
一、前言
FaceFusion是一款开源的AI换脸工具,它能够将一个人的脸部特征替换到另一个人的身体上,实现面部表情和动作的同步。这种技术可以用于制作电影、游戏、社交媒体等多种领域,带来丰富的娱乐和创意效果。
Facefusion:GitHub - facefusion/facefusion: Next generation face swapper and enhancer
Facefusion官方教程:Introduction - FaceFusion
云端部署的优点主要包括以下几点:
① 灵活性:云端部署使得用户可以直接在本地进行数据传输和查询,缓解数据传输速度和存储网络的限制。同时,云端技术能够快速地进行升级和更新,以保证系统的安全和稳定性。
② 可扩展性:云端部署可以自动扩展,根据需求自动增加或减少资源,避免数据量超过一台服务器或当前机器所能承受的范围。
③ 成本效益:云端部署不需要前期成本,而是采用运营费用(OpEx)模式,用户只需按需付费。同时,云服务提供商负责软件和硬件的维护、兼容性和升级,降低用户的IT负担。
④ 安全性:云端部署提供了高水平的安全性,采用数据中心的安全措施,保护数据在云中的安全。同时,云服务提供商负责备份和灾难恢复,确保数据可靠性和可用性。
⑤ 全球访问:云端部署使得用户可以从任何有网络连接的地方访问应用程序,提高了全球范围内的可用性和可访问性。
综上所述,FaceFusion的云端部署可以带来灵活性、可扩展性、成本效益、安全性和全球访问等优点,使得这种AI技术更加普及和可用。
二、云端部署准备工作
云端部署Facefusion需要一些准备工作,首先需要选择一个可靠的云服务器算力平台,这里我推荐仙宫云算力平台,仙宫云算力平台是一个云端部署工具,它提供高性能的GPU算力服务,用于部署AI和机器学习应用。该平台可以快速搭建AI和机器学习环境,提供弹性计费和秒级部署服务。用户可以在平台上选择不同的GPU型号和配置,以满足不同的计算需求。
仙宫云网址:仙宫云 | GPU 算力租赁 | Xiangongyun.com

打开网页后,首先需要注册登录,首次注册登录,即是新用户是会赠送5元的代金券,填写我的邀请码还会有额外的3元代金券自动领取。(邀请码:SJ2FNK)
接着点击左上角的部署GPU计算容器,选择RTX4090


然后点击“公共镜像”,选择一个ubuntu的公共镜像,然后点击“确认部署”


等待一会,容器实例就创建完成啦~🫰
三、安装Facefusion
3.1、进入终端界面
首先点击Jupyter进入终端界面,开始安装Facefusion

首先为当前终端会话启用学术加速,目的是为了待会git拉取代码的时候速度变快点。
. /accelerate/start

3.2、拉取git代码
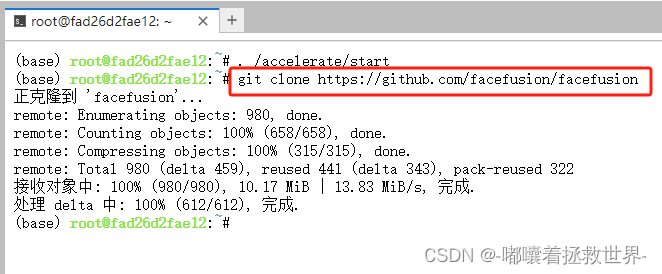
接着使用git拉取Facefusion代码到云端文件夹下
git clone https://github.com/facefusion/facefusion
3.3、创建虚拟环境
在安装相关的依赖之前,先要创建虚拟环境,目的是为了管理不同项目的Python环境,通常建议创建一个虚拟环境。虚拟环境可以帮助您隔离不同项目的依赖项,避免不同项目之间的冲突。
① 创建虚拟环境:运行以下命令来创建一个新的虚拟环境,可以将<env_name>替换为你自己喜欢的环境名称,例如:“facefusion”
conda create -n <env_name> python=<version>例如我这里创建一个名为“face”的虚拟环境,其中python版本为3.10.6,可以运行:
conda create -n face python=3.10.6
② 激活虚拟环境:运行以下命令来激活刚刚创建的虚拟环境。
conda activate face激活虚拟环境后,您将看到虚拟环境的命令提示符前缀显示为(face)。这意味着您现在正在使用该虚拟环境的Python解释器。
3.4、安装必要依赖
好啦,现在可以正式安装Facefusion依赖了,首先进入facefusion的路径,运行以下命令
cd facefusion
接着运行以下命令进行安装依赖项
apt-get update
apt-get install ffmpeg
python install.py --torch cuda --onnxruntime cuda --skip-venv
最后运行以下指令运行Facefusion
python run.py

有这个链接出现就证明安装依赖没问题了,可以直接运行了。
当然,如果你说点击这个链接为什么无法访问,那么我下面教的可能是你需要的啦~
四、运行Facefusion
首先回到容器实例,点击“仙宫云OS”,进入云平台可视化界面。


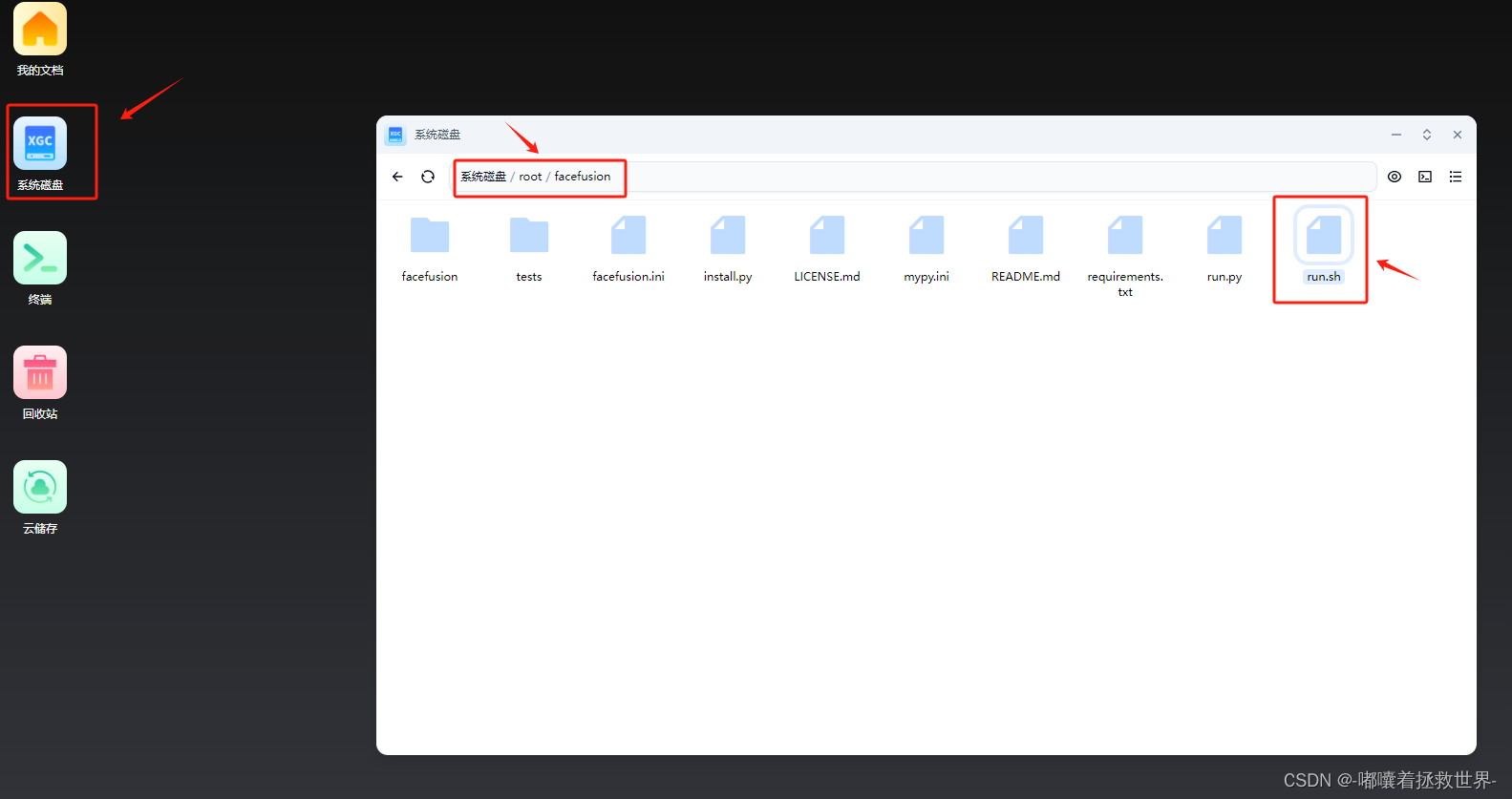
接着点击“系统磁盘”,一步步进入到facefusion文件夹下,点击鼠标右击创建文件“run.sh”,为后续写shell脚本打基础。
然后右击run.sh进入编辑界面,输入以下脚本代码。(输入完后记得保存喔)
#!/bin/bash
# 为当前终端会话启用学术加速
. /accelerate/start
# 指定GPU
mutil_gpu=0
# 激活 Conda 环境
source activate face
# 切换到 GPT-SoVITS 目录
cd /root/facefusion
# 执行 Python 脚本
python run.py
接下来给脚本文件添加执行权限,这是一个重要的步骤,这样你才能直接运行它。在Linux中,你可以使用'chmod'命令来修改文件的权限。对于你的脚本,你需要给它"执行"权限。首先打开一个终端窗口,使用‘cd’命令导航到脚本文件所在的目录。运行以下命令:
chmod +x run.sh
这个命令做了什么:
chmod是用来改变文件权限的命令。+x表示添加执行权限。run.sh是你的脚本文件名。
然后我们需要将脚本文件转换为Linux格式,可以使用如dos2unix这样的工具来实现这一点。如果您没有安装dos2unix,可以使用以下命令安装:
apt-get install dos2unix
然后,使用以下命令转换您的脚本文件:
dos2unix run.sh
完成这些步骤后,你的脚本就有了执行权限,可以通过以下命令直接运行:
(记得在facefusion目录下运行执行命令喔!)
bash run.sh
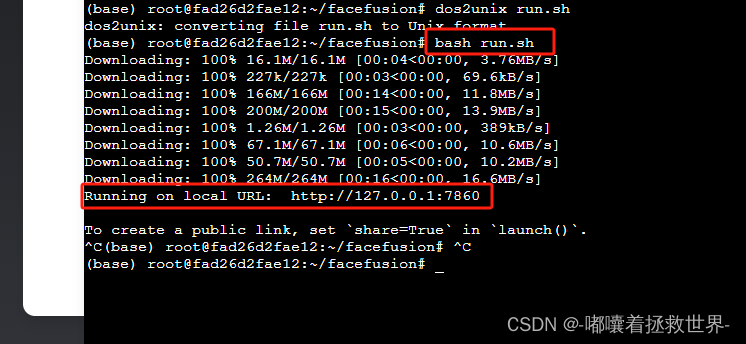
最后最后,关键一步来了,我们需要添加开放端口,在终端执行以下命令:
wget -P /.xgcos/desktop/ "http://public.x-gpu.com/f/WKlCD/80web.app.zip"; cd /.xgcos/desktop; unzip /.xgcos/desktop/80web.app.zip; rm -rf /.xgcos/desktop/80web.app.zip
刷新桌面后,就会出现一个“80端口web”的文件夹,然后双击这个文件夹,进入文件里面后,编辑info.yaml,根据以下命令来进行编辑就行。(记得点击保存按钮!)
name: Facefusion
title: Facefusion换脸工具
icon: 80web.png
type: browser
props:
port: 7860

配置好后,记得保存。然后打开一个新的终端,分别输入以下命令:
cd facefusion/
bash run.sh
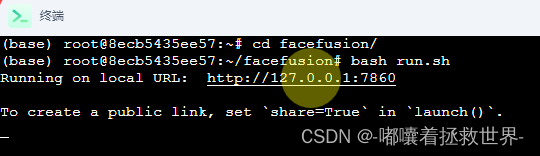
出现网址后,双击桌面上的Facefusion,就可以打开Facefusion的GUI界面啦~

五、使用Facefusion
5.1、快速开始
完整界面如下:

这样看上去好复杂好多英文都看不懂,没事的,看完下面详情的解释说明就明白怎么使用它了。
其实核心的功能操作非常简单,根据下面的图片来操作就行啦。

① 目标人脸(source):拖放文件或者点击上传图片即可。
② 目标图像(Target):这个Target可以是图片,也可以是视频喔。
③ 效果预览(Preview):一旦选中目标之后,软件里面就开始运行,运行之后会把合成预览显示在这个区域。
④ 开始换脸(start):一切都准备好后,点击“start”就可以开始运行了。
⑤ 查看结果(output):换脸成功之后,会把结果显示在这里。
5.2、参数讲解
下面讲解一下左边参数设置栏。
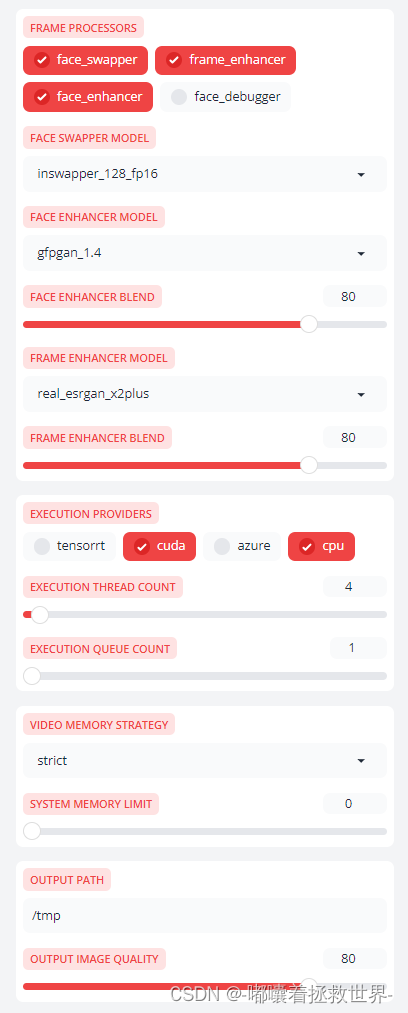
帧率处理器(FRAME PROCESSORS):包括了基础的Face Swapper(面部交换)、Face Enhancer(面部增强)、Frame Enhancer(帧增强)、Face Debugger(面部调试)这四种。
1. Face Swapper(面部交换):(这个是必须要选的!)
- 指的是一种技术或工具,能够识别照片中的人脸并将其与另一张照片中的人脸交换。2. Face Enhancer(面部增强):
- 这种技术旨在改善照片中人脸的质量,包括但不限于清晰度、肤色、去除皱纹或瑕疵等。面部增强可以是自动的,通过软件算法识别并优化人脸特征。3. Frame Enhancer(帧增强):
- 主要用于视频处理,指的是提高视频帧的质量,包括提高分辨率、改善动态范围、颜色校正等。帧增强技术可以使视频看起来更清晰、更流畅,特别是在将低分辨率视频转换为高分辨率输出时。4. Face Debugger(面部调试):
- 用于识别和修正面部识别系统中的错误或问题。例如,它可能涉及到调整算法以更准确地识别不同的面部特征或表情,或者修正在面部追踪、分析过程中出现的错误。
面部交换模型(FACE SWAPPER MODEL):blendswap_256、inswapper_128、inswapper_128_fp16、simswap_256、simswap_512_unofficial。
它们在功能、分辨率和可能的性能优化方面有所不同。面部交换技术通常涉及深度学习和人工智能,以在图像或视频中自动识别和替换面孔。下面是对这些模型名称的一般解释:
1. blendswap_256:
- 这个模型可能专注于将两张图像中的面孔进行混合和交换,256可能表示模型工作的图像分辨率或输出分辨率是256x256像素。这种分辨率适合于较小的图像和需要快速处理的应用。2. inswapper_128 和 inswapper_128_fp16:
- 这两个模型似乎是专为面部交换设计的,128同样指的是处理的图像分辨率为128x128像素。fp16后缀表明该模型使用16位浮点数(FP16)进行计算,这通常意味着它在保持足够精度的同时,能够减少计算资源的需求,加快处理速度,特别适用于资源有限的环境或需要实时处理的应用。3. simswap_256:
- 这个模型可能采用了某种相似性交换算法,256指的是模型处理的分辨率为256x256像素。这种模型可能在保持原图像质量的同时,能够实现高质量的面部交换效果。4. simswap_512_unofficial:
- 与simswap_256类似,但512表明这个版本的模型支持更高的分辨率,即512x512像素,能够生成更高清晰度的面部交换结果。unofficial可能意味着这个版本不是官方发布的,或者是社区成员基于原始模型进行的修改或扩展。每个模型的具体实现和性能可能会根据其设计和优化而有所不同。使用16位浮点数(如
inswapper_128_fp16)是一种优化技术,可在不显著影响输出质量的情况下加速模型运行。更高的分辨率(如simswap_512)能够提供更细腻的细节,但也可能需要更多的计算资源和处理时间。

面部增强模型(FACE ENHANCER MODEL):codeformer、gfpgan_1.2、gfpgan_1.3、gfpgan_1.4、gpen_bfr_256、gpen_bfr_512、restoreformer_plus_plus。
这些术语代表了不同的面部增强模型,它们利用人工智能技术,特别是深度学习,来改善或增强照片中人脸的质量。这些模型能够处理各种问题,如提高分辨率、修复损坏的图像、美化面部特征,甚至在某些情况下恢复老旧照片。下面是对这些模型的简单解释:
1. GFPGAN(Generative Facial Prior-GAN,生成式面部先验-生成对抗网络):
- gfpgan_1.2, gfpgan_1.3, gfpgan_1.4:这些版本代表GFPGAN模型的不同迭代,数字代表版本号,随着版本号的增加,模型的性能、效果或功能可能有所改进。GFPGAN主要用于面部重建和增强,可以修复面部区域的缺陷,提高图像质量,同时尽可能保持人物的真实性。2. CodeFormer:
- 这是一个深度学习模型,专注于图像修复和面部增强。它可能利用编码器-解码器架构来处理图像中的瑕疵,如模糊、遮挡等,同时优化面部细节和表情的自然度。3. GPEN(Generative Portrait Editing Network,生成式肖像编辑网络):
- gpen_bfr_256, gpen_bfr_512:这些模型用于美化和修复面部图像,数字代表模型优化处理的图像分辨率,如256x256或512x512像素。GPEN利用生成对抗网络来提升肖像照片的质量,包括面部特征的清晰度和整体图像的视觉效果。4. RestoreFormer Plus Plus:
- 这个模型名称暗示了它可能是基于Transformer架构的一种先进的图像恢复技术,专门设计来改善图像质量,如通过去噪、提高分辨率或修复老旧照片。"Plus Plus"可能表示这是一个进一步改进或增强的版本,提供了更好的性能或更多的功能。这些模型各自有不同的特点和应用领域,但共同目标是通过最新的AI技术改善面部图像的质量,无论是通过修复损坏的照片、提高分辨率还是进行美化处理。

面部增强融合(FACE ENHANCER BLEND):允许用户调整面部增强效果的强度或程度。
帧率增强模型(FRAME ENHANCER MODEL):是指用于提高视频帧或图像质量的人工智能模型。
"Real-ESRGAN"(Enhanced Super-Resolution Generative Adversarial Networks)是一种基于生成对抗网络(GAN)的技术,主要用于提高图像或视频帧的分辨率,同时尽量保持或增强细节的真实性和质量。下面是对每个模型的简要说明:
1. real_esrgan_x2plus:
- 这个模型旨在将图像分辨率提高2倍(即"x2")。"plus"可能表示模型相对于基本版本有所改进,例如通过增加细节的恢复或优化算法来减少伪影,从而提供更自然和清晰的图像。2. real_esrgan_x4plus:
- 类似于"x2plus"版本,这个模型提供了4倍的分辨率提升。这意味着它可以将低分辨率图像放大到原始尺寸的4倍,同时通过先进的处理技术最大限度地保持图像质量,减少放大过程中常见的问题,如模糊和失真。3. real_esrnet_x4plus:
- 这个术语似乎是对"Real-ESRGAN"的一个变体或打字错误,实际可能指的是"Real-ESRGAN"的某个特定版本或相关模型,同样专注于4倍的超分辨率增强。"ESRNet"可能是另一种模型的简称,也可能是对"ESRGAN"的误称。不过,考虑到上下文,它可能旨在描述一个同样能实现4倍超分辨率提升的增强模型。

执行计算(EXECUTION PROVIDERS):支持执行这些计算任务的后端,可以是不同类型的硬件(如CPU、GPU、TPU等)或者软件层(如特定的库或服务)。这里安装了CUDA相关的依赖项,所以使用cuda,如果只安装CPU,就使用CPU。

六、总结
这篇教程详细介绍了如何云端部署AI换脸开源工具FaceFusion,并通过附带的AI工具使用指南帮助用户更好地理解和使用FaceFusion。教程涵盖了FaceFusion的简介、云端部署的优势、准备工作、部署步骤、验证部署、常见问题和解决方案等,为用户提供了一个全面的指南。通过这篇教程,用户可以轻松地掌握云端部署FaceFusion的整个过程,并利用FaceFusion进行AI换脸处理。同时,用户也可以利用附带的AI工具使用指南深入了解FaceFusion的功能和特点,从而更好地发挥其潜力。总之,这篇教程是一个非常实用的指南,帮助用户轻松地云端部署AI换脸开源工具FaceFusion,并充分利用其功能进行创意和娱乐应用。

❤️码字不易,麻烦给个免费的赞👍,谢谢🦀
版权归原作者 -嘟囔着拯救世界- 所有, 如有侵权,请联系我们删除。