
利用selenium爬取Twitter
从2月9日起,Twitter不再支持免费访问Twitter API,继续使用Twitter API支付较高的费用。下面将介绍一种绕过Twitter API爬取推文的方式
Selenium Webdriver框架
首先介绍一下Selenium Webdriver,这是一款web自动化测试框架,可以利用它在web浏览器上模拟。下面演示下在python中如何引入selenium模块
from selenium import webdriver
实例化配置对象
options = webdriver.ChromeOptions()
配置对象开启无界面模式
options.add_argument("--headless")
实例化带有配置对象的driver对象
driver = webdriver.Chrome('chromedriver', options=options)
进入Twitter页面
Twitter首页 Twitter首页
driver.get('https://twitter.com/home')
登陆Twitter
先在网页上登陆自己的twitter账号,然后把cookies取出来并
cookies=[]#你的cookiesfor cookie in cookies:
driver.add_cookie(cookie)
接下来就可以自由访问twitter啦
爬取Twitter
url =f"https://twitter.com/search?q=hello&src=typed_query"
driver.get(url)
利用BeautifulSoup对网页进行分析
from bs4 import BeautifulSoup
html = driver.page_source
soup = BeautifulSoup(html,"html.parser")
F12查看网页源码,可以看到每条推文的内容都写在红框标出来的区域里面
因此,我们先找出所有为这个属性的元素
tweets = soup.find_all("div",{'data-testid':"cellInnerDiv"})
然后我们再继续找推文内容的属性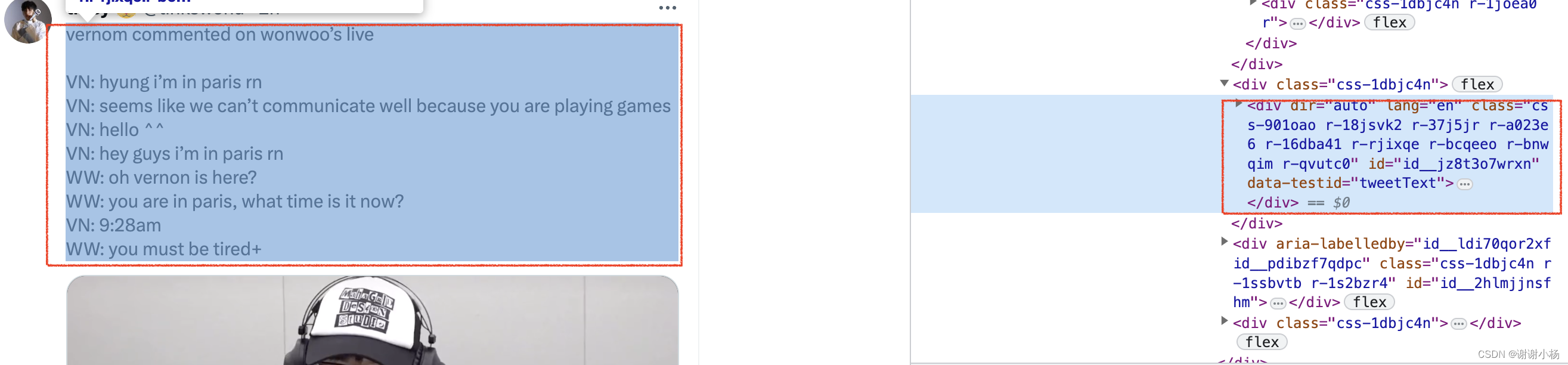
提取推文内容
for tweet in tweets:
content = container.find('div',{'data-testid':"tweetText"}).text
print(content)
本文转载自: https://blog.csdn.net/qq_33828485/article/details/131362819
版权归原作者 谢谢小杨 所有, 如有侵权,请联系我们删除。
版权归原作者 谢谢小杨 所有, 如有侵权,请联系我们删除。