
本文来源:知乎
大家好,我是脚丫先生 (o^^o)
最近小伙伴们,有问到大数据工程师岗位平常的日常工作都是干嘛的?

大数据或者说想入门大数据,技术肯定是第一重要的,不会大数据的技术谈什么大数据。那么大数据的技术怎么学,要知道大数据是依赖Java的,首先要保证Java得会。
一个项目一般包含:前端,后端,后后端,大数据属于后后端,是在项目开发完成之后有了数据之后才到大数据这一步。从上帝视角看张图:
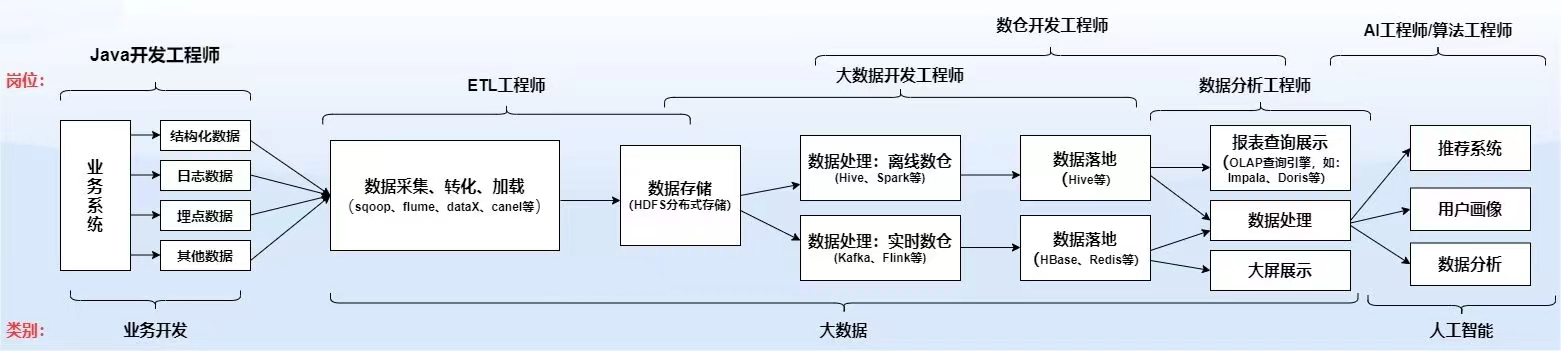
大数据工作分为图上这几种,和后端接触的是ETL工程师,负责将数据拿到大数据平台,然后供数仓开发工程师使用,大数据开发负责大数据平台的建设,后面还有数据分析师,AI工程师等。
一、数仓工程师 (全称:数据仓库工程师)
数仓工程师日常工作一般是不写代码的,主要以写 SQL 为主!
数仓工程师是大数据领域公司招聘较多的岗位,薪资也较高,需要重点关注!数据仓库分为离线数仓和实时数仓,但是企业在招聘时大多要求两者都会,进入公司之后可能会专注于离线或实时其中之一。
就目前来说,大多数的企业还是以离线数仓为主,不过未来趋势肯定是实时数仓为主,所以学习时,为了现在能找到工作,需要学习离线数仓,为了以后的发展,需要学习实时数仓。
所以,离线和实时都是我们重点掌握的!需要掌握的技能:
不管离线还是实时,重中之重就是:SQL****
SQL 语法及调优一定要掌握,这里说的SQL包括mysql中的 sql,hive中的 hive sql,spark中的spark sql,flink中的 flink sql。
在企业招聘的笔记及面试中,一般问的关于 sql 的问题主要是以 hive sql 为主,所以请重点关注!
除sql外,还需要重点掌握以下技能,分为离线和实时
离线数仓需要重点掌握的技能:
- Hadoop(HDFS,MapReduce,YARN)
- Hive(重点,包括hive底层原理,hive SQL及调优)
- Spark(Spark 会用及了解底层原理)
- Oozie(调度工具,会用即可)离线数仓建设(搭建数仓,数仓建模规范)维度建模(建模方式常用的有范式建模和维度建模,重点关注维度建模)
实时数仓需要重点掌握的技能:
- Hadoop(这是大数据基础,不管离线和实时都必须掌握)
- Kafka(重点,大数据领域中算是唯一的消息队列)
- Flink(重中之重,这个不用说了,实时计算框架中绝对王者)
- HBase(会使用,了解底层原理)
- Druid(会用,了解底层原理)
- 实时数仓架构(两种数仓架构:Lambda架构和Kappa架构)
二、大数据开发工程师
数据开发工程师一般是以写代码为主,以 Java 和 Scala 为主。
大数据开发分两类,第一类是编写Hadoop、Spark、Flink 的应用程序,第二类是对大数据处理系统本身进行开发,如对开源框架的扩展开发,数据中台的开发等!
需要重点掌握的技能:
- 语言:Java 和 Scala(语言以这两种为主,需要重点掌握)
- Linux(需要对Linux有一定的理解)
- Hadoop(需理解底层,能看懂源码)
- Hive(会使用,能进行二次开发)
- Spark(能进行开发。对源码有了解)
- Kafka(会使用,理解底层原理)
- Flink(能进行开发。对源码有了解)
- HBase(理解底层原理)
通过以上技能,我们也能看出,数据开发和数仓开发的技能重复率较高,所以很多公司招聘时 大数据开发和数仓建设分的没有这么细,数据开发包含了数仓的工作!
三、ETL工程师
ETL是三个单词的首字母,中文意思是抽取、转换、加载从开始的图中也能看出,ETL工程师是对接业务和数据的交接点,所以需要处理上下游的关系对于上游,需要经常跟业务系统的人打交道,所以要对业务系统比较熟悉。
比如它们存在各种接口,不管是API级别还是数据库接口,这都需要ETL工程师非常了解。
其次是其下游,这意味着你要跟许多数据开发工程师师、数据科学家打交道。比如将准备好的数据(数据的清洗、整理、融合),交给下游的数据开发和数据科学家。
需要重点掌握的技能。
- 语言:Java/Python(会基础)
- Shell脚本(需要对shell较为熟悉)
- Linux(会用基本命令)
- Kettle(需要掌握)
- Sqoop(会用)
- Flume(会用)
- MySQL(熟悉)
- Hive(熟悉)
- HDFS(熟悉)
- Oozie(任务调度框架会用其中一个即可,其他如 azkaban,airflow)
四、数据分析工程师
在数据工程师准备好数据维护好数仓后,数据分析师就上场了。
分析师们会根据数据和业务情况,分析得出结论、制定业务策略或者建立模型,创造新的业务价值并支持业务高效运转。
同时数据分析师在后期还有数据爬虫、数据挖掘和算法工程师三个分支。
需要重点掌握的技能:
- 数学知识(数学知识是数据分析师的基础知识,需要掌握统计学、线性代数等课程)
- 编程语言(需要掌握Python、R语言)
- 分析工具(Excel是必须的,还需要掌握 Tableau 等可视化工具)
- 数据敏感性(对数据要有一定的敏感性,看见数据就能想到它的用处,能带来哪些价值)
总结:
1 写 SQL (很多入职一两年的大数据工程师主要的工作就是写 SQL )。
2 为集群搭大数据环境(一般公司招大数据工程师环境都已经搭好了,公司内部会有现成的大数据平台,但我这边会私下搞一套测试环境,毕竟公司内部的大数据系统权限限制很多,严重影响开发效率)
3 维护大数据平台(这个应该是每个大数据工程师都做过的工作,或多或少会承担“运维”的工作)
4 数据迁移(有部分公司需要把数据从传统的数据库 Oracle、MySQL 等数据迁移到大数据集群中,这个是比较繁琐的工作,吃力不讨好)
5 应用迁移(有部分公司需要把应用从传统的数据库 Oracle、MySQL 等数据库的存储过程程序或者SQL脚本迁移到大数据平台上,这个过程也是非常繁琐的工作,无聊,高度重复且麻烦,吃力不讨好)
6 数据采集(采集日志数据、文件数据、接口数据,这个涉及到各种格式的转换,一般用得比较多的是 Flume 和 Logstash)
7 数据处理
7.1 离线数据处理(这个一般就是写写 SQL 然后扔到 Hive 中跑,其实和第一点有点重复了)
7.2 实时数据处理(这个涉及到消息队列,Kafka,Spark,Flink 这些,组件,一般就是 Flume 采集到数据发给 Kafka 然后 Spark 消费 Kafka 的数据进行处理)
8 数据可视化(这个我司是用 Spring Boot 连接后台数据与前端,前端用自己魔改的 echarts)
9 大数据平台开发(偏Java方向的,大概就是把开源的组件整合起来整成一个可用的大数据平台这样,常见的是各种难用的 PaaS 平台)
10 数据中台开发(中台需要支持接入各种数据源,把各种数据源清洗转换为可用的数据,然后再基于原始数据搭建起宽表层,一般为了节省开发成本和服务器资源,都是基于宽表层查询出业务数据)
11 搭建数据仓(离线数仓和实时数仓)
总之就是离不开写 SQL …
好了,今天就聊到这里,祝各位终有所成,收获满满!
更多精彩内容请关注 微信公众号 👇「大数据指北」🔥:
一枚热衷于分享大数据基础原理,技术实战,架构设计与原型实现之外,还喜欢输出一些个人私活案例。
更多精彩福利干货,期待您的关注 ~
版权归原作者 大数据指北 所有, 如有侵权,请联系我们删除。