
Flink学习笔记-1
Flink的核心目标,是"数据流上的有状态计算"。
具体说明:ApacheFlink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。
一、Flink概述
无界数据流
例如从Kafka这样的消息组件中读取的数据一般,没有数据流结束的定义,即使没有数据也在进行消费。
有界数据流
有界数据流能够等到所有数据都提取之后再进行处理。
有状态流处理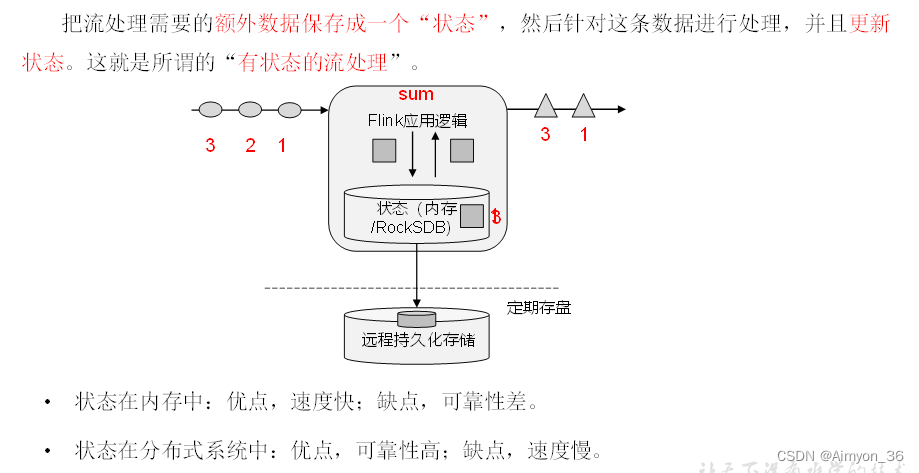
将数据的中间状态进行存储,能够重复使用该状态进行处理。
Flink的特点
Flink vs SparkStreaming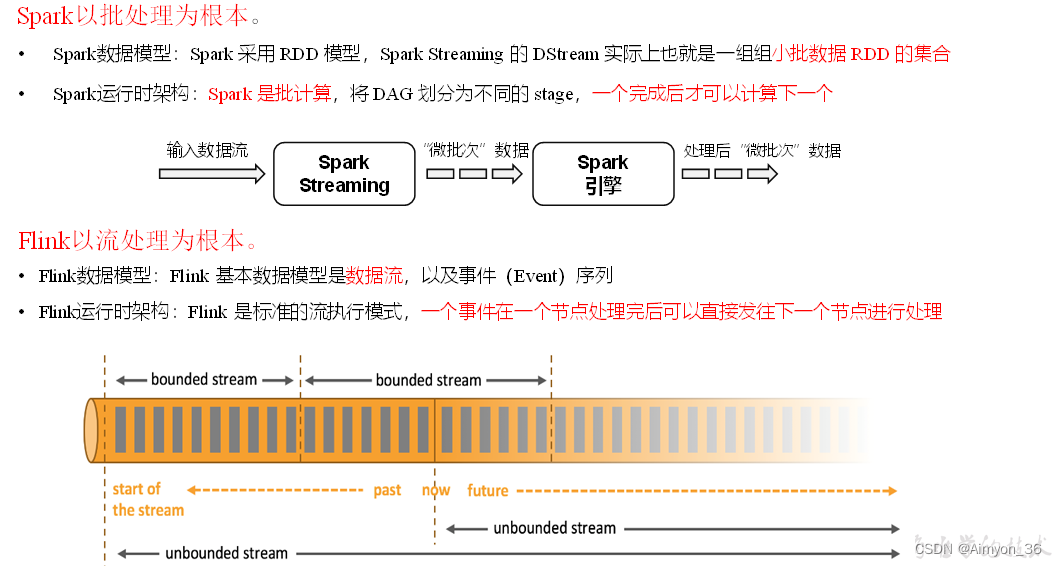
FlinkSparkStreaming计算模型流计算微批处理时间语义事件时间、处理时间处理时间窗口多、灵活少、不灵活(窗口必须是批次的整数倍)状态有没有流式SQL有没有
Flink分层API
二、Flink集群角色和核心概念
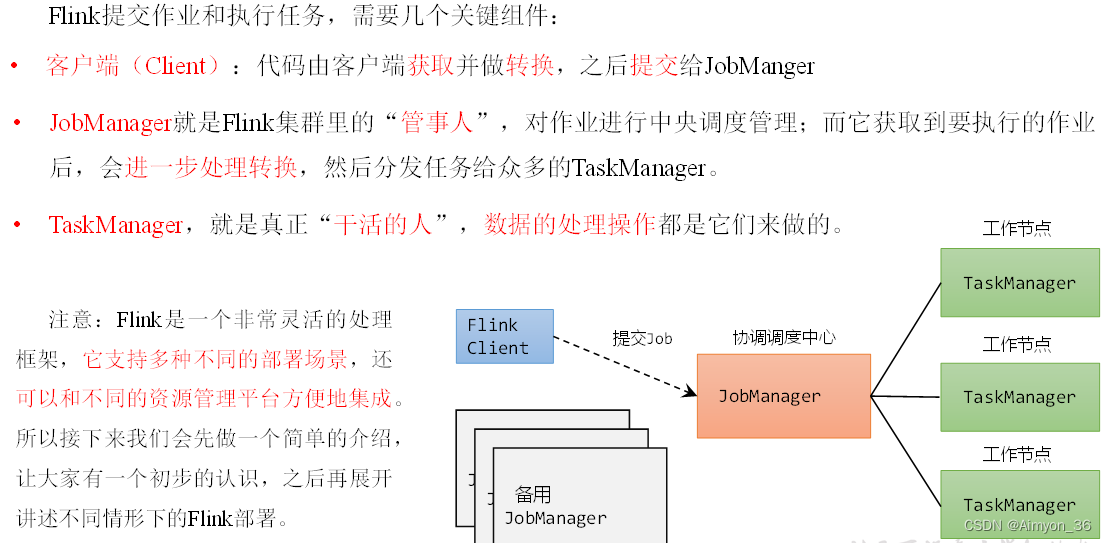
1.Flink运行时架构(Standealone会话模式)
1)作业管理器(JobManager)
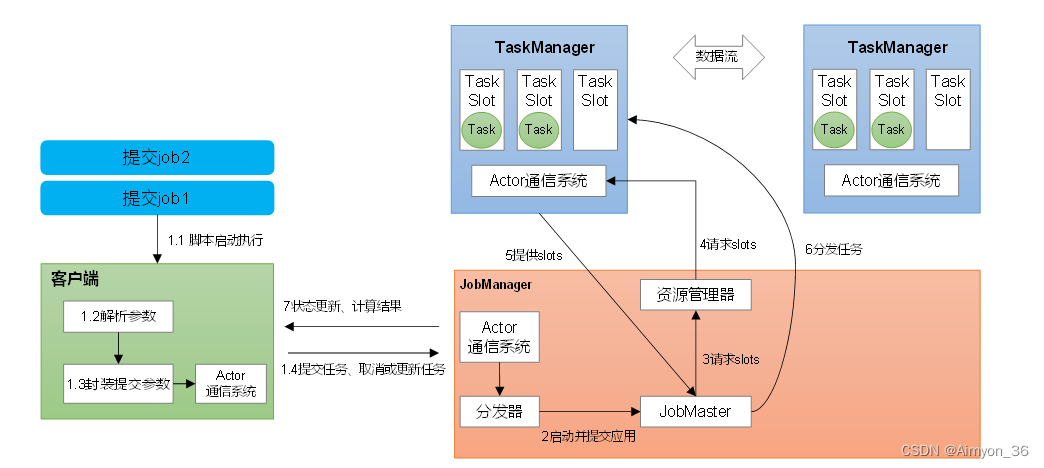
JobManager是一个Flink集群中任务管理和调度的核心,是控制应用执行的主进程。也就是说,每个应用都应该被唯一的JobManager所控制执行。
(1)JobMaster
JobMaster是JobManager中最核心的组件,负责处理单独的作业(Job)。所以JobMaster和具体的Job是一一对应的,多个Job可以同时运行在一个Flink集群中, 每个Job都有一个自己的JobMaster。在早期版本的Flink中JobManager实际指的就是现在所说的JobMaster。
在作业提交时,JobMaster会先接收到要执行的应用。JobMaster会把JobGraph转换成一个物理层面的数据流图,这个图被叫作“执行图”(ExecutionGraph),它包含了所有可以并发执行的任务。JobMaster会向资源管理器(ResourceManager)发出请求,申请执行任务必要的资源。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager上。
运行过程中,JobMaster会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。
(2)资源管理器(ResourceManager)
ResourceManager主要负责资源的分配和管理,在Flink 集群中只有一个。所谓“资源”,主要是指TaskManager的任务槽(task slots)。任务槽就是Flink集群中的资源调配单元,包含了机器用来执行计算的一组CPU和内存资源。每一个任务(Task)都需要分配到一个slot上执行。
该ResourceManager是Flink内置的
(3)分发器(Dispatcher)
Dispatcher主要负责提供一个REST接口,用来提交应用,并且负责为每一个新提交的作业启动一个新的JobMaster 组件。Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。Dispatcher在架构中并不是必需的,在不同的部署模式下可能会被忽略掉。
2)任务管理器(TaskManager)
TaskManager是Flink中的工作进程,数据流的具体计算就是它来做的。Flink集群中必须至少有一个TaskManager;每一个TaskManager都包含了一定数量的任务槽(task slots)。Slot是资源调度的最小单位,slot的数量限制了TaskManager能够并行处理的任务数量。
启动之后,TaskManager会向资源管理器注册它的slots;收到资源管理器的指令后,TaskManager就会将一个或者多个槽位提供给JobMaster调用,JobMaster就可以分配任务来执行了。
在执行过程中,TaskManager可以缓冲数据,还可以跟其他运行同一应用的TaskManager交换数据。
2.并行度(Parallelism)
当要处理的数据量非常大时,我们可以把一个算子操作,“复制”多份到多个节点,数据来了之后就可以到其中任意一个执行。这样一来,一个算子任务就被拆分成了多个并行的“子任务”(subtasks),再将它们分发到不同节点,就真正实现了并行计算。
在Flink执行过程中,每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些子任务在不同的线程、不同的物理机或不同的容器中完全独立地执行。
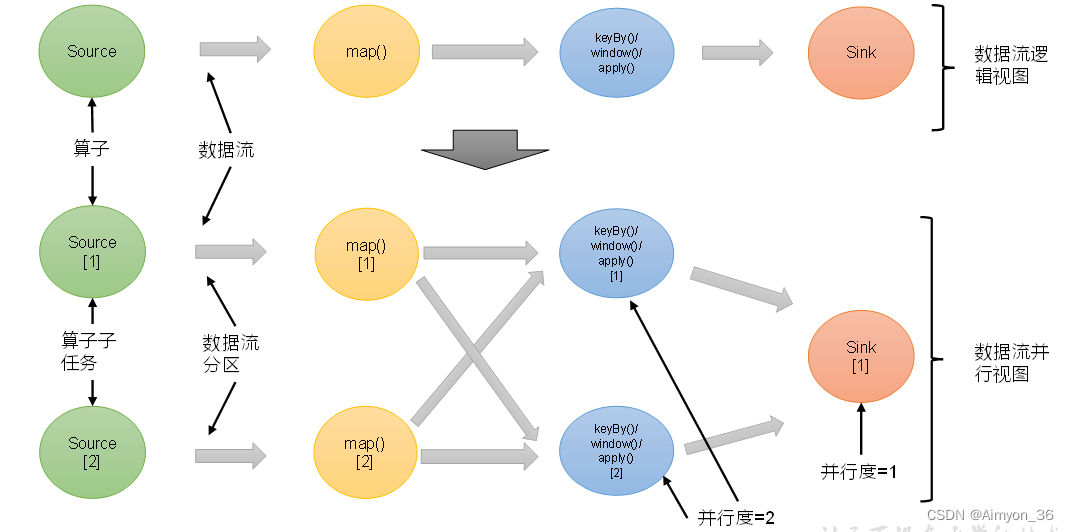
一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。这样,包含并行子任务的数据流,就是并行数据流,它需要多个分区(stream partition)来分配并行任务。一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
例如:如上图所示,当前数据流中有source、map、window、sink四个算子,其中sink算子的并行度为1,其他算子的并行度都为2。所以这段流处理程序的并行度就是2。
不同于Spark的RDD分区,Flink中每个算子都能够设置并行度。
并行度优先级: 算子单独设定 > env > 程序提交时指定 > 配置文件
3.算子链(Operator Chain)
一个数据流在算子之间传输数据的形式可以是一对一(one-to-one)的直通(forwarding)模式,也可以是打乱的重分区(redistributing)模式,具体是哪一种形式,取决于算子的种类。
(1)一对一(One-to-one,forwarding)
这种模式下,数据流维护着分区以及元素的顺序。比如图中的source和map算子,source算子读取数据之后,可以直接发送给map算子做处理,它们之间不需要重新分区,也不需要调整数据的顺序。这就意味着map 算子的子任务,看到的元素个数和顺序跟source 算子的子任务产生的完全一样,保证着“一对一”的关系。map、filter、flatMap等算子都是这种one-to-one的对应关系。这种关系类似于
Spark中的窄依赖。
(2)重分区(Redistributing)
在这种模式下,数据流的分区会发生改变。比如上图中的map和后面的keyBy/window算子之间,以及keyBy/window算子和Sink算子之间,都是这样的关系。
每一个算子的子任务,会根据数据传输的策略,把数据发送到不同的下游目标任务。这些传输方式都会引起重分区的过程,这一过程类似于Spark中的shuffle(宽依赖)。
(3)合并算子链
在Flink中,并行度相同的一对一(one to one)算子操作,可以直接链接在一起形成一个“大”的任务(task),这样原来的算子就成为了真正任务里的一部分,如下图所示。每个task会被一个线程执行。这样的技术被称为“算子链”(Operator Chain)。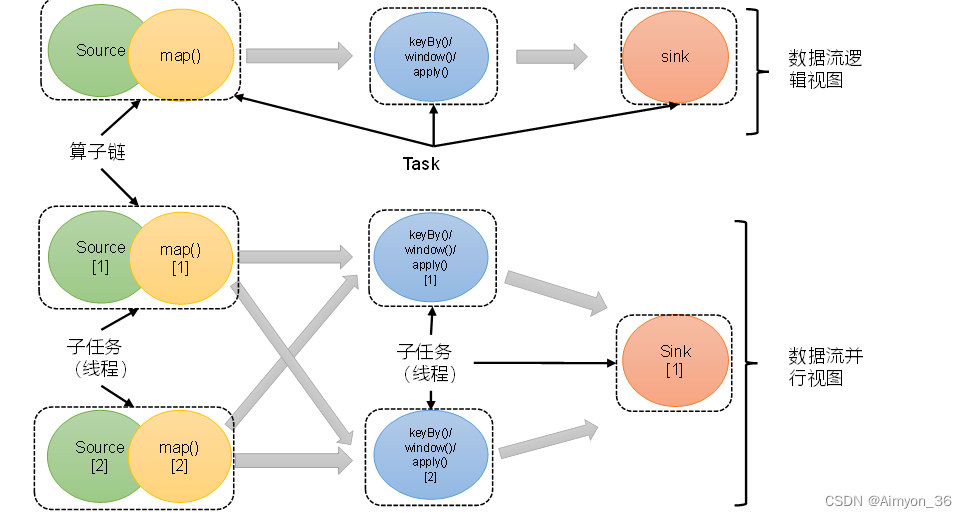
上图中Source和map之间满足了算子链的要求,所以可以直接合并在一起,形成了一个任务;因为并行度为2,所以合并后的任务也有两个并行子任务。
原先map算子和Source算子并行度都为2并且都是一对一的算子操作,经过合并之后,原先需要使用4个线程的map和source算子只需要启用2个线程。
将算子链接成task是非常有效的优化:可以减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。
Flink默认会按照算子链的原则进行链接合并,如果我们想要禁止合并或者自行定义,也可以在代码中对算子做一些特定的设置:
// 禁用算子链
该算子不会与前一个或者后一个算子串在一块
.map(word ->Tuple2.of(word,1L)).disableChaining();// 从当前算子开始新链
该算子不与前一算子串在一起
.map(word ->Tuple2.of(word,1L)).startNewChain()
当两个算子的运算逻辑复杂时,可以选择将这两个算子分开。
4. 任务槽(Task Slots)
Flink中每一个TaskManager都是一个JVM进程,它可以启动多个独立线程,来并行执行多个子任务。
TaskManager的计算资源是有限的,并行的任务越多,每个线程的资源就会越少。那一TaskManager到底能并行处理多少个任务呢?为了控制并发量,我们需要在TaskManager上对每个任务运行所占用的资源做出明确的划分,这就是所谓的任务槽(task slots)。
每个任务槽(task slot)其实表示了TaskManager拥有计算资源的一个固定大小的子集。这些资源就是用来独立执行一个子任务的。
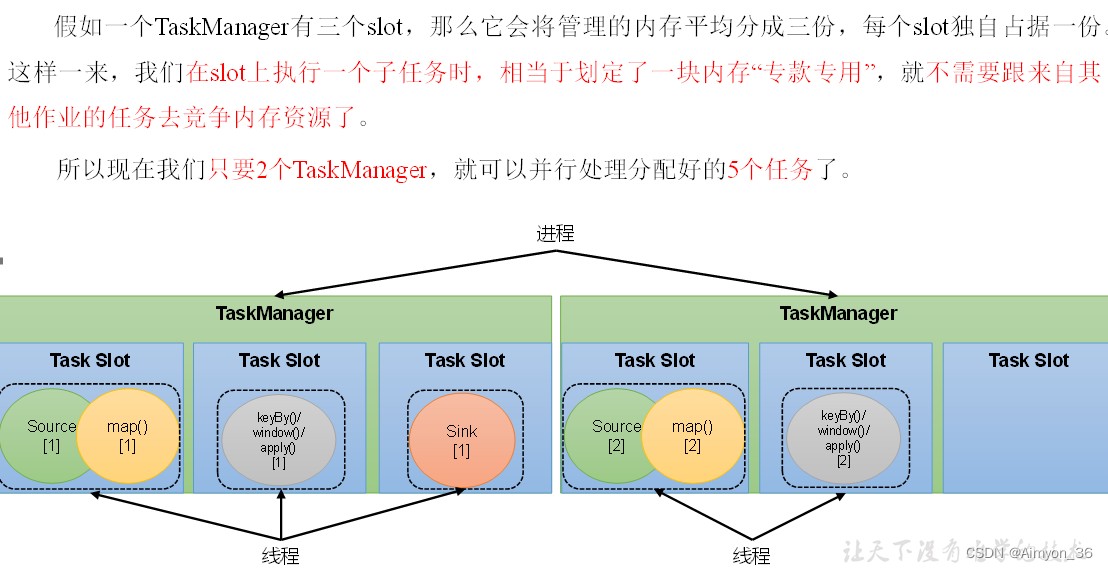
需要注意的是,slot目前仅仅用来隔离内存,不会涉及CPU的隔离。在具体应用时,可以将slot数量配置为机器的CPU核心数,尽量避免不同任务之间对CPU的竞争。这也是开发环境默认并行度设为机器CPU数量的原因。
任务对任务槽的共享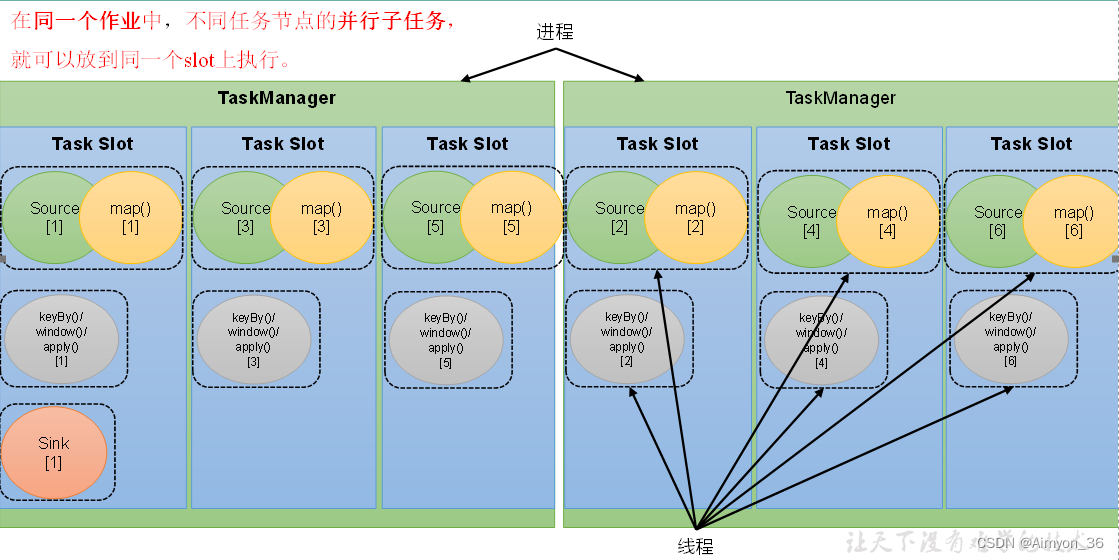
默认情况下,Flink是允许子任务共享slot的。如果我们保持sink任务并行度为1不变,而作业提交时设置全局并行度为6,那么前两个任务g节点就会各自有6个并行子任务,整个流处理程序则有13个子任务。
如上图所示,只要属于同一个作业(程序),那么对于不同任务节点(算子)的并行子任务,就可以放到同一个slot上执行。所以对于第一个任务节点source→map,它的6个并行子任务必须分到不同的slot上,而第二个任务节点keyBy/window/apply的并行子任务却可以和第一个任务节点共享slot。
在同一个slot中,子任务是同时运行的
当我们将资源密集型和非密集型的任务同时放到一个slot中,它们就可以自行分配对资源占用的比例,从而保证最重的活平均分配给所有的TaskManager。
slot共享另一个好处就是允许我们保存完整的作业管道。这样一来,即使某个TaskManager出现故障宕机,其他节点也可以完全不受影响,作业的任务可以继续执行。
当然,Flink默认是允许slot共享的,如果希望某个算子对应的任务完全独占一个slot,或者只有某一部分算子共享slot,我们也可以通过设置“slot共享组”手动指定:
.map(word ->Tuple2.of(word,1L)).slotSharingGroup("1");
这样,只有属于同一个slot共享组的子任务,才会开启slot共享;不同组之间的任务是完全隔离的,必须分配到不同的slot上。在这种场景下,总共需要的slot数量,就是各个slot共享组最大并行度的总和。
任务槽和并行度的关系
任务槽和并行度都跟程序的并行执行有关,但两者是完全不同的概念。简单来说任务槽是静态的概念,是指TaskManager具有的并发执行能力,可以通过参数taskmanager.numberOfTaskSlots进行配置;而并行度是动态概念,也就是TaskManager运行程序时实际使用的并发能力,可以通过参数parallelism.default进行配置。
举例说明:假设一共有3个TaskManager,每一个TaskManager中的slot数量设置为3个,那么一共有9个task slot,表示集群最多能并行执行9个同一算子的子任务。
而我们定义word count程序的处理操作是四个转换算子:
source→ flatmap→ reduce→ sink
当所有算子并行度相同时,容易看出source和flatmap可以合并算子链,于是最终有三个任务节点。
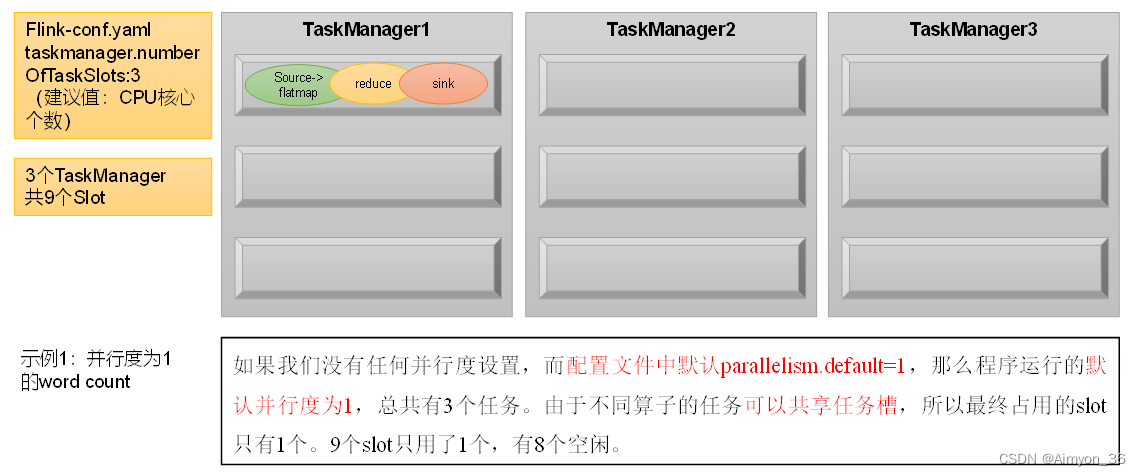
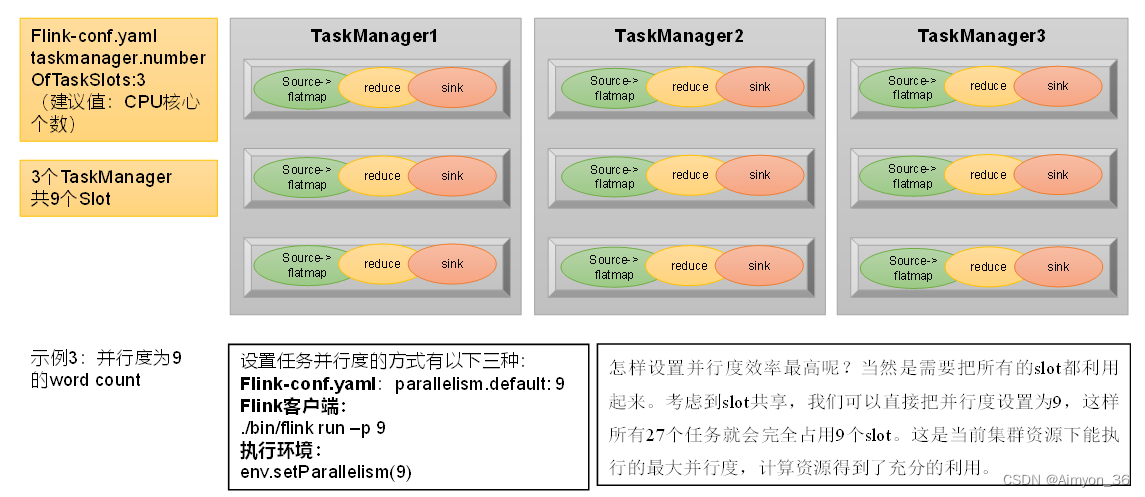
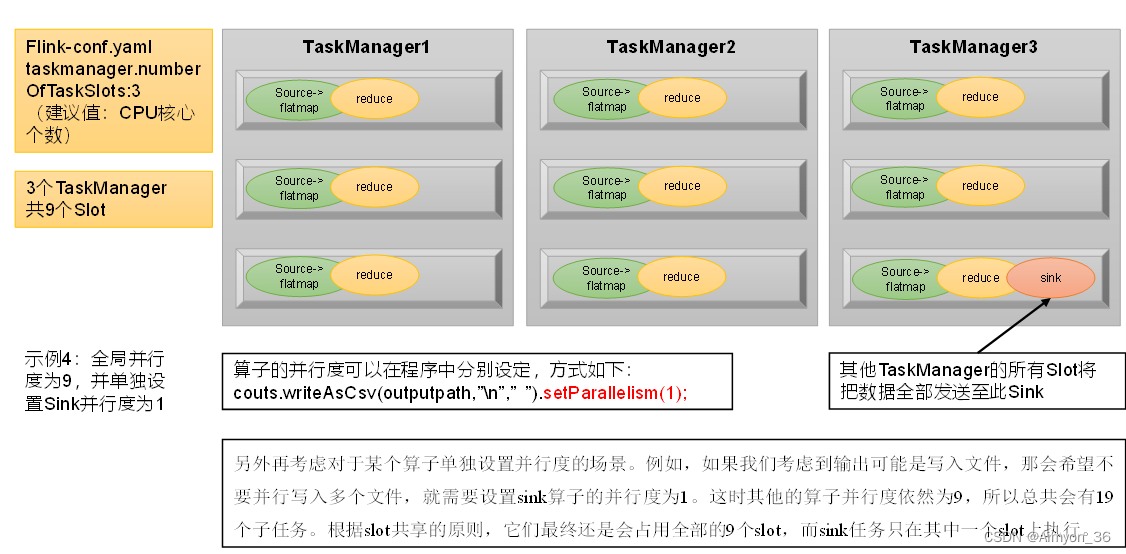
整个流处理程序的并行度,就应该是所有算子并行度中最大的那个,这代表了运行程序需要的slot数量。
三、Flink作业提交流程
1.Standalone会话模式作业提交流程
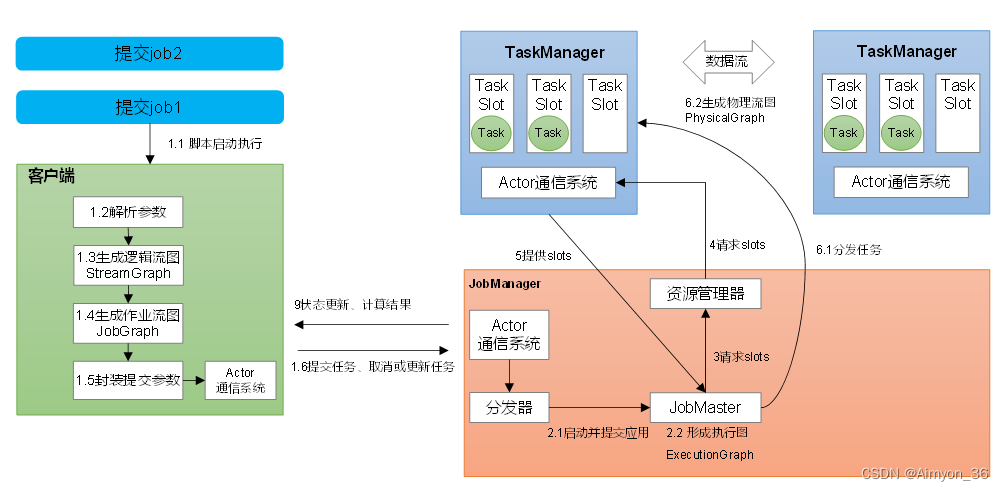
逻辑流图(StreamGraph)→ 作业图(JobGraph)→ 执行图(ExecutionGraph)→ 物理图(Physical Graph)。
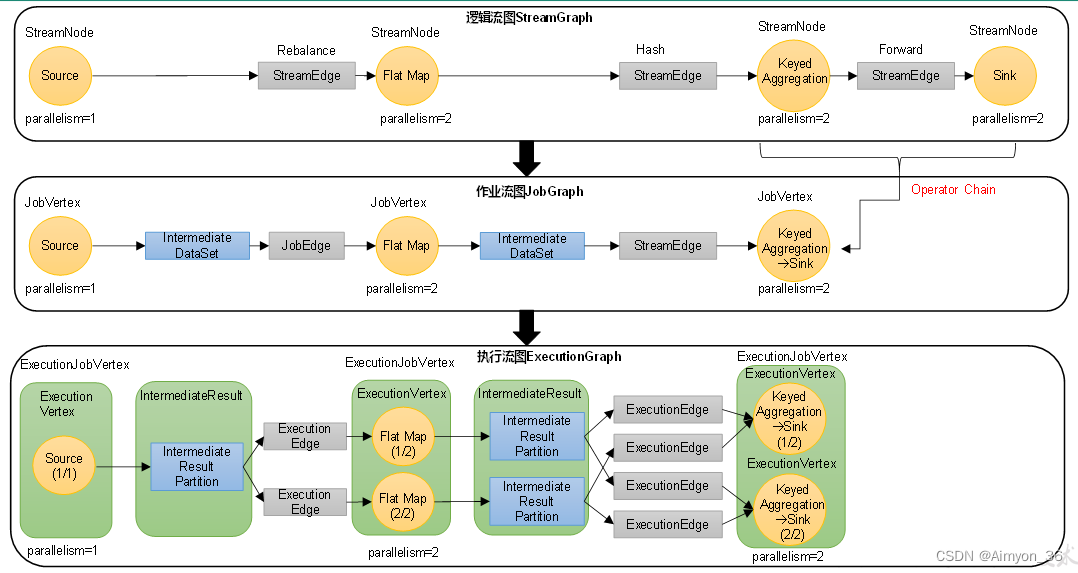
逻辑流图(StreamGraph):这是根据用户通过 DataStream API编写的代码生成的最初的DAG图,用来表示程序的拓扑结构。这一步一般在客户端完成。
作业图(JobGraph):StreamGraph经过优化后生成的就是作业图(JobGraph),这是提交给 JobManager 的数据结构,确定了当前作业中所有任务的划分。主要的优化为:将多个符合条件的节点链接在一起合并成一个任务节点,形成算子链,这样可以减少数据交换的消耗。JobGraph一般也是在客户端生成的,在作业提交时传递给JobMaster。
执行图(ExecutionGraph):JobMaster收到JobGraph后,会根据它来生成执行图(ExecutionGraph)。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。与JobGraph最大的区别就是按照并行度对并行子任务进行了拆分,并明确了任务间数据传输的方式。
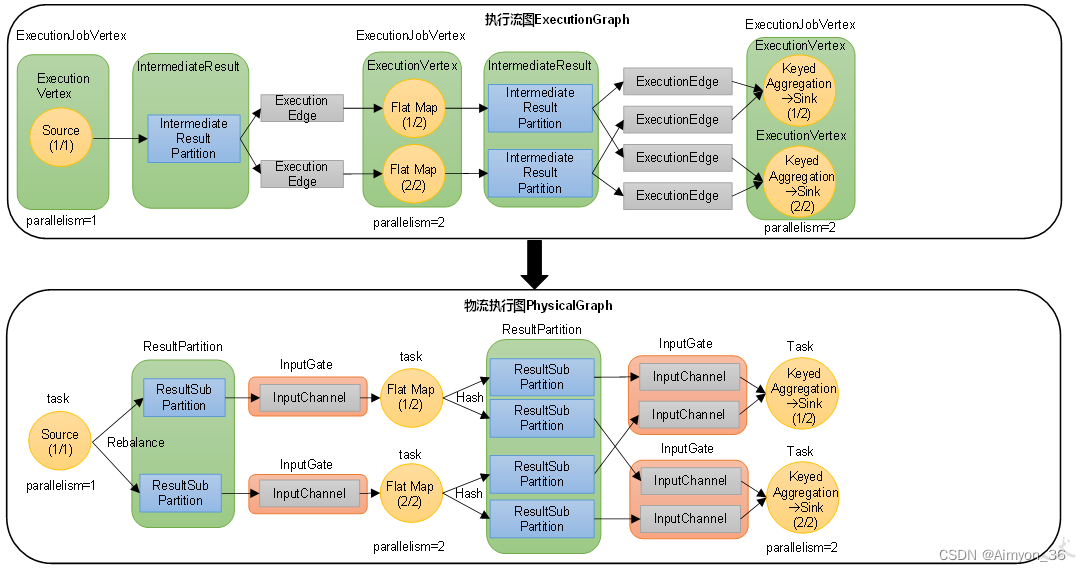
物理图(Physical Graph):JobMaster生成执行图后,会将它分发给TaskManager;各个TaskManager会根据执行图部署任务,最终的物理执行过程也会形成一张“图”,一般就叫作物理图(Physical Graph)。这只是具体执行层面的图,并不是一个具体的数据结构。
物理图主要就是在执行图的基础上,进一步确定数据存放的位置和收发的具体方式。有了物理图,TaskManager就可以对传递来的数据进行处理计算了。
(物理图部署Flink中真实定义的图,是实际执行时产生的图)
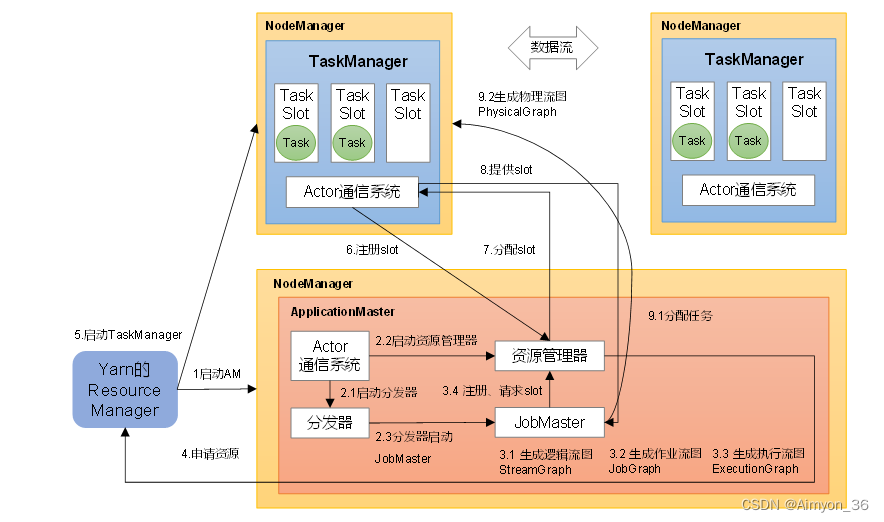
2.Yarn应用模式作业提交流程
四、DataStream API
DataStream API是Flink的核心层API。一个Flink程序,其实就是对DataStream的各种转换。
具体来说,代码基本上都由以下几部分构成: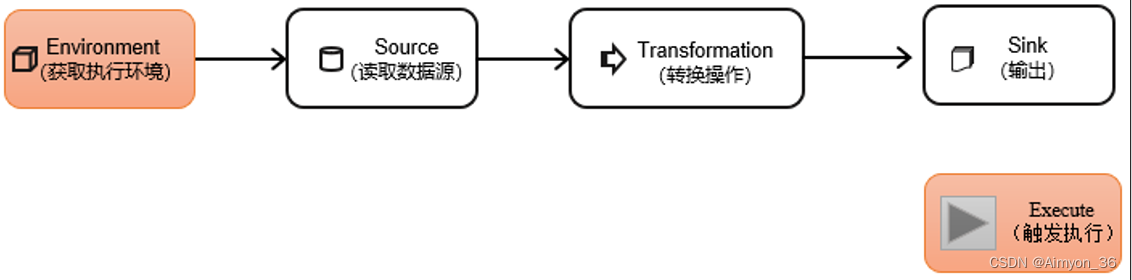
从Flink 1.12开始,官方推荐的做法是直接使用DataStream API,在提交任务时通过将执行模式设为BATCH来进行批处理。不建议使用DataSet API。
DataStream API执行模式包括:流执行模式、批执行模式和自动模式。
流执行模式(Streaming)
这是DataStream API最经典的模式,一般用于需要持续实时处理的无界数据流。默认情况下,程序使用的就是Streaming执行模式。
批执行模式(Batch)
专门用于批处理的执行模式。
自动模式(AutoMatic)
在这种模式下,将由程序根据输入数据源是否有界,来自动选择执行模式。
触发程序执行
需要注意的是,写完输出(sink)操作并不代表程序已经结束。因为当main()方法被调用时,其实只是定义了作业的每个执行操作,然后添加到数据流图中;这时并没有真正处理数据——因为数据可能还没来。Flink是由事件驱动的,只有等到数据到来,才会触发真正的计算,这也被称为“延迟执行”或“懒执行”。
所以我们需要显式地调用执行环境的execute()方法,来触发程序执行。execute()方法将一直等待作业完成,然后返回一个执行结果(JobExecutionResult)。
程序遇到env.execute()后程序才会真正执行,并且程序会等待处理结果。
flink引入了executeAsync()方法,在一个程序(类)中能够写多个executeAsync(),每当程序执行该方法就会产生一个新的job。
通常不会使用executeAsync,转而使用编写多个程序。
Flink支持的数据类型
Flink使用“类型信息”(TypeInformation)来统一表示数据类型。TypeInformation类是Flink中所有类型描述符的基类。它涵盖了类型的一些基本属性,并为每个数据类型生成特定的序列化器、反序列化器和比较器。
对于常见的Java和Scala数据类型,Flink都是支持的。Flink在内部,Flink对支持不同的类型进行了划分,这些类型可以在Types工具类中找到:
(1)基本类型
所有Java基本类型及其包装类,再加上Void、String、Date、BigDecimal和BigInteger。
(2)数组类型
包括基本类型数组(PRIMITIVE_ARRAY)和对象数组(OBJECT_ARRAY)。
(3)复合数据类型
Java元组类型(TUPLE):这是Flink内置的元组类型,是Java API的一部分。最多25个字段,也就是从Tuple0~Tuple25,不支持空字段。
Scala 样例类及Scala元组:不支持空字段。
行类型(ROW):可以认为是具有任意个字段的元组,并支持空字段。
POJO:Flink自定义的类似于Java bean模式的类。
(4)辅助类型
Option、Either、List、Map等。
(5)泛型类型(GENERIC)
Flink支持所有的Java类和Scala类。不过如果没有按照上面POJO类型的要求来定义,就会被Flink当作泛型类来处理。Flink会把泛型类型当作黑盒,无法获取它们内部的属性;它们也不是由Flink本身序列化的,而是由Kryo序列化的。
在这些类型中,元组类型和POJO类型最为灵活,因为它们支持创建复杂类型。而相比之下,POJO还支持在键(key)的定义中直接使用字段名,这会让我们的代码可读性大大增加。所以,在项目实践中,往往会将流处理程序中的元素类型定为Flink的POJO类型。
Flink对POJO类型的要求如下:
类是公有(public)的
有一个无参的构造方法
所有属性都是公有(public)的
所有属性的类型都是可以序列化的
Transform算子(转换算子)
DataStreamSource<WaterSensor> streamSource = env.fromElements(newWaterSensor("s1",1L,1),newWaterSensor("s2",2L,2),newWaterSensor("s3",3L,3),newWaterSensor("s4",4L,4));
自定义pojo数据集
1.map(映射)
map是大家非常熟悉的大数据操作算子,主要用于将数据流中的数据进行转换,形成新的数据流。简单来说,就是一个“一一映射”,消费一个元素就产出一个元素。(通常用来转换数据形式)
我们只需要基于DataStream调用map()方法就可以进行转换处理。方法需要传入的参数是接口MapFunction的实现;返回值类型还是DataStream,不过泛型(流中的元素类型)可能改变。
//todo 匿名实现类SingleOutputStreamOperator<String> mapSource =
streamSource.map(newMapFunction<WaterSensor,String>(){@OverridepublicStringmap(WaterSensor woaterSensor)throwsException{return woaterSensor.id;}});//todo lambda表达式SingleOutputStreamOperator<String> map =
streamSource.map(sensor -> sensor.id);//todo 定义实现类SingleOutputStreamOperator<String> diyMap =
streamSource.map(newMyMapFunction());
定义实现类方式:当一个map操作会被使用多次时,可以定义一个类实现MapFunciton接口,这样就能在开发中提升效率。
2.filter(过滤)
filter转换操作,顾名思义是对数据流执行一个过滤,通过一个布尔条件表达式设置过滤条件,对于每一个流内元素进行判断,若为true则元素正常输出,若为false则元素被过滤掉。
进行filter转换之后的新数据流的数据类型与原数据流是相同的。filter转换需要传入的参数需要实现FilterFunction接口,而FilterFunction内要实现filter()方法,就相当于一个返回布尔类型的条件表达式。
streamSource.filter(newFilterFunction<WaterSensor>(){@Overridepublicbooleanfilter(WaterSensor waterSensor)throwsException{return"s1".equals(waterSensor.getId());}}).print();//WoaterSensor{id='s1', ts=1, vc=1}
3.flatMap(扁平映射)
flatMap操作又称为扁平映射,主要是将数据流中的整体(一般是集合类型)拆分成一个一个的个体使用。消费一个元素,可以产生0到多个元素。flatMap可以认为是“扁平化”(flatten)和“映射”(map)两步操作的结合,也就是先按照某种规则对数据进行打散拆分,再对拆分后的元素做转换处理。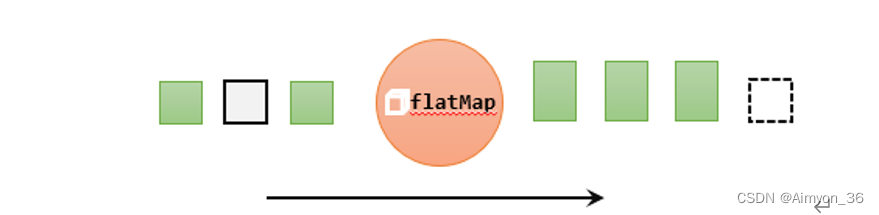
同map一样,flatMap也可以使用Lambda表达式或者FlatMapFunction接口实现类的方式来进行传参,返回值类型取决于所传参数的具体逻辑,可以与原数据流相同,也可以不同。
streamSource.flatMap(newFlatMapFunction<WaterSensor,String>(){@OverridepublicvoidflatMap(WaterSensor waterSensor,Collector<String> collector)throwsException{if("s1".equals(waterSensor.getId())){
collector.collect(waterSensor.getVc().toString());}elseif("s2".equals(waterSensor.getId())){
collector.collect(waterSensor.getTs().toString());
collector.collect(waterSensor.getVc().toString());}}}).print();// 1 2 2
聚合算子(Aggregation)
1.keyBy(分组)
keyBy是聚合前必须要用到的一个算子。keyBy通过指定键(key),可以将一条流从逻辑上划分成不同的分区(partitions)。这里所说的分区,其实就是并行处理的子任务。
基于不同的key,流中的数据将被分配到不同的分区中去;这样一来,所有具有相同的key的数据,都将被发往同一个分区。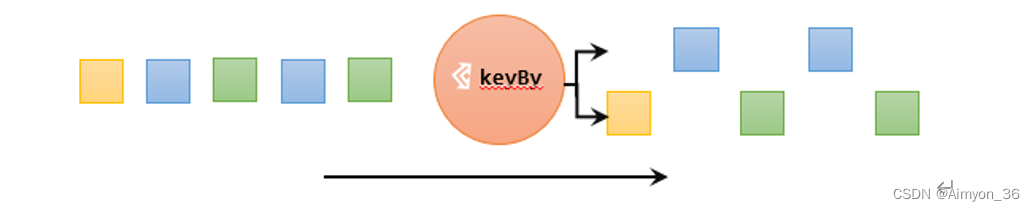
在内部,是通过计算key的哈希值(hash code),对分区数进行取模运算来实现的。所以这里key如果是POJO的话,必须要重写hashCode()方法。
keyBy()方法需要传入一个参数,这个参数指定了一个或一组key。有很多不同的方法来指定key:比如对于Tuple数据类型,可以指定字段的位置或者多个位置的组合;对于POJO类型,可以指定字段的名称(String);另外,还可以传入Lambda表达式或者实现一个键选择器(KeySelector),用于说明从数据中提取key的逻辑。
KeyedStream<WaterSensor,String> keyedStream =
streamSource.keyBy(newKeySelector<WaterSensor,String>(){@OverridepublicStringgetKey(WaterSensor waterSensor)throwsException{return waterSensor.id;}});
keyBy按照指定key的hashcode分组
keyedStream键控流,keyBy不是转换算子,只是对数据进行重分区(HashCode),不能设置并行度
keyBy对数据进行分组,保证相同key的数据在同一个分区,一个子任务可以理解为一个分区
相同Key的一组数据存在于一个分区中,但是一个分区中可能存在几组数据
2.简单聚合算子(sum/min/max/minBy/maxBy)
有了按键分区的数据流KeyedStream,我们就可以基于它进行聚合操作了。Flink为我们内置实现了一些最基本、最简单的聚合API,主要有以下几种:
sum():在输入流上,对指定的字段做叠加求和的操作。
min():在输入流上,对指定的字段求最小值。
max():在输入流上,对指定的字段求最大值。
minBy():与min()类似,在输入流上针对指定字段求最小值。不同的是,min()只计算指定字段的最小值,其他字段会保留最初第一个数据的值;而minBy()则会返回包含字段最小值的整条数据。
maxBy():与max()类似,在输入流上针对指定字段求最大值。两者区别与min()/minBy()完全一致。
max:只会取比较字段的最大值,非比较字段保留第一次 的值
maxby:取比较字段的最大值,同时非比较字段取最大值这条数据的值(取最大值的那条数据)
3. 归约聚合(reduce)
reduce可以对已有的数据进行归约处理,把每一个新输入的数据和当前已经归约出来的值,再做一个聚合计算。
reduce操作也会将KeyedStream转换为DataStream。它不会改变流的元素数据类型,所以输出类型和输入类型是一样的。
DataStreamSource<WaterSensor> streamSource = env.fromElements(newWaterSensor("s1",1L,1),newWaterSensor("s2",2L,2),newWaterSensor("s1",3L,3),newWaterSensor("s2",4L,4),newWaterSensor("s1",1L,3));KeyedStream<WaterSensor,String> keyedStream =
streamSource.keyBy(newKeySelector<WaterSensor,String>(){@OverridepublicStringgetKey(WaterSensor waterSensor)throwsException{return waterSensor.id;}});SingleOutputStreamOperator<WaterSensor> reduceDS =
keyedStream.reduce(newReduceFunction<WaterSensor>(){@OverridepublicWaterSensorreduce(WaterSensor waterSensor,WaterSensor t1)throwsException{returnnewWaterSensor("reduceId"+waterSensor.id, t1.ts, t1.vc + waterSensor.vc);}});
reduceDS.print();=============结果===================WoaterSensor{id='s1', ts=1, vc=1}WoaterSensor{id='s2', ts=2, vc=2}WoaterSensor{id='reduceIds1', ts=3, vc=4}WoaterSensor{id='reduceIds2', ts=4, vc=6}WoaterSensor{id='reduceIdreduceIds1', ts=1, vc=7}
按照分组进行聚合,每组的第一个元素不会执行reduce方法,而是将状态保存下来,等待下一条同组的数据到来后再进行计算。
4. 富函数类(Rich Function Classes)
“富函数类”也是DataStream API提供的一个函数类的接口,所有的Flink函数类都有其Rich版本。富函数类一般是以抽象类的形式出现的。例如:RichMapFunction、RichFilterFunction、RichReduceFunction等。
与常规函数类的不同主要在于,富函数类可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。
Rich Function有生命周期的概念。典型的生命周期方法有:
open()方法,是RichFunction的初始化方法,也就是会开启一个算子的生命周期。
当一个算子的实际工作方法例如map()或者filter()方法被调用之前,open()会首先被调用。
close()方法,是生命周期中的最后一个调用的方法,类似于结束方法。一般用来做一些清理工作。
需要注意的是,这里的生命周期方法,对于一个并行子任务来说只会调用一次;而对应的,实际工作方法,例如RichMapFunction中的map(),在每条数据到来后都会触发一次调用。
5.物理分区算子(Physical Partitioning)
常见的物理分区策略有:随机分配(Random)、轮询分配(Round-Robin)、重缩放(Rescale)和广播(Broadcast)。
随机分区(shuffle)
最简单的重分区方式就是直接“洗牌”。通过调用DataStream的.shuffle()方法,将数据随机地分配到下游算子的并行任务中去。
随机分区服从均匀分布(uniform distribution),所以可以把流中的数据随机打乱,均匀地传递到下游任务分区。因为是完全随机的,所以对于同样的输入数据, 每次执行得到的结果也不会相同。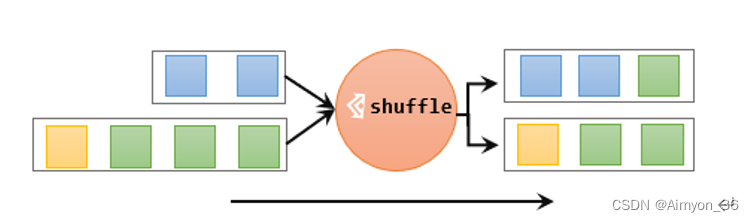
经过随机分区之后,得到的依然是一个DataStream。
stream.shuffle().print()
轮询分区(Round-Robin)
轮询,简单来说就是“发牌”,按照先后顺序将数据做依次分发。通过调用DataStream的.rebalance()方法,就可以实现轮询重分区。rebalance使用的是Round-Robin负载均衡算法,可以将输入流数据平均分配到下游的并行任务中去。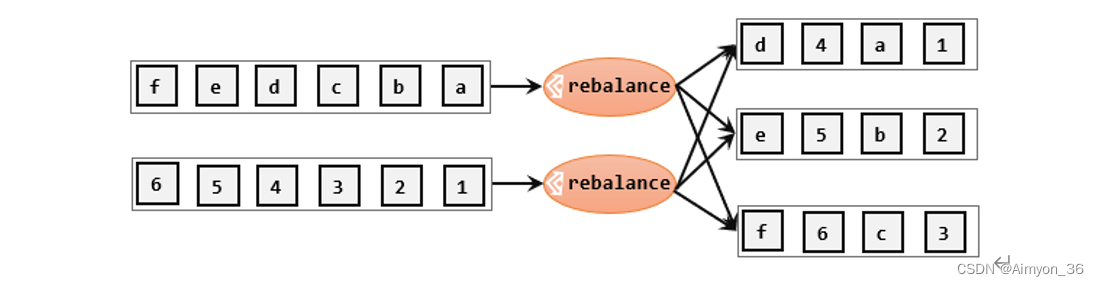
stream.rebalance().print()
重缩放分区(rescale)
重缩放分区和轮询分区非常相似。当调用rescale()方法时,其实底层也是使用Round-Robin算法进行轮询,但是只会将数据轮询发送到下游并行任务的一部分中。rescale的做法是分成小团体,发牌人只给自己团体内的所有人轮流发牌。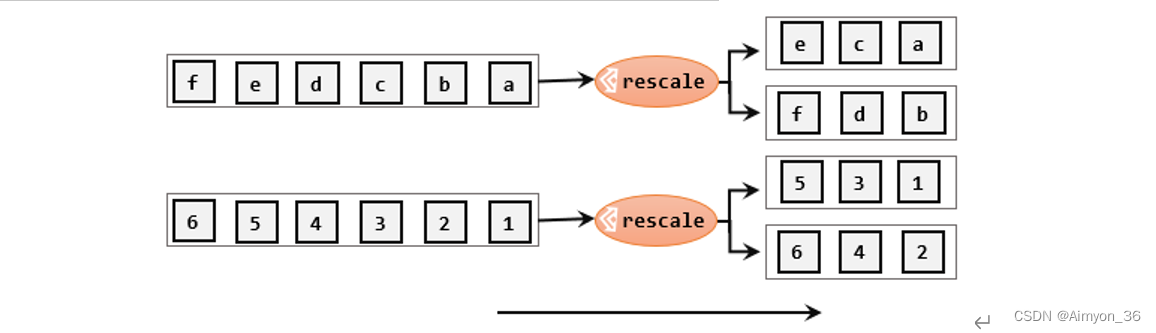
stream.rescale()
广播(broadcast)
这种方式其实不应该叫做“重分区”,因为经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理。可以通过调用DataStream的broadcast()方法,将输入数据复制并发送到下游算子的所有并行任务中去。
stream.broadcast()
将数据发送给下游的所有子任务
全局分区(global)
全局分区也是一种特殊的分区方式。这种做法非常极端,通过调用.global()方法,会将所有的输入流数据都发送到下游算子的第一个并行子任务中去。这就相当于强行让下游任务并行度变成了1,所以使用这个操作需要非常谨慎,可能对程序造成很大的压力。
stream.global()
该算子会将上游的数据发往下游算子的第一个并行子任务中,在下游的算子中,只有第一个子任务是拿到数据的。
自定义分区(Custom)
当Flink提供的所有分区策略都不能满足用户的需求时,我们可以通过使用partitionCustom()方法来自定义分区策略。
自定义分区器:
publicclassMyPartitionerimplementsPartitioner<String>{@Overridepublicintpartition(String key,int numPartitions){returnInteger.parseInt(key)% numPartitions;}}
使用自定义分区器:
DataStream<String> myDS = socketDS.partitionCustom(newMyPartitioner(),
value -> value);
6.分流
所谓“分流”,就是将一条数据流拆分成完全独立的两条、甚至多条流。也就是基于一个DataStream,定义一些筛选条件,将符合条件的数据拣选出来放到对应的流里。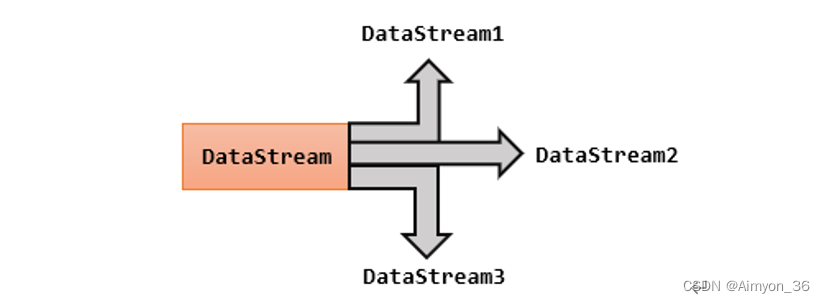
例子:读取一个整数数字流,将数据流划分为奇数流和偶数流。
StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> socketSource =
env.socketTextStream("hadoop102",7777);//读取socket数据
env.setParallelism(2);SingleOutputStreamOperator<String> filterSource_1 =
socketSource.filter(value ->Integer.parseInt(value)%2==0);SingleOutputStreamOperator<String> filterSource_2 =
socketSource.filter(value ->Integer.parseInt(value)%2==1);
filterSource_1.print("偶数流");
filterSource_2.print("奇数流");
env.execute();
这种方法虽然能够实现奇数偶数的分流,但是因为在分流过程中,每个数都需要被filter过滤一次,效率性能较低,不推荐使用。
侧输出流
SingleOutputStreamOperator<WaterSensor> sensorDS =
socketSource.map(newWaterSensorMapFunction());//将输入数据转换为WaterSensor类形OutputTag<WaterSensor> s1Tag =newOutputTag<>("s1支流",Types.POJO(WaterSensor.class));OutputTag<WaterSensor> s2Tag =newOutputTag<>("s2支流",Types.POJO(WaterSensor.class));SingleOutputStreamOperator<WaterSensor> process =
sensorDS.process(newProcessFunction<WaterSensor,WaterSensor>(){@OverridepublicvoidprocessElement(WaterSensor waterSensor,Context context,Collector<WaterSensor> collector)throwsException{String id = waterSensor.getId();if("s1".equals(id)){//如果id为 s1 放入侧输出流
context.output(s1Tag, waterSensor);}elseif("s2".equals(id)){
context.output(s2Tag, waterSensor);}else{//主流数据
collector.collect(waterSensor);}}});
process.print("主流");
process.getSideOutput(s1Tag).print("s1支流");
process.getSideOutput(s2Tag).print("s2支流");===结果===
s1支流:3>WoaterSensor{id='s1', ts=1, vc=1}
s2支流:4>WoaterSensor{id='s2', ts=1, vc=2}
基本合流操作
在实际应用中,我们经常会遇到来源不同的多条流,需要将它们的数据进行联合处理。所以Flink中合流的操作会更加普遍,对应的API也更加丰富。
1. 联合(Union)
最简单的合流操作,就是直接将多条流合在一起,叫作流的“联合”(union)。联合操作要求必须流中的数据类型必须相同,合并之后的新流会包括所有流中的元素,数据类型不变。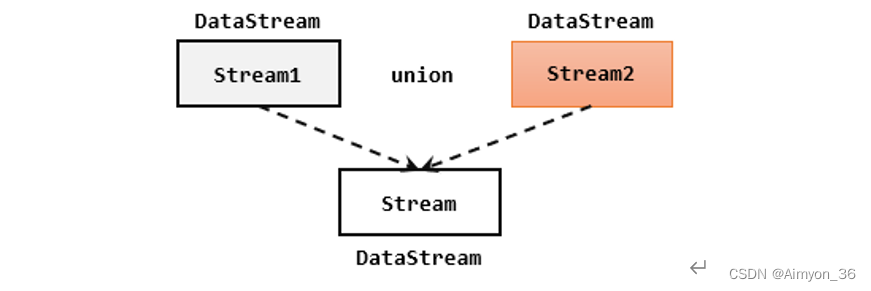
StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);DataStreamSource<Integer> source1 = env.fromElements(1,2,3,4,5);DataStreamSource<Integer> source2 = env.fromElements(11,22,33,44,55);DataStreamSource<String> source3 = env.fromElements("21","23","36");DataStream<Integer> unionSource1 = source1.union(source2,source3.map(value ->Integer.valueOf(value)));DataStream<Integer> unionSource2 = source1.union(source3.map(value ->Integer.valueOf(value)));
unionSource1.print("source1");
unionSource2.print("source2");
env.execute();
2.连接(Connect)
流的联合虽然简单,不过受限于数据类型不能改变,灵活性大打折扣,所以实际应用较少出现。除了联合(union),Flink还提供了另外一种方便的合流操作——连接(connect)。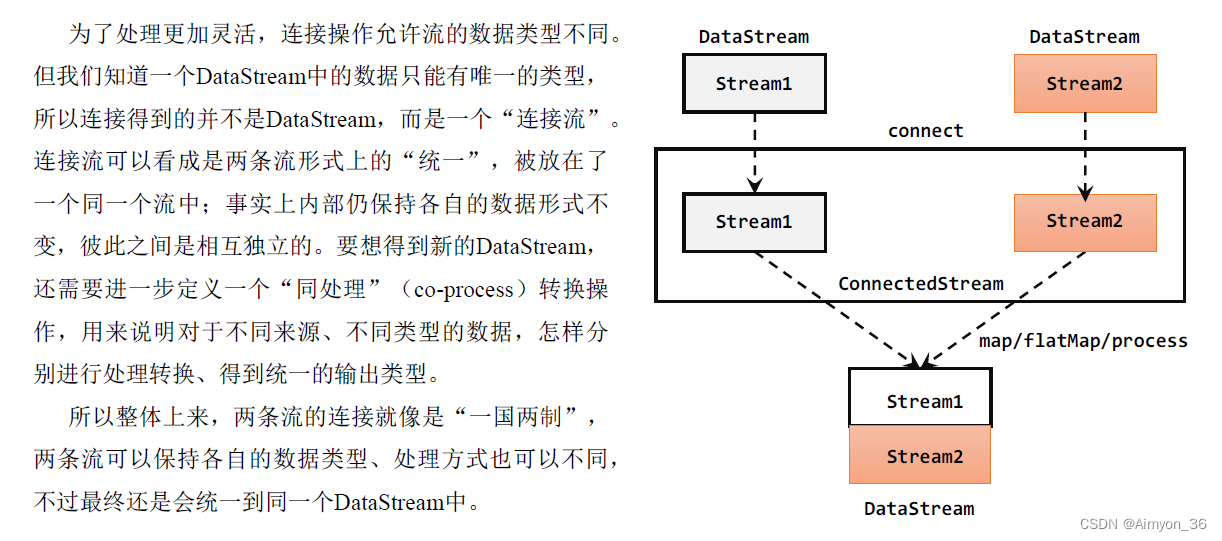
DataStreamSource<Integer> source1 = env.fromElements(1,2,3);DataStreamSource<String> source2 = env.fromElements("a","b","c");ConnectedStreams<Integer,String> connectSource
= source1.connect(source2);SingleOutputStreamOperator<String> coMapSource
= connectSource.map(newCoMapFunction<Integer,String,String>(){@OverridepublicStringmap1(Integer integer)throwsException{Integer value = integer *10;return value.toString();}@OverridepublicStringmap2(String s)throwsException{return s;}});
coMapSource.print();10 a 20 b 30 c
connect合流操作一次只能连接两条流,即使两条数据流进行了连接,其对外展示是一条流,但在进行算子操作时需要两条流分别执行操作
输出算子(Sink)
Flink作为数据处理框架,最终还是要把计算处理的结果写入外部存储,为外部应用提供支持。
1.KafkaSink
StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
env.enableCheckpointing(2000,CheckpointingMode.EXACTLY_ONCE);//todo 监控hadoop102:7777 将数据封装成WaterSensor Pojo对象SingleOutputStreamOperator<String> sensorDS = env
.socketTextStream("hadoop102",7777);//todo kafkaSinkKafkaSink<String> kafkaSink =KafkaSink.<String>builder()//todo 设置kafka地址和端口.setBootstrapServers("hadoop102:9092,hadoop103:9092,hadoop104:9092")
指定序列化器,Topic.setRecordSerializer(KafkaRecordSerializationSchema.<String>builder().setTopic("ws").setValueSerializationSchema(newSimpleStringSchema()).build())
自定义的序列化器(可选).setRecordSerializer(newKafkaRecordSerializationSchema<String>(){@Nullable@OverridepublicProducerRecord<byte[],byte[]>serialize(String s,KafkaSinkContext kafkaSinkContext,Long aLong){String[] datas = s.split(",");byte[] key = datas[0].getBytes(StandardCharsets.UTF_8);byte[] value = s.getBytes(StandardCharsets.UTF_8);returnnewProducerRecord<>("ws",key,value);}})//todo kafka生产者数据精准一次.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)//todo 精准一次需要设置事务id前缀和超时时间.setTransactionalIdPrefix("sinkkafka-").setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG,10*60*1000+"").build();
sensorDS.sinkTo(kafkaSink);
env.execute();
使用socket向flink写数据,flink读取数据后向kafka写数据
如果使用精确一次,需要设置事务前缀,事务超时时间以及开启checkpoint
kafka能根据key将数据发往对应分区
2.MysqlSink
StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);//todo Watersensor Pojo对象SingleOutputStreamOperator<WaterSensor> source = env.socketTextStream("localhost",7777).map(newWaterSensorMapFunction());//todo JDBCSinkSinkFunction<WaterSensor> jdbcSink =JdbcSink.sink("insert into ws(id,ts,vc) values(?,?,?)",//填充参数,lambda表达式(JdbcStatementBuilder<WaterSensor>)(preparedStatement, waterSensor)->{
preparedStatement.setString(1, waterSensor.getId());
preparedStatement.setLong(2, waterSensor.getTs());
preparedStatement.setInt(3, waterSensor.getVc());},//设置重试,批插入,插入时间JdbcExecutionOptions.builder().withMaxRetries(3).withBatchSize(100).withBatchIntervalMs(3000).build(),//设置连接参数newJdbcConnectionOptions.JdbcConnectionOptionsBuilder().withUrl("jdbc:mysql://localhost:3306/dbtest?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8").withUsername("root").withPassword("refrain").withConnectionCheckTimeoutSeconds(60)//连接超时.build());
source.addSink(jdbcSink);
env.execute();
3.自定义Sink
publicclassSinkCustom{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);//todo Watersensor Pojo对象SingleOutputStreamOperator<WaterSensor> source = env.socketTextStream("localhost",7777).map(newWaterSensorMapFunction());
source.addSink(newMySink());
env.execute();}publicstaticclassMySinkextendsRichSinkFunction<WaterSensor>{//todo 该处定义对象// Connection conn = null;@Overridepublicvoidopen(Configuration parameters)throwsException{super.open(parameters);//todo 该处创建连接对象}@Overridepublicvoidclose()throwsException{super.close();//todo 清理,销毁连接}//todo 该方法一条数据调用一次-不能创建对象,需要集成富函数//todo 核心处理逻辑@Overridepublicvoidinvoke(WaterSensor value,Context context)throwsException{//逻辑}}}
通常不建议使用自定义Sink
版权归原作者 Aimyon_36 所有, 如有侵权,请联系我们删除。