
第一步:新建一个maven工程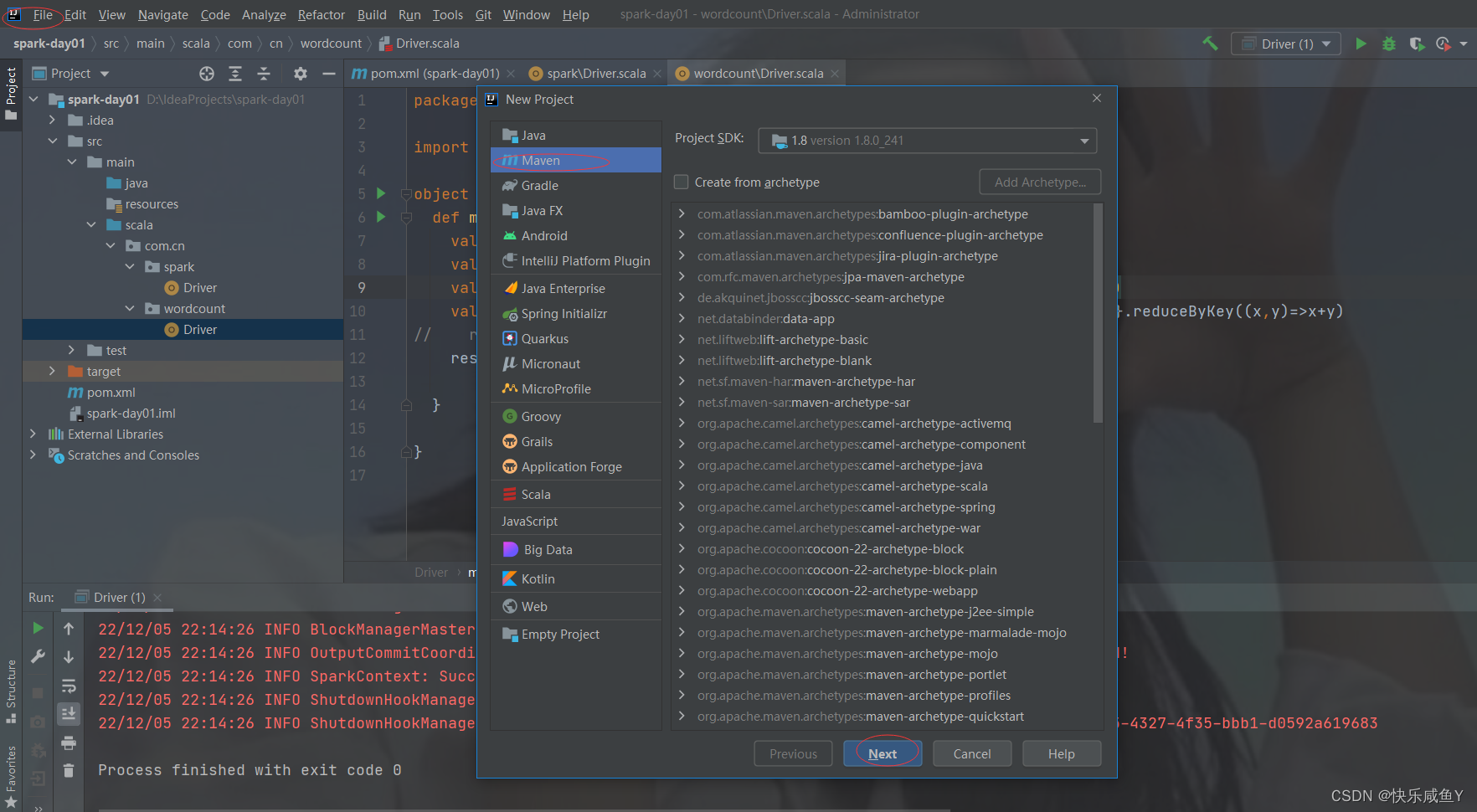
第二部:命名工程名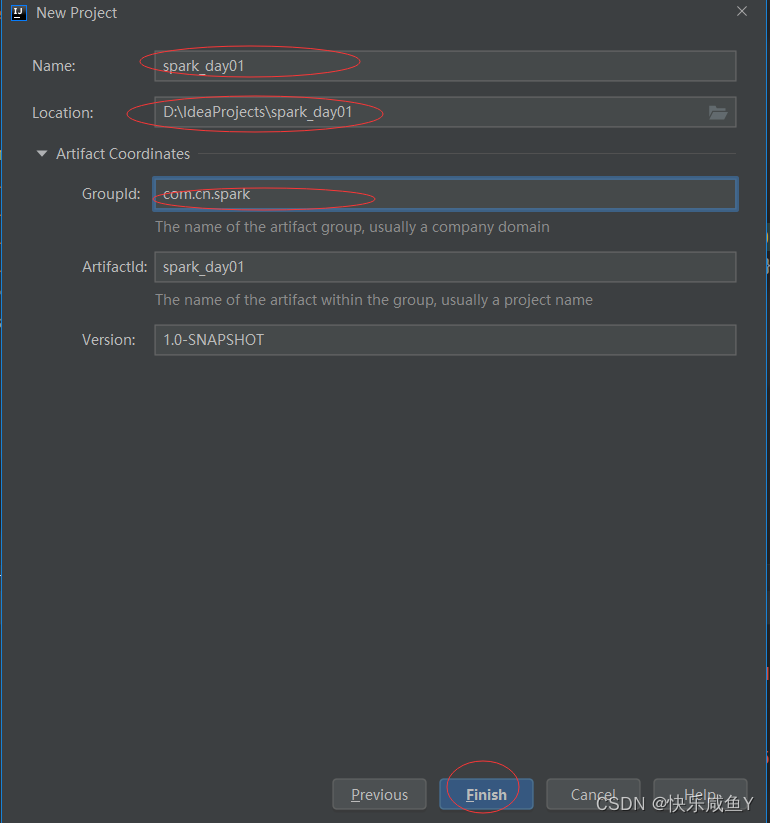
第三步:新建一个文件夹,并设置为sources root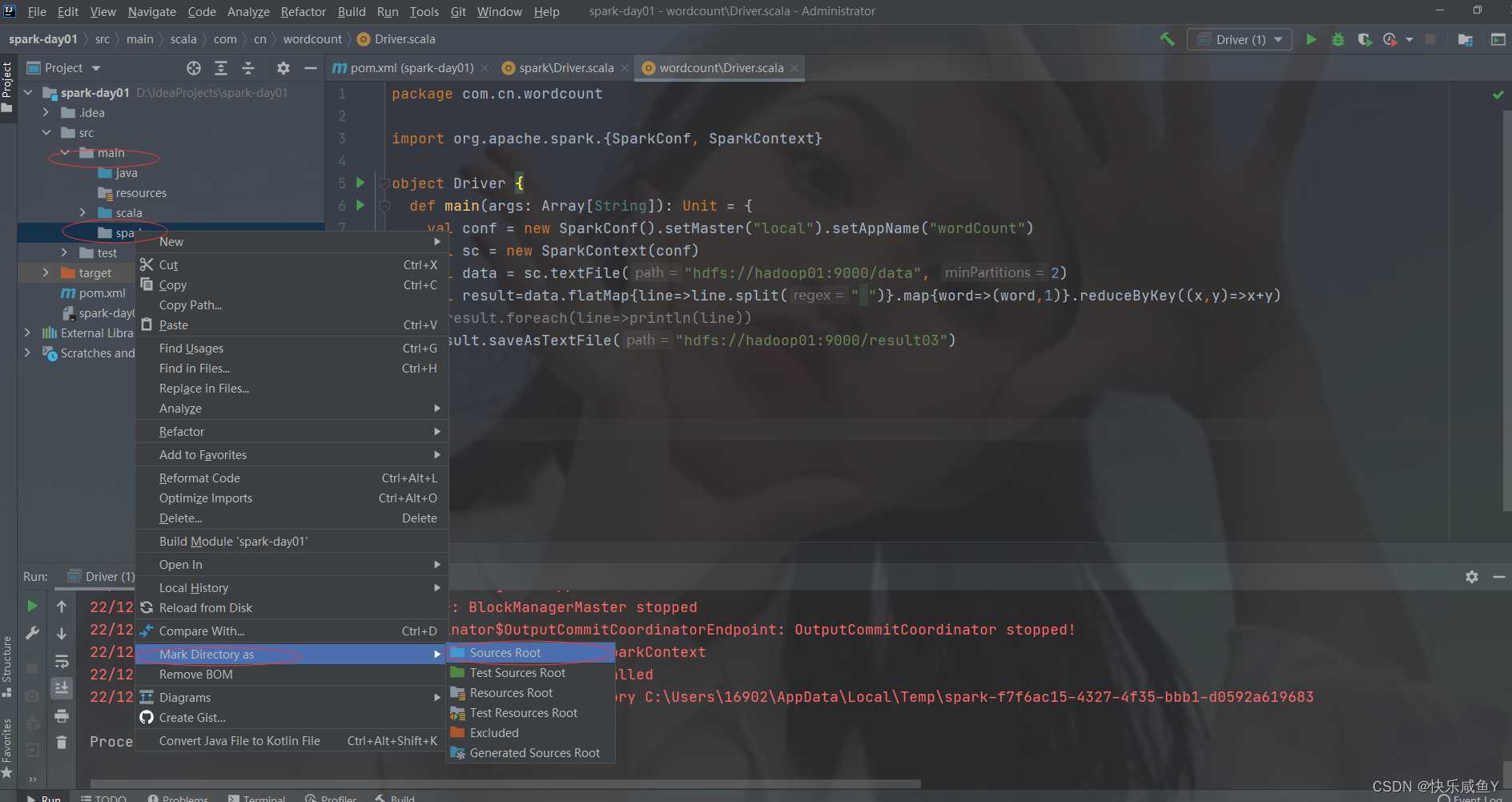
第四步:pom编写
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.cn.spark</groupId><artifactId>spark-day01</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.1</version></dependency></dependencies><build><pluginManagement><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.6.1</version><configuration><source>1.8</source><target>1.8</target><encoding>UTF-8</encoding></configuration></plugin></plugins></pluginManagement></build></project>
第五步:新建一个Scala类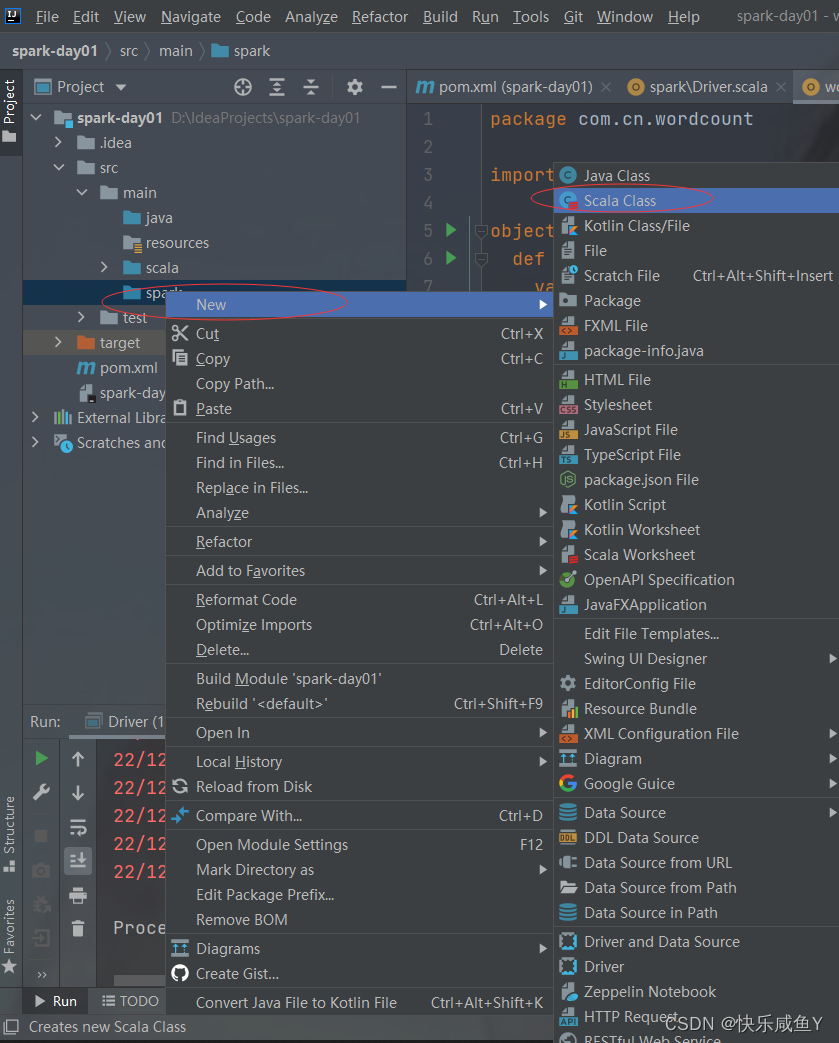
注意:此步可能找不到Scala,需要引入
具体步骤为
1.项目构建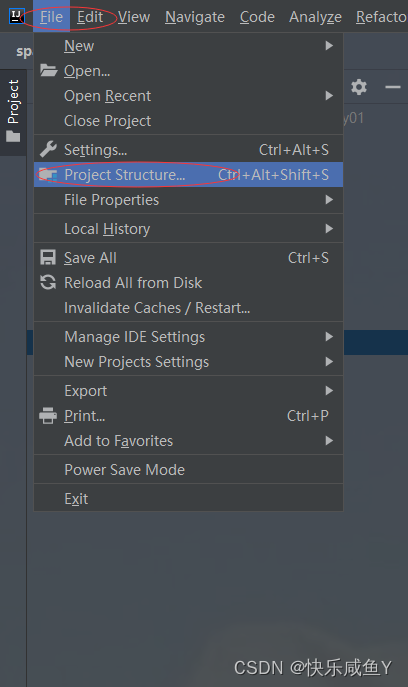
2.点击+
3.添加Scala,如果有Scala环境,会默认识别版本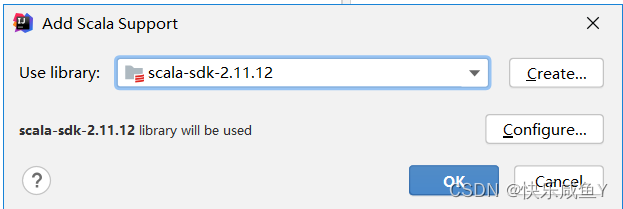
最后会引入Scala,如下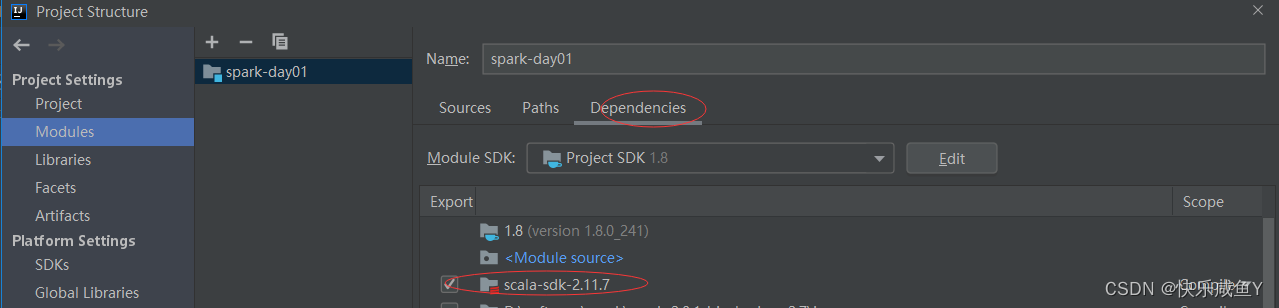
第六步:引入spark相关jar包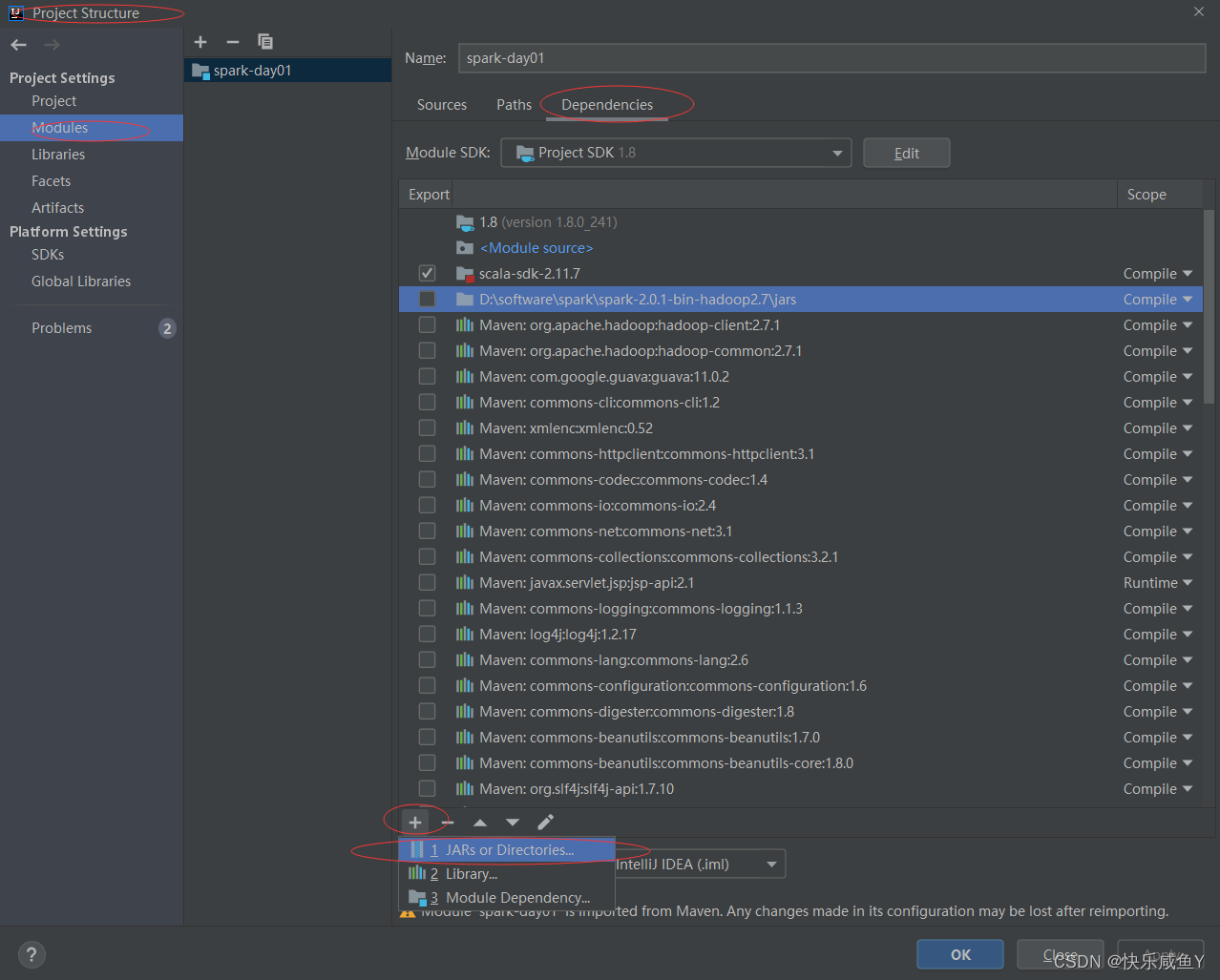
选择自己的spark安装包,里边有jar包目录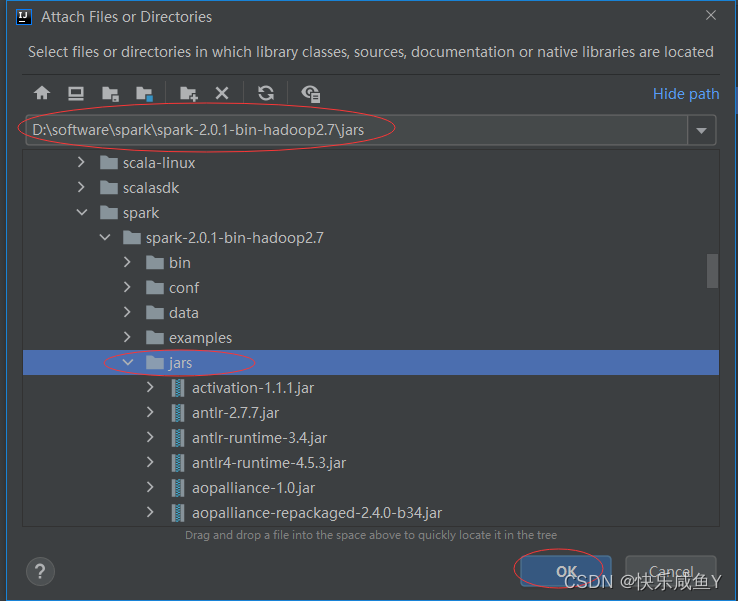
第七步:新建一个Scala
第八步:编写代码验证
packagecom.cn.wordcountimportorg.apache.spark.{SparkConf,SparkContext}
object Driver{
def main(args:Array[String]):Unit={
val conf =newSparkConf().setMaster("local").setAppName("wordCount")
val sc =newSparkContext(conf)
val data = sc.textFile("hdfs://hadoop01:9000/data",2)
val result=data.flatMap{line=>line.split(" ")}.map{word=>(word,1)}.reduceByKey((x,y)=>x+y)// result.foreach(line=>println(line))
result.saveAsTextFile("hdfs://hadoop01:9000/result03")}}
第九步:运行结果(打印到控制台,并且将数据存储到Hadoop中hdfs中)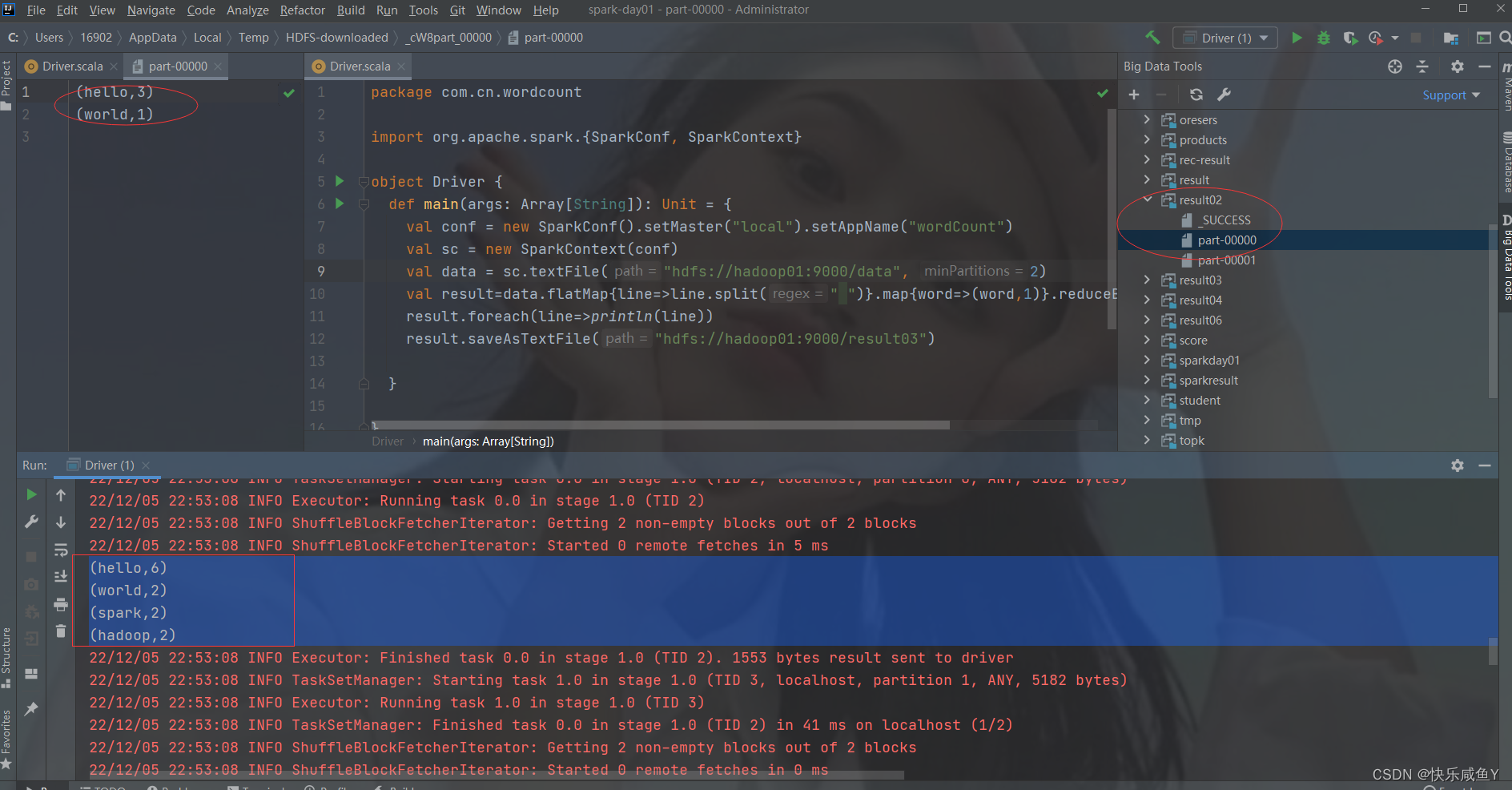
标签:
spark
本文转载自: https://blog.csdn.net/yygyj/article/details/128194459
版权归原作者 快乐咸鱼Y 所有, 如有侵权,请联系我们删除。
版权归原作者 快乐咸鱼Y 所有, 如有侵权,请联系我们删除。