
一、集合简介
1.简述
- 集合类是用来存放某类对象的。集合类有一个共同特点,就是它们只容纳对象(实际上是对象名,即指向地址的指针)。这一点和数组不同,数组可以容纳对象和简单数据。如果在集合类中既想使用简单数据类型,又想利用集合类的灵活性,就可以把简单数据类型数据变成该数据类型类的对象,然后放入集合中处理,但这样执行效率会降低。
- 集合类容纳的对象都是Object类的实例,一旦把一个对象置入集合类中,它的类信息将丢失,也就是说,集合类中容纳的都是指向Object类对象的指针。这样的设计是为了使集合类具有通用性,因为Object类是所有类的祖先,所以可以在这些集合中存放任何类而不受限制。当然这也带来了不便,这令使用集合成员之前必须对它重新造型。
- 集合类是Java数据结构的实现。在编写程序时,经常需要和各种数据打交道,为了处理这些数据而选用数据结构对于程序的运行效率是非常重要的。
2.集合的特点
- 第一点,集合类这种框架是高性能的。对基本类集(动态数组,链接表,树和散列表)的实现是高效率的。一般人很少去改动这些已经很成熟并且高效的APl;
- 第二点,集合类允许不同类型的集合以相同的方式和高度互操作方式工作;
- 第三点,集合类容易扩展和修改,程序员可以很容易地稍加改造就能满足自己的数据结构需求。
3.集合的好处
1)降低编程难度:在编程中会经常需要链表、向量等集合类,如果自己动手写代码实现这些类,需要花费较多的时间和精力。调用Java中提供的这些接口和类,可以很容易的处理数据。
(2)提升程序的运行速度和质量:Java提供的集合类具有较高的质量,运行时速度也较快。使用这些集合类提供的数据结构,程序员可以从“重复造轮子”中解脱出来,将精力专注于提升程序的质量和性能。
(3)无需再学习新的APl:借助泛型,只要了解了这些类的使用方法,就可以将它们应用到很多数据类型中。如果知道了LinkedList的使用方法,也会知道LinkedList怎么用,则无需为每一种数据类型学习不同的API。
(4)增加代码重用性:也是借助泛型,就算对集合类中的元素类型进行了修改,集合类相关的代码也几乎不用修改。
4.集合的框架

二、数据结构
数据结构:
栈:先进后出,后进先出
队列:先进先出
数组:查询快(根据索引值找元素),增删慢
链表:查询慢,增删快
红黑树:查询、增删都比较快
三、Collection 接口、方法
1.Collection 接口
- 子接口List、Set它们的实现子类都是单列集合。
- Collection实子类可以存放多个元素,每个元素可以是Object。
- Collection接口没有直接的实现子类,是通过它的子接口Set和List来实现的。
- Collection的实现类,有些是有序的(List),有些是无序的(Set)。
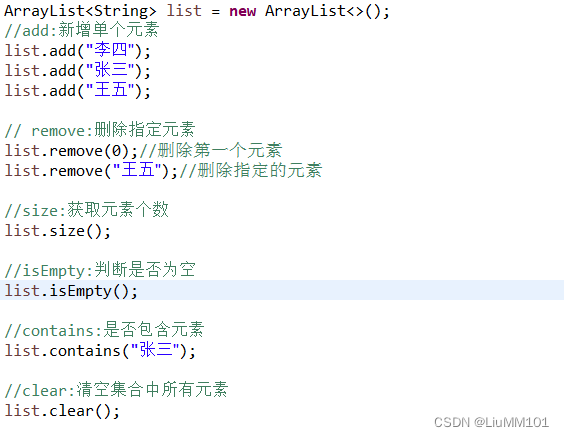
2.子类ArrayList的常用方法
3、遍历方式--Iterator(迭代器)
lterator对象称为迭代器,主要用于遍历Collection集合中的元素。
所有实现了Collection接口的集合类都有一个iterator()方法,用以返回一个实现了iterator接口 的对象,即可以返回一个迭代器 。

四、List集合
1.基本介绍
List接口:有索引值、可以重复、有序
ArrayList:底层是数组,特点,查询快 增删慢 。
LinkedList:底层是链表,特点,查询慢 增删快 。
Vector(较少使用):和ArrayList类似。
Vector:线程安全,效率低。
ArrayList:线程不安全,效率高。
2.常用方法

3.遍历集合的方式
- **iterator-**迭代器
- 增强for循环
- 普通for循环
4.ArrayList分析
- ArrayList 是由数组来实现数据存储的。
- ArrayList 基本等同于Vector,除了ArrayList是线程不安全(执行效率高)。在多线程情况下,不建议使用ArrayList。
5.LinkedList 分析
- LinkedList底层实现了双向链表和双端队列特点。
- 线程不安全,没有实现同步。
6. 如何选择ArrayList和LinkedList
- 如果我们改查的操作多,选择ArrayList
- 如果我们增删的操作多, 选择LinkedList
五、Set集合
1.基本介绍
Set接口:没有索引值,不可以重复
HashSet(无序):底层是哈希表
LinkedHashSet(有序):底层是链表+哈希表
TreeSet(可排序):底层是红黑树
Hashtable:和HashSet类似。
Hashtable:线程安全,效率低。
HashSet:线程不安全,效率高
2.常用方法

3.遍历集合的方式
- 使用**iterator-**迭代器
- 使用增强for循环
4.Set新增过程
- 1.计算新增元素的哈希值(十进制的地址值),调用hashCode();//Object父类的方法。
- 2.通过哈希值%数组长度,去确定元素新增的索引值位置。
- 3.如果该位置没有元素:直接新增。
- 4.如果该位置有元素:判断这两个元素是否相同。
- 5.如果不相同:挂到最后一个元素下面,相同则不新增。
- 6.判断是否相同的标准:比较哈希值相同 && (地址值相同 || equals相同)。
总结 如果自定义类型的对象,我们希望添加到HashSet集合中
我们认为成员变量的值相同,就为同一个元素,
则需要覆盖重写hashCode方法和equals方法
5.HashSet 分析
- shSet 实现了Set接口
- HashSet 的底层实际上是HashMap
- 不能有重复元素或对象
- 可以存放null 值,但是只能有一个null
6.LinkedHashSet 分析
- LinkedHashSet 是 HashSet 的子类
- LinkedHashSet 底层是一个LinkedHashMap,底层维护了一个数组+双向链表
- LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置,
- LinkedHashSet 不允许添重复元素
六、 Map:双列集合的总接口
1.特点
- 一个元素是有一个K,一个V两部分组成
- K V可以是任意的引用数据类型
- 一个K对应唯一的一个V。K不能重复
2. 常用实现类
- HashMap:底层是哈希表。无序
- LinkedHashMap:底层是链表+哈希表。有序
- TreeMap:底层是红黑树。可排序
- Hashtable:线程安全,效率低
- HashMap:线程不安全,效率高
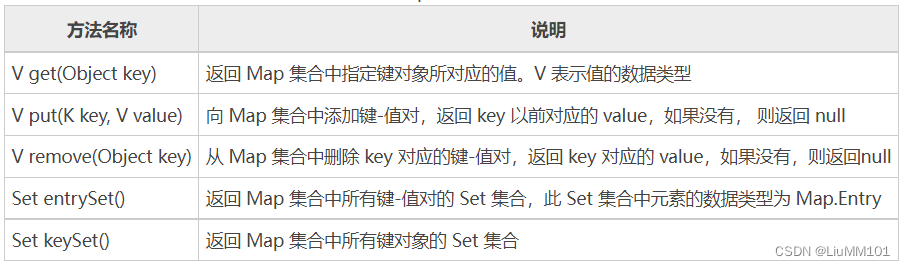
3.常用方法
4.图解

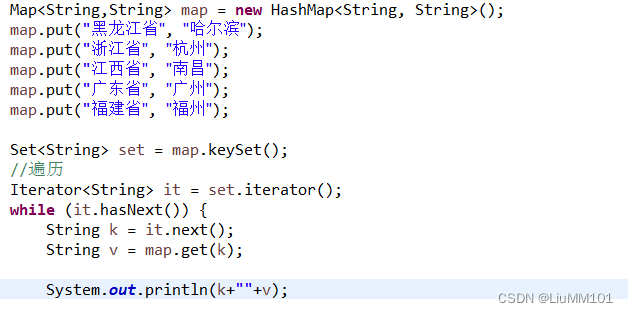
5.遍历Map集合的方式
- 1、将map 集合中所有的键取出存入set集合。
Set<K> keySet() 返回所有的key对象的Set集合再通过get方法获取键对应的值。- 2、 values() ,获取所有的值.
Collection<V> values()不能获取到key对象- 3、 Map.Entry对象 推荐使用 重点
Set<Map.Entry<k,v>> entrySet()- 将map 集合中的键值映射关系打包成一个对象
- Map.Entry对象通过Map.Entry 对象的getKey,
- getValue获取其键和值
图解:


6.HashMap
底层是哈希表,线程是不同步的,可以存入null键,null值。要保证键的唯一性,需要覆盖hashCode方法,和equals方法。
7.TreeMap
TreeMap的排序,TreeMap可以对集合中的键进行排序。如何实现键的排序?
和TreeSet一样原理,需要让存储在键位置的对象实现Comparable接口,重写 compareTo方法,也就是让元素自身具备比较性,这种方式叫做元素的自然排序也叫做默认排序。
七、集合工具类Collections
1.方法addAll&shuffle
- Collections.addAll(Collection<T> col,T... t);
- Collections.shuffle(List<T> list);
2.方法sort(List)
- 如果要对某个类型的对象进行排序,那么该类需要实现Comparable接口,
- 覆盖重写comparto()方法。
- 语法:类 implements Comparable<类>{}
3.方法sort(List,Comparator)
- Collections.sort(List<T> list,Comparator<T> com);
- 覆盖重写Comparator接口的compare方法。
版权归原作者 LiuMM101 所有, 如有侵权,请联系我们删除。