
前言:
前面我们通过oracle的索引来处理单表超1亿的数据量表的查询问题,通过针对主键,展示的维度做多套索引,来提高查询和展现速度。通过在数据源增加索引来提高数据处理时,查询数据源的时间,如增加主键id的索引,通过判断上次插入更新的主键的节点,本次数据处理,只需要处理上次主键之后的数据了。大大提高数据处理效率,而不影响前端展现。对应通过对展示表**增加多套索引来处理常用查询条件查询数据所需的时间加快展现效率**。个人认为针对数据分析需求时,是有必要进行多套索引的建立,但实际生产库就需要根据具体条件来看了。因为在**删除数据的时候也需要删除索引会拖慢删除的进程**。因此需要理性选择。今天我们来看一个看似简单的**跨库数据更新**组件。
一、更新组件介绍
1.1界面

整个组件,包括两大部分,一个是更新的关键字,一般是主键和联合主键。只要我们通过它能找到一个唯一值即可。下面是需要更新的字段,建议只需要需要更新的字段,防止有数据的字段被更新擦除。
1.2废话介绍
Kettle 更新组件是 Kettle 的一个重要功能,它可以帮助用户在数据仓库或数据集中更新已有的数据。
Kettle 更新组件可以执行以下操作:
- 更新操作:将数据仓库或数据集中已有的数据进行更新。这种操作通常是基于某个唯一标识符来实现的,例如更新一个客户的地址信息。
Kettle 更新组件还具有以下特点:
- 灵活性:可以根据用户的需求定制更新组件的行为,例如可以选择在更新失败时是否回滚事务,是否进行批量更新等。
- 安全性:Kettle 更新组件支持使用事务来保证数据的一致性,可以在更新失败时回滚事务,保证数据的完整性。
- 易用性:Kettle 更新组件提供了一个简单易用的界面,用户可以通过拖拽操作来设置更新规则,无需编写复杂的代码。
1.3重点解释
我们在应用更新组件时,重点需要关注三个功能,跳过查询、批量更新和忽略查询失败?
跳过查询:在更新组件中,有时候我们只需要更新数据而不需要查询数据,这时可以使用跳过查询的方式来提高更新效率。
批量更新:在更新组件中,我们有时候需要更新多条数据,这时可以使用批量更新的方式来提高更新效率。
忽略查询失败:在更新组件中,有时候我们的查询条件可能无法匹配到任何数据,这时如果不忽略查询失败,程序会抛出异常,影响程序的正常运行。因此,我们可以选择忽略查询失败,避免程序异常。
因此我们在做跨库更新时,如不能保证更新数据源的主键与目标库中主键是一一对应的,建议勾选“跳过查询”来大大提高更新效率和避免目标库主键不存在时更新失败。
二、应用案例
2.1转换效果
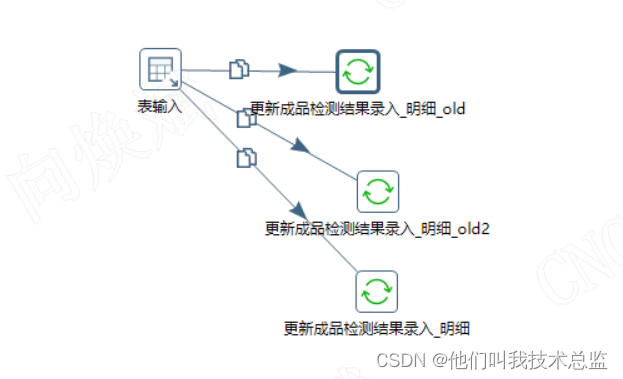
如图所示我们通过更新组件同时更新目标库中三张表的数据,来保持目标库中数据的一致性。
2.2转换简介
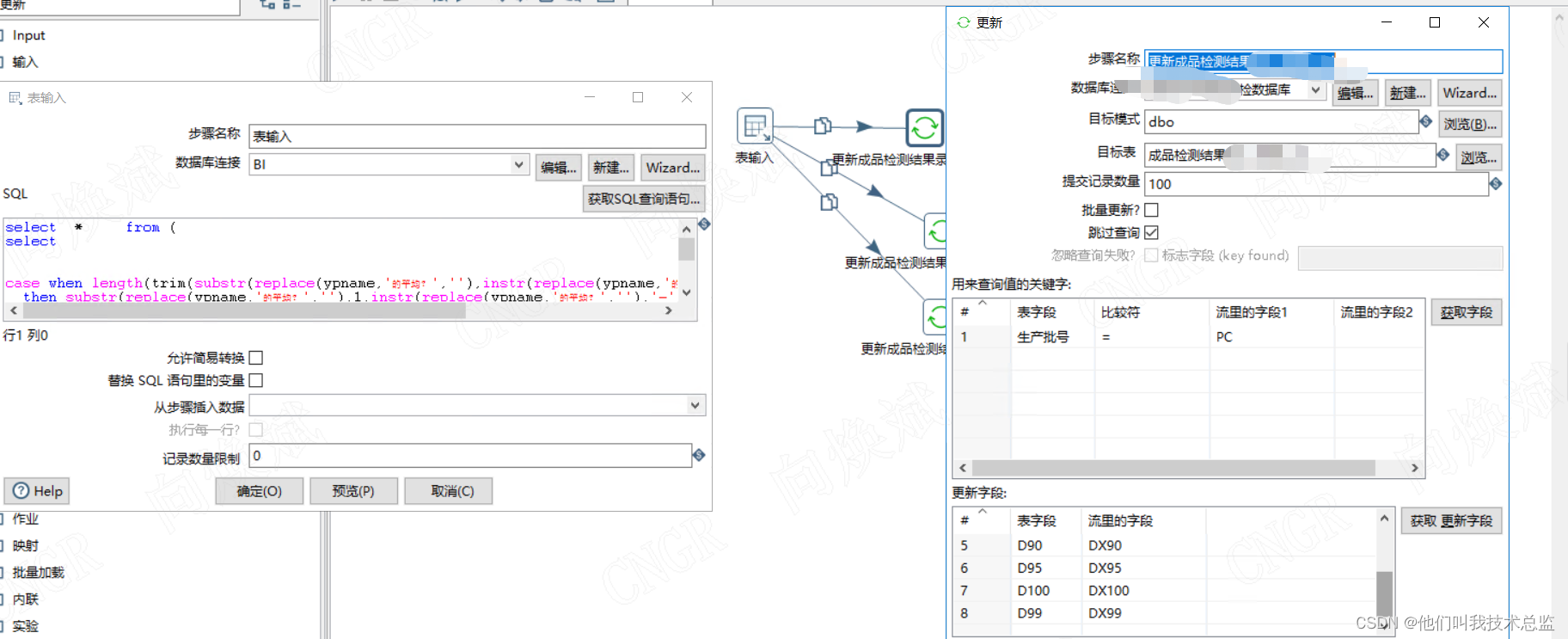
如图所示通过表输入来清洗查询需要的数据,然后按对应批次匹配更新即可。
三、总结
我们在应用这个组件的时候,注意关键字的唯一性和考虑是否需要跳过主键去校验,如不需校验,建议勾选“跳过查询”来提高更新效率。(o゜▽゜)o☆[BINGO!],欢迎点赞、收藏。我们下节课再见。
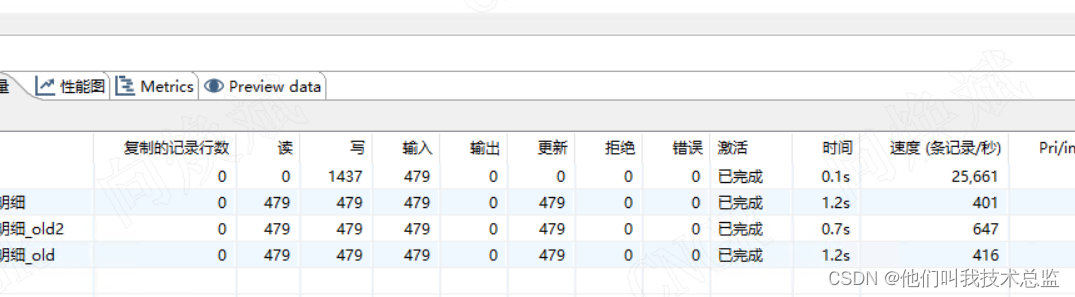 跨库多表更新运行效果图
跨库多表更新运行效果图
本文转载自: https://blog.csdn.net/qq_29061315/article/details/129880527
版权归原作者 他们叫我技术总监 所有, 如有侵权,请联系我们删除。
版权归原作者 他们叫我技术总监 所有, 如有侵权,请联系我们删除。