
提起Valgrind,很多人认为是做内存泄漏的工具,其实memcheck只是Valgrind下的一个功能而已。
接下来我们一起看一下使用Valgrind的Callgrind工具实现Code Profiling/代码性能调优。(主要是针对CPU优化的)
Code Profiling
Code Profiling工具是指一个分析使用资源并生成报告的工具,这里的资源指内存,CPU,网络带宽等。 在做调优的第一步是使用工具将程序运行的真实定量数据收集起来,这种数据,就成为profiling data。通过profiling data,我们可以直观地看到资源消耗,并且找出问题所在,同时也可以科学地评估我们为代码性能调优后的结果。
传统的linux下的profiling工具有gprof,当然这个不在本文的讨论范围。这里我们主要介绍Valgrind。 Valgrind的profiling工具有两个——cachegrind和callgrind。cachegrind主要是统计CPUL1/L2cache的命中数;而callgrind统计函数调用次数以及CPU指令执行次数。
callgrind包含了一个cache类似特性,所以我们可以直接使用callgrind来做profiling。
安装
本人是使用centos做的测试,如果你是linux-like环境,只是安装的方式略有不同,基本都可以在默认的安装源下安装,如果存在找不到的情况,可以下载源码安装。
安装如下:
Step 1
安装Valgrind
yum install valgrind
Step 2
安装kcacheGrind
yum install kcachegrind
kCacheGrind是针对CacheGrind报告分析的可视化工具,需要单独安装。
使用命令
Callgrind有很多参数,但是我们使用默认参数基本就够了
命令如下
valgrind --tool=callgrind --callgrind-out-file=callgrind.log your-program [program options]
当命令程序运行完毕,会生成报告文件callgrind.log
示例如下,
positions: line
events: Ir
summary: 9642152073
Ir的意思是instruction read, collected是说明已经收集了9642152073次
查阅结果
理解Ir次数
Ir次数可以简单理解为CPU指令执行的次数。一句C写的普通代码,一般可以转为一两句或者若干句指令。所以它统计的可能不是代码层级的。
下图是kcachegrind图例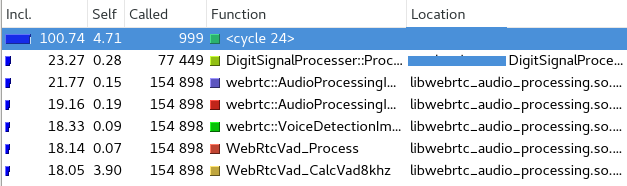
什么是cycle?
从上图中可以看到,排第一的是cycle 24,那么什么是cycle?
cycle是指一组函数,他们相互调用(可能不是直接相互调用),最终形成要给循环。
cycle不一定说明代码存在问题,因为代码也是有recursive的形式;但是这种情况下,对于Valgrind来说,可能不是那么容易看出最耗资源的Function了。
什么是Incl?
首先,这里的数值,是可以是Ir count绝对值或者是相对值(ir count所占总和百分比) 可以通过右键菜单选择不同的展示。
如下图,显示的是Ir count absolute cost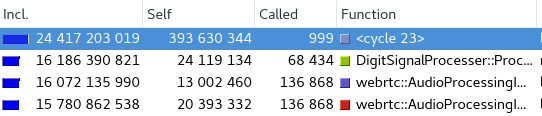
这里提一下,统计数据分为两种方式,inclusive和exclusive。
当你统计function A,那么是指算functionA的Ir count还是也包含内部function的Ir count。
如果包含,那就是inclusive方式;如果不算就是exclusive方式。
这里的incl就是inclusive的意思。
注意事项
- 待测试程序编译过程是否使用-O 可能会影响valgrind的检测结果
- valgrind只能检测运行代码的性能,如果程序执行过程中部分代码没有执行,那么这部分肯定是检测不到的
- valgrind只是做Ir 计数,所以理论上它不是对时间的统计。只能从指令层反应时间的可能消耗
参考与引用
版权归原作者 安安爸Chris 所有, 如有侵权,请联系我们删除。