
纯学渣今天自己搭建了一套,现在回顾一遍,帮自己巩固加深印象。
如果有小伙伴跟着做的话,建议图中创建各种东西名字什么的,你都保持和我一致就行,除了ip是填你自己的,这样最不容易出错,不要自己去取新名字。(都是血泪)任何问题评论留言哦
搭建:1+2一共三台虚拟机
如果你也是:vmware,cenos7,liunx。就更这往下走吧!

虚拟机准备
1.新建三台一模一样的虚拟机,软件左上角那里找一下“新建虚拟机”,无脑新建即可
2.建好之后,打开my1,不要直接登,点那个小小的“no list?”,登录root账号,然后打开终端,接下来要做的事情,简单概括:三次vi,restart,ip addr。三个虚拟机都按这个走一遍,过程中一定要细心哦!
3.输入vi /etc/sysconfig/network-scripts/ifcfg-ens33。如果是新文件无内容,那么就是搞错了,你的默认名字不叫ifcfg-ens33。这时候cd到上一层,然后输入ls -ll,看一下以“ifcfg-”开头的文件,从其中找到正确的文件。
一共修改一处,添加两处,如图所示。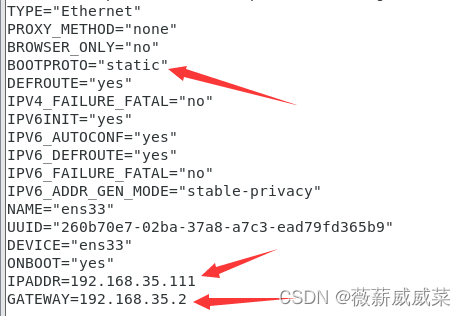
添加的两处,最后一位111,2照填,(但其实这个111也不是固定的,但是2是固定的,跟着填一样的就行!)。前三位你需要点击左上角“编辑”,”虚拟网络编辑器“,然后选择NAT模式,看一下左下角那里你自己的值是什么,然后填入。(后续教程中,我填192.168.35.111,你都填你自己的值,这里要注意!)

wq保存退出,命令行输入systemctl restart network,作用是重启网络,来使得我们的修改生效。
现在我们要看一下我们的修改生效了没,输入ip addr,如果看到是编辑时添加的IPADDR的值,那么就是生效了。
4.设置主机名,输入vi /etc/hostname。把里面原来内容删掉,输入hadoop01。
5.vi /etc/hosts。输入192.168.35.111 hadoop01,192.168.35.112 hadoop02,192.168.35.113 hadoop03,每个输入一行,一共三行
6.打开第二台虚拟机,也是root用户进去,三次编辑:
vi /etc/sysconfig/network-scripts/ifcfg-ens33,vi /etc/hostname,vi /etc/hosts 。
编辑完后:systemctl restart network,ip addr。
当然,第二台主机名叫hadoop02,112,相应修改即可
以此类推,第三台也重复一遍,第三台:hadoop03,113。
当完成到这里,我们已经实现了三台虚拟机相互都知道对方,接下来,我们就要装那些东西进去了,jdk是万物之源,安装顺序jdk,hadoop,zookeeper,spark。(想装spark必须要zookeeper,不许跳过zookeeper安装哦!)
这是我的版本图:大家也可以采用其他版本,但是这里面有兼容问题,需要留心,搭配好。

因为虚拟机里面做事不方便,我们使用Xftp+Xshell(MobaXterm也可),来进行上传文件,配置等操作。
xftp,xshell准备
7.先把三台虚拟机都连上这两个软件,都登root用户,都创建一个文件夹toolss来放软件,(这里我没有切换普通用户,直接在root里面操作,因为root里面有tools这个文件夹,所以我多加了一个s,主打不规不范,,,如果你切换到普通用户,就直接命名为tools,路径就是/home/用户名/tools)
连接好之后,去xshell,三台都输入ssh-keygen,无论出来什么,不用去看,一直按回车哟。三台都输入ssh-copy-id hadoop01,ssh-copy-id hadoop02,ssh-copy-id hadoop03,也就是一共九遍,现在我们可以在hadoop01里面输入ssh hadoop02 ,发现就就切换到02了,然后输入exit去退出。

hadoop配置
现在暂时先不管2和3,下述操作都在1中进行:
8.利用xftp把收集好的四个压缩包都传到hadoop01的toolss里面,
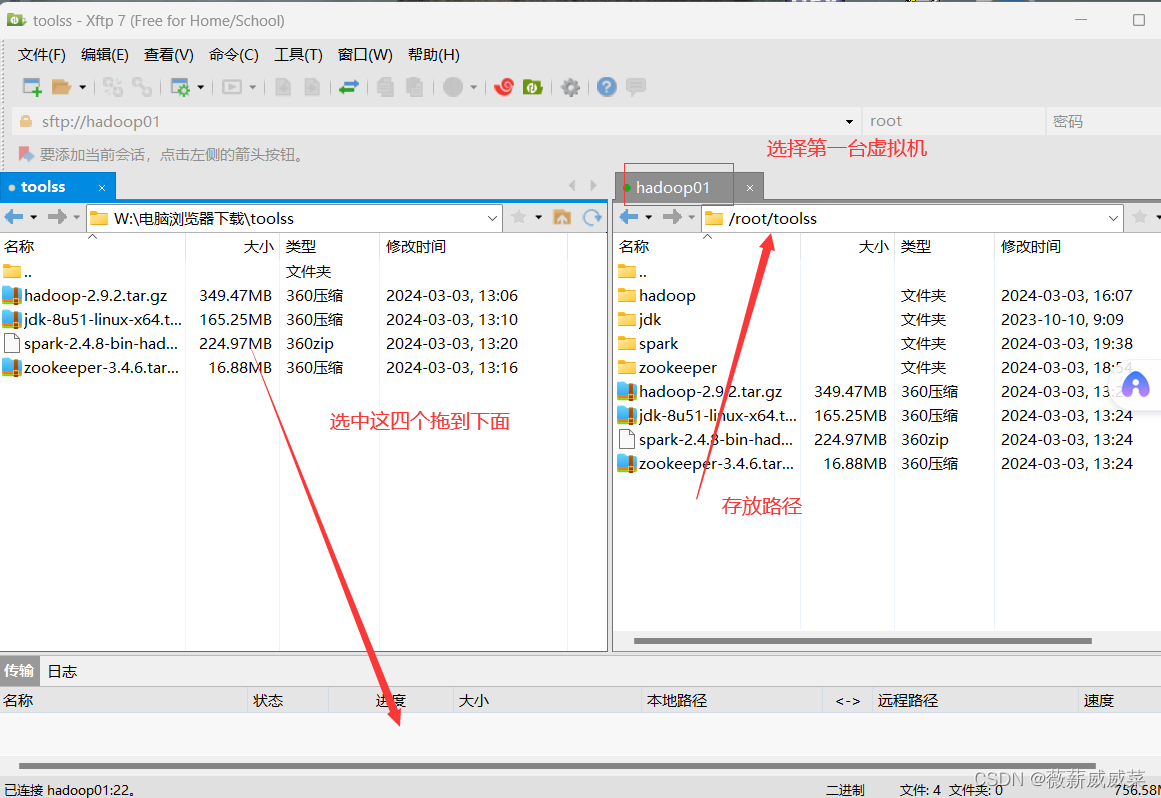
在toolss目录下输入tar -zxvf hadoop-xxx(完整报名)去解压hadoop(这里比较慢是正常的)。同样的,解压jdk,然后把这两货都用mv改成hadoop,jdk,后面用起来方便。以后也都是这样,解压后就改一下名。
9.添加系统环境变量:vi ~/.bashrc,在最下面添加图中内容:
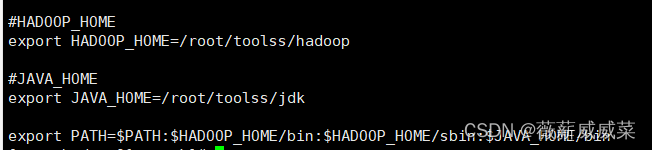
#HADOOP_HOME
export HADOOP_HOME=/root/toolss/hadoop#JAVA_HOME
export JAVA_HOME=/root/toolss/jdkexport PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin
之后,source ~/.bashrc,记住,每次修改完她都要source一下,使得其生效!
10.修改hadoop的配置文件:
cd /root/toolss/hadoop/etc/hadoop,ls,这是存放配置文件的地方。
10-1 vi hadoop-env.sh
把JAVA_HOME=后面修改为你自己的路径,即上图中的JAVA_HOME。wq保存退出
这时输入hadoop version就可以查看到我们的版本2.9.2了,(如果之前下过hadoop,那可能还会显示之前的版本,需要去调整环境变量,全集变量等,然后使生效,重启等,来解决)
10-2 vi slaves
输入hadoop02,hadoop03,每个一行,保存退出。这表明这两台是01的slaves。
10-3 vi hdfs-site.xml
添加图中内容
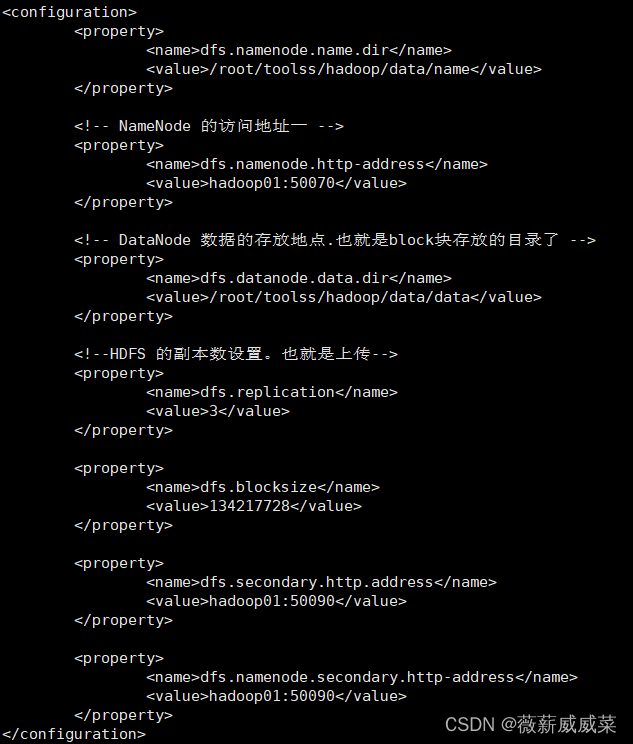
10-4 vi core-site.xml
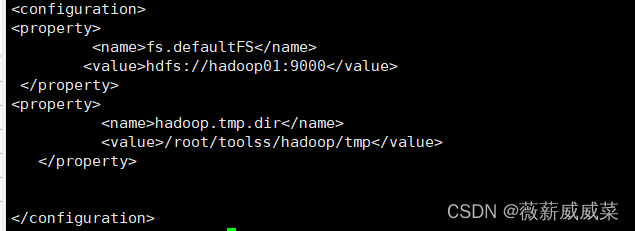
11.到这里,我们已经把hadoop01中的hadoop配置的不错了~~,接下来,我们就把配置好的传到2和3里面,2和3就也有了,scp真是个好东西。
回到上一级,tools目录,输入scp -r hadoop hadoop02:/root/toolss/。这里需等待好一会。
jdk也丢过去,scp -r jdk hadoop02:/root/toolss/。然后03也丢一份过去,一共丢四次。
12.配置文件也要丢,前面咱修改过的那个bashrc玩意,scp /.bashrc hadoop02:/
,2改成3,再来一次。(然后去 02和03中都source ~/.bashrc,因为我们修改了配置文件)。
13.三台都要操作:关闭防火墙,systemctl stop firewalld。
验证安装配置是否成功:在三台中都去输入javac,hadoop version,正常情况如下:
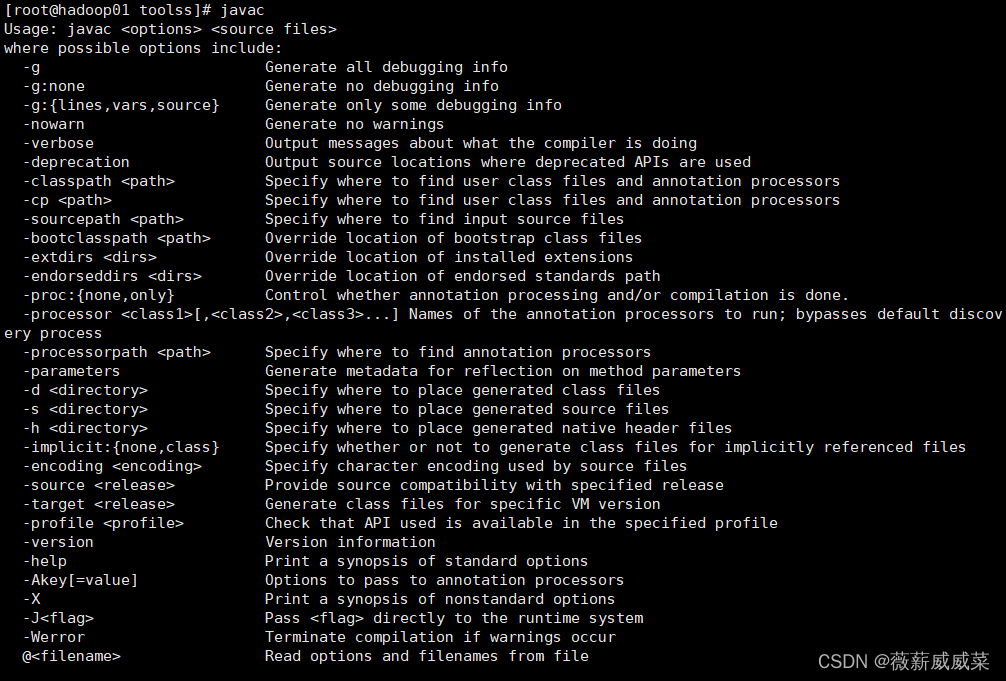

如果报错,先看报错信息提示什么,八成是前面hadoop的配置文件搞错了,这下子因为我们三台都复制了1的hadoop,如果检查出来配置文件问题,要三台都去查看配置文件相应修改。还有如果之前装过hadoop的,要去修改环境变量全局变量。如果还是无法解决,就去看hadoop日志(自行百度命令),日志会写的很清楚具体到哪个文件哪一行出错了。当你感觉什么都改正了,还是报错,就去重启试一下,
14.启动hadoop
在hadoop01中:cd /root/toolss 格式化节点:hadoop namenode format,然后启动:start-dfs.sh。(以后再次启动不需要格式化,不学了的时候记得随手关闭:stop-dfs.sh)
。这下子三台都启动了(不需要启动2和3,因为我们之前在hadoop01中的slaves里面已经把2和3都配置进去了)
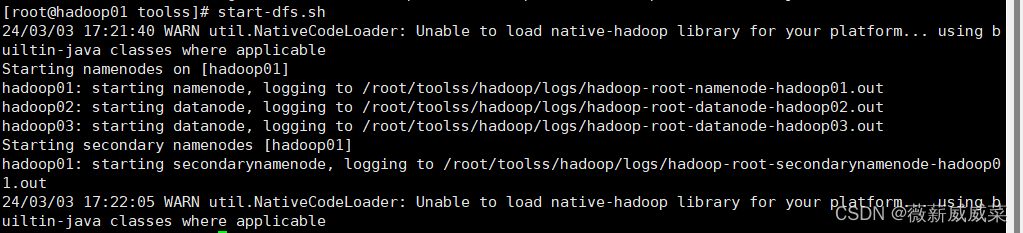
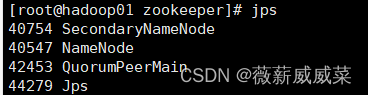
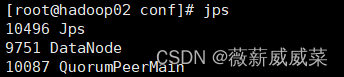
三台都输入jsp查看

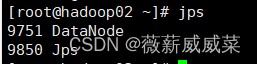

如果2和3中,没有datanode,即没有正确启动,去看日志cat /root/toolss/hadoop/logs/hadoop-root-datanode-hadoop02.out,找出问题把解决问题(很可能是配置文件搞错了),也可能是端口被占用。解决后,去重启一下节点:sudo systemctl restart hadoop-hdfs-datanode。
如果已经使用
start-dfs.sh
启动了 HDFS 服务,在修改配置文件后,使用以下命令单独重启datanode:
hadoop-daemon.sh stop datanode
hadoop-daemon.sh start datanode
到这里,hadoop集群已经顺利完成,可在浏览器查看: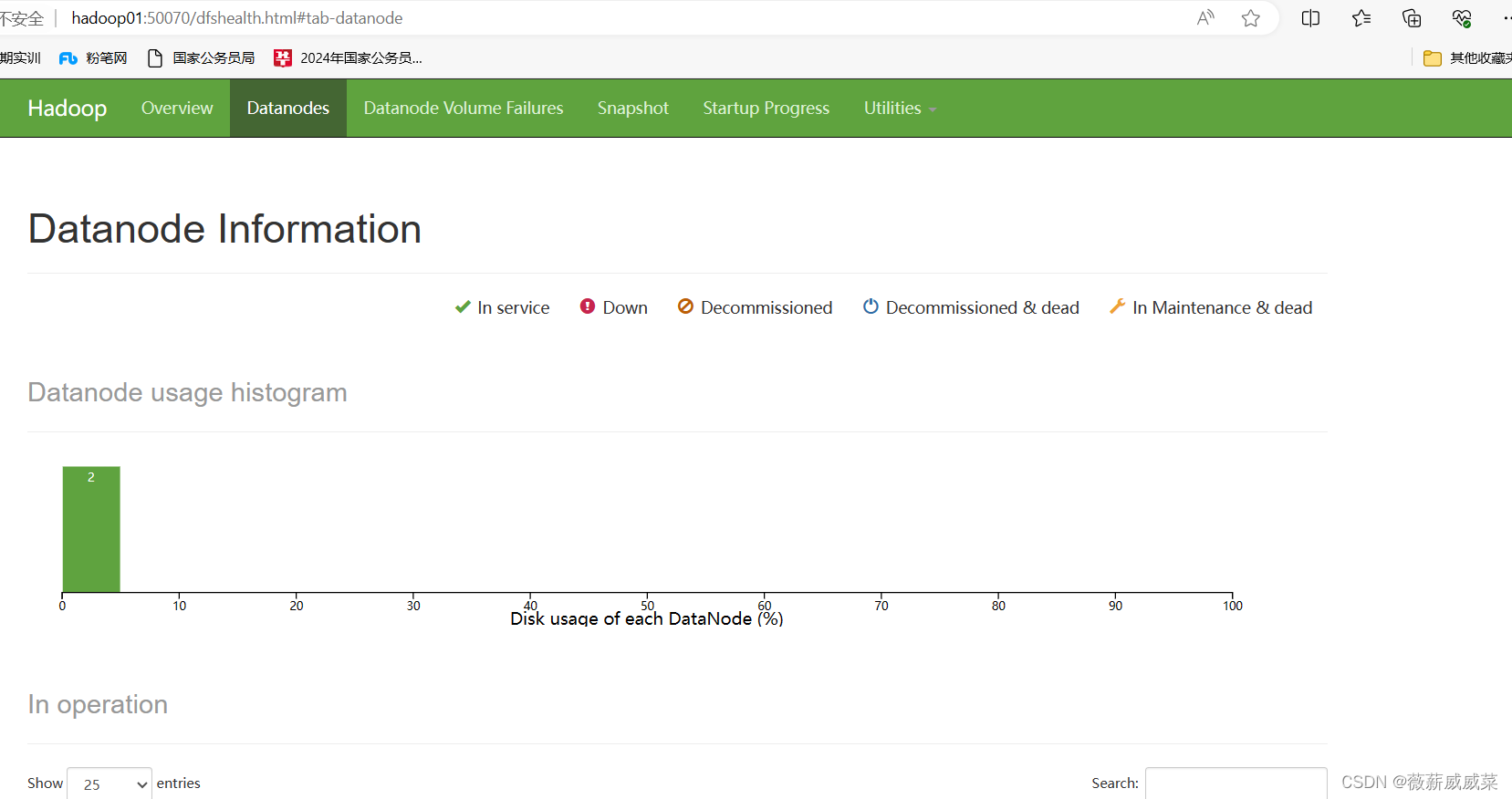
zookeeper安装配置
15.配置zookeeper
15-1 和jdk一样,先解压,改名。
15-2 配置文件改名如下:

配置文件内容修改如下: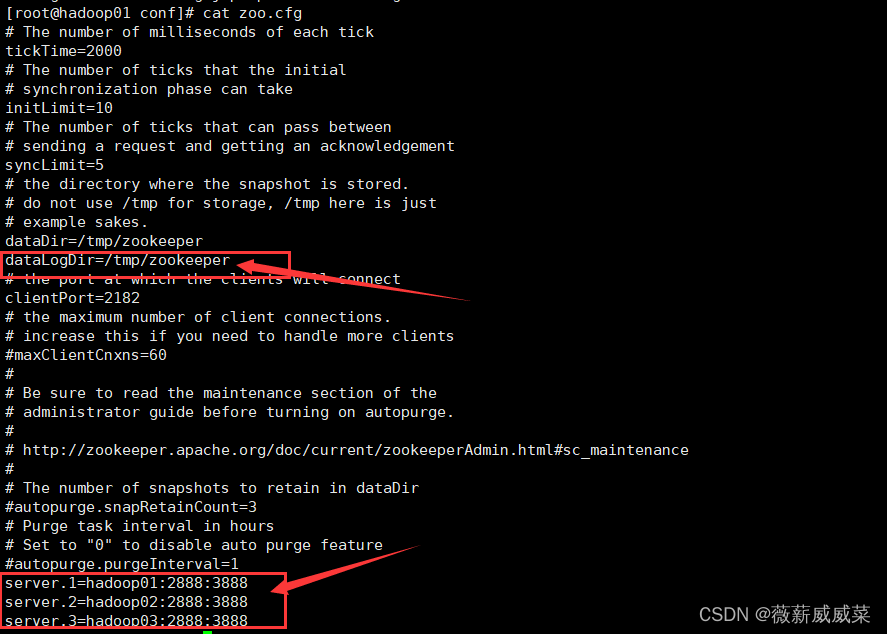
15-3 创建文件夹zookeeper,文件myid,文件内输入1,不要额外多余符号,结构如下图:

15-4 用scp把zookeeper传到2和3,和前面一样,就是改个单词就行。
15-5 去2和3中都重复15-3,2的myid是2,以此类推。
15-6 启动zookeeper,去toolss下面的zookeeper,不是刚刚创建的zookeeper文件夹!!!!!
cd /root/toolss/zookeeper
先把三台都要启动:bin/zkServer.sh start,
都启动后,三台都去需要验证:bin/zkServer.sh status,
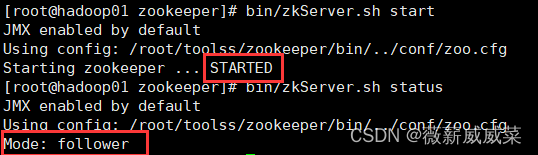

03显示和01一样,13follower,2leader。
到这里zookeeper完成了
spark安装配置
16.配置spark
16-1 在Hadoop01中,和jdk一样,先解压,改名spark
16-2 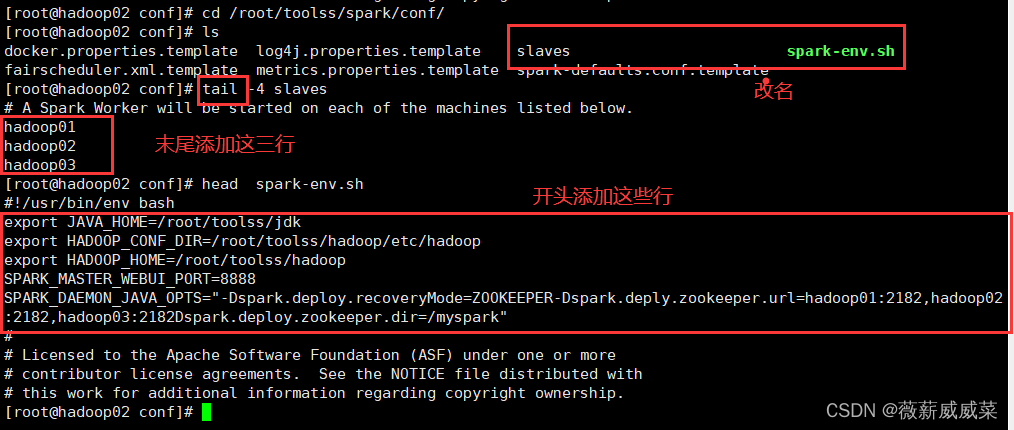
我的因为2181的端口号被占用,所以我用了2182的端口号,你们写2181就行。
16-3 scp传给 2和3
16-4 启动spark:cd /root/toolss/spark
sbin/start-all.sh,只需在hadoop01上启动

查看jps

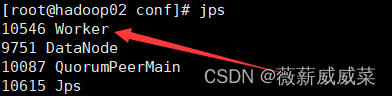
spark开启成功!
浏览器查看,hadoop01:8888(如果你的spark-env.sh配置和我一样,那么也是8888)

spark顺利搭建。
到这里就结束了,如果遇到任何问题可以在评论区留言哦。
版权归原作者 学不会又听不懂 所有, 如有侵权,请联系我们删除。