
Mac 配置Hadoop、spark、Scala、jdk1.8
一、安装jdk1.8(适配于 Mac M1芯片)
下载地址:
Java Downloads | Oracle
1.下载好使用 终端 进行解压
tar -zxf jdk-8u401-macosx-aarch64.tar.gz
2.配置环境变量
1.终端打开 .bash_profile
vim ~/.bash_profile
2.将以下代码放进 .bash_profile 里面(注意修改路径)
export PATH=${PATH}:/Users/laohe_juan/Downloads/jdk1.8.0_401.jdk/Contents/Home
export PATH=$JAVA_HOME/bin:$PATH
3.esc按键 + :号键 输入 wq (保存并退出)
4.重新加载 .bash_profile 文件
source ~/.bash_profile
5.输入以下代码检查配置是否成功
java -version

二、安装Spark
下载链接:
News | Apache Spark
1.下载好并使用 终端 进行解压
tar -zxf spark-3.1.1-bin-hadoop3.2.tar
2.进行环境配置
1.终端打开 .bash_profile
vim ~/.bash_profile
2.以下代码放进 .bash_profile 里面(注意修改路径)
# 方式一
export SPARK_HOME=/Users/laohe_juan/Downloads/spark-3.1.1-bin-hadoop3.2
export PATH=$PATH:$SPARK_HOME/bin
export PYSPARK_PYTHON=python3
# 注意 python3是自己系统安装的版本
# 方式二 需要先安装 Hadoop 请先跳转到安装 Hadoop 记得再返回到此处
export SPARK_HOME=/Users/laohe_juan/Downloads/spark-3.1.1-bin-hadoop3.2
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
3.esc按键 + :号键 输入 wq (保存并退出)
4.重新加载 .bash_profile 文件
source ~/.bash_profile
5.输入以下代码检查配置是否成功
pyspark

使用方式二: (确保 Hadoop 安装完成,否则 请跳转到 安装 Hadoop)
1.进入 conf 修改 文件名
cd Downloads/spark-3.1.1-bin-hadoop3.2/conf
# 修改一下两个文件
mv spark-env.sh.template spark-enc.sh
mv workers.template workers
2.修改配置文件 spark-enc.sh
vim spark-enc.sh
添加如下:( 注意修改地址 )
export JAVA_HOME=/Users/laohe_juan/Downloads/jdk1.8.0_401.jdk/
export HADOOP_HOME=/Users/laohe_juan/Downloads/hadoop-3.1.3/
export HADOOP_CONF_DIR=/Users/laohe_juan/Downloads/hadoop-3.1.3/etc/hadoop
export SPARK_MASTER_HOST=localhost
3.进入 sbin 修改 启动命令 (使不与 hadoop 同样)
mv start-all.sh start-spark.sh //启动spark
mv stop-all.sh stop-spark.sh //关闭spark
4.启动spark (出现 Master 和 Worker 则启动成功)
start-spark.sh
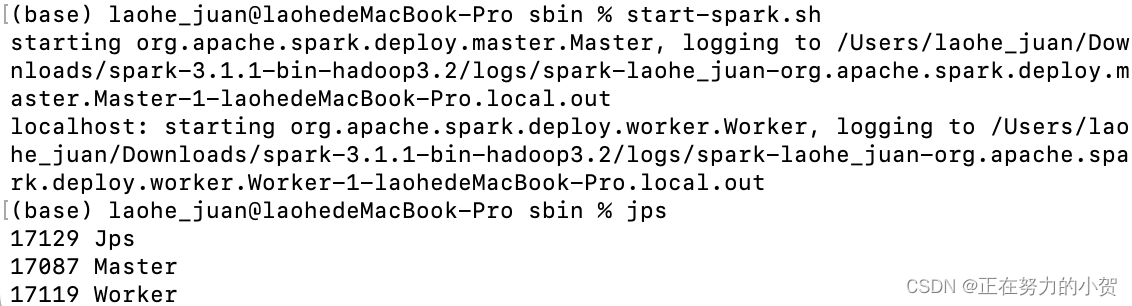
三、安装Hadoop(确保ssh)
下载链接:
Apache Hadoop
0.ssh
1.确保已经安装SSH
ps -e|grep ssh
查看版本号:
ssh -V
2.依次输入以下命令(免密)
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/id_rsa.pub
3.ssh测试
ssh localhost

1.下载好并使用 终端 进行解压
tar -zxf hadoop-3.1.3.tar
2.进行环境配置
1.终端打开 .bash_profile
vim ~/.bash_profile
2.以下代码放进 .bash_profile 里面(注意修改路径)
export HADOOP_HOME=/Users/laohe_juan/Downloads/hadoop-3.1.3/
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/nativ"
3.esc按键 + :号键 输入 wq (保存并退出)
4.重新加载 .bash_profile 文件
source ~/.bash_profile
5.输入以下代码检查配置是否成功
hadoop version
3.修改配置文件(首先进入到Hadoop)
cd /Users/laohe_juan/Downloads/hadoop-3.1.3/etc/hadoop
1.打开 hadoop-env.sh 配置 jdk 路径 ( 注意路径两边的引号需要添加 )
export JAVA_HOME="/Users/laohe_juan/Downloads/jdk1.8.0_401.jdk/Contents/Home"
2.配置 core-site.sh 文件 ( 注意路径需要修改为自己的 )
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/Users/laohe_juan/Downloads/hdfs/tmp/</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
</configuration>
3.配置 hdfs-site.xml 文件 ( 注意路径需要修改为自己的 )
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/Users/laohe_juan/Downloads/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/Users/laohe_juan/Downloads/hdfs/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4.配置 mapred-site.xml 文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.配置 yarn-site.xml 文件
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>127.0.0.1</value>
</property>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PERPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
6.执行 命令
hdfs namenode -format
成功则如下:
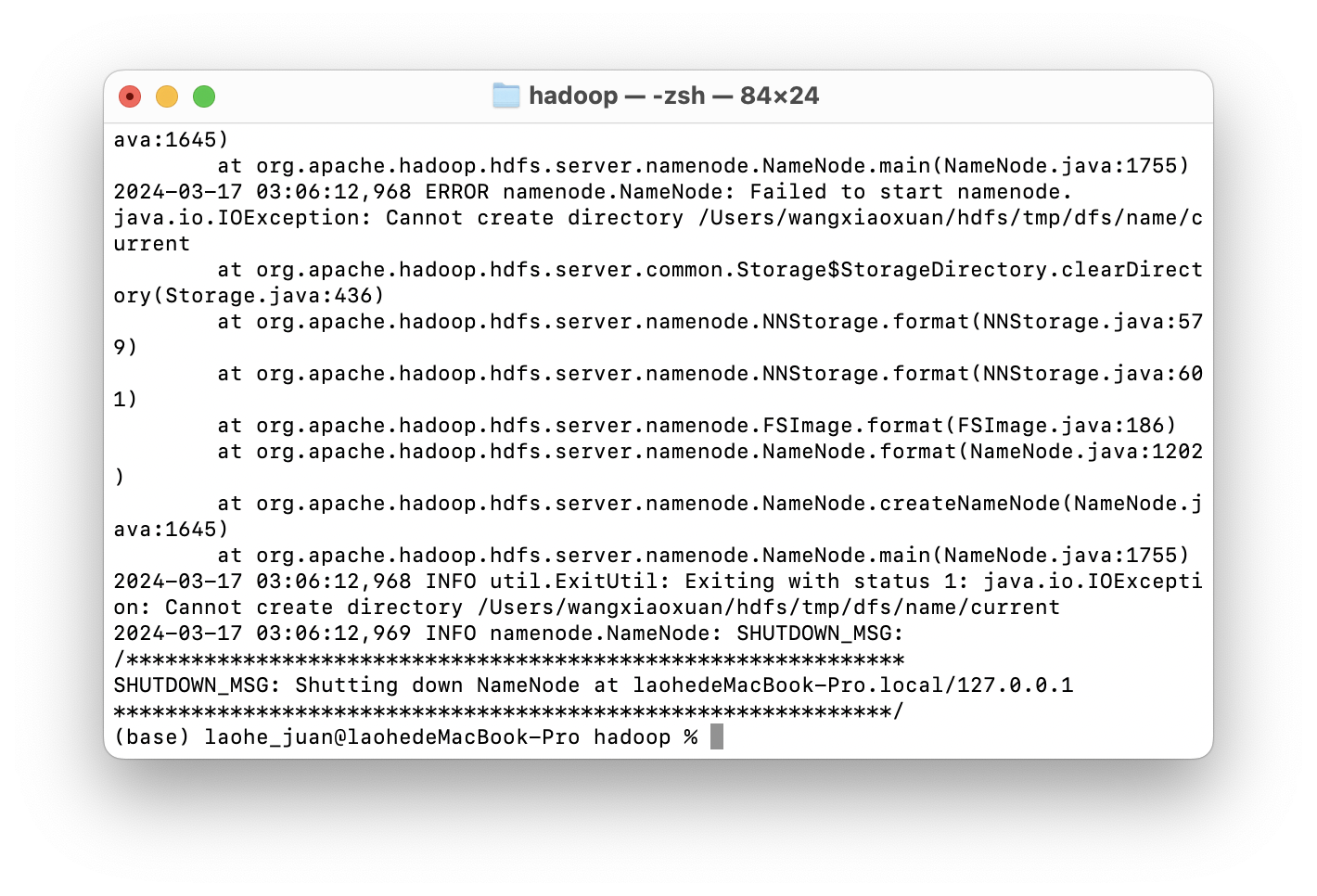
注意:如果后面有进程没有启动成功时,切记 查看进程(在安装目录下的 logs 目录),然后有关 没有匹配的目录类型的日志报错的话,多半是在最开始配置中有错误然后没有重新生成对应的目录及文件!所以重新执行此命令大概率就解决了。
7.启动集群
start-all.sh
8.查看集群是否全部启动成功
jps
Hadoop 配置文件总阅:

成功后的所有进程:
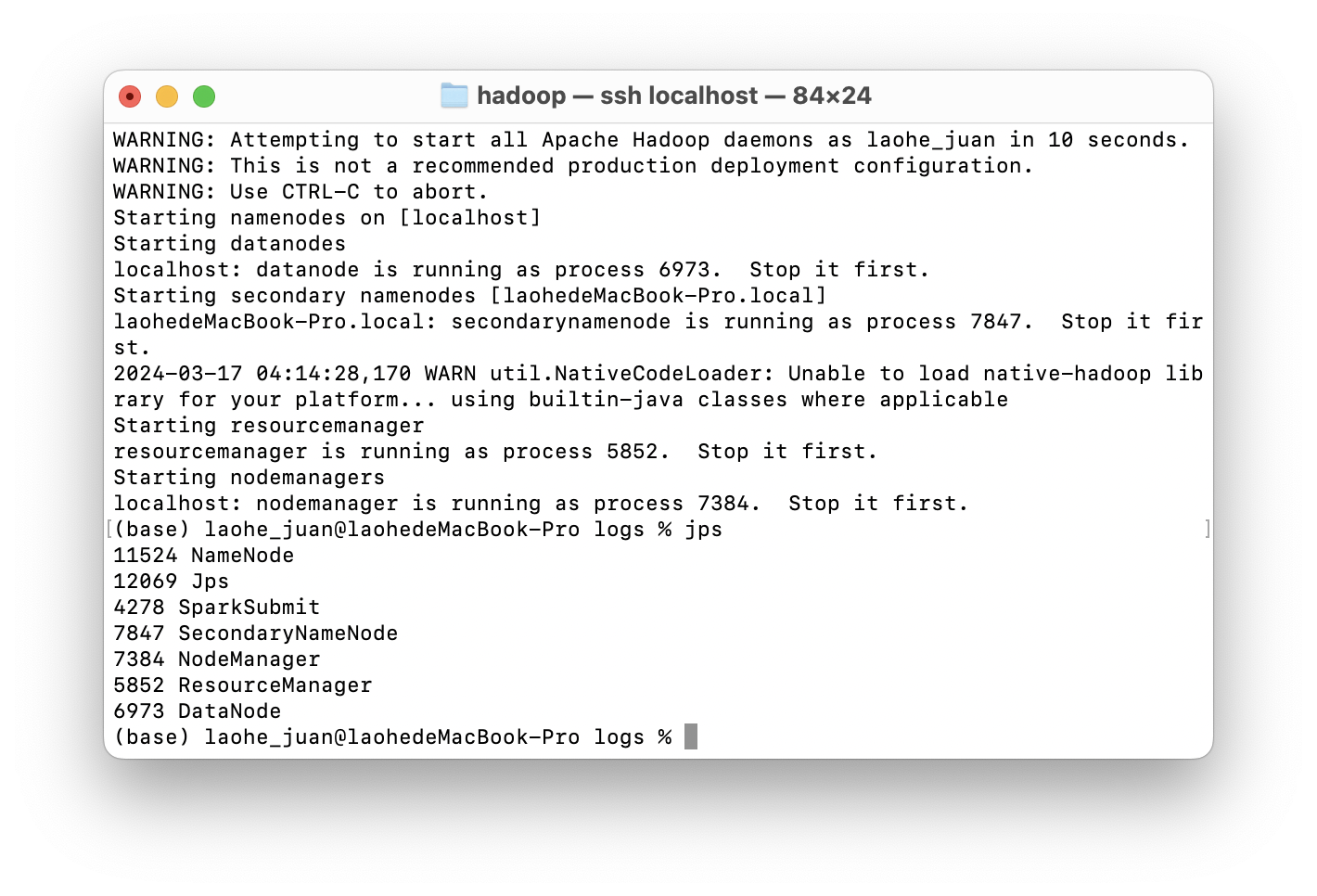
四、安装Scala ( 确保有java环境 )
下载安装(此用到的是2.12版本)
下载地址:Scala 2.12.0 | The Scala Programming Language
1.下载好使用 终端 解压
tar -zxf scala-2.12.0.tar
2.配置环境变量
1.终端打开 .bash_profile
vim ~/.bash_profile
2.将以下代码放进 .bash_profile 里面(注意修改路径)
export PATH=${PATH}:/Users/laohe_juan/Downloads/scala-2.12.0/bin
export PATH=$SCALA_HOME/bin:$PATH
3.esc按键 + :号键 输入 wq (保存并退出)
4.重新加载 .bash_profile 文件
source ~/.bash_profile
5.输入以下代码检查配置是否成功
scala -version

本文转载自: https://blog.csdn.net/hjjhjji/article/details/136788420
版权归原作者 正在努力的小贺 所有, 如有侵权,请联系我们删除。
版权归原作者 正在努力的小贺 所有, 如有侵权,请联系我们删除。