
有开发过ChatGPT相关应用的都知道,小程序是不支持流式请求的,目前市面上大多数开发者的解决方案都是使用websocket来解决。
还有一部分开发者是小程序嵌套网页解决这个问题,前者对于我们软件销售型的团队来说,交付会很麻烦,而且问题也会很多,而后者主要是体验不怎么好,而且需要设置网页授权域名。
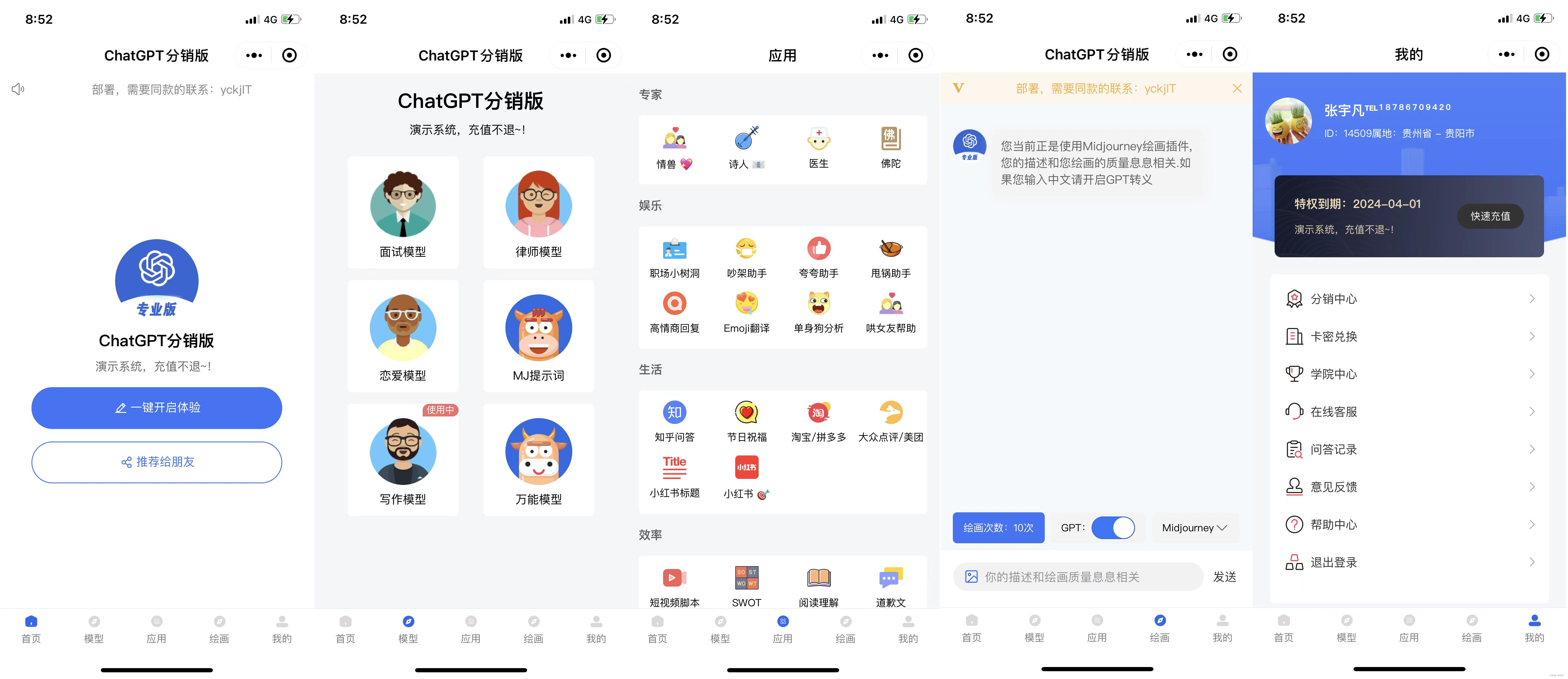
作为ChatGPT最早期的开发者,我们开发的ChatGPT分销版占据了市面上60%左右的市场,和下面图片相似的都是我们的ChatGPT分销版。
在开发这个项目之前,我们开源了这个产品的前端模板,现在市面上很多雷同的产品都是基于我们的模板进行开发的,或者是借鉴开发的。
有客户运营我们的产品,目前已经累计200w+的充值金额,净利润预估至少100w+,我们的产品质量源自于这些客户的数据支撑。
我们的后端使用ThinkPHP5.0进行开发,Saas架构,界面看上去很大气,如下图所示。

颜值绝对秒杀市面上的所有ChatGPT应用,当然我们的定价和服务也是相当超值的。
废话不多说,接下来我来详细介绍下我是怎么实现微信小程序的流式请求的。
一、设置请求头
我的微信小程序和网页H5都是用的同一个接口,而微信小程序不支持stream的方式,只能使用分段传输的方式。
所以在这一步你需要做一个接口的兼容,我是传一个参数代表是微信小程序请求还是网页请求,从而设置不同的请求头。
网页H5的我就不给出header了,这里主要给出小程序的请求头,如下所示。
// 设置响应头信息
header('Access-Control-Allow-Credentials: true');
// 设置响应头信息
header('Transfer-Encoding: chunked');
header('Cache-Control: no-cache');
header('Access-Control-Allow-Origin: *');
header('Access-Control-Allow-Methods: GET, POST, OPTIONS');
header('Access-Control-Allow-Headers: Content-Type');
header('Connection: keep-alive');
header('X-Accel-Buffering: no');
二,设置回复兼容
网页H5的流式请求我是直接返回的官方的响应数据,所以这里不能动之前的数据格式,在小程序请求这个接口时,需要单独返回对应的数据格式。
if ($is_wxapp) {
echo "success: " . json_encode(['content' => $content]) . "\r\n";
}
结尾使用“\r\n”,并且当所有数据响应完成之后一定要输出0,如下图所示。
if ($is_wxapp) {
echo "0\r\n\r\n";
ob_flush();
flush();
}
我这里为了兼容网页H5的流式请求,也是同样的加了判断之后输出的。
三,进入前端请求代码
以下是我完整的小程序请求方法,里面包含了我很多的业务逻辑,你可以根据你的业务进行修改,后面我会挑几个注意事项进行简述。
async onChatApplet() {
let _this = this;
let token = uni.getStorageSync('token');
const url = "";
const requestTask = uni.request({
url: url,
timeout: 15000,
responseType: 'text',
method: 'GET',
enableChunked: true,
data: {},
success: response => {
// console.log(response)
},
fail: error => {}
})
requestTask.onHeadersReceived(function(res) {
// console.log(res.header);
});
requestTask.onChunkReceived(function(response) {
const arrayBuffer = response.data;
const uint8Array = new Uint8Array(arrayBuffer);
let text = uni.arrayBufferToBase64(uint8Array)
text = new Buffer(text, 'base64')
text = text.toString('utf8');
if (text.indexOf('error') > 0) {
let error = text.replace("event: error\ndata: ", "").replace("\r\n", "")
error = JSON.parse(error)
let len = _this.question.length
_this.disabled = false
if (error.code == 0) {
_this.$refs.uToast.show({
type: 'error',
message: error.msg
})
if (len > 0) {
_this.question[len - 1].content = error.msg
} else {
_this.question[0].content = error.msg
}
return false;
}
if (in_array(error.code, [10001, 11000, 500, 404])) {
let length1 = 0
if (length1 > 0) {
_this.question[length1 - 1].content = error.msg
} else {
_this.question[0].content = error.msg
}
_this.$refs.uToast.show({
type: 'error',
message: error.msg
})
return false;
}
switch (error.code) {
case -1:
_this.question.pop()
uni.navigateTo({
url: '/pages/user/passport/login'
})
break;
case 101:
_this.question.pop()
_this.$refs.uToast.show({
type: 'error',
message: error.msg,
complete() {
uni.navigateTo({
url: '/pages/user/recharge/index'
})
}
})
break;
case 102:
let length = _this.question.length
if (length > 0) {
_this.question[length - 1].content = error.msg
} else {
_this.question[0].content = error.msg
}
_this.$refs.uToast.show({
type: 'error',
message: error.msg
})
break;
default:
break;
}
return false;
}
if (text.indexOf('success') != -1) {
let json = text.split('success: ');
json.forEach(function(element) {
if (element) {
element = JSON.parse(element)
let index = 0
if (_this.question.length > 0) {
index = _this.question.length - 1
}
_this.question[index].content += element.content;
_this.$nextTick(() => {
uni.pageScrollTo({
scrollTop: 2000000,
duration: 0
});
});
}
})
return false;
}
let done = text.replace("\r\n", "")
if (done == 0) {
_this.disabled = false
}
})
}
注意事项:编码
const arrayBuffer = response.data;
const uint8Array = new Uint8Array(arrayBuffer);
let text = uni.arrayBufferToBase64(uint8Array)
text = new Buffer(text, 'base64')
text = text.toString('utf8');
我这个方式比较简单粗暴,我在网上看到有人使用了第三方库,但是我测试下来行不通,就使用了uni官方这个转成Base64,然后再进行转码。
以上就是整个小程序的流式响应回复所需要用到的技术,也是最直接有效的方法,如果你现在掌握这门技术,再加上ChatGPT目前的势头,我相信你也能做出一些事情。
好了,就这样,做一个小小的记录,后期如果有空,我会继续分享我在开发ChatGPT产品的其他思路。
个人公众号:程序员在囧途
欢迎大佬交流合作,交个朋友也行。
版权归原作者 程序员在囧途 所有, 如有侵权,请联系我们删除。