
文章目录
Spark
Spark是什么
- 定义:Apache Spark是用于大规模数据处理的统一分析引擎
- 简单来说,spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算PB、TB乃至EB级别的海量数据
PySpark
- Spark对Python语言的支持重点体现在Python第三方库:PySpark上
- PySpark是由Spark官方开发的Python语言第三方库
- Python开发者可以使用pip程序快速的安装PySpark库
基础准备
Spark库安装
- 使用pip命令直接安装
pip install pyspark
构建pyspark执行环境入口对象
- 想要使用pyspark库完成数据处理,首先需要构建一个执行环境入口对象
- pyspark的执行环境入口对象是:类
SparkContext的类对象 - 代码示例
# *_*coding:utf-8 *_*# 导包from pyspark import SparkConf, SparkContext
# 创建SparkConf对象# setMaster("local[*]")表明spark运行模式是单机,运行在本地# setAppName("test") 给当前spark程序起一个名字
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")# 基于sparkConf构建sparkContext类对象
sc = SparkContext(conf=conf)# 查看spark运行版本print(sc.version)# 停止pyspark程序
sc.stop()
PySpark的编程模型
- SparkContext类对象,是PySpark变成中一切功能的入口
- PySpark的编程,主要分为三大步骤 - 数据输入:通过SparkContext类对象的成员方法,完成数据的读取操作,读取后得到RDD类对象- 数据处理计算:通过RDD类对象的成员方法完成各种数据计算的需求- 数据输出:将处理完成后的RDD对象,调用各种成员方法完成,写出文件,转换为list等操作
数据输入
RDD对象
- PySpark支持多种数据的输入,在输入完成后,都会得到一个:RDD类的对象
- RDD全称是:弹性分布式数据集
- PySpark针对数据的处理都是以RDD对象作为载体 - 数据存储在RDD内- 各类数据的计算方法,也都是RDD的成员方法- RDD的数据计算方法,返回值依旧是RDD对象
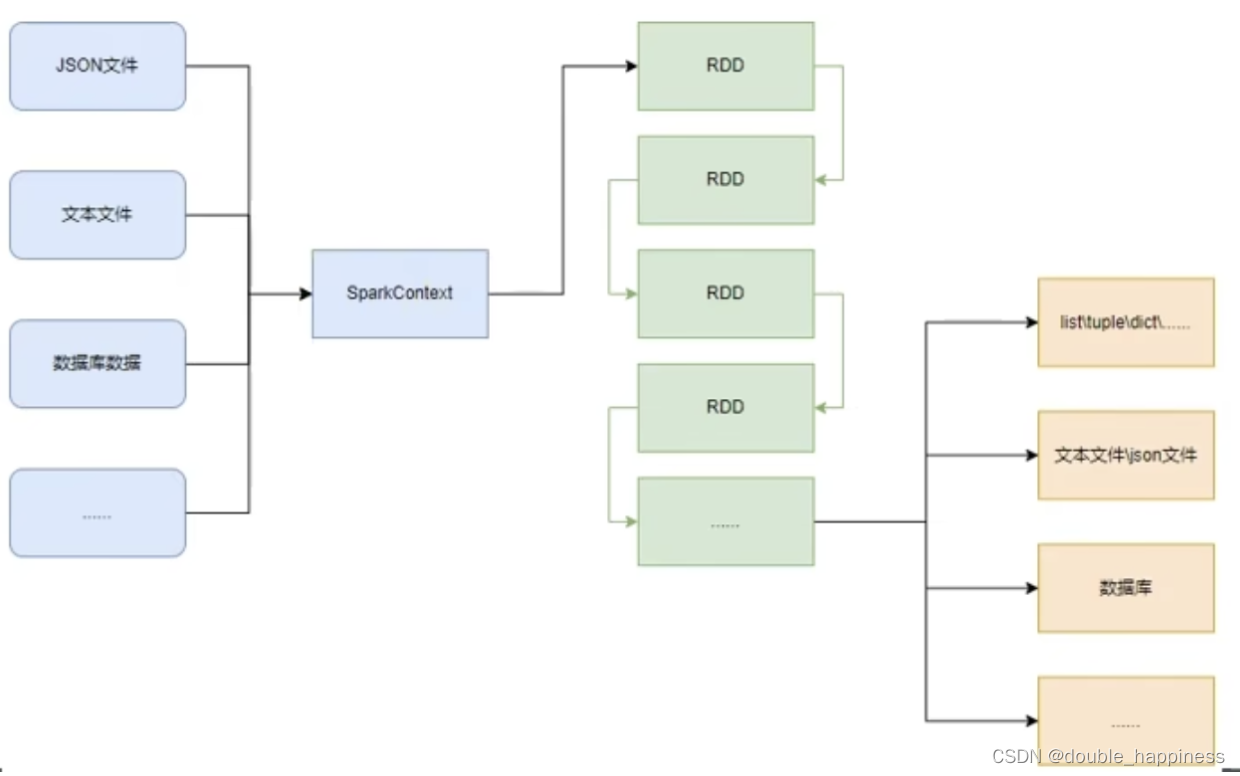
Python数据容器转RDD对象
- PySpark支持通过SparkContext对象的parallelize成员方法将
list/tuple/set/dict/str转换为PySpark的RDD对象 - 注意 - 字符串会被拆分成一个个的字符存入RDD对象- 字典仅有key会被存入RDD对象
- 代码示例
# *_*coding:utf-8 *_*from pyspark import SparkContext, SparkConf
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")# 基于sparkConf构建sparkContext类对象
sc = SparkContext(conf=conf)# rdd = sc.parallelize(数据容器对象)
rdd1 = sc.parallelize([1,2,3,4])
rdd2 = sc.parallelize((1,2,3,4))
rdd3 = sc.parallelize({1,2,3,4})
rdd4 = sc.parallelize({"a":1,"b":2})
rdd5 = sc.parallelize("erdtfhdsadg")print(rdd1.collect())print(rdd2.collect())print(rdd3.collect())print(rdd4.collect())print(rdd5.collect())
sc.stop()
- 运行结果
[1, 2, 3, 4][1, 2, 3, 4][1, 2, 3, 4]['a', 'b']['e', 'r', 'd', 't', 'f', 'h', 'd', 's', 'a', 'd', 'g']
读取文件转RDD对象
- 通过textFile()方法将文件转成RDD对象
- 代码示例
# *_*coding:utf-8 *_*from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster('local[*]').setAppName("test_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.textFile('./读取文件转RDD对象.py')print(rdd.collect())
sc.stop()
数据计算
map方法
- PySpark的数据计算,都是基于RDD对象来进行的,RDD对象内置丰富的:成员方法(算子)
- 功能:map算子是将RDD的数据一条条处理(处理的逻辑基于map算子中接收的处理函数),返回新的RDD
- 语法:
rdd.map(func)# func: f:(T)->U# (T)->U 表示的是方法的定义# ()表示传入参数,(T)表示传入一个参数,()表示没有传入参数# T是泛型的代称,在这里表示任意类型# U也是泛型的代称,在这里表示任意类型# ->U 表示返回值# (T)->U 总结起来的意思是:这是一个方法,接收一个参数传入,传入参数类型不限,返回一个返回值,返回值类型不限# (A)->A 总结起来的意思是:这是一个方法,接收一个参数传入,传入参数类型不限,返回一个返回值,返回值和传入参数类型一致
- 代码示例
# *_*coding:utf-8 *_*from pyspark import SparkContext, SparkConf
# map方法
sc = SparkContext(conf=SparkConf().setAppName("test_spark_app").setMaster("local[*]"))# 准备一个rdd
rdd = sc.parallelize([1,2,3,4,5])# 调用map方法进行计算# 对传入的值先进行*10在进行+5
rdd1 = rdd.map(lambda x: x *10).map(lambda x: x +5)# 查看计算完毕后rdd中的内容print(rdd1.collect())
flatMap方法
- 功能:对rdd执行map操作,然后进行解除嵌套操作
- 解除嵌套
# 嵌套的list
lst =[[1,2,3],[4,5,6],[7,8,9]]# 解除嵌套后的list
lst =[1,2,3,4,5,6,7,8,9]
- 代码示例
# *_*coding:utf-8 *_*from pyspark import SparkContext, SparkConf
# flatmap方法
sc = SparkContext(conf=SparkConf().setAppName("test_spark_app").setMaster("local[*]"))# 准备一个rdd
rdd = sc.parallelize(["fdsf fsf eerer","fdtfydus adas ouore","ier wir hdgi ldre"])# 需求:将RDD数据里面的一个个单词提取出来
rdd1 = rdd.map(lambda x: x.split(" "))
rdd2 = rdd.flatMap(lambda x: x.split(" "))print(f'map方法转化完内容:{rdd1.collect()}')print(f'flatmap方法转化完内容:{rdd2.collect()}')
sc.stop()
reduceByKey方法
- 功能:针对KV型RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成数据的聚合操作
- 用法
rdd.reduceByKey(func)# func:(V,V)->V# 接收两个传入参数(类型要一致),返回一个返回值,类型和传入要求一致
- 代码示例
# *_*coding:utf-8 *_*from pyspark import SparkContext, SparkConf
# flatmap方法
sc = SparkContext(conf=SparkConf().setAppName("test_spark_app").setMaster("local[*]"))# 准备一个rdd
rdd = sc.parallelize([('a',1),('a',1),('b',1),('b',1),('b',1)])# reduceByKey 自动按照key分组,然后根据聚合逻辑完成value聚合操作# rdd中数据有两个key:'a'和'b'# 聚合逻辑为:不断的将value值相加
rdd1 = rdd.reduceByKey(lambda a, b: a + b)print(f'map方法转化完内容:{rdd1.collect()}')
sc.stop()
Filter方法
- 功能:过滤想要的数据进行保留
- 语法
rdd.filter(func)# func: (T)->bool 传入一个随机类型参数,返回值必须是bool类型,返回为True的数据被保留,返回为False的被丢弃
- 代码示例
# *_*coding:utf-8 *_*from pyspark import SparkContext, SparkConf
sc = SparkContext(conf=SparkConf().setMaster("local[*]").setAppName("test_spark_app"))
rdd = sc.parallelize([1,2,3,4,5])# 需求:保留奇数# rdd1 = rdd.filter(lambda x: x % 2 == 1)# print(rdd1.collect())print(rdd.filter(lambda x: x %2==1).collect())
distinct方法
- 功能:对rdd数据进行去重返回新的rdd
- 语法:
rdd.distinct() - 代码示例:
# *_*coding:utf-8 *_*from pyspark import SparkContext, SparkConf
sc = SparkContext(conf=SparkConf().setMaster("local[*]").setAppName("test_spark_app"))
rdd = sc.parallelize([1,1,2,4,2,1])print(rdd.distinct().collect())
sortby方法
- 功能:基于指定的排序规则对RDD数据进行排序
- 语法:
rdd.sortBy(func, ascending=False, numPartitions=1)# func: (T)-> U:告知RDD中的那个数据进行排序,比如lambda x: x[1]表示按照RDD中的第二列元素进行排序# ascending True升序,False降序# numPartitions:用多少分区排序
- 代码示例
# *_*coding:utf-8 *_*from pyspark import SparkContext, SparkConf
sc = SparkContext(conf=SparkConf().setMaster("local[*]").setAppName("test_spark_app"))
rdd = sc.parallelize([("dasds",5),("ferew",2),("dsgyds",7),("dsdsfds",4),("dsfsfs",2)])print(rdd.sortBy(lambda x: x[1], ascending=False, numPartitions=1).collect())
数据输出
collect方法
- 功能:将RDD各个分区的数据,统一收集到Driver中,形成一个list对象
- 用法:
rdd.collect(),返回值是一个list
reduce方法
- 功能:对RDD数据按照传入的逻辑进行聚合
- 语法:
rdd.reduce(func)# func: (T,T) ->T# 2个参数 1个返回值,返回值和传入参数要求类型一致
- 代码示例
# *_*coding:utf-8 *_*from pyspark import SparkContext, SparkConf
sc = SparkContext(conf=SparkConf().setMaster("local[*]").setAppName("test_spark_app"))
rdd = sc.parallelize([1,2,3,4,5])print(rdd.reduce(lambda a, b: a + b))
take方法
- 功能:取RDD的前N个元素,组成list后返回
- 用法:
rdd.take(N)
count方法
- 功能:计算RDD有多少条数据,返回一个数字
- 用法:
rdd.count()
输出到文件
- saveAsTextFile方法
- 功能:将RDD的数据写入到文本文件中
- 支持 本地写出,hdfs等文件系统
- 代码示例
sc.parallelize([1,2,3,4,5]).saveAsTextFile("输出文件路径")
本文转载自: https://blog.csdn.net/double_happiness/article/details/136810980
版权归原作者 double_happiness 所有, 如有侵权,请联系我们删除。
版权归原作者 double_happiness 所有, 如有侵权,请联系我们删除。