
Kafka 3.x.x 入门到精通(02)——对标尚硅谷Kafka教程


本文档参看的视频是:
- 尚硅谷Kafka教程,2024新版kafka视频,零基础入门到实战
- 黑马程序员Kafka视频教程,大数据企业级消息队列kafka入门到精通
- 小朋友也可以懂的Kafka入门教程,还不快来学
本文档参看的文档是:
- 尚硅谷官方文档,并在基础上修改 完善!非常感谢尚硅谷团队!!!!
参考:
- https://mp.weixin.qq.com/s/uI2zkf74KXsWaCOplX1Ing
- https://mp.weixin.qq.com/s/oxb2Ezn4K2jMPzubqFULuw
- https://mp.weixin.qq.com/s/tTKXb6On5bfJGjcvn9IpbA
- https://mp.weixin.qq.com/s/CCAP8n0mTCrUT-NzOAacCg
- https://blog.csdn.net/qq_43745578/article/details/135931980
在这之前大家可以看我以下几篇文章,循序渐进:
❤️Kafka 3.x.x 入门到精通(01)——对标尚硅谷Kafka教程
2. Kafka基础
Kafka借鉴了JMS规范的思想,但是却并没有完全遵循JMS规范,因此从设计原理上,Kafka的内部也会有很多用于数据传输的组件对象,这些组件对象之间会形成关联,组合在一起实现高效的数据传输。所以接下来,我们就按照数据流转的过程详细讲一讲Kafka中的基础概念以及核心组件。

大量的生产者,大量的消费者,可能对于单一的Kafka造成 吞吐量过大,IO热点问题,那么单一的Kafka就有可能作为整个系统的性能瓶颈,降低可用性和稳定性,而且如果Down掉了,那就不是一个好的系统方案。
有效策略:



- 为了数据可靠性,可以将数据文件进行备份,但是Kafka没有备份的概念
- Kafka中称之为副本,多个副本同时只能有一个提供数据的读写操作
- 具有读写能力的副本称之为Leader副本,作为备份的副本称之为Follower副本

如果管理者出现了问题,有2种解决方案:
- 给管理者增加备份
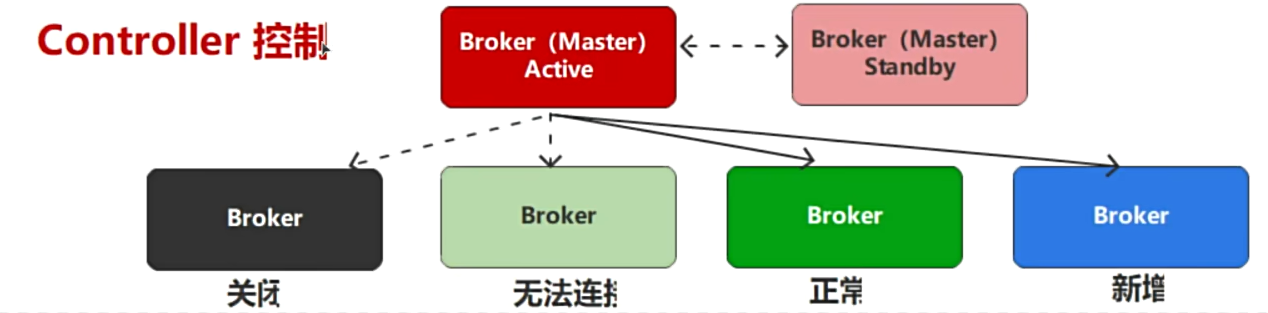
- 任何一个节点都可以做备份
那都是Standby,如果我的master down掉了,如何确定哪一个上位
谁来控制选举呢?ZooKeeper!!!
SO!!!!
2.1 集群部署
生产环境都是采用linux系统搭建服务器集群,但是我们的重点是在于学习kafka的基础概念和核心组件,所以这里我们搭建一个简单易用的windows集群方便大家的学习和练习。Linux集群的搭建会在第3章给大家进行讲解。
2.1.1 解压文件
(1) 在磁盘根目录创建文件夹cluster,文件夹名称不要太长

(2) 将kafka安装包kafka-3.6.1-src.tgz解压缩到kafka文件夹

2.1.2 安装ZooKeeper
(1) 修改文件夹名为kafka-zookeeper
因为kafka内置了ZooKeeper软件,所以此处将解压缩的文件作为ZooKeeper软件使用。

(2) 修改config/zookeeper.properties文件
# Licensed to the Apache Software Foundation (ASF) under one or more# contributor license agreements. See the NOTICE file distributed with# this work for additional information regarding copyright ownership.# The ASF licenses this file to You under the Apache License, Version 2.0# (the "License"); you may not use this file except in compliance with# the License. You may obtain a copy of the License at# # http://www.apache.org/licenses/LICENSE-2.0# # Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.# the directory where the snapshot is stored.# 此处注意,如果文件目录不存在,会自动创建dataDir=E:/cluster/kafka-zookeeper/data
# the port at which the clients will connect# ZooKeeper默认端口为2181clientPort=2181# disable the per-ip limit on the number of connections since this is a non-production configmaxClientCnxns=0# Disable the adminserver by default to avoid port conflicts.# Set the port to something non-conflicting if choosing to enable thisadmin.enableServer=false
# admin.serverPort=8080

2.1.3 安装Kafka
(1) 将上面解压缩的文件复制一份,改名为kafka-node-1

(2) 修改config/server.properties配置文件
broker.id=1############################# Socket Server Settings ############################## 监听器 9091为本地端口,如果冲突,请重新指定listeners=PLAINTEXT://:9091
num.network.threads=3num.io.threads=8# The send buffer (SO_SNDBUF) used by the socket serversocket.send.buffer.bytes=102400# The receive buffer (SO_RCVBUF) used by the socket serversocket.receive.buffer.bytes=102400# The maximum size of a request that the socket server will accept (protection against OOM)socket.request.max.bytes=104857600############################# Log Basics #############################log.dirs=E:/cluster/kafka-node-1/data
num.partitions=1num.recovery.threads.per.data.dir=1############################# Internal Topic Settings #############################offsets.topic.replication.factor=1transaction.state.log.replication.factor=1transaction.state.log.min.isr=1############################# Log Flush Policy #############################log.retention.hours=168log.segment.bytes=190log.flush.interval.messages=2log.index.interval.bytes=17# The interval at which log segments are checked to see if they can be deleted according# to the retention policieslog.retention.check.interval.ms=300000# ZooKeeper软件连接地址,2181为默认的ZK端口号 /kafka 为ZK的管理节点zookeeper.connect=localhost:2181/kafka
# Timeout in ms for connecting to zookeeperzookeeper.connection.timeout.ms=18000############################# Group Coordinator Settings #############################group.initial.rebalance.delay.ms=0



(3) 将kafka-node-1文件夹复制两份,改名为kafka-node-2,kafka-node-3

(4) 分别修改kafka-node-2,kafka-node-3文件夹中的配置文件server.properties
- 将文件内容中的
broker.id=1分别改为broker.id=2,broker.id=3 - 将文件内容中的
9091分别改为9092,9093(如果端口冲突,请重新设置) - 将文件内容中的
kafka-node-1分别改为kafka-node-2,kafka-node-3
2.1.4 封装启动脚本
因为Kafka启动前,必须先启动ZooKeeper,并且Kafka集群中有多个节点需要启动,所以启动过程比较繁琐,这里我们将启动的指令进行封装。
(1) 在kafka-zookeeper文件夹下创建zk.cmd批处理文件

(2) 在zk.cmd文件中添加内容
# 添加启动命令
call bin/windows/zookeeper-server-start.bat config/zookeeper.properties
(3) 在kafka-node-1,kafka-node-2,kafka-node-3文件夹下分别创建kfk.cmd批处理文件

(4) 在kfk.bat文件中添加内容
# 添加启动命令
call bin/windows/kafka-server-start.bat config/server.properties
(5) 在cluster文件夹下创建cluster.cmd批处理文件,用于启动kafka集群

(6) 在cluster.cmd文件中添加内容
cd kafka-zookeeper
start zk.cmd
ping127.0.0.1 -n10>nul
cd../kafka-broker-1
start kfk.cmd
cd../kafka-broker-2
start kfk.cmd
cd../kafka-broker-3
start kfk.cmd
(7) 在cluster文件夹下创建cluster-clear.cmd批处理文件,用于清理和重置kafka数据

(8) 在cluster-clear.cmd文件中添加内容
cd kafka-zookeeper
rd /s /q data
cd../kafka-broker-1
rd /s /q data
cd../kafka-broker-2
rd /s /q data
cd../kafka-broker-3
rd /s /q data
(9) 双击执行cluster.cmd文件,启动Kafka集群
集群启动命令后,会打开多个黑窗口,每一个窗口都是一个kafka服务,请不要关闭,一旦关闭,对应的kafka服务就停止了。如果启动过程报错,主要是因为zookeeper和kafka的同步问题,请先执行cluster-clear.cmd文件,再执行cluster.cmd文件即可。



2.2 集群启动
2.2.1 相关概念
2.2.1.1 代理:Broker
**使用Kafka前,我们都会启动Kafka服务进程,这里的Kafka服务进程我们一般会称之为Kafka Broker或Kafka Server。因为Kafka是分布式消息系统,所以在实际的生产环境中,是需要多个服务进程形成集群提供消息服务的。所以
每一个服务节点都是一个broker
,而且在Kafka集群中,为了区分不同的服务节点,每一个broker都应该有一个不重复的全局ID,称之为
broker.id
,这个ID可以在kafka软件的配置文件server.properties中进行配置**
############################# ServerBasics #############################
# The id of the broker. This must be set toa unique integer for each broker
# 集群ID
broker.id=0
咱们的Kafka集群中每一个节点都有自己的ID,整数且唯一。
主机kafka-broker1kafka-broker2kafka-broker3broker.id123
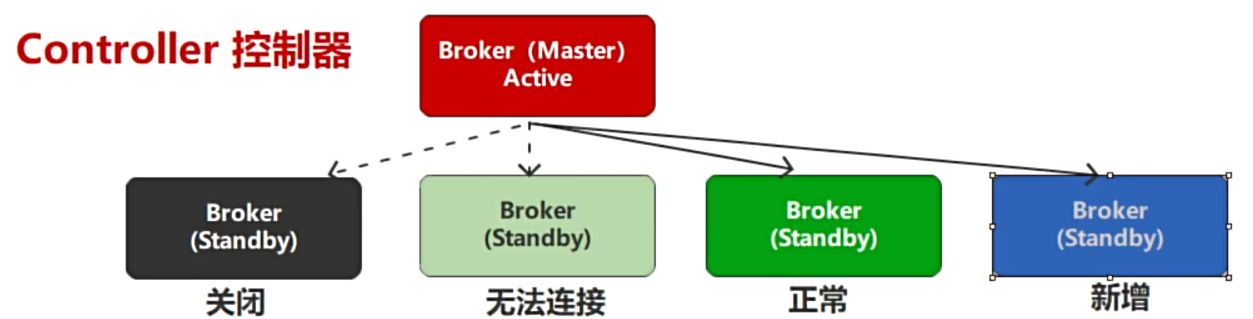
2.2.1.2 控制器:Controller
**Kafka是分布式消息传输系统,所以存在多个
Broker服务节点
,但是它的软件架构采用的是分布式系统中比较常见的主从(Master - Slave)架构,也就是说需要从
多个Broker
中找到一个用于管理整个Kafka集群的
Master节点
,这个节点,我们就称之为
Controller
。它是Apache Kafka的核心组件非常重要。它的主要作用是在Apache Zookeeper的帮助下管理和协调控制整个Kafka集群。**

如果在运行过程中,Controller节点出现了故障,那么Kafka会依托于ZooKeeper软件选举其他的节点作为新的Controller,让Kafka集群实现高可用。

Kafka集群中Controller的基本功能:
- Broker管理- 监听
/brokers/ids节点相关的变化:- Broker数量增加或减少的变化- Broker对应的数据变化 - Topic管理- 新增:监听
/brokers/topics节点相关的变化- 修改:监听/brokers/topics节点相关的变化- 删除:监听/admin/delete_topics节点相关的变化 - Partation管理- 监听
/admin/reassign_partitions节点相关的变化- 监听/isr_change_notification节点相关的变化- 监听/preferred_replica_election节点相关的变化 - 数据服务
- 启动分区状态机和副本状态机
ZooKeeper工具:



ZooKeeper客户端
2.2.2 启动ZooKeeper
Kafka集群中含有多个服务节点,而分布式系统中经典的主从(Master - Slave)架构就要求从多个服务节点中找一个节点作为集群管理Master,Kafka集群中的这个Master,我们称之为集群控制器Controller

如果此时Controller节点出现故障,它就不能再管理集群功能,那么其他的Slave节点该如何是好呢?

如果从剩余的2个Slave节点中选一个节点出来作为新的集群控制器是不是一个不错的方案,我们将这个选择的过程称之为:选举(elect)。方案是不错,但是问题就在于选哪一个Slave节点呢?不同的软件实现类似的选举功能都会有一些选举算法,而Kafka是依赖于ZooKeeper软件实现Broker节点选举功能。




ZooKeeper如何实现Kafka的节点选举呢?这就要说到我们用到ZooKeeper的3个功能:
- 一个是在ZooKeeper软件中创建节点Node,创建一个Node时,我们会设定这个节点是
持久化创建,还是临时创建。所谓的持久化创建,就是Node一旦创建后会一直存在,而临时创建,是根据当前的客户端连接创建的临时节点Node,一旦客户端连接断开,那么这个临时节点Node也会被自动删除,所以这样的节点称之为临时节点。 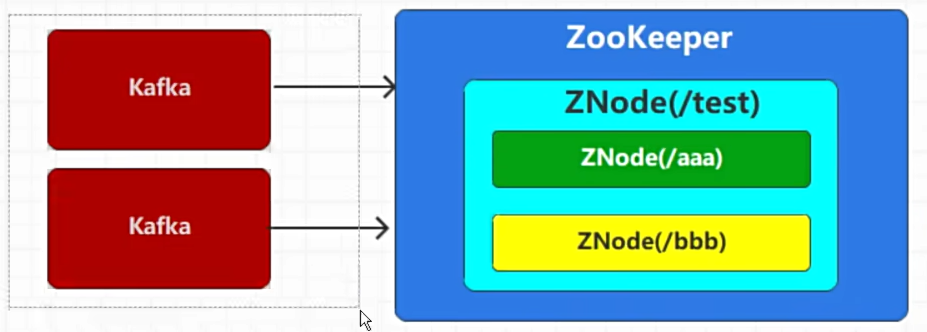
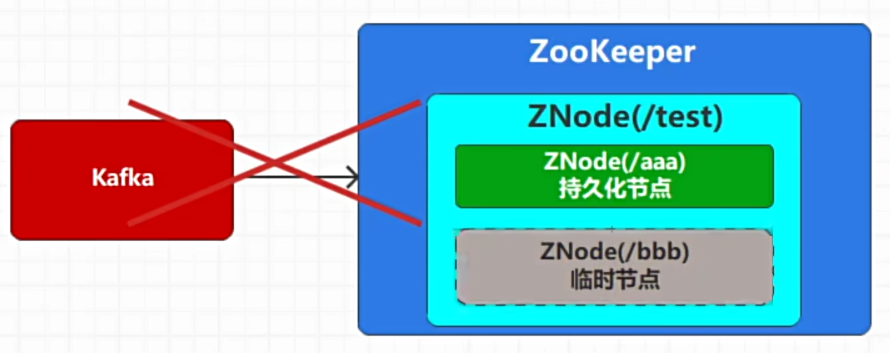
- ZooKeeper节点是不允许有重复的,所以多个客户端创建同一个节点,只能有一个创建成功。
- 另外一个是客户端可以在ZooKeeper的节点上增加监听器,用于监听节点的状态变化,一旦监听的节点状态发生变化,那么监听器就会触发响应,实现特定监听功能。
有了上面的三个知识点,我们这里就介绍一下Kafka是如何利用ZooKeeper实现Controller节点的选举的:
- 第一次启动Kafka集群时,会同时启动多个Broker节点,每一个Broker节点就会连接ZooKeeper,并尝试创建一个临时节点 /controller
- 因为ZooKeeper中一个节点不允许重复创建,所以多个Broker节点,最终只能有一个Broker节点可以创建成功,那么这个创建成功的Broker节点就会自动作为Kafka集群控制器节点,用于管理整个Kafka集群。
- 没有选举成功的其他Slave节点会创建Node监听器,用于监听 /controller节点的状态变化。
- 一旦Controller节点出现故障或挂掉了,那么对应的ZooKeeper客户端连接就会中断。ZooKeeper中的 /controller 节点就会自动被删除,而其他的那些Slave节点因为增加了监听器,所以当监听到 /controller 节点被删除后,就会马上向ZooKeeper发出创建 /controller 节点的请求,一旦创建成功,那么该Broker就变成了新的Controller节点了。
现在我们能明白启动Kafka集群之前,为什么要先启动ZooKeeper集群了吧。就是因为ZooKeeper可以协助Kafka进行集群管理。
2.2.3 启动Kafka
ZooKeeper已经启动好了,那我们现在可以启动多个Kafka Broker节点构建Kafka集群了。构建的过程中,每一个Broker节点就是一个Java进程,而在这个进程中,有很多需要提前准备好,并进行初始化的内部组件对象。
2.2.3.1初始化ZooKeeper
Kafka Broker启动时,首先会先创建ZooKeeper客户端(KafkaZkClient),用于和ZooKeeper进行交互。客户端对象创建完成后,会通过该客户端对象向ZooKeeper发送创建Node的请求,注意,这里创建的Node都是持久化Node。

节点类型说明/admin/delete_topics持久化节点配置需要删除的topic,因为删除过程中,可能broker下线,或执行失败,那么就需要在broker重新上线后,根据当前节点继续删除操作,一旦topic所有的分区数据全部删除,那么当前节点的数据才会进行清理/brokers/ids持久化节点服务节点ID标识,只要broker启动,那么就会在当前节点中增加子节点,brokerID不能重复/brokers/topics持久化节点服务节点中的主题详细信息,包括分区,副本/brokers/seqid持久化节点seqid主要用于自动生产brokerId/config/changes持久化节点kafka的元数据发生变化时,会向该节点下创建子节点。并写入对应信息/config/clients持久化节点客户端配置,默认为空/config/brokers持久化节点服务节点相关配置,默认为空/config/ips持久化节点IP配置,默认为空/config/topics持久化节点主题配置,默认为空/config/users持久化节点用户配置,默认为空/consumers持久化节点消费者节点,用于记录消费者相关信息/isr_change_notification持久化节点ISR列表发生变更时候的通知,在kafka当中由于存在ISR列表变更的情况发生,为了保证ISR列表更新的及时性,定义了isr_change_notification这个节点,主要用于通知Controller来及时将ISR列表进行变更。/latest_producer_id_block持久化节点保存PID块,主要用于能够保证生产者的任意写入请求都能够得到响应。/log_dir_event_notification持久化节点主要用于保存当broker当中某些数据路径出现异常时候,例如磁盘损坏,文件读写失败等异常时候,向ZooKeeper当中增加一个通知序号,Controller节点监听到这个节点的变化之后,就会做出对应的处理操作/cluster/id持久化节点主要用于保存kafka集群的唯一id信息,每个kafka集群都会给分配要给唯一id,以及对应的版本号
第一个Broker启动的流程
第二个Broker启动的流程

第三个Broker启动的流程

controller节点删除
2.2.3.2初始化服务
Kafka Broker中有很多的服务对象,用于实现内部管理和外部通信操作。


2.2.3.2.1 启动任务调度器
每一个Broker在启动时都会创建内部调度器(KafkaScheduler)并启动,用于完成节点内部的工作任务。底层就是Java中的定时任务线程池
ScheduledThreadPoolExecutor
2.2.3.2.2 创建数据管理器
每一个Broker在启动时都会创建数据管理器(LogManager),用于接收到消息后,完成后续的数据创建,查询,清理等处理。
2.2.3.2.3 创建远程数据管理器
每一个Broker在启动时都会创建远程数据管理器(RemoteLogManager),用于和其他Broker节点进行数据状态同步。
2.2.3.2.4 创建副本管理器
每一个Broker在启动时都会创建副本管理器(ReplicaManager),用于对主题的副本进行处理。
2.2.3.2.5 创建ZK元数据缓存
每一个Broker在启动时会将ZK的关于Kafka的元数据进行缓存,创建元数据对象(ZkMetadataCache)
2.2.3.2.6 创建Broker通信对象
每一个Broker在启动时会创建Broker之间的通道管理器对象(BrokerToControllerChannelManager),用于管理Broker和Controller之间的通信。
2.2.3.2.7 创建网络通信对象
每一个Broker在启动时会创建自己的网络通信对象(SocketServer),用于和其他Broker之间的进行通信,其中包含了Java用于NIO通信的Channel、Selector对象。
2.2.3.2.8 注册Broker节点
Broker启动时,会通过ZK客户端对象向ZK注册当前的Broker 节点ID,注册后创捷的ZK节点为临时节点。如果当前Broker的ZK客户端断开和ZK的连接,注册的节点会被删除。
2.2.3.3 启动控制器
控制器(KafkaController)是每一个Broker启动时都会创建的核心对象,用于和ZK之间建立连接并申请自己为整个Kafka集群的Master管理者。如果申请成功,那么会完成管理者的初始化操作,并建立和其他Broker之间的数据通道接收各种事件,进行封装后交给事件管理器,并定义了process方法,用于真正处理各类事件。
2.2.3.3.1 初始化通道管理器
创建通道管理器(ControllerChannelManager),该管理器维护了Controller和集群所有Broker节点之间的网络连接,并向Broker发送控制类请求及接收响应。
2.2.3.3.2 初始化事件管理器
创建事件管理器(ControllerEventManager)维护了Controller和集群所有Broker节点之间的网络连接,并向Broker发送控制类请求及接收响应。
2.2.3.3.3 初始化状态管理器
创建状态管理器(ControllerChangeHandler)可以监听 /controller 节点的操作,一旦节点创建(ControllerChange),删除(Reelect),数据发生变化(ControllerChange),那么监听后执行相应的处理。
2.2.3.3.4 启动控制器
控制器对象启动后,会向事件管理器发送Startup事件,事件处理线程接收到事件后会通过ZK客户端向ZK申请 /controller 节点,申请成功后,执行当前节点成为Controller的一些列操作。主要是注册各类 ZooKeeper 监听器、删除日志路径变更和 ISR 副本变更通知事件、启动 Controller 通道管理器,以及启动副本状态机和分区状态机。
2.2.4 反正到这 我是懵啦~
我这边阅读了其他人的博客 感谢这位大佬!!! ┭┮﹏┭┮
- Kafka服务实例,负责消息的持久化、中转等功能。一个独立的Kafka 服务器被就是一个broker。
- broker 是集群的组成部分。每个集群都有一个broker 同时充当了集群控制器Controller的角色。
- kafka使用Zookeeper(ZK)进行元数据管理,保存broker注册信息,包括主题(Topic)、分区(Partition)信息等,选择分区leader,在低版本kafka消费者的offset信息也会保存在ZK中。
简简单单的三句话:大致总结了好多东西~
在每一个
Broker
在启动时都会向
ZK
注册信息,
ZK
会选取一个最早注册的Broker作为
Controller
,后面
Controller
会与
ZK
进行数据交互获取元数据(即整个Kafka集群的信息,例如有那些
Broker
,每个
Broker
中有那些Partition等信息),并负责管理工作,包括将分区分配给broker 和监控
broker
,其他
Broker
是与
Controller
进行交互进而感知到整个集群的所有信息。
2.2.4.1 Broker总体工作流程

流程如下:
- broker 启动后,向 ZK 集群进行注册
- 各个 broker 的 controller 抢占 ZNode
- 抢占到的 Controller 监听 brokers 节点的变化
- Controller 决定 Leader 的选举规则:在 isr 中存活的 broker,按照 AR 中排在前面的优先
- Controller 将节点信息上传到 ZK
- 其他 controller 从 ZK 同步相关信息
- 假设此时 broker1 中的 Leader 挂了
- Controller 监听到了节点变化
- 从 ZK 中获取 ISR
- 选举出新的 Leader
- 向 ZK 更新 Leader 和 ISR
2.2.4.2 为什么需要Controller
在Kafka早期版本,对于分区和副本的状态的管理依赖于zookeeper的Watcher和队列:每一个broker都会在zookeeper注册
Watcher,所以zookeeper就会出现大量的Watcher, 如果宕机的broker上的
partition很多比较多,会造成多个
Watcher触发,造成集群内大规模调整;每一个replica都要去再次zookeeper上注册监视器,当集群规模很大的时候,zookeeper负担很重。这种设计很容易出现脑裂和羊群效应以及zookeeper集群过载。
新的版本中该变了这种设计,使用KafkaController,只有KafkaController,Leader会向zookeeper上注册Watcher,其他broker几乎不用监听zookeeper的状态变化。
Kafka集群中多个broker,有一个会被选举为controller leader,负责管理整个集群中分区和副本的状态,比如partition的leader 副本故障,由controller 负责为该partition重新选举新的leader 副本;当检测到ISR列表发生变化,有controller通知集群中所有broker更新其MetadataCache信息;或者增加某个topic分区的时候也会由controller管理分区的重新分配工作。
2.3 创建主题
Topic主题是Kafka中消息的逻辑分类,但是这个分类不应该是固定的,而是应该由外部的业务场景进行定义(注意:Kafka中其实是有两个固定的,用于记录消费者偏移量和事务处理的主题),所以Kafka提供了相应的指令和客户端进行主题操作。
2.3.1 相关概念
2.3.1.1 主题:Topic
Kafka是分布式消息传输系统,采用的数据传输方式为发布,订阅模式,也就是说由消息的生产者发布消息,消费者订阅消息后获取数据。
为了对消费者订阅的消息进行区分,所以对消息在逻辑上进行了分类,这个分类我们称之为主题:Topic。消息的生产者必须将消息数据发送到某一个主题,而消费者必须从某一个主题中获取消息,并且消费者可以同时消费一个或多个主题的数据。Kafka集群中可以存放多个主题的消息数据。
为了防止主题的名称和监控指标的名称产生冲突,官方推荐主题的名称中不要同时包含下划线和点。

2.3.1.2 分区:Partition
Kafka消息传输采用发布、订阅模式,所以消息生产者必须将数据发送到一个主题,假如发送给这个主题的数据非常多,那么主题所在broker节点的负载和吞吐量就会受到极大的考验,甚至有可能因为热点问题引起broker节点故障,导致服务不可用。一个好的方案就是将一个主题从物理上分成几块,然后将不同的数据块均匀地分配到不同的broker节点上,这样就可以缓解单节点的负载问题。这个主题的分块我们称之为:分区partition。默认情况下,topic主题创建时分区数量为1,也就是一块分区,可以指定参数–partitions改变。Kafka的分区解决了单一主题topic线性扩展的问题,也解决了负载均衡的问题。
topic主题的每个分区都会用一个编号进行标记,一般是从0开始的连续整数数字。Partition分区是物理上的概念,也就意味着会以数据文件的方式真实存在。每个topic包含一个或多个partition,每个partition都是一个有序的队列。partition中每条消息都会分配一个有序的ID,称之为偏移量:Offset
2.3.1.3 副本:Replication
分布式系统出现错误是比较常见的,只要保证集群内部依然存在可用的服务节点即可,当然效率会有所降低,不过只要能保证系统可用就可以了。咱们Kafka的topic也存在类似的问题,也就是说,如果一个topic划分了多个分区partition,那么这些分区就会均匀地分布在不同的broker节点上,一旦某一个broker节点出现了问题,那么在这个节点上的分区就会出现问题,那么Topic的数据就不完整了。所以一般情况下,为了防止出现数据丢失的情况,我们会给分区数据设定多个备份,这里的备份,我们称之为:副本Replication。
Kafka支持多副本,使得主题topic可以做到更多容错性,牺牲性能与空间去换取更高的可靠性。

注意:这里不能将多个备份放置在同一个broker中,因为一旦出现故障,多个副本就都不能用了,那么副本的意义就没有了。
2.3.1.4 副本类型:Leader & Follower
假设我们有一份文件,一般情况下,我们对副本的理解应该是有一个正式的完整文件,然后这个文件的备份,我们称之为副本。但是在Kafka中,不是这样的,所有的文件都称之为副本,只不过会选择其中的一个文件作为主文件,称之为:Leader(主导)副本,其他的文件作为备份文件,称之为:Follower(追随)副本。在Kafka中,这里的文件就是分区,每一个分区都可以存在1个或多个副本,只有Leader副本才能进行数据的读写,Follower副本只做备份使用。

但是 还是有点问题:
还是容易出现IO热点问题:
更合理:


Kafka!没办法站在上帝的视角分配,只能尽可能的做到负载均衡
2.3.1.5 日志:Log
Kafka最开始的应用场景就是日志场景或MQ场景,更多的扮演着一个日志传输和存储系统,这是Kafka立家之本。所以Kafka接收到的消息数据最终都是存储在log日志文件中的,底层存储数据的文件的扩展名就是log。
主题创建后,会创建对应的分区数据Log日志。并打开文件连接通道,随时准备写入数据。
2.3.1(续) IDEA创建主题
packagecom.atguigu.kafka.test.admin;importorg.apache.kafka.clients.admin.Admin;importorg.apache.kafka.clients.admin.AdminClientConfig;importorg.apache.kafka.clients.admin.NewTopic;importjava.util.ArrayList;importjava.util.Arrays;importjava.util.Objects;importjava.util.Properties;publicclassAdminTopicTest{publicstaticvoidmain(String[] args){Properties properties =newProperties();
properties.setProperty(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");// TODO 管理员对象Admin admin =Admin.create(properties);// TODO 创建主题需要三个参数// 主题名称String topicName ="test1";// 主题分区的数量int partitionCount =1;// 主题分区的副本的因子(数量)short replicationCount =1;NewTopic topic1 =newNewTopic(topicName,partitionCount,replicationCount);// 主题名称String topicName1 ="test2";// 主题分区的数量int partitionCount1 =2;// 主题分区的副本的因子(数量)short replicationCount1 =2;NewTopic topic2 =newNewTopic(topicName1,partitionCount1,replicationCount1);// TODO 创建主题
admin.createTopics(Arrays.asList(topic1,topic2));// TODO 关闭管理者对象
admin.close();}}





主题是逻辑上的分类,而分区才是文件夹层次上的区分
2.3.2 创建第一个主题
创建主题Topic的方式有很多种:命令行,工具,客户端API,自动创建。在server.properties文件中配置参数
auto.create.topics.enable=true
时,如果访问的主题不存在,那么Kafka就会自动创建主题,这个操作不在我们的讨论范围内。由于我们学习的重点在于学习原理和基础概念,所以这里我们选择比较基础的命令行方式即可。
我们首先创建的主题,仅仅指明主题的名称即可,其他参数暂时无需设定。
2.3.2.1 执行指令

[atguigu@kafka-broker1 ~]$ cd /opt/module/kafka
[atguigu@kafka-broker1 kafka]$ bin/kafka-topics.sh --bootstrap-server kafka-broker1:9092--create --topic first-topic
2.3.2.2 ZooKeeper节点变化
指令执行后,当前Kafka会增加一个主题,因为指令中没有配置分区和副本参数,所以当前主题分区数量为默认值1,编号为0,副本为1,编号为所在broker的ID值。为了方便集群的管理,创建topic时,会同时在ZK中增加子节点,记录主题相关配置信息:
- /config/topics节点中会增加first-topic节点。

- /brokers/topics节点中会增加first-topic节点以及相应的子节点。

节点节点类型数据名称数据值说明/topics/first-topic持久类型removing_replicas无partitions{“0”:[3]}分区配置topic_id随机字符串adding_replicas无version3/topics/first-topic/partitions持久类型主题分区节点,每个主题都应该设置分区,保存在该节点/topics/first-topic/partitions/0持久类型主题分区副本节点,因为当前主题只有一个分区,所以编号为0/topics/first-topic/partitions/0/state持久类型controller_epoch 7 主题分区副本状态节点leader3Leader副本所在的broker Idversion1leader_epoch0isr[3]副本同步列表,因为当前只有一个副本,所以副本中只有一个副本编号
2.3.2.3 数据存储位置
主题创建后,需要找到一个用于存储分区数据的位置,根据上面ZooKeeper存储的节点配置信息可以知道,当前主题的分区数量为1,副本数量为1,那么数据存储的位置就是副本所在的broker节点,从当前数据来看,数据存储在我们的第三台broker上。
[atguigu@kafka-broker3 ~]$ cd /opt/module/kafka/datas
[atguigu@kafka-broker3 datas]$ ll

[atguigu@kafka-broker3 datas]$ cd first-topic-0[atguigu@kafka-broker3 first-topic-0]$ ll

路径中的
00000000000000000000.log
文件就是真正存储消息数据的文件,文件名称中的0表示当前文件的起始偏移量为0,index文件和timeindex文件都是数据索引文件,用于快速定位数据。只不过index文件采用偏移量的方式进行定位,而timeindex是采用时间戳的方式。
2.3.3 创建第二个主题
接下来我们创建第二个主题,不过创建时,我们需要设定分区参数
--partitions
,参数值为3,表示创建3个分区
2.3.3.1 执行指令

[atguigu@kafka-broker1 ~]$ cd /opt/module/kafka
[atguigu@kafka-broker1 kafka]$ bin/kafka-topics.sh --bootstrap-server kafka-broker1:9092--create --topic second-topic --partitions 3
2.3.3.2 ZooKeeper节点变化
指令执行后,当前Kafka会增加一个主题,因为指令中指定了分区数量(–partitions 3),所以当前主题分区数量为3,编号为[0、1、2],副本为1,编号为所在broker的ID值。为了方便集群的管理,创建Topic时,会同时在ZK中增加子节点,记录主题相关配置信息:
/config/topics节点中会增加second-topic节点。
/brokers/topics节点中会增加second-topic节点以及相应的子节点。
2.3.3.3 数据存储位置
主题创建后,需要找到一个用于存储分区数据的位置,根据上面ZooKeeper存储的节点配置信息可以知道,当前主题的分区数量为3,副本数量为1,那么数据存储的位置就是每个分区Leader副本所在的broker节点。
[atguigu@kafka-broker1 ~]$ cd /opt/module/kafka/datas
[atguigu@kafka-broker1 datas]$ ll

[atguigu@kafka-broker1 datas]$ cd second-topic-0[atguigu@kafka-broker1 second-topic-0]$ ll

[atguigu@kafka-broker2 ~]$ cd /opt/module/kafka/datas
[atguigu@kafka-broker2 datas]$ ll

[atguigu@kafka-broker2 datas]$ cd second-topic-1[atguigu@kafka-broker2 second-topic-1]$ ll

[atguigu@kafka-broker3 ~]$ cd /opt/module/kafka/datas
[atguigu@kafka-broker3 datas]$ ll

[atguigu@kafka-broker3 datas]$ cd second-topic-2[atguigu@kafka-broker3 second-topic-2]$ ll

2.3.4 创建第三个主题
接下来我们创建第三个主题,不过创建时,我们需要设定副本参数 --replication-factor,参数值为3,表示每个分区创建3个副本。
2.3.4.1 执行指令

[atguigu@kafka-broker1 ~]$ cd /opt/module/kafka
[atguigu@kafka-broker1 kafka]$ bin/kafka-topics.sh --bootstrap-server kafka-broker1:9092--create --topic third-topic --partitions 3--replication-factor 3
2.3.4.2 ZooKeeper节点变化
指令执行后,当前Kafka会增加一个主题,因为指令中指定了分区数量和副本数量(–replication-factor 3),所以当前主题分区数量为3,编号为[0、1、2],副本为3,编号为[1、2、3]。为了方便集群的管理,创建Topic时,会同时在ZK中增加子节点,记录主题相关配置信息:
/config/topics节点中会增加third-topic节点。
/brokers/topics节点中会增加third-topic节点以及相应的子节点。
2.3.4.3 数据存储位置
主题创建后,需要找到一个用于存储分区数据的位置,根据上面ZooKeeper存储的节点配置信息可以知道,当前主题的分区数量为3,副本数量为3,那么数据存储的位置就是每个分区副本所在的broker节点。
[atguigu@kafka-broker1 ~]$ cd /opt/module/kafka/datas
[atguigu@kafka-broker1 datas]$ ll

[atguigu@kafka-broker1 datas]$ cd third-topic-2[atguigu@kafka-broker1 third-topic-2]$ ll

[atguigu@kafka-broker2 ~]$ cd /opt/module/kafka/datas
[atguigu@kafka-broker2 datas]$ ll

[atguigu@kafka-broker2 datas]$ cd third-topic-0[atguigu@kafka-broker2 third-topic-0]$ ll

[atguigu@kafka-broker3 ~]$ cd /opt/module/kafka/datas
[atguigu@kafka-broker3 datas]$ ll

[atguigu@kafka-broker3 datas]$ cd third-topic-1[atguigu@kafka-broker3 third-topic-1]$ ll

2.3.5 创建主题流程
Kafka中主题、分区以及副本的概念都和数据存储相关,所以是非常重要的。前面咱们演示了一下创建主题的具体操作和现象,那么接下来,我们就通过图解来了解一下Kafka是如何创建主题,并进行分区副本分配的。
2.3.5.1 命令行提交创建指令

- 通过命令行提交指令,指令中会包含操作类型(–create)、topic的名称(–topic)、主题分区数量(–partitions)、主题分区副本数量(–replication-facotr)、副本分配策略(–replica-assignment)等参数。
- 指令会提交到客户端进行处理,客户端获取指令后,会首先对指令参数进行校验。 - a. 操作类型取值:create、list、alter、describe、delete,只能存在一个。- b. 分区数量为大于1的整数。- c. 主题是否已经存在- d. 分区副本数量大于1且小于Short.MaxValue,一般取值小于等于Broker数量。
- 将参数封装主题对象(NewTopic)。
- 创建通信对象,设定请求标记(CREATE_TOPICS),查找Controller,通过通信对象向Controller发起创建主题的网络请求。
2.3.5.2 Controller接收创建主题请求

(1) Controller节点接收到网络请求(Acceptor),并将请求数据封装成请求对象放置在队列(requestQueue)中。
(2) 请求控制器(KafkaRequestHandler)周期性从队列中获取请求对象(BaseRequest)。
(3) 将请求对象转发给请求处理器(KafkaApis),根据请求对象的类型调用创建主题的方法。
2.3.5.3 创建主题

(1) 请求处理器(KafkaApis)校验主题参数。
- 如果分区数量没有设置,那么会采用Kafka启动时加载的配置项: - num.partitions(默认值为1)
- 如果副本数量没有设置,那么会采用Kafka启动时记载的配置项: - default.replication.factor(默认值为1)
(2) 在创建主题时,如果使用了replica-assignment参数,那么就按照指定的方案来进行分区副本的创建;如果没有指定replica-assignment参数,那么就按照Kafka内部逻辑来分配,内部逻辑按照机架信息分为两种策略:【未指定机架信息】和【指定机架信息】。当前课程中采用的是【未指定机架信息】副本分配策略:
- 分区起始索引设置0
- 轮询所有分区,计算每一个分区的所有副本位置: - 副本起始索引 =
(分区编号 + 随机值) % BrokerID列表长度。- 其他副本索引 =。。。随机值(基本算法为使用随机值执行多次模运算)
################################################################### 假设 # 当前分区编号 : 0# BrokerID列表 :【1,2,3,4】# 副本数量 : 4# 随机值(BrokerID列表长度): 2# 副本分配间隔随机值(BrokerID列表长度): 2################################################################### 第一个副本索引:
(分区编号 + 随机值)% BrokerID列表长度 =
(0+2)%4=2# 第一个副本所在BrokerID : 3# 第二个副本索引
(第一个副本索引 + (1+(副本分配间隔 +0)% (BrokerID列表长度 -1))) % BrokerID列表长度 =
(2+(1+(2+0)%3))%4=1# 第二个副本所在BrokerID:2# 第三个副本索引:(第一个副本索引 + (1 +(副本分配间隔 + 1)% (BrokerID列表长度 - 1))) % BrokerID列表长度 = (2 +(1+(2+1)%3))% 4 = 3# 第三个副本所在BrokerID:4# 第四个副本索引:(第一个副本索引 + (1 +(副本分配间隔 + 2)% (BrokerID列表长度 - 1))) % BrokerID列表长度 = (2 +(1+(2+2)%3))% 4 = 0# 第四个副本所在BrokerID:1# 最终分区0的副本所在的Broker节点列表为【3,2,4,1】# 其他分区采用同样算法
- 通过索引位置获取副本节点ID
- 保存分区以及对应的副本ID列表。
(3) 通过ZK客户端在ZK端创建节点:
- 在 /config/topics节点下,增加当前主题节点,节点类型为持久类型。
- 在 /brokers/topics节点下,增加当前主题及相关节点,节点类型为持久类型。 (4) Controller节点启动后,会在/brokers/topics节点增加监听器,一旦节点发生变化,会触发相应的功能:
- 获取需要新增的主题信息
- 更新当前Controller节点保存的主题状态数据
- 更新分区状态机的状态为:NewPartition
- 更新副本状态机的状态:NewReplica
- 更新分区状态机的状态为:OnlinePartition,从正常的副本列表中的获取第一个作为分区的Leader副本,所有的副本作为分区的同步副本列表,我们称之为ISR( In-Sync Replica)。在ZK路径/brokers/topics/主题名上增加分区节点/partitions,及状态/state节点。
- 更新副本状态机的状态:OnlineReplica (5) Controller节点向主题的各个分区副本所属Broker节点发送LeaderAndIsrRequest请求,向所有的Broker发送UPDATE_METADATA请求,更新自身的缓存。
- Controller向分区所属的Broker发送请求
- Broker节点接收到请求后,根据分区状态信息,设定当前的副本为Leader或Follower,并创建底层的数据存储文件目录和空的数据文件。
文件目录名:主题名 + 分区编号
文件名说明0000000000000000.log数据文件,用于存储传输的小心0000000000000000.index索引文件,用于定位数据0000000000000000.timeindex时间索引文件,用于定位数据
版权归原作者 _Matthew 所有, 如有侵权,请联系我们删除。