
1、在centos7中创建必要的目录;
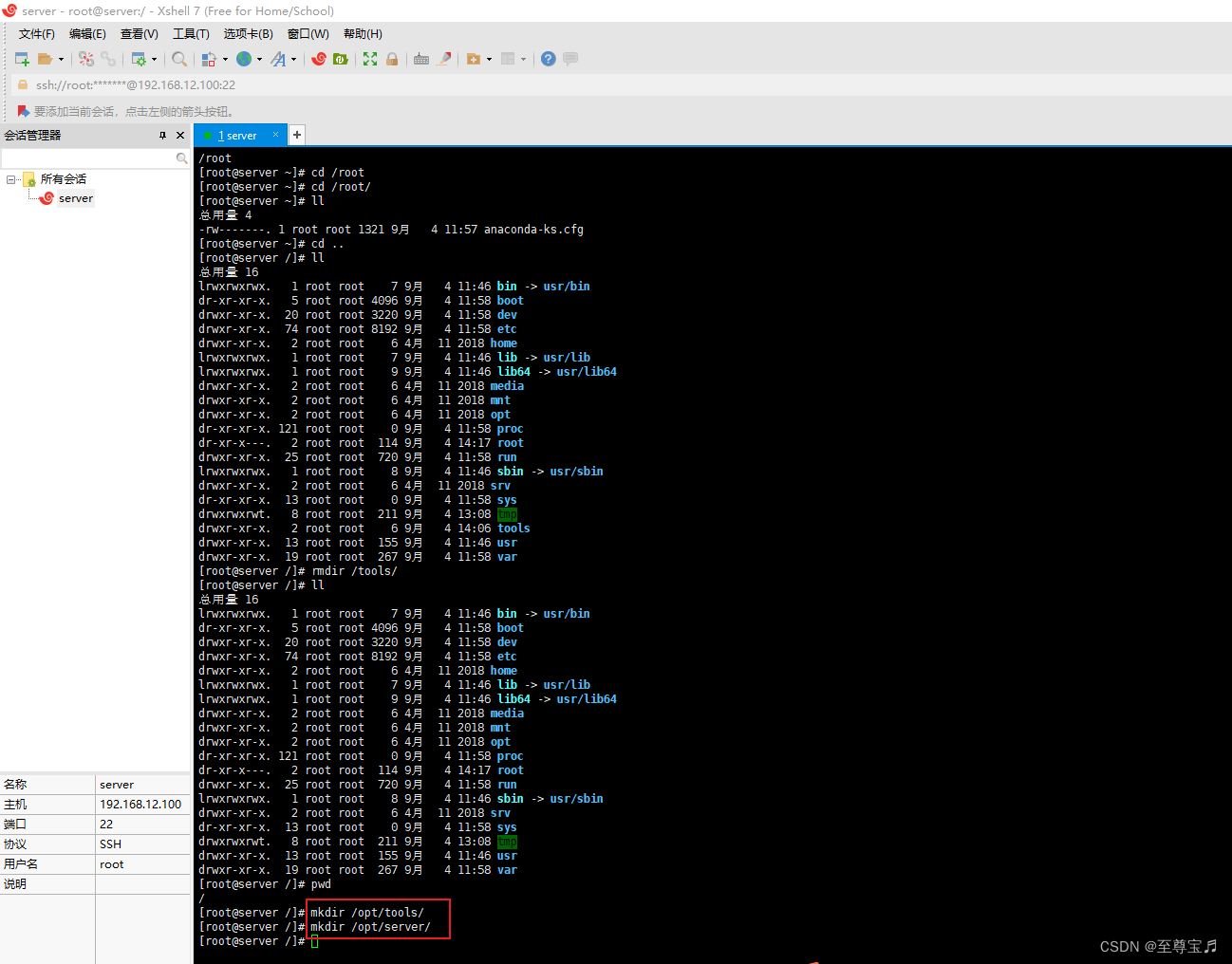
2、上传JDK安装包到tools目录;

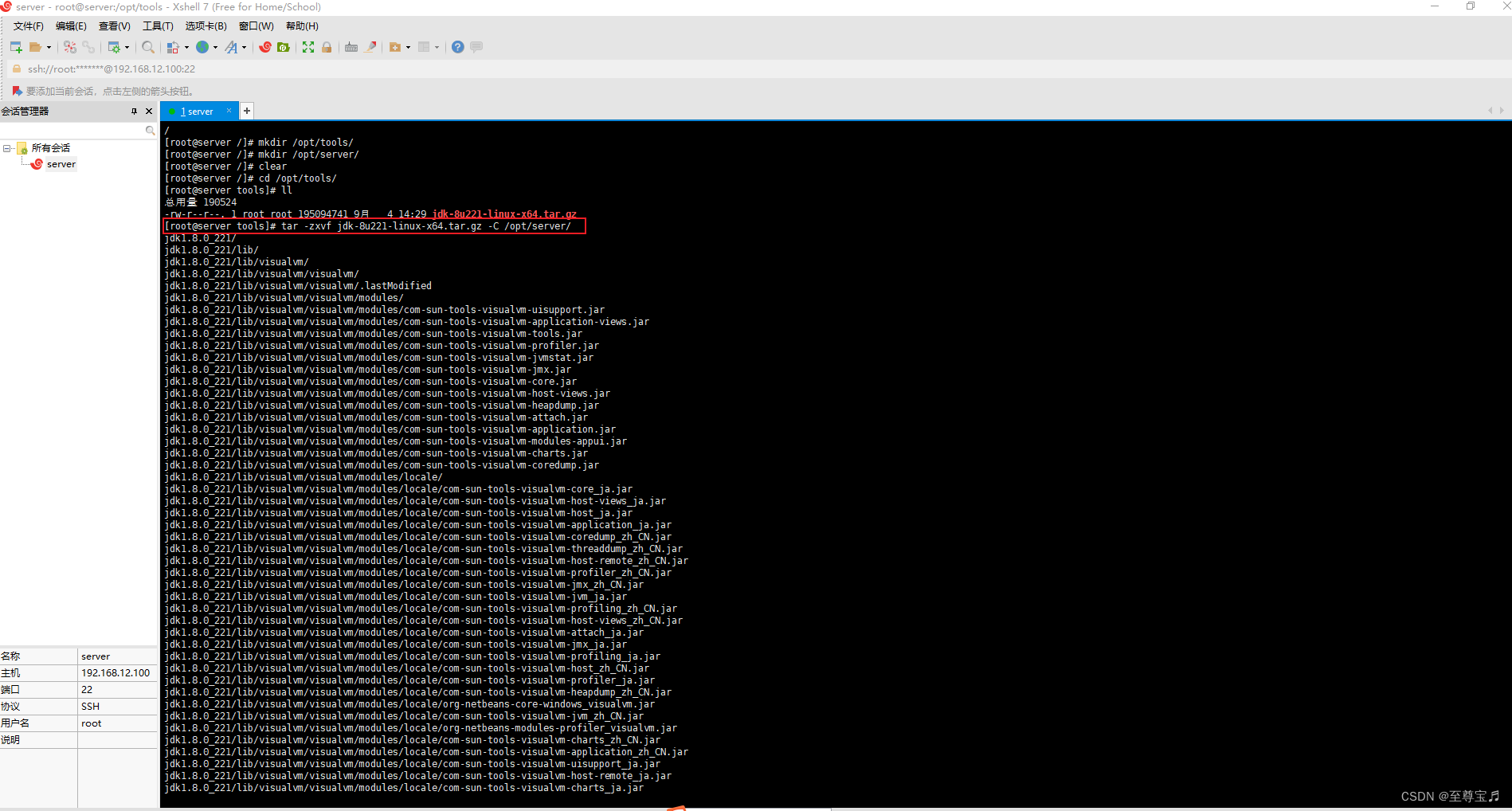
3、解压JDK到/opt/server/目录;
tar -zxvf jdk-8u221-linux-x64.tar.gz -C /opt/server/
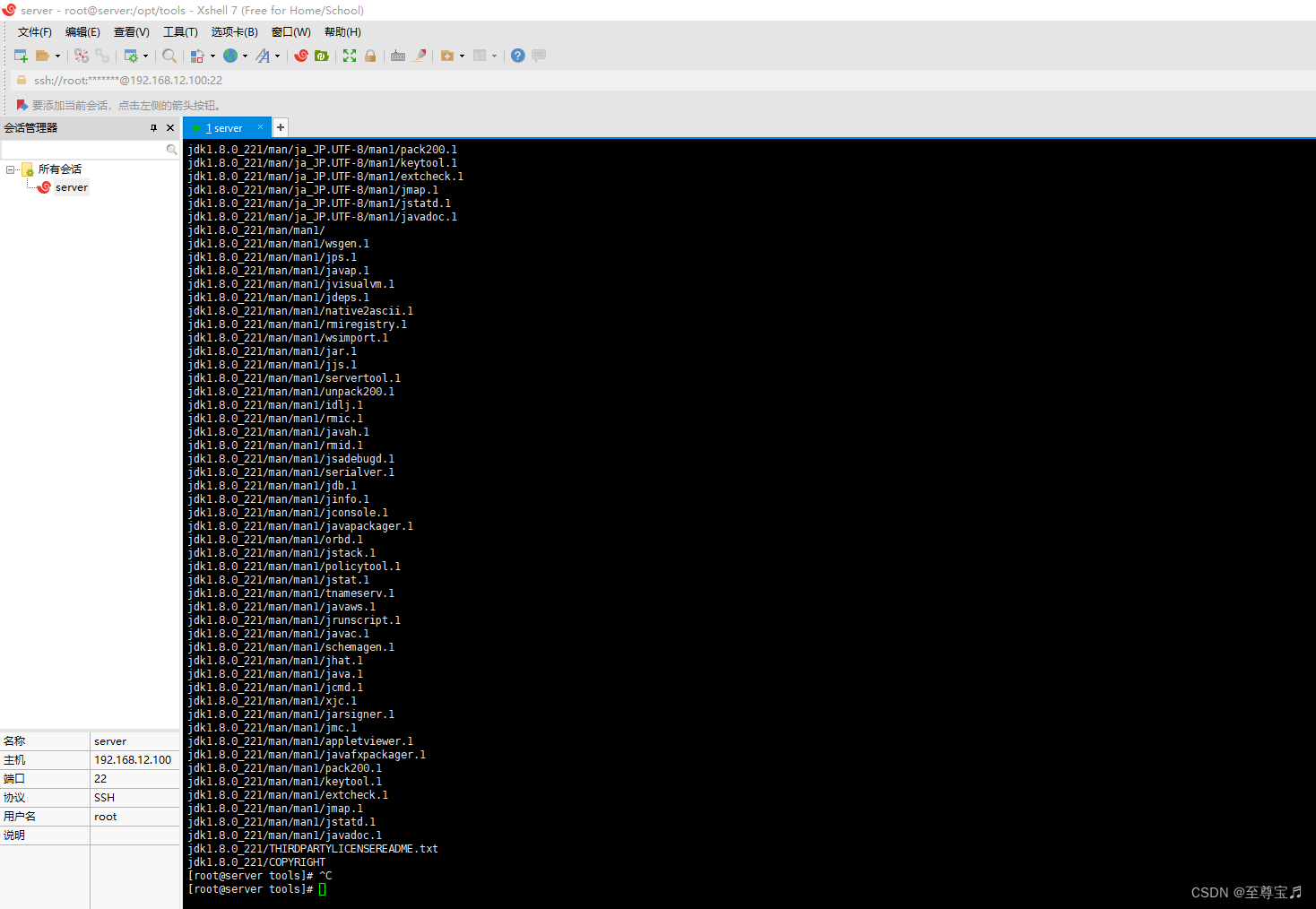
4、“vim:未找到命令”的解决办法;
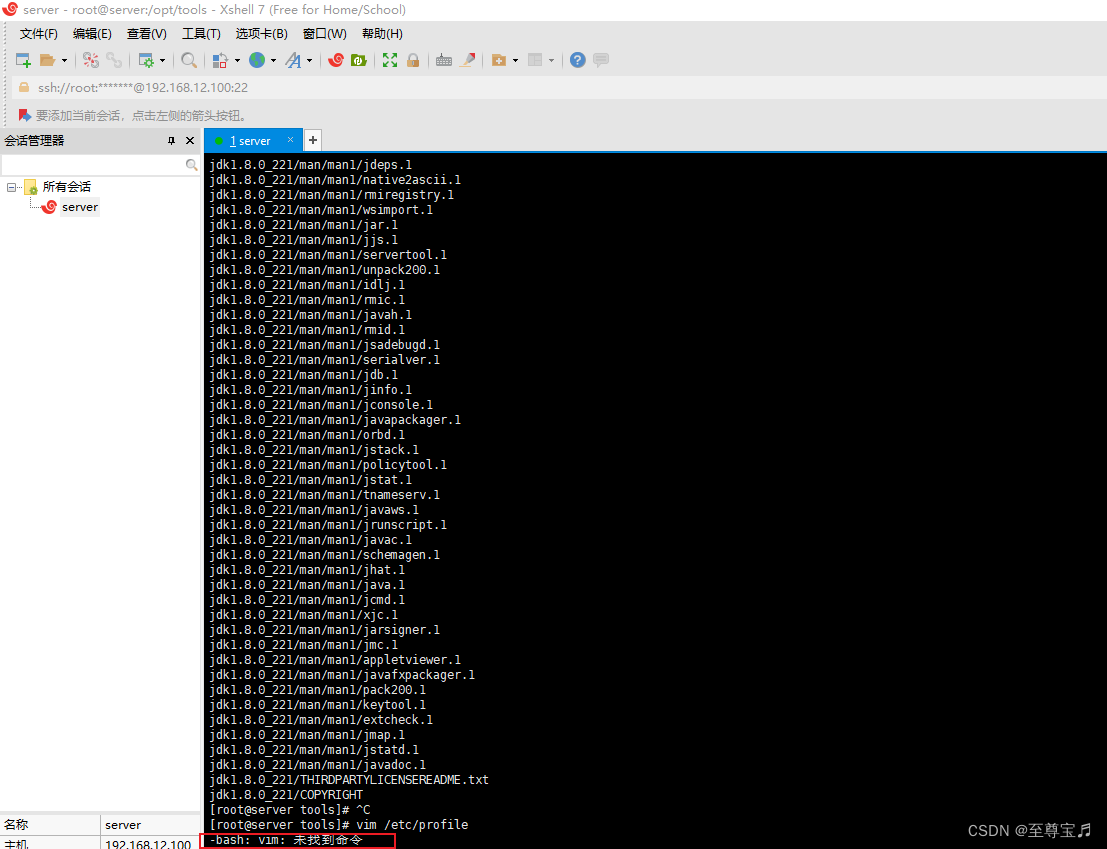
安装vim即可;
yum install -y vim


5、JDK配置环境变量;
vim /etc/profile

按“o”进入编辑模式;
#JDK环境变量
export JAVA_HOME=/opt/server/jdk1.8.0_221
export PATH=${JAVA_HOME}/bin:$PATH
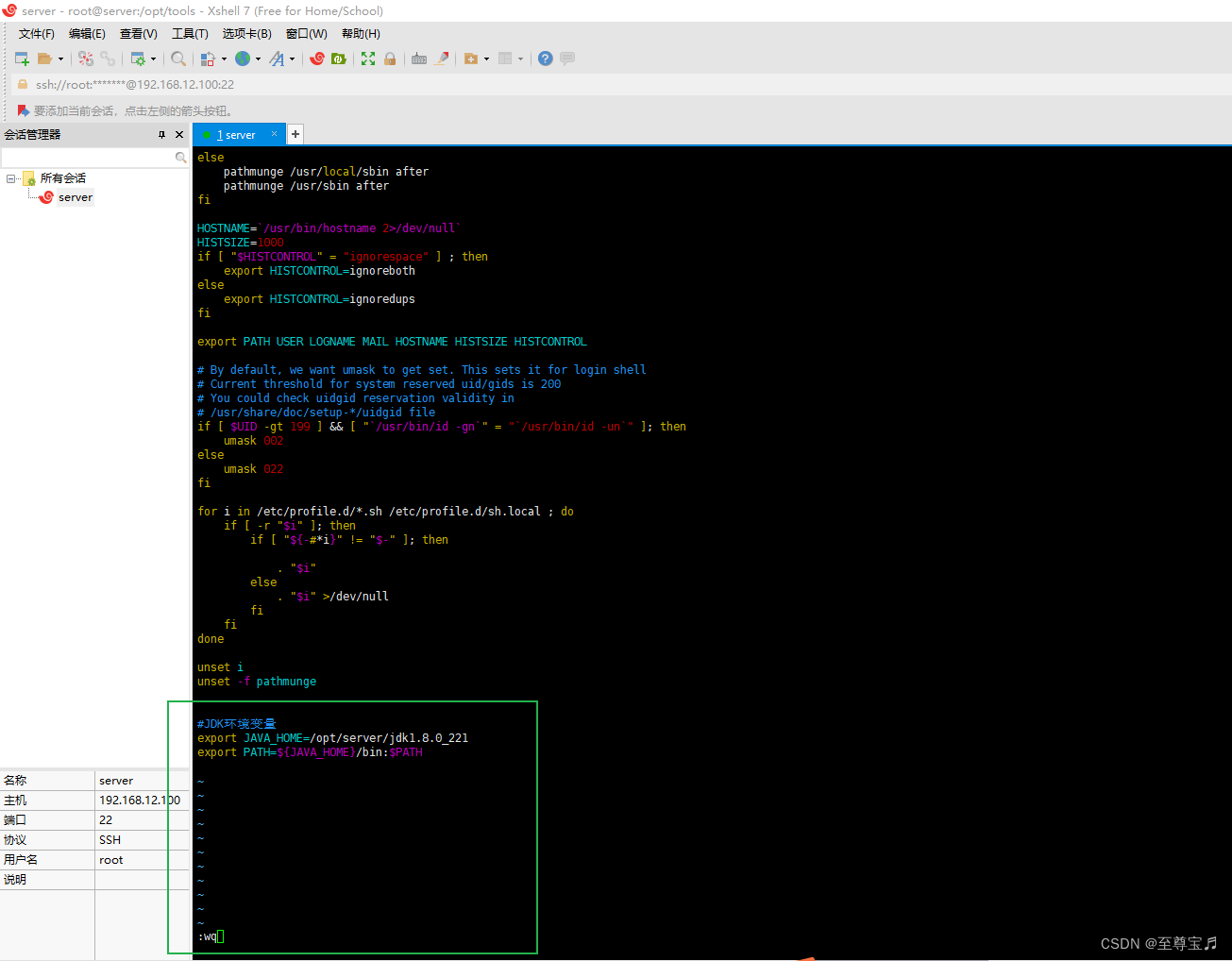
编辑完内容后,“esc”-->“:”-->"wq"-->回车,执行保存并退出。
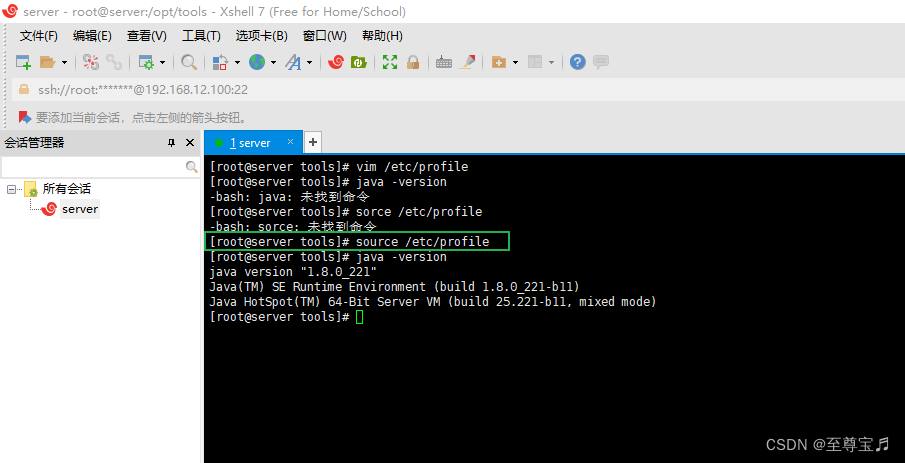
6、刷新环境变量,使其生效;
source /etc/profile
7、配置hosts;
vim /etc/hosts
点"i"或者"o"进入编辑模式;
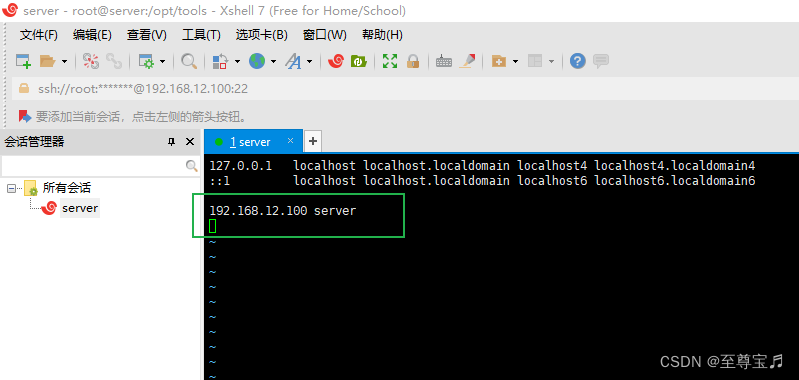
编辑完后,点"Esc"-->":"-->"wq",回车,保存退出。
8、配置免密;
生成公钥和私钥;(一直点下去即可)
ssh-keygen -t rsa
授权是单向的;
8.1、方法一:
进入 ~/.ssh 目录下,查看生成的公匙和私匙,并将公匙写入到授权文件;
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keys
8.2、方法二:
# 本机公钥拷贝到102服务器
ssh-copy-id hadoop102
# 回车,确认102密码后生效
方法二注意:切换用户后,需要重新配置免密。
9、上传hadoop3.3.1并解压;

10、配置hadoop;
进入/opt/server/hadoop-3.3.1/etc/hadoop/目录下,
(1)、修改hadoop-env.sh文件,设置JDK的安装路径;
vim hadoop-env.sh

(2)、修改core-site.xml文件,分别指定hdfs 协议文件系统的通信地址及hadoop 存储临时文件的目录 (此目录不需要手动创建);
vim core-site.xml

<configuration>
<property>
<!--指定 namenode 的 hdfs 协议文件系统的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://server:8020</value>
</property>
<property>
<!--指定 hadoop 数据文件存储目录-->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data</value>
</property>
</configuration>
(3)、修改hdfs-site.xml,指定 dfs 的副本系数;
vim hdfs-site.xml
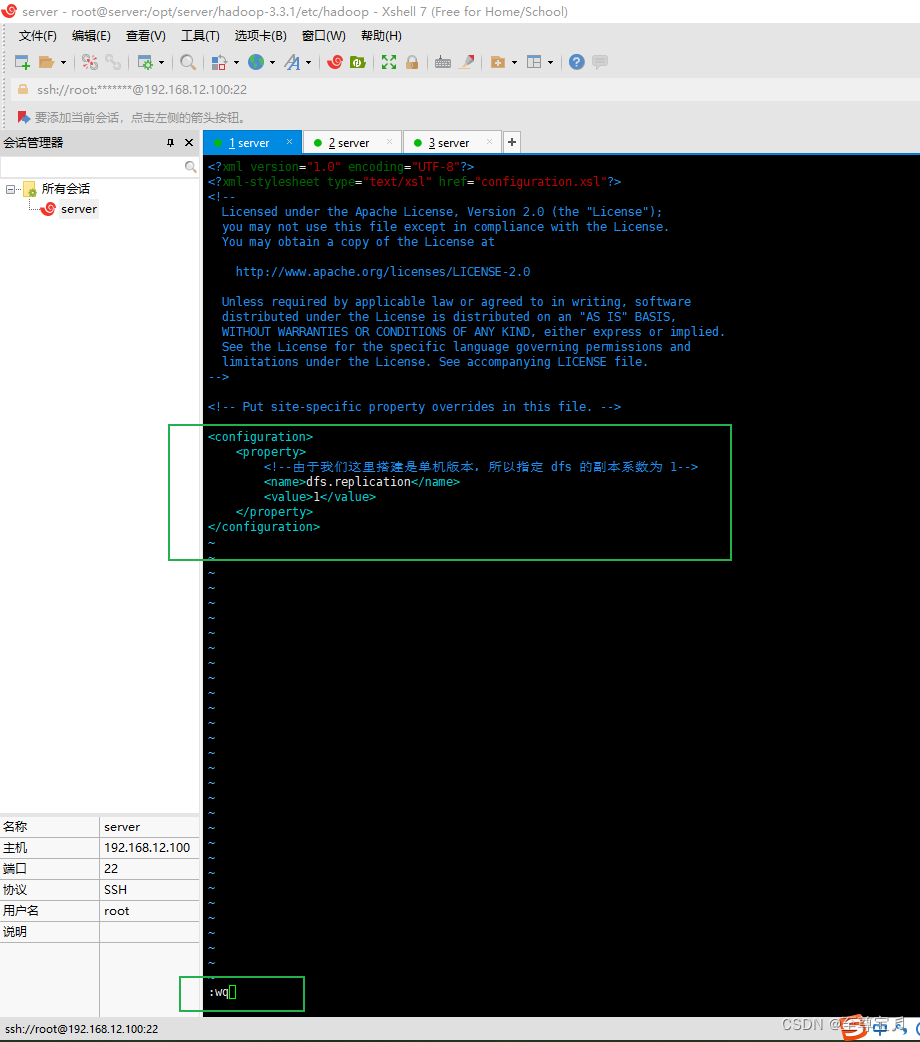
<configuration>
<property>
<!--由于我们这里搭建是单机版本,所以指定 dfs 的副本系数为 1-->
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
(4)、修改workers文件,配置所有从属节点;
vim workers
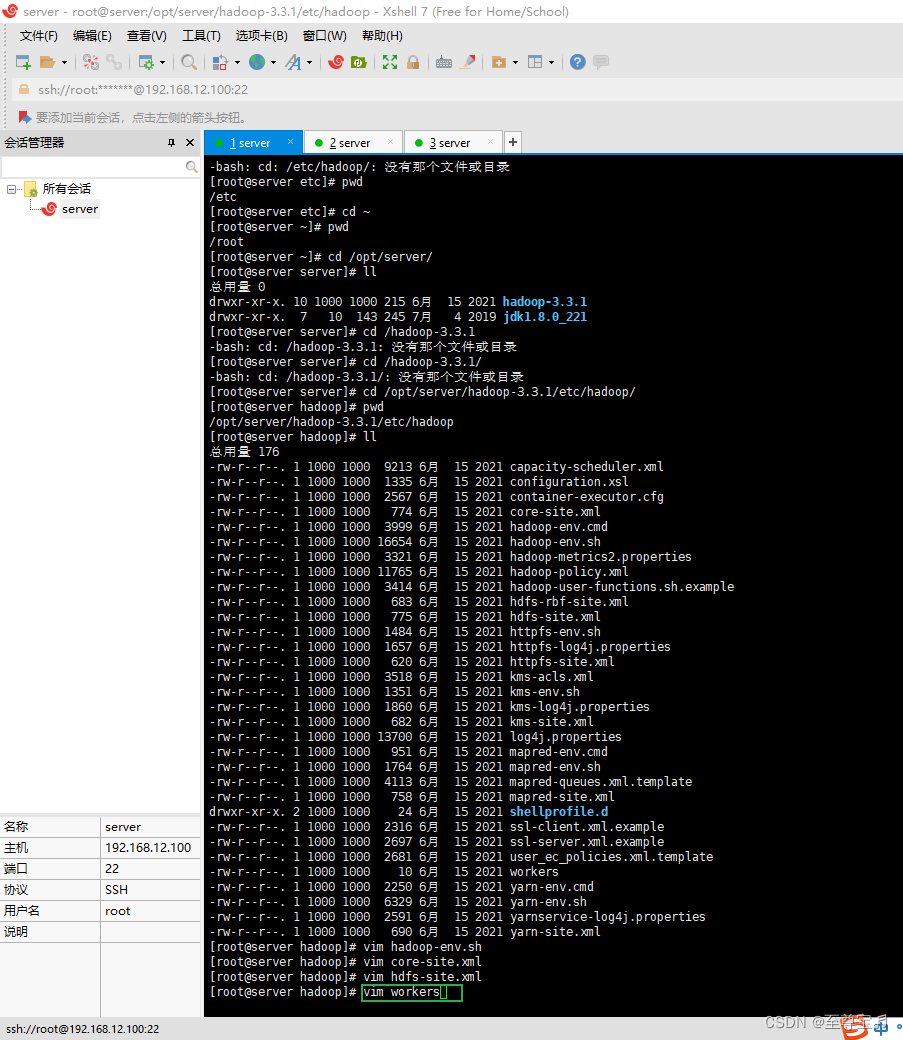
server
11、关闭防火墙;
如果不关闭防火墙,可能导致无法访问 Hadoop 的 Web UI 界面;
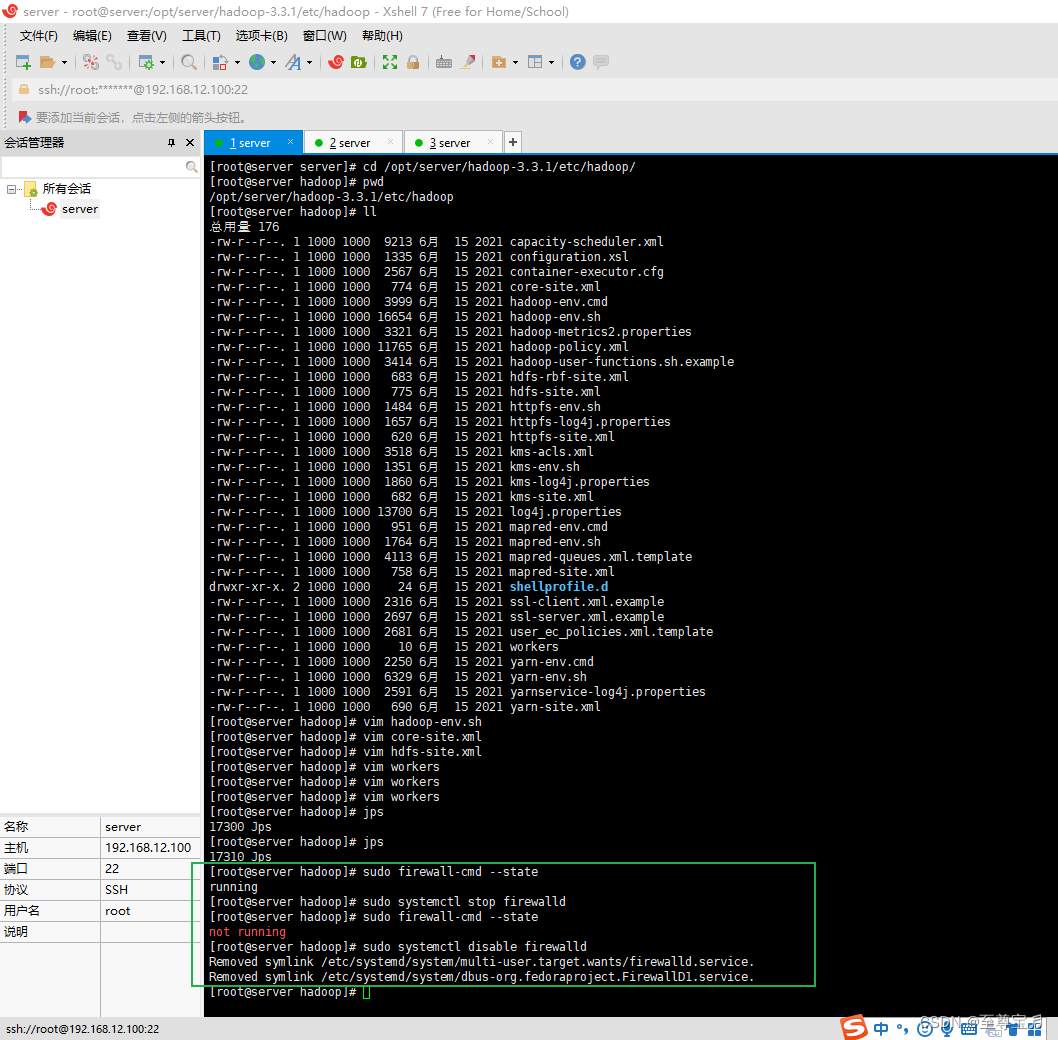
# 查看防火墙状态
sudo firewall-cmd --state
# 关闭防火墙:
sudo systemctl stop firewalld
# 禁止开机启动
sudo systemctl disable firewalld
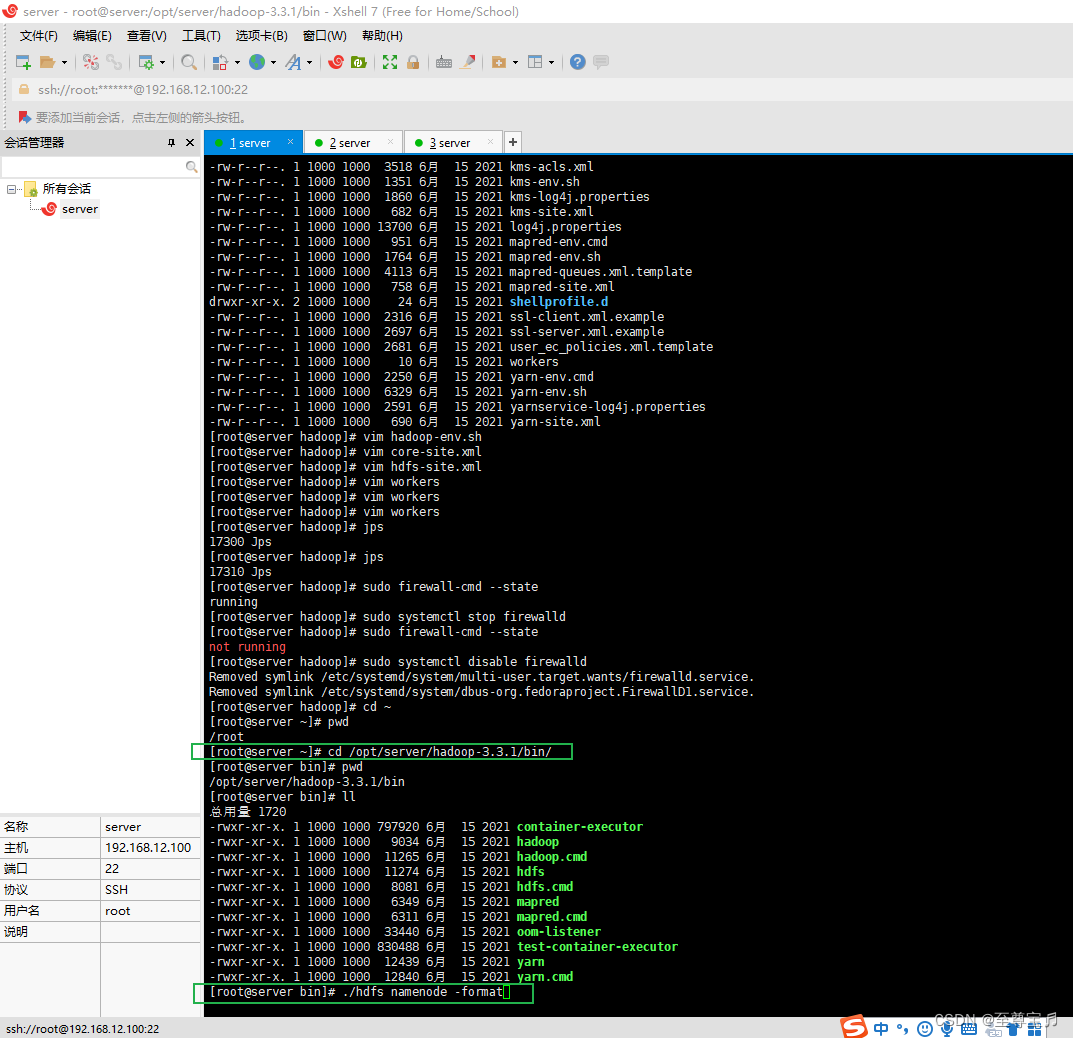
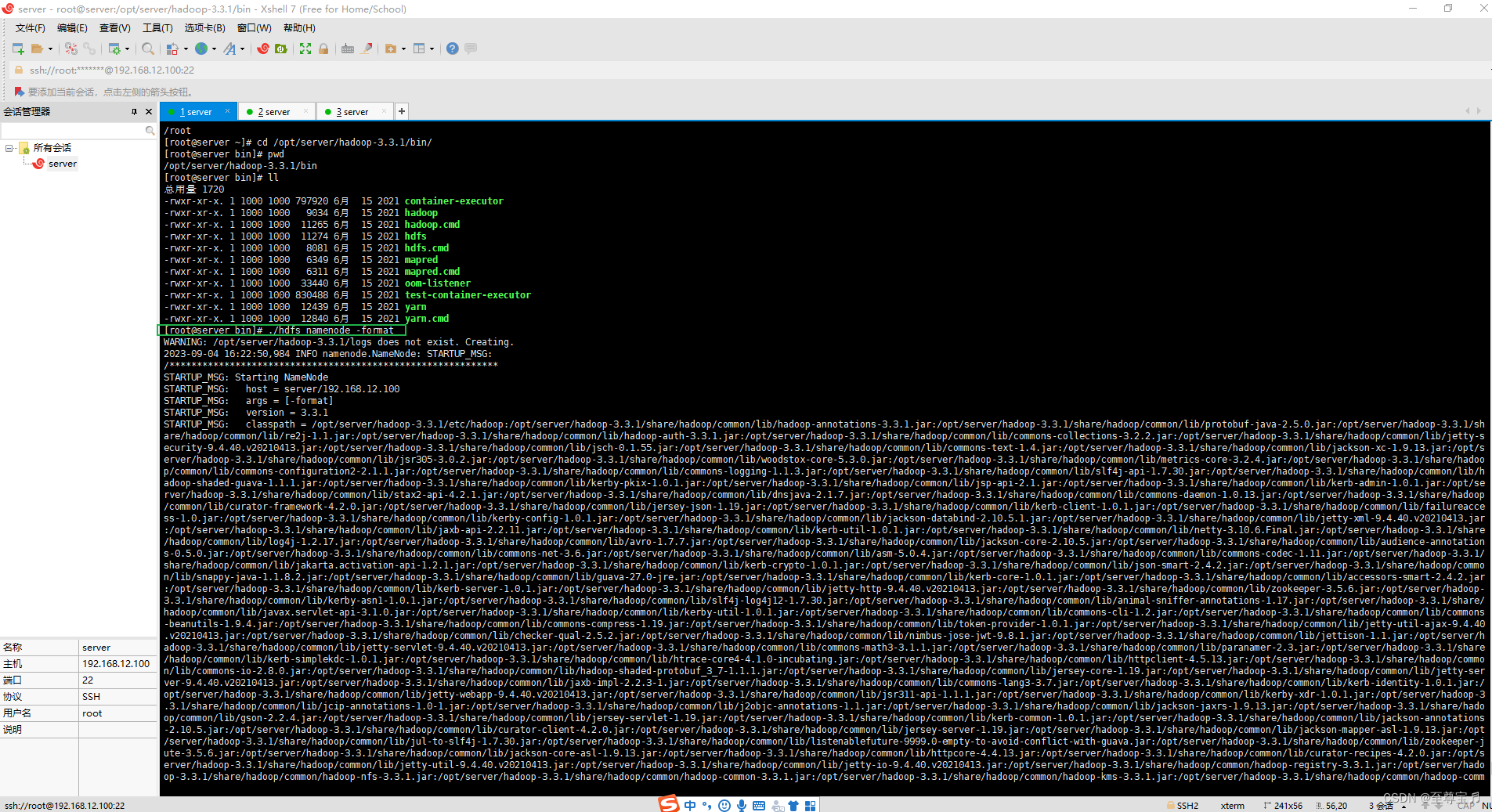
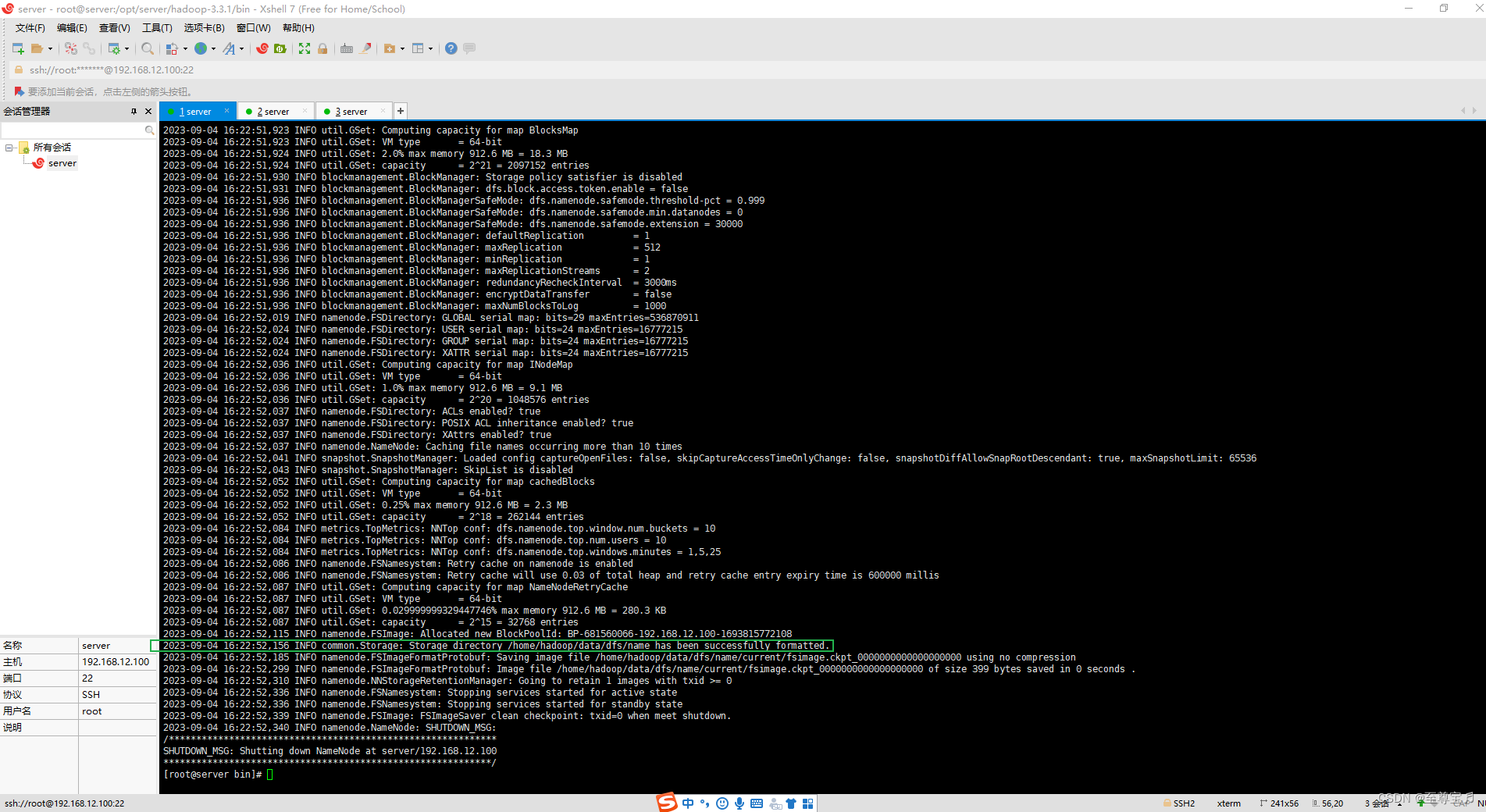
12、格式化namenode;
初始化,第一次启动 Hadoop 时需要进行初始化,进入 /opt/server/hadoop-3.3.1/bin目录下,执
行以下命令:

13、Hadoop 3中不允许使用root用户来一键启动集群,需要配置启动用户;
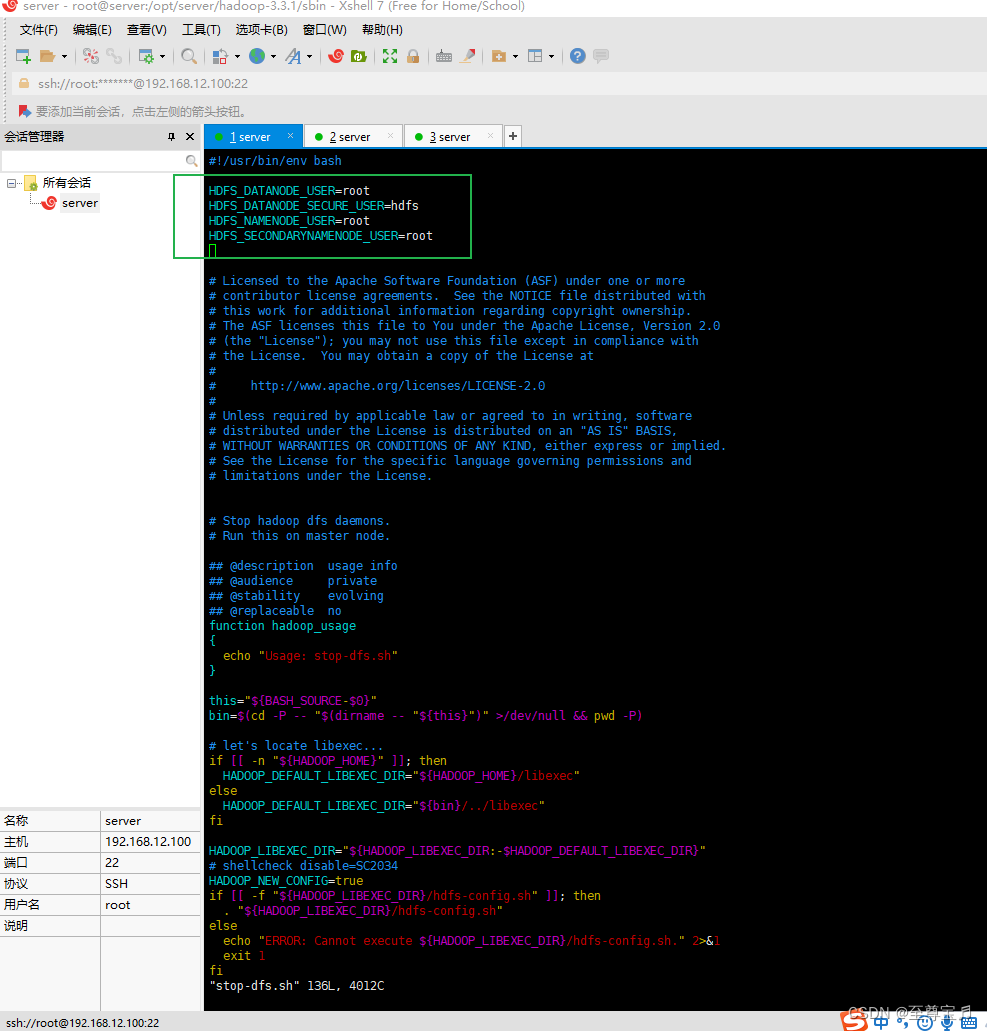
进入目录“/opt/server/hadoop-3.3.1/sbin”,编辑start-dfs.sh、stop-dfs.sh,在顶部加入以下内容;
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
start-dfs.sh如下:

stop-dfs.sh如下:
14、启动hdfs;
进入/opt/server/hadoop-3.3.1/sbin/目录下,
./start-dfs.sh
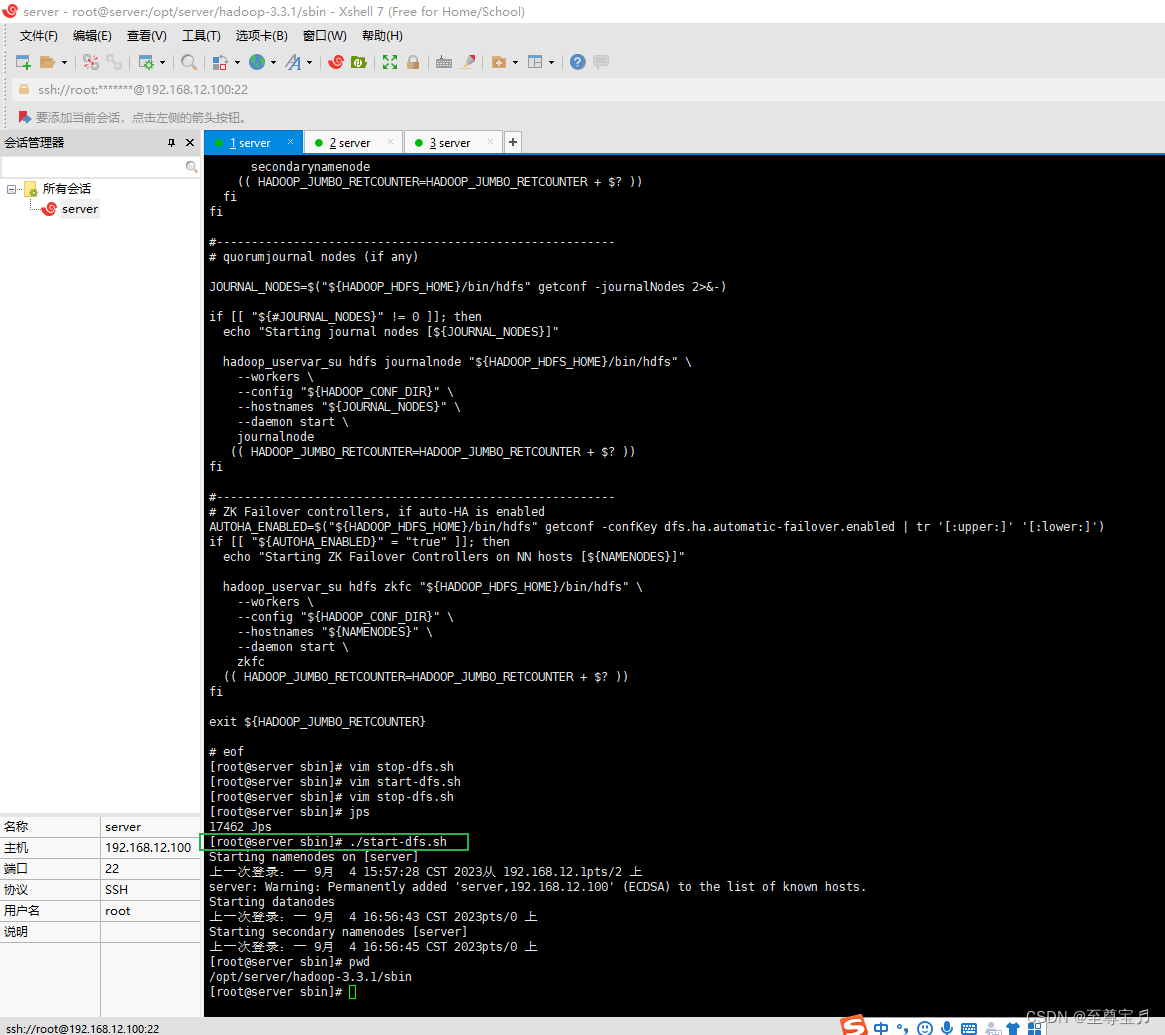
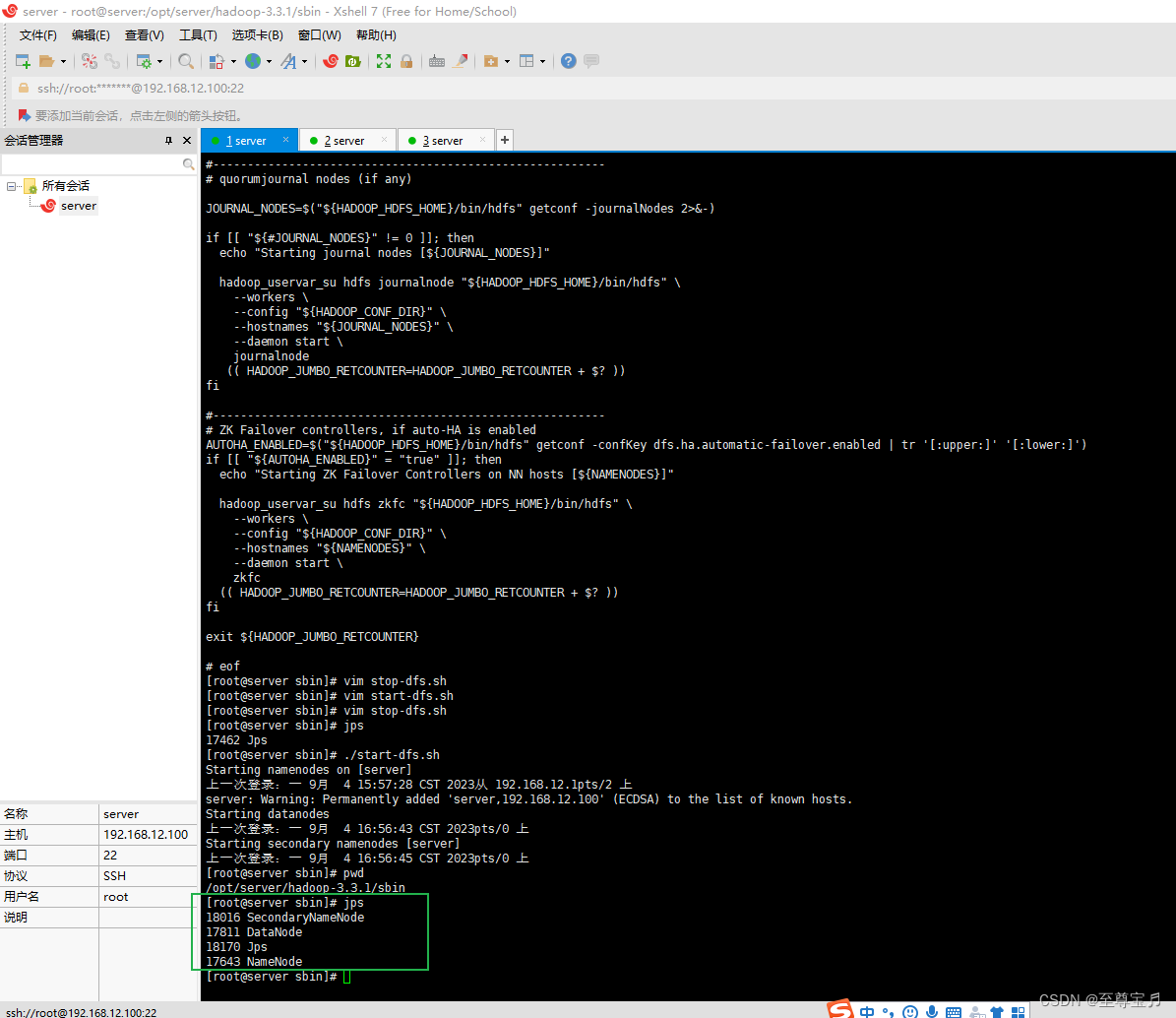
启动成功;
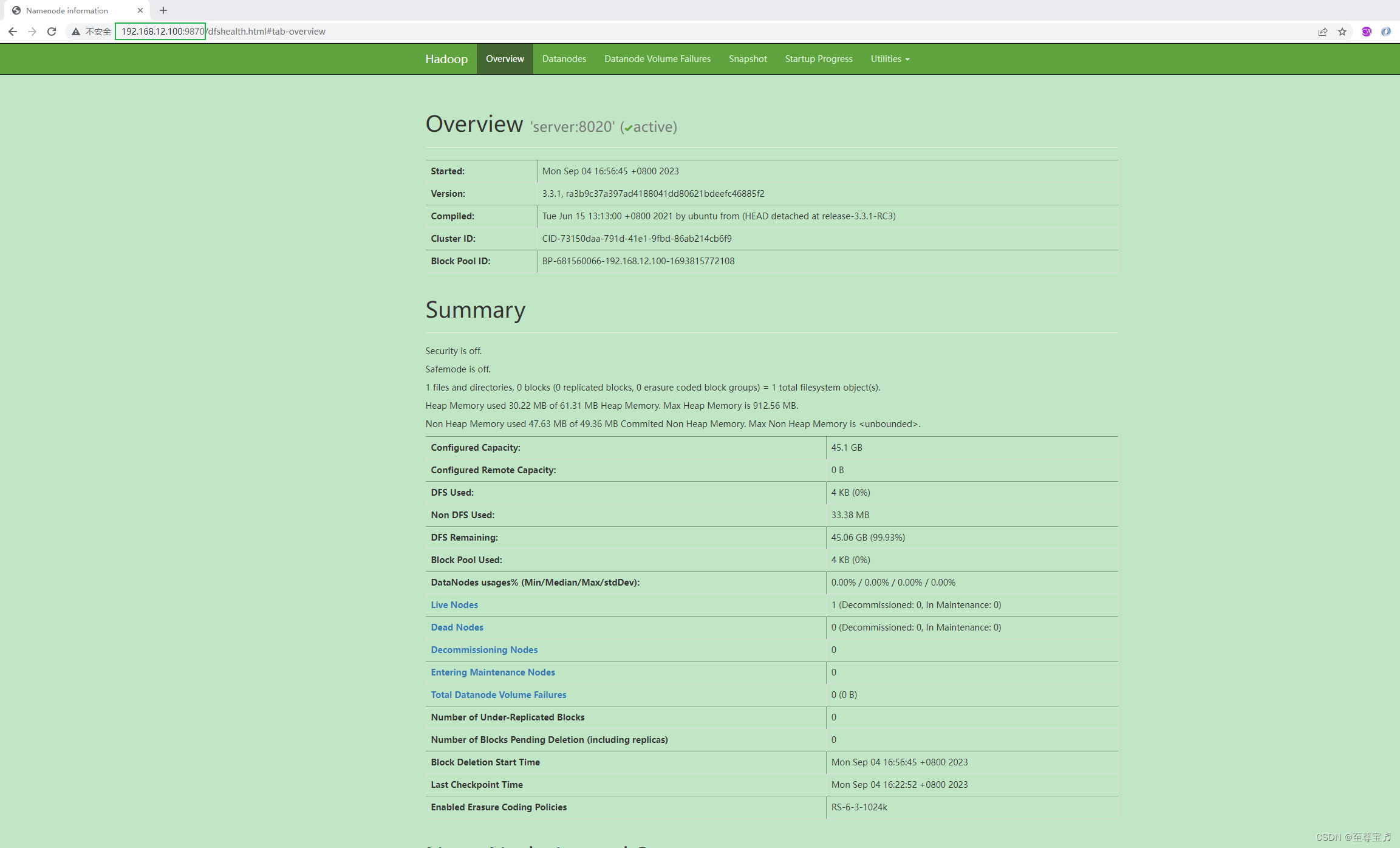
15、查看 Web UI 界面,端口为 9870;
16、配置hadoop环境变量,方便启动;

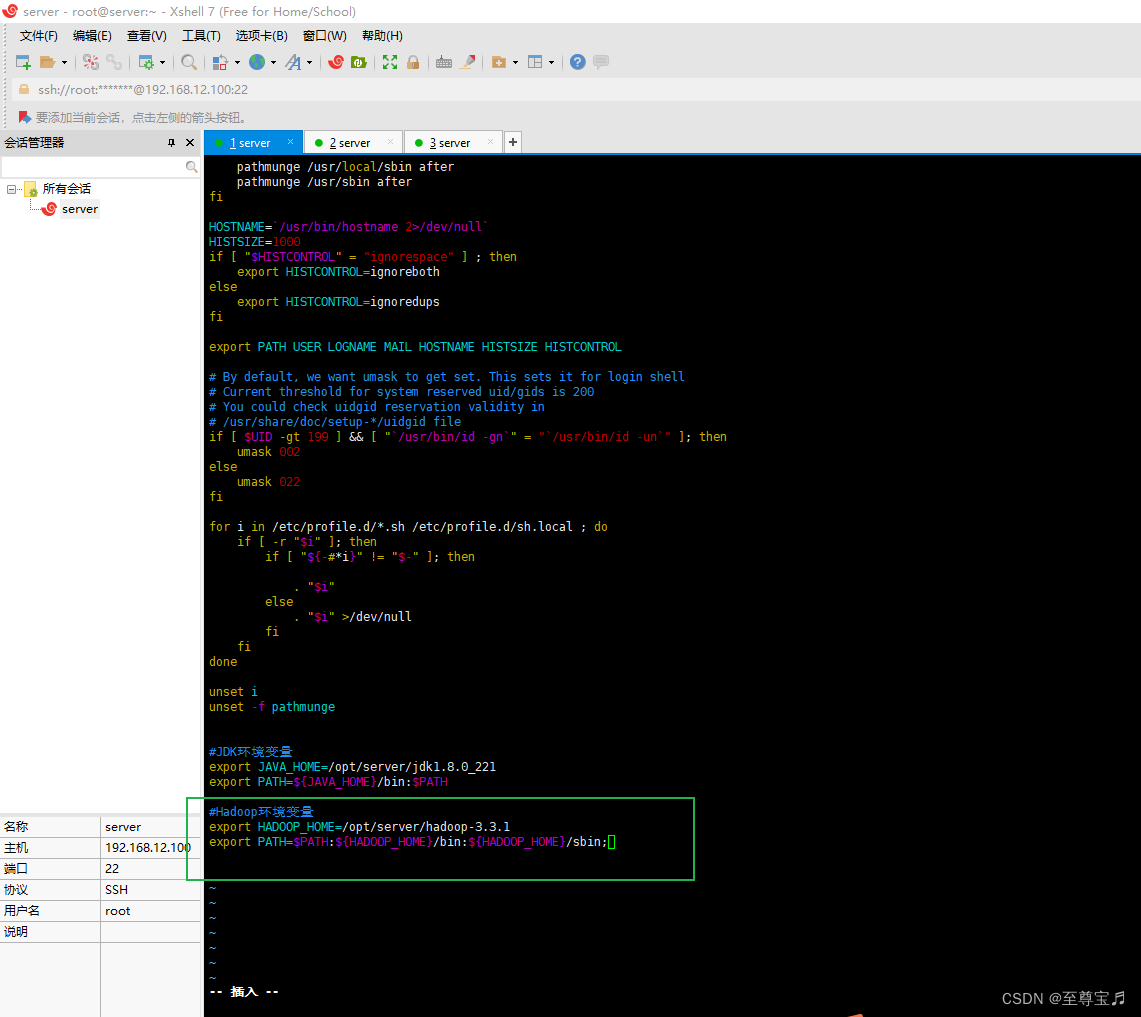
#Hadoop环境变量
export HADOOP_HOME=/opt/server/hadoop-3.3.1
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin;
执行“source /etc/profile”刷新,使其生效。

17、yarn环境搭建;
(1)、配置mapred-site.xml;
进入/opt/server/hadoop-3.3.1/etc/hadoop/目录;
vim mapred-site.xml

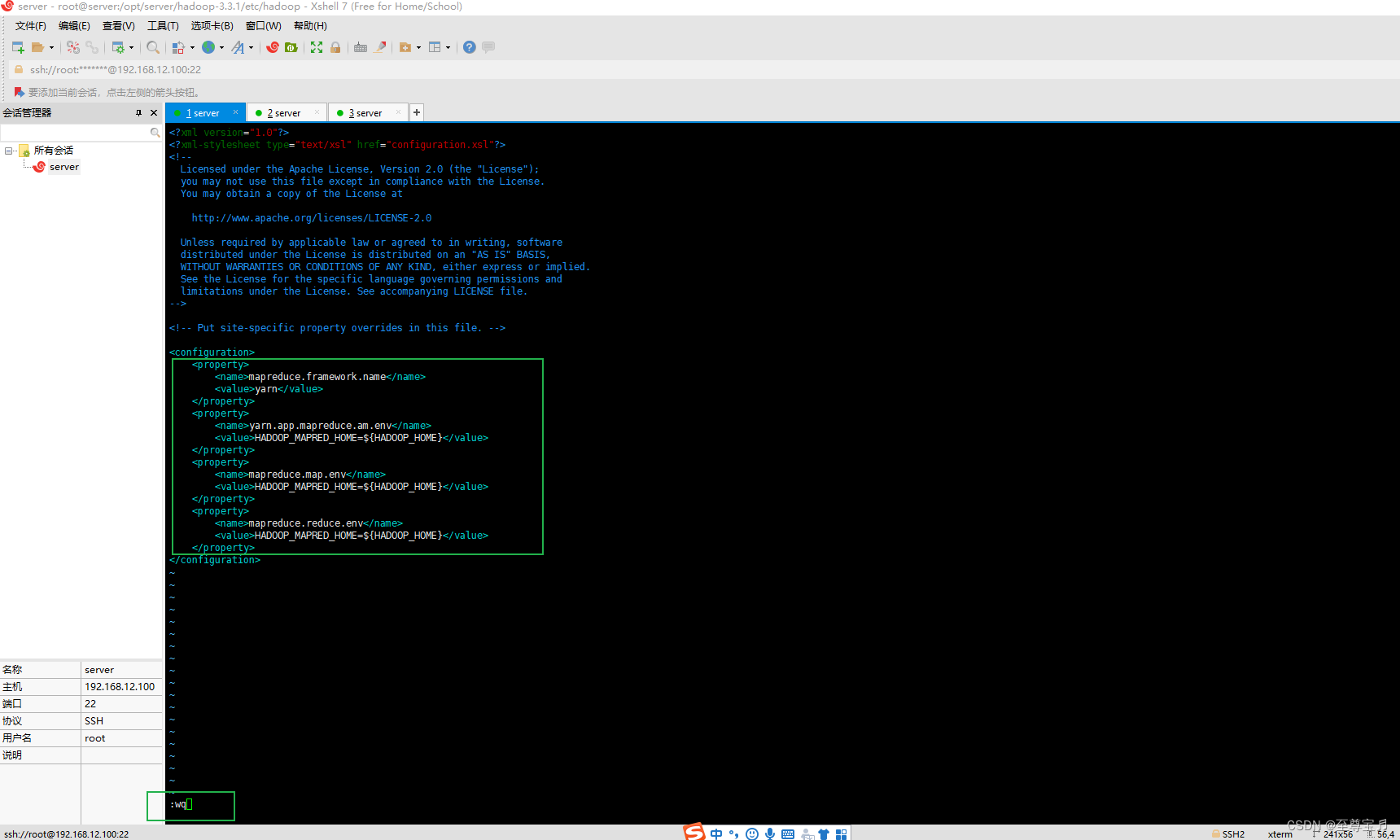
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
(2)、配置yarn-site.xml;
vim yarn-site.xml
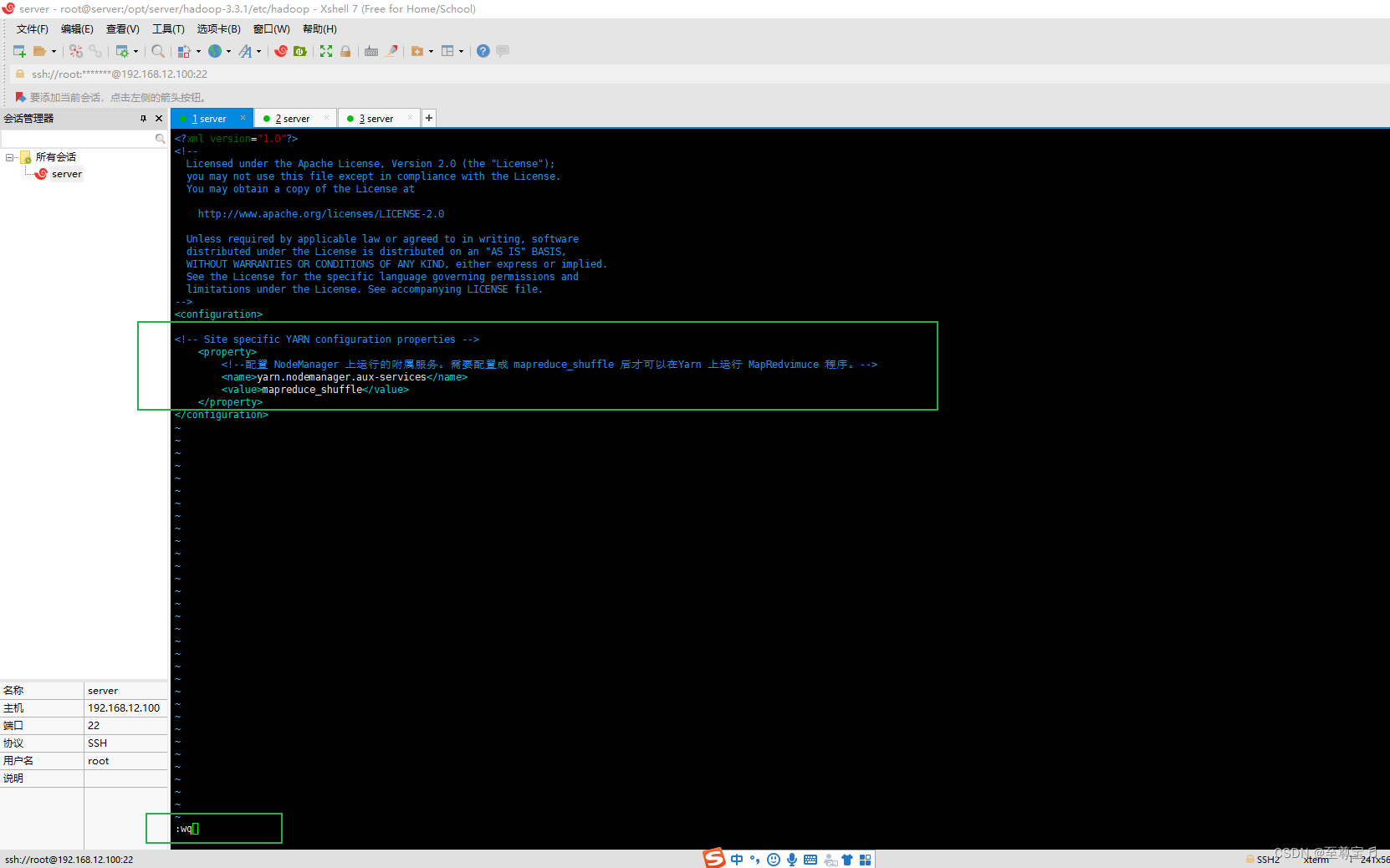
<configuration>
<property>
<!--配置 NodeManager 上运行的附属服务。需要配置成 mapreduce_shuffle 后才可以在Yarn 上运行 MapRedvimuce 程序。-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
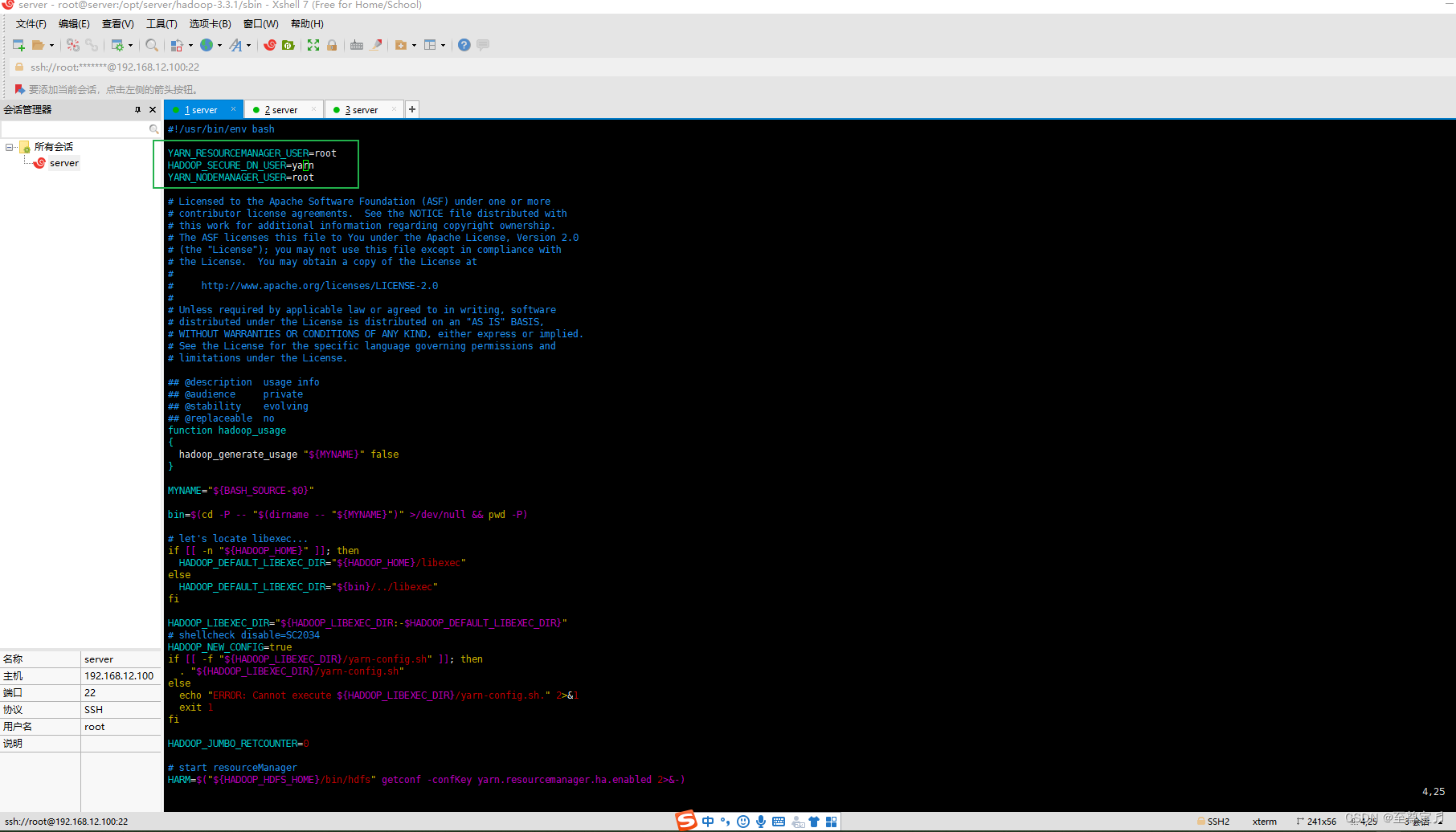
18、hadoop3配置root启动yarn权限;
进入“/opt/server/hadoop-3.3.1/sbin/”目录;
# start-yarn.sh stop-yarn.sh在两个文件顶部添加以下内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
vim start-yarn.sh
vim stop-yarn.sh

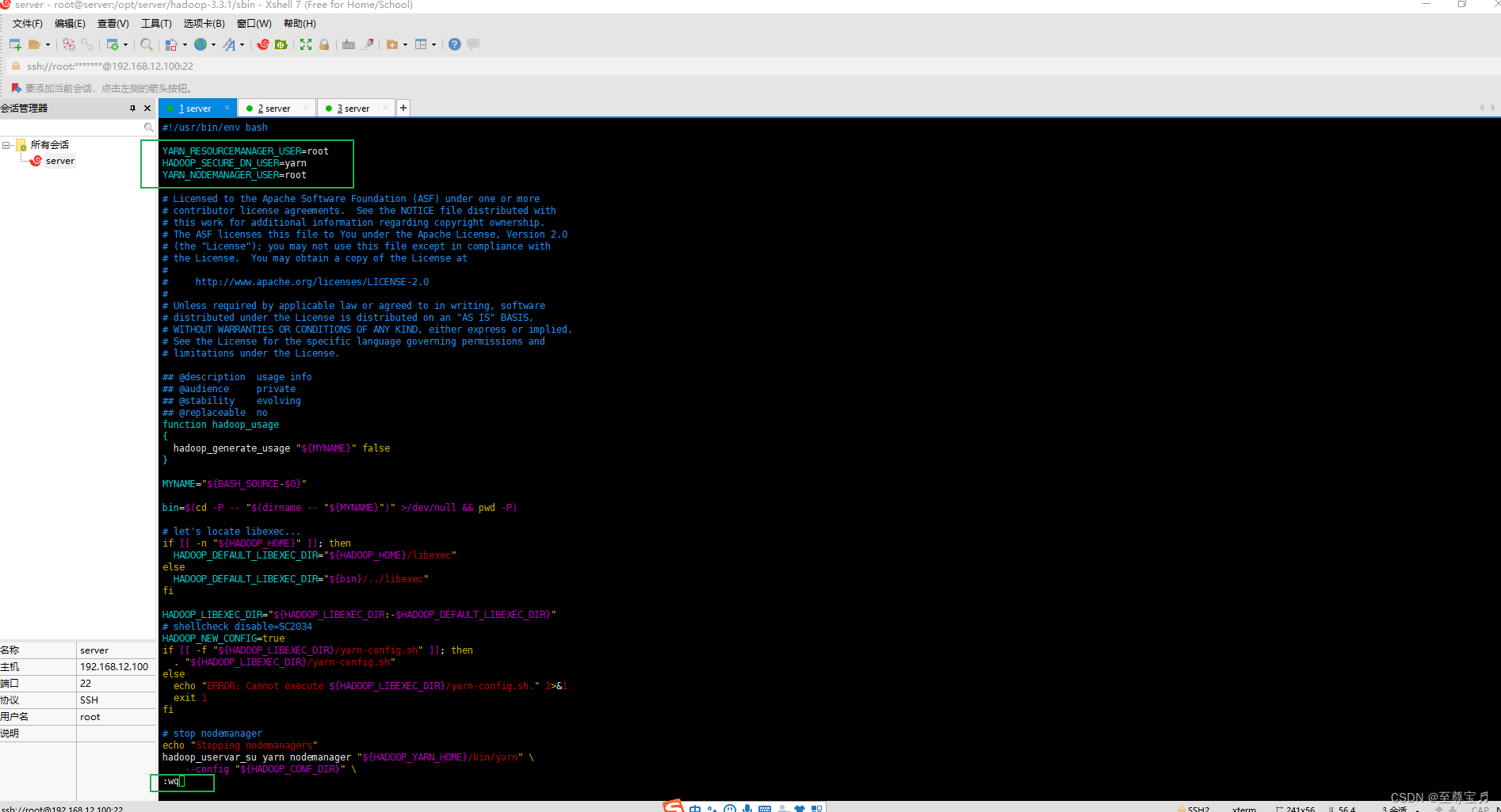
19、启动yarn;
进入“/opt/server/hadoop-3.3.1/sbin/”目录;
./start-yarn.sh

20、访问yarn的web管理界面;
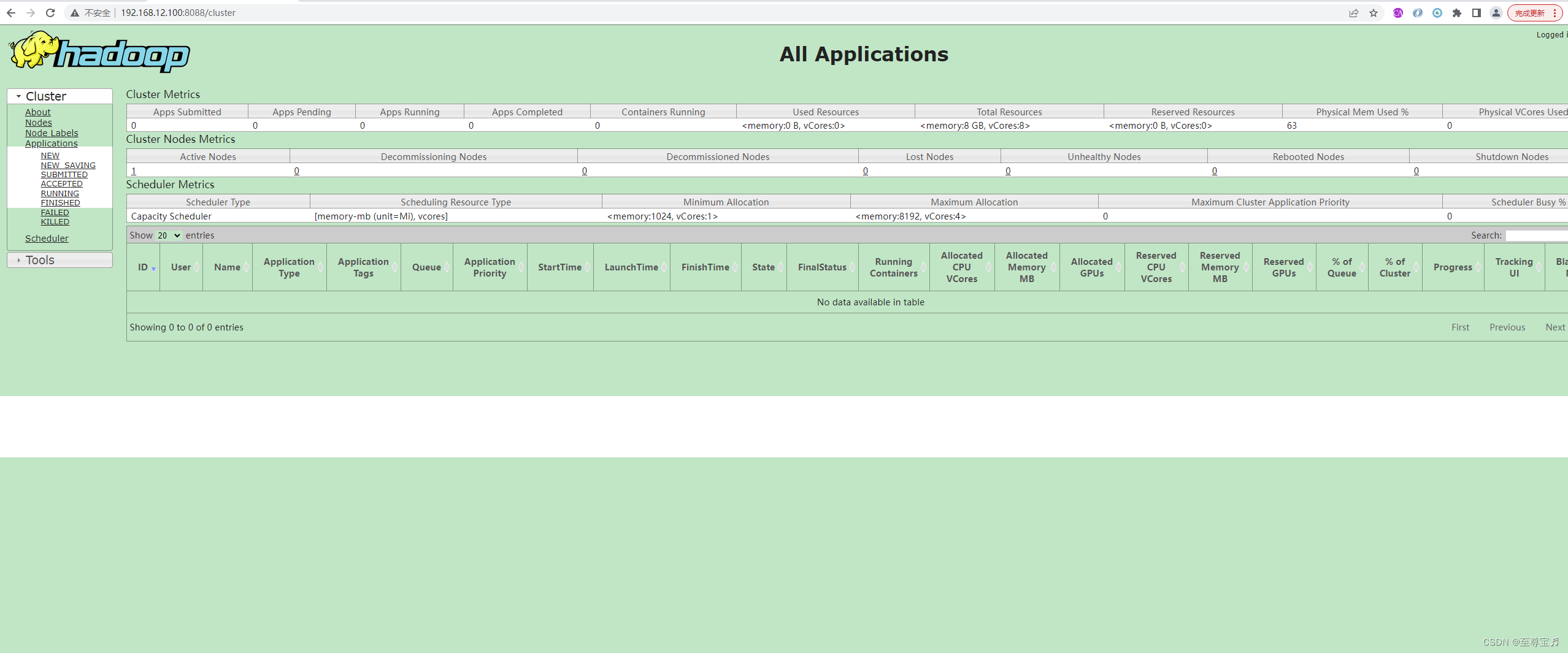
21、“Permission denied: user=dr.who, access=WRITE, inode="/":root:supergroup:drwxr-xr-x”;
创建目录、上传文件失败。
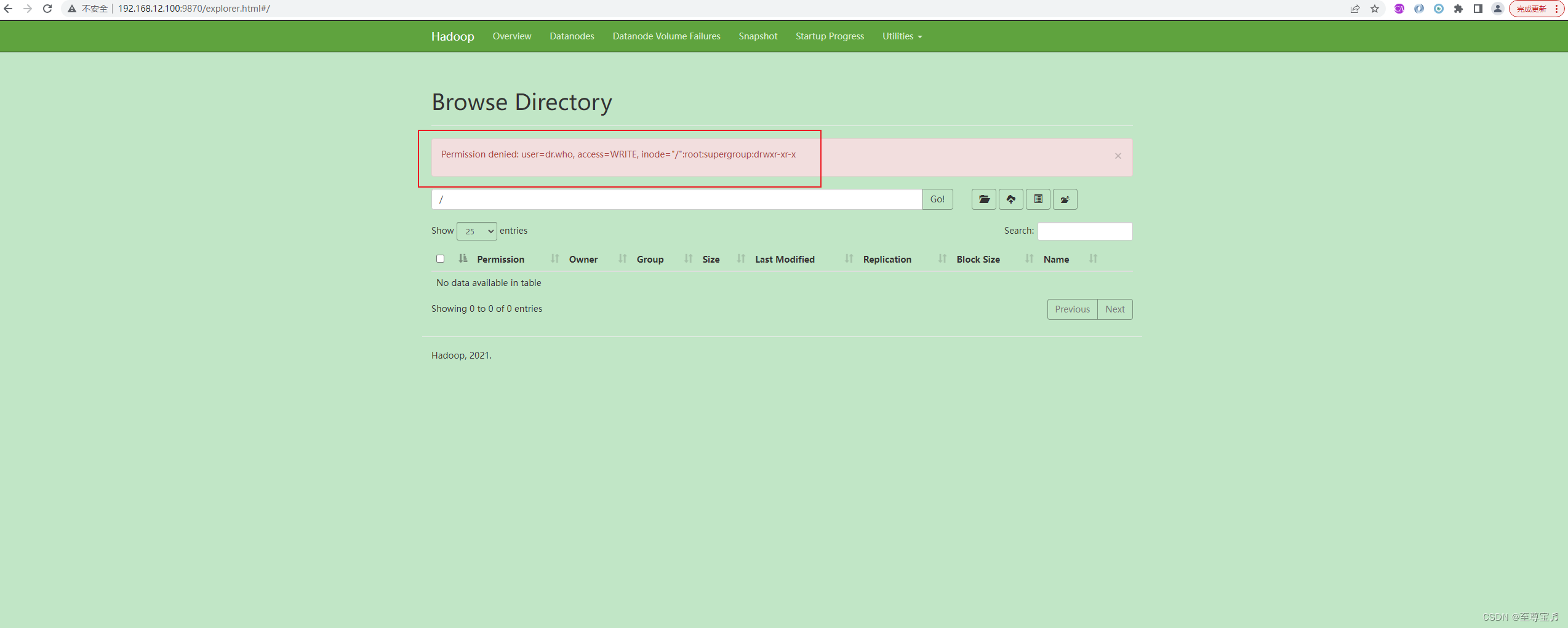
这里“dr.who”表示的是在网页端访问hdfs时的默认用户名,而真实是不存在的,它的权限很小,为了保证数据安全,无法访问其他用户的数据。修改默认登录用户就可解决此处权限问题。
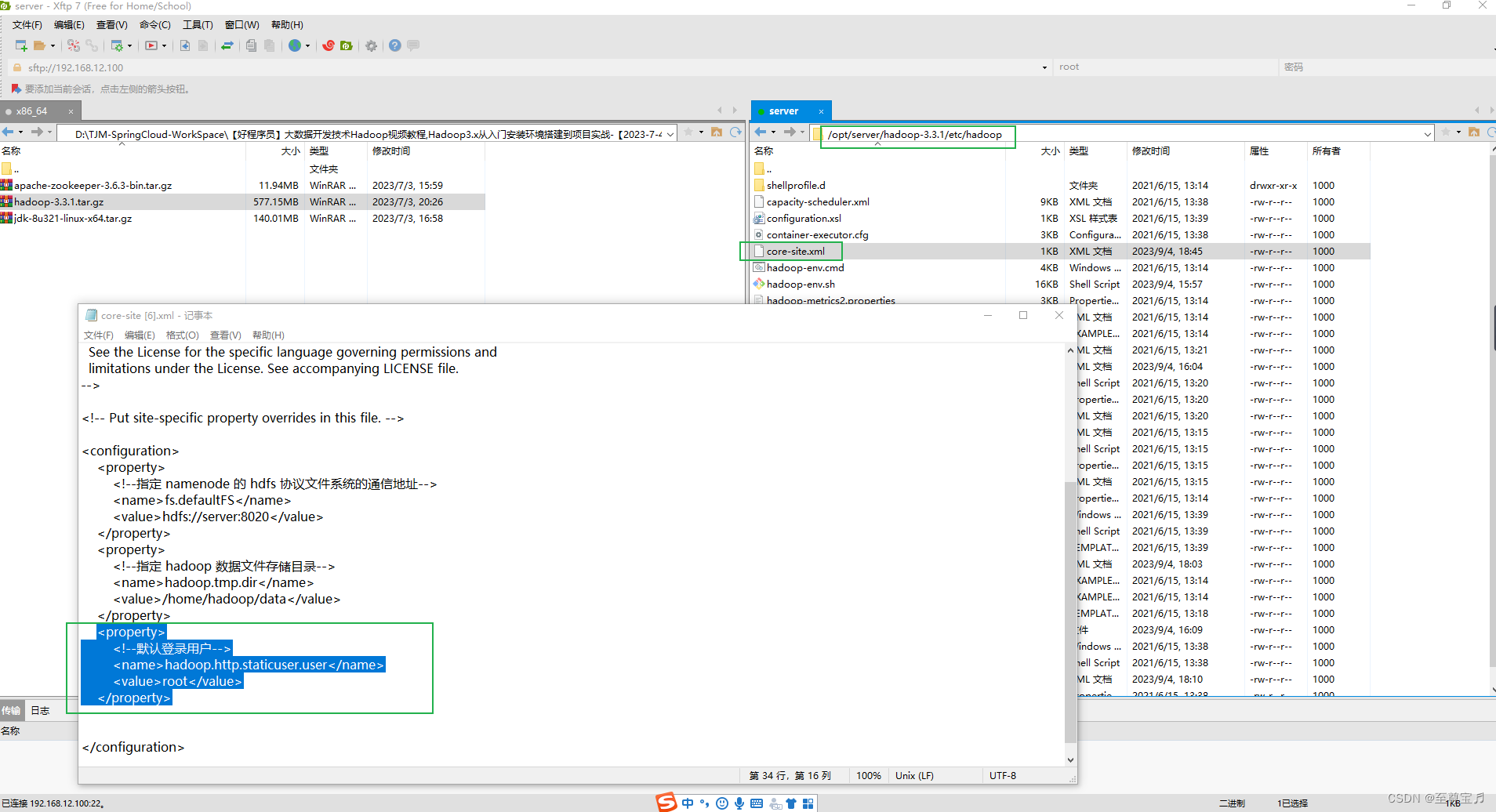
修改“/opt/server/hadoop-3.3.1/etc/hadoop/”目录下的core-site.xml;
添加下面属性;
<property>
<!--默认登录用户-->
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
重启hdfs服务即可。
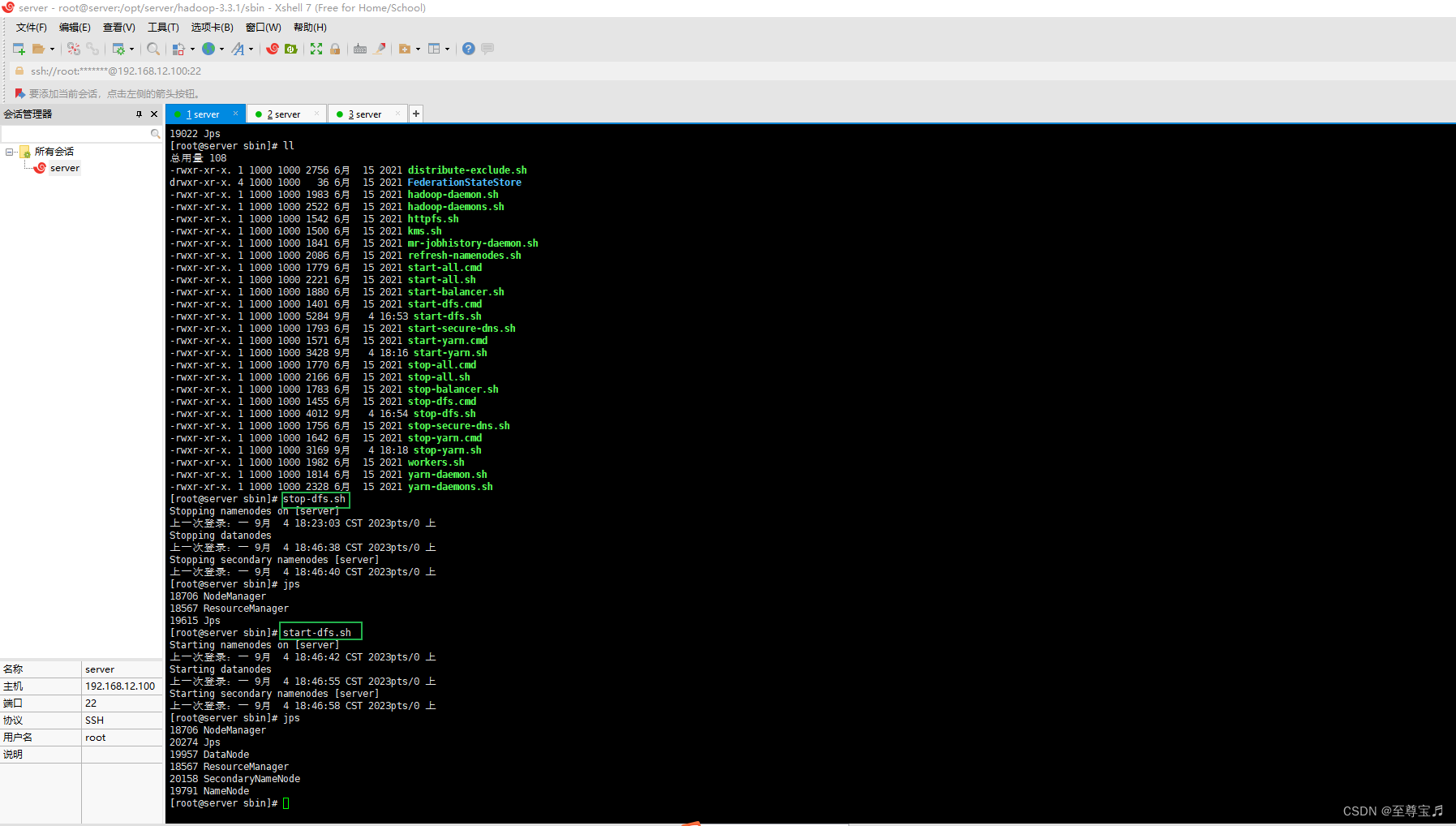
创建目录成功;

22、hdfs上传文件失败,“Couldn't upload the file xxxxxxxxxxx.csv.”;
原因:客户端web无法解析server域名到指定ip引起的。

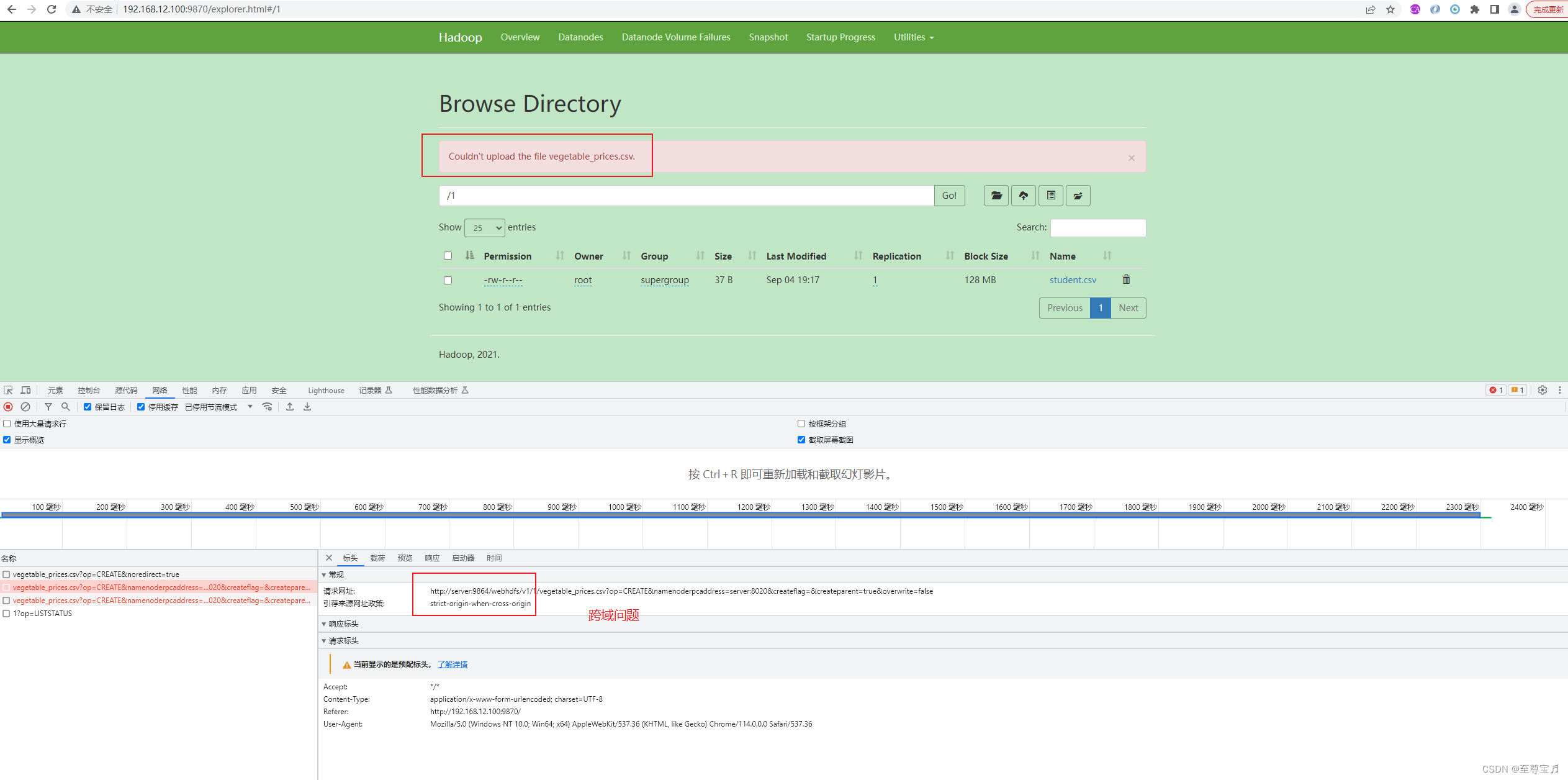
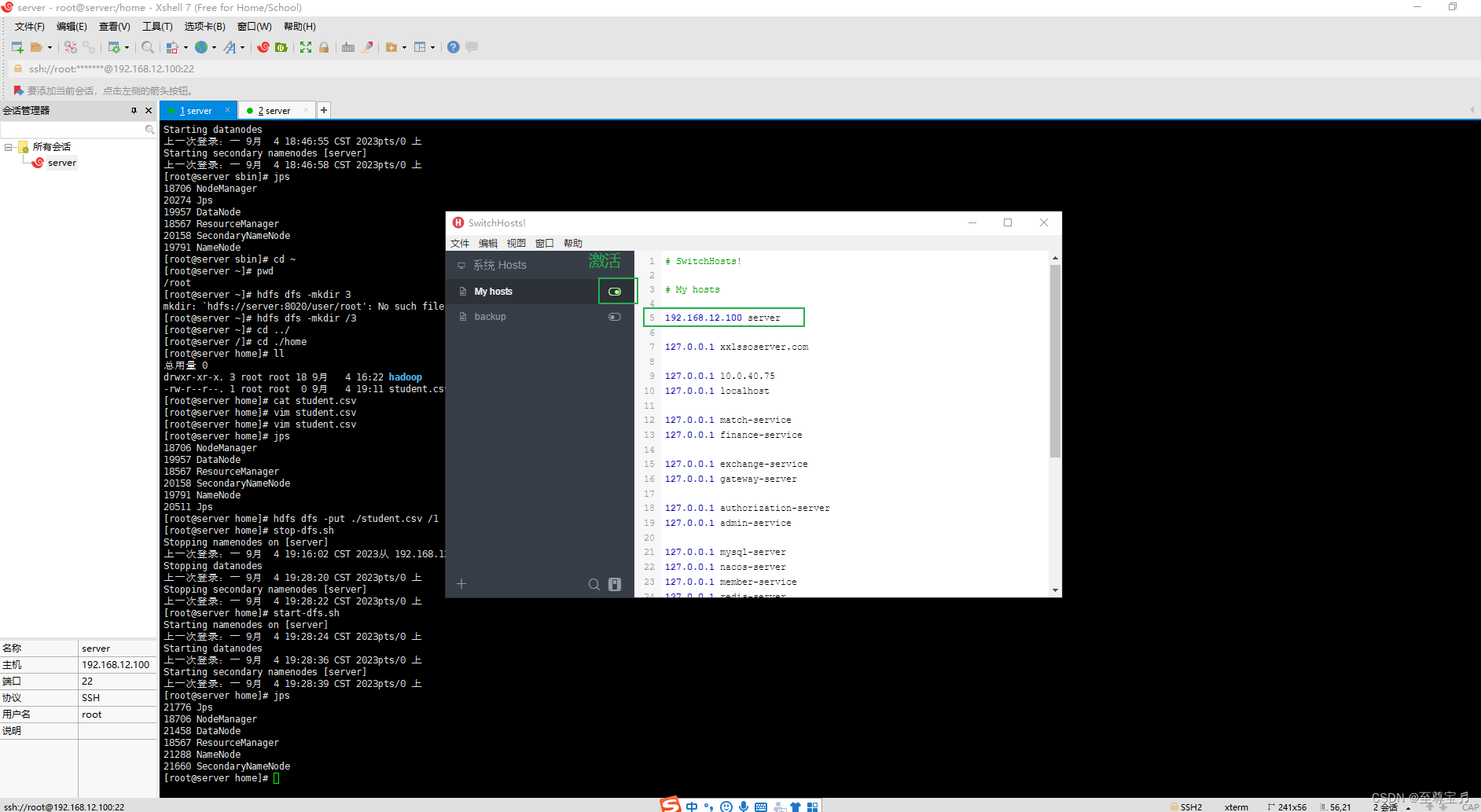
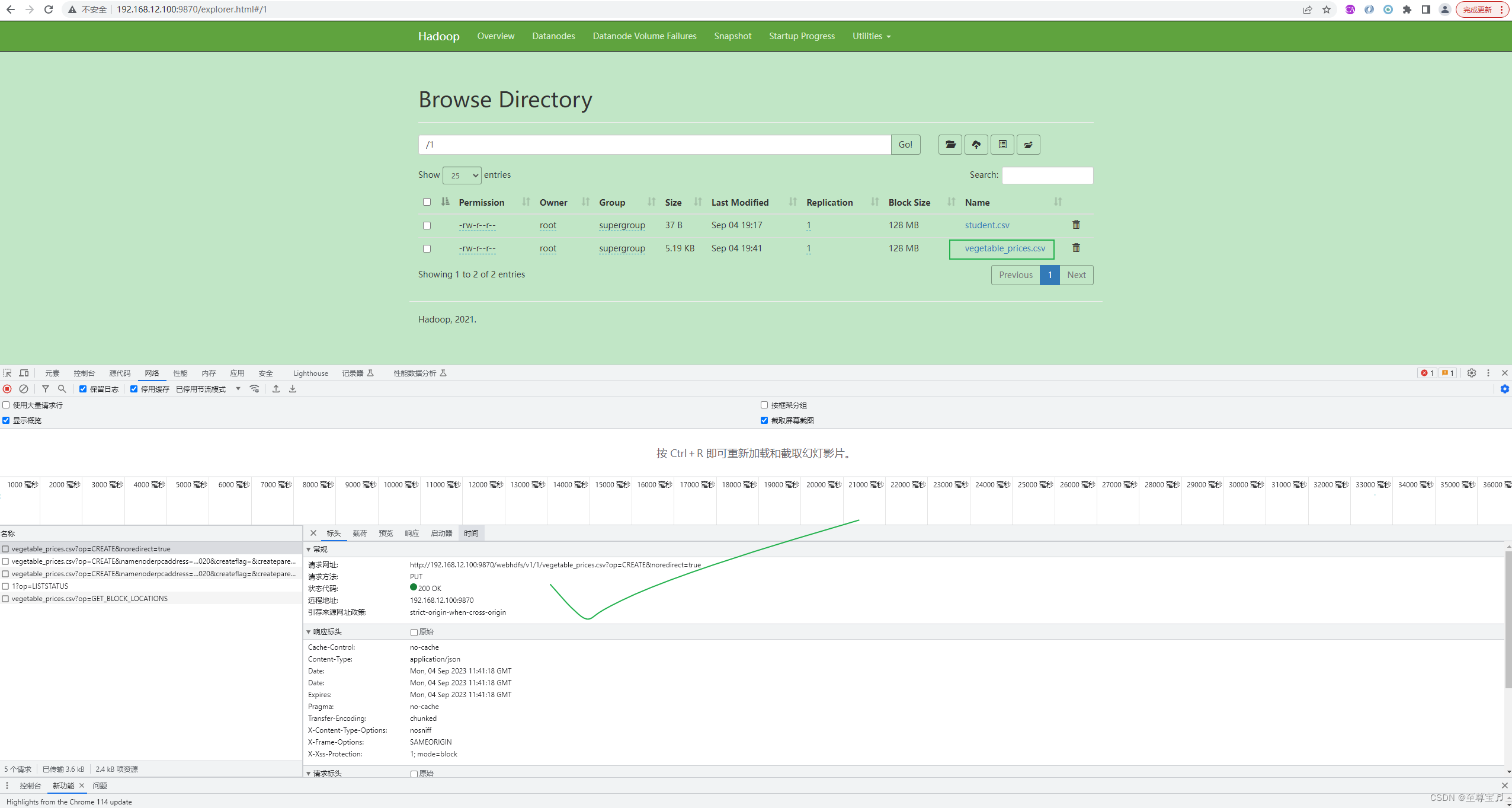
解决方法:
在本地win10配置host对虚拟机地址的访问;
192.168.12.100 server
版权归原作者 至尊宝♬ 所有, 如有侵权,请联系我们删除。