
本“大数据技术”专题的文章基于B站“黑马程序员”的大数据技术系列课程(强推!黑马的课易懂且全面),作为自用的复习笔记。
大家有需要也可以作为参考,但是由于刚入门大数据并且刚开始写博客,很多地方可能会缺乏一些细节或者存在一些问题,欢迎大家提出宝贵的建议和意见。
为什么需要分布式存储
单台服务器承担不了大文件
对于很大的文件,单台服务器无法承担。
因此可以使用多台服务器,靠数量取胜。具体来说,可以把文件划分成多个部分,存在多个服务器里。

分布式带来两好处
- 能存海量数据
- 性能up
分布式同样也使得性能得到了提升。
把一个文件分成三部分放到三个服务器,从而网络传输有了三倍的传输效率以及三倍的磁盘写入效率。
分布式的基础架构分析
分布式带来的问题:

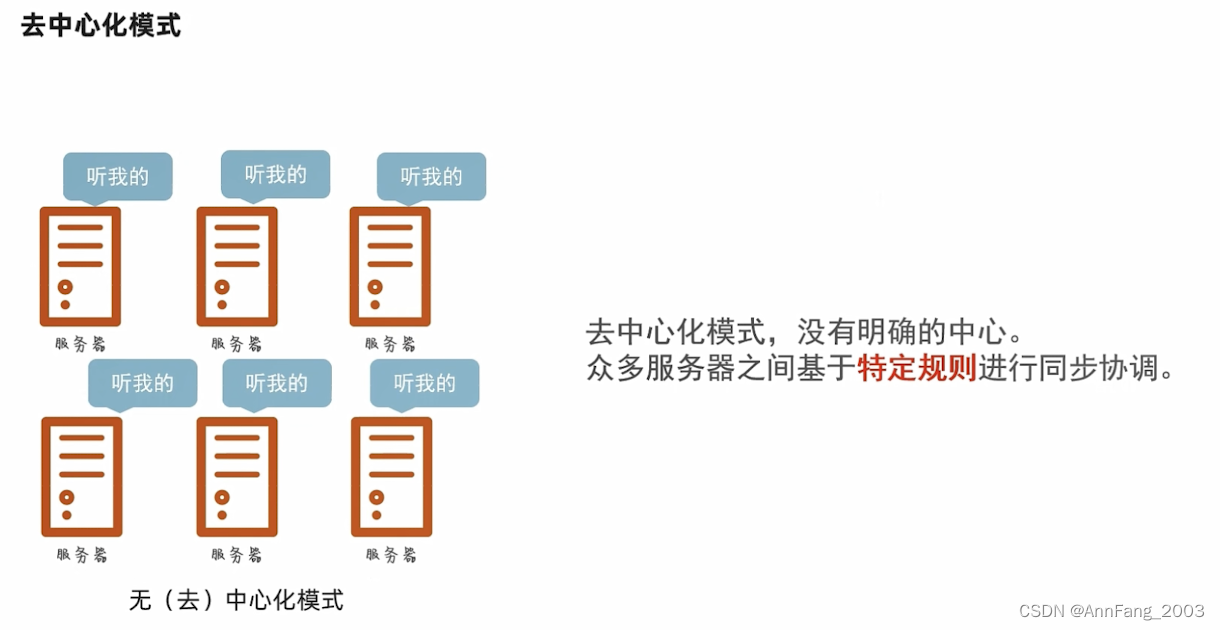
两种分布式的调度方式:
- 去中心化模式
- 中心化模式
以一个节点作为中心,去统一调度其他节点。
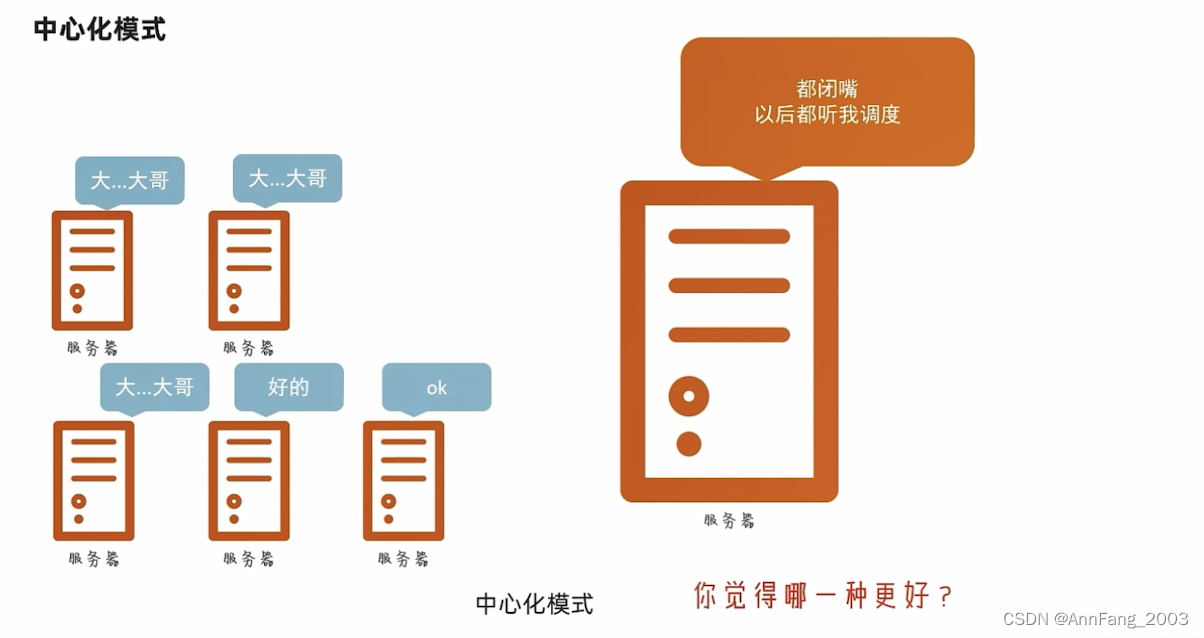
绝大数的架构都用主从模式(中心化模式):

我们学习的Hadoop框架,就是一个典型的主从模式架构的技术框架。
HDFS的基础架构
HDFS是什么
完成海量数据的存储工作

HDFS的基础架构
上面说了两种基础架构:去中心化和中心化架构。HDFS就是中心化架构。
HDFS集群有三种角色:
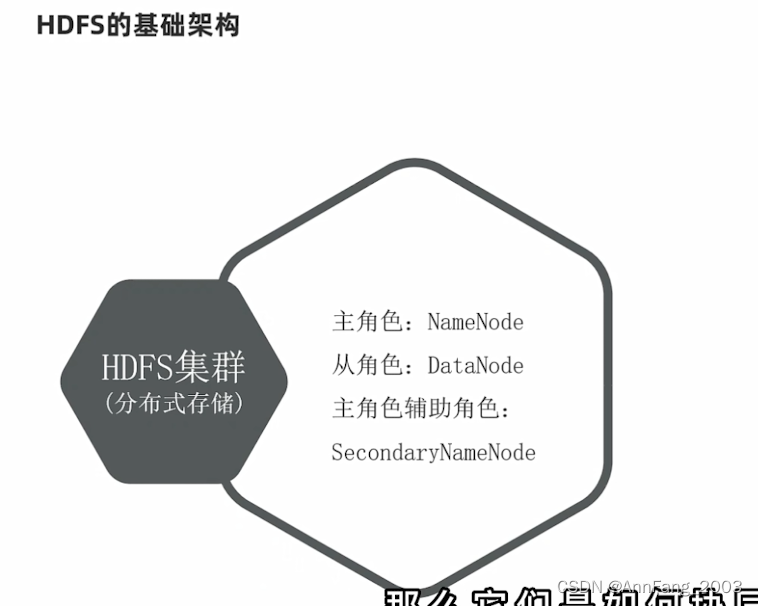
- 主角色NameNode发布命令(老板)
- 从角色Datanode根据命令干活(员工)
- SecondaryNameNode帮主角色打杂,完成一些元数据的处理(老板的秘书)

细说三个角色的作用:

HDFS集群环境部署
这部分实操,我之前已经部署完了,简单复习一下部署过程
- 下载安装包
- 由于之前已经配好了三台虚拟机(三个节点),三个节点分配的角色如下:
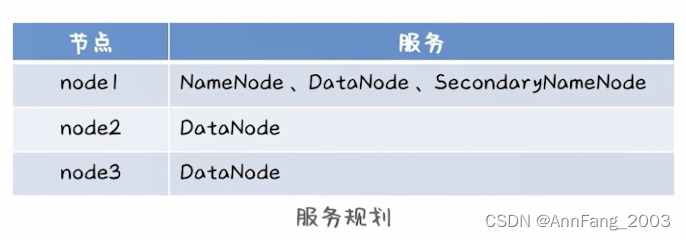
- 将安装包上传到node1中,并解压到指定路径
- 看看Hadoop文件夹的内部结构(没有实际功能,只是看看学习一下)

- 修改配置文件

- workers记录了DataNode有哪些。我们之前设立了三台虚拟机作为集群的三个节点,所以在这里就是node1~3。
- hadoop-env里配置了相关环境变量。比如JAVA_HOME(Java的安装位置),因为Hadoop是用Java开发的,所以运行过程中需要JAVA环境;
- core-site.xml文件(核心端的配置)配置了两个东西:fs.defaultFS(下面的8020是规定俗称的,如果换一个8030其实也可以但没必要)以及io.file.buffer.size,即io操作文件缓冲区大小:

- hdfs-site.xml文件配置了6个项:


- 准备数据目录

- 分发Hadoop文件夹
将node1中的Hadoop安装文件夹远程复制到node2和node3中。

- 配置环境变量
为了方便操作Hadoop,可以将一些脚本、程序配置到PATH里面,然后后续直接敲命令就可以了。
在/etc/profile里面配置(三个node都要):

- 授权为Hadoop用户
以普通用户Hadoop来启动整个Hadoop服务。(因为用root权限太大了,不安全,一般操作都不会直接用root)
以root身份,在三个节点中执行:

上面9个步骤就将集群的部署完成了,下面开始执行相关的命令来启动:
- 格式化整个文件系统
由于hdfs是一个分布式文件系统,起分布式存储的功能。所以要对这个存储系统进行初始化:

格式化成功后,可以在data/nn的文件夹里面看见出现东西了,后续会说这些东西是什么。反正这里证明格式化成功了。
- 启动HDFS
启动:在node1执行start-dfs.sh,然后就能启动namenode、datanode、secondarynamenode。

然后用jps就能显示这三个进程。
在node2和node3中,datanode也通过start-dfs命令被启动成功。
在namenode的9870端口可以直接查看hdfs的WEB UI。
HDFS的Shell操作
HDFS相关进程的启停管理命令
一键启停脚本:

单进程的启停:
 上面这些命令之所以可以直接用,而不用进入对应路径是因为之前在配置PATH的时候将bin和sbin都配好了,所以可以直接执行。
上面这些命令之所以可以直接用,而不用进入对应路径是因为之前在配置PATH的时候将bin和sbin都配好了,所以可以直接执行。
HDFS文件系统基础操作(命令操作、在WEBUI里操作)
HDFS文件系统的基本信息(路径表达方式)
和Linus系统一样,均以/作为根目录的组织形式。
比如:
那么如何区分我们要进入Linux的路径还是HDFS的呢?答:加上协议头。
- Linux的协议头:file://
- HDFS的协议头:hdfs://namenode:port(namenode和port要具体写,比如node1:8020)
比如:
但是真正不需要用协议头,因为写起来很麻烦。在真正操作的时候,可以省略不写:

Hadoop有2套命令体系

具体命令的学习:
- 创建文件夹
下面两个指令都OK,一个老版本一个新版本,只是开头不一样。
hadoop fs -mkdir [-p] <path>
hdfs dfs -mkdir [-p] <path>

- 查看指定目录下的内容
hadoop fs -ls [-h] [-R] [<path>...]
hdfs dfs -ls [-h] [-R] [<path>...]

- 上传文件到HDFS指定目录下
hadoop fs -put [-f] [-p] <localsrc> ... <dst>
hdfs dfs -put [-f] [-p] <localsrc> ... <dst>

例如:(注意第一个路径参数:localsrc默认就是本机,可以但没必要写file://,第二个参数dst默认是hdfs,同样没必要写hdfs://node1:8020)

- 查看HDFS文件内容:
hadoop fs -cat <src> ...
hdfs dfs -cat <src> ...
读取src的文件内容,显示在sio控制台上。大文件可以使用管道符|配合more:

more:可以对内容进行翻页(用空格来进行翻页)查看。(一直滚动会让终端奔溃)
- 下载HDFS文件(和第3个从本机传到hdfs的put命令相反,现在是从hdfs到本机)
hadoop fs -get [-f] [-p] <src> ... <localdst>
hdfs dfs -get [-f] [-p] <src> ... <localdst>
注意:localdst必须是目录

- 拷贝HDFS文件
hadoop fs -cp [-f] <src> ... <dst>
hdfs dfs -cp [-f] <src> ... <dst>
- src是hdfs里面的文件
- dst是hdfs里面的文件夹或不存在的文件(如文件不存在,则创建,并且不存在的文件可以和src的名字不一样)
其中的-f用于覆盖已存在的目标文件。
- 追加数据到HDFS文件中
hadoop fs -appendToFile <localsrc> ... <dst>
hdfs dfs -appendToFile <localsrc> ... <dst>

注意不能修改HDFS中文件的某一处,只能删/追加。
- HDFS数据移动操作
hadoop fs -mv <src> ... <dst>
hdfs dfs -mv <src> ... <dst>

- HDFS数据删除操作
hadoop fs -rm -r [-skipTrash] URI [URI ...]
hdfs dfs -rm -r [-skipTrash] URI [URI ...]
-r:删除文件夹。

上面的1440和120的单位都是分钟,1440表示保留1天,120表示2个小时检查一次。
如果回收站功能开启,执行上面-rm -r操作就相当于移动到了回收站路径,没有真正从hdfs删除。
在WEB UI操作文件系统:

补充知识:hdfs权限

HDFS客户端-Jetbrians产品插件
上面敲命令来进行操作的方式不方便,可以用图形化的工具BigDataTools。

使用NFS网关功能将HDFS挂载到本地系统
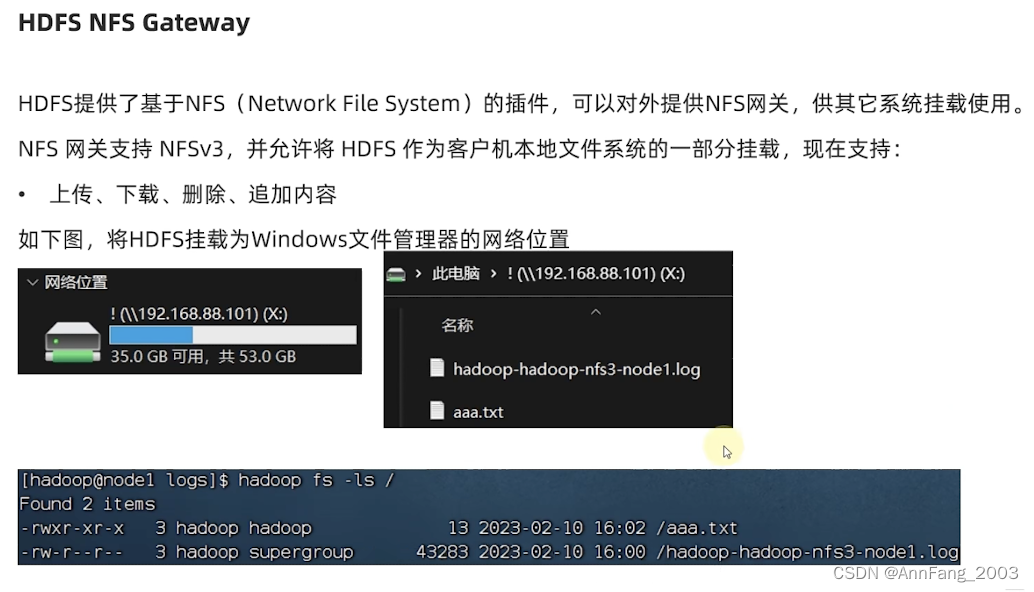
HDFS的存储原理
存储原理
如何存储数据(分布式存储)
一个大文件如何在多台服务器存储呢?答:如果有三台服务器,则将文件分为三份,并各自存到服务器中: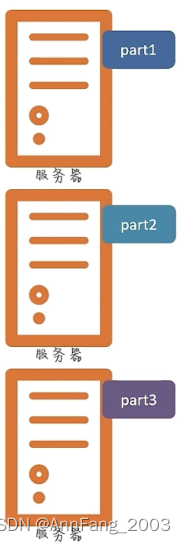
那么如何从服务器取回来呢?答:从三台服务器取出每个part,然后组装回去。
引出分布式存储的概念:每个服务器(节点)存储文件的一部分。
多个文件的存储:
假设有多个文件,大小不一。还是划分为三部分。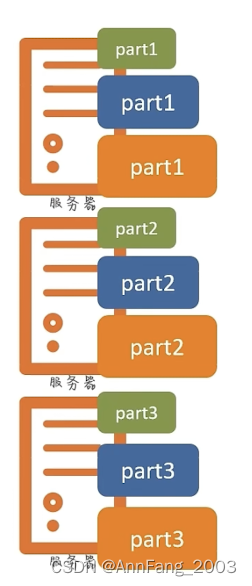
block(块)的引出:
但是这样导致一个问题:文件大小不一,不利于统一管理。
所以要划分为统一的单位:block 块。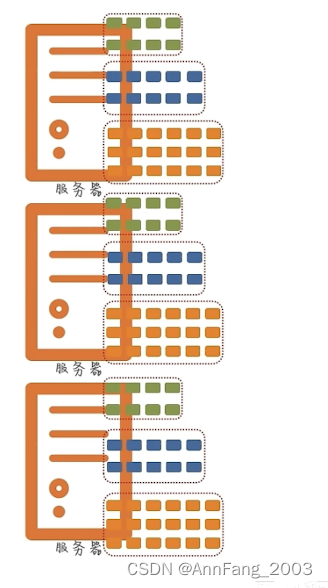

块丢失存在的问题:
但是如果某个块丢失了,这个文件就还原不了了。并且block越多,损坏的几率越大。
解决块丢失的方案:
准备多个副本来备份。(备份放在其他的服务器上)

fsck命令
HDFS副本块数量的配置
方式一:在hdfs-site.xml中配置如下属性:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>

方式二:

方式三:

用fsck命令检查文件的副本数
fsck=file system check
hdfs fsck path [-files[-blocks[-locations]]]

block配置

NameNode元数据
namenode如何管理block
namenode能基于一批edits文件和一个fsimage文件来管理block。
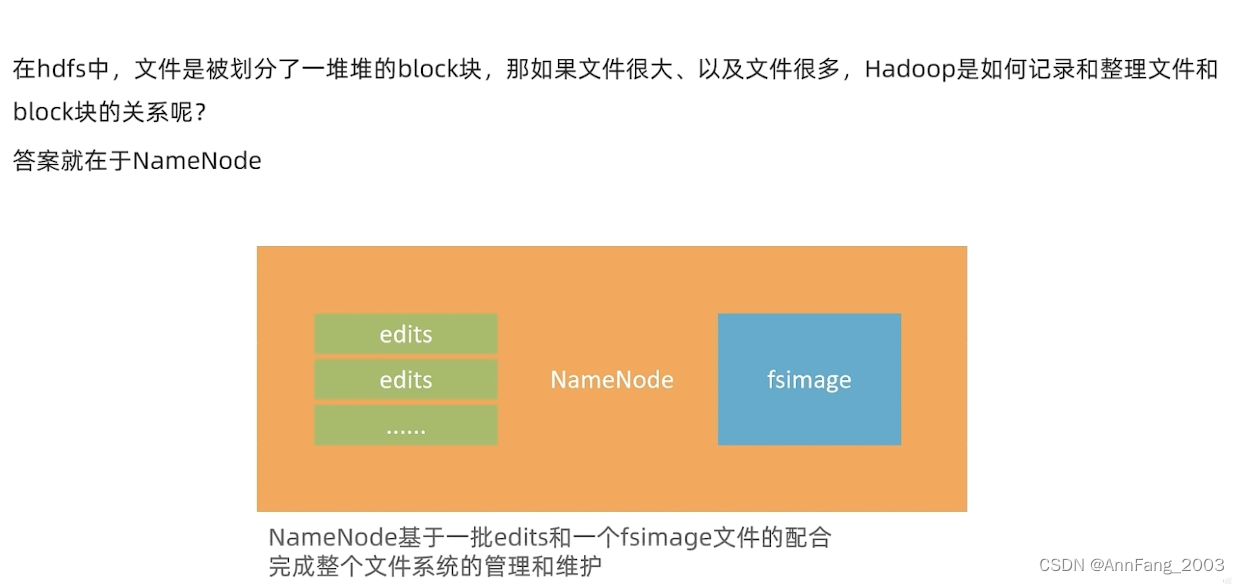
edits文件
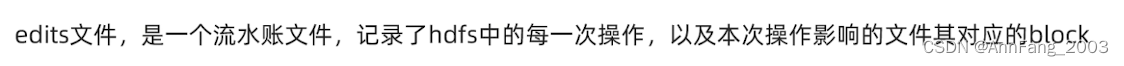

但是随着每次操作的记录,edits文件会越来越大,为了避免超大的edits文件:

fsimage文件
那么即使有了多个edits文件,也存在以下问题:

为了解决这个问题:
由于edits就是流水账,中间所有乱七八糟的操作都被记下来了。但是往往有用信息只在于“最终的状态”,中间一个个的状态对用户来说没有意义。所以要“合并”。
如何合并呢?
见下面的例子,右边等价于左边:

左边的这个记录的文件就叫fsimage。
流水账:一堆edits;
最终的结果:一个fsimage。
namenode基于这两种文件管理fs的具体流程
下图[2.]更正:上线->上限

元数据合并的控制参数

合并元数据的工作是谁做的呢?
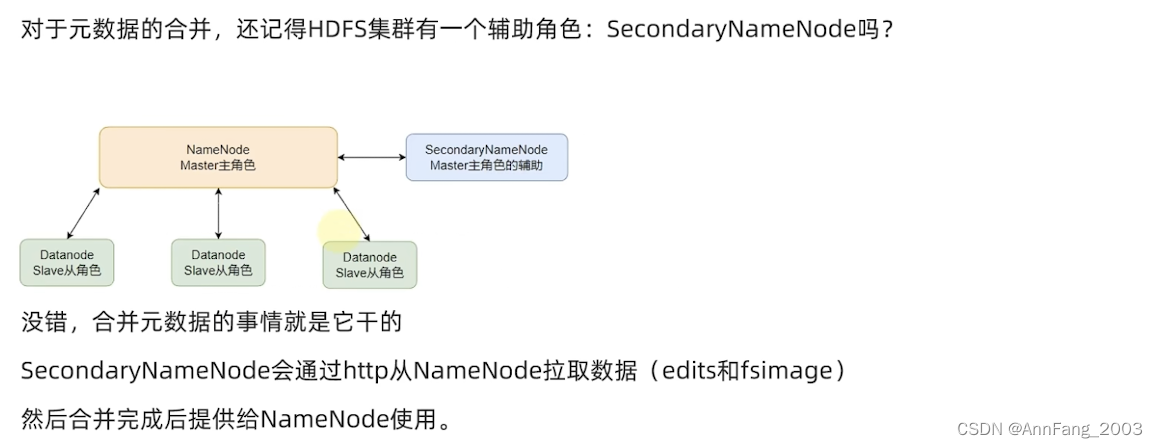
HDFS数据的读写流程
数据写入的流程
数据写入指的是从客户端写数据到hdfs里面。那么客户端是什么呢?之前用到的Hadoop fs和hdfs dfs的这些命令就是一个客户端(Linux命令构建的客户端),包括之前的Big Data Tools也是一种图形化的客户端。
数据写入流程如下:


数据读取流程

版权归原作者 AnnFang_2003 所有, 如有侵权,请联系我们删除。