
1、kettle下载以安装
1)kettle的官网下载地址:Pentaho from Hitachi Vantara - Browse Files at SourceForge.net
2)如果需要下载其他版本:
直接点击对应的版本Name(8.0以下的是在Data Integration文件夹里面)进去,再选择client-tools点击进去,最后选择pdi-ce-xxx.zip进行下载。

3)安装
不管是windows和linux环境下安装都是直接解压即可,再配置jdk环境。同步数据时,需要在lib加入对应的数据库驱动包。
2、Kettle的注意点与问题点
【Kettle-201】${Internal.Entry.Current.Directory},该参数要求ktr文件和job文件必须放到同一目录下。
当然,可以给他加后缀设置不一样的路径,或者直接把对应文件的路径放进去
【Kettle-202】 输入和输出的字段格式不一致
以ElasticSearch为输入源,数据库为输出为例,es可能是驼峰命名字段,数据库可能是下划线命名。处理时可以在idea通过camelBar插件进行辅助转换。(快捷键:Alt+Shift+U 或者通过Edit-->camelBar)
【Kettle-203】hive相关问题,如果是同步到hive,默认情况下表输出是比较慢的,需要修改big-data-plugin插件源码。
异常原因:在kettle的big-data-plugin插件的源码中把批量提交的方法关闭了,所以其只能单挑插入,效率就非常低。
解决办法:
1)下载big-data-plugin插件源码(github上面直接搜索),选择与当前kettle版本对应的源码版本,如cdh510;
2)kettle官网下载kettle程序(暂且称为安装版);
3)在Idea上新建一个Java Project,把下载的插件源码解压,src下的文件拷贝到工程目录src下,工程中新建lib目录,把kettle安装版目录/lib下的kettle-core-版本号.jar、kettle-dbdialog-版本号.jar、kettle-engine-版本号.jar、kettle-ui-版本号.jar 四个jar包拷贝到工程lib目录并buildpath;
4)把工程src下除了org.pentaho.di.core.database 包之外的其他包都删除(这里只用hive2数据库连接,所以其他大数据插件就不要了,个人可以根据自身需求而定。);
5)修改Hive2DatabaseMeta类中的 public boolean supportsBatchUpdates()方法,把返回值由false改为true;
6)把工程达成jar包,名称参考安装版 plugins/pentaho-big-data-plugin/下的pentaho-big-data-plugin-版本号.jar的名字,然后替换安装版这个jar包为工程导出的jar包,重启kettle,DB连接的HadoopHive2连接的特征列表的supportsBatchUpdate已经是Y了,实际转换中的表输出速度也提高到几千条每秒。后台spark界面看提交的sql语句也变成batchinsert而不是之前的insert。
参考文章:https://download.csdn.net/download/weixin_43861380/11166617?utm_source=bbsseo
【Kettle-204】kettle连接不上hive
异常原因:如果使用kettle版本过高,hive版本过低,可能会导致连接不上hive。
解决方案:① 可以通过修改源码来解决。
② 也可以直接下载个低版本的kettle,修改plugin.properties配置文件(active.hadoop.configuration=),指定对应的CDH的版本(假设使用使用cdh)
在data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations可以看到对应的大数据一些组件版本。
【Kettle-205】Caused by: com.mysql.jdbc.exceptions.jdbc4.MySQLIntegrityConstraintViolationException: Column 'id' cannot be null
异常原因:① 如果目标表有主键,过来的数据为空,也会报主键不能为空的问题。② 如果是通过REST client就可能是查询条件出问题。
解决方案:① 确保同步同步过来的数据不为空
② 检查查询语句是否有异常
【Kettle-206】Caused by: java.sql.SQLException: Incorrect string value: '\xF0\x9F\x9A\x80WZ...' for column
异常原因:通常情况,Mysql数据编码格式为“utf-8”,对于汉字来说足够;Mysql中utf8占3个字节,但是,3个字节对于表情符号是不够的,需4个字节;此时使用utf8,会出现‘\xF0\x9F\x8D\x83\xF0\x9F’的问题。
utf8mb4编码是utf8编码的超集,兼容utf8,并且能存储4字节的表情字符。
解决方案:
① 设置kettle的数据库连接的配置(这种设置后可能连接不上数据库,数据库那边可能还要调整)
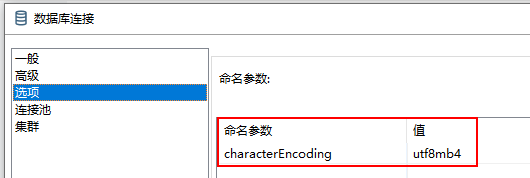
② 针对字段修改编码格式为utf8mb4(推荐使用)
ALTER TABLE table_name CHANGE field_name field_name VARCHAR(64) CHARACTER SET utf8mb4 ;
③ 修改数据库表的编码格式,修改为utf8mb4;修改Mysql配置文件my.cnf(windows下为my.ini),然后重启数据库 。
[client]
default-character-set = utf8mb4
[mysql]
default-character-set = utf8mb4
[mysqld]
character-set-server = utf8mb4
参考文章:解决Mysql:Incorrect string value: '\xF0\x9F\x8D\x83\xF0\x9F...' for column_春风化作秋雨的博客-CSDN博客_incorrect string value:
【Kettle-207】目标表新增字段,kettle同步的时候无法显示的问题
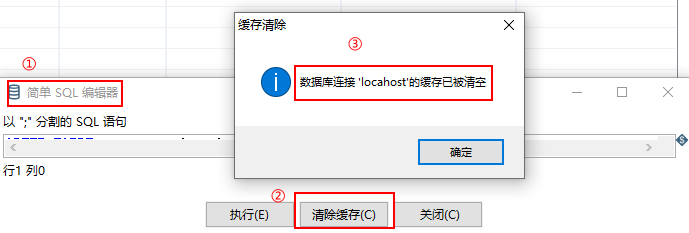
异常原因:主要是kettle缓存问题导致的
解决方案:直接在最后的输出步骤里,点击下方的SQL进行缓存清理。
3、kettle启动停止工具脚本
#!/bin/sh
# @date 2023-01-03
# kettle启动停止工具脚本
KJB_NAME=$2
## kettle的父路径
KETTLE_PATH='/opt/module/kettle/pdi-ce-8.2.0.0-342'
## 使用说明,用来提示输入参数
usage(){
echo "Usage: sh 脚本名.sh [start|stop|restart|status|tail] [KJB_NAME]"
exit 1
}
## 检查执行的文件是否存在
is_exist(){
if [[ ! -e ${KETTLE_PATH}/jobs/${KJB_NAME}.kjb ]]; then
echo "该${KJB_NAME}.kjb在${KETTLE_PATH}/jobs/下不存在!"
exit 1
fi
}
## 检查程序是否在运行
is_running(){
pid=`ps -ef|grep ${KJB_NAME}.kjb|grep -v grep|awk '{print $2}'`
}
## 启动方法
start(){
is_exist
is_running
echo "pid=${pid}"
if [[ -z "${pid}" ]]; then
nohup ${KETTLE_PATH}/data-integration/kitchen.sh -file=${KETTLE_PATH}/jobs/${KJB_NAME}.kjb >> ${KETTLE_PATH}/logs/${KJB_NAME}.log 2>&1 &
echo "${KJB_NAME} start success!"
else
echo "${KJB_NAME} is already running."
fi
}
## 关闭方法
stop(){
is_running
if [[ -z "${pid}" ]]; then
echo "${KJB_NAME} is not running!"
else
echo "${KJB_NAME}, Trying to kill the pid=${pid}."
kill -9 ${pid}
echo "${KJB_NAME} stop success!"
fi
}
## 重启方法
restart(){
stop
start
}
## 启动方法
status(){
is_exist
is_running
echo "pid=${pid}"
if [[ -z "${pid}" ]]; then
nohup ${KETTLE_PATH}/data-integration/kitchen.sh -file=${KETTLE_PATH}/jobs/${KJB_NAME}.kjb >> ${KETTLE_PATH}/logs/${KJB_NAME}.log 2>&1 &
echo "${KJB_NAME} start success!"
else
echo "${KJB_NAME} is already running."
fi
}
if [[ $# -lt 2 ]]; then
usage
fi
case $1 in
"start")
echo "=================== start kettle_kjb ==================="
start
;;
"stop")
echo "=================== stop kettle_kjb ==================="
stop
;;
"restart")
echo "=================== restart kettle_kjb ==================="
restart
;;
"status")
echo "=================== status kettle_kjb ==================="
ps -ef|grep ${KJB_NAME}.kjb|grep -v grep
;;
"tail")
echo "=================== tail kettle_kjb ==================="
tail -60f ${KETTLE_PATH}/logs/${KJB_NAME}.log
;;
*)
echo "Input Args Error..."
;;
esac
版权归原作者 ykqidev 所有, 如有侵权,请联系我们删除。