
Flink系列之:Flink CDC深入了解MySQL CDC连接器
一、增量快照特性
1.增量快照读取
增量快照读取是一种读取表快照的新机制。与旧的快照机制相比,增量快照具有许多优点,包括:
- (1)在快照读取期间,Source 支持并发读取
- (2)在快照读取期间,Source 支持进行 chunk 粒度的 checkpoint
- (3)在快照读取之前,Source 不需要数据库锁权限。
- 如果希望 source 并行运行,则每个并行 reader 都应该具有唯一的 server id,因此server id的范围必须类似于 5400-6400, 且范围必须大于并行度。
- 在增量快照读取过程中,MySQL CDC Source 首先通过表的主键将表划分成多个块(chunk), 然后 MySQL CDC Source 将多个块分配给多个 reader 以并行读取表的数据。
- 为每个 Reader 设置不同的 Server id
- 每个用于读取 binlog 的 MySQL 数据库客户端都应该有一个唯一的 id,称为 Server id。
- MySQL 服务器将使用此 id 来维护网络连接和 binlog 位置。 因此,如果不同的作业共享相同的 Server id, 则可能导致从错误的 binlog 位置读取数据。
- 因此,建议通过为每个 Reader 设置不同的 Server id SQL Hints, 假设 Source 并行度为 4, 我们可以使用 SELECT * FROM source_table /*+ OPTIONS(‘server-id’=‘5401-5404’) */ ; 来为 4 个 Source readers 中的每一个分配唯一的 Server id。
2.并发读取
增量快照读取提供了并行读取快照数据的能力。 你可以通过设置作业并行度的方式来控制 Source 的并行度 parallelism.default。
Flink SQL> SET 'parallelism.default'=8;
3.全量阶段支持 checkpoint
增量快照读取提供了在区块级别执行检查点的能力。它使用新的快照读取机制解决了以前版本中的检查点超时问题。
4.无锁算法
MySQL CDC source 使用 增量快照算法, 避免了数据库锁的使用,因此不需要 “RELOAD” 权限。
5.MySQL高可用性支持
mysql cdc 连接器通过使用 GTID 提供 MySQL 高可用集群的高可用性信息。为了获得高可用性, MySQL集群需要启用 GTID 模式,MySQL 配置文件中的 GTID 模式应该包含以下设置
gtid_mode =on
enforce_gtid_consistency =on
如果监控的MySQL服务器地址包含从实例,则需要对MySQL配置文件设置以下设置。设置 log slave updates=1 允许从实例也将从主实例同步的数据写入其binlog, 这确保了mysql cdc连接器可以使用从实例中的全部数据。
gtid_mode =on
enforce_gtid_consistency =on
log-slave-updates =1
MySQL 集群中你监控的服务器出现故障后, 你只需将受监视的服务器地址更改为其他可用服务器,然后从最新的检查点/保存点重新启动作业, 作业将从 checkpoint/savepoint 恢复,不会丢失任何记录。
建议为 MySQL 集群配置 DNS(域名服务)或 VIP(虚拟 IP 地址), 使用mysql cdc连接器的 DNS 或 VIP 地址, DNS或VIP将自动将网络请求路由到活动MySQL服务器。 这样,你就不再需要修改地址和重新启动管道。
二、增量快照读取的工作原理
- 当 MySQL CDC Source 启动时,它并行读取表的快照,然后以单并行度的方式读取表的 binlog。
- 在快照阶段,根据表的主键和表行的大小将快照切割成多个快照块。 快照块被分配给多个快照读取器。每个快照读取器使用 区块读取算法 并将读取的数据发送到下游。 Source 会管理块的进程状态(完成或未完成),因此快照阶段的 Source 可以支持块级别的 checkpoint。 如果发生故障,可以恢复 Source 并继续从最后完成的块中读取块。
- 所有快照块完成后,Source 将继续在单个任务中读取 binlog。 为了保证快照记录和 binlog 记录的全局数据顺序,binlog reader 将开始读取数据直到快照块完成后并有一个完整的 checkpoint,以确保所有快照数据已被下游消费。 binlog reader 在状态中跟踪所使用的 binlog 位置,因此 binlog 阶段的 Source 可以支持行级别的 checkpoint。
- Flink 定期为 Source 执行 checkpoint,在故障转移的情况下,作业将重新启动并从最后一个成功的 checkpoint 状态恢复,并保证只执行一次语义
三、全量阶段分片算法
- 在执行增量快照读取时,MySQL CDC source 需要一个用于分片的的算法。 MySQL CDC Source 使用主键列将表划分为多个分片(chunk)。 默认情况下,MySQL CDC source 会识别表的主键列,并使用主键中的第一列作为用作分片列。 如果表中没有主键, 增量快照读取将失败,你可以禁用 scan.incremental.snapshot.enabled 来回退到旧的快照读取机制。
对于数值和自动增量拆分列,MySQL CDC Source 按固定步长高效地拆分块。 例如,如果你有一个主键列为id的表,它是自动增量 BIGINT 类型,最小值为0,最大值为100, 和表选项 scan.incremental.snapshot.chunk.size 大小 value为25,表将被拆分为以下块:
(-∞,25),[25,50),[50,75),[75,100),[100,+∞)
对于其他主键列类型, MySQL CDC Source 将以下形式执行语句: SELECT MAX(STR_ID) AS chunk_high FROM (SELECT * FROM TestTable WHERE STR_ID > ‘uuid-001’ limit 25) 来获得每个区块的低值和高值, 分割块集如下所示:
(-∞,'uuid-001'),['uuid-001','uuid-009'),['uuid-009','uuid-abc'),['uuid-abc','uuid-def'),[uuid-def,+∞).
四、Chunk 读取算法
对于上面的示例MyTable,如果 MySQL CDC Source 并行度设置为 4,MySQL CDC Source 将在每一个 executes 运行 4 个 Readers 通过偏移信号算法 获取快照区块的最终一致输出。 偏移信号算法简单描述如下:
- (1) 将当前 binlog 位置记录为LOW偏移量
- (2) 通过执行语句读取并缓冲快照区块记录 SELECT * FROM MyTable WHERE id > chunk_low AND id <= chunk_high
- (3) 将当前 binlog 位置记录为HIGH偏移量
- (4) 从LOW偏移量到HIGH偏移量读取属于快照区块的 binlog 记录
- (5) 将读取的 binlog 记录向上插入缓冲区块记录,并发出缓冲区中的所有记录作为快照区块的最终输出(全部作为插入记录)
- (6) 继续读取并发出属于 单个 binlog reader 中HIGH偏移量之后的区块的 binlog 记录。
注意: 如果主键的实际值在其范围内分布不均匀,则在增量快照读取时可能会导致任务不平衡。
五、Exactly-Once 处理
- MySQL CDC 连接器是一个 Flink Source 连接器,它将首先读取表快照块,然后继续读取 binlog, 无论是在快照阶段还是读取 binlog 阶段,MySQL CDC 连接器都会在处理时准确读取数据,即使任务出现了故障。
六、MySQL心跳事件支持
- 如果表不经常更新,则 binlog 文件或 GTID 集可能已在其最后提交的 binlog 位置被清理。 在这种情况下,CDC 作业可能会重新启动失败。因此心跳事件将帮助更新 binlog 位置。 默认情况下,MySQL CDC Source 启用心跳事件,间隔设置为30秒。 可以使用表选项heartbeat指定间隔。或将选项设置为0s以禁用心跳事件。
七、启动模式
配置选项scan.startup.mode指定 MySQL CDC 使用者的启动模式。有效枚举包括:
- initial (默认):在第一次启动时对受监视的数据库表执行初始快照,并继续读取最新的 binlog。
- earliest-offset:跳过快照阶段,从可读取的最早 binlog 位点开始读取
- latest-offset:首次启动时,从不对受监视的数据库表执行快照, 连接器仅从 binlog 的结尾处开始读取,这意味着连接器只能读取在连接器启动之后的数据更改。
- specific-offset:跳过快照阶段,从指定的 binlog 位点开始读取。位点可通过 binlog 文件名和位置指定,或者在 GTID 在集群上启用时通过 GTID 集合指定。
- timestamp:跳过快照阶段,从指定的时间戳开始读取 binlog 事件。
使用 DataStream API:
MySQLSource.builder().startupOptions(StartupOptions.earliest())// 从最早位点启动.startupOptions(StartupOptions.latest())// 从最晚位点启动.startupOptions(StartupOptions.specificOffset("mysql-bin.000003",4L)// 从指定 binlog 文件名和位置启动.startupOptions(StartupOptions.specificOffset("24DA167-0C0C-11E8-8442-00059A3C7B00:1-19"))// 从 GTID 集合启动.startupOptions(StartupOptions.timestamp(1667232000000L)// 从时间戳启动....build()
使用 SQL:
CREATETABLE mysql_source (...)WITH('connector'='mysql-cdc','scan.startup.mode'='earliest-offset',-- 从最早位点启动'scan.startup.mode'='latest-offset',-- 从最晚位点启动'scan.startup.mode'='specific-offset',-- 从特定位点启动'scan.startup.mode'='timestamp',-- 从特定位点启动'scan.startup.specific-offset.file'='mysql-bin.000003',-- 在特定位点启动模式下指定 binlog 文件名'scan.startup.specific-offset.pos'='4',-- 在特定位点启动模式下指定 binlog 位置'scan.startup.specific-offset.gtid-set'='24DA167-0C0C-11E8-8442-00059A3C7B00:1-19',-- 在特定位点启动模式下指定 GTID 集合'scan.startup.timestamp-millis'='1667232000000'-- 在时间戳启动模式下指定启动时间戳...)
注意:
- MySQL source 会在 checkpoint 时将当前位点以 INFO 级别打印到日志中,日志前缀为 “Binlog offset on checkpoint {checkpoint-id}”。 该日志可以帮助将作业从某个 checkpoint 的位点开始启动的场景。
- 如果捕获变更的表曾经发生过表结构变化,从最早位点、特定位点或时间戳启动可能会发生错误,因为 Debezium 读取器会在内部保存当前的最新表结构,结构不匹配的早期数据无法被正确解析。
八、DataStream Source
import org.apache.flink.api.common.eventtime.WatermarkStrategy;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;import com.ververica.cdc.connectors.mysql.source.MySqlSource;public class MySqlSourceExample {
public static void main(String[] args) throws Exception {
MySqlSource<String> mySqlSource = MySqlSource.<String>builder().hostname("yourHostname").port(yourPort).databaseList("yourDatabaseName")// 设置捕获的数据库, 如果需要同步整个数据库,请将 tableList 设置为 ".*"..tableList("yourDatabaseName.yourTableName")// 设置捕获的表.username("yourUsername").password("yourPassword").deserializer(new JsonDebeziumDeserializationSchema())// 将 SourceRecord 转换为 JSON 字符串.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置 3s 的 checkpoint 间隔
env.enableCheckpointing(3000);
env
.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(),"MySQL Source")// 设置 source 节点的并行度为 4.setParallelism(4).print().setParallelism(1);// 设置 sink 节点并行度为 1
env.execute("Print MySQL Snapshot + Binlog");
}
}
九、动态加表
扫描新添加的表功能使你可以添加新表到正在运行的作业中,新添加的表将首先读取其快照数据,然后自动读取其变更日志。
想象一下这个场景:一开始, Flink 作业监控表 [product, user, address], 但几天后,我们希望这个作业还可以监控表 [order, custom],这些表包含历史数据,我们需要作业仍然可以复用作业的已有状态,动态加表功能可以优雅地解决此问题。
以下操作显示了如何启用此功能来解决上述场景。 使用现有的 Flink CDC Source 作业,如下:
MySqlSource<String> mySqlSource = MySqlSource.<String>builder().hostname("yourHostname").port(yourPort).scanNewlyAddedTableEnabled(true)// 启用扫描新添加的表功能.databaseList("db")// 设置捕获的数据库.tableList("db.product, db.user, db.address")// 设置捕获的表 [product, user, address].username("yourUsername").password("yourPassword").deserializer(new JsonDebeziumDeserializationSchema())// 将 SourceRecord 转换为 JSON 字符串.build();// 你的业务代码
如果我们想添加新表 [order, custom] 对于现有的 Flink 作业,只需更新 tableList() 将新增表 [order, custom] 加入并从已有的 savepoint 恢复作业。
Step 1: 使用 savepoint 停止现有的 Flink 作业。
$ ./bin/flink stop $Existing_Flink_JOB_ID
Suspending job "cca7bc1061d61cf15238e92312c2fc20"with a savepoint.Savepoint completed. Path: file:/tmp/flink-savepoints/savepoint-cca7bc-bb1e257f0dab
Step 2: 更新现有 Flink 作业的表列表选项。
更新 tableList() 参数.
编译更新后的作业,示例如下:
MySqlSource<String> mySqlSource =MySqlSource.<String>builder().hostname("yourHostname").port(yourPort).scanNewlyAddedTableEnabled(true).databaseList("db").tableList("db.product, db.user, db.address, db.order, db.custom")// 设置捕获的表 [product, user, address ,order, custom].username("yourUsername").password("yourPassword").deserializer(newJsonDebeziumDeserializationSchema())// 将 SourceRecord 转换为 JSON 字符串.build();// 你的业务代码
Step 3: 从 savepoint 还原更新后的 Flink 作业。
$ ./bin/flink run \
--detached \
--fromSavepoint /tmp/flink-savepoints/savepoint-cca7bc-bb1e257f0dab \
./FlinkCDCExample.jar
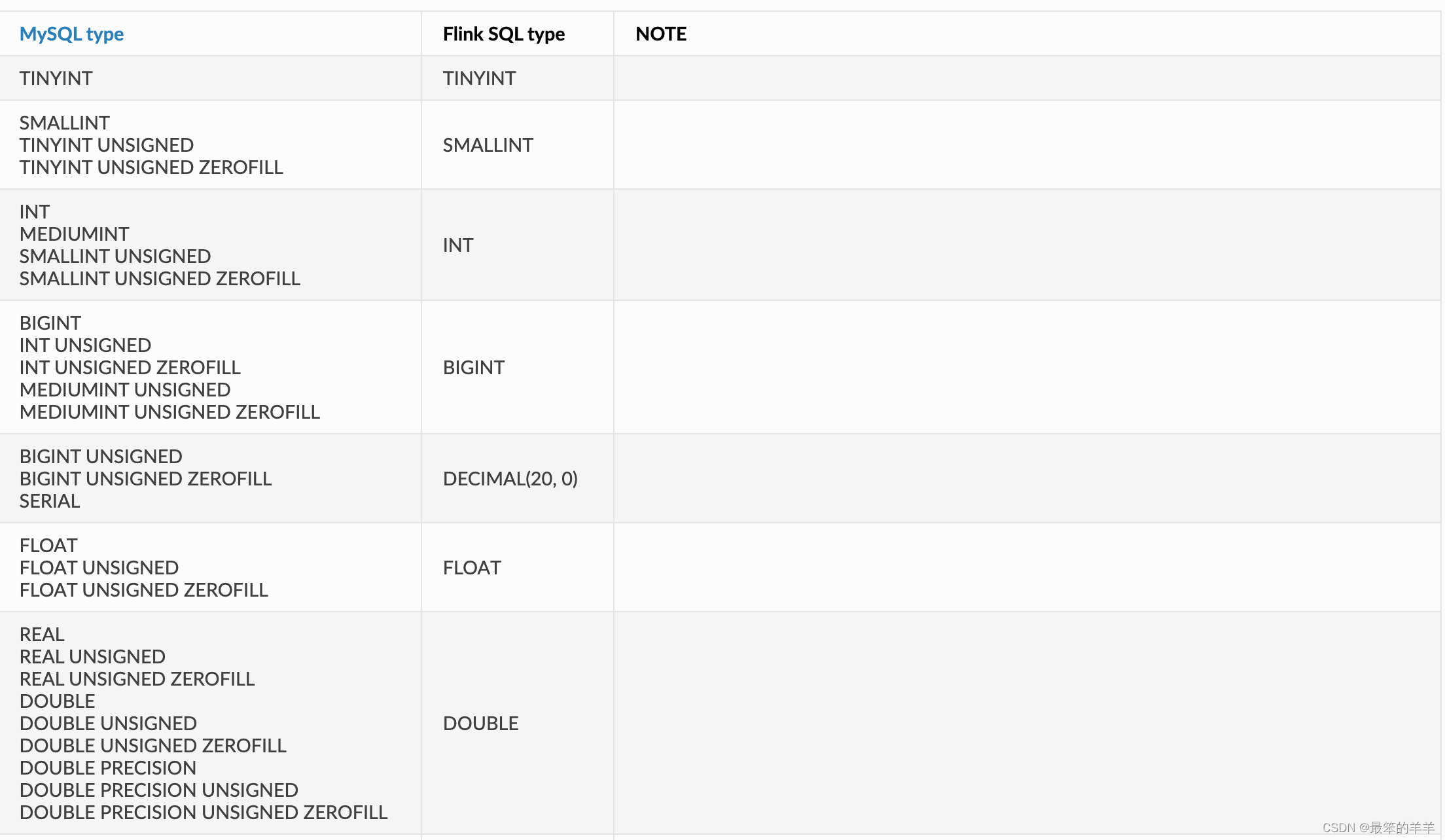
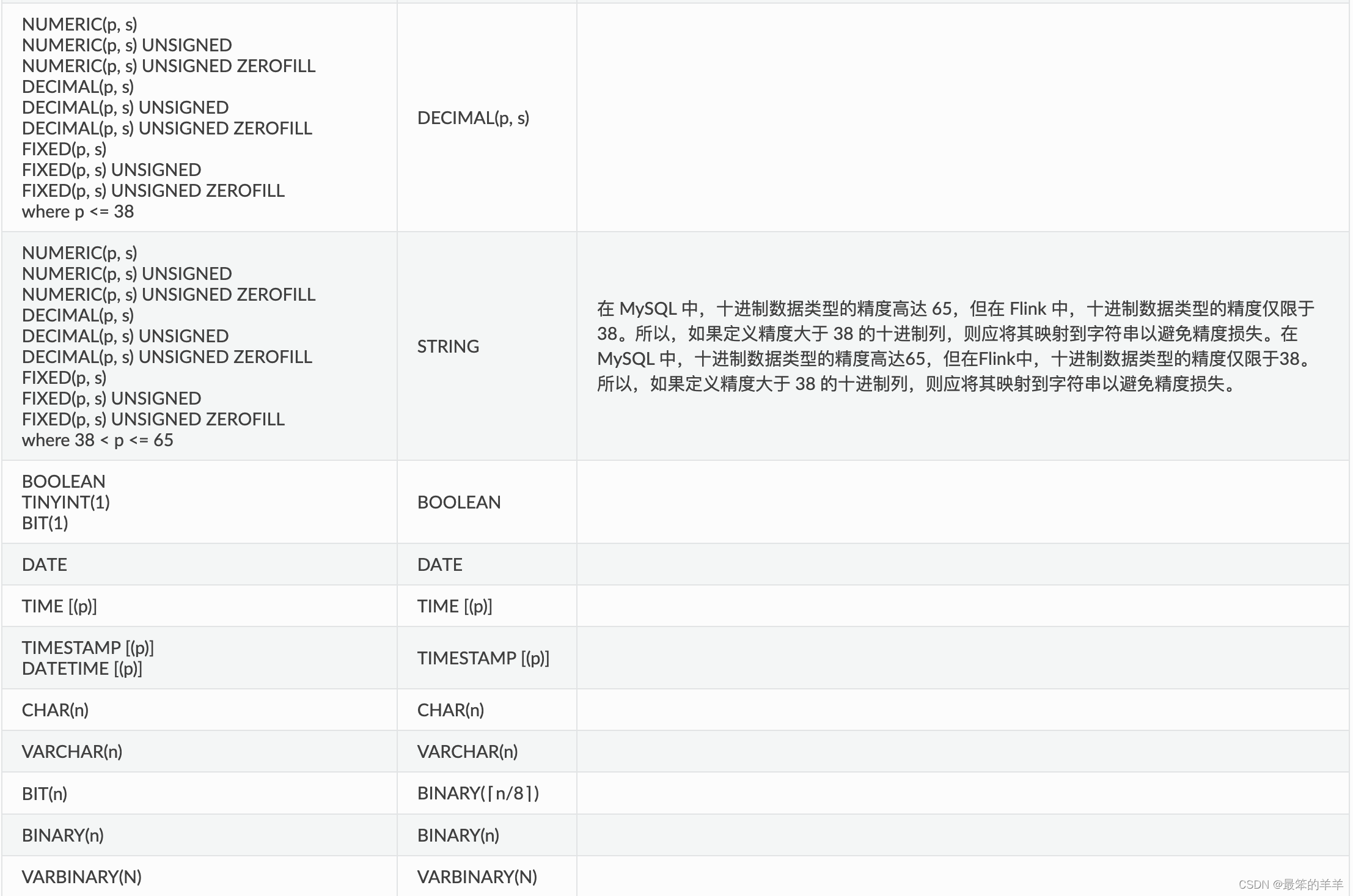
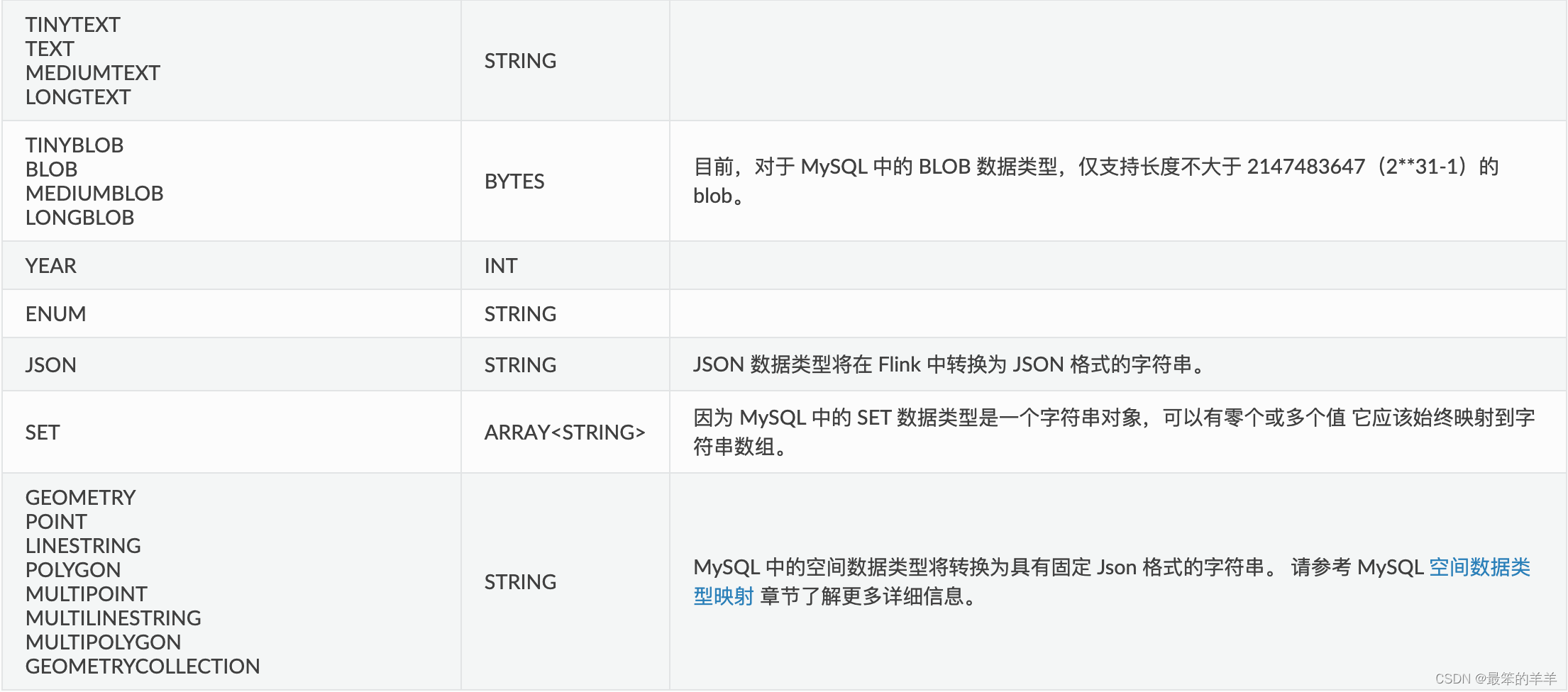
十、数据类型映射
版权归原作者 最笨的羊羊 所有, 如有侵权,请联系我们删除。