 每个服务器接收来自其他各服务器的投票,并判断投票的有效性:检查是否是本轮投票,是否来自LOOKING状态的服务器
- 收到其他服务器的投票后与自己的投票进行PK,PK规则有:- 优先检查ZXID,ZXID较大的服务器优先作为Leader- ZXID相同时比较myid,myid较大的作为Leader> 此时Server1收到Server2的投票(2,0),ZXID相同,但myid较小,会更新自己的投票为 (2,0) 并发出。Server2发现自己的myid较大,无需更新投票信息,只是再次向集群中所有机器发出上一次投票信息
- 统计投票:每次投票后服务器会统计所有投票,判断是否有过半(> n/2 + 1)的机器接收到相同的投票信息来决定Leader服务器 此时3台服务器已有 2台(Server1 Server2)达成一致,超过半数,将选举出Leader - Server2
- 改变服务器状态:确定了Leader后服务器需要更新自己的状态,Follower变更为FOLLOWING,Leader会变更为 LEADING 状态
服务器运行期间的Leader选举
Leader服务器宕机后进入新一轮的Leader选举
- 变更状态:Leader宕机后剩下的非Observer服务器都会将自己的状态变更为LOOKING,开始进入Leader选举流程
- 每个Server发出一个投票:生成投票信息(myid, ZXID)在第一轮投票中,每个服务器都会投自己,后续的判断过程与服务器启动时期的Leader选举相同
Leader选举算法 - FastLeaderElection
ZooKeeper提供了3种Leader选举算法:LeaderElection、UDP版本的FastLeaderElection、TCP版本的FastLeaderElection。
术语解释:
SID - 服务器ID,唯一标识ZooKeeper集群中的机器的数字,与myid一致
ZXID - 事务ID,用于唯一标识一次服务器状态的变更,某一时刻,集群中的每台服务器的ZXID不一定完全一致
Vote - 投票
Quorum - 过半机器数,quorum = n/2 + 1
ZooKeeper集群中服务器出现下述两种情况之一就会进入Leader选举:集群初始化启动阶段;Leader宕机/断网
而一台机器进入Leader选举流程时,当前集群也可能会处于两种状态:
- 集群中本来就存在Leader,此时试图发起选举会被告知当前服务器的Leader信息,直接与Leader建立连接并同步状态
- 集群中不存在Leader:所有机器进入LOOKING状态进行投票选举Leader
【选举案例】集群有5台机器,SID分别为 1 2 3 4 5,ZXID分别为 9 9 9 8 8,在某一时刻SID为 1 2 的机器宕机退出,集群此时开始进行Leader选举
第一次投票时,由于还无法检测到集群中其他机器的状态信息,每台机器都将投自己,于是SID为 3 4 5的机器分别投票(SID,ZXID) (3,9) (4,8) (5,8)
每台机器发出自己的投票后也会收到来自集群中其他机器的投票,每台机器都会对比收到的投票,决定是否替换。假设机器自己的投票是 (self_sid, self_zxid) 接收到的投票是 (vote_sid, vote_zxid),对比的规则是:
- 如果 vote_zxid > self_zxid 则认可当前投票,并再次将更新后的投票发送出去
- 如果 vote_zxid < self_zxid 则不作变更
- 如果 vote_zxid = self_zxid && vote_sid > self_sid,就认可当前接收到的投票,并改为 (vote_sid, vote_zxid) 投递出去
- 如果 vote_zxid = self_zxid && vote_sid < self_sid,则不作变更
SID为 3 4 5的机器对投票进行对比,会统一更新为投票 (3,9) ,此时quorum = 3 >= (5/2 + 1) 超过半数,选举服务器3作为Leader
ZXID越大的机器,数据也就越新,这样可以保证数据的恢复(更少的数据丢失),所以适合作为Leader服务器
Leader选举的实现细节
在QuorumPeer.ServerState 类中定义了4种服务器状态
public enum ServerState {
LOOKING, // 寻找Leader状态,当前集群中没有Leader,需要进入Leader选举流程
FOLLOWING, // 当前服务器的角色是Follower
LEADING, // 当前服务器角色是Leader
OBSERVING // 当前服务器角色是 Observer
}
org.apache.zookeeper.server.quorum.Vote 数据结构的定义
public class Vote {
private final int version;
private final long id; // 选举的Leader的SID
private final long zxid;
//逻辑时钟,用于判断多个投票是否在同一轮选举周期中。该值在服务端是一个自增序列,每次进入新一轮投票后,都会对该值+1
private final long electionEpoch;// 被推举的Leader的epoch
private final long peerEpoch;//当前服务器的状态
QuorumCnxManager 网络IO
每个服务器启动时会启动一个QuorumCnxManager,负责各服务器的底层Leader选举过程中的网络通信。
QuorumCnxManager内部维护了一系列按SID分组的消息队列:
recvQueue:消息接收队列,存放从其他服务器接收到的消息
queueSendMap:消息发送队列,保存待发送的消息。此Map的key是SID,分别为集群中的每台机器分配了一个单独队列,从而保证各台机器之间的消息发送互不影响
senderWorkerMap:发送器集合,同样按SID分组,每个SenderWorker消息发送器对应一台远程ZooKeeper服务器
lastMessageSent:最近发送过的消息,为每个SID记录最近发送过的消息
选举时集群中的机器是如何建立连接的:
为了能够进行互相投票,ZooKeeper集群中的机器需要两两建立网络连接。
QuorumCnxManager启动时会创建一个ServerSocket监听Leader选举的通信端口(默认3888),接收其他服务器的TCP连接请求并交给receiveConnection函数来处理。为了避免两台机器之间重复创建TCP连接,ZooKeeper设计一种建立TCP连接的规则:只允许SID大的服务器主动和其他服务器建立连接,否则断开连接。如果服务器收到TCP连接请求发现比自己的SID值小,会断开这个连接并主动与发起连接的远程服务器建立连接。
建立连接后就会根据外部服务器的SID创建对应的消息发送器 SendWorker 和 消息接收器RecvWorker 并启动
FastLeaderElection选举算法的核心
ZooKeeper对于选票的管理
- sendqueue:选票发送队列,保存待发送的选票
- recvqueue:选票接收队列,保存接收到的外部选票
- FastLeaderElection.Messenger.WorkerReceiver:选票接收器,不断从QuorumCnxManager中取出其他服务器发出的选举消息,并转成Vote,保存到recvqueueu。如果接收到的外部投票选举轮次小于当前服务器(validVoter方法返回false),直接忽略改选票同时发出自己的投票。如果当前的服务器并不是LOOKING状态(if (self.getPeerState() == QuorumPeer.ServerState.LOOKING)),就将Leader信息以投票的形式发出。 选票接收器接收到的消息如果来自Observer就会忽略该消息,并将自己当前的投票发送出去
- WorkerSender 选票发送器,会不断从sendqueue队列中获取待发送的选票,并将其传递到底层QuorumCnxManager中
FastLeaderElection#lookForLeader方法中揭示了选举算法的流程,该方法在服务器状态变成LOOKING时触发
选举算法流程
- 自增选举轮次 logicalclock ++ FastLeaderElection中的 AtomicLong logicalclock 字段标记当前Leader的选举轮次,ZooKeeper在开始新一轮投票时,会首先对logicalclock进行自增操作
- 初始化选票 初始化选票Vote的属性:将自己推荐为Leader(id=服务器自身SID,zxid=当前服务器最新ZXID,electionEpoch=当前服务器的选举轮次,peerEpoch=被推举的服务器的选举轮次,state=LOOKING)
- 将初始化好的选票放入sendqueue中,由WorkerSender负责发出
- 服务器不断从 recvqueue 接收外部投票,如果服务器发现无法获取到任何投票会检查与其他服务器的连接,修复连接后重新发出
- 处理外部投票,根据选举轮次判断进行不同的处理:- 外部投票选举轮次 > 内部轮次:立即更新自己的选举轮次logicalclock,清空所有已收到的投票,使用初始化的投票进行PK以确定是否变更内部投票,最终将内部投票发送出去- 外部投票选举轮次 < 内部轮次:忽略外部投票,返回步骤4- 两边一致,绝大多数场景,选举轮次一致时开始进行选票PK
- 选票PK:收到其他服务器有效的外部投票后,进行选票PK,执行FastLeaderElection.totalOrderPredicate方法,选票PK的目的是确定当前服务器是否需要变更投票,主要从 logicalclock、ZXID、SID三个维度判断,符合下述任意一个条件就进行投票变更:- 外部投票推举的Leader服务器的 logicalclock > 内部投票的,需要进行内部投票变更- logicalclock一致的,对比两者的ZXID,外部投票ZXID > 内部的,进行内部投票变更- 两者的ZXID一致就对比SID,外部的大就进行投票变更
- 变更投票:如果需要变更投票就使用外部投票的选票信息覆盖内部投票,变更完成后再将这个变更后的内部投票发出去
- 选票归档:无论是否进行了投票变更,外部投票都会存入recvset中进行归档,recvset中按照服务器对应的SID来区分{(1,vote1),(2,vote2),...}
- 统计投票:统计集群中是否已经有过半的机器认可了当前的内部投票,否则返回步骤4
- 更新服务器状态:如果此时已经确定可以终止投票,就更新服务器状态:根据过半机器认可的投票对应的服务器是否是自己确定是否成为Leader,并将状态切换为LEADING/FOLLOWING/OBSERVING
上述10个步骤就是FastLeaderElection的选举流程,步骤4~9会经过几轮循环,直到Leader选举产生。在步骤9如果已经有过半服务器认可了当前选票,此时ZooKeeper并不会立即进入步骤10,而是等待一段时间(默认200ms)来确定是否有新的更优的投票。
服务器角色介绍
Leader
工作内容:事务请求的唯一调度和处理者,保证集群事务处理的顺序性;集群内部各服务器的调度者;
ZooKeeper使用责任链模式来处理客户端请求

- PrepRequestProcessor是Leader服务器的请求预处理器,在ZK中,将创建删除节点/更新数据/创建会话等会改变服务器状态的请求称为事务请求,对于事务请求,预处理器会进行一系列预处理,如创建请求事务头、事务体、会话检查、ACL检查和版本检查
- ProposalRequestProcessor Leader的事务投票处理器,也是Leader服务器事务处理流程的发起者。- 对于非事务请求:直接将请求流转到CommitProcessor,不作其他处理- 对于事务请求:除了交给CommitProcessor,还会根据对应请求类型创建对应的Proposal,并发送给所有Follower服务器发起一次集群内的事务投票。ProposalRequestProcessor还会将事务请求交给SyncRequestProcessor进行事务日志的记录
- SyncRequestProcessor 事务日志处理器,将事务请求记录到事务日志文件中,触发ZooKeeper进行数据快照
- AckRequestProcessor 是Leader特有的处理器,负责在SyncRequestProcessor处理器完成事务日志记录后向Proposal的投票收集器发送ACK反馈,通知投票收集器当前服务器已完成对该Proposal的事务日志记录
- CommitProcessor 事务提交处理器
- ToBeCommitProcessor 该处理类中有一个toBeApplied队列(ConcurrentLinkedQueue<Proposal> toBeApplied)存储被CommitProcessor处理过的可被提交的Proposal,等待FinalRequestProcessor处理完提交的请求后从队列中移除
- FinalRequestProcessor 进行客户端请求返回前的收尾工作:创建客户端请求的响应、将事务应用到内存数据库
LearnerHandler:Leader服务器会与每一个Follower/Observer服务器建立一个TCP长链接,同时为每个Follower/Observer服务器创建LearnerHandler。LearnerHandler是ZK集群中的Learner服务器的管理器,负责Follower/Observer服务器和Leader服务器之间的网络通信:数据同步、请求转发、Proposal提议的投票。
Follower
Follower的职责:处理客户端非事务请求,转发事务请求给Leader服务器;参与事务请求Proposal的投票;参与Leader选举投票;
Follower不需要负责事务请求的投票处理(所以不需要ProposalRequestProcessor),所以其请求处理链简单一些

- FollowerRequestProcessor 识别出当前请求是否是事务请求,如果是事务请求,Follower就会将请求转发给Leader服务器,Leader服务器收到请求后提交给请求处理器链,按正常事务请求进行处理
- SendAckRequestProcessor Follower服务器上另一个和Leader服务器有差异的请求处理器,与Leader服务器上的AckRequestProcessor类似,SendAckRequestProcessor同样承担了事务日志记录反馈的角色,在完成事务日志记录后,会向Leader服务器发送ACK消息表明自身完成了事务日志的记录工作。两者的一个区别是:AckRequestProcessor在Leader服务器上,因此ACK反馈是一个本地操作,而SendAckRequestProcessor在Follower上,需要通过ACK消息的形式向Leader服务器进行反馈。
Observer
观察ZooKeeper集群的最新状态并将这些状态变更同步过来,Observer服务器在工作原理上与Follower基本一致,对于非事务请求可以进行独立的处理,对于事务请求同样需要转发到Leader服。与Follower的一大区别是:Observer不参与任何形式的投票,包括Leader选举和事务请求Proposal的投票。
集群内消息通信
ZK集群各服务器间消息类型分为4类:数据同步型、服务器初始化型、请求处理型、会话管理型
数据同步消息
Learner与Leader进行数据同步使用的消息,分为4种(消息类型定义在Leader.java中,使用常量数字标记):
- DIFF, 13 Leader发送给Learner,通知Learner进行DIFF方式的数据同步
- TRUNC, 14 Leader --> Learner 触发Learner服务器进行内存数据库的回滚操作
- SNAP, 15 Leader --> Learner 通知Learner,Leader即将与其进行全量数据同步
- UPTODATE, 12 Leader --> Learner 通知Learner完成了数据同步,可以对外提供服务
服务器初始化型消息
整个集群或某些机器初始化时,Leader与Learner之间相互通信所使用的消息类型:
- OBSERVERINFO,16: Observer在启动时发送消息给Leader,用于向Leader注册Observer身份,消息中包含当前Observer服务器的SID和已经处理的最新ZXID
- FOLLOWERINFO,11:Follower启动时发送包含SID和已处理的最新ZXID的注册消息到Leader
- LEADERINFO,17:上述两种情形下,Leader服务器会返回包含最新EPOCH值的LeaderInfo返回给Observer或Follower
- ACKEPOCH,18:Learner在收到LEADERINFO消息时会将自己的最新ZXID和EPOCH以ACKEPOCH消息的形式发送给Leader
- NEWLEADER,10:足够多的Follower连接上Leader服务器,或是Leader服务器完成数据同步后,Leader向Learner发送的阶段性标识信息,包含当前最新ZXID
请求处理型
请求处理过程中Leader和Learner之间互相通信所使用的消息:
- REQUEST,1:Learner收到事务请求时需要将请求转发给Leader,该请求使用REQUEST消息的形式进行转发
- PROPOSAL,2:在处理事务请求时,Leader服务器会将事务请求以PROPOSAL消息的形式创建投票发送给集群中的所有的Follower进行事务日志的记录
- ACK,3:Follower完成事务日志的记录后会以ACK消息的形式反馈给Leader
- COMMIT,4:Leader通知集群中的所有Follower,可以进行事务请求的提交了,Leader在收到过半Follower发来的ACK消息后,进入事务请求的最终提交流程——生成COMMIT消息,告知所有Follower进行事务请求的提交,这是一个2PC的过程
- INFORM,8:Leader发起事务投票并通知提交事务,只需要PROPOSAL和COMMIT消息给Follower就可以了,而Observer不参与事务投票,无法接收COMMIT消息,但需要知道事务提交的内容,所以ZK设计了INFORM消息发给Observer,消息中会携带事务请求的内容
- SYNC,7:Leader通知Learner服务器已完成Sync操作
会话管理型
ZK服务器在进行会话管理过程中,与Learner服务器之间通信所使用的消息:
- PING,5:ZK客户端随机选择一个服务器进行连接,所以Leader服务器无法直接收到所有客户端的心跳检测,所以需要委托Learner维护所有客户端的心跳检测。Leader定时向Learner发送PING消息就是要求Learner将一段时间内保持心跳检测的客户端列表同样以PING消息的形式返回给Leader,这样Leader就能获取到全部客户端的活跃状态并进行会话激活了。
- REVALIDATE,6:客户端发生重连后(可能切换了服务器)新连接的服务器需要向Leader发送REVALIDATE消息以确定客户端会话是否已经超时。
客户端请求的处理
会话创建请求
ZK服务端对于会话创建的处理,可以分为请求接收、会话创建、预处理、事务处理、事务应用和会话响应。
zookeeper源码分析(3)— 一次会话的创建过程 - 简书

请求接收
- IO层接收来自客户端的请求,NIOServerCnxn实例维护每一个客户端连接,负责客户端与服务端通信,并将请求内容从底层网络IO中读取出来
- 判断是否是客户端“会话创建”请求:检查当前请求对应的NIOServerCnxn实体是否已经初始化,未初始化时第一个请求必定是会话创建请求
- 反序列化ConnectRequest请求,确定是会话创建请求后就可以反序列化得到一个ConnectRequest请求实体
- 判断是否是ReadOnly客户端,如果ZK服务器是以ReadOnly模式启动,所有来自非ReadOnly型客户端的请求将无法处理。所以服务端需要从ConnectRequest中检查是否是ReadOnly客户端,以此来决定是否接受此“会话创建”请求
- 检查客户端ZXID:出现客户端ZXID比服务端还大这种反常情形时,服务端不接受此会话创建请求
- 协商sessionTimeout:客户端有自己设置的sessionTimeout值,传到服务端后,服务端要根据自身配置进行检查限定,通常的规则是 2 * ticketTime ~ 20 * tickerTime 之间
- 判断是否需要重新创建会话:解析客户端传入的sessionID进行判断
会话创建
- 为客户端生成sessionID:每个ZK服务器启动时都会初始化一个会话管理器SessionTracker,同时初始化一个基准sessionID,这个基准sessionID的生成需要保证后续客户端在此基础上不断+1能够全局唯一。sessionID生成算法见客户端介绍:会话Session > sesssionID的生成原理。
- 注册会话:将会话信息保存到SessionTracker的本地字段中:ConcurrentHashMap<Long, SessionImpl> sessionsById、ConcurrentMap<Long, Integer> sessionsWithTimeout
- 会话激活:服务端根据配置的ticketTime和会话超时时间比对计算下一次会话超时时间(使用了分桶策略)sessionsWithTimeout
- 生成会话密码:随机数,生成代码见 ZooKeeperServer#generatePasswd
预处理
- PrepRequestProcessor处理请求(责任链模式)
- 创建请求事务头:对于事务请求,ZK会为其创建请求事务头,后续请求处理器都是基于该请求头标识当前请求是否是事务请求,请求事务头包含:clientId(唯一标识请求所属客户端)cxid(客户端操作序列号)zxid(事务请求对应的zxid)time(服务端开始处理事务请求的时间)type(事务请求的类型:ZooDefs.OpCode.create、delete、setData和createSession等)
- 创建请求事务体CreateSessionTxn
- 注册与激活会话:额外处理非Leader转发的会话创建请求
事务处理

- ProposalRequestProcessor处理请求:PrepRequestProcessor将请求交给下一级处理器,提案Proposal是ZK中对因事务请求展开的投票流程中的事务操作的包装,该处理器就是处理提案的,处理流程有:- Sync流程:SyncRequestProcessor处理器记录事务日志。完成事务日志记录后,每个Follower都会向Leader发送ACK消息,表明自身完成了事务日志的记录,以便Leader服务器统计每个事务请求的投票情况- Proposal流程:ZK的实现中,每个事务请求都需要集群中过半机器投票认可才能真正应用到ZK的内存数据库中,这个投票与统计的过程就叫 Proposal流程:- 发起投票:对于事务请求,Leader服务器会发起一轮事务投票,发起事务投票之前会检查服务端ZXID是否可用,如果不可用会抛出XidRolloverException- 生成提议Proposal:如果服务端ZXID可用,就可以开始事务投票了,ZK会将之前创建的请求头和事务体,以及ZXID和请求本身序列化到Proposal对象中- 广播提议:Leader服务器会以ZXID作为key,将提议放入投票箱ConcurrentMap<Long, Proposal> outstandingProposals中,同时将该提议广播给所有Follower服务器- 收集投票:Follower服务器接收到Leader发来的提议后,会进入Sync流程进行事务日志的记录,执行完后发送ACK消息给Leader,Leader根据ACK消息统计Proposal的投票情况。当过半机器通过时,就进入Proposal的Commit阶段- Commit Proposal前将请求放入 toBeApplied 队列中- 广播COMMIT消息:Leader会向Observer广播包含Proposal内容的INFORM消息,而对于Follower服务器则需只发送ZXID(上文有介绍)- Commit流程:- 将请求交给CommitProcessor.java处理器,放入 LinkedBlockingQueue<Request> queuedRequests 中,独立线程会取出处理- 标记topPending:如果是事务请求(write类型),就会将topPending标记为当前请求,用于确保事务请求的顺序性,便于CommitProcessor检测当前集群中是否正在进行事务请求的投票- 等待Proposal投票:Commit流程处理时,Leader根据当前事务请求生成Proposal广播给所有Follower,此时Commit流程需要等待- 投票通过,提议获得过半机器认可,ZK会将请求放入committedRequests队列中,同时唤醒Commit流程- 提交请求:将请求放入toProcess队列中,交给FinalRequestProcessor处理
事务应用
- FinalRequestProcessor检查outstandingChanges队列中请求的有效性,如果队列中的请求落后于当前正在处理的请求,则从队列中移除
- 之前的请求处理逻辑中仅仅是将事务请求记录到了事务日志中,内存数据库中的状态尚未变更。因此需要将事务变更应用到内存数据库中。对于会话创建这种“事务请求”,只需向SessionTracker进行会话注册
- 完成内容应用后将事务请求放入队列 commitProposal,这个队列保存最近被提交的事务请求,以便集群间机器进行数据的快速同步
会话响应
此时客户端请求在ZK服务端已经完成了所有链路的处理
- 统计处理:计算请求在服务器端处理所花费的时间,统计客户端连接的一些基本信息:lastZxid-最新的ZXID;lastOp-最后一次和服务端的操作;lastLatency-最后一次请求处理所花费的时间;
- 创建响应ConnectResponse 会话创建成功后的响应,包含:当前客户端与服务端之间的通信协议版本号;会话超时时间;sessionID;会话密码;
- 序列化 ConnectResponse
- IO层发送响应给客户端
SetData请求的处理

预处理
- IO层接收来自客户端的请求
- 判断是否是客户端会话创建类请求,setData请求到来时已完成了会话创建
- PrepRequestProcessor处理器进行处理
- 创建请求事务头
- 检查会话是否超时,超时向客户端抛出SessionExpiredException
- 反序列化请求,创建ChangeRecord记录。ZK对于客户端请求,反序列化生成特定SetDataRequest请求,请求中包含数据节点path、更新数据内容data、期望的数据节点版本version。
- ACL权限检查,没有权限会抛出NoAuthException
- 数据版本检查(乐观锁)
- 创建事务请求体SetDataTxn
- 保存事务操作到outstandingChanges队列中
事务处理:无论对于会话创建还是SetData请求,事务处理流程都是一致的:由ProposalRequestProcessor处理器发起,通过Sync、Proposal、Commit 3个子流程相互协作完成
事务应用
- FinalRequestProcessor处理
- ZK将请求事务头和事务体交给内存数据库 ZKDatabase进行事务应用,返回ProcessTxnResult,包含了数据节点内容更新后的stat
- 将事务请求放入 commitProposal 队列
请求响应
- 统计处理
- 创建响应体SetDataResponse,包含当前数据节点的最新状态stat
- 创建响应头,方便客户端对响应进行解析,包括当前响应对应的事务ZXID和请求处理是否成功的标识err
- 序列化响应
- IO层发送响应给客户端
事务请求转发
所有非Leader服务器如果收到了来自客户端的事务请求,必须将其转发给Leader服务器处理。Follower或Observer服务器中,第一个请求处理器分别是FollowerRequestProcessor和ObserverRequestProcessor,都会检查当前请求是否是事务请求,对于事务请求会议REQUEST消息的形式转发给Leader,Leader解析出原始请求后提交到自己的请求处理链中。
GetData请求

预处理:
IO层接收来自客户端的请求;判断是否是客户端会话创建请求;PrepRequestProcessor处理;会话检查;
由于GetData请求是非事务请求,因此不需要事务预处理逻辑:创建请求事务头、ChangeRecord、事务体、数据节点版本的检查;
非事务处理:
反序列化GetDataReqeuest(得到path和watcher注册情况);获取数据节点(ZK从内存数据库中获取节点及ACL信息);ACL检查;获取数据内容和stat,注册watcher;
请求响应:
创建响应体GetDataResponse,获取数据成功后的响应,包含当前数据节点内容和状态stat;创建响应头;统计处理;序列化响应;IO层发送响应给客户端;
ZK底层数据与存储
内存数据库存储了ZK树结构的数据,包括节点路径、节点数据和ACL信息,ZK会定时将这些数据存储到磁盘上
DataTree类
org.apache.zookeeper.server.DataTree维护了树形结构数据,内部没有任何网络或客户端连接逻辑,所以可以单独进行调试。
DataNode是数据存储的最小单元,内含数据节点内容 byte[] data、ACL列表对应的map key Long acl、节点状态对象StatPersisted stat、子节点列表Set<String> children、父节点parent的引用?
DataTree维护了两个数据结构:path与DataNode组成的ConcurrentHashMap<String, DataNode> nodes、DataNode树;
另外为方便及时访问和清理临时节点,额外维护字段 Map<Long, HashSet<String>> ephemerals = new ConcurrentHashMap<Long, HashSet<String>>()
ZKDatabase
ZooKeeper的内存数据库,管理ZK的所有会话、DataTree存储和事务日志。ZKDatabase会定时向磁盘dump快照数据,ZK服务器启动时会通过磁盘上的事务日志和快照文件进行恢复
事务日志
zoo.cfg配置文件中的dataDir目录默认用于存储事务日志文件,dataLogDir可以配置为事务日志单独分配一个文件存储目录。
如果配置了 dataLogDir = /home/admin/zkData/zk_log,ZK运行时会在该目录下创建 version-2 子目录,该目录的命名跟随ZK的事务日志版本号。这样运行一段时间后在 /home/admin/zkData/zk_log/version-2 出现了日志文件
-rw-rw-r-- 1 admin admin 67108880 02-23 16:10 log.2c01631713
-rw-rw-r-- 1 admin admin 67108880 02-23 17:07 log.2c0164334d
-rw-rw-r-- 1 admin admin 67108880 02-23 18:19 log.2d01654af8
-rw-rw-r-- 1 admin admin 67108880 02-23 19:28 log.2d0166a224
- 这些日志文件大小固定都是64MB
- 文件后缀名是十六进制数字,即ZXID - 64位数字,前32位表示ecpoch,这些日志文件只有两个epoch:2c、2d;后32位是操作序列号。每个日志文件达到设定的大小后,创建新日志文件并以当时的ZXID为文件名,这样方便根据日志文件后缀名寻找ZXID的存储位置
- 事务日志文件内容的解析命令
java LogFormatter log.2d0166a224
# 事务日志文件头信息,输出事务日志的DBID和日志版本号
ZooKeeper Transactional Log File with dbid 0 txnlog format version 2
# 客户端会话创建的事务操作日志,分别记录了 事务操作时间、客户端会话ID、CXID客户端操作序列号、ZXID、操作类型和会话超时时间
...11:07:41 session 0x1446994y6273434 cxid 0x0 zxid 0x300000002 createSession 30000
# 节点创建的事务操作日志,记录了操作类型、节点路径、节点数据内容、节点ACL信息、是否是临时节点(F表示永久节点,T表示临时节点)、节点版本号
...11:08:40 session 0x1446995520000 cxid 0x2 zxid 0x3000003 create '/test_log,#7631,v{s{31,s{'world,'anyone}}},F,2
- 事务日志文件不会记录读操作
FileTxnLog类
在其public synchronized boolean append(TxnHeader hdr, Record txn, TxnDigest digest)方法中进行了日志的写入,会传递事务头TxnHeader和事务体Record,日志写入步骤:
- 判断FileTxnLog是否已关联上一个可写的事务日志文件,如果没有关联上,就会用与事务操作关联的ZXID作为后缀创建一个事务日志文件,同时构建事务日志文件头信息(包含魔数magic、事务日志格式版本version、dbid)并写入日志文件。改日志文件的文件流会放入 Queue<FileOutputStream> streamsToFlush = new ArrayDeque<>() 中
- 对日志文件进行磁盘空间预分配(日志文件不断追加写入会触发底层磁盘空白块的Seek,为提高IO效率,所以预分配磁盘空间),通常一个日志文件预分配64MB,已分配空间不足4KB时会再次分配,预分配的文件使用0填充,预分配的文件大小使用 zookeeper.preAllocSize 进行设置
- 事务序列化,包括事务头TxnHeader和事务体Record的序列化,事务体又分为会话创建事务CreateSessionTxn、节点创建事务CreateTxn、节点删除事务DeleteTxn、节点数据更新事务SetDataTxn
- 为保证事务日志文件的完整性和准确性,ZK在将事务日志写入文件前,会根据序列化步骤产生的字节数组计算checksum,ZK默认使用Adler32算法计算checksum
- 将序列化后的事务头、事务体和checksum写入文件流,由于ZK使用的是BufferedOutputStream,写入的数据并没有立刻到达磁盘
- 事务日志刷入磁盘:将缓冲数据输入磁盘,从streamToFlush 中获取文件流,调FileChannel.force(bool metadata) 进行磁盘文件的强制写入,该方法基于底层的fsync接口,通过 zookeeper.forceSync 来设置
TRUNC日志截断
在运行过程中如果出现非Leader服务器的ZXID(peerLastZxid)大于Leader服务器的,此时Leader服务器会发出TRUNC给这台服务器,清除掉所有包含或大于peerLastZxid的事务日志,保持与Leader服务器的同步
Sanpshot数据快照
记录ZK服务器上某一时刻全量内存数据内容,写入到指定磁盘文件中,同样位于指定的dataDir目录下。与事务日志文件不同的是,快照文件没有采用预分配的方式,所以快照文件的大小就可以反映当前ZK服务器内存中的全量数据大小。
快照数据的解析可使用命令
java SnapshotFormatter snapshot.30000000007
快照文件记录的是数据节点的元信息,不包含节点的数据内容
FileSnap类
ZK定期将内存数据库全量Dump到本地文件,这个文件就是Snapshot,通过snapCount配置在事务日志记录多少次后进行快照写入。数据快照的流程是
- 理论上在snapCount后进行数据快照,但考虑到数据快照对ZK服务器性能的影响,需要避免所有机器在同一时刻进行进行snapshot。ZK采用了过半随机策略,满足下述条件就进行数据快照:logCount > (snapshot / 2 + randRoll) ,logCount表示当前已经记录的事务日志数量,randRoll为 1 ~ snapCount/2 之间的随机数,所以上述条件相当于:如果配置snapCount=1000,则ZK会在500~1000次事务日志后进行一次快照
- 切换事务日志文件:当前事务日志文件已经写入了snapCount条事务日志,需要创建一个新的事务日志文件
- 创建数据快照异步线程,不影响ZooKeeper主流程
- 从ZkDatabase获取全量数据DataTree和会话信息
- 根据当前已提交的最大ZXID确定快照文件名称
- 先序列化文件头信息(包含魔数、版本号和dbid信息)对会话信息和DataTree分别进行序列化,生成checksum写入快照文件
服务器初始化流程
初始化流程 Zookeeper--数据初始化过程-蒲公英云 主要包括从快照文件中加载数据和从事务日志文件中进行数据订正两个过程
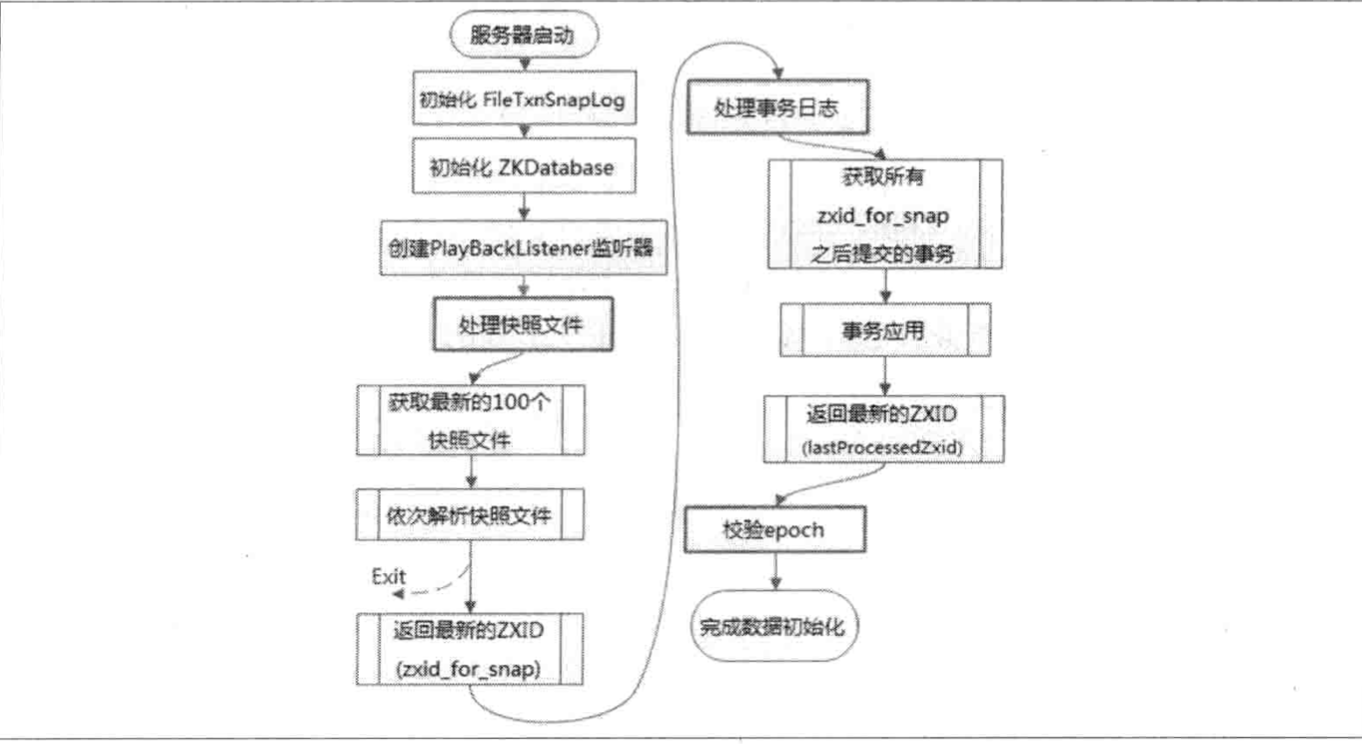
- 初始化FileTxnSnapLog:FileTxnSnapLog是ZooKeeper事务日志和快照数据访问层,用于衔接上层业务与底层数据存储,底层数据又分为snapshot和txn两部分,所以FileTxnSnapLog内部又分为FileTxnLog和FileSnap的初始化
- 初始化ZKDatabase:DataTree是ZooKeeper内存数据的核心模型,在每个ZooKeeper服务器内部是单例。ZkDatabase初始化时也会初始化DataTree:创建一些ZK的默认节点,如/ /zookeeper /zookeeper/quota。初始化阶段还会创建一个会话超时时间记录器 sessionsWithTimeouts
- 创建PlayBackListener监听器,接收事务使用过程中的回调。在ZK数据恢复后期事务订正过程中会回调这个监听器进行数据校正
- 完成内存数据库的初始化后从磁盘的快照文件中恢复数据
- 获取至多100个最近的快照文件
- 反序列化这些二进制文件生成DataTree对象和sessionWithTimeouts集合,同时进行文件的checkSum校验。当最新的快照文件不可用时才会进行逐个文件解析,直到这100个文件全部解析完,否则服务启动失败
- 获取最新的ZXID,从加载解析成功的快照文件的文件名中可以得到一个最新的ZXID
- 完成快照文件加载后,此时ZK服务器内存中已经有一份近似全量的数据,就可以通过事务日志更新增量数据了
- 从事务日志中获取比快照文件最大ZXID zxid_for_snap 大的事务操作
- 将这些事务操作逐个应用到之前基于快照数据文件恢复出来的DataTree 和 sessionsWithTimeouts 中。当一个事务被应用到内存数据库中后,ZK会回调PlayBackListener监听器,将这一事务操作记录转换成Proposal,保存到ZKDatabase.committedLog中,以便Follower进行快速同步
- 所有事务被完整应用后,此时就能获取到上次服务器正常运行时提交的最大事务ID
- 校验当前Leader周期 epoch 纪元号:上一步骤得到的ZXID中解析到epochOfZxid,同时与磁盘上的currentEpoch、acceptedEpoch文件中的epoch值进行校验
Leader应用完事务日志后的数据同步
PlayBackListener是一个事务应用监听器,Leader在事务应用后会回调该Listener的 onTxnLoaded 方法
public interface PlayBackListener {
void onTxnLoaded(TxnHeader hdr, Record rec, TxnDigest digest);
}
PlayBackListener会将这些事务通过 ZKDatabase#addCommittedProposal方法转存到 ZKDatabase.committedLog 中,便于集群间同步。
事务同步的过程就是Leader向Learner同步事务的过程,Learner向Leader注册的最后阶段会发送一个ACKEPOCH数据包,Leader会从该数据包中解析出该Learner的 currentEpoch 和 lastZxid。
数据同步初始化
数据同步代码位于LearnerHandler和Learner两个类中。Leader依据内存数据库ZKDatabase中的committedLog进行初始化,生成3个ZXID值:
- peerLastZxid:Learner服务器最后处理的ZXID
- minCommittedLog:Leader服务器提案缓存队列committedLog中的最小ZXID
- maxCommittedLog:Leader服务器提案缓存队列committedLog中的最大ZXID
ZK集群数据同步分为4类:
- DIFF 差异化同步(触发条件 minCommittedLog <= peerLastZxid <= maxCommittedLog)Leader向Learner发送DIFF指令通知Leader进入差异化同步状态,针对每个 ZXID > peerLastZxid 的提案,Leader会发出 PROPOSAL内容 和 COMMIT指令 两个数据包。与通常的Leader和Follower之间的事务请求的提交过程一致。 Leader在发送完差异数据后,会将Learner加入到 forwardingFollowers 或 observingLearners 队列中,随后向Learner发出NEWLEADER指令,通知其差异化同步完毕。 此后Learner反馈一个ACK消息给Leader,Leader接收到过半Learner的ACK消息后,会向所有已完成数据同步的Learner发送UPTODATE指令,通知Learner已经完成了数据同步。此时集群中过半机器完成了数据同步,具备了对外提供服务的能力。 Learner在接收到这个来自Leader的UPTODATE指令后,会终止数据同步流程,向Leader再次反馈一个ACK消息。
@startuml
autonumber
Leader <- Learner : FOLLOWERINFO/OBSERVERINFO
Leader -> Learner : LEADERINFO
Leader <- Learner : ACKEPOCH
note right
1-3 注册
end note
Leader -> Learner : DIFF
Leader -> Learner : PROPOSAL
Leader -> Learner : COMMIT
note right
4-9 差异化同步
end note
Leader -> Learner : PROPOSAL
Leader -> Learner : COMMIT
Leader -> Learner : NEWLEADER
Leader <- Learner : ACK
Leader -> Learner : UPTODATE 等待过半
Leader <- Learner : ACK
note right
10-12 同步确认
end note
- TRUNC+DIFF 先回滚再差异化同步。适用场景:A B C三台机器,某一时刻B是Leader,当前的Leader_Epoch=5,被过半数机器提交的ZXID包括 0x500000001、0x500000002,B服务器在处理完0x500000003事务时将该事务写入本地事务日志。但在B向其他Follower发送Proposal进行投票时,B服务器宕机,Proposal没有被同步出去。在新一轮选举后新Leader A服务器将Leader_Epoch变更为6,之后AC两台服务器对外提供服务,又提交了0x600000001、0x600000002两个事务,此时服务器B恢复加入集群。此时peerLastZxid、minCommittedLog、maxCommittedLog的值分别是 0x500000003、0x500000001、0x600000002,满足 minCommittedLog <= peerLastZxid <= maxCommittedLog。 当Leader服务器发现某个Learner包含了一条自己没有的事务记录,就需要让该Learner进行事务回滚,回滚到Leader上存在的且是最接近peerLastZxid的ZXID(上述例子中就是 0x500000002),然后再进行差异化同步
- TRUNC 仅回滚同步
- SNAP 全量同步。适用场景: peerLastZxid < minCommittedLog 或 Leader服务器上没有committedLog,peerLastZxid != lastProcessedZxid Leader服务器上数据恢复后得到的最大ZXID。这两种场景下,Leader都无法使用committedLog与Learner进行数据同步,因此只能进行全量同步
ZooKeeper技术内幕总结
ZooKeeper以树作为其内存数据模型,树上的每一个节点是最小的数据单元,即ZNode。ZNode有一个递增的版本号,以此可以实现分布式数据的原子性更新。
ZooKeeper序列化层使用从Hadoop中遗留下来的Jute组件,该组件不是性能最好的序列化框架,但在ZooKeeper中够用。
ZooKeeper的客户端和服务端之间会建立起TCP长链接进行网络通信,基于该TCP连接衍生出的会话概念,是客户端和服务端之间所有请求与响应交互的基础。在会话的生命周期中,会出现连接断开、重连或是会话失效等一系列问题。Leader服务器会负责管理每个会话的生命周期,包括会话的创建、心跳检测和销毁等。
服务器启动阶段会进行磁盘数据的恢复,恢复完成后会进行Leader选举,一旦选举产生Leader后,就立即开始进行集群间的数据同步——在整个过程中,ZooKeeper都处于不可用状态,直到数据同步完毕(集群中绝大部分机器数据和Leader一致),ZooKeeper才可以对外提供服务。在运行期间,如果Leader服务器所在机器宕机或是和集群中绝大部分机器断开连接,就会触发新一轮Leader选举。
一个正常运行的ZooKeeper集群,其机器角色通常由Leader、Follower和Observer组成。ZooKeeper对于客户端请求的处理严格按照ZAB协议规范进行。每个服务器在启动初始化阶段都会组装一个请求处理链,Leader服务器能够处理所有类型的客户端请求,而Follower或是Observer服务器只能处理非事务请求。对于每个事务请求,Leader都会为其分配一个全局唯一且递增的ZXID,以此保证事务处理的顺序性。在事务请求的处理过程中,Leader和Follower都会进行事务日志的记录。ZooKeeper通过JDK的File接口简单实现了自己的数据库存储系统,底层数据存储包括事务日志和快照数据两部分,这些都是ZooKeeper实现数据一致性非常关键的部分。
2022.07.27 23:00于 ibor四村
版权归原作者 人可德福 所有, 如有侵权,请联系我们删除。