
闲着没事想写一个爬虫去爬取一下百度图片,但是通过连接访问发现返回的是 百度安全验证,然后发现selenium下的web driver可以直接调起浏览器访问网址,并且可以拿到网站内容,所以根据这个写了一个爬虫,代码可以在window上直接运行。
所需第三方库
import time
#用于调起浏览器
from selenium import webdriver
# 用来解析网页内容
from bs4 import BeautifulSoup
import os, requests,re
安装第三方库
可以考虑使用阿里云镜像加快安装速度,只需要把bs4换成对应的第三方库就可以。
pip install -i https://mirrors.aliyun.com/pypi/simple/ bs4
观察页面代码,查看自己需要爬去的标签格式
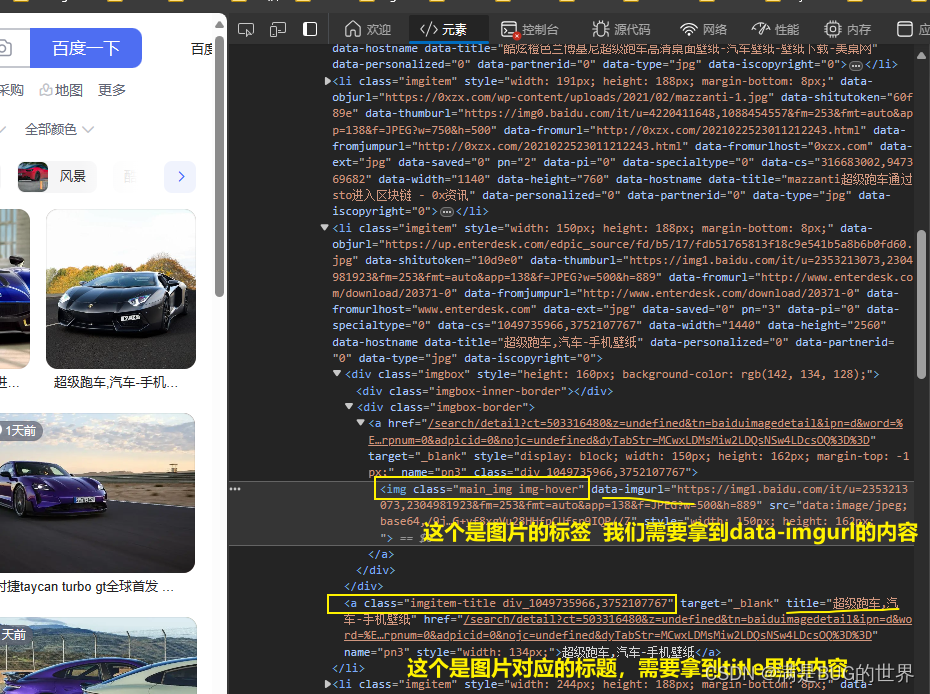
通过F12查看页面源代码可以发现,图片的标签是**<img class="main_img img-hover"** 标签下,我们需要拿到这个标签里的data-imgurl属性的内容。标题则是在**<a class= "imgitem-title "**标签下,我们需要title的内容拿来当标题
可以使用 bs4包里的 BeautifulSoup 用来解析网页拿到这两个标签获取我们想要的属性内容
#HTML解析器
b = BeautifulSoup(text, "html.parser")
# 得到页面中所有 img标签并且class是main_img img-hover开头的图片列表
img = b.find_all("img", class_="main_img img-hover")
# 得到页面中所有 a标签并且class是imgitem-title开头的图片标题列表
title = b.find_all("a", class_="imgitem-title")
直接上完整代码,可直接运行
我这里使用的是edge浏览器,如果想使用谷歌,可以把 webdriver.Edge() 换成 webdriver.Chrome();需要注意的是webdriver和浏览器的版本对应不上可能会调不起来。
import time
from selenium import webdriver
from bs4 import BeautifulSoup
import os, requests,re
# 图片存储地址
path = r"D:\pythonTest\photos"
# 正则表达式 过滤并得到图片标题中所有的中文
pattern = '[\u4e00-\u9fa5]+'
def parseHtml(text):
# 因为title标签有很多错误数据,所以记录一下下标
titleIndex = 0;
#HTML解析器
b = BeautifulSoup(text, "html.parser")
# 得到页面中所有 img标签并且class是main_img img-hover开头的图片列表
img = b.find_all("img", class_="main_img img-hover")
# 得到页面中所有 a标签并且class是imgitem-title开头的图片标题列表
title = b.find_all("a", class_="imgitem-title")
# 循环拿到的图片列表,解析标题下载图片
for index, value in enumerate(img):
imageUrl = img[index]["data-imgurl"]
imageName = "default" + str(index)
# 一个循环用于拿到每个图片的正确标题
if len(title) > index:
titleIndex = getImageTitle(title, titleIndex)
imageName = "".join(re.findall(pattern, title[titleIndex].text))
if imageName == "":
imageName = "default" + str(index)
titleIndex += 1
imageName += ".jpg"
print("准备下载第%s个图片,名字叫:%s 地址:%s" % (str(index+1), imageName, imageUrl))
savePhoto(imageUrl, imageName)
# 页面里有很多class=imgitem-title的标签,图片的标题一般有title属性,根据title属性过滤标签
def getImageTitle(title, index):
if "title" in title[index].attrs:
return index
else:
getImageTitle(title, index + 1)
return index + 1
# 保存照片
def savePhoto(imageUrl, filename):
p = os.path.join(path, filename)
c = requests.get(imageUrl)
createFile(path)
with open(p, 'wb') as f:
f.write(c.content)
time.sleep(0.3)
print("下载完了 休息0.3秒")
# 创建本地文件
def createFile(path):
print("path:",path)
file = os.path.exists(path)
if not file:
os.makedirs(path)
# 滑动浏览器窗口,加载更多图片,滑动一次加载20多张图片
# numer为想滑动的次数
def slideBrowseWindow(driver, number):
for i in range(number):
time.sleep(0.1)
driver.execute_script("window.scrollBy(0,{})".format(i * 1000))
time.sleep(0.3)
if __name__ == "__main__":
#这里的豪车可以改成自己想搜索的内容
searchName = "豪车"
#这里使用的是edge浏览器,如果想使用谷歌浏览器,可以换成webdriver.Chrome()
driver = webdriver.Edge()
driver.get("https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1709260324755_R&pv=&ic=&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&dyTabStr=MCwxLDMsMiw4LDYsNCw1LDcsOQ%3D%3D&ie=utf-8&sid=&word="+ searchName +"&f=3&oq=%E7%BE%8E%E5%A5%B3&rsp=0")
# 百度图片是下滑加载更多
slideBrowseWindow(driver, 10)
# 获取页面的源代码
page_source = driver.page_source
# 输出页面源代码
parseHtml(page_source)
driver.quit()
print("done.")
本文转载自: https://blog.csdn.net/L1481333167/article/details/136678967
版权归原作者 满是BUG的世界 所有, 如有侵权,请联系我们删除。
版权归原作者 满是BUG的世界 所有, 如有侵权,请联系我们删除。