
在谈起“添加一个键值对元素时,HashMap发生了什么变化?”这个问题前,我们先一起认识一下HashMap的存储结构、HashMap中的哈希函数以及如何计算存储位置。
HashMap的存储结构
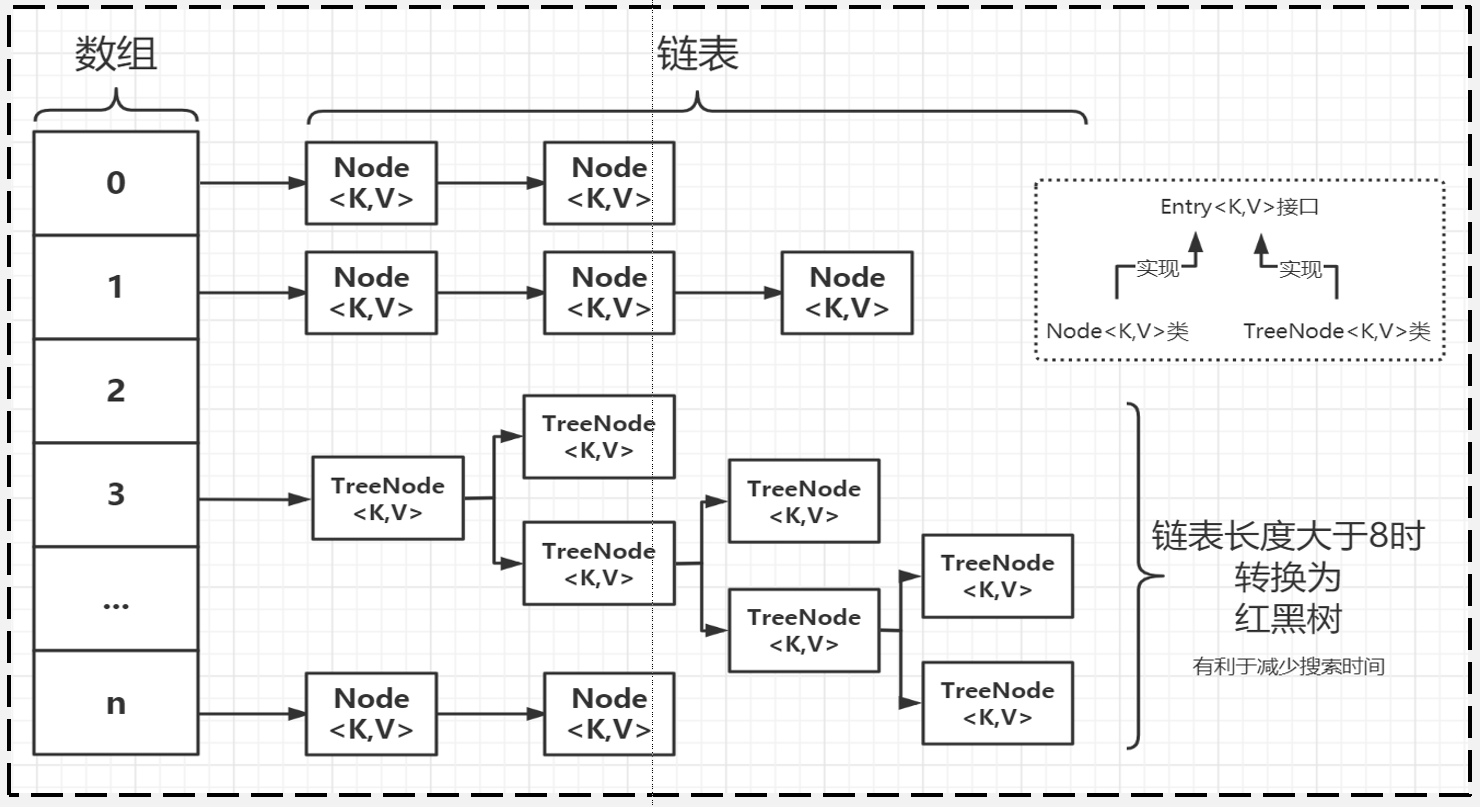
HashMap内部数据结构使用数组+链表+红黑树进行存储。数组类型为Node[],每个Node都保存了某个KV键值对元素的key、value、hash、next等值。由于next的存在,所以每个Node对象都是一个单向链表中的组成节点。
//Node 类型的数组
public class HashMap{
// 每个Node既保存一个KV键值对,同时也是链表中的一个节点
Node<K,V>[] table;
}
//链表节点类 Node
public class HashMap{
// ...
// 静态内部类Node
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; // 哈希值
final K key; // 键
V value; // 值
Node<K,V> next; // 下一个节点(由于只拥有next,所以该链表为单向链表)
}
// ...
}
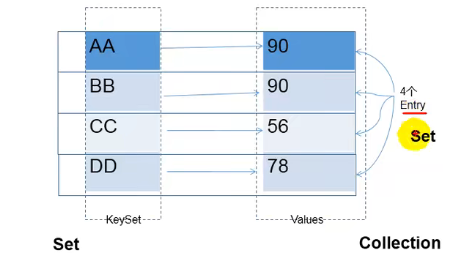
Map中的Key:无序不可重复,使用set进行存储
Map中的Value:无序可重复,使用collection进行存储
Map中的Key-Value键值对:无序不可重复,构成一个entry对象,使用set进行存储
**HashMap中的哈希函数 **
在向HashMap中存储元素时,首先会通过key所在类的hashcode()方法,计算出key的哈希值,然后将该哈希值与其高16位相异或,计算出一个哈希函数,通过该哈希函数来计算在底层数组中的存储位置。
static final int hash(Object key) {
int h;
// 通过key的hashCode()方法返回的哈希值与它的高16位进行异或运算
// 作用:计算出的hash值,在计算下标位置时,会更“散列”,减少哈希冲突
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
HashMap中计算存储位置的方式
首先HashMap初始化时,默认的数组大小只有16,通过位运算1<<4计算得出。并且,数组的长度必须为2n 。因为数组长度为2的n次幂时,可以使用&与位运算,结合hash值,快速计算该元素在数组中的下标位置,提高HashMap的使用效率。
//HashMap内部数组初始默认容量
public class HashMap{
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// 添加键值对
final V putVal(int hash, K key, V value) {
Node<K,V>[] tab; // 数组
Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
// 如果数组为空,则该数组扩容为16
n = (tab = resize()).length;
}
}
添加时,通过key的hash值,使用&按位与位运算,计算该元素在数组中的下标。作用等同于hash % 数组长度。
//通过当前元素key的值计算下标
int index = (数组长度 - 1) & key的hash值
public class HashMap{
// 添加键值对
final V putVal(int hash, K key, V value) {
Node<K,V>[] tab; // 数组
Node<K,V> p; // 临时节点
int n, i; // n代表数组长度,i代表元素下标位置
// 根据当前元素的key的hash值,计算该元素在数组tab中的下标位置i
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
}
}
HashMap底层存储原理
当向HashMap中添加元素(KV键值对)时,首选调用Key所在类的HashCode方法计算Key的哈希值,然后通过该哈希值计算哈希函数,再通过哈希函数计算元素在数组中的存储位置。如果数组中该位置为空则添加成功(情况1);如果该位置已经有元素,则调用Key所在类的HashCode方法计算哈希值并判断两元素的哈希值是否相同,如果哈希值不相同,则添加成功(情况2),如果哈希值相同(即产生了哈希冲突),再调用Key所在类的equals()方法,判断内容是否相同,如果内容不相同则添加成功(情况3),如果内容相同则添加失败。
对于添加成功的情况2和情况3而言,采用链地址法存储:即将要添加的元素封装为一个Node对象,添加到数组中指定下标位置的链表的尾部(尾插法)。如果数组长度达到64,且数组中某一下标位置以链表形式存储的元素超过8个,则该位置的元素采用红黑树进行存储。
了解添加一个元素时,HashMap底层的存储原理后,我们再设想一个问题:我们知道 HashMap的默认容量为16,当我们不断调用put()方法向Map中添加元素时,必然会涉及到扩容问题。那么,HashMap是如何实现扩容的呢?
HashMap扩容
HashMap底层采用数组+链表+红黑树,扩容过程中需要按照数组容量和加载因子来进行判断。
数组容量:基础数组Node<K,V>[] table的长度。如果没有指定容量,添加第一个元素时,该数组按照默认值16进行初始化。
加载因子:用来表示HashMap集合中元素的填满程度,默认为0.75f。越大则表示允许填满的元素就越多,集合的空间利用率就越高,但是冲突的机会增加。反之,越小则冲突的机会就会越少,但是空间很多就浪费。
public class HashMap{
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final float DEFAULT_LOAD_FACTOR = 0.75f;
}
情况1:HashMap中的元素个数超过扩容阈值threshold时,就会进行数组扩容(扩容阈值 = 数组容量 × 加载因子)。例如:加载因子的默认值为0.75f,数组容量默认为16,当HashMap中元素个数超过16 × 0.75=12的时候,数组就会扩容。
情况2:HashMap加入新元素时,如果链表长度大于8时,会将当前链表转换为红黑树。在转换红黑树之前,会判断数组长度,如果小于64,会产生数组扩容。如果数组长度大于64,才会将链表转换为红黑树。(链表属于线性查找,速度慢)
HashMap每次扩容时,会按照当前数组的容量扩容2倍。例如:当前数组容量为16,当HashMap中元素个数超过16 × 0.75=12的时候,数组就会扩容2倍;
// 新容量 = 原有容量的2倍
newCap = oldCap << 1
如何文章对你有帮助,请留下你的点赞,谢谢!
版权归原作者 小田同学卷代码 所有, 如有侵权,请联系我们删除。