
一、安装配置 java 环境(已有 java 环境则跳过)
所需文件下载
链接:https://pan.baidu.com/s/1OYoeMVHOtcu05jR1mL7LeA
提取码:yyds
下载 jdk1.8.0_66_windows-x64_bin.exe(或其他版本)
配置环境变量:
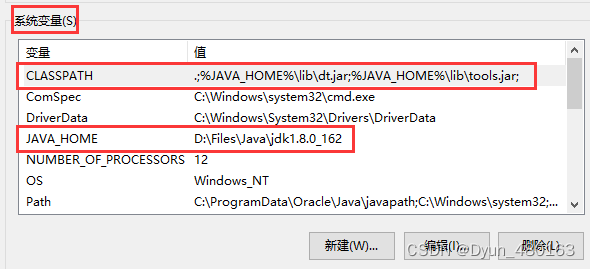
此电脑(右击)==>属性==>高级系统设置==>环境变量==>系统变量==>新建
CLASSPATH:.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;
JAVA_HOME:C:\Program Files\Java\jdk1.8.0_66(jdk安装路径)
此电脑(右击)==>属性==>高级系统设置==>环境变量==>系统变量==>Path==>新建
%JAVA_HOME%\bin
%JAVA_HOME%\jre\bin

二、scala 安装****配置
下载 scala-2.11.12.msi
配置环境变量
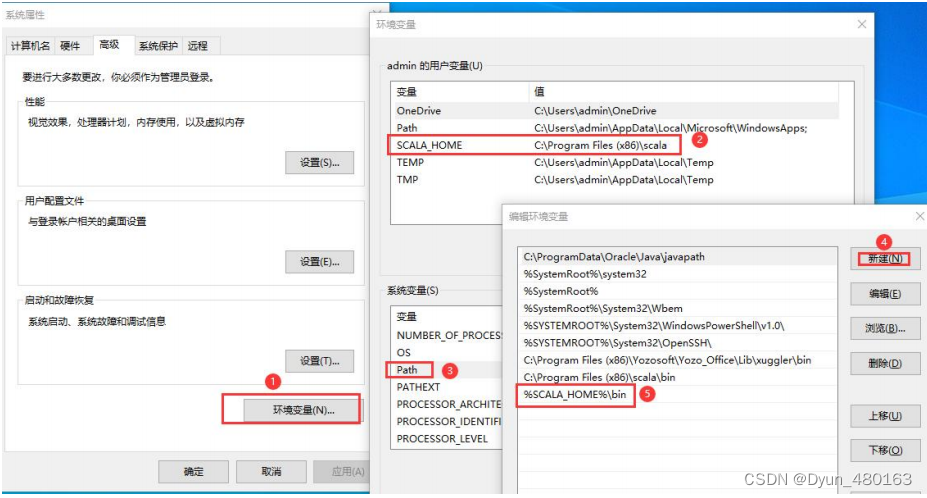
此电脑(右击)==>属性==>高级系统设置==>环境变量==>系统变量==>Path==>新建
%SCALA_HOME%\bin
查看是否安装成功
scala -version

三、Spark 安装配置
解压 spark-2.3.0-bin-hadoop2.7.tgz 文件夹至本地
配置 spark 环境变量
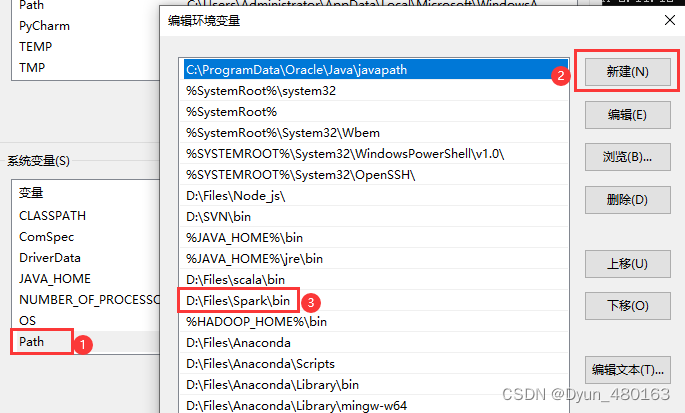
此电脑(右击)==>属性==>高级系统设置==>环境变量==>系统变量==>Path==>新建
D:\Files\Spark\bin (spark安装路径)
配置 hadoop环境
解压 hadoop-2.8.3.tar.gz 至本地
配置 HADOOP_HOME&Path:
HADOOP_HOME:D:\Files\Hadoop (hadoop安装路径)
path:%HADOOP_HOME%\bin
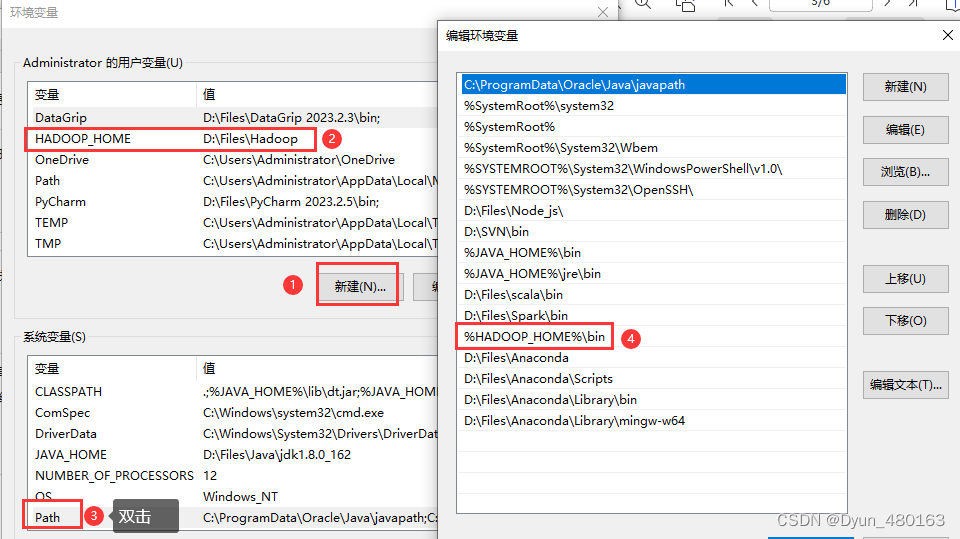
将对应版本的 bin.zip 解压后的 bin 目录直接替换本地 hadoop 的 bin 目录 即可
验证环境搭建是否成功
cmd 中输入 spark-shell 回车
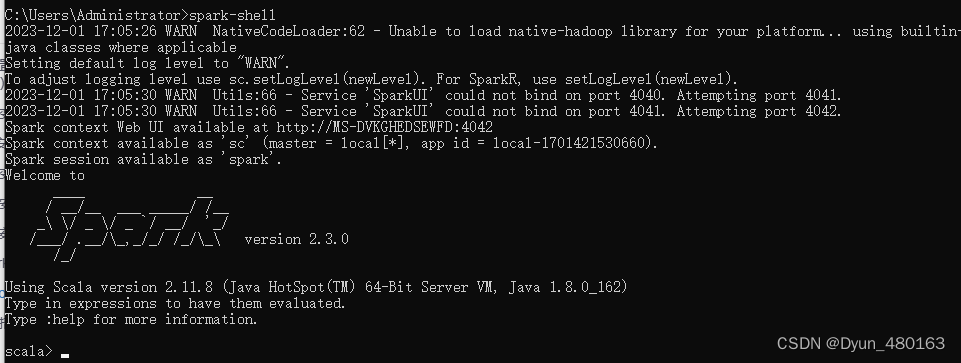
则 win10 单机版 spark 环境搭建成功
四、使用 pyspark 则要求 python 环境(已有 python 环境则跳过)
Spark 对 python 高版本支持不是很好,建议安装 python 的版本 3.6
用Anaconda创建虚拟环境
用Anaconda的虚拟环境配置python环境(Anaconda安装略)
创建名为 pyspark 虚拟环境,python版本为3.6.3
conda create -name pyspark python=3.6.3
查看虚拟环境
conda -v
激活虚拟环境
conda activate pyspark
打开pycharm应用环境
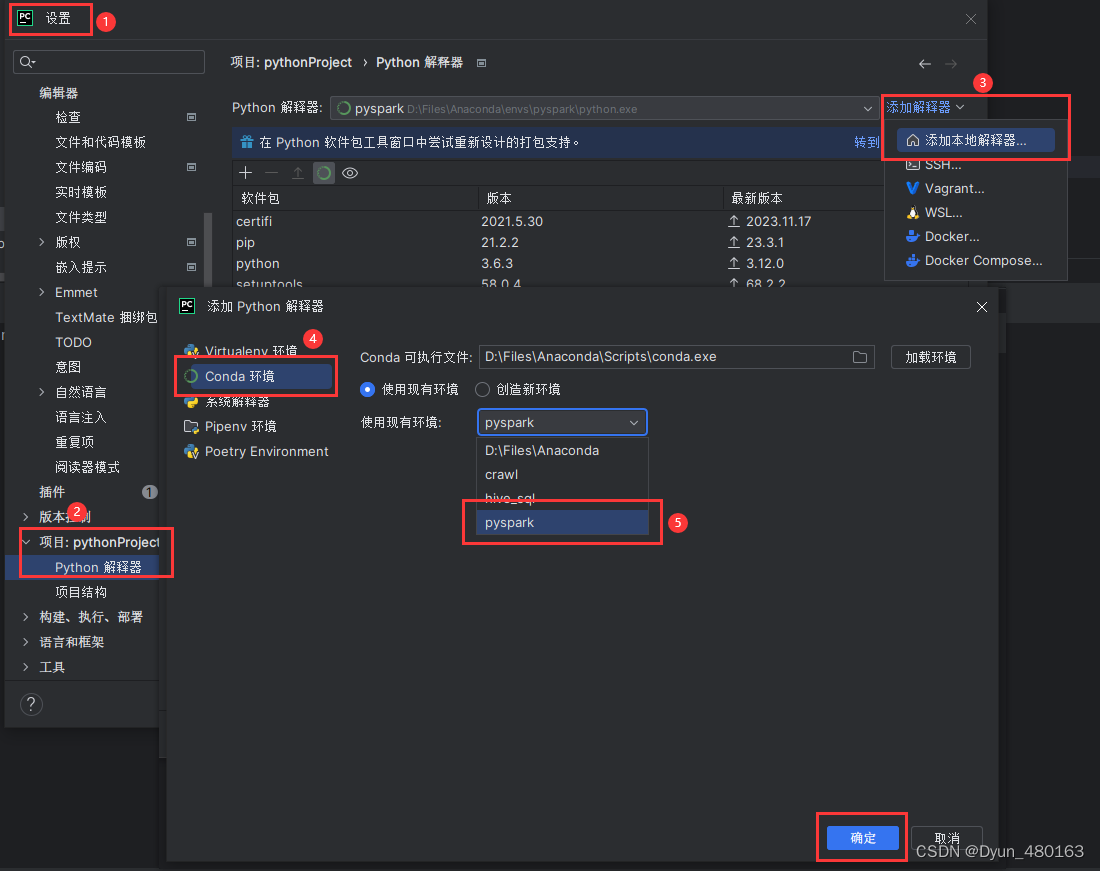
五、pycharm 配置 pyspark 环境
安装依赖模块
pip install pyspark==2.3.0
PyCharm 测试是否配置成功
from pyspark import Spark
Contextsc = SparkContext("local", "test")
t1 = sc.parallelize([1,2,3])
t2 =t1.collect()
print(t1)
print(t2)
六、Jupter notebook 配置 pyspark 环境
安装 jupyter notebook: pip install jupyter
启动 jupyter notebook

版权归原作者 我天生不爱笑 所有, 如有侵权,请联系我们删除。