
kettle在Linux下分布式集群服务器搭建
一、Kettle的集群原理
集群技术可以用来水平扩展转换,使得他们能够同时运行在多台服务器上。它将转换的工作量均分到不同的服务器上。生产环境中kettle服务器都是部署在linux服务器上,在windows本地开发好kettle任务,然后在linux集群环境上运行。
一个集群schema由一台主服务器,和一些子服务器组成,主服务器作为一个集群的控制器。简单的说,我们提到的Carte控制服务器就是主服务器,其他的Carte服务器就是子服务器。
二、Kettle集群优劣势
1.集群的优点
和其它系统的集群一样,有以下优点:
1)多服务器运行,加快处理速度,对于大数据量的操作更明显。
2)防单点失败,一台服务器故障后其它服务器还可以运行。
2.集群的缺点
1)采用主从结构,不具备自动切换主从的功能。所以一旦主节点宕机,整个系统不可用。
2)对网络要求高,节点之间需要不断的传输数据。
3)需要更多的服务器,而且主节点没有处理能力(在该步骤没有处理能力,在其他的没有使用集群功能的步骤仍具有处理能力)。
3.适用场景
适合于:
1)需求kettle能时刻保持正常运行的场景。
2)大批量处理数据的场景。
三、完全分布式集群搭建
1. 环境规划
该环境模拟一台主服务器,两台从服务器的方式。
名称、IP端口、说明:
master:192.168.16.102:8080 主服务器
Slave1: 192.168.16.103:8081 从服务器1
Slave2: 192.168.16.104:8082 从服务器2
2. 环境准备
首先需要先准备三台linux服务器,并且分别在三台机器上安装好jdk和kettle。虚拟机完成ip设置,ssh免密登录,同步分发脚本的编写,主机名和ip地址的映射。
(1) JDK安装
1. 上传jdk1.8的tar包上传到Linux上的/opt/soft目录下
2. 解压tar包到/opt/moudle/下
3. 配置环境变量JAVA_HOME
4. 分发解压后的jdk目录和配置目录
5. 让三台机器的环境变量生效
(2) Kettle安装
1.将pdi-ce-8.2.0.0-342.ziph上传到Linux操作系统上
unzip pdi-ce-8.2.0.0-342.zip
cd data-integration
(3) 测试安装是否成功
在kettle的data-integration目录中执行kitchen.sh文件,若出现帮助信息,证明安装成功
./kitchen.sh
(4)将MySQL_jdbc驱动拷贝到data-integration->lib目录下,解决数据库连接的问题
3.环境配置
和windows环境一样修改kettle配置文件,打开kettle的安装目录,进入到data-integration->pwd目录,找到carte-config-master-8080.xml文件。该文件主要是进行master主机配置,name、hostname、port依次配置名称、主机IP和端口号(如果已经使用可以修改)。
注意:username和password并不是指主机的登陆账号和密码,是集群的账号密码,该账号密码是集群连接的依据,账号密码是通过混淆的方式保存在pwd文件,kettle默认的账号密码是cluster/cluster,所以,在本机开发的时候,为了方便,账号密码都不用修改,都使用cluster即可。
进入Kettle的data-integration/pwd目录下,如图:
配置目录结构图
在该目录下含有6个文件
一个主服务器配置文件carte-config-master-8080.xml,四个从服务器配置文件
carte-config-8081.xml
carte-config-8082.xml
carte-config-8083.xml
carte-config-8084.xml
,这里我们使用前两个文件来配置两个子服务器,分别是slave1和slave2,
还有一个集群账号密码文件kettle.pwd(密码可以修改)。
(1)主服务器配置
主服务器配置文件carte-config-master-8080.xml内容如下: 主服务器配置图
主服务器配置图
其中name属性指定Kettle主服务器名称,hostname属性指定Kettle主服务器IP地址,port属性指定Kettle主服务器端口号,master属性指定是否是主服务器。伪分布式环境不需要配置该文件。
(2)子服务器配置
carte-config-8081.xml文件是从服务器1的配置文件。打开该文件,如下图。其中masters中,name、hostname、port需要和carte-config-master-8080.xml中完全一致。然后,同样修改carte-config-8082.xml文件。子服务器配置文件carte-config-8081.xml内容如下: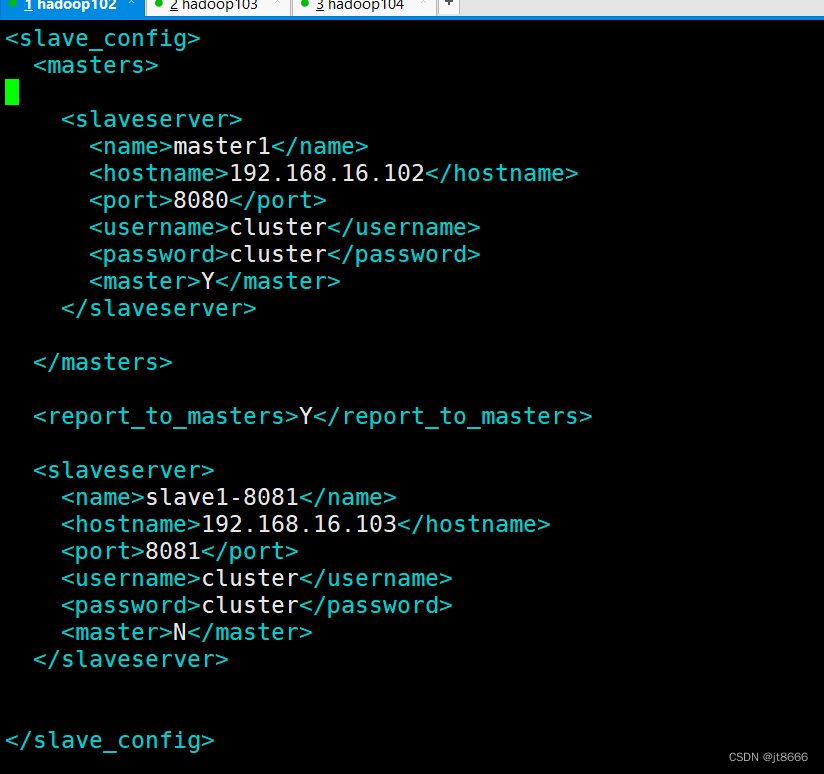
carte-config-8081.xml配置图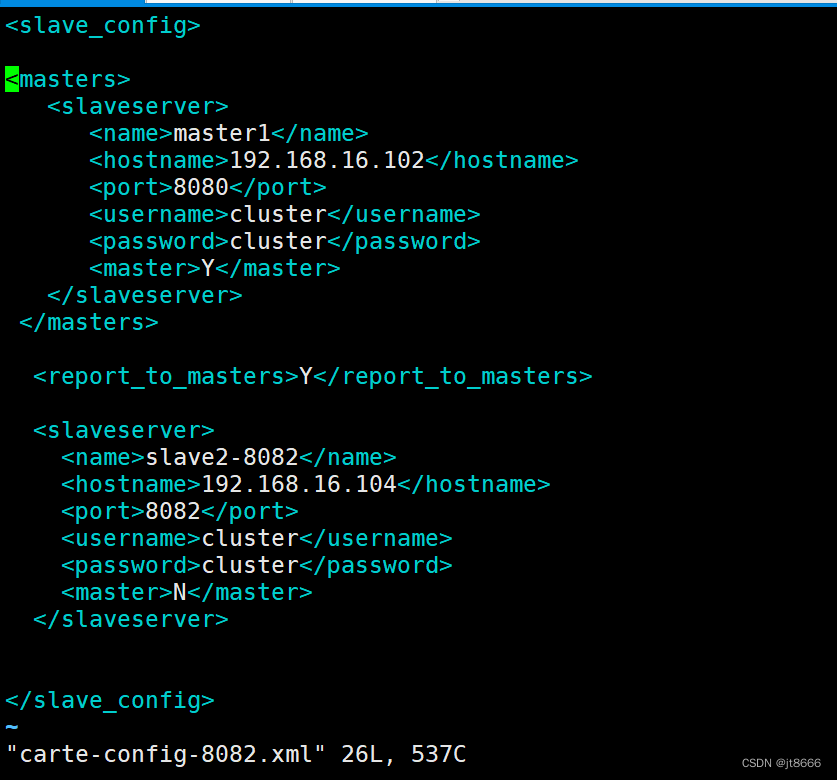
carte-config-8082.xml配置图
(3)配置kettle的环境变量,分发配置环境变量脚本,data-integration文件
(4)启动主从服务器,测试成功
启动主服务器 carte.sh 192.168.16.102 8080
主服务器启动图
启动第一台从服务器 carte.sh pwd/carte-config-8081.xml
脚本命令执行图
从服务器启动图
启动第二台从服务器 carte.sh pwd/carte-config-8082.xml
从服务器启动图
启动之后,在浏览器输入192.168.16.102:8080,出现如下图:
用户名和密码均为配置文件中配置的cluster,cluster
主服务器web端页面图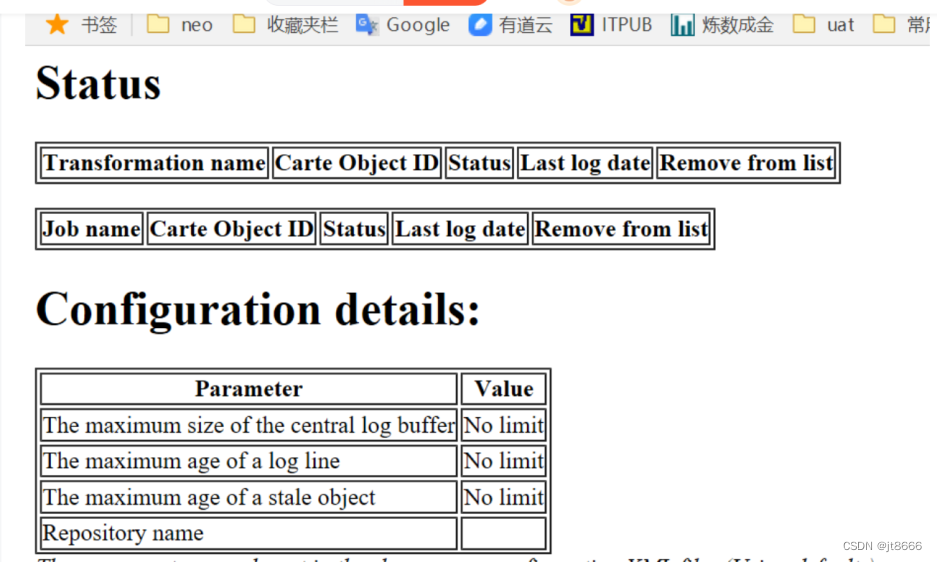
其他两台从服务器均以此查看web端页面,查看是否成功。
第一台从服务器web端页面
第二台从服务器web端页面
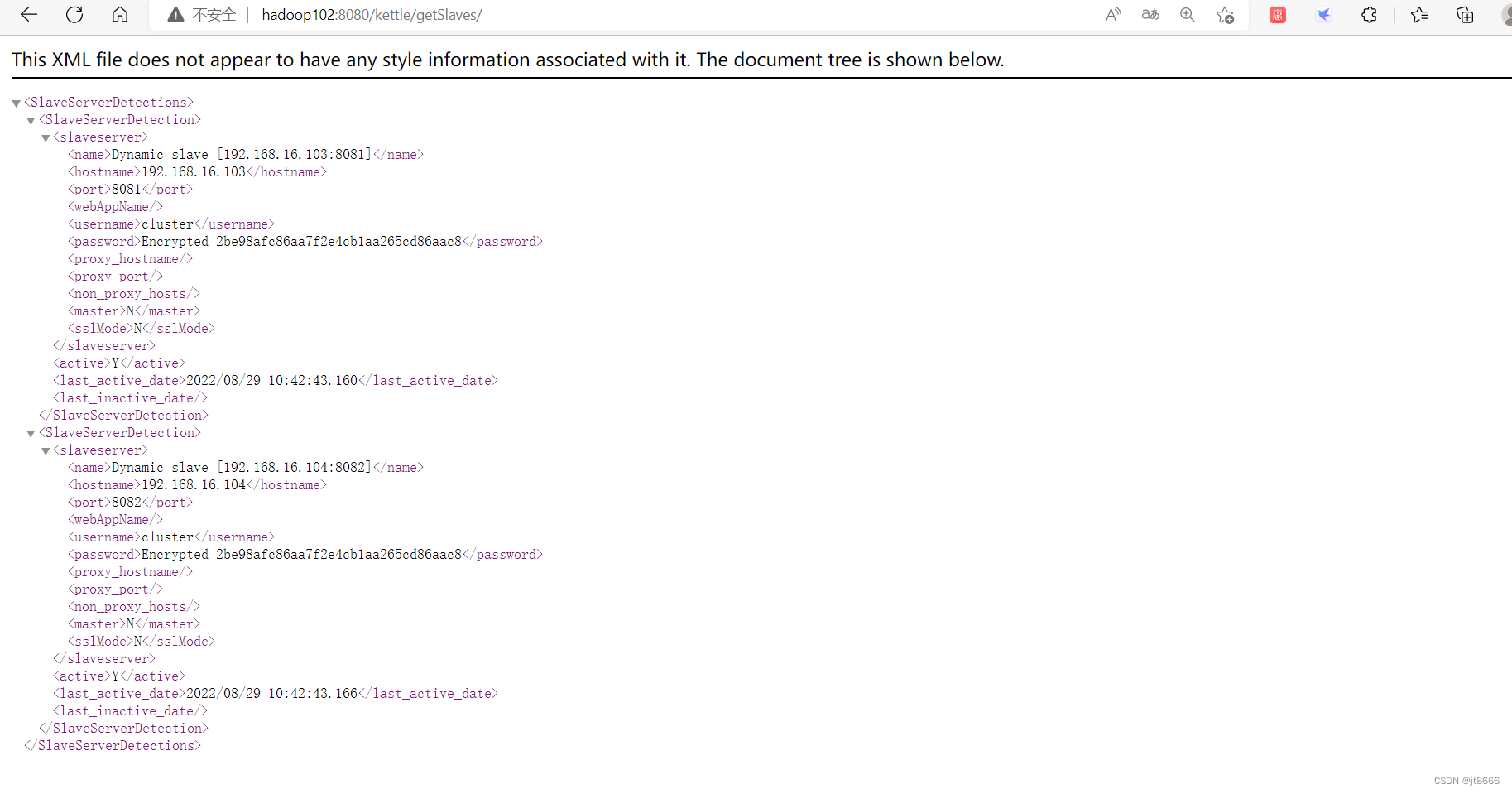
查看kettle子服务器的信息图
四、完全分布式集群下示例
1.需求说明
读取源数据表中数据到目标数据表中,具体转换过程如下所示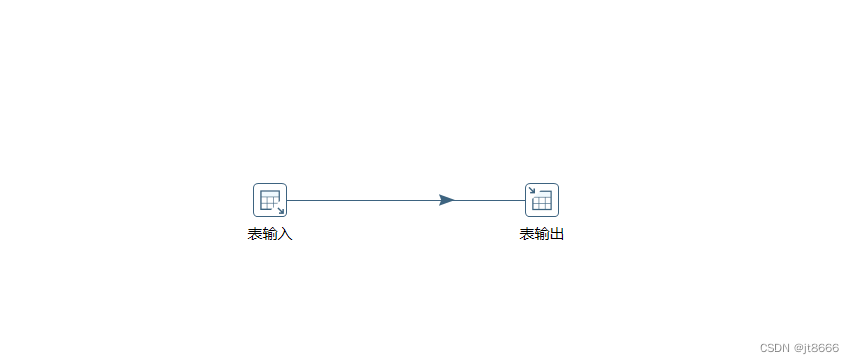
组织配置图
2. 启动环境
首先按上面步骤启动集群环境,然后双击双击 Spoon.bat 启动 kettle图形界面工具。
3. 环境配置
1) 在主对象树中新建子服务器,配置分别如下图

子服务器配置图
主服务器配置如上所示,记得勾选“是主服务器"。
主服务器配置图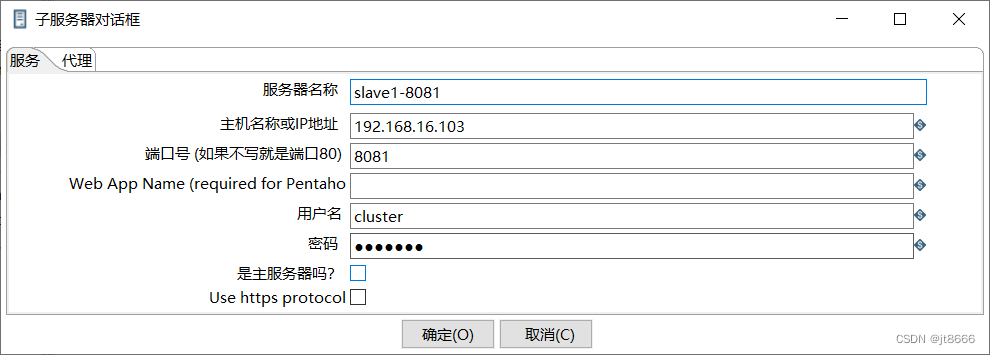
第一台从服务器配置图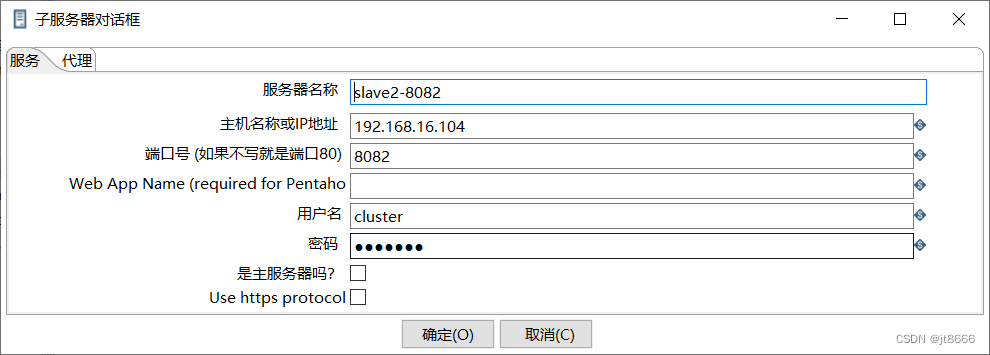
第二台从服务器配置图
2) 在主对象树中,在“kettle集群schmas”中右键,新建,点击“选择子服务器”,添加刚才新建的子服务器,然后确定。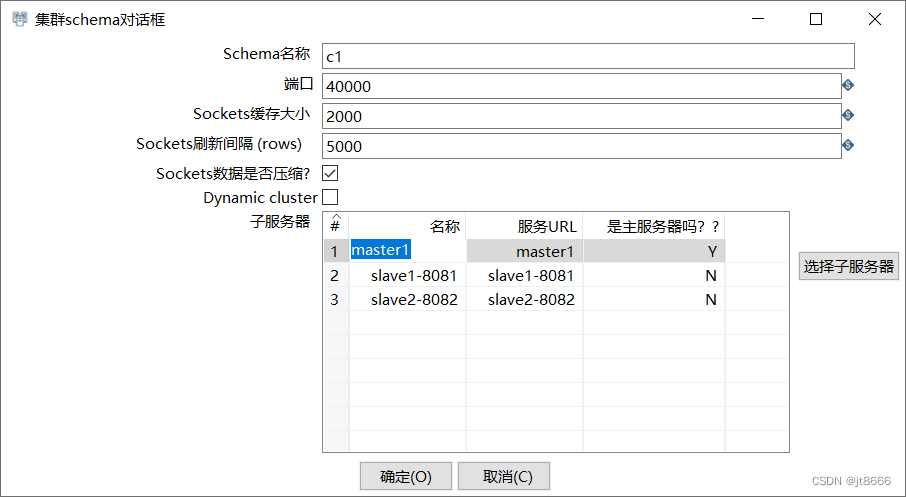
选择子服务器图
4. 设置运行参数
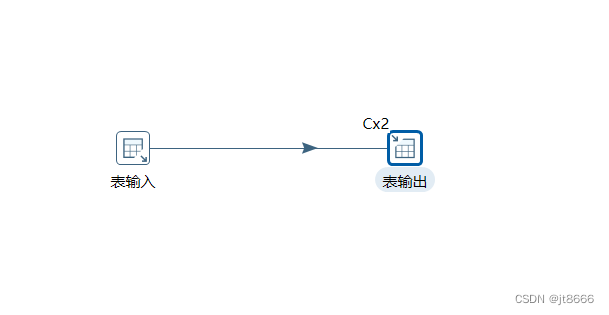
- 在步骤上右击,选择集群,然后会发现排序纪录多出”CX2”,表示有2个子服务器来执行。在一个三个子服务器的集群中,主服务器负责任务分发、结果收集,转换任务由从服务器执行,故只有两个节点执行。
- 在主对象树中,在集群-“Run Configurations”中右键,新建,新增一个参数配置。
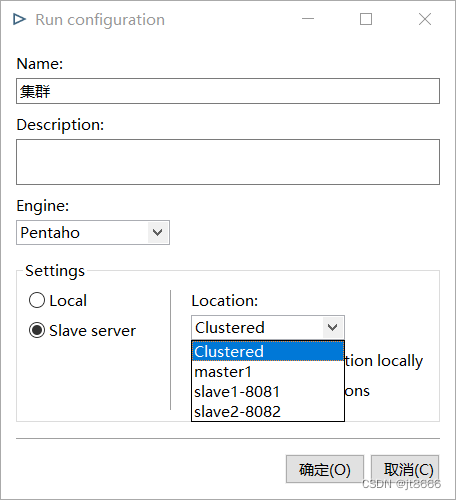
Run Configurations参数配置图
5. 运行用例
点击“运行”,运行配置选择刚刚创建的参数-“集群”,点击“启动”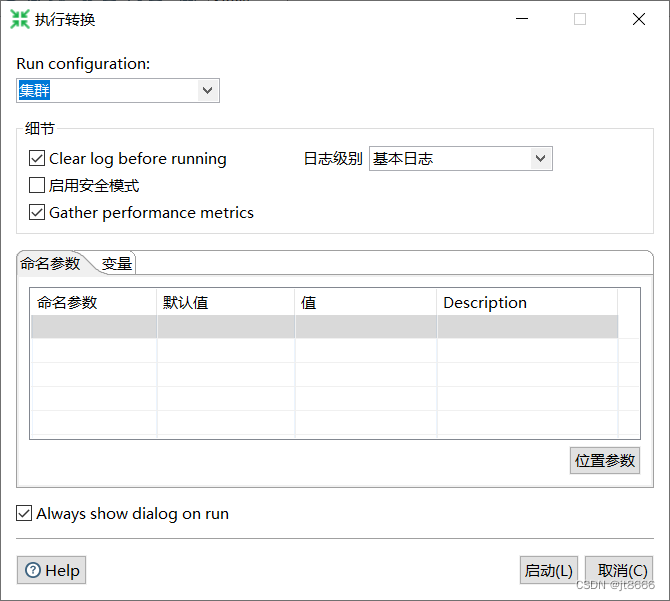
用例启动图
观察slave1和slave2后台日志,发现两个从服务器都在执行转换,主服务器没有日志,因为它只负责分发。
(1) 主服务器hadoop102上面日志信息,汇总记录总的日志信息,总共读入4677条数据,输出4677条数据。如下所示:
主服务器日志信息图
(2) 子服务器hadop103日志信息,该服务器总共读入2339条数据,输出2239条数据,如下所示:
从服务器日志信息图
(3) 子服务器hadoop104日志信息,该服务器总共读入2条数据,输出2条数据,如下所示: 从服务器日志信息图
从服务器日志信息图
(4)固定数据量子服务器的部署:
使用条件:有大数据量的数据需要处理,并且有固定的子服务器可以一直保持可连接使用(如果数据处理过程中子服务器不可用导致集群运行失败)
断开从服务器hadoop104,运行工作任务。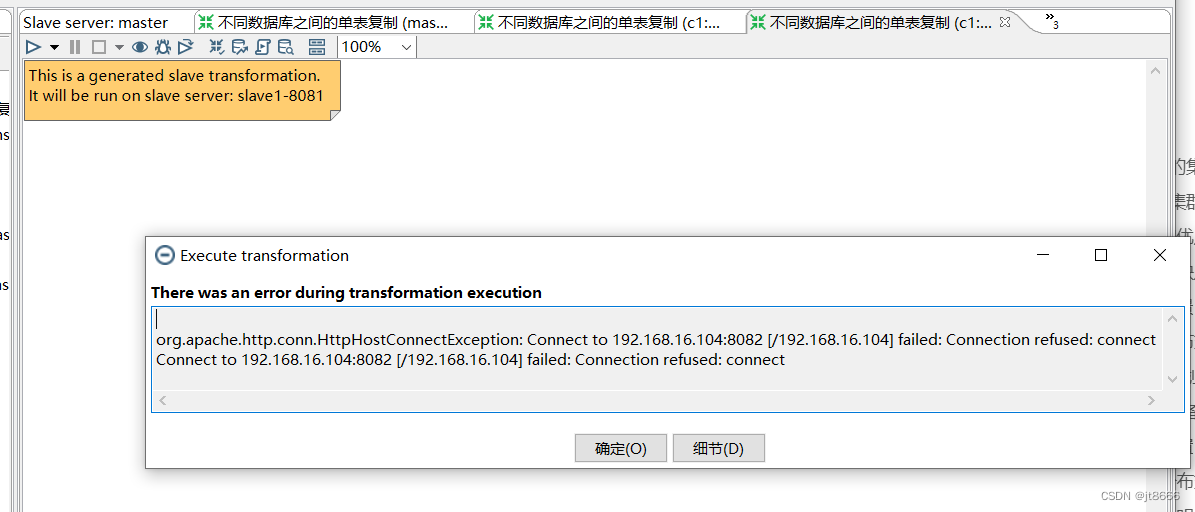
固定子服务器断开连接测试图
(5)动态集群配置
子服务器可以动态改变并没有固定数量,在带有集群的功能的作业准换运行过程中,如果子服务器断开,集群还可以继续运行直至成功。但在作业与转换启动后,如果有新的子服务器连接创建,也不会加入到正在运行的集群中。
在配置集群schemas中勾选集群,平切只选择主服务即可
动态集群配置图
“kettle集群schmas”中右键,新建,点击“选择子服务器”,添加刚才新建的子服务器,然后确定。出现CxN就是动态服务器。
点击运行之后,测试。在断开hadoop104的从服务器配置,测试运行,并不会报错正常运行。
版权归原作者 jt8666 所有, 如有侵权,请联系我们删除。