
文章目录
基本操作
新增Topic
指定两个分区,两个副本,replication不能大于集群中的broker数
[root@hadoop01 kafka_2.12-2.4.0]# bin/kafka-topics.sh --create --zookeeper hadoop01:2181 --partitions 2 --replication-factor 2 --topic hello
Created topic hello.
查询Topic
[root@hadoop01 kafka_2.12-2.4.0]# bin/kafka-topics.sh --list --zookeeper hadoop01:2181
hello
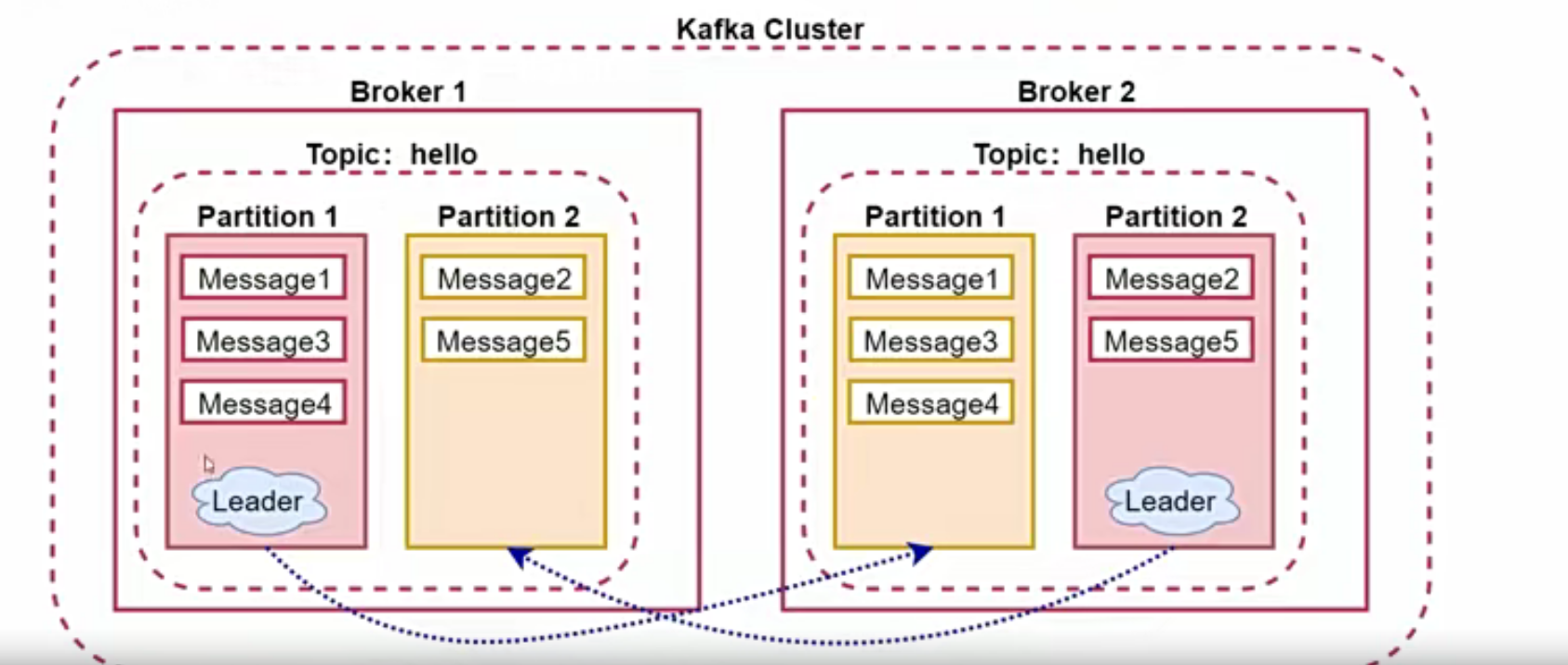
# 查看详细信息[root@hadoop01 kafka_2.12-2.4.0]# bin/kafka-topics.sh --describe --zookeeper hadoop01:2181
Topic: hello PartitionCount: 2 ReplicationFactor: 2 Configs:
Topic: hello Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: hello Partition: 1 Leader: 2 Replicas: 2,0 Isr: 2,0
修改Topic
修改partition的数量,只能增加
[root@hadoop01 kafka_2.12-2.4.0]# bin/kafka-topics.sh --alter --zookeeper hadoop01:2181 --partitions 5 --topic hello
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Adding partitions succeeded![root@hadoop01 kafka_2.12-2.4.0]# bin/kafka-topics.sh --describe --zookeeper hadoop01:2181
Topic: hello PartitionCount: 5 ReplicationFactor: 2 Configs:
Topic: hello Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: hello Partition: 1 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic: hello Partition: 2 Leader: 0 Replicas: 0,2 Isr: 0,2
Topic: hello Partition: 3 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: hello Partition: 4 Leader: 2 Replicas: 2,0 Isr: 2,0
删除Topic
删除topic,删除操作是不可逆的,从1.0开始默认开启删除功能,之前的版本只会标记为删除状态,需要设置delete.topic.enable为true才可以真正删除
[root@hadoop01 kafka_2.12-2.4.0]# bin/kafka-topics.sh --delete --zookeeper hadoop01:2181 --topic helloTopic hello is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
生产者和消费者
创建生产者
bin/kafka-console-prodecer.sh
创建消费者
bin/kafka-console-consumer.sh
[root@hadoop01 kafka_2.12-2.4.0]# bin/kafka-topics.sh --create --zookeeper hadoop01:2181 --partitions 5 --replication-factor 2 --topic hello
Created topic hello.
# producer[root@hadoop01 kafka_2.12-2.4.0]# bin/kafka-console-producer.sh --broker-list hadoop01:9092 --topic hello# consumer 这个只消费最新的消息[root@hadoop01 kafka_2.12-2.4.0]# bin/kafka-console-consumer.sh --bootstrap-server hadoop01:9092 --topic hello# 消费之前的消息[root@hadoop01 kafka_2.12-2.4.0]# bin/kafka-console-consumer.sh --bootstrap-server hadoop01:9092 --topic hello --from-beginning
Broker扩展
配置文件server.properties
# The number of messages to accept before forcing a flush of data to disk# 根据条数选择刷新磁盘的时机log.flush.interval.messages=10000# 根据消息的间隔时间刷新# The maximum amount of time a message can sit in a log before we force a flushlog.flush.interval.ms=1000# The minimum age of a log file to be eligible for deletion due to age 日志保存时间log.retention.hours=168# A size-based retention policy for logs. Segments are pruned from the log unless the remaining# segments drop below log.retention.bytes. Functions independently of log.retention.hours.#log.retention.bytes=1073741824# The maximum size of a log segment file. When this size is reached a new log segment will be created.log.segment.bytes=1073741824# The interval at which log segments are checked to see if they can be deleted according# to the retention policies 每隔5分钟检查文件是否满足删除的条件log.retention.check.interval.ms=300000
Producer扩展
- Partitioner:根据用户设置的算法(比如根据消息的key来设计算法到底分发到哪个分区里面)来计算发送到哪个分区-Partition,默认是随机
- 数据通信方式:同步发送和异步发送,同步是指生产者发送数据后,要等待接收方发回响应后再发送下一个数据的通讯方式;异步指发送生产者发送消息后不等接收方响应就立即发送下一条数据的方式,通信方式通过acks的配置来控制。 - acks:默认为1.表示需要Leader节点回复收到消息- acks:all,表示需要所有的Leader节点以及所有的副本节点回复收到消息(acks=-1)- acks:0,不需要回复
Topic、Partition、Message扩展
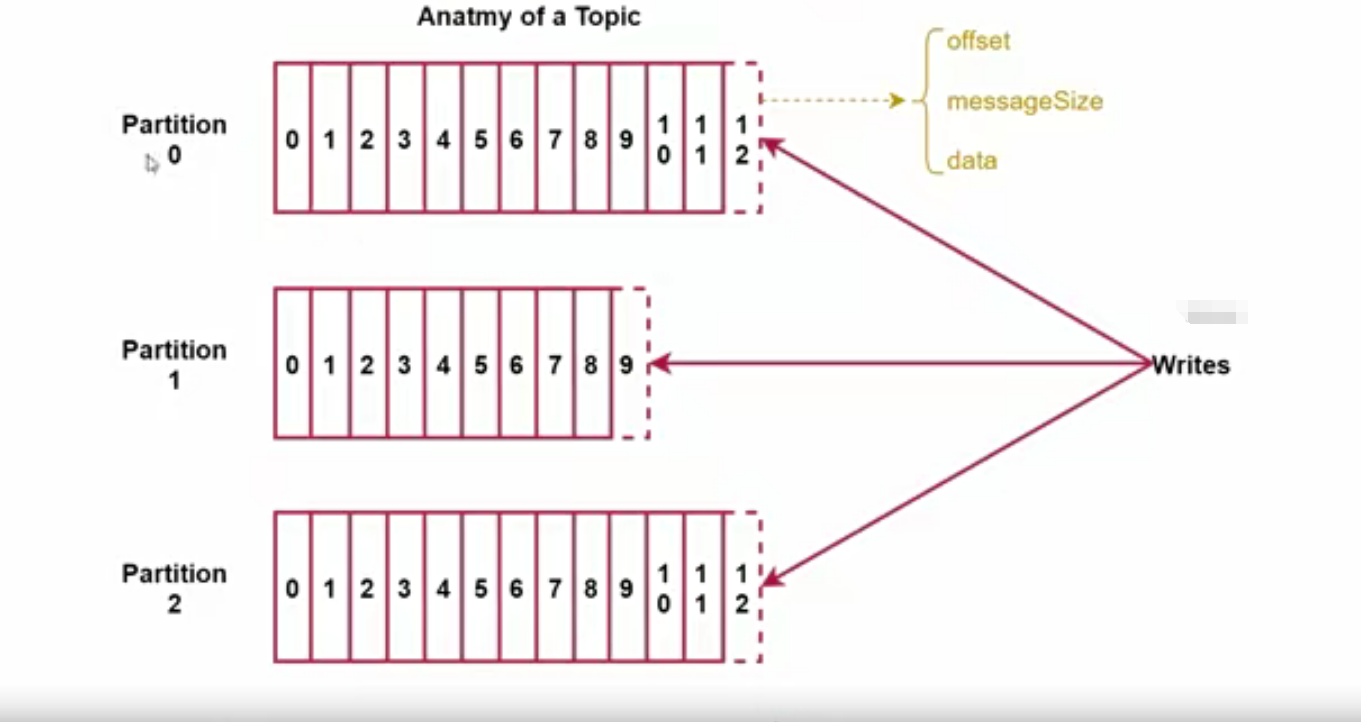
- 每个Partition在存储层面是Append Log文件,新消息都会被直接追加到log文件的尾部,每条消息在log文件中的位置称为offset(偏移量)
- 越多的Partition可以容纳更多的Consumer,有效提升并发消费的能力
- 业务类型增加了可以增加Topic,数据量大需要增加Partition
- Message:offset,类型是long表示此消息在一个Partition中的起始位置,可以认为offset是Partition中的messageId,自增;MessageSize,类似为int32,表示此消息的字节大小;data,类型为bytes,表示message的具体内容
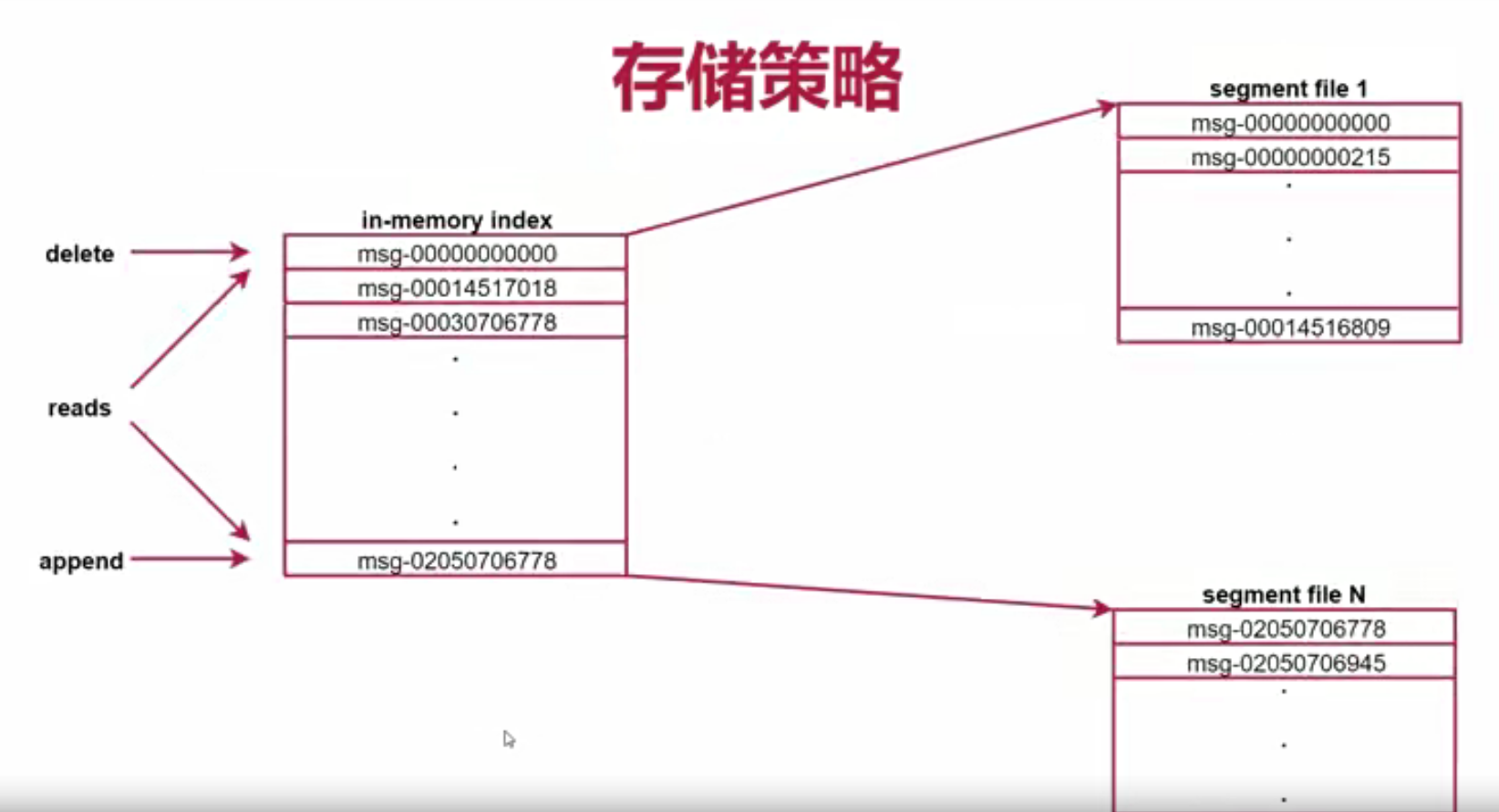
存储策略
- 在kafka中每个topic包含1到多个partition,每个partition存储一部分Message,每条Message包含三个属性,其中有一个是Offset
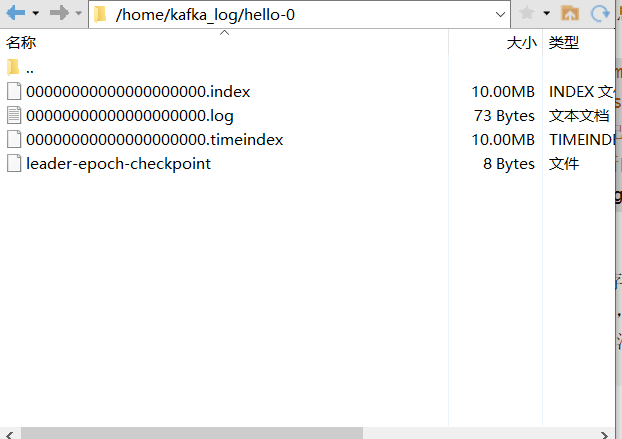
- Offset相当于这个partition中的message的唯一ID,可以通过分段+索引的方式去找到这个message;分段就是segment文件,每个partition由多个segment文件组成;索引就是index,每个index里面都会记录每个segment文件中的第一条数据的偏移量,然后根据这个偏移量就可以去segment文件中找到对应的消息
# The maximum size of a log segment file. When this size is reached a new log segment will be created.# 这个配置就表示每个segment文件的大小,超过这个大小就会再创建一个新的文件log.segment.bytes=1073741824
kafka消息的存储流程:producer生产的消息会被发送到Topic的多个Partition上面,Topic收到消息之后会往partition的最后一个segment文件中添加这条消息,文件达到一定大小后会创建新的文件
容错机制
- 一个Broker宕机后对集群的影响不大
# 模拟节点宕机[root@hadoop01 config]# jps41728 NameNode53523 Kafka42246 ResourceManager59789 Jps41998 SecondaryNameNode52655 QuorumPeerMain[root@hadoop01 config]# kill 53523[root@hadoop01 config]# jps41728 NameNode59809 Jps42246 ResourceManager41998 SecondaryNameNode52655 QuorumPeerMain# 连接到kafka[root@hadoop01 zookeeper3.8.4]# bin/zkCli.sh[zk: localhost:2181(CONNECTED)0]ls /[admin, brokers, cluster, config, consumers, controller, controller_epoch, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper][zk: localhost:2181(CONNECTED)1]ls /brokers [ids, seqid, topics][zk: localhost:2181(CONNECTED)2]ls /brokers/ids [1, 2][zk: localhost:2181(CONNECTED)4] get /brokers/ids/1{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://hadoop02:9092"],"jmx_port":-1,"host":"hadoop02","timestamp":"1710206078306","port":9092,"version":4}[zk: localhost:2181(CONNECTED)5]``````# zookeeper会重新选举leader[root@hadoop01 kafka_2.12-2.4.0]# bin/kafka-topics.sh --describe --zookeeper hadoop01:2181 --topic helloTopic: hello PartitionCount: 5 ReplicationFactor: 2 Configs: Topic: hello Partition: 0 Leader: 2 Replicas: 0,2 Isr: 2 Topic: hello Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1 Topic: hello Partition: 2 Leader: 2 Replicas: 2,1 Isr: 2,1 Topic: hello Partition: 3 Leader: 1 Replicas: 0,1 Isr: 1 Topic: hello Partition: 4 Leader: 1 Replicas: 1,2 Isr: 1,2You have new mail in /var/spool/mail/root- 当kafka集群中新增一个Broker节点,zookeeper会自动识别并在适当的时机选择此节点提供Leader服务# 重新启动[root@hadoop01 kafka_2.12-2.4.0]# bin/kafka-server-start.sh -daemon config/server.properties You have new mail in /var/spool/mail/root[root@hadoop01 kafka_2.12-2.4.0]# jps41728 NameNode60640 Kafka60707 Jps42246 ResourceManager41998 SecondaryNameNode52655 QuorumPeerMain# 进入zookeeper观察[zk: localhost:2181(CONNECTED)2]ls /brokers/ids[0, 1, 2][zk: localhost:2181(CONNECTED)3] get /brokers/ids/0{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://hadoop01:9092"],"jmx_port":-1,"host":"hadoop01","timestamp":"1710221534732","port":9092,"version":4}# 查询kafka topic信息[root@hadoop01 kafka_2.12-2.4.0]# bin/kafka-topics.sh --describe --zookeeper hadoop01:2181 --topic helloTopic: hello PartitionCount: 5 ReplicationFactor: 2 Configs: Topic: hello Partition: 0 Leader: 2 Replicas: 0,2 Isr: 2,0 Topic: hello Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1,0 Topic: hello Partition: 2 Leader: 2 Replicas: 2,1 Isr: 2,1 Topic: hello Partition: 3 Leader: 1 Replicas: 0,1 Isr: 1,0 Topic: hello Partition: 4 Leader: 1 Replicas: 1,2 Isr: 1,2You have new mail in /var/spool/mail/root - 新启动的几点不会是任何分区的leader,所以要重新均匀分配,其实不分配也可以,在kafka中有对应的配置
[root@hadoop01 kafka_2.12-2.4.0]# bin/kafka-leader-election.sh --bootstrap-server hadoop01:9092 --election-type preferred --all-topic-partitionsYou have new mail in /var/spool/mail/root[root@hadoop01 kafka_2.12-2.4.0]# bin/kafka-topics.sh --describe --zookeeper hadoop01:2181 --topic helloTopic: hello PartitionCount: 5 ReplicationFactor: 2 Configs: Topic: hello Partition: 0 Leader: 0 Replicas: 0,2 Isr: 2,0 Topic: hello Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1,0 Topic: hello Partition: 2 Leader: 2 Replicas: 2,1 Isr: 2,1 Topic: hello Partition: 3 Leader: 0 Replicas: 0,1 Isr: 1,0 Topic: hello Partition: 4 Leader: 1 Replicas: 1,2 Isr: 1,2
在kafka中的Broker是无状态的,本身是不保存任何信息的,Broker的所有信息都放在zookeeper里面了,所以,Broker进程挂掉或者启动,对集群的影响不大!
本文转载自: https://blog.csdn.net/Grady00/article/details/136650213
版权归原作者 拉霍拉卡 所有, 如有侵权,请联系我们删除。
版权归原作者 拉霍拉卡 所有, 如有侵权,请联系我们删除。