
三种通用JOIN策略原理
Hash Join 散列连接
Hash join散列连接是CBO 做大数据集连接时的常用方式,优化器使用两个表中较小的表(通常是小一点的那个表或数据源)利用连接键(JOIN KEY)在内存中建立散列表,将列数据存储到hash列表中,然后扫描较大的表,同样对JOIN KEY进行HASH后探测散列表,找出与散列表匹配的行。需要注意的是:如果HASH表太大,无法一次构造在内存中,则分成若干个partition,写入磁盘,则会多一个写的代价,会降低效率。
这种方式适用于较小的表完全可以放于内存中的情况,这样总成本就是访问两个表的成本之和。但是在表很大的情况下并不能完全放入内存,这时优化器会将它分割成若干不同的分区,不能放入内存的部分就把该分区写入磁盘的临时段,此时要有较大的临时段从而尽量提高I/O 的性能。
仅支持等值连接,不支持全外连接(full outer joins)。
原理详解
问题背景
连接(join)是数据库表之间的常用操作,通过把多个表之间某列相等的元组提取出来组成新的表。两个表若是元组数目过多,逐个遍历开销就很大,哈希连接就是一种提高连接效率的方法。
哈希连接主要分为两个阶段:建立阶段(build phase)和探测阶段(probe phase)
Bulid Phase
选择一个表(一般情况下是较小的那个表,以减少建立哈希表的时间和空间),对其中每个元组上的连接属性(join attribute)采用哈希函数得到哈希值,从而建立一个哈希表。
Probe Phase
对另一个表,扫描它的每一行并计算连接属性的哈希值,与bulid phase建立的哈希表对比,若有落在同一个bucket的,如果满足连接谓词(predicate)则连接成新的表。
在内存足够大的情况下建立哈希表的过程时整个表都在内存中,完成连接操作后才放到磁盘里。但这个过程也会带来很多的I/O操作。
另一种哈希连接:Grace hash join
这个方法适合用于内存不足的情况,核心在于分块处理
第一阶段分块阶段(Partition Phase):把每个关系(relation)分别用同一个哈希函数h(x)在连接属性上进行分块(partition)。分块后每个元组分配到对应的bucket,然后分别把这些buckets写到磁盘当中。
第二阶段和普通的哈希连接类似,将分别来自于两个关系对应的bucket加载到内存中,为较小的那个bucket构建哈希表(注意,这里一定要用不同的哈希函数,因为数据很多的情况下不同值的哈希值可能相同,但不同值的两个哈希值都相同可能性非常小)

也有可能出现一个或多个bucket仍无法写入到内存的情况,这时可递归对每一个bucket采用该算法。与此同时这会增加很多时间,所以最好尽可能通过选择合理的哈希函数形成小的bucket来减少这种情况的发生。
Sort Merge Join 排序合并连接
Merge Join 是先将关联表的关联列各自做排序,然后从各自的排序表中抽取数据,到另一个排序表中做匹配。
因为merge join需要做更多的排序,所以消耗的资源更多。 通常来讲,能够使用merge join的地方,hash join都可以发挥更好的性能,即散列连接的效果都比排序合并连接要好。然而如果行源已经被排过序,在执行排序合并连接时不需要再排序了,这时排序合并连接的性能会优于散列连接。
Sort Merge Join和Shuffle Hash Join类似,会有一个Shuffle阶段,将key相同的记录重分配同一个executor上,不同的是,在每个executor上,不再构造哈希表,而是对两个分区进行排序,然后用两个下标同时遍历两个分区,如果两个下标指向的记录key相同,则输出这两条记录,否则移动key较小的下标。
对于排序合并连接的优缺点及适用场景如下:
- 通常情况下,排序合并连接的执行效率远不如哈希连接,但前者的使用范围更广,因为哈希连接只能用于等值连接条件,而排序合并连接还能用于其他连接条件(如<,<=,>.>=) - 排序合并连接不适用于的连接条件是:不等于<>,like- 大于>,小于<,大于等于>=,小于等于<=,是可以适用于排序合并连接
- 通常情况下,排序合并连接并不适合OLTP类型的系统,其本质原因是对于因为OLTP类型系统而言,排序是非常昂贵的操作,当然,如果能避免排序操作就例外了。
Nested Loop 嵌套循环连接
Nested loop 工作方式是循环从一张表中读取数据(驱动表outer table),然后访问另一张表(被查找表 inner table)。驱动表中的每一行与inner表中的相应记录JOIN。类似一个嵌套的循环。
影响JOIN操作的因素
数据集的大小
参与JOIN的数据集的大小会直接影响Join操作的执行效率。同样,也会影响JOIN机制的选择和JOIN的执行效率。
JOIN的条件
JOIN的条件会涉及字段之间的逻辑比较。根据JOIN的条件,JOIN可分为两大类:等值连接和非等值连接。等值连接会涉及一个或多个需要同时满足的相等条件。在两个输入数据集的属性之间应用每个等值条件。当使用其他运算符(运算连接符不为**=**)时,称之为非等值连接。
JOIN的类型
在输入数据集的记录之间应用连接条件之后,JOIN类型会影响JOIN操作的结果。主要有以下几种JOIN类型:
- 内连接(Inner Join):仅从输入数据集中输出匹配连接条件的记录。
- 外连接(Outer Join):又分为左外连接、右外链接和全外连接。
- 半连接(Semi Join):右表只用于过滤左表的数据而不出现在结果集中。
- 交叉连接(Cross Join):交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积。
Spark中JOIN执行的5种策略
Spark提供了5种JOIN机制来执行具体的JOIN操作。该5种JOIN机制如下所示:
- Shuffle Hash Join
- Broadcast Hash Join
- Sort Merge Join
- Cartesian Join
- Broadcast Nested Loop Join
Shuffle Hash Join
当两个数据集都小于可以使用Broadcast Hash Join的阈值时,采用Shuffle Join,先对两个数据集进行Shuffle,Shuffle是意思是根据key的哈希值,对两个数据集进行重新分区,使得两个数据集中key的哈希值相同的记录会被分配到同一个executor上,此时在每个executor上的分区都足够小,各个executor分别执行Hash Join即可。
Shuffle操作会带来大量的网络IO开销,因此效率会受到影响。同时,在executor的内存使用方面,如果executor的数量足够多,每个分区处理的数据量可以控制到比较小。
当要JOIN的表数据量比较大时,可以选择Shuffle Hash Join。这样可以将大表进行按照JOIN的key进行重分区,保证每个相同的JOIN key都发送到同一个分区中。如下图示:
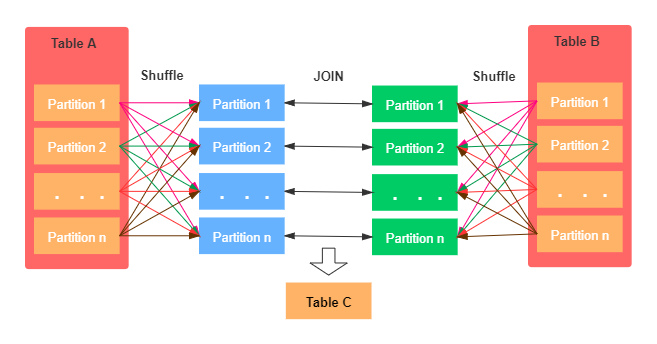
如上图所示:Shuffle Hash Join的基本步骤主要有以下两点:
- 首先,对于两张参与JOIN的表,分别按照join key进行重分区,该过程会涉及Shuffle,其目的是将相同join key的数据发送到同一个分区,方便分区内进行join。
- 其次,对于每个Shuffle之后的分区,会将小表的分区数据构建成一个Hash table,然后根据join key与大表的分区数据记录进行匹配。
条件与特点
- 仅支持等值连接,join key不需要排序
- 支持除了全外连接(full outer joins)之外的所有join类型:Hash Join的特性所决定的。
- 需要对小表构建Hash map,属于内存密集型的操作,如果构建Hash表的一侧数据比较大,可能会造成OOM
- 将参数*spark.sql.join.prefersortmergeJoin (default true)*置为false
Broadcast Hash Join
当其中一个数据集足够小时,采用Broadcast Hash Join,较小的数据集会被广播到所有Spark的executor上,并转化为一个Hash Table,之后较大数据集的各个分区会在各个executor上与Hash Table进行本地的Join,各分区Join的结果合并为最终结果。
Broadcast Hash Join 没有Shuffle阶段、效率最高。但为了保证可靠性,executor必须有足够的内存能放得下被广播的数据集,所以当进两个数据集的大小都超过一个可配置的阈值之后,Spark不会采用这种Join。控制这个阈值的参数为
spark.sql.autoBroadcastJoinThreshold,最新版本(3.0.1)中默认值为10M。
Broadcast Hash Join也称之为Map端JOIN。当有一张表较小时,我们通常选择Broadcast Hash Join,这样可以避免Shuffle带来的开销,从而提高性能。比如事实表与维表进行JOIN时,由于维表的数据通常会很小,所以可以使用Broadcast Hash Join将维表进行Broadcast。这样可以避免数据的Shuffle(在Spark中Shuffle操作是很耗时的),从而提高JOIN的效率。在进行 Broadcast Join 之前,Spark 需要把处于 Executor 端的数据先发送到 Driver 端,然后 Driver 端再把数据广播到 Executor 端。如果我们需要广播的数据比较多,会造成 Driver 端出现 OOM。具体如下图示:
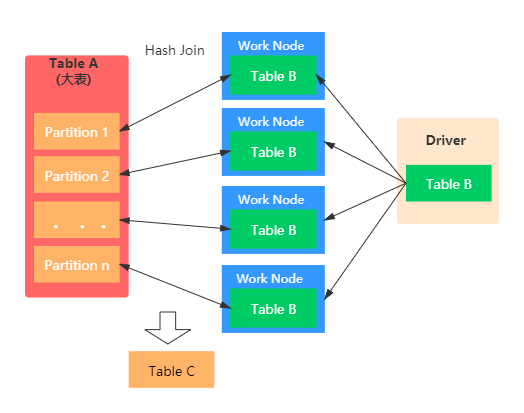
Broadcast Hash Join主要包括两个阶段:
- Broadcast阶段 :小表被缓存在executor中
- Hash Join阶段:在每个 executor中执行Hash Join
条件与特点
- 仅支持等值连接,join key不需要排序
- 支持除了全外连接(full outer joins)之外的所有join类型:Hash Join的特性所决定的。
- Broadcast Hash Join相比其他的JOIN机制而言,效率更高。但是,Broadcast Hash Join属于网络密集型的操作(数据冗余传输),除此之外,需要在Driver端缓存数据,所以当小表的数据量较大时,会出现OOM的情况
- 被广播的小表的数据量要小于spark.sql.autoBroadcastJoinThreshold值,默认是10MB(10485760)
- 被广播表的大小阈值不能超过8GB,spark2.4源码如下:BroadcastExchangeExec.scala
longMetric("dataSize") += dataSize
if (dataSize >= (8L << 30)) {
throw new SparkException(
s"Cannot broadcast the table that is larger than 8GB: ${dataSize >> 30} GB")
}
- 基表不能被broadcast,比如左连接时,只能将右表进行广播。形如:fact_table.join(broadcast(dimension_table),可以不使用broadcast提示,当满足条件时会自动转为该JOIN方式。
Sort Merge Join
该JOIN机制是Spark默认的,可以通过参数spark.sql.join.preferSortMergeJoin进行配置,默认是true,即优先使用Sort Merge Join。一般在两张大表进行JOIN时,使用该方式。Sort Merge Join可以减少集群中的数据传输,该方式不会先加载所有数据的到内存,然后进行hashjoin,但是在JOIN之前需要对join key进行排序。
Sort Merge Join和Shuffle Hash Join类似,会有一个Shuffle阶段,将key相同的记录重分配同一个executor上,不同的是,在每个executor上,不再构造哈希表,而是对两个分区进行排序,然后用两个下标同时遍历两个分区,如果两个下标指向的记录key相同,则输出这两条记录,否则移动key较小的下标。
Sort Merge Join也有Shuffle阶段,因此效率同样不如Broadcast Hash Join。在内存使用方面,因为不需要构造哈希表,需要的内存比Hash Join要少。
具体图示:
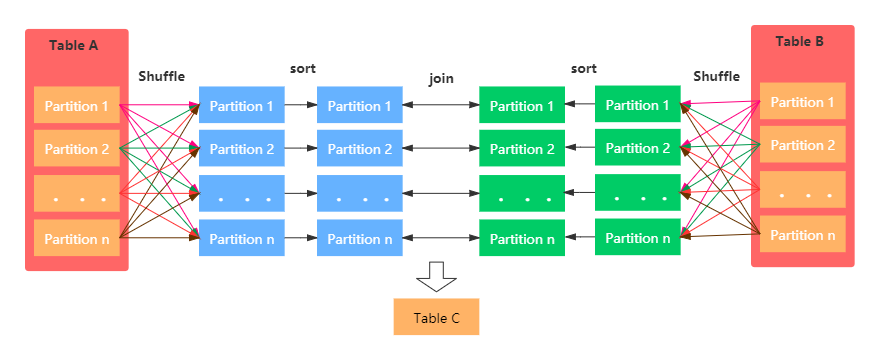
Sort Merge Join主要包括三个阶段:
- Shuffle Phase : 两张大表根据Join key进行Shuffle重分区
- Sort Phase: 每个分区内的数据进行排序
- Merge Phase: 对来自不同表的排序好的分区数据进行JOIN,通过遍历元素,连接具有相同Join key值的行来合并数据集
条件与特点
- 仅支持等值连接
- 支持所有join类型
- Join Keys是排序的
- 参数**spark.sql.join.prefersortmergeJoin (默认true)**设定为true
Cartesian Join
如果 Spark 中两张参与 Join 的表没指定join key(ON 条件)那么会产生 Cartesian product join,这个 Join 得到的结果其实就是两张行数的乘积。
Cartesian Join机制专门用来实现cross join,结果的分区数等于输入数据集的分区数之积,结果中每一个分区的数据对应一个输入数据集的一个分区和另外一个输入数据集的一个分区。
Cartesian Join会产生非常多的分区,但如果要进行cross join,别无选择。
条件
- 仅支持内连接
- 开启参数spark.sql.crossJoin.enabled=true
Broadcast Nested Loop Join
Broadcast Nested Join将一个输入数据集广播到每个executor上,然后在各个executor上,另一个数据集的分区会和第一个数据集使用嵌套循环的方式进行Join输出结果。
Broadcast Nested Join需要广播数据集和嵌套循环,计算效率极低,对内存的需求也极大,因为不论数据集大小,都会有一个数据集被广播到所有executor上。
该方式是在没有合适的JOIN机制可供选择时,最终会选择该种join策略。优先级为:
Broadcast Hash Join > Shuffle Hash Join > Sort Merge Join > Cartesian Join > Broadcast Nested Loop Join.
在Cartesian 与Broadcast Nested Loop Join之间,如果是内连接,或者非等值连接,则优先选择Broadcast Nested Loop策略,当时非等值连接并且一张表可以被广播时,会选择Cartesian Join。
条件与特点
- 支持等值和非等值连接
- 支持所有的JOIN类型,主要优化点如下: - 当右外连接时要广播左表- 当左外连接时要广播右表- 当内连接时,要广播左右两张表
Spark如何选择JOIN策略
等值连接的情况
有join提示(hints)的情况,按照下面的顺序
- 1.Broadcast Hint:如果join类型支持,则选择broadcast hash join
- 2.Sort merge hint:如果join key是排序的,则选择 sort-merge join
- 3.shuffle hash hint:如果join类型支持, 选择 shuffle hash join
- 4.shuffle replicate NL hint: 如果是内连接,选择笛卡尔积方式
没有join提示(hints)的情况,则逐个对照下面的规则
- 1.如果join类型支持,并且其中一张表能够被广播(spark.sql.autoBroadcastJoinThreshold值,默认是10MB),则选择 broadcast hash join
- 2.如果参数spark.sql.join.preferSortMergeJoin设定为false,且一张表足够小(可以构建一个hash map) ,则选择shuffle hash join
- 3.如果join keys 是排序的,则选择sort-merge join
- 4.如果是内连接,选择 cartesian join
- 5.如果可能会发生OOM或者没有可以选择的执行策略,则最终选择broadcast nested loop join
非等值连接情况
有join提示(hints),按照下面的顺序
- 1.broadcast hint:选择broadcast nested loop join.
- 2.shuffle replicate NL hint: 如果是内连接,则选择cartesian product join
没有join提示(hints),则逐个对照下面的规则
- 1.如果一张表足够小(可以被广播),则选择 broadcast nested loop join
- 2.如果是内连接,则选择cartesian product join
- 3.如果可能会发生OOM或者没有可以选择的执行策略,则最终选择broadcast nested loop join
object JoinSelection extends Strategy
with PredicateHelper
with JoinSelectionHelper {
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
case j @ ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, nonEquiCond, left, right, hint) =>
def createBroadcastHashJoin(onlyLookingAtHint: Boolean) = {
getBroadcastBuildSide(left, right, joinType, hint, onlyLookingAtHint, conf).map {
buildSide =>
Seq(joins.BroadcastHashJoinExec(
leftKeys,
rightKeys,
joinType,
buildSide,
nonEquiCond,
planLater(left),
planLater(right)))
}
}
def createShuffleHashJoin(onlyLookingAtHint: Boolean) = {
getShuffleHashJoinBuildSide(left, right, joinType, hint, onlyLookingAtHint, conf).map {
buildSide =>
Seq(joins.ShuffledHashJoinExec(
leftKeys,
rightKeys,
joinType,
buildSide,
nonEquiCond,
planLater(left),
planLater(right)))
}
}
def createSortMergeJoin() = {
if (RowOrdering.isOrderable(leftKeys)) {
Some(Seq(joins.SortMergeJoinExec(
leftKeys, rightKeys, joinType, nonEquiCond, planLater(left), planLater(right))))
} else {
None
}
}
def createCartesianProduct() = {
if (joinType.isInstanceOf[InnerLike]) {
Some(Seq(joins.CartesianProductExec(planLater(left), planLater(right), j.condition)))
} else {
None
}
}
def createJoinWithoutHint() = {
createBroadcastHashJoin(false)
.orElse {
if (!conf.preferSortMergeJoin) {
createShuffleHashJoin(false)
} else {
None
}
}
.orElse(createSortMergeJoin())
.orElse(createCartesianProduct())
.getOrElse {
val buildSide = getSmallerSide(left, right)
Seq(joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), buildSide, joinType, nonEquiCond))
}
}
createBroadcastHashJoin(true)
.orElse { if (hintToSortMergeJoin(hint)) createSortMergeJoin() else None }
.orElse(createShuffleHashJoin(true))
.orElse { if (hintToShuffleReplicateNL(hint)) createCartesianProduct() else None }
.getOrElse(createJoinWithoutHint())
if (canBuildLeft(joinType)) BuildLeft else BuildRight
}
def createBroadcastNLJoin(buildLeft: Boolean, buildRight: Boolean) = {
val maybeBuildSide = if (buildLeft && buildRight) {
Some(desiredBuildSide)
} else if (buildLeft) {
Some(BuildLeft)
} else if (buildRight) {
Some(BuildRight)
} else {
None
}
maybeBuildSide.map { buildSide =>
Seq(joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), buildSide, joinType, condition))
}
}
def createCartesianProduct() = {
if (joinType.isInstanceOf[InnerLike]) {
Some(Seq(joins.CartesianProductExec(planLater(left), planLater(right), condition)))
} else {
None
}
}
def createJoinWithoutHint() = {
createBroadcastNLJoin(canBroadcastBySize(left, conf), canBroadcastBySize(right, conf))
.orElse(createCartesianProduct())
.getOrElse {
Seq(joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), desiredBuildSide, joinType, condition))
}
}
createBroadcastNLJoin(hintToBroadcastLeft(hint), hintToBroadcastRight(hint))
.orElse { if (hintToShuffleReplicateNL(hint)) createCartesianProduct() else None }
.getOrElse(createJoinWithoutHint())
case _ => Nil
}
}
Spark如何选择Join机制
Spark根据以下的因素选择实际执行Join的机制:
- 参数配置
- hint参数
- 输入数据集大小
- Join类型
- Join条件
其中,hint参数是一种在join时手动指定join机制的方法,例如:
df1.hint("broadcast").join(df2, ...)
下面介绍在什么情况下使用何种Join机制。
何时使用Broadcast Hash Join
必需条件:
- 只用于等值Join
- 不能用于Full Outer Join
以下条件需要满足一个:
- 左边的数据集使用了broadcast hint,Join类型是Right Outer,Right Semi或Inner
- 没使用hint,但左边的数据集小于
spark.sql.autoBroadcastJoinThreshold参数,Join类型是Right Outer,Right Semi或Inner - 右边的数据集使用了broadcast hint,Join类型是Left Outer,Left Semi或Inner
- 没使用hint,但右边的数据集小于
spark.sql.autoBroadcastJoinThreshold参数,Join类型是Left Outer,Left Semi或Inner - 两个数据集都使用了broadcast hint,Join类型是Left Outer,Left Semi,Right Outer,Right Semi或Inner
- 没使用hint,但两个数据集都小于
spark.sql.autoBroadcastJoinThreshold参数,Join类型是Left Outer,Left Semi,Right Outer,Right Semi或Inner
何时使用Shuffle Hash Join
必需条件:
- 只用于等值Join
- 不能用于Full Outer Join
spark.sql.join.prefersortmergeJoin参数默认值为true,设置为false
以下条件需要满足一个:
- 左边的数据集使用了shuffle_hash hint,Join类型是Right Outer,Right Semi或Inner
- 没使用hint,但左边的数据集比右边的数据集显著小,Join类型是Right Outer,Right Semi或Inner
- 右边的数据集使用了shuffle_hash hint,Join类型是Left Outer,Left Semi或Inner
- 没使用hint,但右边的数据集比左边的数据集显著小,Join类型是Left Outer,Left Semi或Inner
- 两边的数据集都使用了shuffle_hash hint,Join类型是Left Outer,Left Semi,Right Outer,Right Semi或Inner
- 没使用hint,两个数据集都比较小,Join类型是Left Outer,Left Semi,Right Outer,Right Semi或Inner
何时使用Sort Merge Join
必需条件:
- 只用于等值Join
- Join条件中的key是可排序的
spark.sql.join.prefersortmergeJoin参数默认值为true,设置为true
以下条件需要满足一个:
- 有一个数据集使用了merge hint,Join类型任意
- 没有使用merge hint,Join类型任意
何时使用Cartesian Join
必需条件:
- Cross Join
以下条件需要满足一个:
- 使用了shuffle_replicate_nl hint,是等值或不等值Join均可
- 没有使用hint,等值或不等值Join均可
何时Broadcast Nested Loop Join
Broadcast Nested Loop Join是默认的Join机制,当没有选用其他Join机制被选择时,用它来进行任意条件任意类型的Join。
当有多种Join机制可用时,选择的优先级为Broadcast Hash Join > Sort Merge Join > Shuffle Hash Join > Cartesian Join。
在进行Inner Join和不等值Join时,如果有一个数据集可以被广播,Broadcast Nested Loop Join的优先级比Cartesian Join优先级高。
版权归原作者 话数Science 所有, 如有侵权,请联系我们删除。