
核心指标
- SYSTEM指标 针对主机系统的监控指标具体配置详情请参考HDP官方文档 https://docs.cloudera.com/HDPDocuments/Ambari-2.7.3.0/using-ambari-core-services/content/amb_system_servers.html 1.1 指标名称 CPU的IO/WAIT 指标含义 表示在一个采样周期内有百分之几的时间属于以下情况:CPU空闲、并且有仍未完成的I/O请求. 指标图例
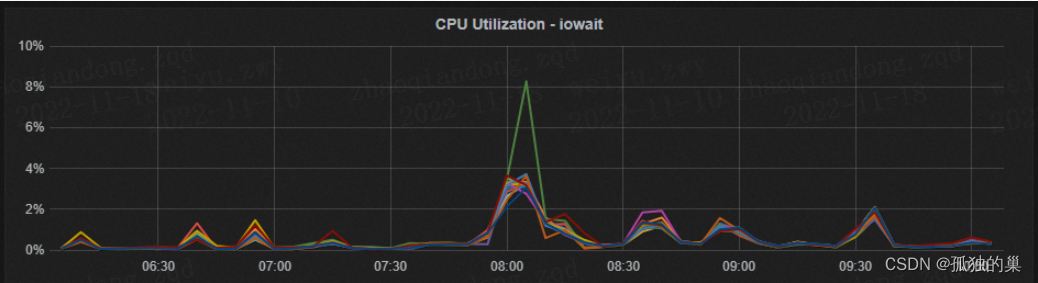
影响因素 1. 此指标的数值升高的情况,可能会导致HBASE的集群的数据查询RT升高问题,那么此时就需要关注下面的关联指标是否存在瓶颈。 关联指标 1. 磁盘指标(IO带宽、IOPS) 2. 网络指标(网络带宽、网络发送数据包) 常见误区 知识参考:http://linuxperf.com/?p=331.2 指标名称 磁盘IO带宽 指标含义 表示每秒钟磁盘读写的最大的字节数。 指标图例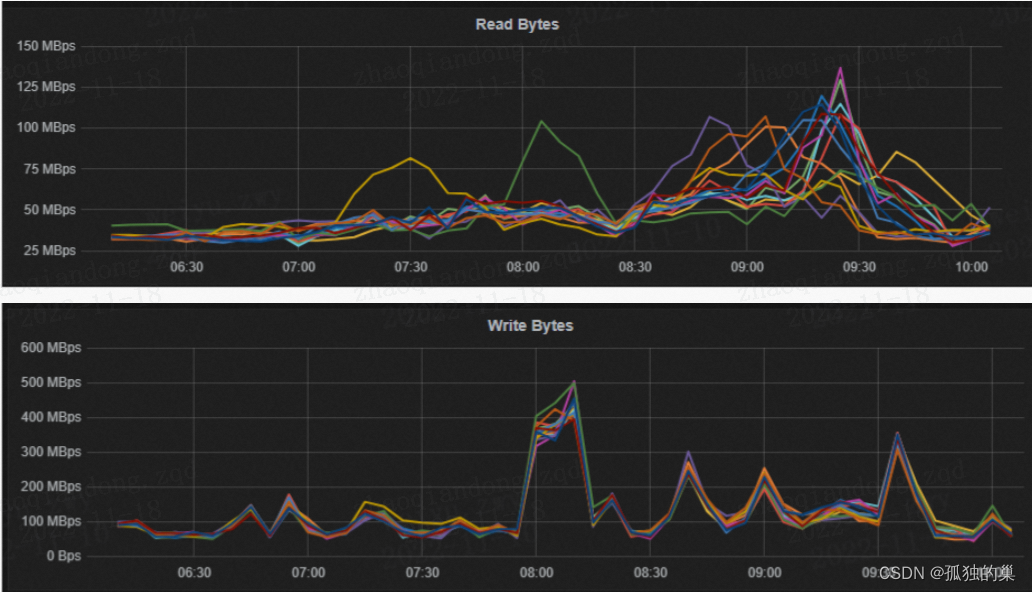
影响因素 1. 磁盘的物理机械特性。(比如磁盘的寻道时间、磁盘的缓存大小) 2. 磁盘的挂在方式。(多块磁盘做raid) 3. 磁盘的类型。(机械硬盘、SSD盘等) 关联指标 1. CPU的IOWAIT指标(任务数多,进程处于等待磁盘数据的时候,指标结果就反应异常)。 2. HBASE集群的QPS(高并发场景下的PQS大小)。 3. HBASE集群的RT(高并发场景下的请求响应时长【查询、写入】)。 4. HBASE集群的Compact任务队列长度(影响Compact任务的执行快慢,进而影响到Compact任务队列、进而影响Hbase集群QPS、RT)。
1.3 指标名称
磁盘IOPS指标
指标含义
磁盘每秒课完成的最大读写次数
指标图例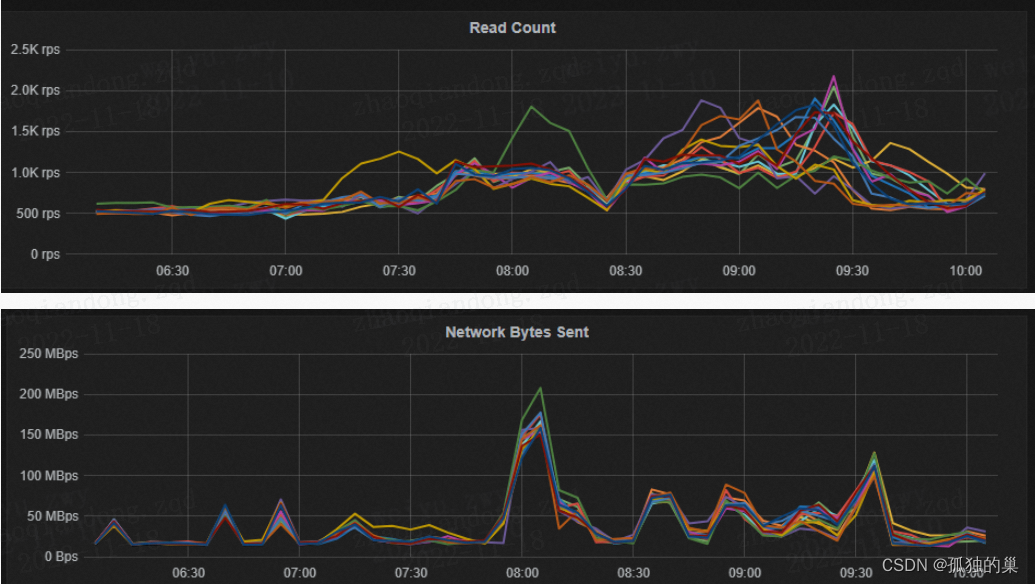
影响因素
1. 磁盘的物理机械特性。(比如磁盘的转速)
2. 磁盘的挂在方式。(多块磁盘做raid)
3. 磁盘的类型。(机械硬盘、SSD盘等)
关联指标
1. CPU的IOWAIT指标(任务数多,进程处于等待磁盘数据的时候,指标结果就反应异常)。
2. HBASE集群的QPS(高并发场景下的PQS大小)。
3. HBASE集群的RT(高并发场景下的请求响应时长【查询、写入】)。
4. HBASE集群的Compact任务队列长度(影响Compact任务的执行快慢,进而影响到Compact任务队列、进而影响Hbase集群QPS、RT)。
1.4 指标名称
网络IO带宽
指标含义
packets per second每秒发包数量。
指标图例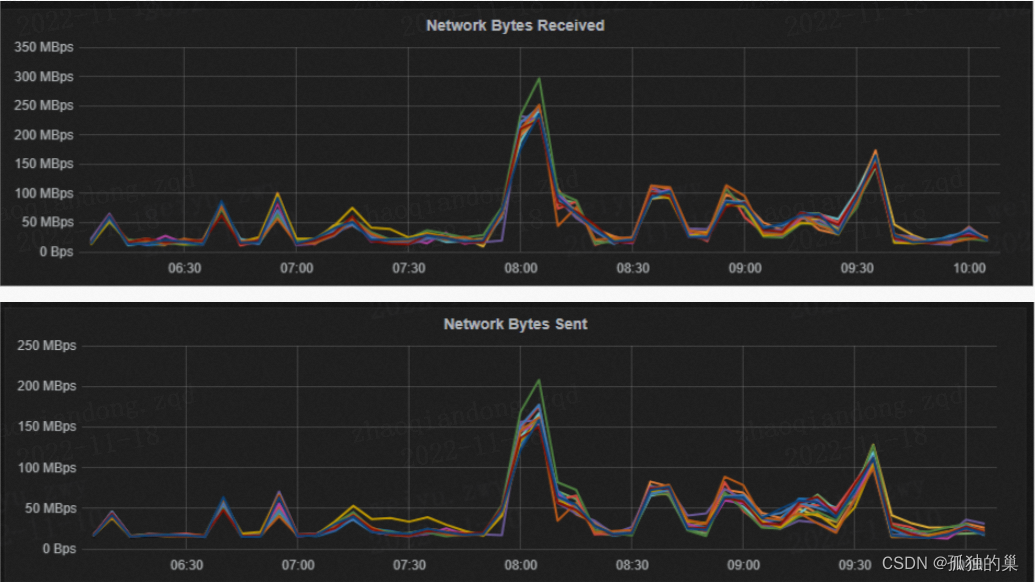
影响因素
1. 网卡的硬件参数。
2. 数据传输通道的介质相关(光纤等)。
3. 受实例负载、镜像版本、组网模型等.
关联指标
1. CPU的IOWAIT指标(任务数多,进程处于等待磁盘数据的时候,指标结果就反应异常)。
2. HBASE集群的QPS(高并发场景下的PQS大小)。
3. HBASE集群的RT(高并发场景下的请求响应时长【查询、写入】)【达到瓶颈后会出现获取大批量数据慢】。
4. HBASE集群的Compact任务队列长度(影响Compact任务的执行快慢,进而影响到Compact任务队列、进而影响Hbase集群QPS、RT)。
1.5 指标名称
网络收发数据包数
指标含义
单位时间内能够传输的数据包数量
指标图例
影响因素
1. 受实例负载、镜像版本、组网模型等。
2. 网卡的硬件参数。
关联指标
1. CPU的IOWAIT指标(任务数多,进程处于等待磁盘数据的时候,指标结果就反应异常)。
2. HBASE集群的QPS(高并发场景下的PQS大小)。
3. HBASE集群的RT(高并发场景下的请求响应时长【查询、写入】)【达到瓶颈后会出现获取大批量数据慢】。
4. HBASE集群的Compact任务队列长度(影响Compact任务的执行快慢,进而影响到Compact任务队列、进而影响Hbase集群QPS、RT)。
Hbase指标
针对HBASE的监控指标具体配置详情请参考HDP官方文档
https://docs.cloudera.com/HDPDocuments/Ambari-2.7.5.0/using-ambari-core-services/content/amb_hbase_regionservers.html
2.1. 指标名称
BlockCache
指标含义
用途:在JVM堆内存上开辟的一个HBASE 数据块,用于存储从HFILE(磁盘上文件)当中加载的数据放到内存中提高数据的查询效率。
大小:其默认大小为64KB
设置:数据块的大小直接影响着不同场景下数据检索的效率,以及内存的使用率
场景:1.大的数据块适合顺序访问(其内存利用率也高、降低了块索引的大小)
2.小的数据块适合随机访问(其内存利用率不高、块索引数据占了大量的内存)
算法:采用LRU的淘汰算法(heapsize * hfile.block.cache.size * 0.85)
分类:BlockSize:Total BlockCache size of the RegionServer
Num Blocks in Cache:Total number of hfile blocks in the BlockCache of the RegionServer
Num BlockCache Hits /s:Total number of hfile blocks in the BlockCache of the RegionServer
Num BlockCache Misses /s:Number of BlockCache misses per second in the RegionServer.
Num BlockCache Evictions /s:Number of BlockCache evictions per second in the RegionServer.
BlockCache Caching Hit Percent:Percentage of BlockCache hits per second for requests that requested cache blocks in the RegionServer.
BlockCache Hit Percent:Percentage of BlockCache hits per second in the RegionServer.
影响因素
1. 【大小】
服务器硬件内存大小。
blockcache 根据集群使用场景可进行设置。
2. 【命中率】
根据场景设置表的blocksize,提高缓存使用率,命中率。
缓存淘汰算法。
关联指标
1. HBASE集群的QPS(高并发场景下的PQS大小)。
2. HBASE集群的RT(高并发场景下的请求响应时长【查询、写入】)【达到瓶颈后会出现获取大批量数据慢】。
3. HBASE集群的Compact任务会导致(BlockCache中的数据块失效),导致数据QPS,RT波动。
2.2. 指标名称
【GET】OPERATION LATENCIES
指标含义
含义:用于采集HBASE的GET操作的延时指标。
场景:其中Get查询主要使用场景为基于Hbase的RowKey查询。
分类: Mean、Median、75th、95th、99th、Max
用途:可用于发现针对HBASE操作中,耗时操作的类型
影响因素
1.【性能】
表的RowKey设计的好坏。
数据是否在缓存中。
磁盘的性能。
网络的性能。
关联指标
1. HBASE集群的GT的QPS
2. HBASE集群的RPC - CALL QUEUED TIMES。
3. HBASE集群的Compact任务会导致(BlockCache中的数据块失效),导致数据Get操作QPS,RT波动。
4. SYSTEM相关【CPU、磁盘、网络】
2.3. 指标名称
【SCAN】OPERATION LATENCIES
指标含义
含义:用于采集HBASE的SCAN操作的延时指标。
场景:其中Get查询主要使用场景为基于Hbase的RowKey查询。
分类: Mean、Median、75th、95th、99th、Max
用途:可用于发现针对HBASE操作中,耗时操作的类型
影响因素
1.【性能】
表的RowKey设计的好坏。
数据是否在缓存中。
磁盘的性能。
网络的性能。
关联指标
1. HBASE集群的GT的QPS
2. HBASE集群的RPC - CALL QUEUED TIMES。
3. HBASE集群的Compact任务会导致(BlockCache中的数据块失效),导致数据Get操作QPS,RT波动。
4. SYSTEM相关【CPU、磁盘、网络】
2.4. 指标名称
RPC - OVERVIEW
指标含义
含义:HBASE的远程调用(RPC)监控,主要使用的协议为Google ProtoBuf和JAVA NIO
场景:主要用于Hbase Client 与Hbase master、Hbase RegionServer 之间的通信
HMaster
与Client关系:到Master的调用主要为【DDL、Sechma】操作
主要作用:为HRegionServer分配region
管理HRegionServer实现其负载均衡
发现失效的Region server并重新分配其上的region
HDFS上的垃圾文件回收
RegionServer
与Client关系:Client到RegionServer主要做一些DML操作。
主要作用:存放和管理本地HRegion,并负责切分正在运行过程中变的过大的region
维护HRegion,处理HRegion的IO请求,向HDFS文件系统中读写数据
分类:
Num RPC /s:Number of RPCs per second in the RegionServer.
Num Active Handler Threads:Number of active RPC handler threads (to process requests) in the RegionServer
Num Connections:Number of connections to the RegionServer.
用途:
主要用于发现HBASE集群的负载(集群整体的RPC操作、单个服务器负载、是否有数据热点等)。
影响因素
1. 系统维度
1.1 【Region】Hregion在RegionServer上的分配策略,导致HRegion在不同RegionServer的数量不一致。
1.2 【数据】数据查询请求包含数据热点。
1.3 【访问方式】GET请求/SCAN请求导致查询的数据量差异(影响缓存)。
1.4 【操作系统】操作系统的内核参数设置。
2. 整体硬件
2.1 RegionServer服务器的整体硬件配置(CPU、内存、磁盘、网络)。
关联指标
1. HBASE集群的GET的QPS。
2. HBASE集群的SCAN的QPS。
3. RegionServer服务器磁盘的性能。
4. RegionServer服务器网络的性能。
2.5. 指标名称
RPC - CALL PROCESS TIMES
指标含义
含义:表示RegionServer处理客户端RPC调用的耗时。
场景:比如客户端通过RPC调用进行数据的操作比如(GET、SCAN、DELETE等)。
分类:RPC - Call Process Time - Mean、RPC - Call Process Time - Median、RPC - Call Process Time - 75th、RPC - Call Process Time - 95th、RPC - Call Process Time - 99th、RPC - Call Process Time - Max
用途:主要用于评估当前集群的健康状况。
影响因素
1. 用户对数据操作的类型占比,比如(GET、SCAN)。
2. 表数据的分布情况。比如(数据分布不均匀,导致数据热点,进而导致部分服务器压力过大,导致服务器过载)。
3. Region在集群中分配策略,影响
ByRegion:按照region总数均匀的分配到集群当中。
ByTable:按照集群规模、表的Region数在集群中均匀分布。
4. 内存(大小,频率),影响热数据的存放时间。
5. 磁盘性能(带宽、OIPS),影响查询获取冷数据的提取效率。
6. 网络带宽(带宽、收发包),影响数据数据的传输效率。
7. CPU(主频、核心数),影响数据的压缩、解压。
关联指标
1. HBASE集群RPC (OVERVIEW、GET、SCAN)
2. HBASE集群BLOCKCACHE(OVERVIEW、HITS/MISSES)
3. HBASE集群COMPACTION
4. CPU的(IOWAIT、LOAD、USER)
5. DISK的(IO、IOPS)
6. NETWORK(IO、PACKETS)
2.6. 指标名称
COMPACTION QUEUES
指标含义
含义:Hbase表的Compaction任务队列。
场景:主要用于对表做数据文件的合并,提升数据的读效率。
分类:MINI COMPACTION、MAJOR COMPACTION。
用途:通过对集群中的数据表定期/周期性的做COMPACTION清理表中的无效数据、并且将小的HFILE文件合并成大的HFILE提高Hbase的查询效率。
影响因素
1. HBASE集群参数
1.1 COMPACTION 线程数(small、large)。
1.2 COMPACTION 限速(lower、higher)。
1.3 COMPACTION 合并文件数(min、max)。
1.4 COMPACTION KV数量(每次从Hfile中读取kv的个数)。
2. 硬件层面
2.1 CPU(主频、核心数),影响数据的压缩、解压。
2.2 磁盘性能(带宽、OIPS),影响查询获取冷数据的提取效率。
2.3 网络带宽(带宽、收发包),影响数据数据的传输效率。
2.4 网络带宽(带宽、收发包),影响数据数据的传输效率。
关联指标
1. HBASE集群BLOCKCACHE(OVERVIEW、HITS/MISSES)。
2. HBASE集群RPC - CALL PROCESS TIMES。
3. CPU的(IOWAIT、LOAD、USER)。
4. DISK的(IO、IOPS)。
5. NETWORK(IO、PACKETS)。
常见误区
1. 合理的安排表的Compaction的时间。
2. 并且不是Compaction执行越快越好。
版权归原作者 孤独的巢 所有, 如有侵权,请联系我们删除。