
背景:需求是这样的,原始文件是txt文件(每天300个文件),最终想要的结果是每天将txt中的数据加载到es中,开始的想法是通过logstash加载数据到es中,但是对logstash不太熟悉,不知道怎么讲程序弄成读取一个txt文件到es中以后,就将这个txt原始文件备份并且删除掉,然后就想到了通过一个中间件来做,Python读取成功一个txt文件,并且加载到kafka中以后,就将这个txt文件备份然后删除掉原始文件。
第一步:向kafka中添加数据,我用Python连接kafka集群,向其中加载数据
# -*- coding: utf-8-*-import json
import json
import msgpack
from loguru import logger
from kafka import KafkaProducer
from kafka.errors import KafkaError
def kfk_produce_1():"""
发送 json 格式数据
:return:"""
producer =KafkaProducer(
bootstrap_servers='192.168.85.109:9092',
value_serializer=lambda v: json.dumps(v).encode('utf-8'))
#logstash-topic-one
#producer.send('python_test_topic',{'key':'value'})
producer.send('logstash-topic-one',{'name':'value'})kfk_produce_1()
执行完的结果,来界面工具上看,显示这样,说明数据已经加载进来了
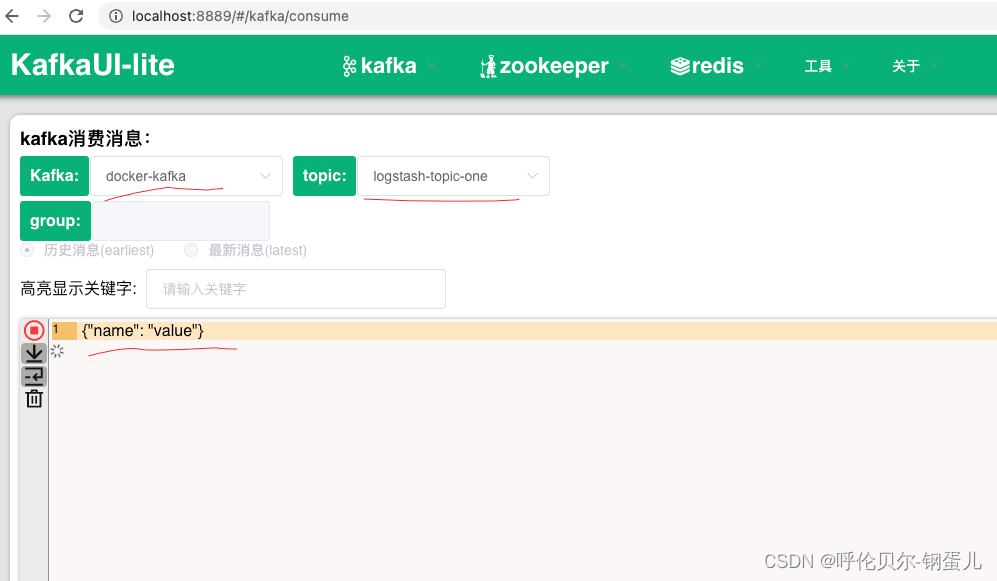
第二步:配置logstash,将kafka中的数据加载到es集群中
编写的logstash.conf配置如下;
input{
kafka{bootstrap_servers=>"192.168.85.109:9092"client_id=>"consumer_id"group_id=>"consumer_group"auto_offset_reset=>"latest"consumer_threads=>1decorate_events=>truetopics=>["logstash-topic-one","logstash-topic-two"]}}
output {if[@metadata][kafka][topic]=="logstash-topic-one"{
elasticsearch {hosts=>"http://192.168.85.109:9200"index=>"kafka-one-data"timeout=>300}}if[@metadata][kafka][topic]=="logstash-topic-two"{
elasticsearch {hosts=>"http://192.168.85.109:9200"index=>"kafka-two-data"timeout=>300}}
stdout {}}
第三步:执行logstash,通过kibana查看数据是否在es集群中,展示如下,则说明配置是正确的
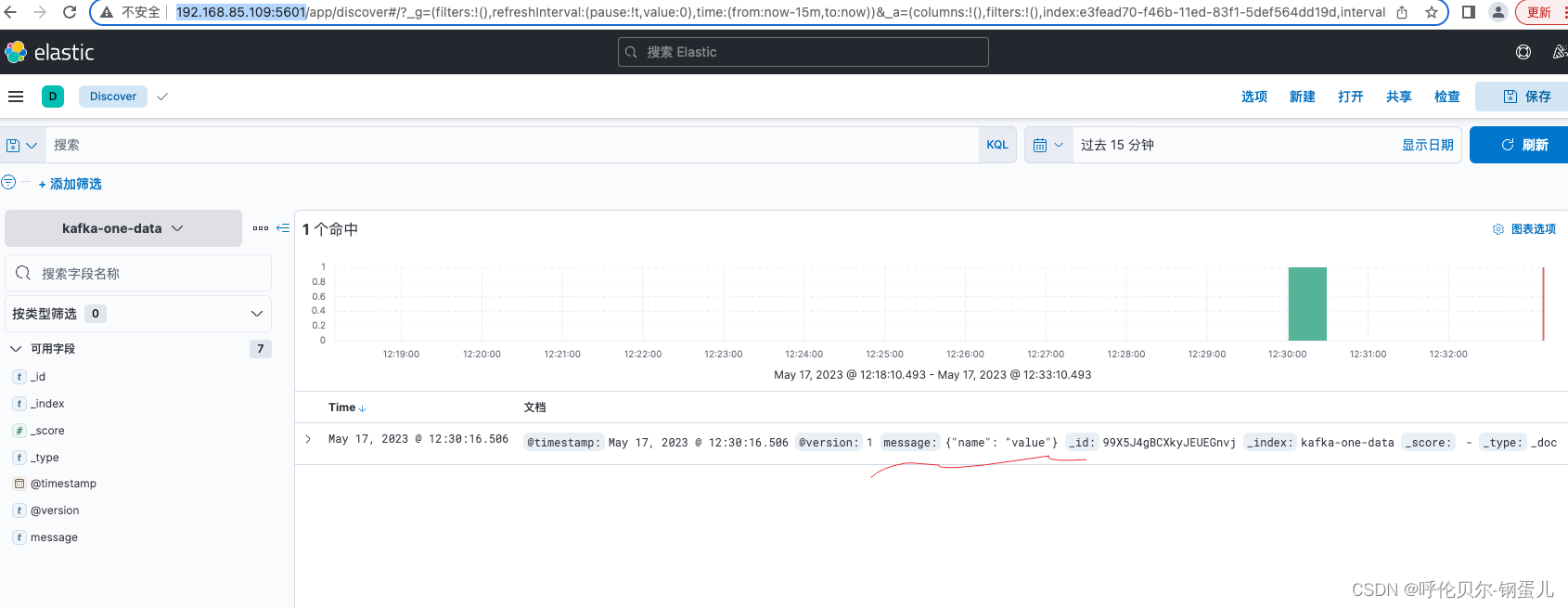
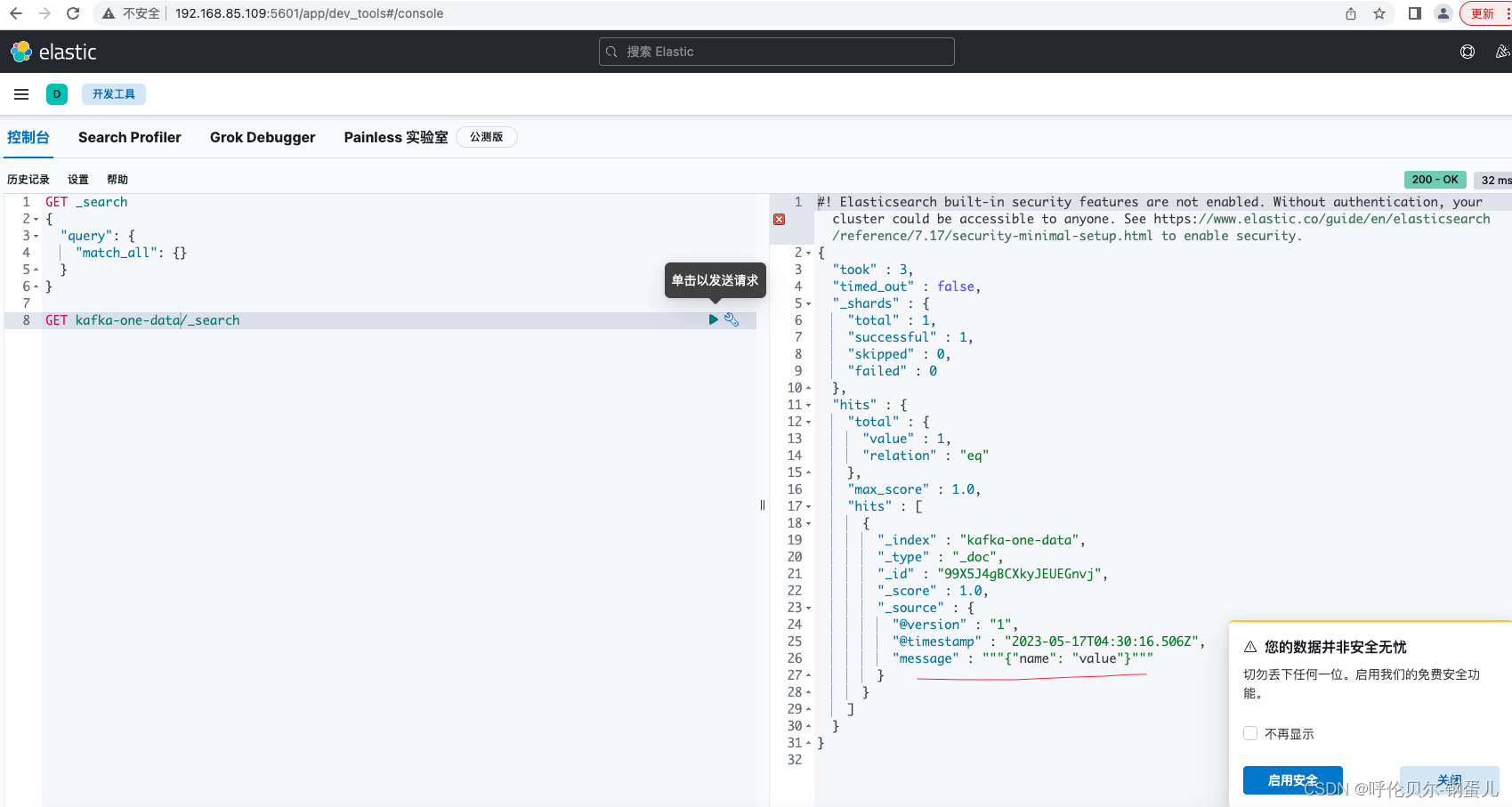
问题1:现在发现,name字段是在message下面,如果是多个字段的话,不方便查询,想着怎么讲字段从message中弄出来,修改的配置如下,增加一段这样的代码就OK了
type=>"json"codec=> json {charset=>"UTF-8"}
完整的配置文件logstash.conf代码如下;
input{
kafka{bootstrap_servers=>"192.168.85.109:9092"client_id=>"consumer_id"group_id=>"consumer_group"auto_offset_reset=>"latest"consumer_threads=>1decorate_events=>truetopics=>["logstash-topic-one","logstash-topic-two"]type=>"json"codec=> json {charset=>"UTF-8"}}}
output {if[@metadata][kafka][topic]=="logstash-topic-one"{
elasticsearch {hosts=>"http://192.168.85.109:9200"index=>"kafka-one-data"timeout=>300}}if[@metadata][kafka][topic]=="logstash-topic-two"{
elasticsearch {hosts=>"http://192.168.85.109:9200"index=>"kafka-two-data"timeout=>300}}
stdout {}}
然后我又造了一个多字段的场景如下;
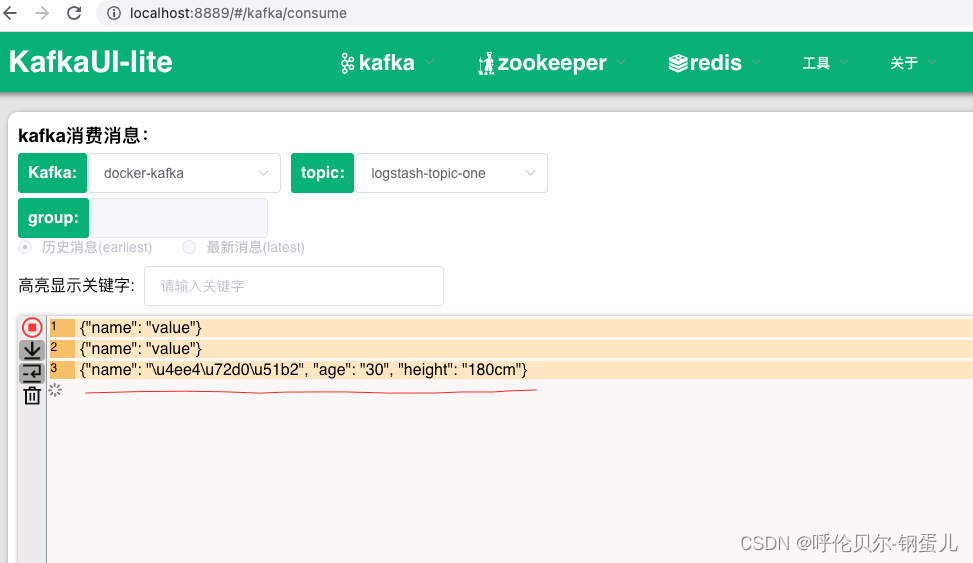
我先去logstash中查看日志如下,字段已经分离出来了
{"name"=>"value","@version"=>"1","type"=>"json","@timestamp"=>2023-05-17T06:13:48.825Z
}{"@version"=>"1","type"=>"json","@timestamp"=>2023-05-17T06:20:57.729Z,"name"=>"令狐冲","age"=>"30","height"=>"180cm"}
去kibana中去查询,显示如下,测试成功喽,😄
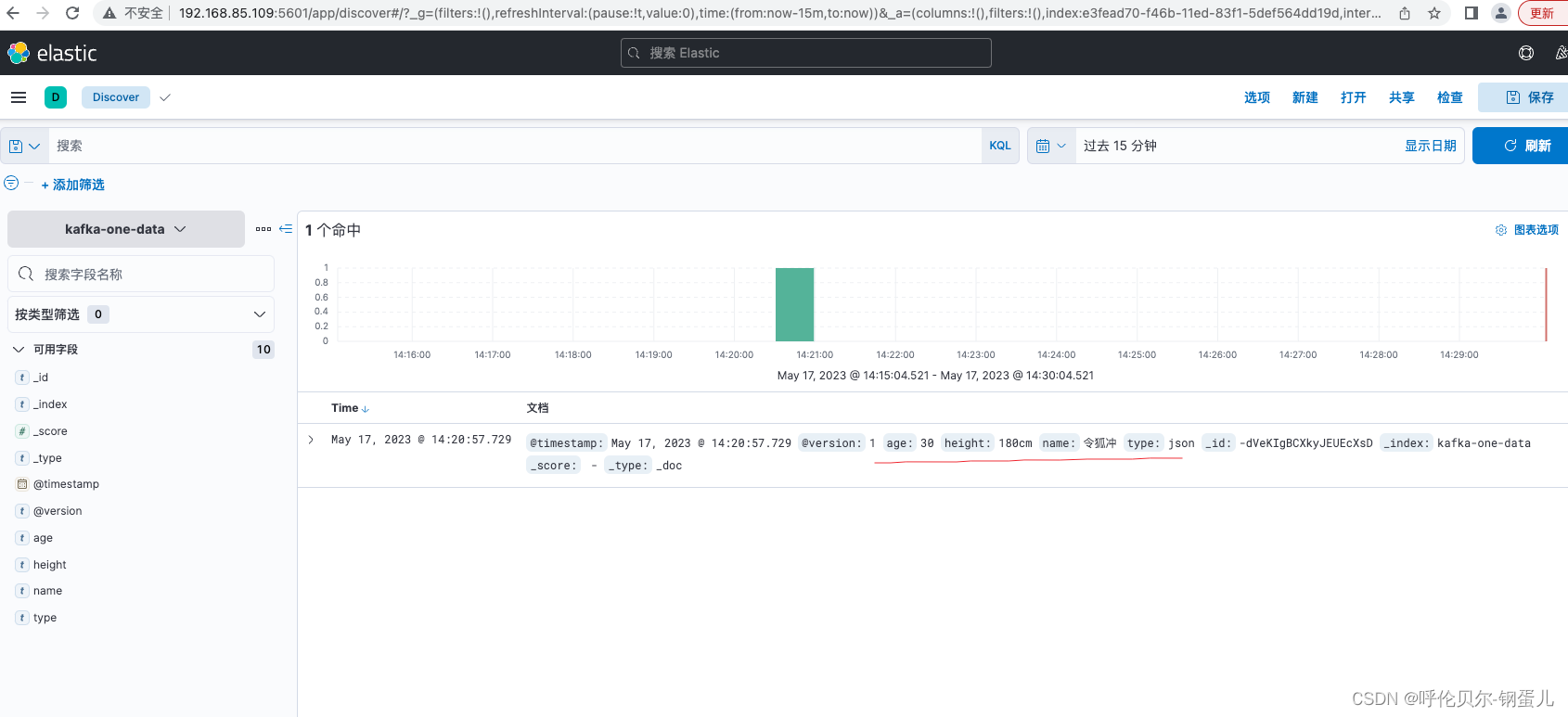
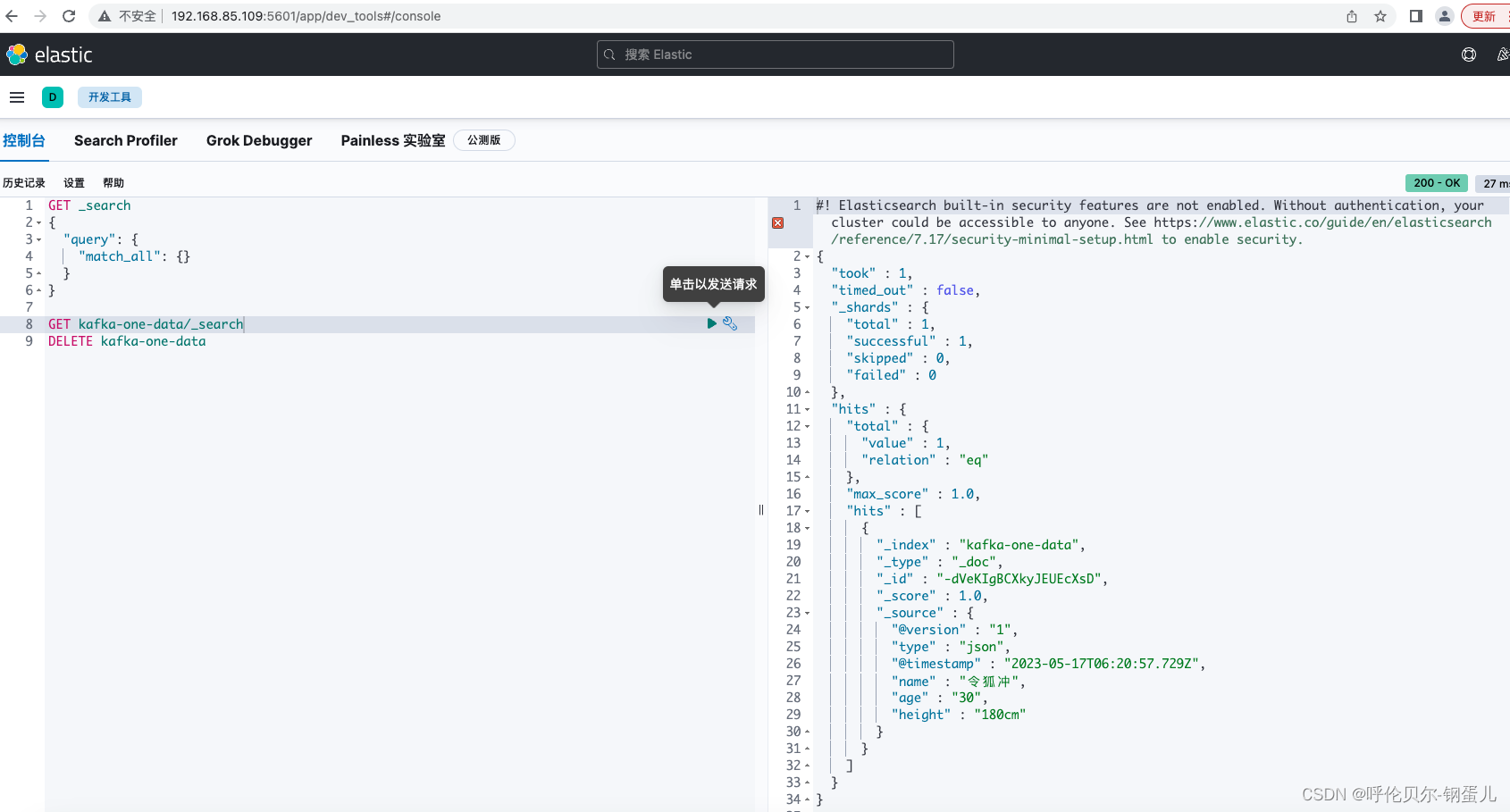
问题2:在查询结果中发现,有些字段是没有用的,看看怎么去掉?
在配置文件中增加一个过滤器就可以解决了
filter { mutate {remove_field=>["@version","@timestamp","type"] # 删除字段
}}
然后再去kibana中去查看,就发现这会儿的字段格式非常好看了,😄
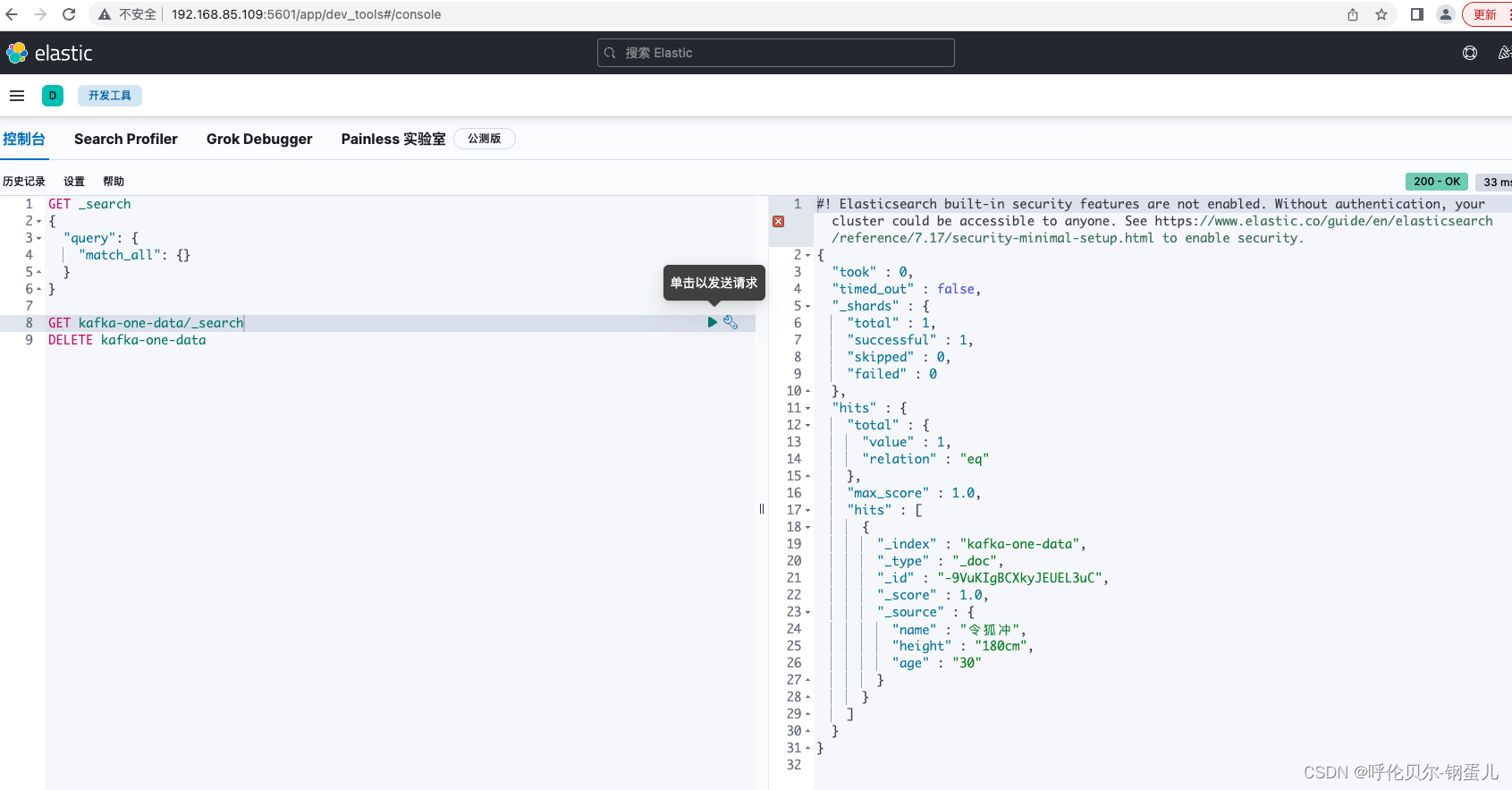
文档后续再继续完善,有好的建议或者问题可以留言交流,😄
本文转载自: https://blog.csdn.net/qq_38220334/article/details/130724262
版权归原作者 呼伦贝尔-钢蛋儿 所有, 如有侵权,请联系我们删除。
版权归原作者 呼伦贝尔-钢蛋儿 所有, 如有侵权,请联系我们删除。