
目录
0.预备知识
1.理解源IP地址和目的IP地址
- 每台计算机都有一个唯一的IP地址,如果一台主机上的数据要传输到另一台主机,那么对端主机的IP地址就应该作为该数据传输时的目的IP地址。但仅仅知道目的IP地址是不够的,当对端主机收到该数据后,对端主机还需要对该主机做出响应,因此对端主机也需要发送数据给该主机,此时对端主机就必须知道该主机的IP地址 - 因此一个传输的数据当中应该涵盖其源IP地址和目的IP地址 - 目的IP地址表明该数据传输的目的地- 源IP地址作为对端主机响应时的目的IP地址
- 在数据进行传输之前,会先自顶向下贯穿网络协议栈完成数据的封装,其中在网络层封装的IP报头当中就涵盖了源IP地址和目的IP地址
2.理解源MAC地址和目的MAC地址
大部分数据的传输都是跨局域网的,数据在传输过程中会经过若干个路由器,最终才能到达对端主机
源MAC地址和目的MAC地址是包含在链路层的报头当中的,而MAC地址实际只在当前局域网内有效,因此当数据跨网络到达另一个局域网时,其源MAC地址和目的MAC地址就需要发生变化,因此当数据达到路由器时,路由器会将该数据当中链路层的报头去掉,然后再重新封装一个报头,此时该数据的源MAC地址和目的MAC地址就发生了变化

如上主机1向主机2发送数据的过程中,数据的源MAC地址和目的MAC地址的变化过程如下:
时间轴源MAC地址目的MAC地址刚开始主机1的MAC地址路由器A的MAC地址经过路由器A之后路由器A的MAC地址路由器B的MAC地址因此数据在传输的过程中是有两套地址: - 一套是源IP地址和目的IP地址,这两个地址在数据传输过程中基本是不会发生变化的 - 存在一些特殊情况,比如在数据传输过程中使用NET技术,其源IP地址会发生变化,但至少目的IP地址是不会变化的- 另一套就是源MAC地址和目的MAC地址,这两个地址是一直在发生变化的,因为在数据传输的过程中路由器不断在进行解包和重新封装
3.端口号
- 端口号(port)是传输层协议的内容 - 端口号是一个2字节16位的整数- 端口号用来标识一个进程,告诉操作系统,当前的这个数据要交给哪一个进程来处理- IP****地址 + 端口号能够标识网络上的某一台主机的某一个进程- 一个端口号只能被一个进程占用
4.理解端口号和进程ID
- PID表示唯一一个进程,此处端口号也是唯一表示一个进程。那么这两者之间是怎样的关系?- 网络模块和进程管理模块进行解耦合。进程pid在技术上是可以标定当前主机上某一个唯一的进程,但是实际上不会用进程PID做,进程PID属于进程管理范畴,而端口号属于网络范畴。如果非要用进程pid做两用(既做调度进程管理,又在网络上标定主机的一个唯一进程),无疑是将进程管理和网络强耦合起来了。它可以但不合理
- 底层如何通过port找到对应进程的?- 实际底层采用哈希的方式建立了端口号和进程PID或PCB之间的映射关系,当底层拿到端口号时就可以直接执行对应的哈希算法,然后就能够找到该端口号对应的进程
- 一个进程可以绑定多个端口号吗?- 可以的。未来一个进程在进行网络通信的时候,它可能既和客户端A通信,也和客户端A的子模块通信,所以此进程就会绑定两个端口号。只要能够通过端口号找到同一个进程即可- 但是一个端口号不能被多个进程绑定。因为端口号到进程具有唯一性
5.理解源端口号和目的端口号
- 传输层协议(TCP和UDP)的数据段中有两个端口号,分别叫做源端口号和目的端口号。就是在描述"数据是谁发的,要发给谁"
- 对于源IP地址和目的IP地址,就是确定了哪两台主机要通信
- 对于源端口号和目的端口号,就是确定了两台主机上的哪两个进程要进行通信
6.通过IP地址、端口号、协议号进行通信识别
- 本质上两台主机进行通信是需要IP地址、端口号和协议号的
- 如下图所示:①和②的通信是在两台计算机上进行的。它们的目标端口号相同,都是80- 例如打开两个Web浏览器,同时访问服务器上的两个页面,就会在这个浏览器跟服务器之间产生类似前面的两个通信- 在这种情况下必须严格区分这两个通信 - 因此可以源端口号加以区分
- 下图中③和①的目标端口号和源端口号完全相同,但是它们各自的源IP地址不同
- 此外,还有一种情况下图中并未列出,那就是IP地址和端口完全都一样,只是协议号(表示上层是TCP或UDP的一种编号)- 这种情况下,也会认为是两个不同的通信。
- 因此,TCP/IP或UDP/IP通信中通常采用5个信息来识别一个通信- 源IP地址、目标IP地址、协议号、源端口号、目标端口号- 只要有一项不同就被认为是其他通信
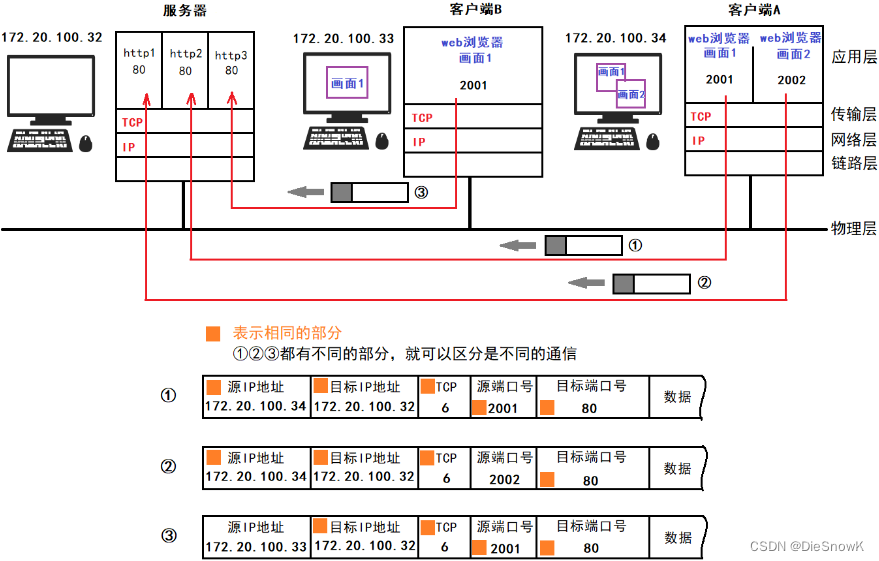
- 总结:- IP****地址最大的意义在于指导一个报文该如何进行路径选择,到哪里去就是去找目标IP地址- 端口号的意义在于唯一的标识一台机器上的唯一一个进程- IP****地址 + 端口号 = 能够标识互联网中的唯一一个进程- IP****地址 + port(端口号) = socket(套接字)
7.认识TCP协议和UDP协议
- TCP协议:- TCP协议叫做传输控制协议(Transmission Control Protocol),TCP协议是一种面向连接的、可靠的、基于字节流的传输层通信协议- TCP协议是面向连接的,如果两台主机之间想要进行数据传输,那么必须要先建立连接,当连接建立成功后才能进行数据传输。其次,TCP协议是保证可靠的协议(也意味着要做更多的事情),数据在传输过程中如果出现了丢包、乱序等情况,TCP协议都有对应的解决方法
- UDP协议:- UDP协议叫做用户数据报协议(User Datagram Protocol),UDP协议是一种无需建立连接的、不可靠的、面向数据报的传输层通信协议- 使用UDP协议进行通信时无需建立连接,如果两台主机之间想要进行数据传输,那么直接将数据发送给对端主机就行了,但这也就意味着UDP协议是不可靠的,数据在传输过程中如果出现了丢包、乱序等情况,UDP协议本身是不知道的
- TCP协议和UDP协议不存在哪个更好的说法- 虽然TCP协议是可靠的,不过这也意味着它为了维持自己的可靠性,一定要做更多的工作,一定会比较复杂- 而UDP虽然是不可靠的,不需要做过多的工作,不过这也意味着UDP是足够简单的
8.网络字节序
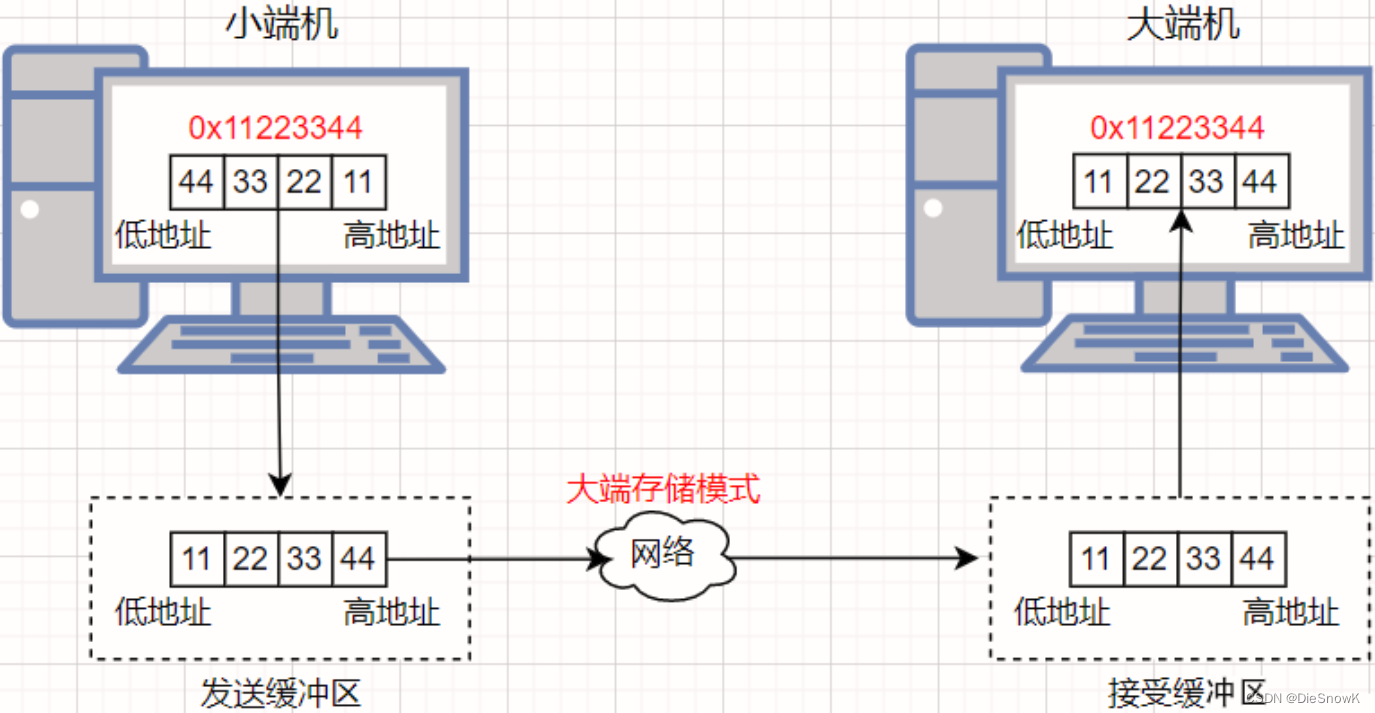
- 网络中的大小端问题:- 计算机在存储数据时是有大小端的概念的:- 大端模式: 数据的高字节内容保存在内存的低地址处,数据的低字节内容保存在内存的高地址处- 小端模式: 数据的高字节内容保存在内存的高地址处,数据的低字节内容保存在内存的低地址处
- 由于我们不能保证通信双方存储数据的方式是一样的,因此网络当中传输的数据必须考虑大小端问题
- 因此TCP/IP协议规定如下:网络数据流采用大端字节序,即低地址高字节- 无论是大端机还是小端机,都必须按照TCP/IP协议规定的网络字节序来发送和接收数据- 如果发送端是小端,需要先将数据转成大端,然后再发送到网络当中- 如果发送端是大端,则可以直接进行发送- 如果接收端是小端,需要先将接收到数据转成小端后再进行数据识别- 如果接收端是大端,则可以直接进行数据识别
- 注意:- 发送主机通常将发送缓冲区中的数据按内存地址从低到高的顺序发出- 接收主机把从网络上接到的字节依次保存在接收缓冲区中,也是按内存地址从低到高的顺序保存- 因此,网络数据流的地址应这样规定:先发出的数据是低地址,后发出的数据是高地址
- 如下:由于发送端是小端机,因此在发送数据前需要先将数据转成大端,然后再发送到网络当中,而由于接收端是大端机,因此接收端接收到数据后可以直接进行数据识别,此时接收端识别出来的数据就与发送端原本想要发送的数据相同了
- 为使网络程序具有可移植性,使同样的C代码在大端和小端计算机上编译后都能正常运行,系统提供了四个函数,可以通过调用以下库函数实现网络字节序和主机字节序之间的转换- 这些函数名很好记,h表示host,n表示network,l表示32位长整数,s表示16位短整数。 - 例如htonl表示将32位的长整数从主机字节序转换为网络字节序,例如将IP地址转换后准备发送- 如果主机是小端字节序,这些函数将参数做相应的大小端转换然后返回- 如果主机是大端字节序,这些函数不做转换,将参数原封不动地返回
#include<arpa/inet.h>uint32_thtonl(uint32_t hostlong);// 主机转网络uint16_thtons(uint16_t hostshort);// 网络转主机uint32_tntohl(uint32_t netlong);// 按4字节为单位主机转网络uint16_tntohs(uint16_t netshort);// 按2字节网络转主机
1.套接字地址结构(sockaddr)
- socket API是一层抽象的网络编程接口,适用于各种底层网络协议**(定义在netinet/in.h)**- 如IPv4、IPv6,以及后面要讲的UNIX Domain Socket- 然而,各种网络协议的地址格式并不相同
- 套接字不仅支持跨网络的进程间通信(网络套接字),还支持本地的进程间通信(域间套接字)- 在进行跨网络通信时我们需要传递的端口号和IP地址,而本地通信则不需要
- 网络的设计者想要把跨网络通信和本地通信进行大一统,因此套接字提供了sockaddr_in结构体和sockaddr_un结构体- 其中sockaddr_in结构体是用于跨网络通信的(网络套接字)- 而sockaddr_un结构体是用于本地通信的(域间套接字)
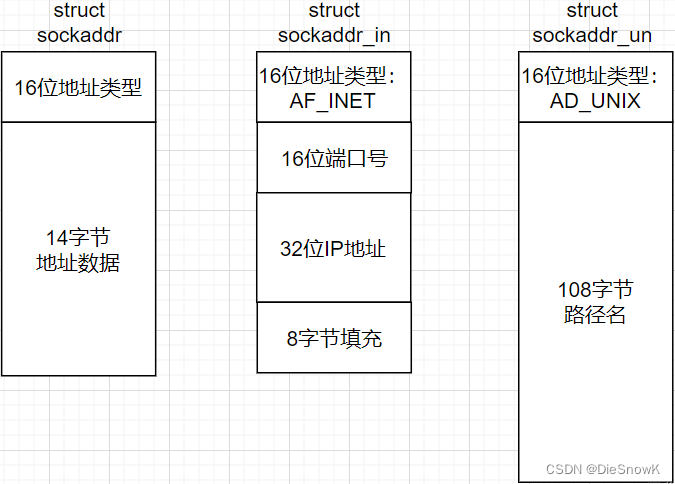
- 为了让套接字的网络通信和本地通信能够使用同一套函数接口,于是就出现了sockaddr结构体- 该结构体与sockaddr_in和sockaddr_un的结构都不相同,但这三个结构体头部的16个比特位都是一样的,这个字段叫做协议家族
- 也就是说我们的套接字接口就这么一套,但是通信方式确有多种,你只需要给这个结构体(struct sockaddr)传输你想要的通信方式即可- 其实也不难看出,这种就类似于多态,所有的通信方式都是子类,struct sockaddr就是父类,父类指向不同的子类,就使用不同的方法
- 我们要做的就是在使用的时进行强制类型转换即可- 类似C语言中指针void,它的功能就是可以接受任意类型的指针,再进行强转也可以- 但是,早期在设计的时候还没有void这种指针,所以这种用法一直延续至今
- 此时当我们在传参时,就不用传入sockeaddr_in或sockeaddr_un这样的结构体,而统一传入sockaddr这样的结构体- 在设置参数时就可以通过设置协议家族这个字段,来表明是要进行网络通信还是本地通信 - 在这些API内部就可以提取sockeaddr结构头部的16位进行识别- 如果前16为地址类型是AF_INET,就是网络间通信- 如果地址类型是AF_UNIX,就是本地间通信
- 如上就通过通用sockaddr结构,将套接字网络通信和本地通信的参数类型进行了统一
- 注意:- IPv4和IPv6的地址格式定义在netinet/in.h中,IPv4地址用sockaddr_in结构体表示,包括16位地址类型,16位端口号和32位IP地址- IPv4、IPv6地址类型分别定义为常数AF_INET、AF_INET6- socket API可以都用struct sockaddr* 类型表示,在使用的时候需要强制转化成sockaddr_in - 这样的好处是程序的通用性,可以接收IPv4、IPv6,以及UNIX Domain Socket各种类型的sockaddr结构体指针做为参数
// 通用套接字地址结构/* Structure describing a generic socket address. */structsockaddr{__SOCKADDR_COMMON(sa_);/* Common data: address family and length */char sa_data[14];/* Address data. */};// IPV4套接字地址结构/* Structure describing an Internet socket address. */structsockaddr_in{__SOCKADDR_COMMON(sin_);
in_port_t sin_port;/* Port number. */structin_addr sin_addr;/* Internet address. *//* Pad to size of `struct sockaddr'. */unsignedchar sin_zero[sizeof(structsockaddr)-
__SOCKADDR_COMMON_SIZE -sizeof(in_port_t)-sizeof(structin_addr)];};// Unix域套接字地址结构/* Structure describing the address of an AF_LOCAL (aka AF_UNIX) socket */structsockaddr_un{__SOCKADDR_COMMON(sun_);char sun_path[108];/* Path name. */};/* Internet address. */typedefuint32_t in_addr_t;structin_addr{
in_addr_t s_addr;};
- in_addr用来表示一个IPv4的IP地址,其实就是一个32位的整数
本文转载自: https://blog.csdn.net/qq_37281656/article/details/138261097
版权归原作者 DieSnowK 所有, 如有侵权,请联系我们删除。
版权归原作者 DieSnowK 所有, 如有侵权,请联系我们删除。